【CentOS】安装 Hadoop (单机版)
文章目录
- 1、上传 hadoop 安装包
- 2、解压安装包并重名命
- 3、配置 Hadoop 环境变量
- 4、配置 Hadoop 文件
- 5、测试 Hadoop 本地模式的运行
环境准备
- 装有jdk的可上网虚拟机
- hadoop-2.7.1.tar.gz 安装包
1、上传 hadoop 安装包
通过XShell将 hadoop-2.7.1.tar.gz 安装包上传至 download 目录(自行创建)下:
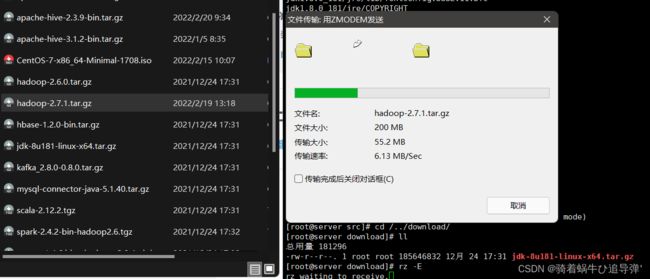

返回顶部
2、解压安装包并重名命
使用如下命令将其进行解压:
[root@server download]# tar -zxvf ./hadoop-2.7.1.tar.gz -C /usr/local/src/
找到解压后的文件夹,并将其重新命名为 hadoop:

打开 hadoop 目录:

说明:
bin: 此目录中存放 Hadoop、HDFS、YARN 和 MapReduce 运行程序和管理软件。
etc: 存放 Hadoop 配置文件。
include: 类似 C 语言的头文件。
lib: 本地库文件,支持对数据进行压缩和解压。
libexe: 本地库文件,支持对数据进行压缩和解压。
sbin: Hadoop 集群启动、停止命令。
share: 说明文档、案例和依赖 jar 包。
返回顶部
3、配置 Hadoop 环境变量
和设置 JAVA 环境变量类似,修改 /etc/profile 文件。
[root@server ~]# vi /etc/profile
在文件的最后增加如下两行:
# HADOOP_HOME 指向 JAVA 安装目录
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source 使用设置生效:
[root@server ~]# source /etc/profile
检查设置是否生效:
[root@server ~]# hadoop
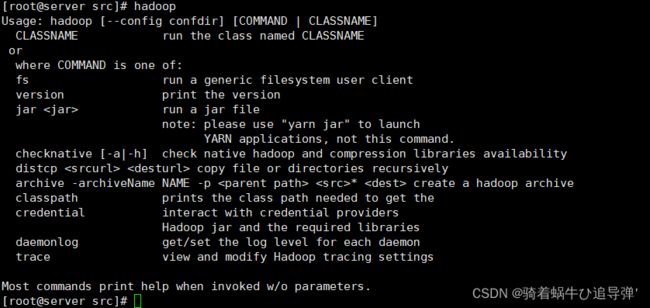
出现上述 Hadoop 帮助信息就说明 Hadoop 已经安装好了。
返回顶部
4、配置 Hadoop 文件
进入 Hadoop 目录:
[root@server ~]# cd /usr/local/src/hadoop/
配置 hadoop-env.sh 文件,目的是告诉 Hadoop 系统 JDK 的安装目录:
[root@server ~]# vi etc/hadoop/hadoop-env.sh
在文件中查找 export JAVA_HOME=.... 这行,将其改为如下所示内容:
export JAVA_HOME=/usr/local/src/java
这样就设置好 Hadoop 的本地模式,下面使用官方案例来测试 Hadoop 是否运行正常。
返回顶部
5、测试 Hadoop 本地模式的运行
将输入数据存放在 ~/input 目录(hadoop 用户主目录下的 input 目录中)。
[root@server ~]$ mkdir ~/input
创建数据输入数据文件 data.txt,将要测试的数据内容输入到 data.txt 文件中:
[root@server ~]$ vi ~/input/data.txt
输入如下内容,保存退出:
Hello World
Hello Hadoop
Hello Spark
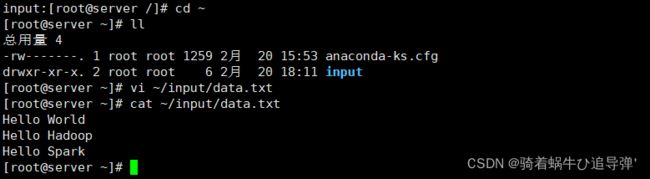
使用 MapReduce 运行 WordCount 官方案例,统计 data.txt 文件中单词的出现频度,首先我们需要到 /hadoop/sbin 目录下开启 hadoop:
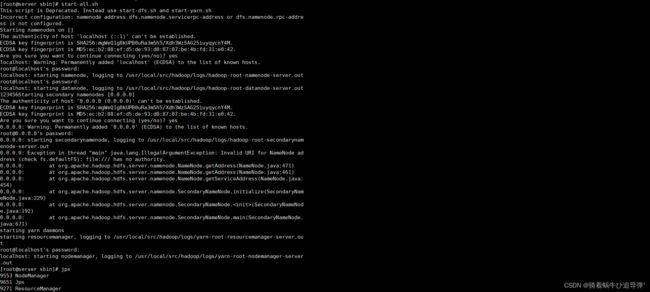
接着使用命令:hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount ~/input/data.txt ~/output,测试案例:
[root@server hadoop]# hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount ~/input/data.txt ~/output
22/02/20 18:26:32 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
22/02/20 18:26:32 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
22/02/20 18:26:33 INFO input.FileInputFormat: Total input paths to process : 1
22/02/20 18:26:33 INFO mapreduce.JobSubmitter: number of splits:1
