肝通宵写了三万字把SQL数据库的所有命令,函数,运算符讲得明明白白讲解,内容实在丰富,建议收藏+三连好评!
文章目录
-
- 前言
- MYSQL 最重要的命令
- SELECT选择语句
- SELECT DISTINCT 选择不同语句
- WHERE 查询定位 子句
- AND、OR 和 NOT 运算符
- ORDER BY 关键字
- INSERT INTO 插入语句
- NULL 空值
- UPDATE更新语句
- DELETE删除语句
- TOP、LIMIT、FETCH FIRST 或 ROWNUM限制子句
- MIN() 和 MAX()函数求最大最小值
- COUNT()、AVG() 和 SUM()函数
- LIKE运算符
- 通配符*?!等
- IN运算符
- BETWEEN 之间运算符
- AS 别名使用
- JOIN连接
- INNER JOIN内连接关键字
- LEFT JOIN 左连接 关键字
- RIGHT JOIN右连接 关键字
- FULL OUTER JOIN 关键字
- Self Join自连接 关键字
- GROUP BY语句
- HAVING 子句
- EXISTS 运算符
- 注释
- 运算符
前言
大家可能不习惯SQL大写的习惯,但是真正的规范就是要大写,所以大家要慢慢习惯我用大写的方式讲解。在下面所有的讲解中,我将会以基本语法,案例,联系形式讲解,从而加强对每一个语句的使用和认识。本篇文章是笔者整理了整整一个通宵才写出,希望大家三连好评,谢谢。当然,拥有本篇文章,你将会完全掌握mysql的所有命令使用,不再用去购买或者杂乱学习。本篇内容暂时讲解数据库的筛选部分,因为数据库的最初入门如创建,备份等都有讲过,魔法传送:传送门
该传送门内容有:

MYSQL 最重要的命令
SELECT 从数据库中提取数据
UPDATE 更新数据库中的数据
DELETE 从数据库中删除数据
INSERT INTO 将新数据插入数据库
CREATE DATABASE 创建一个新的数据库
ALTER DATABASE 修改数据库
CREATE TABLE 创建一个新表
ALTER TABLE 修改表
DROP TABLE 删除表
CREATE INDEX 创建索引(搜索键)
DROP INDEX 删除索引
SELECT选择语句
该SELECT语句用于从数据库中选择数据。返回的数据存储在一个结果表中,称为结果集。
SELECT 语法:
SELECT column1, column2, ...
此处,column1、column2、… 是要从中选择数据的表的字段名称。如果要选择表中的所有可用字段,请使用以下语法:
SELECT * FROM table_name;
假设我们已经有一个数据库Customers如下:

SELECT 列示例
以下 SQL 语句从“Customers”表中选择“CustomerName”和“City”列:
SELECT CustomerName, City FROM Customers;
SELECT * 示例
以下 SQL 语句从“Customers”表中选择所有列:
SELECT * FROM Customers;
练习题:
1-获取Customers表中的所有列。
SELECT * FROM Customers;
2-编写一条语句,City从Customers表中选择列。
SELECT City FROM Customers;
3-从Customers表中的Country列中选择所有不同的值。(下面会讲,不懂没关系)
SELECT DISTINCT Country FROM Customers;
SELECT DISTINCT 选择不同语句
该SELECT DISTINCT语句仅用于返回不同(不同)的值。在表中,一列通常包含许多重复值;有时您只想列出不同的(不同的)值。
SELECT DISTINCT 语法
SELECT DISTINCT column1, column2, ...
FROM table_name;
我们还是假设有这样一个Customers数据库:

没有 DISTINCT 的 SELECT 示例
以下 SQL 语句从“Customers”表的“Country”列中选择所有(包括重复的)值:
SELECT Country FROM Customers;
SELECT DISTINCT 示例
SELECT DISTINCT Country FROM Customers;
以下 SQL 语句列出了不同(不同)客户国家/地区的数量:
SELECT COUNT(DISTINCT Country) FROM Customers;
练习:
1-从表中的Country列中选择所有不同的值Customers。
SELECT DISTINC Country FROM Customers;
WHERE 查询定位 子句
该WHERE子句用于过滤记录。它用于仅提取满足指定条件的记录。
WHERE 语法
SELECT column1, column2, ...
FROM table_name
WHERE condition;
注: 该WHERE条款不仅在使用 SELECT的语句,它也被用在UPDATE, DELETE等!
我们假设还是有Customers这样一个数据库如下:

WHERE 子句示例
以下 SQL 语句在“Customers”表中选择来自国家“Mexico”的所有客户:
SELECT * FROM Customers
WHERE Country='Mexico';
文本字段与数字字段
SQL 需要在文本值周围使用单引号(大多数数据库系统也允许双引号)。但是,数字字段不应包含在引号中:
SELECT * FROM Customers
WHERE CustomerID=1;
WHERE 子句中的运算符
可以在WHERE子句中使用以下运算符:

