centos7搭建hadoop完全分布式(详细过程)
centos7安装hadoop(详细过程)
本实验最终的结果是使用四台虚拟机,搭建hadoop集群。我们采用先配置一台,然后,剩下的三台直接克隆虚拟机,然后稍微修改配置就好了。
| 192.168.149.161 | namenode/ resourcemanager/secondarynamenode |
|---|---|
| 192.168.149.162 | datanode/nodemanager |
| 192.168.149.163 | datanode/nodemanager |
| 192.168.149.164 | datanode/nodemanager |
一、 准备条件
- 一台centos7虚拟机(我使用的软件是vm)
- 文件传输工具:Xftp(vm有vm tool但是不太好用)
- 远程连接工具:Xshell(与命令行界面类似,但是支持复制粘贴)
二、修改ip为固定
我当时创建的虚拟机采用的网络连接方式是NAT模式,这样比较适合与外网连接。如果当时选的不是NAT的话,也可以修改。

找到虚拟机的设置选项
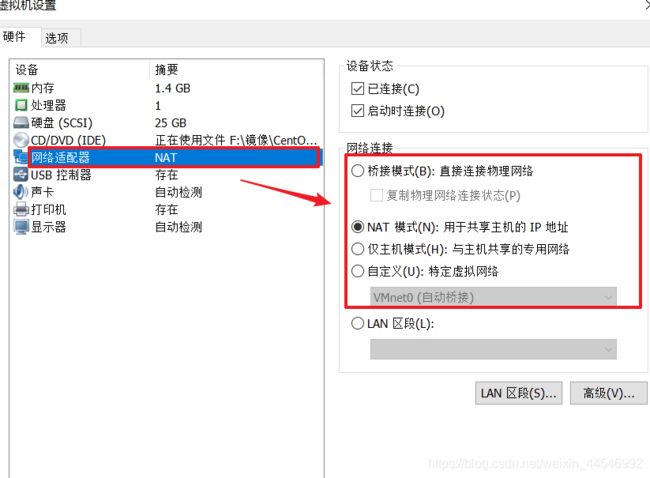
在这里更改之后,点击确定就好。
下面说说具体配置固定ip:
- 确定虚拟网络的参数


选择vmnet8,这就是你的虚拟机的网卡。然后再选择NAT设置和DHCP设置


在本机中查看DNS服务器的ip:

记录好这些内容,当然这些参数大部分是可以修改。但是为了不必要的麻烦(因为懒),我们就不修改了。
2. 进入虚拟机,修改配置
后续步要在root用户下进行
![]()
找到这个文件进行修改,最后的“ens”可能不同,去目录中看一下就知道

ipaddr是你要固定的ip
netmask是子网掩码
gateway是网关
service network restart
重启网络服务
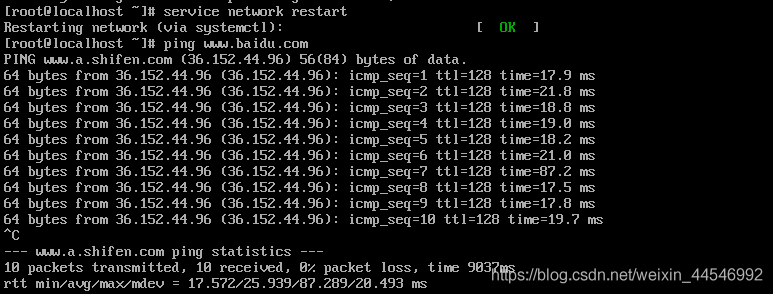
网络启动正常,ping一下百度也没有问题
三、安装jdk
- 下载jdk
去oracle官网下载适宜版本的jdk

需要注册登录,不过下载是免费的。 - 将jdk传输到centos中
我是通过xftp传输的。

这个软件按使用很简单,推荐大家使用,vm本身的工具,我觉得不好用。 - 解压jdk
tar -zxvf jdk-8u241-linux-x64.tar.gz /opt/soft/jdk
记住自己解压的位置,我是习惯于把软件安装到/opt/soft文件夹下,新建一个jdk目录
- 编辑配置文件
vi /etc/profile
将光标移动到末尾,输入以下内容
#java environment
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_241
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
source /etc/profile
使配置文件生效。
- 检查文件是否生效
java -verison

- 修改bashrc文件
vi ~/.bashrc
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_241
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bashrc
四、各种设置
- 关闭防火墙
systemctl stastus fiewalld.service #查看防火墙状态
systemctl stop fiewalld.service #临时关闭防火墙
systemctl disable fiewalld.service #禁止开机自启动
systemctl start fiewalld.service #打开防火墙
systemctl enable fiewalld.service #打开开机启动
这里我们只要用到前三个命令。
- 修改主机名
hostnamectl set-hostname s161

3. 关闭selinux
getenforce #查看状态
setenforce 0 #临时关闭
setenforce 1 #临时打开
要永久关闭,需要修改/etc/sysconfig/selinux文件
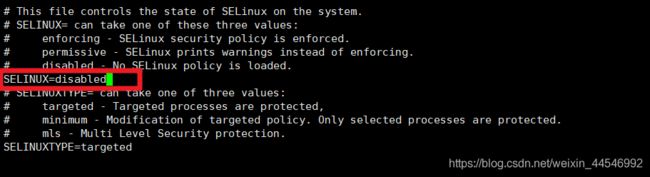