22/02/20 18:26:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1456367336_0001
22/02/20 18:26:33 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
22/02/20 18:26:33 INFO mapreduce.Job: Running job: job_local1456367336_0001
22/02/20 18:26:33 INFO mapred.LocalJobRunner: OutputCommitter set in config null
22/02/20 18:26:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
22/02/20 18:26:33 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
22/02/20 18:26:33 INFO mapred.LocalJobRunner: Waiting for map tasks
22/02/20 18:26:33 INFO mapred.LocalJobRunner: Starting task: attempt_local1456367336_0001_m_000000_0
22/02/20 18:26:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
22/02/20 18:26:33 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
22/02/20 18:26:33 INFO mapred.MapTask: Processing split: file:/root/input/data.txt:0+37
22/02/20 18:26:33 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
22/02/20 18:26:33 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
22/02/20 18:26:33 INFO mapred.MapTask: soft limit at 83886080
22/02/20 18:26:33 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
22/02/20 18:26:33 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
22/02/20 18:26:33 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
22/02/20 18:26:33 INFO mapred.LocalJobRunner:
22/02/20 18:26:33 INFO mapred.MapTask: Starting flush of map output
22/02/20 18:26:33 INFO mapred.MapTask: Spilling map output
22/02/20 18:26:33 INFO mapred.MapTask: bufstart = 0; bufend = 61; bufvoid = 104857600
22/02/20 18:26:33 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214376(104857504); length = 21/6553600
22/02/20 18:26:33 INFO mapred.MapTask: Finished spill 0
22/02/20 18:26:33 INFO mapred.Task: Task:attempt_local1456367336_0001_m_000000_0 is done. And is in the process of committing
22/02/20 18:26:33 INFO mapred.LocalJobRunner: map
22/02/20 18:26:33 INFO mapred.Task: Task 'attempt_local1456367336_0001_m_000000_0' done.
22/02/20 18:26:33 INFO mapred.LocalJobRunner: Finishing task: attempt_local1456367336_0001_m_000000_0
22/02/20 18:26:33 INFO mapred.LocalJobRunner: map task executor complete.
