[当人工智能遇上安全] 7.基于机器学习的安全数据集总结
您或许知道,作者后续分享网络安全的文章会越来越少。但如果您想学习人工智能和安全结合的应用,您就有福利了,作者将重新打造一个《当人工智能遇上安全》系列博客,详细介绍人工智能与安全相关的论文、实践,并分享各种案例,涉及恶意代码检测、恶意请求识别、入侵检测、对抗样本等等。只想更好地帮助初学者,更加成体系的分享新知识。该系列文章会更加聚焦,更加学术,更加深入,也是作者的慢慢成长史。换专业确实挺难的,系统安全也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
前一篇文章普及了基于机器学习的入侵检测和攻击识别。为了更好的帮助大家从事安全领域机器学习和深度学习(AI+安全)相关的研究,这篇文章将分享安全相关的数据集供大家下载和实验,包括恶意URL、流量分析、域名检测、恶意软件、图像分类、垃圾邮件等,也欢迎大家留言推荐数据集供我补充。基础性文章,希望对您有所帮助~
文章目录
- KDD CUP 99
- HTTP DATASET CSIC 2010
- honeypot.json
- Masquerading User Data
- ADFA IDS Datasets
- 域名相关
- Webshell
- 登录日志
- 恶意URL
- 综合安全数据
- The Malware Capture Facility Project
- 恶意软件数据库
- APT攻击数据集
- 图像分类数据集-1000
- MNIST-手写数字
- 垃圾邮件数据集
- 自然灾害数据集
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习AI安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
前文推荐:
- [当人工智能遇上安全] 1.人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [当人工智能遇上安全] 2.清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [当人工智能遇上安全] 3.安全领域中的机器学习及机器学习恶意请求识别案例分享
- [当人工智能遇上安全] 4.基于机器学习的恶意代码检测技术详解
- [当人工智能遇上安全] 5.基于机器学习算法的主机恶意代码识别研究
- [当人工智能遇上安全] 6.基于机器学习的入侵检测和攻击识别——以KDD CUP99数据集为例
- [当人工智能遇上安全] 7.基于机器学习的安全数据集总结
作者的github资源:
- https://github.com/eastmountyxz/AI-Security-Paper
KDD CUP 99
KDD CUP 99 dataset 是KDD竞赛在1999年举行时采用的数据集。1998年美国国防部高级规划署(DARPA)在MIT林肯实验室进行了一项入侵检测评估项目收集而来的数据,其竞争任务是建立一个网络入侵检测器,这是一种能够区分称为入侵或攻击的“不良”连接和“良好”的正常连接的预测模型。该数据集包含一组要审核的标准数据,其中包括在军事网络环境中模拟的多种入侵。
- 内容类型:网络流量,主机行为
- 是否特征化: 是
- 适用范围:主机入侵检测,异常流量监控
- 下载地址:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
- 数据示例:
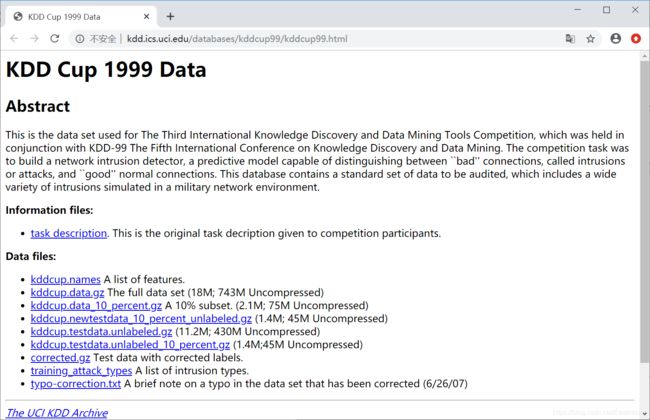
数据文件包括:
kddcup.names 功能列表。
kddcup.data.gz 完整数据集(18M; 743M未压缩)
kddcup.data_10_percent.gz 10%的数据集(2.1M; 75M未压缩)
kddcup.newtestdata_10_percent_unlabeled.gz(1.4M; 45M未压缩)
kddcup.testdata.unlabeled.gz (11.2M; 430M未压缩)
kddcup.testdata.unlabeled_10_percent.gz (1.4M; 45M未压缩)
corrected.gz 正确标签的测试数据
training_attack_types 入侵类型列表
typo-correction.txt 关于数据集中的简要说明
推荐文章:基于机器学习的入侵检测和攻击识别——以KDD CUP99数据集为例
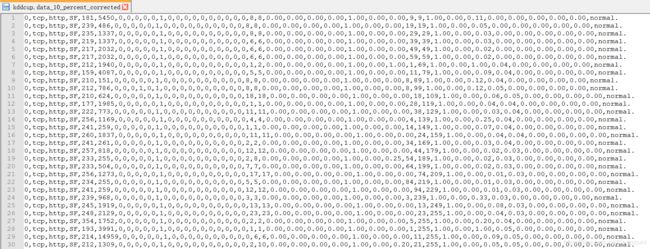
HTTP DATASET CSIC 2010
HTTP DATASET CSIC 2010 包含已经标注过的针对Web服务的请求。该数据集由西班牙最高科研理事会 CSIC 在论文 Application of the Generic Feature Selection Measure in Detection of Web Attacks 中作为附件给出的,是一个电子商务网站的访问日志,包含 36000 个正常请求和 25000 多个攻击请求。异常请求样本中包含 SQL 注入、文件遍历、CRLF 注入、XSS、SSI 等攻击样本。其中,下载地址已经为我们分类好了训练用的正常数据,测试用的正常数据,测试用的异常数据。
- 内容类型:网络流量
- 是否特征化:否
- 使用范围:WAF类产品,异常流量监控
- 下载地址:
http://www.isi.csic.es/dataset/
https://github.com/zambery/Machine-Learning-on-CSIC-2010 - 数据示例:
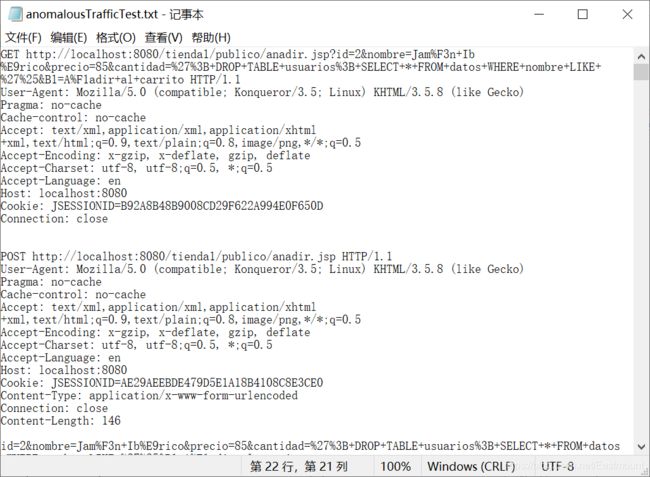
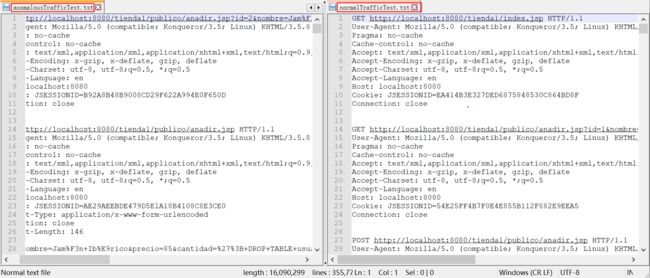
推荐文章:
- 机器学习实战之CSIC2010网络攻击数据 - Ackerzy
- 崔艳鹏,刘咪,胡建伟. 基于CNN的恶意Web请求检测技术[J]. 计算机科学, 2020,47(2): 281-286.
honeypot.json
honeypot 是由多种类型的蜜罐采集回来的数据,主要是WEB请求,约99万条数据。由于没有分类和规整,需要自己数据清洗,也可以用作校验模型的数据。
- 内容类型:网络流量
- 是否特征化:否
- 使用范围: WAF类产品,异常流量监控
- 下载地址:http://www.secrepo.com/honeypot/honeypot.json.zip
- 数据示例:

Masquerading User Data
Masquerading User Data 是Matthias Schonlau 教授通过正常数据构造出来用于训练和检测 Masquerading User攻击的数据集。内部攻击者分为两种,一种是内鬼[Traitor],一种是窃取了身份凭证的正常用户的伪装者[Masquerading User]。由于是构造出来的数据,缺乏实际攻击的真实性,在一定程度上,训练出来的模型会存在一定的过拟。
- 内容类型:主机行为
- 是否特征化:否
- 使用范围:入侵检测类 用户异常行为识别
- 下载地址:http://www.schonlau.net/intrusion.html
- 数据示例:

ADFA IDS Datasets
ADFA IDS Datasets 是澳大利亚国防大学发布的一套关于HIDS的数据集。分为linux(ADFA-LD)和window(ADFA-WD)。
- 内容类型: 主机行为
- 是否特征化:是
- 使用范围: 入侵检测
- 下载地址:https://www.unsw.adfa.edu.au/unsw-canberra-cyber/cybersecurity/ADFA-IDS-Datasets/
– The ADFA Linux Dataset (ADFA-LD)
– The ADFA Windows Dataset (ADFA-WD)
– Stealth Attacks Addendum (ADFA-WD:SAA) - 数据示例:

域名相关
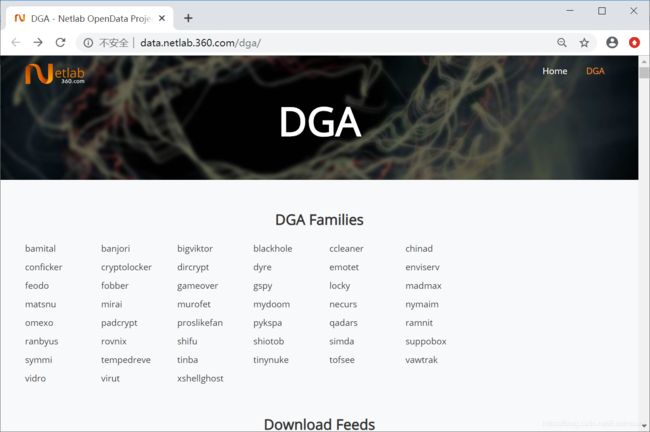
DGA 正常域名和可疑域名检测,主要用于DGA的检测。这里直接用Alexa Top 100W 作为正常域名,用其他的开放的DGA数据作为黑样本。
- 内容类型:文本样本
- 是否特征化:否
- 使用范围:入侵检测 异常流量 WAF
- 下载地址
Alexa Top 100W:http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
360DGA:http://data.netlab.360.com/dga/
zeusDGA:http://www.secrepo.com/misc/zeus_dga_domains.txt.zip - 数据示例:
Webshell
Webshell数据集 是github有一个比较多样本的收集,涵盖了很多的语言。
- 内容类型:文本样本
- 是否特征化:否
- 使用范围:入侵检测 异常流量 WAF
- 下载地址:
– https://github.com/tennc/webshell
– https://github.com/ysrc/webshell-sample - 数据示例:


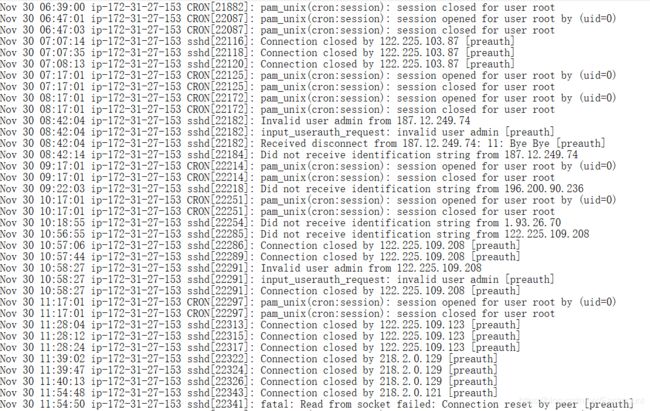
登录日志
auth.log 主要是都是登录失败的日志 适合用作判断是爆破登录还是正常的输错密码
- 内容类型:主机行为
- 是否特征化:否
- 使用范围:入侵检测 异常流量 WAF
- 下载地址:http://www.secrepo.com/auth.log/auth.log.gz
- 数据示例:
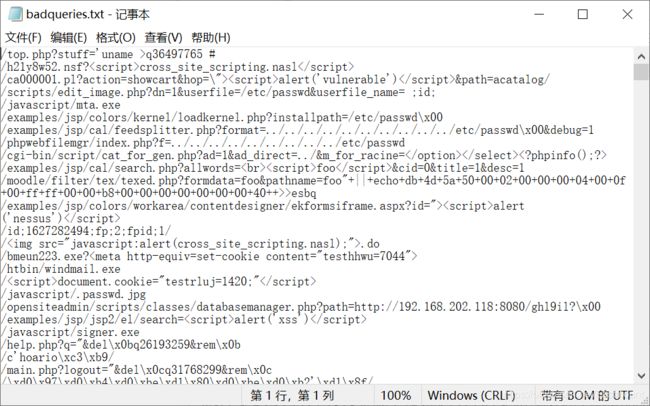
恶意URL
- malicious-URLs 在Github上面一个 使用机器学习去检测恶意URL的项目 ,里面有一个训练集,有做标记是正常的URL还是恶意的URL
- 内容类型: 文本样本
- 是否特征化:否
- 使用范围: 入侵检测 异常流量 WAF
- 下载地址&检测方法:
https://github.com/faizann24/Using-machine-learning-to-detect-malicious-URLs
https://github.com/exp-db/AI-Driven-WAF
https://github.com/Echo-Ws/UrlDetect - 数据示例:
推荐作者文章:基于机器学习的恶意请求识别及安全领域中的机器学习
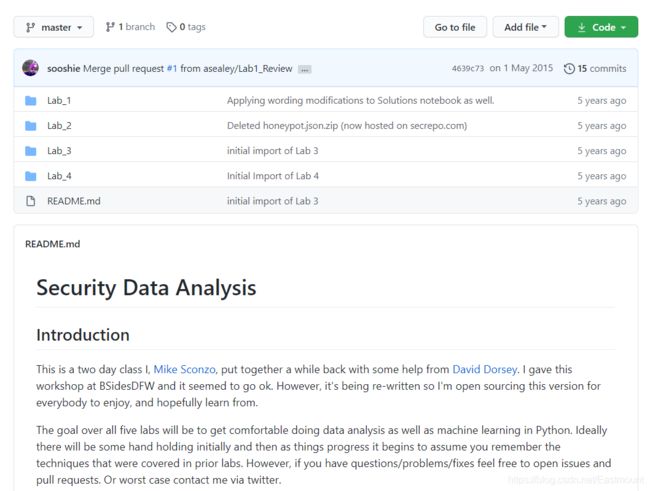
综合安全数据
在github上有一个叫 Security-Data-Analysis 的项目,里面有4个实验室,每个实验室的数据都不一样,包含http、连接记录、域名、host等等。
- 内容类型:网络流量
- 是否特征化:否
- 使用范围:异常流量
- 下载地址:https://github.com/sooshie/Security-Data-Analysis
- 数据示例:
The Malware Capture Facility Project
MCFP 是捷克理工大学用于捕抓恶意软件的而抓去的网络流量,里面的数据非常多,有他们自己分析出来的恶意流量,也有所有的流量,包括网络文件、日志、DNS请求等。
- 内容类型:网络流量
- 是否特征化:否
- 使用范围: 异常流量 WAF
- 下载地址:https://mcfp.weebly.com/mcfp-dataset.html
- 数据示例:
恶意软件数据库
MalwareDB 包含了恶意软件列表 hash检测结果,所属域名等数据。
- 内容类型:文本样本
- 使用范围:特征库 入侵检测
- 下载地址:
http://malwaredb.malekal.com/
https://bbs.kafan.cn/thread-2156285-1-1.html - 数据示例:

APT攻击数据集
非常棒的两个数据集,APT样本HASH值和APT报告。
- https://github.com/RedDrip7/APT_Digital_Weapon
- https://github.com/kbandla/APTnotes
下载推荐:
- https://virusshare.com/
- https://virusshare.com/
- https://app.any.run/
![[当人工智能遇上安全] 7.基于机器学习的安全数据集总结_第1张图片](http://img.e-com-net.com/image/info8/bddc284e20024527b2daeb07f7f42ee0.jpg)
