NLP:self-attention + Transformer
# 前言
通常认为RNN有两个缺点:1、RNN隐藏层中记录的较早信息会随着时间步的推移而冲淡,所以就无法建立起和较早时间步信息的依赖关系。2、RNN不能并行化处理。因而催生出了attention解决上述问题。
Attention机制的本质来自于人类视觉注意力机制。人们视觉在感知东西的时候一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当人们发现一个场景经常在某部分出现自己想观察的东西时,人们会进行学习在将来再出现类似场景时把注意力放到该部分上。
# 背景
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是2014年google mind团队的这篇论文《Recurrent Models of Visual Attention》,他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。自注意力机制也成为了大家近期的研究热点,并在各种NLP任务上进行探索。
# self-attention 原理
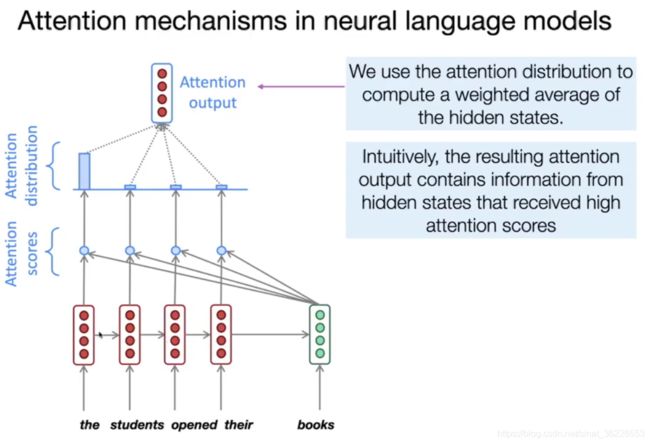
以序列标注为例,我们输入一个序列a,得到输出序列b。![]() 的输出不只是依靠
的输出不只是依靠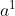 的信息,而是基于整个输入序列
的信息,而是基于整个输入序列![]() 的信息。
的信息。
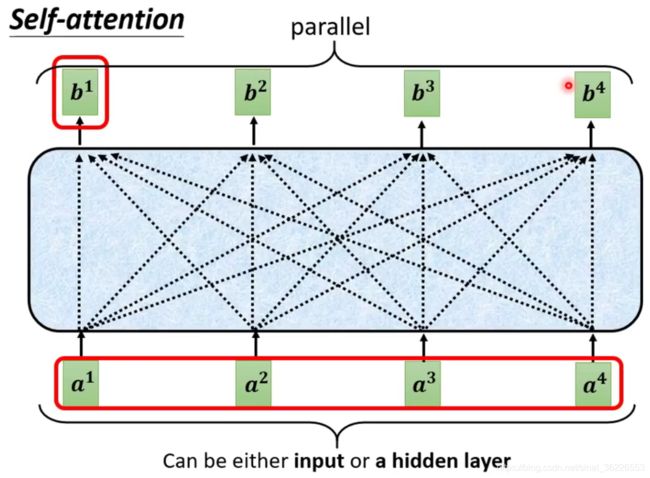
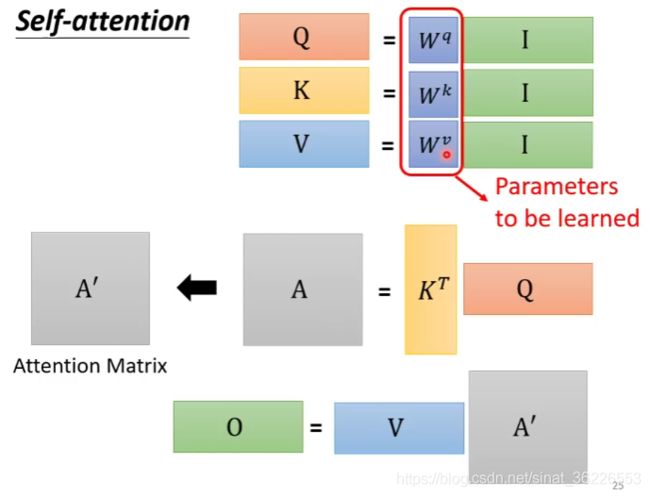
这里我们需要了解key vector、query vector 和 value vector。(目前在NLP研究中,key和value常常都是同一个,即key=value)key vector 和 query vector 用于计算 attention score,value vector 用于计算加权平均注意力