我们可以一一演示这些符号的使用,耐心学
假设我们有一下数据库叫做Product:
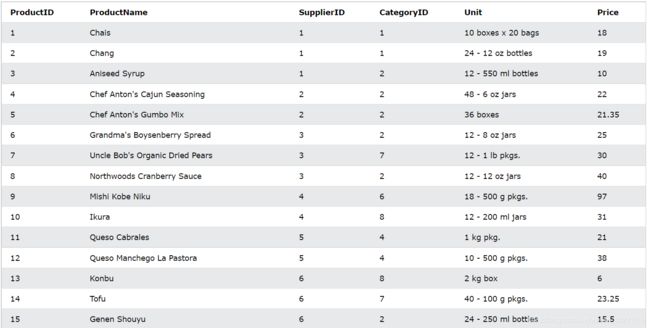
选取价格为18的所有产品(=)
SELECT * FROM Products
WHERE Price = 18;
选取所有价格大于30的产品(>)
SELECT * FROM Products
WHERE Price > 30;
选取所有价格小于30的产品(<)
SELECT * FROM Products
WHERE Price < 30;
选取所有价格大于等于30的产品(>= )
SELECT * FROM Products
WHERE Price >= 30;
选取所有价格小于等于30的产品( <= )
SELECT * FROM Products
WHERE Price <= 30;
选取所有价格不等于18的产品(相当于!=)
SELECT * FROM Products
WHERE Price <> 18;
选取所有价格处于50和60之间的产品
SELECT * FROM Products
WHERE Price BETWEEN 50 AND 60;
从上面的Customers数据库搜索所有字母s开头的城市
SELECT * FROM Customers
WHERE City LIKE 's%';
从Customers数据库中查找所有在Paris和London的用户
SELECT * FROM Customers
WHERE City IN ('Paris','London');
以上便是对所有符号的演示。
我们再来一些练习加以巩固(我们用到的是上面的customers)
1-选择City列值为“Berlin”的所有记录。
SELECT * FROM Customers
WHERE City='Berlin';
2-使用NOT关键字选择City不是"Berlin"的所有记录。
SELECT * FROM Customers
WHERE NOT City ='Berlin';
3-选择CustomerID列值为 32 的所有记录。
SELECT * FROM Customers
WHERE CustomerID =12;
AND、OR 和 NOT 运算符
该WHERE子句可以结合 AND,OR和 NOT操作。在AND与OR操作用于基于多个条件筛选记录:
该AND操作显示一个记录,如果所有条件满足 AND 为真。
所述OR操作显示一个记录,如果任何一个条件满足OR为真。
该NOT操作显示,如果条件(S)是不正确的记录。
AND 语法
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3 ...;
OR语法
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;
NOT语法
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;
我们还是假设有如下“Customers”表:
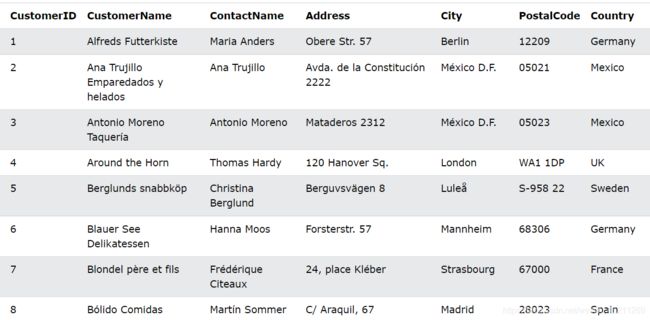
AND 示例
以下 SQL 语句从Customers中选择国家为"Germany"且city为"Berlin"的所有字段:
SELECT * FROM Customers
WHERE Country='Germany' AND City='Berlin';
OR 示例
选取所有"Customers" 中city为"Berlin" OR “München”:
SELECT * FROM Customers
WHERE City='Berlin' OR City='München';
NOT 示例
从 “Customers” 选取country不是 "Germany"的字段:
SELECT * FROM Customers
WHERE NOT Country='Germany';
结合AND, OR and NOT
从"Customers" 中选择国家为"Germany"”且城市必须为"Berlin" OR "München"的所有字段(使用括号形成复杂的表达式):
SELECT * FROM Customers
WHERE Country='Germany' AND (City='Berlin' OR City='München');
从 “Customers"中选择国家不是“Germany” 也不是"USA":的所有字段:
SELECT * FROM Customers
WHERE NOT Country='Germany' AND NOT Country='USA';
练习
选择 City 列值为 ‘Berlin’ 且 PostalCode 列值为 12209 的所有记录。
SELECT * FROM Customers
WHERE City = 'Berlin'
AND PostalCode= 12209;
ORDER BY 关键字
该ORDER BY关键字用于按升序或降序对结果集进行排序。ORDER BY默认情况下,关键字按升序对记录进行排序。要按降序对记录进行排序,请使用 DESC关键字。
ORDER BY 语法
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
我们还是假设有这个“Customers”表如下:
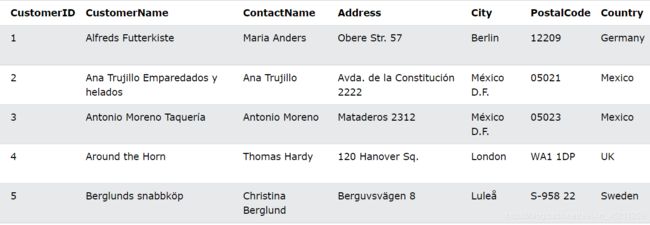
ORDER BY 示例
从“Customers”表中选择所有客户,按“Country”列排序:
SELECT * FROM Customers
ORDER BY Country;
ORDER BY DESC 示例
从“Customers”表中选择所有客户,按“Country”列按 DESCENDING 排序:
SELECT * FROM Customers
ORDER BY Country DESC;
ORDER BY 多列示例
从“Customers”表中选择所有客户,按“Country”和“CustomerName”列排序。这意味着它按国家/地区排序,但如果某些行具有相同的国家/地区,则按 CustomerName 排序:
SELECT * FROM Customers
ORDER BY Country, CustomerName;
从“Customers”表中选择所有客户,按“Country”升序和“CustomerName”列降序排序:
SELECT * FROM Customers
ORDER BY Country ASC, CustomerName DESC;
练习
从Customers表中选择所有记录,按城市列的字母顺序对结果进行排序。
SELECT * FROM Customers
ORDER BY City;
INSERT INTO 插入语句
该INSERT INTO语句用于在表中插入新记录。
INSERT语法
可以INSERT INTO 用两种方式编写语句:
1- 指定要插入的列名和值:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
2-如果要为表的所有列添加值,则无需在 SQL 查询中指定列名。但是,请确保值的顺序与表中的列顺序相同。在这里, INSERT INTO语法如下:
INSERT INTO table_name
VALUES (value1, value2, value3, ...);
我们假设还是有着样一个Customers表:
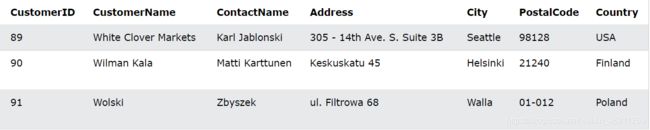
INSERT示例
以下 SQL 语句在“Customers”表中插入一条新记录:
INSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country)
VALUES ('Cardinal', 'Tom B. Erichsen', 'Skagen 21', 'Stavanger', '4006', 'Norway');
运行显示如下:
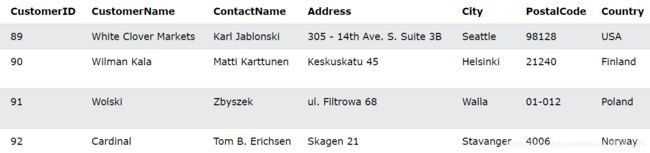
您是否注意到我们没有在 CustomerID 字段中插入任何数字?CustomerID 列是一个自动递增字段,将在新记录插入表中时自动生成。
仅在指定列中插入数据
下面的 SQL 语句将插入一条新记录,但只在“CustomerName”、“City”和“Country”列中插入数据(CustomerID 会自动更新):
INSERT INTO Customers (CustomerName, City, Country)
VALUES ('Cardinal', 'Stavanger', 'Norway');
运行后将会显示如下:
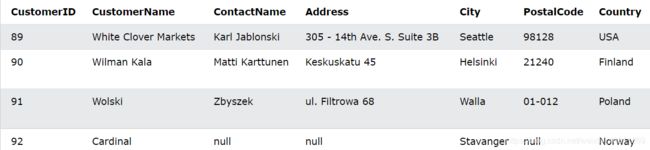
练习:
表中插入一条新记录。
INSERT INTO Customers
(
CustomerName,
Address,
City,
PostalCode,
Country
)
VALUES
(
'Hekkan Burger',
'Gateveien 15',
'Sandnes',
'4306',
'Norway'
)
;
NULL 空值
具有 NULL 值的字段是没有值的字段。如果表中的字段是可选的,则可以在不向该字段添加值的情况下插入新记录或更新记录。然后,该字段将保存为 NULL 值。
注意: NULL 值不同于零值或包含空格的字段。具有 NULL 值的字段是在创建记录期间留空的字段!
如何测试 NULL 值?
无法使用比较运算符(例如 =、< 或 <>)测试 NULL 值。我们将不得不改用IS NULL和 IS NOT NULL运算符。
IS NULL 语法
SELECT column_names
FROM table_name
WHERE column_name IS NULL;
IS NOT NULL 语法
SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;
我们还是以”Customers”表为例子:

IS NULL 运算符
列出了 "Address"字段中具有 NULL 值的所有客户:
SELECT CustomerName, ContactName, Address
FROM Customers
WHERE Address IS NULL;
提示:始终使用 IS NULL 来查找 NULL 值。
IS NOT NULL 运算符
该IS NOT NULL运算符用于测试非空值(NOT NULL 值)。
列出了在 "Address”字段中具有值的所有客户:
SELECT CustomerName, ContactName, Address
FROM Customers
WHERE Address IS NOT NULL;
练习:
从列为空的Customers位置选择所有记录PostalCode。
SELECT * FROM Customers
WHERE PostalCode IS NULL;
UPDATE更新语句
UPDATE语句用于修改表中的现有记录。
UPDATE 语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
注意: 更新表中的记录时要小心!注意 WHERE语句中的子句UPDATE。该WHERE子句指定应该更新哪些记录。如果省略该WHERE子句,表中的所有记录都将被更新!
我们还是以“Customers”表为例:

更新表
更新CustomerID = 1的用户名字和城市数据
UPDATE Customers
SET ContactName = 'Alfred Schmidt', City= 'Frankfurt'
WHERE CustomerID = 1;
更新过后将会如下:

更新多条记录
该WHERE子句确定将更新多少条记录。
将国家为"Mexico"的所有记录的 ContactName 更新为“Juan”:
UPDATE Customers
SET ContactName='Juan'
WHERE Country='Mexico';
更新后将会变成:

更新警告!
更新记录时要小心。如果省略该 WHERE子句,则所有记录都将被更新!
例如:
UPDATE Customers
SET ContactName='Juan';
则会导致如下结果:

练习:
更新表City中所有记录的Customers列。
UPDATE Customers
SET City = 'Oslo';
DELETE删除语句
该DELETE语句用于删除表中的现有记录。
删除语法
DELETE FROM table_name WHERE condition;
注意: 删除表中的记录时要小心!注意 WHERE语句中的子句 DELETE。该WHERE条款指定应删除哪些记录。如果省略该WHERE子句,表中的所有记录都将被删除!
哈哈哈哈,我们还是以“Customers”表为例子如下:

删除示例
从“Customers”表中删除客户“Alfreds Futterkiste”:
DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste';
于是就变成这样:

删除所有记录
可以在不删除表的情况下删除表中的所有行。这意味着表结构、属性和索引将保持不变
DELETE FROM table_name;
例如:删除“Customers”表中的所有行,但不删除该表:
DELETE FROM Customers;
练习:从Customers表中删除Country值为“挪威”的所有记录。
DELETE FROM Customers
WHERE Country = 'Norway';
TOP、LIMIT、FETCH FIRST 或 ROWNUM限制子句
SELECT TOP 子句
SELECT TOP子句用于指定要返回的记录数。SELECT TOP子句在具有数千条记录的大表上很有用。返回大量记录会影响性能。
注意: 并非所有数据库系统都支持该 SELECT TOP子句。MySQL 支持LIMIT子句选择有限数量的记录,而 Oracle 使用FETCH FIRST n ROWSONLYROWNUM
Server / MS 访问语法:
SELECT TOP number|percent column_name(s)
FROM table_name
WHERE condition;
MySQL 语法:
SELECT column_name(s)
FROM table_name
WHERE condition
LIMIT number;
Oracle 12 语法:
SELECT column_name(s)
FROM table_name
ORDER BY column_name(s)
FETCH FIRST number ROWS ONLY;
比如还是“Customers”表如下

TOP、LIMIT 和 FETCH FIRST示例
从 "Customers表中选择前三个记录(用于 SQL Server/MS Access):
SELECT TOP 3 * FROM Customers;
MySQL 的等效示例:
SELECT * FROM Customers
LIMIT 3;
Oracle 的等效示例:
SELECT * FROM Customers
FETCH FIRST 3 ROWS ONLY;
TOP PERCENT 示例
从"Customers“表中选择前 50% 的记录(用于 SQL Server/MS Access):
SELECT TOP 50 PERCENT * FROM Customers;
Oracle 的等效示例:
SELECT * FROM Customers
FETCH FIRST 50 PERCENT ROWS ONLY;
添加 WHERE 条款
从“Customers”表中选择前三个记录,其中国家是“Germany”(对于 SQL Server/MS Access):
SELECT TOP 3 * FROM Customers
WHERE Country='Germany';
MySQL 的等效示例
SELECT * FROM Customers
WHERE Country='Germany'
LIMIT 3;
Oracle 的等效示例:
SELECT * FROM Customers
WHERE Country='Germany'
FETCH FIRST 3 ROWS ONLY;
MIN() 和 MAX()函数求最大最小值
MIN()函数返回所选列的最小值。MAX()函数返回所选列的最大值。
MIN() 语法
SELECT MIN(column_name)
FROM table_name
WHERE condition;
MAX() 语法
SELECT MAX(column_name)
FROM table_name
WHERE condition;
现在我们换一个新的表Product如下:
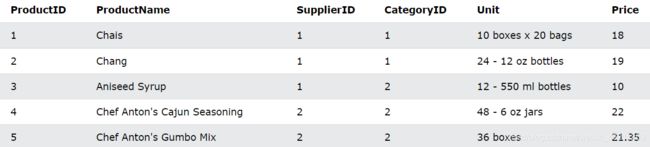
MIN() 示例
查找最便宜产品的价格:
SELECT MIN(Price) AS SmallestPrice
FROM Products;
显示如下:

MAX() 示例
查找最贵产品的价格:
SELECT MAX(Price) AS LargestPrice
FROM Products;
返回如下:

练习:
使用该MIN函数选择Price列的最小值的记录。
SELECT MIN(Price) FROM Products;
COUNT()、AVG() 和 SUM()函数
该COUNT()函数返回与指定条件匹配的行数。
COUNT() 语法
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
该AVG()函数返回数字列的平均值。
AVG() 语法
SELECT AVG(column_name)
FROM table_name
WHERE condition;
该SUM()函数返回数字列的总和。
SUM() 语法
SELECT SUM(column_name)
FROM table_name
WHERE condition;
我们还是用表product
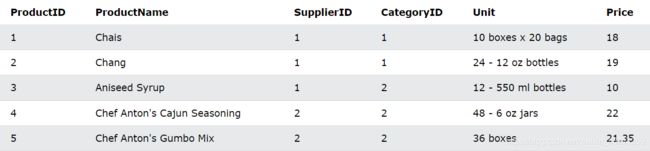
COUNT() 示例
查找产品数量:
SELECT COUNT(ProductID)
FROM Products;
注意: NULL 值不计算在内。
AVG() 示例
查找所有产品的平均价格:
SELECT AVG(Price)
FROM Products;
注意: NULL 值被忽略。
假设我现在有“OrderDetails”表如下:
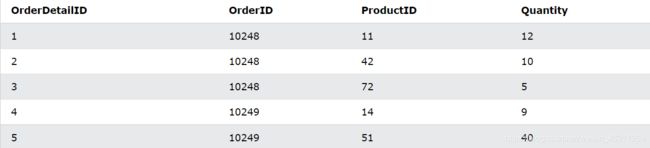
SUM() 示例
查找“OrderDetails”表中“Quantity”字段的总和:
SELECT SUM(Quantity)
FROM OrderDetails;
返回如下:

注意: NULL 值被忽略。
练习:
返回Price值设置为18的记录数
SELECT COUNT(*) FROM Products
WHERE Price = 18;
LIKE运算符
该LIKE运算符在 WHERE子句中用于搜索列中的指定模式。有两个通配符经常与 LIKE运算符结合使用:
百分号 (%) 代表零、一个或多个字符
下划线 () 代表一个,单个字符
但是呢注意: MS Access 使用星号 (*) 代替百分号 (%),使用问号 (?) 代替下划线 ()
当然百分号和下划线也可以组合使用!
LIKE 语法
SELECT column1, column2, ...
FROM table_name
WHERE columnN LIKE pattern;
提示:您还可以使用 AND或OR运算符组合任意数量的条件。
以下是一些示例,显示了LIKE带有“%”和“_”通配符的不同运算符:
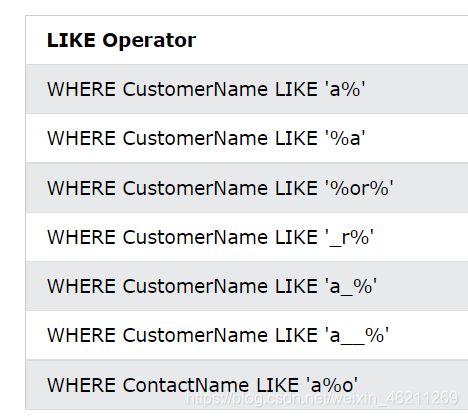
所对应意思为:
第一行:匹配任何以a开头的字段
第二行:匹配任何以a结尾的字段
第三行:匹配任何具有“or”的字段
第四行:查找第二个位置有“r”的任何值
第五行:查找任何以“a”开头且长度至少为 2 个字符的值
第六行:查找任何以“a”开头且长度至少为 3 个字符的值
第七行:查看以“a”开头并以“o”结尾的任何值
比如我们还是有如下Customers”表:
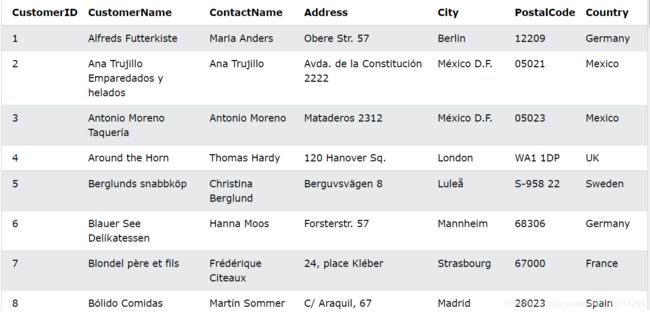
LIKE 示例
选择 CustomerName 以“a”开头的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE 'a%';
选择 CustomerName 以“a”结尾的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE '%a';
选择 CustomerName 中任何位置都有“或”的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE '%or%';
选择 CustomerName 中第二个位置为“r”的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE '_r%';
选择 CustomerName 以“a”开头且长度至少为 3 个字符的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE 'a__%';
选择 ContactName 以“a”开头并以“o”结尾的所有客户:
SELECT * FROM Customers
WHERE ContactName LIKE 'a%o';
选择 CustomerName 不以“a”开头的所有客户:
SELECT * FROM Customers
WHERE CustomerName NOT LIKE 'a%';
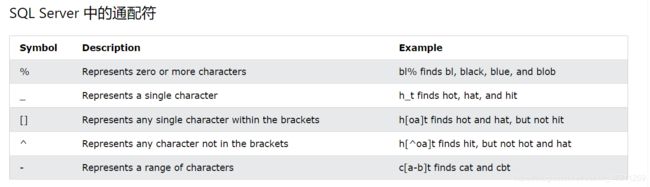
通配符*?!等
这是英文文档所有通配符描述(实在不想翻译,大家自己看看)

