linux下centOs7搭建hadoop完全分布式集群
hadoop作用及其hadoop一些理论知识,我在这里就不讲解了,我搭建hadoop之前我也看了好多博客各种搭建,按照其他博客上写的我搭建了好多次都未能安装成功,后来还是在网上看了马士兵老师的讲解后才搭建成功的(自己看其他博客未能搭建成功,可能是由于自身理解与举一反三有限导致)好了,不再多说废话了来跟我一起搭建吧!
我这里搭建是完全分布式集群,用了四台linux服务器(虚拟机,因为没有正式的服务器,服务器太贵了没有钱买,如果哪位想学习真正的技术或者可以真正的模拟生产环境可以资助我点钱买服务器,我们可以一起使用学习)
一台namenode,三台datanode,且由一台namenode管理三台datanode
服务器分别为 namenode master 192.168.140.134 datanode 分别为 slave1 192.168.140.135 slave1 192.168.140.136 slave1 192.168.140.137
这里我们先在一台master操作,这个配置完在复制出3分slave
1.永久性的关闭防火墙(至于为何永久性关闭,怕重启服务器后防火墙自动打开影响使用)systemctl disable firewalld
安装java环境我在此就不在说了,如果说不懂linux的话 看我centOs7基本软件安装博客 https://blog.csdn.net/qq_15138689/article/details/80427467
去官网下载hadoop压缩包,我这里使用的hadoop-2.7.7
将其上传至 master 服务器 将其解压
tar -zxvf ... 解压 方便起见将解压的文件改名为 hadoop
mv hadoop-2.7.7 hadoop

进入hadoop

jdk的java_home需要配置一下,yum安装的jdk没有配置javahome 我们要进入 /etc/profile去编译一下
![]()

jdk的所在目录要根据自己服务器的具体路径去配置
配置完需要重启加载生效一下
![]()
验证一下是否生效

经过验证生效了,接下来我们修改主机名称,便于hadoop的从节点访问(ip不是也可以访问,你来回写ip不是很麻烦,给他起个名字配置一下岂不是很方便)
![]()
执行查看一下

接下来修改hadoop的配置文件,
先修改

配置hadoop的javahome路径地址
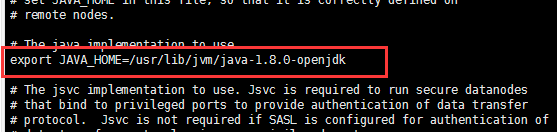
这一段,这一块的地址要根据自身情况来,这一块的地址要根据自身情况来,这一块的地址要根据自身情况来,重要的事情说三遍
配置core-site.xml


加上这一段
是不是比写ip方便多了,9000端口是服务端tcp默认的访问通信端口
配置完成后,我们在把hadoop的命令也加再配置文件里,

![]()
hadoop的地址路径是自己解压的文件路径
加载生效一下配置文件
![]()
执行以下看看是否生效了没有
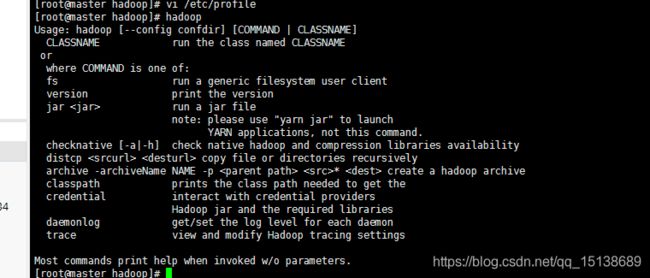
说明已经生效了
shutdown -h now 立即关机
为什么关机啊!因为我前边说过,配置过一个后需要复制出3台slave从节点
我这里已经克隆复制过了,就不在演示了
然后我们分别修改复制的三个服务名字为slave1,slave2,slave3

修改完成后进行配置hosts文件以便于彼此之间能够通过主机名称可以访问
![]()