以为例,通过与![]() 内积得到
内积得到![]() ,
,![]() 通过与
通过与![]() 内积得到
内积得到![]() ,
,![]() 分别与
分别与![]() 计算相关性得到attention score(算法有多种,如图所示)。
计算相关性得到attention score(算法有多种,如图所示)。![]() 经过一个非线性激活函数(如softmax、ReLU等)得到
经过一个非线性激活函数(如softmax、ReLU等)得到![]()
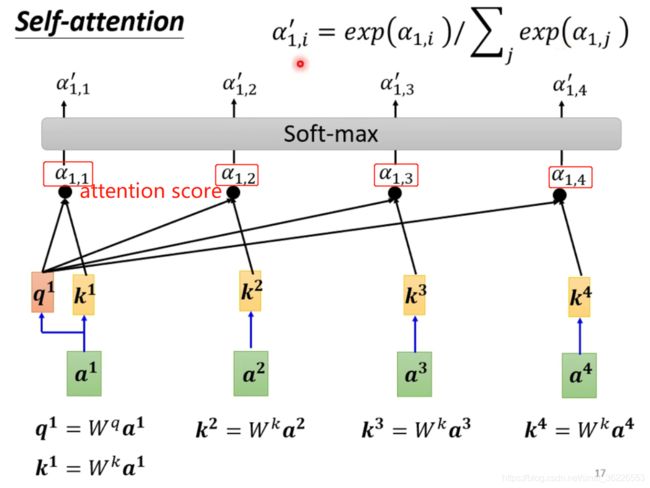

注:《Attention is all you need》中采用的Scaled dot product中的因子![]() 起到调节作用,使得内积不至于太大(注:太大的话softmax后就非0即1了♀️♀️
起到调节作用,使得内积不至于太大(注:太大的话softmax后就非0即1了♀️♀️
![]() 通过与
通过与![]() 内积得到
内积得到![]() ,
,![]() 与
与![]() 对应相乘后求和得到
对应相乘后求和得到![]() (PS:若、
(PS:若、 关联性很强,则
关联性很强,则![]() 值很大,那么
值很大,那么![]() 的值可能会比较接近
的值可能会比较接近![]() 。同理,与当前词不相关的词对
。同理,与当前词不相关的词对![]() 的贡献就很小),同理可以求得
的贡献就很小),同理可以求得![]() ( 可以看出
( 可以看出![]() 均涵盖了整个 sequence 中的信息,且它们之间互不依赖,可以并行计算得到
均涵盖了整个 sequence 中的信息,且它们之间互不依赖,可以并行计算得到

总结汇总公式,可以合成矩阵简化表达式:

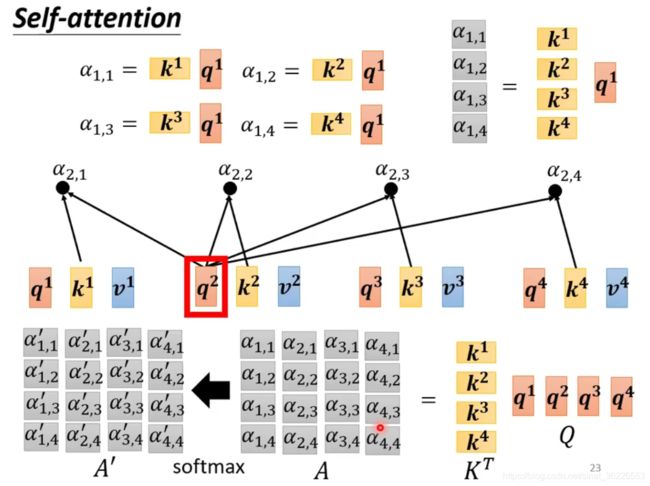
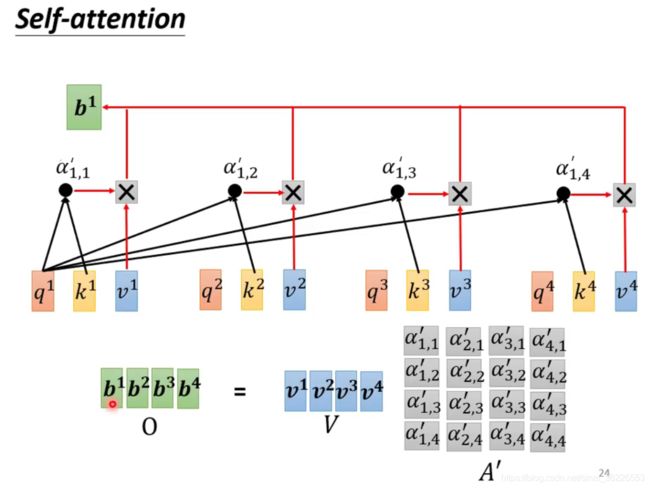
即:
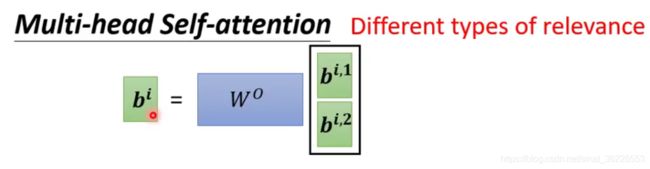
# Multi-head Self-attention 原理
多头即会生成多个key vector、query vector 和 value vector,这扩展了模型对不同位置的关注度,每个头关注点不同。
用 2 heads 的情况举例,这种情况下,![]() 会分裂成两个——
会分裂成两个—— ![]() 和
和 ![]()