22/02/20 18:26:33 INFO mapred.LocalJobRunner: Waiting for reduce tasks
22/02/20 18:26:33 INFO mapred.LocalJobRunner: Starting task: attempt_local1456367336_0001_r_000000_0
22/02/20 18:26:33 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
22/02/20 18:26:33 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
22/02/20 18:26:33 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@2758e013
22/02/20 18:26:33 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10
22/02/20 18:26:33 INFO reduce.EventFetcher: attempt_local1456367336_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
22/02/20 18:26:33 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1456367336_0001_m_000000_0 decomp: 51 len: 55 to MEMORY
22/02/20 18:26:33 INFO reduce.InMemoryMapOutput: Read 51 bytes from map-output for attempt_local1456367336_0001_m_000000_0
22/02/20 18:26:33 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 51, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->51
22/02/20 18:26:33 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
22/02/20 18:26:33 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
22/02/20 18:26:33 INFO mapred.LocalJobRunner: 1 / 1 copied.
22/02/20 18:26:33 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
22/02/20 18:26:33 INFO mapred.Merger: Merging 1 sorted segments
22/02/20 18:26:33 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 42 bytes
22/02/20 18:26:33 INFO reduce.MergeManagerImpl: Merged 1 segments, 51 bytes to disk to satisfy reduce memory limit
22/02/20 18:26:33 INFO reduce.MergeManagerImpl: Merging 1 files, 55 bytes from disk
22/02/20 18:26:33 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
22/02/20 18:26:33 INFO mapred.Merger: Merging 1 sorted segments
22/02/20 18:26:33 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 42 bytes
22/02/20 18:26:33 INFO mapred.LocalJobRunner: 1 / 1 copied.
22/02/20 18:26:33 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
22/02/20 18:26:33 INFO mapred.Task: Task:attempt_local1456367336_0001_r_000000_0 is done. And is in the process of committing
22/02/20 18:26:33 INFO mapred.LocalJobRunner: 1 / 1 copied.
22/02/20 18:26:33 INFO mapred.Task: Task attempt_local1456367336_0001_r_000000_0 is allowed to commit now
22/02/20 18:26:33 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1456367336_0001_r_000000_0' to file:/root/output/_temporary/0/task_local1456367336_0001_r_000000
22/02/20 18:26:33 INFO mapred.LocalJobRunner: reduce > reduce
22/02/20 18:26:33 INFO mapred.Task: Task 'attempt_local1456367336_0001_r_000000_0' done.
22/02/20 18:26:33 INFO mapred.LocalJobRunner: Finishing task: attempt_local1456367336_0001_r_000000_0
22/02/20 18:26:33 INFO mapred.LocalJobRunner: reduce task executor complete.
22/02/20 18:26:34 INFO mapreduce.Job: Job job_local1456367336_0001 running in uber mode : false
22/02/20 18:26:34 INFO mapreduce.Job: map 100% reduce 100%
22/02/20 18:26:34 INFO mapreduce.Job: Job job_local1456367336_0001 completed successfully
22/02/20 18:26:34 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=547378
FILE: Number of bytes written=1098168
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=61
Map output materialized bytes=55
Input split bytes=90
Combine input records=6
Combine output records=4
Reduce input groups=4
Reduce shuffle bytes=55
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=397410304
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=37
File Output Format Counters
Bytes Written=45
运行结果保存在 ~/output 目录中,命令执行后查看结果:
[root@server~]$ ll ~/output
总用量 4
-rw-r--r--. 1 root root 33 2月 20 18:26 part-r-00000
-rw-r--r--. 1 root root 0 2月 20 18:26 _SUCCESS
文件 _SUCCESS 表示处理成功,处理的结果存放在 part-r-00000 文件中,查看该文件。
[root@server~]$ cat ~/output/part-r-00000
Hadoop 1
Hello 3
Spark 1
World 1
统计结果正确,说明 Hadoop 本地模式运行正常。
注意:输出目录不能事先创建,如果已经有~/output 目录,就要选择另外的输出目录,或者将~/output 目录先删除,删除命令如下所示。
[root@server~]$ rm -rf ~/output
返回顶部