上一篇文章推导了贝尔曼方程,这一篇文章来继续分享对应的马尔可夫决策的案例,并且引入策略迭代法,证明其收敛性。
主要的学习资源是四个:
- B站许志钦老师的视频(主要入门理论)https://www.bilibili.com/video/BV15a4y1j7vg?spm_id_from=333.999.0.0
- 书籍《强化学习入门:从原理到实践》(叶强等著,机械工业出版社)
- github中的配套资源 https://github.com/qqiang00/Reinforce
- 书籍《强化学习精要:核心算法与TensorFlow实现》(冯超著,中国工信出版集团)
1. 贝尔曼方程的矩阵表示
对于上篇文章推导的贝尔曼方程
为了便于运用矩阵,写成如下:
那么判断好维数就可以得出如下形式:
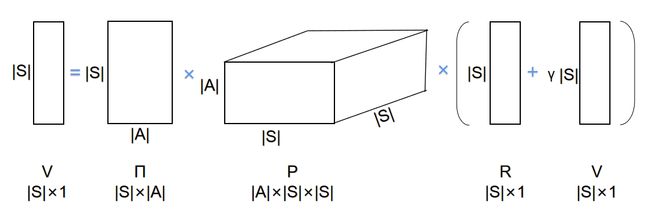
可以抽象出公式:
其中V用于表示状态值函数的向量,Π表示策略矩阵,P表示状态转移矩阵,R表示回报向量。通过求解可以得到:
但矩阵表示起来比较困难,尤其状态转移矩阵P是三维的,我还没有厘清这边的关系,而且大部分资料都不选择去详细解释这个部分,因为这种运算方法计算起来也比较困难,反而大家都采用迭代的方法。关于迭代的方法,我们下面的案例就会涉及到。该案例用python实现,由于其特殊的字典结构,形式上就可以不用数组来构建矩阵,也没有用上面推导的矩阵公式来求解状态。
2. 学生马尔科夫决策奖励过程实例
继续上一篇文章的例子,图中的状态数变成了 5 个,为了方便理解,我们把这五个状态分别命名为:浏览手机中、第一节课、第二节课、第三节课、休息中;行为总数也是 5 个,但具体到某一状态则只有 2 个可能的行为,这 5 个行为分别命名为:浏览手机、学习、离开浏览、泡吧、退出学习。与马尔科夫奖励过程不同,马尔科夫决策过程的状态转移概率与奖励函数均与行为相关。本例中多数状态下某行为将以 100% 的概率到达一个后续状态,但在状态 第三节课 选择 泡吧 行为除外。在对该马尔科夫决策过程进行建模时,我们将使用字典这个数据结构来存放这些概率和奖励。

2.1 构建辅助函数
叶强老师先写了utils.py作为辅助程序,如果只关注函数的用法,可以直接略过这部分的代码。
# 辅助函数
def str_key(*args):
'''将参数用"_"连接起来作为字典的键,需注意参数本身可能会是tuple或者list型,
比如类似((a,b,c),d)的形式。
'''
new_arg = []
for arg in args:
if type(arg) in [tuple, list]:
new_arg += [str(i) for i in arg]
else:
new_arg.append(str(arg))
return "_".join(new_arg)
def set_dict(target_dict, value, *args):
target_dict[str_key(*args)] = value
def set_prob(P, s, a, s1, p = 1.0): # 设置概率字典
set_dict(P, p, s, a, s1)
def get_prob(P, s, a, s1): # 获取概率值
return P.get(str_key(s,a,s1), 0)
def set_reward(R, s, a, r): # 设置奖励字典
set_dict(R, r, s, a)
def get_reward(R, s, a): # 获取奖励值
return R.get(str_key(s,a), 0)
def display_dict(target_dict): # 显示字典内容
for key in target_dict.keys():
print("{}: {:.2f}".format(key, target_dict[key]))
print("")
# 辅助方法
def set_value(V, s, v): # 设置价值字典
set_dict(V, v, s)
def get_value(V, s): # 获取价值值
return V.get(str_key(s), 0)
def set_pi(Pi, s, a, p = 0.5): # 设置策略字典
set_dict(Pi, p, s, a)
def get_pi(Pi, s, a): # 获取策略(概率)值