用同样的步骤计算出 ![]() 和
和 ![]()
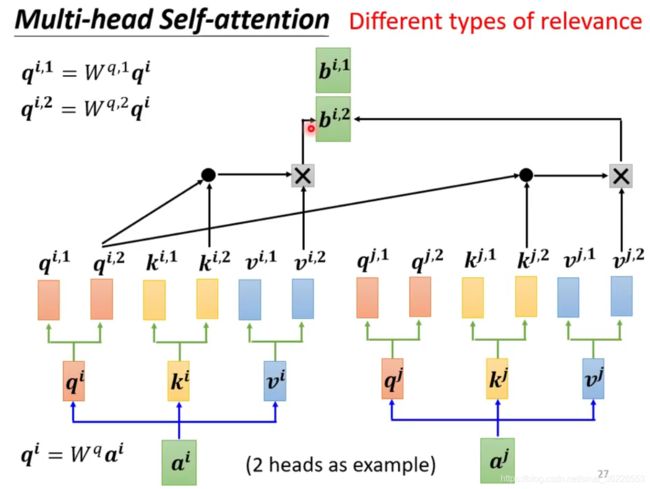
把它们两个 concat 后乘以一个矩阵![]() ,得到
,得到 ![]()
# 动画展示
这就是一层 Multi-head self-attention + feed forward 的构造,当应用时可能会使用多层架构。

# attention? self-attention?
若有一个输入序列 X=(x1,x2,…,xt),Attention获取全局信息的解决方案:
![]()
其中A,B是另外一个序列(矩阵)。如果都取A=B=X,那么就称为Self Attention。所谓Self Attention,其实就是Attention(X,X,X)。也就是说,在序列内部做Attention,寻找序列内部的联系。
在Google的论文《Attention is all you need》中,大部分的Attention都是Self Attention。
举个例子来说:假如我们正在做机器翻译,将“I am a student”翻译成中文“我是一个学生”。根据encoder-decoder模型,在输出“学生”时,我们用到了“我”、“是”、“一个”以及encoder的输出。但事实上,我们或许并不需要“I am a ”这些无关紧要的信息,而仅仅只需要“student”这个词的信息就可以输出“学生”(或者说“I am a”这些信息没有“student”重要)。这个时候就需要用到attention机制来分别为“I”、“am”、“a”、“student”赋一个权值了,这时student的重要性就可依据权重体现出来。
self-attention显然是attentio机制的一种。上面所讲的attention是输入对输出的权重,例如在上文中,是“I am a student”对“学生”的权重。self-attention则是自己对自己的权重,例如I am a student分别对am的权重、对student的权重。之所以这样做,是为了充分考虑句子之间不同词语之间的语义及语法联系。
# 位置编码
self-attention 没有用到 sequence 的位置信息。即使句子中的词序打乱,那么Attention的结果还是一样的。

Google采用Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
在输入![]() 经过 transformation 得到
经过 transformation 得到 ![]() 后,还要加上一个
后,还要加上一个 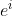 , 是人工设置的,这个 代表了位置信息(业界多用sinθ、cosθ等函数交错生成
, 是人工设置的,这个 代表了位置信息(业界多用sinθ、cosθ等函数交错生成
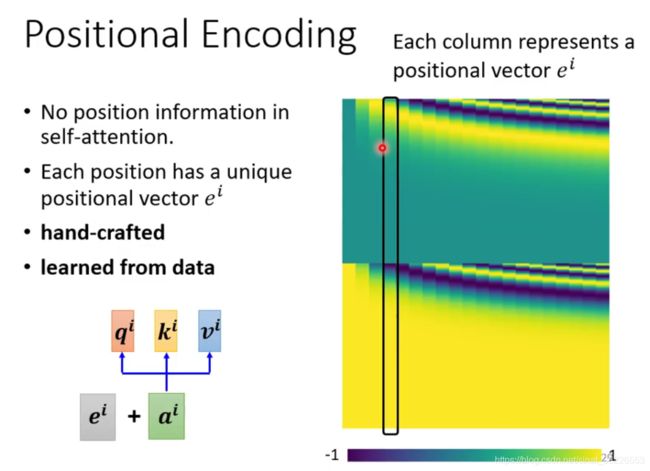
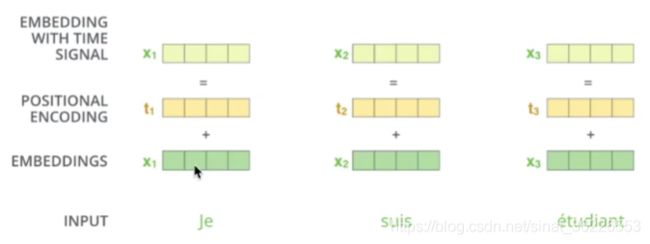

其中,PE为二维矩阵,维度和序列的Embedding一致,这样才能将两者对应相加,矩阵的行表示不同词语,列表示词向量或者位置向量,pos表示词语在句子中的位置(假设句子长度为L,则pos取值为0~L-1), 表示词向量的维度,i表示词向量的某一维度,例如为512,则i的取值为0~255(因为上面公式中使用2i和2i+1分别计算奇数和偶数位置的值,在偶数词向量位置加的是sin公式求出的位置向量,在奇数词向量位置加的是cos公式求出的位置向量),所以维度为512了。
表示词向量的维度,i表示词向量的某一维度,例如为512,则i的取值为0~255(因为上面公式中使用2i和2i+1分别计算奇数和偶数位置的值,在偶数词向量位置加的是sin公式求出的位置向量,在奇数词向量位置加的是cos公式求出的位置向量),所以维度为512了。
为什么要选择这样的公式作为位置编码计算使用呢?
因为三角函数满足以下公式:
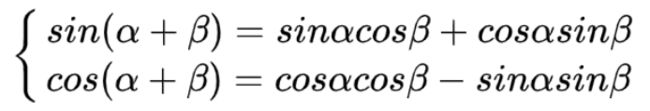
结合我们的具体公式,可以得到:

这意味着,在计算PE(pos+k, 2i),可以使用PE(pos,2i)和PE(pos,2i+1)线性表示,当在计算某个 k 和 i 给定时(就是确定了要计算某个位置的词pos+k的位置向量的某个维度上的数字i),也就是此时k,i都是确定的数。则PE(pos+k, 2i),则上面公式的右边的PE(pos,2i)和PE(pos,2i+1)的线性组合可以表示PE(pos+k,2i)和PE(pos+k,2i+1)。
# Transformer
Transformer模型在《Attention is all you need》论文中提出。这篇论文主要亮点在于:
1)不同于以往主流机器翻译使用基于RNN的seq2seq模型框架,该论文用attention机制代替了RNN搭建了整个模型框架。
2)提出了多头注意力(Multi-head attention)机制方法,在编码器和解码器中大量的使用了多头自注意力机制(Multi-head self-attention)。
3)在WMT2014语料中的英德和英法任务上取得了先进结果,并且训练速度比主流模型更快。
Google论文的主要贡献之一是它表明了self-attention在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的 [来源]
把Transformer想象成一个黑匣子,在机器翻译的领域中,这个黑匣子的功能就是输入一种语言然后将它翻译成其他语言。如下图:

掀起The Transformer的盖头,我们看到在这个黑匣子由2个部分组成,一个Encoders和一个Decoders。
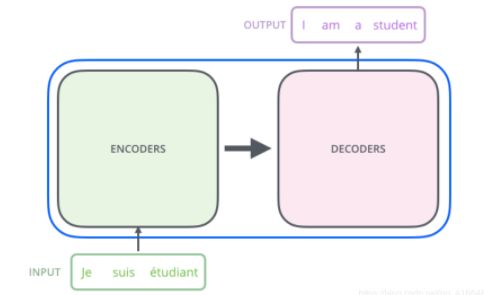
该论文模型的整体结构如下图,还是由编码器和解码器组成:
1️⃣:在编码器的一个网络块(Block)中,由一个Multi-Head Attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。
2️⃣:类似于编码器,只是解码器的一个网络块中多了一个Multi-Head Attention层。
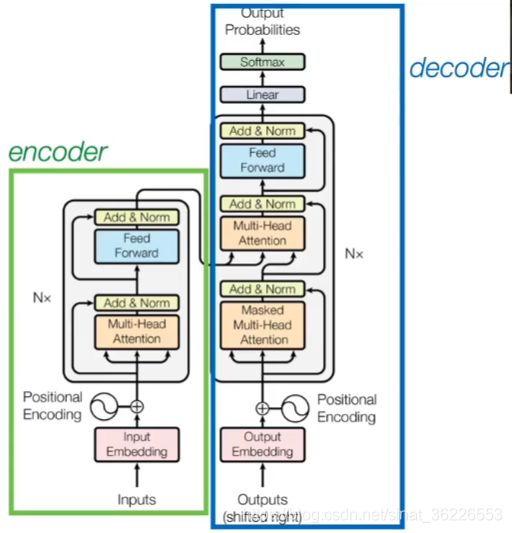 图1 The Transformer - model architecture
图1 The Transformer - model architecture
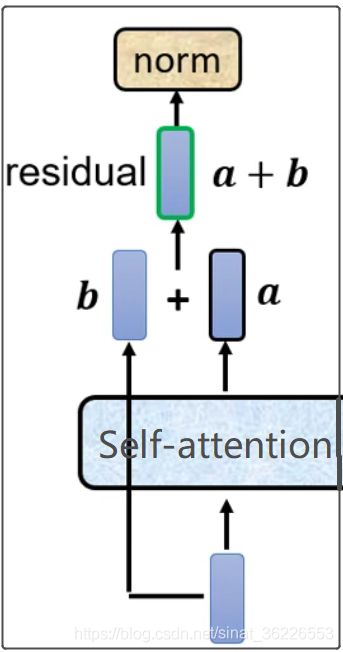
为了更好的优化深度网络,整个网络使用了残差连接(residual connection)和对层进行了归一化,即图中的Add&Norm。

Add 指我们会把 Multi-Head Attention 的输入和输出加起来得到 ![]() ,Norm指我们会把得到的
,Norm指我们会把得到的 ![]() 做 Layer Norm。残差连接通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分;Normalization可以加快收敛。
做 Layer Norm。残差连接通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分;Normalization可以加快收敛。
Layer Norm 不同于 Batch Norm。 Batch Norm 是希望整个 batch 里面同一个 dimension 的均值为0,方差为1。Layer Norm 是给一组 data,我们希望不同 dimension 的均值为0,方差为1(这样其实不用考虑到Batch

Norm:
( while m is mean,σ is standard deviation
链接:标准化(Standardization)和归一化(Normalization)什么区别?
## Encoder
Transformer中的每个Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到self-attention层,self-attention层产生一个等量512维向量列表,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的列表,然后将输出向上传递到下一个encoder (注:词向量维度的大小是可以设置的超参数。一般情况下,它是我们训练数据集中最长的句子的长度。
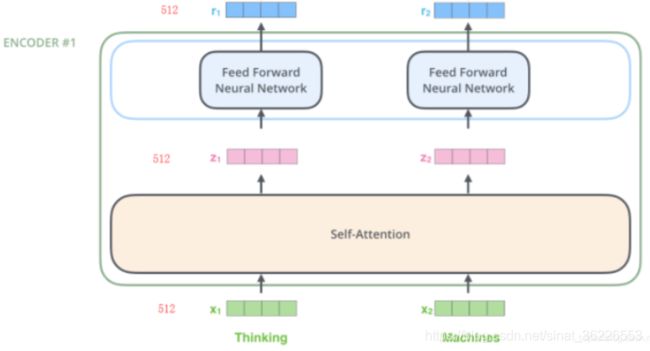
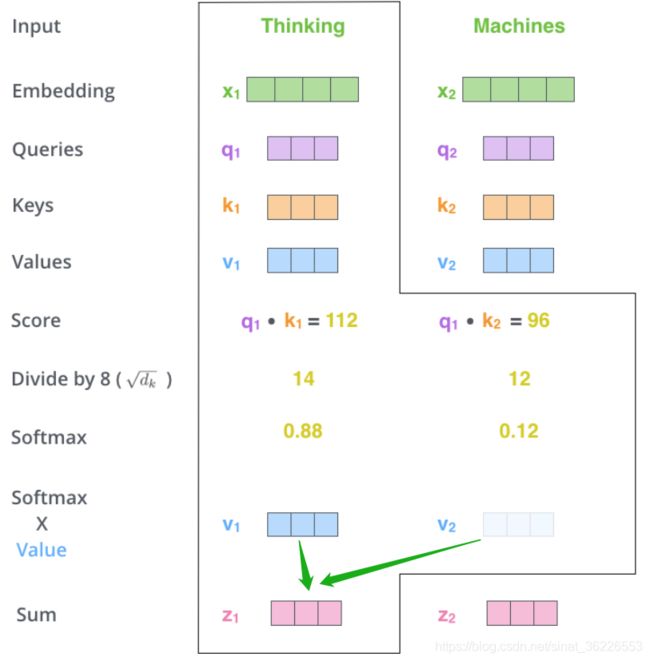
Self-attention层的计算过程已在前文讲解,不再赘述。
注:Queries、Keys 和 Values 新向量的维度比嵌入向量小。我们知道嵌入向量的维度为512,而这里的新向量的维度只有64维。新向量并不是必须小一些,这是网络架构上的选择使得Multi-Head Attention(大部分)的计算不变。
这里也采用了多头,所以要将h次的放缩点积attention结果进行拼接(concat),再进行一次线性变换得到的值作为多头attention的结果( 这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息
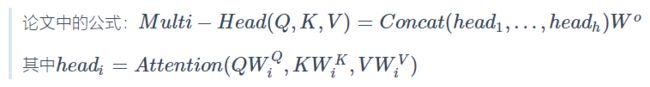