保存退出,ping一下试试
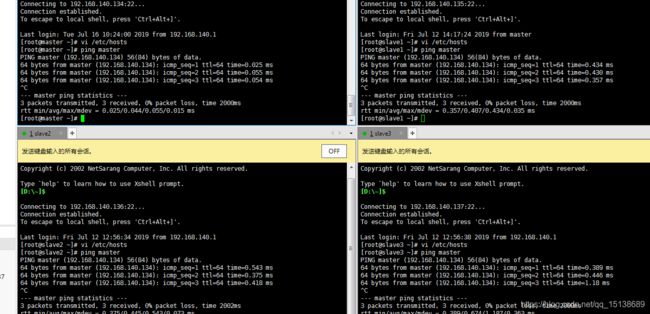

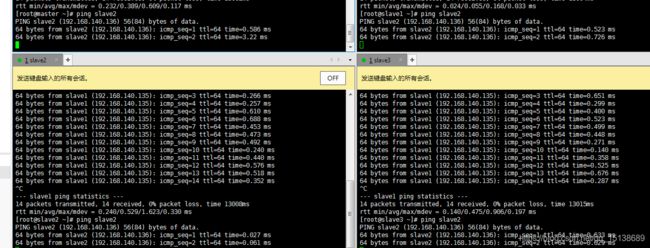
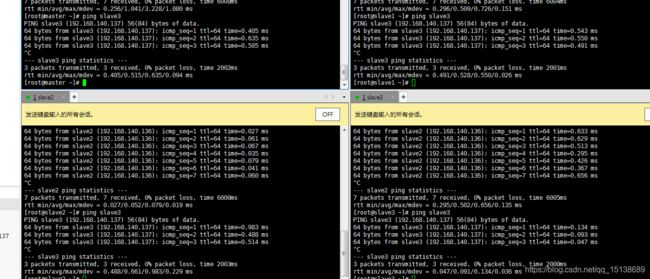
都是可以ping通的,那么这个基本上就可以算是完成了一大半了,那么我们开始启动一下hadoop
先格式化一下namenode
hdfs namenode -format

执行,ok我们启动hadoop

先启动namenode节点,在启动其他的datanode节点
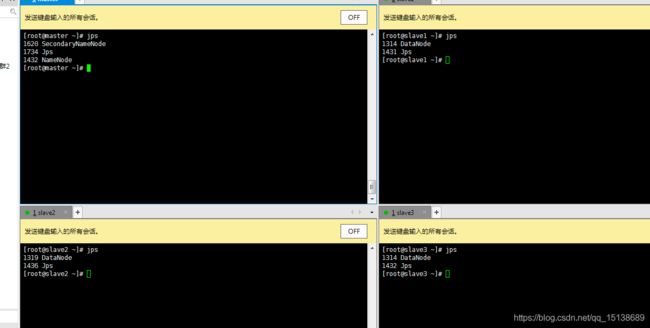
查询一下,jps看到都启动起来了,我们也可以访问以下页面看看
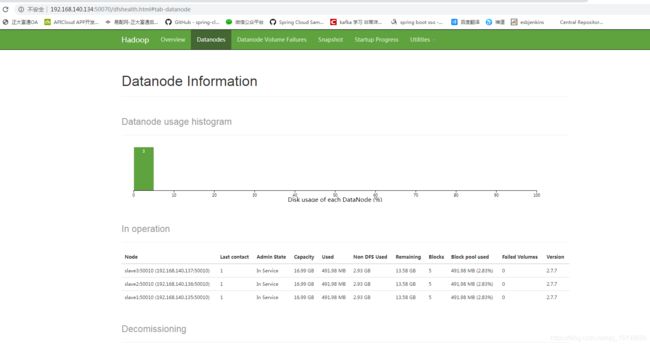
都是ok的,但是这样来回一个个启动感觉好麻烦,如果能通过执行一个电脑全部启动就好了,接下来我们配置一下ssh免登陆模式去集群式启动
在master上生成ssh秘钥
查看秘钥执行如下