return Pi.get(str_key(s,a), 0)
2.2 构建MDP模型
MDP就是五元组(S,A,R,P,γ),整体用元组作为数据结构使用。状态集S和动作集A就用列表定义,状态转移概率矩阵和奖励矩阵就用字典存储。具体参数就参考上面的图中的数值。
from utils import str_key, display_dict
from utils import set_prob, set_reward, get_prob, get_reward
from utils import set_value, set_pi, get_value, get_pi
# 构建学生马尔科夫决策过程
S = ['浏览手机中','第一节课','第二节课','第三节课','休息中']
A = ['浏览手机','学习','离开浏览','泡吧','退出学习']
R = {} # 奖励Rsa
P = {} # 状态转移概率Pss'a
gamma = 1.0 # 衰减因子
# 根据学生马尔科夫决策过程示例的数据设置状态转移概率和奖励,默认概率为1
set_prob(P, S[0], A[0], S[0]) # 浏览手机中 - 浏览手机 -> 浏览手机中
set_prob(P, S[0], A[2], S[1]) # 浏览手机中 - 离开浏览 -> 第一节课
set_prob(P, S[1], A[0], S[0]) # 第一节课 - 浏览手机 -> 浏览手机中
set_prob(P, S[1], A[1], S[2]) # 第一节课 - 学习 -> 第二节课
set_prob(P, S[2], A[1], S[3]) # 第二节课 - 学习 -> 第三节课
set_prob(P, S[2], A[4], S[4]) # 第二节课 - 退出学习 -> 休息中
set_prob(P, S[3], A[1], S[4]) # 第三节课 - 学习 -> 休息中
set_prob(P, S[3], A[3], S[1], p = 0.2) # 第三节课 - 泡吧 -> 第一节课
set_prob(P, S[3], A[3], S[2], p = 0.4) # 第三节课 - 泡吧 -> 第二节课
set_prob(P, S[3], A[3], S[3], p = 0.4) # 第三节课 - 泡吧 -> 第三节课
set_reward(R, S[0], A[0], -1) # 浏览手机中 - 浏览手机 -> -1
set_reward(R, S[0], A[2], 0) # 浏览手机中 - 离开浏览 -> 0
set_reward(R, S[1], A[0], -1) # 第一节课 - 浏览手机 -> -1
set_reward(R, S[1], A[1], -2) # 第一节课 - 学习 -> -2
set_reward(R, S[2], A[1], -2) # 第二节课 - 学习 -> -2
set_reward(R, S[2], A[4], 0) # 第二节课 - 退出学习 -> 0
set_reward(R, S[3], A[1], 10) # 第三节课 - 学习 -> 10
set_reward(R, S[3], A[3], +1) # 第三节课 - 泡吧 -> -1
MDP = (S, A, R, P, gamma)
至此,描述学生马尔科夫决策过程的模型就建立好了。当该 MDP 构建好之后,我们可以调用显示字典的方法来查看我们的设置是否正确:
print("----状态转移概率字典(矩阵)信息:----")
display_dict(P)
print("----奖励字典(函数)信息:----")
display_dict(R)
# ----状态转移概率字典(矩阵)信息:----
# 浏览手机中_浏览手机_浏览手机中: 1.00
# 浏览手机中_离开浏览_第一节课: 1.00
# 第一节课_浏览手机_浏览手机中: 1.00
# 第一节课_学习_第二节课: 1.00
# 第二节课_学习_第三节课: 1.00
# 第二节课_退出学习_休息中: 1.00
# 第三节课_学习_休息中: 1.00
# 第三节课_泡吧_第一节课: 0.20
# 第三节课_泡吧_第二节课: 0.40
# 第三节课_泡吧_第三节课: 0.40
# ----奖励字典(函数)信息:----
# 浏览手机中_浏览手机: -1.00
# 浏览手机中_离开浏览: 0.00
# 第一节课_浏览手机: -1.00
# 第一节课_学习: -2.00
# 第二节课_学习: -2.00
# 第二节课_退出学习: 0.00
# 第三节课_学习: 10.00
# 第三节课_泡吧: 1.00
2.3 初始化策略与价值