在模型的超参实验中可以看到,多头attention的超参h太小也不好,太大也会下降。整体更大的模型比小模型要好,使用dropout可以帮助过拟合。

encoder有N个子层叠加而成(图1只绘制了1个子层),论文中取N=6;对于encoder的每个子层中,进行multi-head attention计算后会进行残差连接以及归一化,然后送入全连接层(feed-forward layer),进行非线性变换(所用的激活函数为ReLU),得到子层的输出。

注:这里在encoder的第一层会对Z拷贝head*3 份,分别作为K,V,Q的输入,即Q=K=V=Z。然后再将上述的结构堆叠N层,就可以得到最终的Encoder的输出。

## Decoder
Decoder多了一个multi-head attention,该层的输入的Q为self-attention的输出,K和V来自Encoder(对应层)的输出( 特别注意是对应层:encoder的第一层的输出作为decoder第一层的输出)从上往下,他们的堆叠关系如下图:
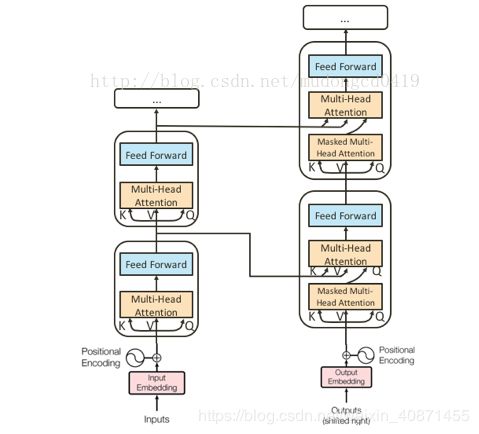
虽然该论文是这样,但也有不少研究考虑了其它对应关系
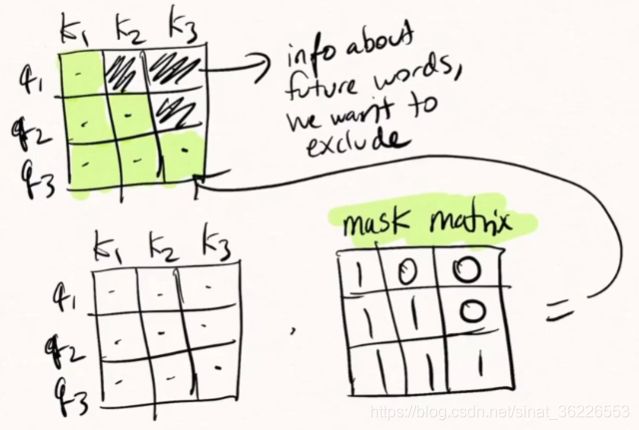
Masked Multi-Head Attention:所谓masked就是输出层在计算第 j 个词与其他词的attention时,只考虑 j 前面的词。如果不掩盖的话,训练的时候相当于模型能看到后面的答案,那就是“作弊”!masking 的作用就是防止在训练的时候使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能参考比 i 前的输出。
 【双语字幕】麻省大学《CS685 自然语言处理进阶》课程(2020) by Mohit Iyyer_哔哩哔哩_bilibili
【双语字幕】麻省大学《CS685 自然语言处理进阶》课程(2020) by Mohit Iyyer_哔哩哔哩_bilibili