图像分类数据集-1000
Sort_1000pics数据集 包含了1000张图片,总共分为10大类,分别是人(第0类)、沙滩(第1类)、建筑(第2类)、大卡车(第3类)、恐龙(第4类)、大象(第5类)、花朵(第6类)、马(第7类)、山峰(第8类)和食品(第9类),每类100张。
- 内容类型:图像样本
- 使用范围:图像分类、恶意家族分类
- 推荐理由:个人感觉这是图像分类实验的基础,恶意样本转换灰度图进行恶意家族分类实验也都可以基于此实验拓展
- 下载地址:https://github.com/eastmountyxz/ImageProcessing-Python
- 数据示例:
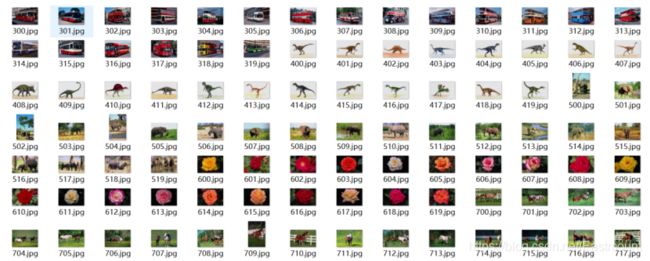
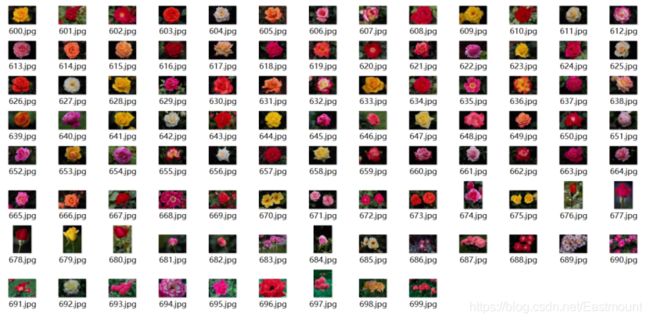
通常会将所有各类图像按照对应的类标划分至“0”至“9”命名的文件夹中,如图所示,每个文件夹中均包含了100张图像,对应同一类别。

比如,文件夹名称为“6”中包含了100张花的图像,如下图所示。
推荐作者文章:图像分类原理及基于KNN、朴素贝叶斯算法的图像分类案例
MNIST-手写数字
MNIST数据集 是手写体识别数据集,也是入门级的计算机视觉数据集。MNIST图片数据集包含了大量的数字手写体图片,如下图所示,我们可以尝试用它进行分类实验。该数据集共包含三部分:
- 训练数据集:55,000个样本,mnist.train
- 测试数据集:10,000个样本,mnist.test
- 验证数据集:5,000个样本,mnist.validation

MNIST数据集中的一个样本数据包含两部分内容:手写体图片和对应的label。这里我们用xs和ys分别代表图片和对应的label,训练数据集和测试数据集都有xs和ys,使用mnist.train.images和mnist.train.labels表示训练数据集中图片数据和对应的label数据。如下图所示,它表示由28x28的像素点矩阵组成的一张图片,这里的数字784(28x28)如果放在我们的神经网络中,它就是x输入的大小,其对应的矩阵如下图所示,类标label为1。

- 内容类型:图像样本
- 使用范围:图像分类、恶意家族分类
- 推荐理由:个人感觉这是图像分类实验的基础,恶意样本转换灰度图进行恶意家族分类实验也都可以基于此实验拓展
- 下载地址:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(‘MNIST_data’, one_hot=True) - 推荐作者文章:
TensorFlow实现分类学习及MNIST手写体识别案例
Keras搭建分类神经网络及MNIST数字图像案例分析
垃圾邮件数据集
SpamBase数据集 入门级垃圾邮件分类训练集,其包含57个属性和4601个实例,该数据集主要用于垃圾邮件的识别分类,其中垃圾邮件的资源均来自于邮件管理员和提交垃圾邮件的个人,其可被用于构建垃圾邮件过滤器。该数据集由惠普实验室于1999年7月发布,主要发布人有Mark Hopkins、Erik Reeber、George Forman和Jaap Suermondt。另一个垃圾邮件数据集是 Enron。