虽然已经描述好了MDP模型,但要体现强化学习的思想,还要初始化每个状态的价值(开始为0),并且引入指定一个策略π,暂时先采用随机策略。
初始条件下所有状态的价值均设为 0。对于每一个状态只有两种可能性为的该学生马尔科夫决策过程来说,每个可选行为的概率均为 0.5。
# S = ['浏览手机中','第一节课','第二节课','第三节课','休息中']
# A = ['浏览手机','学习','离开浏览','泡吧','退出学习']
# 设置行为策略:pi(a|.) = 0.5
Pi = {}
set_pi(Pi, S[0], A[0], 0.5) # 浏览手机中 - 浏览手机
set_pi(Pi, S[0], A[2], 0.5) # 浏览手机中 - 离开浏览
set_pi(Pi, S[1], A[0], 0.5) # 第一节课 - 浏览手机
set_pi(Pi, S[1], A[1], 0.5) # 第一节课 - 学习
set_pi(Pi, S[2], A[1], 0.5) # 第二节课 - 学习
set_pi(Pi, S[2], A[4], 0.5) # 第二节课 - 退出学习
set_pi(Pi, S[3], A[1], 0.5) # 第三节课 - 学习
set_pi(Pi, S[3], A[3], 0.5) # 第三节课 - 泡吧
print("----策略字典(矩阵)信息:----")
display_dict(Pi)
# 初始时价值为空,访问时会返回0
print("----状态价值字典(矩阵)信息:----")
V = {}
display_dict(V)
# ----策略字典(矩阵)信息:----
# 浏览手机中_浏览手机: 0.50
# 浏览手机中_离开浏览: 0.50
# 第一节课_浏览手机: 0.50
# 第一节课_学习: 0.50
# 第二节课_学习: 0.50
# 第二节课_退出学习: 0.50
# 第三节课_学习: 0.50
# 第三节课_泡吧: 0.50
# ----状态价值字典(矩阵)信息:----
2.4 贝尔曼公式的函数实现
上一篇文章得到的贝尔曼公式是由下面两个子公式实现的。
def compute_q(MDP, V, s, a):
'''根据给定的MDP,价值函数V,计算状态行为对s,a的价值qsa
'''
S, A, R, P, gamma = MDP
q_sa = 0
for s_prime in S:
q_sa += get_prob(P, s,a,s_prime) * get_value(V, s_prime)
q_sa = get_reward(R, s,a) + gamma * q_sa
return q_sa
def compute_v(MDP, V, Pi, s):
'''给定MDP下依据某一策略Pi和当前状态价值函数V计算某状态s的价值
'''
S, A, R, P, gamma = MDP
v_s = 0
for a in A:
v_s += get_pi(Pi, s,a) * compute_q(MDP, V, s, a)
return v_s
3. 迭代法(策略评估)
认真看的同学也发现了,前面的过程中每个状态的价值还是初始化的状态,状态价值字典(矩阵) 为空。我们在第一节就提到了迭代法可以代替矩阵公式求解最终稳定的状态的价值。接下来我们就正式介绍迭代法,或者称为策略评估。
策略评估指计算给定策略下求解状态价值函数的过程。对策略评估,我们可以使用如下方法:从任意一个状态价值函数开始,依据给定的策略,结合贝尔曼方程、状态转移概率和奖励同步迭代更新状态价值函数,直至其收敛,得到该策略下最终的状态价值函数。
对上述过程做几点解释:
- 采用的迭代公式如下:
其中k表示迭代周期。
- 同步迭代:学过数字电路的都知道,同步和异步的区别在于时刻性。在本轮更新未结束前,采用计算的所有数据都是上一轮的。
- 给定策略:在迭代过程中,策略始终不变,无论策略好坏。
- 收敛性:关于这一部分知乎上有一篇专栏讲的比较详细 https://zhuanlan.zhihu.com/p/39279611