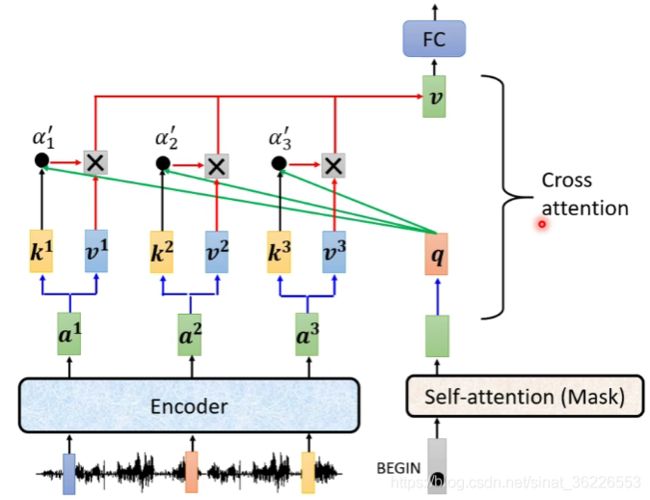
Decoder中传入的Outputs(shifted right)是指在训练期间的target sequence that have been shifted to the right (e.g.,
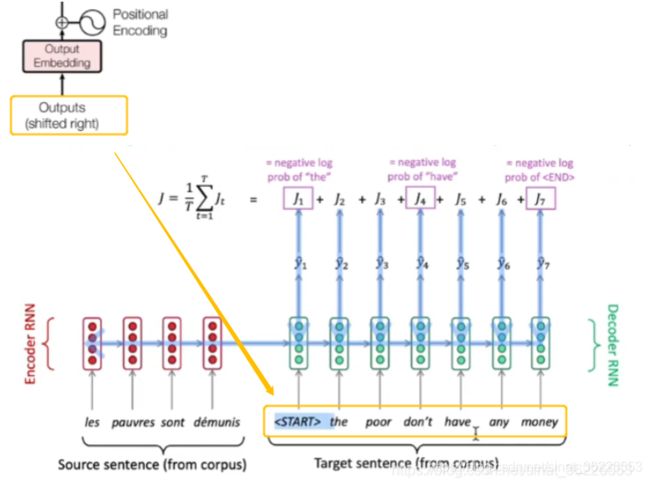
Teacher Forcing:using the ground truth as input.
不同于训练模型,当我们在测试机器翻译效果时,是不具有translated target sequences,则无法进行Masked Multi-Head Attention,此时我们只能采用与RNN一样的方法:预测一个词,将其放入模型预测下一个词,再将预测出的词放入模型预测下一个词...这个操作无法并行,因此在测试阶段Transformer并不比RNN在速度方面有所提升。
# 效果可视化
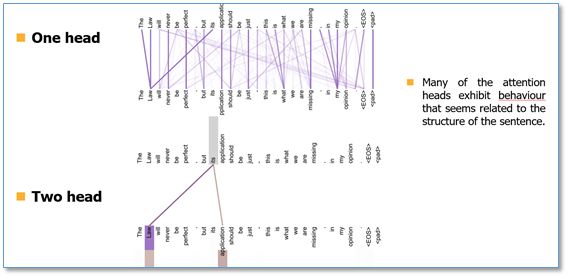
不同颜色代表attention不同头的结果,颜色越深attention值越大。可以看到self-attention在这里可以学习到句子内部长距离依赖"making…….more difficult"这个短语。

在两个头和单头的比较中,可以看到单头"its"这个词只能学习到"law"的依赖关系,而两个头"its"不仅学习到了"law"还学习到了"application"依赖关系。多头能够从不同的表示子空间里学习相关信息。
# seq2seq with / without attention
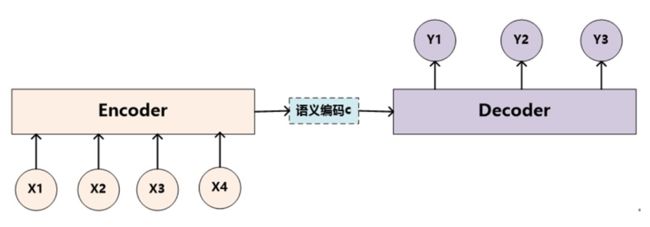 Encoder-Decoder框架抽象表示
Encoder-Decoder框架抽象表示
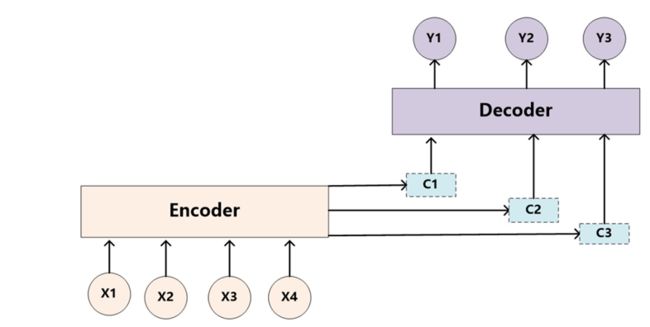 注意力模型的Encoder-Decoder框架
注意力模型的Encoder-Decoder框架