查看一下,这个生成的目录在跟目录的.ssh目录下需要执行


会生成这两个,默认的情况下只有一个 known_hosts 文件
然后我们依次将这个秘钥发给三个从节点,也再发给自己一份,因为master服务器也是需要验证的
![]()
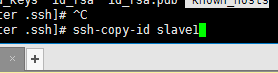


在此过程中如果有的需要输入yes、no时就输入yes 及登录密码即可(因为我之前配置过了,这里就不在重复演示了)
然后测试登录一下



看到我们已经登录成功了ok,接下来在去配置master的hadoop的 slaves配置文件


只需要将主机名写入即可,是不是很方便,ok保存退出
好的,那我们关闭服务 hadoop-daemon.sh stop namenode hadoop-daemon.sh stop datanode
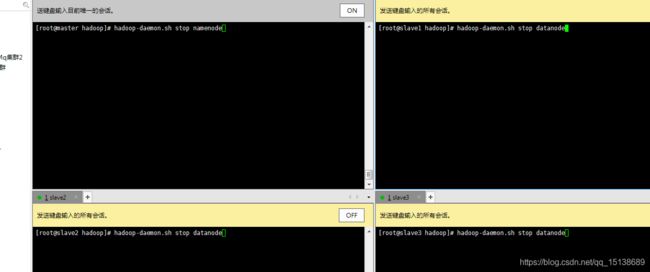

查询一下关闭了,那我们在单个集群启动一下
只需要在master上执行即可
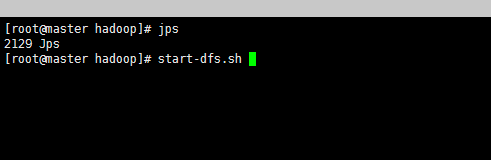
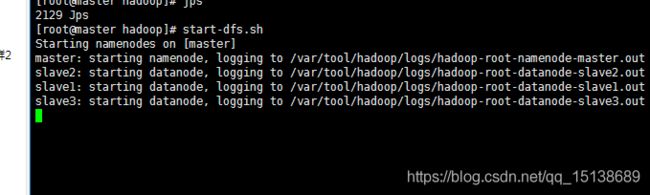
说明在启动了,
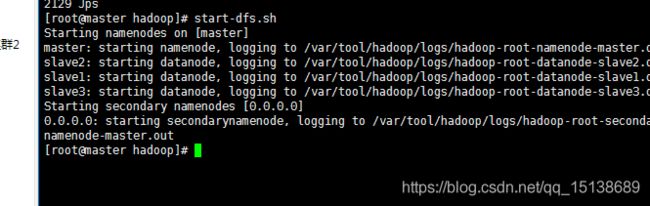
ok启动成功了,我们查看一下

启动成功了,页面在访问以下
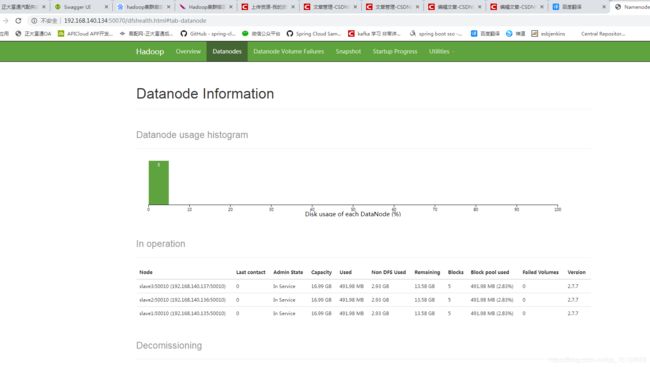
附加如果使用的是2.9.2 需要再datanode节点的服务器 core-site.xml 文件里添加如下
页面也是ok的,到这里hadoop完全分布式集群搭建成功了,后续我会继续完善hadoop并会分享springboot与hadoop的整合,大家如果有什么不懂的或者我这里写的不到的地方欢迎留言探讨