- 内容类型:垃圾邮件
- 使用范围:邮件分类、垃圾邮件识别分类
- 下载地址:https://hyper.ai/datasets/4949
- 数据示例:

自然灾害数据集
xBD数据集 是迄今为止第一个建筑破坏评估数据集,是带注释的高分辨率卫星图像的规模最大、质量最高的公共数据集之一。该数据集包含22068张图像,均是1024x1024的高分辨率卫星遥感图像,标记有19种不同的事件,包括地震、洪水、野火、火山爆发和车祸等。这些图像包括了灾前、灾后图像,图像可用于构建定位和损伤评估这两项任务。
- 发布机构:麻省理工学院
- 内容类型:图像样本
- 数据大小:31.2GB
- 使用范围:图像分类、自然灾害识别
- 推荐理由:个人感觉该数据集对于对抗样本、AI和安全结合的案例有帮助
- 下载地址:https://hyper.ai/datasets/13272
- 相关论文:《Building Disaster Damage Assessment in Satellite Imagery with Multi-Temporal Fusion》(《具有多时相融合的卫星影像中的建筑物灾害破坏评估》)
总结
学习安全或深度学习数据集是第一步,可能很多同学会受到数据集的困扰,真心希望这些数据集对您有所帮助,也欢迎大家继续补充新的数据集。作者后续会整理这些年抓取的文本数据以开源,供大家进行文本挖掘或NLP研究。
同时感觉自己要学习的知识好多,也有好多大神卧虎藏龙,开源分享。作为初学者,我和他们有很大差距,但不论之前是什么方向,是什么工作,是什么学历,我都会朝着这个目标去努力!有差距不可怕,我们需要的是去缩小差距,去战斗,况且这个学习的历程真的很美,AI和安全真的有意思,共勉~
最后,给科研初学者安利一张SCI论文撰写的技巧图(源自中科院王老师),返校科研近十天,修改了两篇论文,写了一个本子,做了一次PPT汇报,正在做第四个和第五个工作的实验,加油!
![[当人工智能遇上安全] 7.基于机器学习的安全数据集总结_第2张图片](http://img.e-com-net.com/image/info8/60d53e51633640559feb598e038a1cd4.jpg)
小珞珞这嫌弃的小眼神,也拿到了最喜欢的玩具——扫把,哈哈。最近社交媒体账号都注销了,博客基本停更,手机很少看,朋友圈估计明年或半年后再见,专心科研,非诚勿扰,有事短信留言。拿出最好的状态,fighting~天行健,君子以自强不息。地势坤,君子以厚德载物。
![[当人工智能遇上安全] 7.基于机器学习的安全数据集总结_第3张图片](http://img.e-com-net.com/image/info8/65dd5bbf80ed4856abe223064c78f41b.jpg)
(By:Eastmount 2022-02-22 夜于武汉 https://blog.csdn.net/Eastmount )
参考资料:
[1] https://xz.aliyun.com/t/1879
[2] https://blog.csdn.net/u011311291/article/details/79045675
[3] https://hyper.ai/datasets/4949