# 应用 Application
-
语音识别
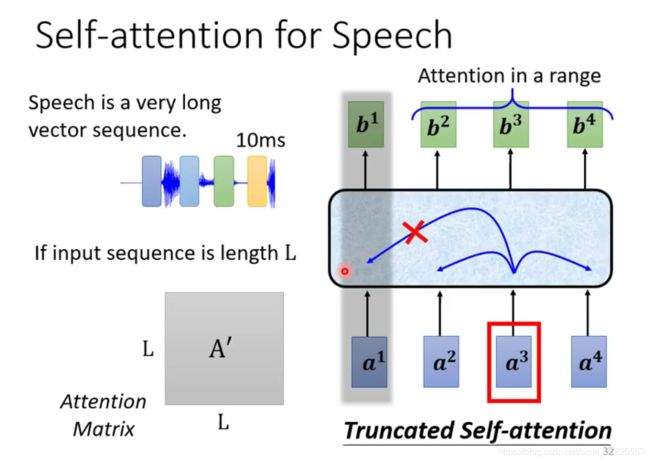
并非所有问题都需要长程的、全局的依赖的,也有很多问题只依赖于局部结构,这时候用纯Attention也不大好。
- 图神经网络GNN

- 神经语言模型NLM

# 结语
摘自苏神博客 苏剑林. (Jan. 06, 2018). 《《Attention is All You Need》浅读(简介+代码) 》
Attention层的好处是能够一步到位捕捉到全局的联系,因为它直接把序列两两比较(代价是计算量变为![]() ,当然由于是纯矩阵运算,这个计算量相当也不是很严重)
,当然由于是纯矩阵运算,这个计算量相当也不是很严重)
Attention虽然跟CNN没有直接联系,但事实上充分借鉴了CNN的思想,比如Multi-Head Attention就是Attention做多次然后拼接,这跟CNN中的多个卷积核的思想是一致的;还有论文用到了残差结构,这也源于CNN网络。
无法对位置信息进行很好地建模,这是硬伤。尽管可以引入Position Embedding,但我认为这只是一个缓解方案,并没有根本解决问题。举个例子,用这种纯Attention机制训练一个文本分类模型或者是机器翻译模型,效果应该都还不错,但是用来训练一个序列标注模型(分词、实体识别等),效果就不怎么好了。那为什么在机器翻译任务上好?我觉得原因是机器翻译这个任务并不特别强调语序,因此Position Embedding所带来的位置信息已经足够了,此外翻译任务的评测指标BLEU也并不特别强调语序。
并非所有问题都需要长程的、全局的依赖的,也有很多问题只依赖于局部结构,这时候用纯Attention也不大好。事实上,Google似乎也意识到了这个问题,因此论文中也提到了一个restricted版的Self-Attention(不过论文正文应该没有用到它),它假设当前词只与前后 r 个词发生联系,因此注意力也只发生在这2r+1个词之间,这样计算量就是O(nr),这样也能捕捉到序列的局部结构了。但是很明显,这就是卷积核中的卷积窗口的概念!
# 参考
1️⃣ 视频:麻省大学《CS685 自然语言处理进阶》课程(2020) by Mohit Iyyer
2️⃣ 视频:台大李宏毅21年机器学习课程 self-attention和transformer
3️⃣ transformer 模型(self-attention自注意力)
4️⃣ 苏剑林. (Jan. 06, 2018). 《《Attention is All You Need》浅读(简介+代码) 》
5️⃣ 自然语言处理中的自注意力机制(Self-attention Mechanism)
6️⃣ Self-Attention 和 Transformer
7️⃣ self-attention详解
8️⃣ 从零开始学Python自然语言处理(27)—— 开辟新纪元的Transformer