假设我们还是有如下“Customers”表:
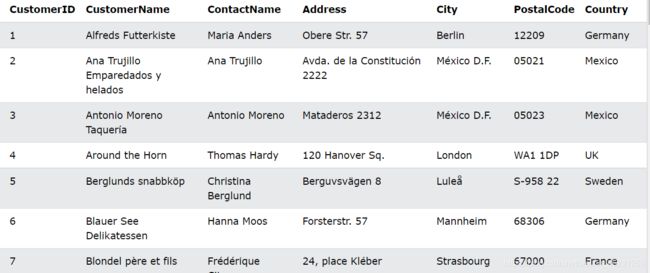
使用 % 通配符
选择 City 以“ber”开头的所有客户:
SELECT * FROM Customers
WHERE City LIKE 'ber%';
选择 City 包含“es”的所有客户:
SELECT * FROM Customers
WHERE City LIKE '%es%';
返回如下:
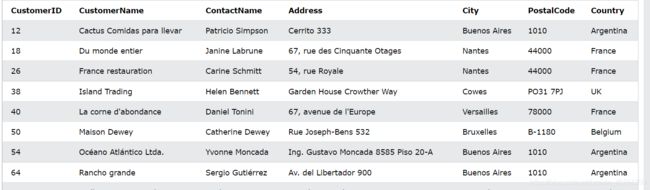
使用 _ 通配符
选择 City 以任何字符开头,后跟“ondon”的所有客户:
SELECT * FROM Customers
WHERE City LIKE '_ondon';
选择 City 以“L”开头、后跟任意字符、“n”、任意字符、“on”的所有客户:
SELECT * FROM Customers
WHERE City LIKE 'L_n_on';
使用 [charlist] 通配符
选择 City 以“b”、“s”或“p”开头的所有客户:
SELECT * FROM Customers
WHERE City LIKE '[bsp]%';
选择 City 以“a”、“b”或“c”开头的所有客户:
SELECT * FROM Customers
WHERE City LIKE '[a-c]%';
使用 [!charlist] 通配符
选择 City 不是以“b”、“s”或“p”开头的所有客户:
SELECT * FROM Customers
WHERE City LIKE '[!bsp]%';
或者
SELECT * FROM Customers
WHERE City NOT LIKE '[bsp]%';
IN运算符
IN运算符允许您在 WHERE子句中指定多个值。
IN操作是针对多个速记 OR条件。
IN 语法
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);
我们还是以“Customers”表为例子:
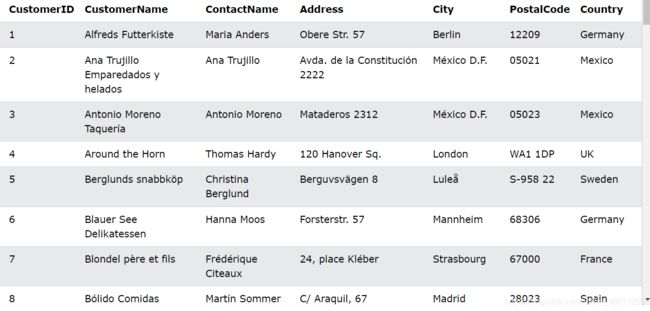
IN 运算符示例
选择位于’Germany’, ‘France’, 'UK’的所有客户:
SELECT * FROM Customers
WHERE Country IN ('Germany', 'France', 'UK');
选择不在选择位于’Germany’, ‘France’, 'UK’的所有客户:
SELECT * FROM Customers
WHERE Country NOT IN ('Germany', 'France', 'UK');
选择与 Suppliers来自相同国家的所有客户:
SELECT * FROM Customers
WHERE Country IN (SELECT Country FROM Suppliers);
返回如下
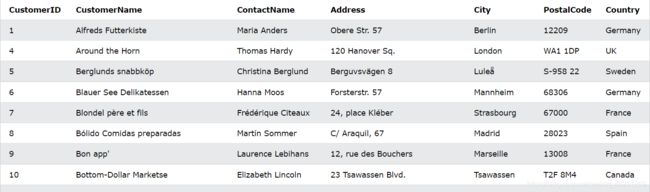
BETWEEN 之间运算符
在BETWEEN操作者选择一个给定的范围内的值。值可以是数字、文本或日期。
BETWEEN 语法
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
我们有用到如下的product表:
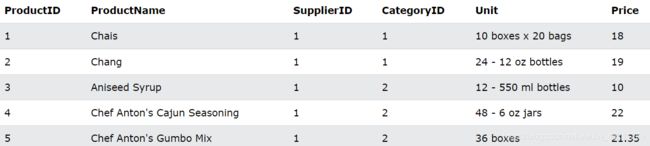
between示例
选择价格在 10 到 20 之间的所有产品:
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20;
要显示上一个示例范围之外的产品,请使用 NOT BETWEEN:
SELECT * FROM Products
WHERE Price NOT BETWEEN 10 AND 20;
数字之间
选择价格在 10 到 20 之间的所有产品。此外;不要显示 CategoryID 为 1,2 或 3 的产品:
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20
AND CategoryID NOT IN (1,2,3);
文本值之间
语句选择 Carnarvon Tigers 和 Mozzarella di Giovanni 之间具有 ProductName 的所有产品
SELECT * FROM Products
WHERE ProductName BETWEEN 'Carnarvon Tigers' AND 'Mozzarella di Giovanni'
ORDER BY ProductName;
选择产品名称介于 Carnarvon Tigers 和 Chef Anton’s Cajun Seasoning 之间的所有产品:
SELECT * FROM Products
WHERE ProductName BETWEEN "Carnarvon Tigers" AND "Chef Anton's Cajun Seasoning"
ORDER BY ProductName;
NOT BETWEEN 文本值
选择 ProductName 不在 Carnarvon Tigers 和 Mozzarella di Giovanni 之间的所有产品:
SELECT * FROM Products
WHERE ProductName NOT BETWEEN 'Carnarvon Tigers' AND 'Mozzarella di Giovanni'
ORDER BY ProductName;
我们现在假设有如下"Orders" 表:
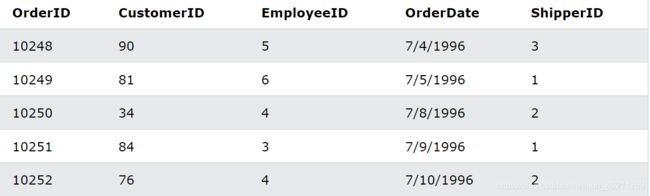
日期之间示例
选择 OrderDate 介于 ‘01-July-1996’ 和 ‘31-July-1996’ 之间的所有订单
SELECT * FROM Orders
WHERE OrderDate BETWEEN #07/01/1996# AND #07/31/1996#;
或者使用:
SELECT * FROM Orders
WHERE OrderDate BETWEEN '1996-07-01' AND '1996-07-31';
AS 别名使用
别名列语法
SELECT column_name AS alias_name
FROM table_name;
别名表语法
SELECT column_name(s)
FROM table_name AS alias_name;
现在我们还是假设有custorm表如下:
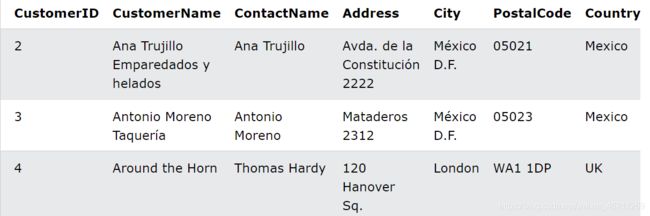
还有一个oeder表
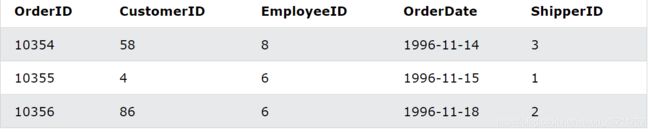
列的别名示例
创建两个别名,一个用于 CustomerID 列,另一个用于 CustomerName 列:
SELECT CustomerID AS ID, CustomerName AS Customer
FROM Customers;
创建两个别名,一个用于 CustomerName 列,另一个用于 ContactName 列。注意:如果别名包含空格,则需要双引号或方括号:
SELECT CustomerName AS Customer, ContactName AS [Contact Person]
FROM Customers;
创建一个名为“Address”的别名,该别名组合了四列(Address、PostalCode、 City 和Country):
SELECT CustomerName, Address + ', ' + PostalCode + ' ' + City + ', ' + Country AS Address
FROM Customers;
注意:要使上面的 SQL 语句在 MySQL 中工作,请使用以下命令:
SELECT CustomerName, CONCAT(Address,', ',PostalCode,', ',City,', ',Country) AS Address
FROM Customers;
表别名示例
选择来自 CustomerID=4(Around the Horn)的客户的所有订单。我们使用“Customers”和“Orders”表,分别给它们表别名“c”和“o”(这里我们使用别名来缩短SQL)
SELECT o.OrderID, o.OrderDate, c.CustomerName
FROM Customers AS c, Orders AS o
WHERE c.CustomerName='Around the Horn' AND c.CustomerID=o.CustomerID;
以下 SQL 语句与上面相同,但没有别名:
SELECT Orders.OrderID, Orders.OrderDate, Customers.CustomerName
FROM Customers, Orders
WHERE Customers.CustomerName='Around the Horn' AND Customers.CustomerID=Orders.CustomerID;
别名在以下情况下很有用:
1.一个查询涉及多个表
2.一个查询涉及多个表
3.查询中使用的函数
4.列名很大或不太可读
5.两列或更多列组合在一起
JOIN连接
JOIN子句用于行从两个或更多表根据它们之间的相关列结合。
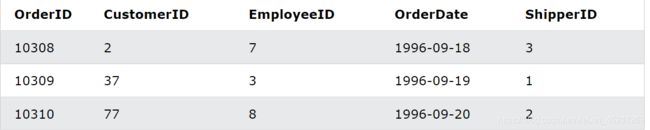
假设我们现在有"Orders" 表如下

同时还有表 “Customers” 如下:

请注意,“Orders”表中的“CustomerID”列指的是“Customers”表中的“CustomerID”。上面两个表之间的关系是“CustomerID”列。
示例
使用INNER JOIN选择在两个表中具有匹配值的记录:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
返回如下
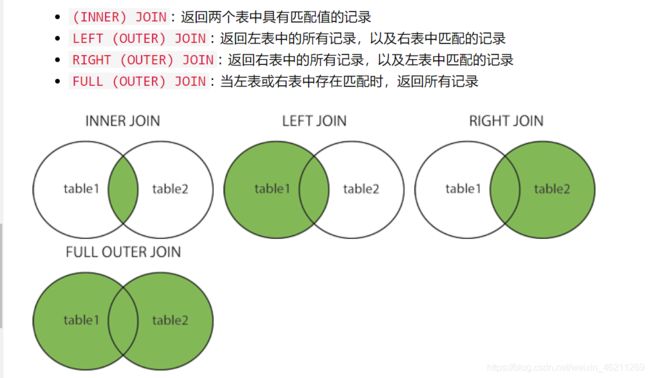
不同类型的 SQL JOIN
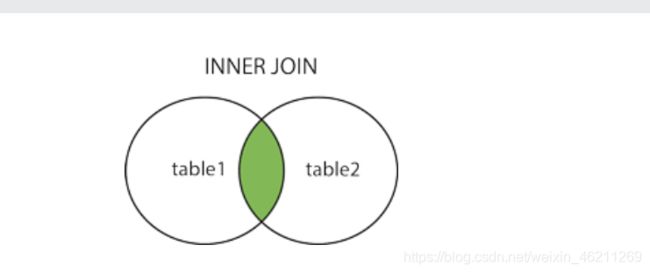
INNER JOIN内连接关键字
INNER JOIN关键字选择在两个表中具有匹配值的记录。
语法:
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
画个图理解:
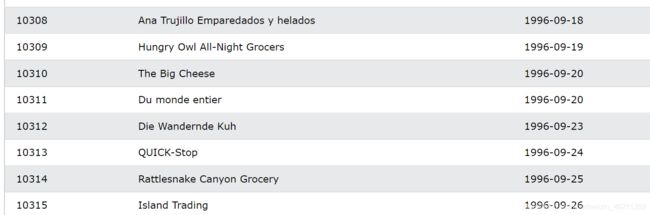
假设我们还是有order表
customer表
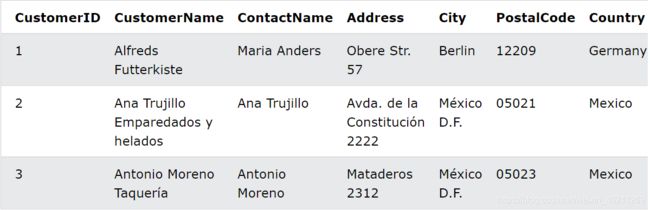
INNER JOIN 示例
选择所有包含客户信息的订单:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
返回
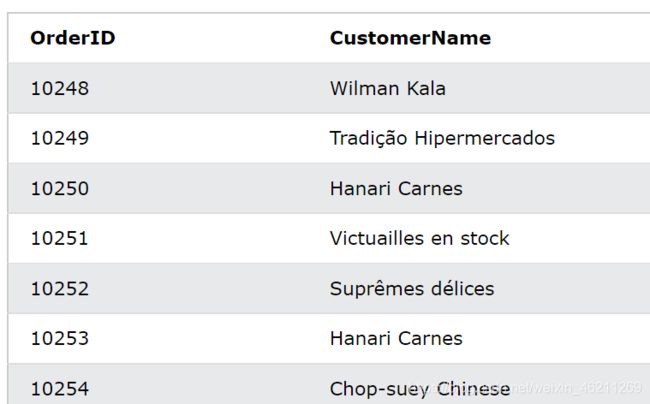
JOIN 三张表
选择包含客户和发货人信息的所有订单
SELECT Orders.OrderID, Customers.CustomerName, Shippers.ShipperName
FROM ((Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID)
INNER JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID);
返回如下
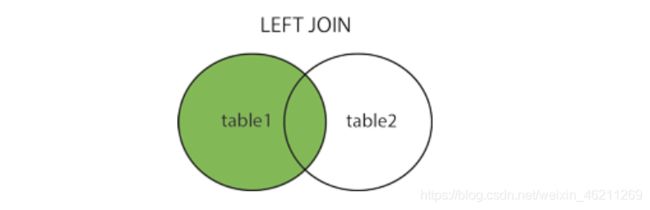
LEFT JOIN 左连接 关键字
LEFT JOIN关键字返回左表 (table1) 中的所有记录,以及右表 (table2) 中的匹配记录。如果没有匹配项,则结果是右侧的 0 条记录。
左连接语法
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
来个图就懂了
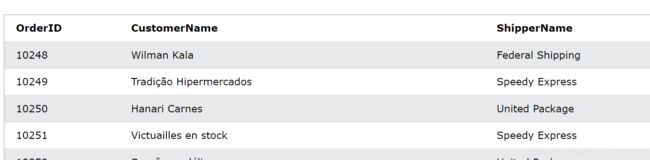
我们还是用customer表:
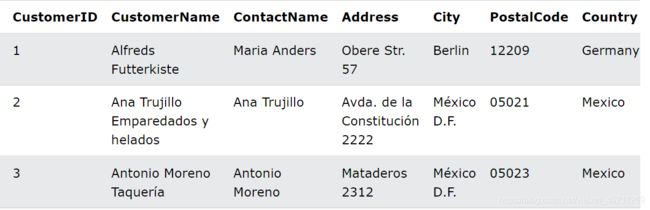
order表
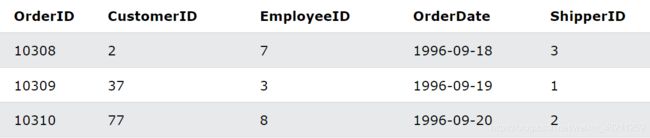
LEFT JOIN 示例
选择所有客户,以及他们可能拥有的任何订单:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;
返回如下

RIGHT JOIN右连接 关键字
语法
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
上图就懂了
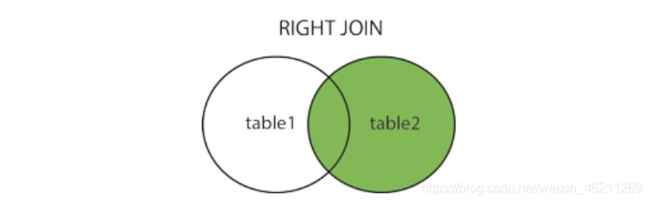
现在我们用到order表如下

还有个employee表

返回所有员工,以及他们可能下过的任何订单:
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;
FULL OUTER JOIN 关键字
FULL OUTER JOIN和 FULL JOIN是一样的。
语法为:
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name
WHERE condition;
来个图就懂了
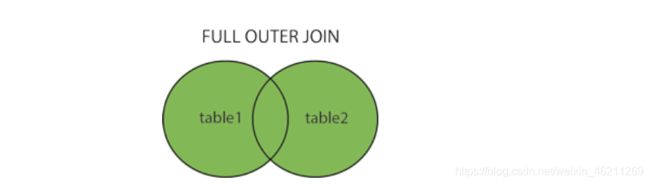
我们假设还是以customer表
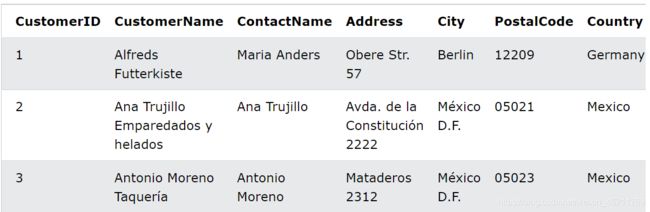
还有个order表

选择所有客户和所有订单:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName;
返回如下
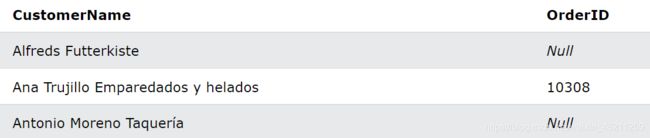
Self Join自连接 关键字
语法
SELECT column_name(s)
FROM table1 T1, table1 T2
WHERE condition;
我们假设有custormer表

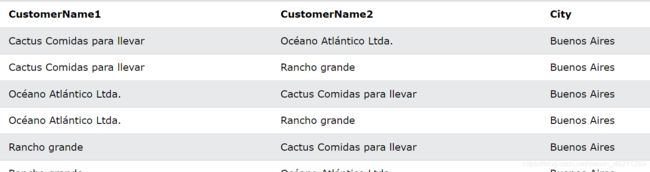
匹配来自同一城市的客户:
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2, A.City
FROM Customers A, Customers B
WHERE A.CustomerID <> B.CustomerID
AND A.City = B.City
ORDER BY A.City;
返回如下
GROUP BY语句
该GROUP BY语句将具有相同值的行分组为汇总行,例如“查找每个国家/地区的客户数量”。
该GROUP BY语句通常与聚合函数 ( COUNT(), MAX(), MIN(), SUM(), AVG()) 一起使用, 以按一列或多列对结果集进行分组。
语法:
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
假设我们还是有customer这个表
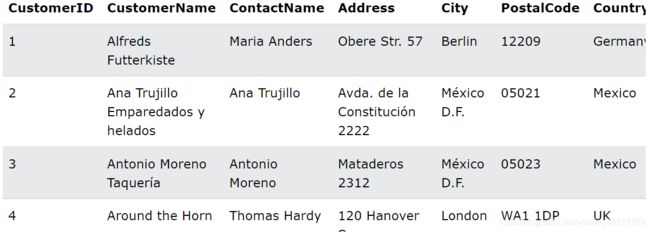
列出了每个国家/地区的客户数量:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
列出了每个国家的客户数量,从高到低排序:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;
HAVING 子句
语法:
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
假设还是有custorm表如下
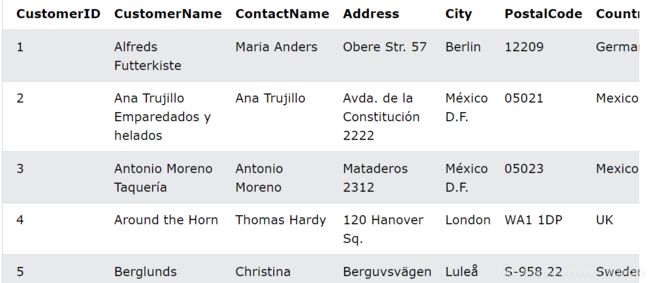
列出了每个国家/地区的客户数量。仅包括拥有超过 5 个客户的国家/地区:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5;
列出了每个国家的客户数量,从高到低排序(仅包括客户超过 5 个的国家):
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5
ORDER BY COUNT(CustomerID) DESC;
EXISTS 运算符
EXISTS运算符用于测试子查询中是否存在任何记录。
EXISTS运算符返回true,如果子查询返回一个或多个记录。
语法
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);
假设我们还是用到product表
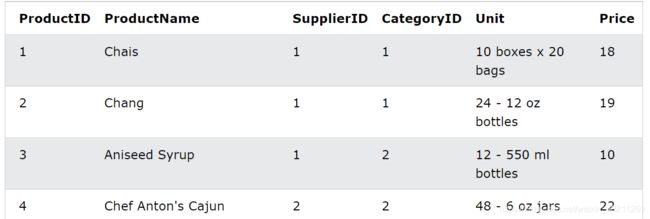
suppiler表

例如:
返回 TRUE 并列出产品价格小于 20 的供应商:
SELECT SupplierName
FROM Suppliers
WHERE EXISTS (SELECT ProductName FROM Products WHERE Products.SupplierID = Suppliers.supplierID AND Price < 20);
返回如下
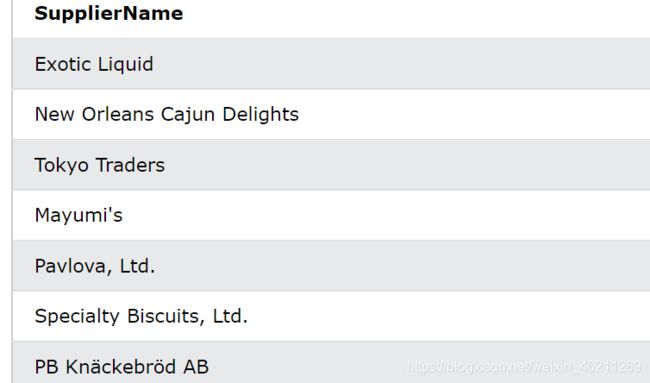
返回 TRUE 并列出产品价格等于 22 的供应商:
SELECT SupplierName
FROM Suppliers
WHERE EXISTS (SELECT ProductName FROM Products WHERE Products.SupplierID = Suppliers.supplierID AND Price = 22);
返回为:

注释
单行注释以–.
– 和行尾之间的任何文本都将被忽略(不会被执行)
例如:
--Select all:
SELECT * FROM Customers;
又例如
SELECT * FROM Customers -- WHERE City='Berlin';
多行注释/*以 /.
/ 和 */ 之间的任何文本都将被忽略。
例如:
/*Select all the columns
of all the records
in the Customers table:*/
SELECT * FROM Customers;
又例如
/*SELECT * FROM Customers;
SELECT * FROM Products;
SELECT * FROM Orders;
SELECT * FROM Categories;*/
SELECT * FROM Suppliers;
忽略语句的一部分:
例如
SELECT CustomerName, /*City,*/ Country FROM Customers;
又例如
SELECT * FROM Customers WHERE (CustomerName LIKE 'L%'
OR CustomerName LIKE 'R%' /*OR CustomerName LIKE 'S%'
OR CustomerName LIKE 'T%'*/ OR CustomerName LIKE 'W%')
AND Country='USA'
ORDER BY CustomerName;
运算符
其实这一节内容,我已经在前面的运算符都演示过了。再说一下呗。
算术运算符有
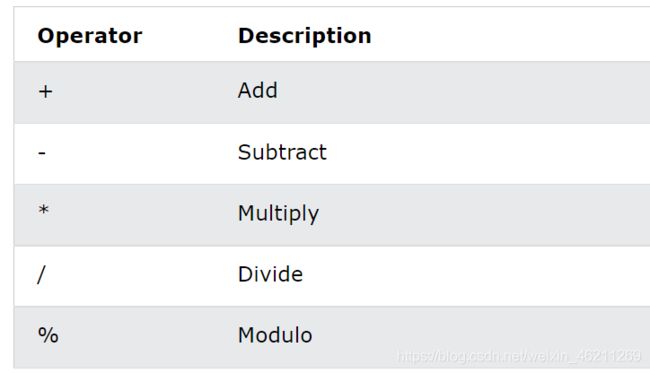
演示一部分
比如求20+30:
SELECT 30 + 20;
除法(返回3)
SELECT 30 / 10;
取余数(返回2)
SELECT 17 % 5;
比较运算符
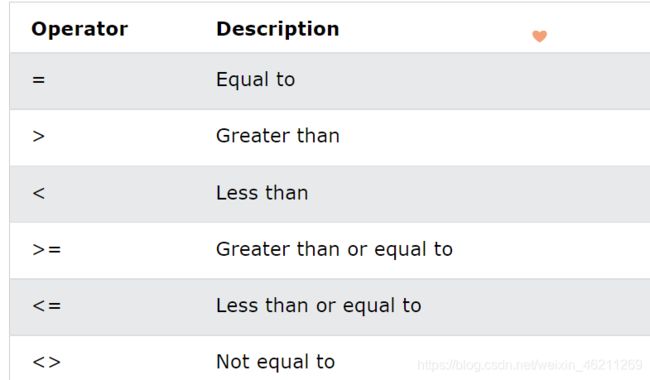
演示一部分
大于
SELECT * FROM Products
WHERE Price = 18;
不等于
SELECT * FROM Products
WHERE Price <> 18;
大于等于
SELECT * FROM Products
WHERE Price >= 30;