这边我自己也总结一下收敛性的证明思路。
| 3.1 策略迭代收敛性证明 |
3.1.1度量空间
常见的度量有:
- 范数:\(d(x, y)=||x-y||_n,n>1\),其中\(||c||_n\)表示向量的n范数,\(||c||_n = (\sum_i|c_i|^n)^{\frac{1}{n}}\)
- \(n=2\)时即为欧式距离
- \(n=1\)时为绝对值距离,又叫曼哈顿距离,即\(d(x, y)=\sum_i|x_i-y_i|\)
- \(n=\infty\)时为最大值距离,又叫切比雪夫距离,即\(d(x,y)=max_i|x_i-y_i|\)
- 离散:
度量空间的定义:一个度量空间由一个二元组 \(
对于任意 \(x,y,z\in M\) , 有
- (非负性) \(d(x,y)>0\) ,且 \(d(x,y)=0\) ⇔ \(x=y\)
- (对称性) \(d(x,y)=d(y,x)\)
- (三角不等式) \(d(x,z)
3.1.2完备的度量空间
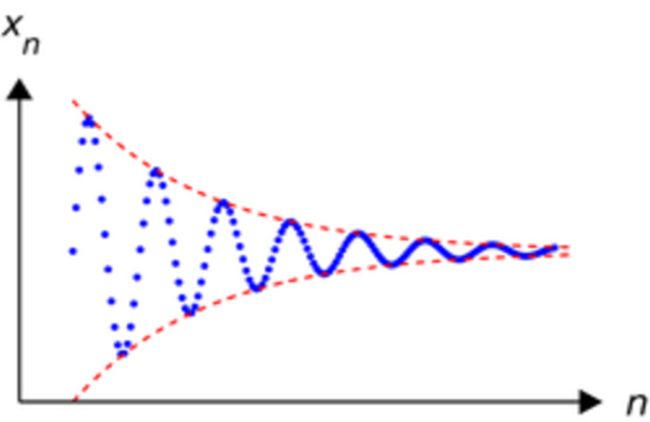
一个柯西序列是指一个这样一个序列,它的元素随着序数的增加而愈发靠近。更确切地说,在去掉有限个元素后,可以使得余下的元素中任何两点间的距离的最大值不超过任意给定的正的常数。
完备的度量空间的定义:一个度量空间\(
3.1.3压缩映射定理
压缩映射的定义 : 对于一个度量空间\(
压缩映射定理:对于完备的度量空间\(
该定理的证明可以参考上面的知乎专栏。
3.1.4策略评估的收敛性
在一般的马尔可夫强化学习中,有限状态集\(S=\{s_0,s_1,...,s_n\}\),对应的状态值函数的向量\(V\)为:
该向量属于值函数空间 \(M\),考虑 \(M\) 是一个n维向量全空间。又因为我们迭代希望的是接近无穷,所以可以定义该空间的度量是无穷范数(切比雪夫距离),即
其中 \(V\) 和 \(U\) 都是 \(M\) 中的向量。
由于 \(M\) 是向量全空间,因此\(
类似于本文的开头已经抽象出的贝尔曼矩阵表示形式:\(V=Π P (R+γV)\),策略评估也抽象出如下的贝尔曼迭代公式:
若对任意策略,都以一定的概率在有限步终止,则可以证明\(F\)是一个压缩映射:
第一个不等号是根据切比雪夫距离的定义,第二个不等号是因为 \(Π\) 和 \(P\) 都是概率,所有的元素都不大于1。
根据压缩映射定理,我们可以直接得到:在策略评估中,贝尔曼期望方程收敛于唯一的\(V'\),且满足\(V'=Π P (R+γV')\)
| 3.2 策略评估实例 |
我们继续本文的例子,其进行迭代,不断更新状态价值字典。
# 根据当前策略使用回溯法来更新状态价值。
def update_V(MDP, V, Pi):
'''给定一个MDP和一个策略,更新该策略下的价值函数V
'''
S, _, _, _, _ = MDP
V_prime = V.copy()
for s in S:
#set_value(V_prime, s, V_S(MDP, V_prime, Pi, s))
V_prime[str_key(s)] = compute_v(MDP, V_prime, Pi, s)
return V_prime
# 策略评估,得到该策略下最终的状态价值。
def policy_evaluate(MDP, V, Pi, n):
'''使用n次迭代计算来评估一个MDP在给定策略Pi下的状态价值,初始时价值为V
'''
for i in range(n):
V = update_V(MDP, V, Pi)
#display_dict(V)
return V
测试验证,我们期望的状态价值结果应该是和所给实例中的状态参数一致。
V = policy_evaluate(MDP, V, Pi, 100)
display_dict(V)
# 验证状态在某策略下的价值
v = compute_v(MDP, V, Pi, "第三节课")
print("第三节课在当前策略下的价值为:{:.2f}".format(v))
# 浏览手机中: -2.31
# 第一节课: -1.31
# 第二节课: 2.69
# 第三节课: 7.38
# 休息中: 0.00
# 第三节课在当前策略下的价值为:7.38
本系列第一个学生马尔可夫项目已经分享完成,下一篇文章会介绍策略提升和价值迭代,引入格子世界项目