已经关闭。
4. 配置节点的域名解析
vi /etc/hosts

在后面添加,四个节点的ip和主机名,这里我们暂时只有一台虚拟机,这是预准备。
五、安装Hadoop
- 下载hadoop
apache官网的版本挺全,但是下载速度较慢;国内清华的镜像下载的速度挺快,但是版本不是很全。
apache官网:https://archive.apache.org/dist/hadoop/common/
清华镜像:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
我下载的是2.9.1版,不推荐用3.x版,新本有一些生态还不够完善 - 传到centos中解压安装

解压:tar -zxvf hadoop-2.9.1.tar.gz - 配置环境变量
vi /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop/hadoop-2.9.1
export HADOOP_CONF_FILE=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
- 修改~/.bashrc文件
vi ~/.bansrc
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_241
export HADOOP_PREFIX=/opt/soft/hadoop/hadoop-2.9.1
export PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH

注意:这里是在原来jdk的基础上修改的,即这里是jdk+hadoop的内容,不只是hadoop。
最后再使配置文件生效source ~/.bashrc
5. 检查配置
hadoop version
注意这里没有“-”。

ok,成功;
六、编写Hadoop的配置文件
进入${HADOOP_HOME}/etc/hadoop目录下
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s161:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop/hadoop_data/tmp</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop/hadoop_data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop/hadoop_data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
- mapred-site.xml
这个文件本身不存在先执行以下命令:
cp mapred-site.xml.template mapred-site.xml
这就是把mapred-site.xml.template文件在当前文件夹中复制一份并命名为mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>s161:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>s161:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>s161:8031</value>
</property>
</configuration>
- slaves
s162
s163
s164
这里写的是从节点的主机名
- hadoop-env.sh
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_241

七、将虚拟机复制三份
这一步没啥好说的,复制粘贴就完事了。记得先关闭虚拟机再复制。
八、修改另外三台虚拟机信息
- 修改主机名
采用命令:hostnamrctl set-hostname xxx来修改主机名 - 修改ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
改变其中的ip信息
使用:service network restart重启网络服务,最后再ping一下baidu,试一下网络是否是连通的。
3.注意!!!
这里修改的信息,要与之前在/etc/hosts文件中的内容相符。
九、配置四台机器的免密登录
- 修改配置信息
vi /etc/ssh/sshd_config
将下面部分前面的注释“#”去掉
#RSAAuthentication yes
#PubkeyAuthentication yes
#AuthorizedKeysFile .ssh/authorized_keys
这是开启ssh密钥认证。
- 生成密钥
这里采用是rsa加密算法
ssh-keygen -t rsa
连续敲回车就行
- 将公钥写入认证文件
这一步是将自己的公钥写入认证文件
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
连接其他机器,将他们的密钥也写入认证文件
ssh root@s162 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
以其中一台为例,其他两台只要将主机名更换就行。
- 查看认证文件的内容
cat ~/.ssh/authorized_keys
 四台机器的密钥都已经写入认证文件
四台机器的密钥都已经写入认证文件
- 查看known_hosts中的主机列表
vi ~/.ssh/known_hosts
![]() 这里我们可以看到没有s161机器的内容,我们连接一下s161机器
这里我们可以看到没有s161机器的内容,我们连接一下s161机器
ssh s161
 因为这里是主机连接本身,所以之后的用户名和主机名不会有变化,可以输入命令:exit退出连接。再查看一下known_hosts文件
因为这里是主机连接本身,所以之后的用户名和主机名不会有变化,可以输入命令:exit退出连接。再查看一下known_hosts文件![]()
ok了,已经包含全部的四台机器了。
- 将认证文件复制到其他主机
scp ~/.ssh/authorized_keys root@s162:~/.ssh/authorized_keys

这里是由于第一次连接还要输入密码。scp命令常用于传输文件。
-
到其他节点查看文件是否正确传输
 在s162机器中查看文件传输正确。
在s162机器中查看文件传输正确。 -
免密登录测试
ssh s163
在s161节点中输入命令

可以尝试连接所有机器,全部验证一遍。
十、Hadoop集群的启动
- 格式化集群
cd /opt/soft/hadoop/hadoop-2.9.1/etc/hadoop/
hdfs namenode -format
出现以下信息,表示格式化成功

- 启动节点
start-dfs.sh
start-yarn.sh
使用:jps查看启动进程
主节点:

从节点:

- 关闭节点
stop-dfs.sh
stop-yarn.sh
在不适用,或者其他情况下尽量关闭节点。
4. 注意
如果之前有配置错的,重新配置后想要重新格式化,要先删除格式化创建的目录,否则可能会造成datanode进程无法启动的状况。
十一、在web界面中查看hadoop集群
因为我之前装的是没有GUI的centos系统,所以先安装图形界面
- 安装图形界面
我是参考了大神的博客:https://www.jianshu.com/p/94d9135edb91 - 启动集群
这一步与之前启动的方式相同。 - 在web中查看
进入图形界面的虚拟机,以root用户登录(创建hadoop集群的用户)
打开firefox浏览器,在地址栏输入:s161:50070

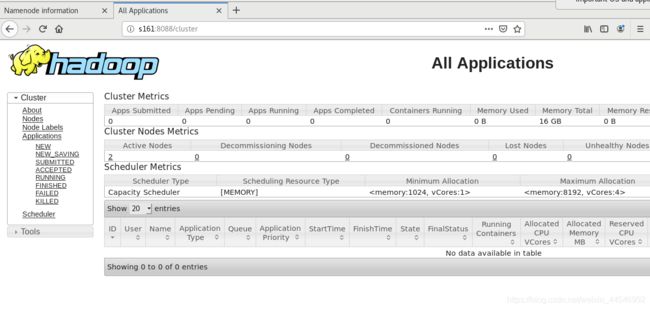
通过8088端口可以查看作业状态: