了解并掌握Halcon HDevelop 仿真程序语法
(一)Halcon的语法结构特点
特点:
1)Halcon大部分的语句是Halcon提供的算子,此外也包含了少部分的控制语句;
2)不允许单独声明变量;
3)提供自动的内存管理(初始化、析构及OverWrite),但句柄则需要显示释放;
4)C++(算子模式)
通过代码导出,以C++为例,默认导出为算子型的语法结构,而非面向对象的;在此模式下,全部函数声明为全局类型,数据类型只需要用Hobject、HTuple两类类型进行声明;
5)C++(面向对象)
可以以面向对象的方式重写代码,也即利用类及类的成员函数;
在这种模式下,控制变量的类型仍未HTuple,而图形数据可以由多种类型,如HImage等
8.1 参数的基本类型
Halcon区分两种数据:控制数据(数字或字符串)和图形数据(图像,区域等)。进一步区分输入和输出参数可以获得四种不同的参数。如下:
operator (iconic input : iconic output : control input : control output)
显而易见,总是先传递图形输入对象,然后才传递图形输出对象。 图形数据后跟控制数据,并且输入参数紧随输出参数之后。
四种类型的参数中的任何一个都可以为空。 例如,read_image的读取:
read_image ( : Image : FileName : )
算子read_image有一个图形输出参数Image 和一个输入控制参数FileName.在算子窗口输入算子时,会反馈参数类型。HDevelop程序窗口显示的实际算子调用为:
read_image(Image,‘Name’)
参数之间用逗号隔开。输入控制参数可以是变量、常量或表达式。表达式在传递给接收计算结果的参数之前先进行求值。图形参数必须是变量。控制输出参数也必须是变量,因为它们存储算子测试的结果。
8.2控制类型和常量
在HDevelop中,所有非图形数据都由所谓的控制数据(数字或字符串)表示。halcon算子可以控制图像处理(例如,分割操作符的阈值)的表现(效果)。在HDevelop中的控制参数可能包含算术或逻辑运算。控件数据项可以是下列数据类型之一:integer, real, string, and boolean(整数、实数、字符串和布尔值)。
integer
integer的数据类型在与C中相同的语法规则下使用。可以以标准的十进制表示法输入整数,以十六进制表示的数字以0x为前缀,以八进制表示的数字以0(零)作为前缀。
例如:
4711
-123
0xbeef (48879 in decimal notation)
073421 (30481 in decimal notation)
real(整数)类型的数据的数据转化为计算机内部的表示法,即C的long型(4或8个字节)。
real
real数据类型在与C相同的语法规则下使用。
例如:
73.815
0.32214
.56
-17.32e-122
32E19
real类型的数据转化为计算机内部的表示法,即c中的double形(8bit)
string
字符串是用单引号( ’ )括起来的一系列字符。 如表8.1所示,特殊字符(如换行符)以类似C的符号表示(请参见C语言参考进行比较)。 您可以使用\ xnn格式(其中nn是两位数字的十六进制数字)或使用\ 0nnn格式(其中nnn是三位数字的八进制数字)输入任意字符。 如果字符串是明确的,则可以使用较少的数字。 例如,除非字符串以另一个十六进制数字(0-F)继续,否则可以将换行符指定为\ xa。
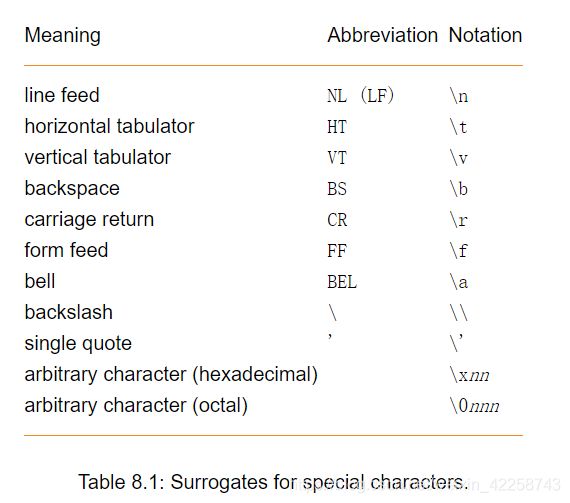
例如:字符串 Sobel’s edge-filter必须指定为'Sobel\'s edge-filter'。windows目录路径可以输入为'C:\\Programs\\MVTec\\Halcon\\images'
boolean
常量true和false属于布尔数据类型。 true值由数字1表示,false值由0表示。这意味着,在表达式Val:= true中,Val的有效值设置为1。通常,除0之外的每个整数都表示true。 请注意,某些HALCON算子采用逻辑值作为输入(例如set_system)。 在这种情况下,HALCON算子期望使用字符串常量,例如“ true”或“ false”,而不是布尔值true或false。
除了这些常规类型之外,还有分别用于HALCON或HDevelop的特殊常量和元组类形。 从HALCON 12.0开始,HDevelop还支持变量类型vector(请参见“向Vector一节)。
constants
一个算子的返回值(结束状态)是常量。 这些常量可以与算子dev_error_var和dev_set_check一起使用。 这些常量表示算子的正常返回值, so-called messages。

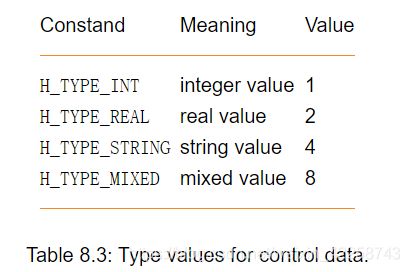
在表8.2中可以找到所有返回消息。此外,还有控制数据类型的常量(见表8.3)。这些可以与算子类型的结果进行比较,以对不同类型的控制数据作出反应(参见第811页的“类型操作”部分)。
tuple
控制类型仅在通用HDevelop中的元组类型中使用。长度为1的元组被解释为原子值。一个元组可以由几个不同类型的数据项组成。元组的标准表示是括号中包含的元素的列表。如图8.1所示。
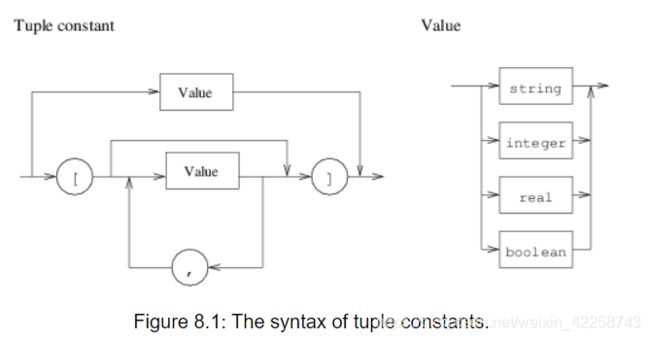
8.1 元组常量的语法
[ ]指定空元组。一个只有一个元素的元组被视为一个特例,因为它既可以用元组表示法指定,也可以作为原子值来指定:[55]定义了与55相同的常量。元组的示例包括:
[]
4711
0.815
'Text'
[16]
[100.0,100.0,200.0,200.0]
['FileName','Extension']
[4711,0.815,'Hugo']
8.3变量
变量的名称通常是由字母、数字和下划线“_”组成的。变量的类型(图形或控制变量)取决于它在首次使用变量标识符的参数列表中的位置。变量的类型是在输入算子参数的过程中确定的:每当出现新标识符时,都会创建具有相同标识符的新变量。控制和图形变量的名称必须不同。变量(图形或控制)的值在第一个赋值定义之前是未定义的(变量尚未实例化)。对未定义变量的读取访问将导致运行时错误。
HDevelop提供了一个named_(单下划线)的预定义变量。 您可以将该变量用于你不希望使用其值的输出控制参数。请注意,不允许将此变量用于HDevelop特定的算子(HALCON参考手册中的“ Control and Develop i”章节)。 不建议在程序中使用variable _,这些变量以后会导出为外来编程语言。
实例化的变量包含元组值。根据变量的类型,数据项可以是图标对象,也可以是控制数据。元组的长度由已执行算子动态决定。一个变量可以得到任何次数的新值,但一旦一个值被分配,这个变量将一直被实例化,除非你选择菜单项菜单 Execute ⇒ Reset Program Execution.。在给变量赋新值之前删除变量的内容。
8.3.1变量类型
不同类型的变量允许对变量(控制或图形数据)进行第一次(“粗略”)类型化的概念,而数据的实际类型(如实数、整数、字符串等)是未定义的,直到变量被指定了一个具体的值。
在HDevelop中,以三种不同的方式定义变量的类型:
explicitly:
过程参数定义
全局变量声明
implicitly:
代码中的用法
在这三种可能性中,过程参数定义是最有效的一种,在任何情况下都会推翻另外两种可能性,其次是全局变量声明。因此,在代码中使用是最无效的。在后一种情况下,变量的类型是由这些代码行定义的,并且仅由这些代码行定义,其中变量的值是写入的,新值的确切类型是先验已知的(即,在运行时之前)。
在其范围内,变量必须始终具有相同的类型(控制、图形)和相同的维度,否则将导致错误:
1)如果变量的类型从未正确定义,则变量将具有未定义的类型。所有使用该变量的行都将无效,变量将不会显示在变量窗口中。
2)如果一个变量的类型被定义了两次或更多次,那么变量类型也将是未定义的,上述情况也同样适用。
3)如果变量的类型定义正确,但在错误的上下文中使用(例如,将变量用作控制输入参数),则只有受影响的代码行将变为无效。
8.3.2变量范围(局部或全局)
HDevelop支持局部和全局变量。默认情况下,所有变量都是局部变量,即它们只存在于其进程中。因此,同名的局部变量可以存在于不同的进程中,而不会相互干扰。相反,全局变量可以在整个程序中访问。它们必须使用算子global显式声明。
声明: global tuple File
声明名为File的全局控制变量:global object Image
声明一个全局图形变量Image
def关键字允许将一个声明明确标记为定义变量的位置,例如global def object Image。 仅在将程序导出为编程语言时才有意义。 有关更多信息,请参见算子global的描述。
声明全局变量后,就可以像在声明该过程中的局部变量一样使用它。如果要在其他过程中访问全局变量,则必须使用相同的global …进行声明。 。(否则,将创建一个局部变量)。
主程序:
* declare global variables
global tuple File
global object Image
...
File := 'particle'
read_image(Image, File)
process_image()
* Image has been changed by process_image()
* File remains unchanged
...
process_image procedure:
* use global variable
global object Image
...
bin_threshold(Image, Region)
File := 'fuse'
read_image(Image, File)
return()
因为过程必须明确声明它们使用全局变量,所以不能通过在程序的其他部分引入全局变量来破坏现有的过程。从本质上讲,全局变量的名称在整个HDevelop程序中必须是唯一的,即所有加载的外部过程、主过程和所有本地过程。“变量”窗口提供了一个特殊的选项卡,用于列出当前声明的所有全局变量。
 Figure 8.2: Global variables.
Figure 8.2: Global variables.
8.4 对图形对象的操作
图形目标仅由HALCON算子处理。 HALCON算子处理图形对象的元组,这些元组由HALCON数据管理中的代理项表示。 这些算子的结果又是图形对象或控制数据元素的元组。
8.5输入控制参数的表达式
在HDevelop中,诸如算术运算或字符串运算之类的表达式的使用仅限于控制输入参数。 所有其他类型的参数都必须由变量分配。
8.5.1元组运算的一般特征
本节将简要概述元组的特性及其操作。下面几节将对这里提到的每个运算进行更详细的描述。
请注意,在下面所有的表格中,变量和常量都被表示允许的数据类型的字母代替。这些字母提供了关于定义范围可能存在的限制的信息。字母及其含义见表8.4。对这些符号的操作只能应用于指定类型的参数或返回指定类型结果的表达式。
符号名i、a、l和s可以表示原子元组(长度为1的元组)以及任意长度的元组。

表8.4:运算说明符
通常使用原子元组来描述操作。如果元组包含多个元素,大多数运算符的工作方式如下:
1)如果一个元组的长度为一,则将其他元组的所有元素与该单个值组合以进行所选操作。
2)如果两个元组的长度都大于1,则两个元组的长度必须相同(否则会发生运行时错误)。 在这种情况下,所选算子将应用于具有相同索引的所有元素。 结果元组的长度与输入元组的长度相同。
3)如果其中一个元组的长度为0([]),则会发生运行时错误。
在表8.5中,您可以找到一些使用元组进行算术运算的示例。 要特别注意执行字符串串联的顺序。 HDevelop中的基本算术运算是+,-,*,/。 请注意,+是双态运算:如果两个操作数都是数字,则将数字相加。 如果至少一个操作数是字符串,则将两个操作数连接为字符串。

8.5.2赋值
在HDevelop中,赋值被视为运算符。要使用赋值,必须选择算子assign(Input,Result)。此运算符具有以下语义:它计算Input(赋值的右侧)并将其存储在Result(赋值的左侧)。然而,在程序文本中,赋值由赋值运算符的常用语法表示: assign(Input,Result)。
assign : 对数据赋值,对数组的初始化。但不能对数组中的某一个值进行赋值。
以下示例概述了C语法中的赋值与其在HDevelop中的转换版本之间的区别:
C语法中的赋值:u = sin(x) + cos(y);
在HDevelop中使用赋值算子定义为: assign (sin(x) + cos(y), u)
在程序窗口中显示为:u := sin(x) + cos(y)
如果表达式的结果不需要存储到变量中,则表达式可以直接用作任何运算符的输入值。因此,只有在值必须多次使用或变量必须初始化(例如,对于循环)时,才需要赋值。
assign_at : 对数组中的某一个值进行赋值。
赋值算子assign_at(Index,Value,Result)用于修改元组元素:assign_at (Radius-1, Area, Areas)
在程序文本中不是作为运算符调用,而是以更直观的形式显示为:Areas[Radius-1] := Area.
譬如说:
Areas := [1,2,3]
Areas[1] := 9
将Areas设置为[1,9,3]。
要使用assign_at构造元组,通常使用空元组作为初始值,并将元素插入循环中:
Tuple := []
for i := 0 to 5 by 1
Tuple[i] := sqrt(real(i))
endfor
从示例中可以看到,元组的索引从0开始。
通常可以通过以下方式之一将其插入元组:
1)如果将值附加在“后”或“前”,则可以使用元组串联操作(逗号)。此处运算符赋值与以下参数一起使用:
assign ([Tuple,NewVal],Tuple)
显示为: Tuple := [Tuple,NewVal]
2)如果索引位置介于两者之间,则必须使用运算符tuple_insert。
要将元组[11,12,13]插入到元组[1,2,3]的位置1,请使用:
tuple_insert ([1,2,3], 1, [11,12,13], Result)
结果为:[1,11,12,13,2,3].
在下面的示例中,使用圆形掩膜对区域进行扩张,然后将区域存储到元组区域中。 在这种情况下,将使用运算符Assign_at。
read_image (Mreut, 'mreut')
threshold (Mreut, Region, 190, 255)
Areas := []
for Radius := 1 to 50 by 1
dilation_circle (Region, RegionDilation, Radius)
area_center (RegionDilation, Area, Row, Column)
Areas[Radius-1] := Area
endfor
请注意,首先必须对变量Areas进行初始化,以避免运行时错误。 在示例中,Areas用空元组([ ])初始化。 而不是assign_at这个算子使用元组连接赋值。(assign_at:对数组中的某一个值进行赋值)
Areas := [Areas,Area]
无法使用,因为元素附加在元组的后面。更多的例子可以在assign.hdev程序中找到。
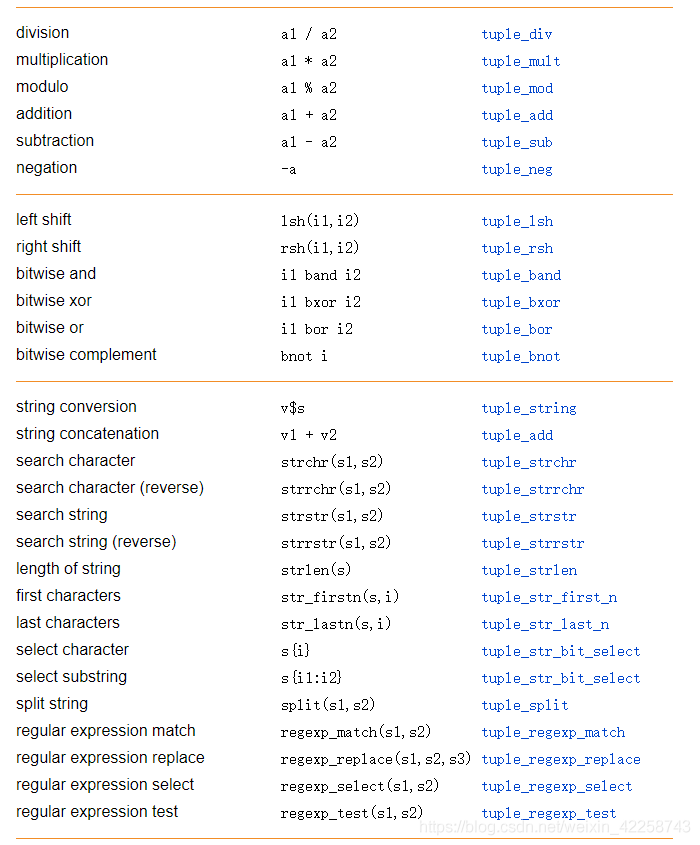
8.5.3基本元组运算
基本的元组运算可以是选择一个或多个值,组合元组(连接)或获取元素数(关于对包含控制数据的元组的运算,请参见表8.6)。
表8.6:元组(控制数据)和相应的HALCON算子的基本运算。
连接接受一个或多个变量或常量作为输入。它们都列在括号中,用逗号分隔。结果也是一个元组。请注意以下事项:[[t]] = [t] = t。
| t | 返回元组的元素数。 元素的索引的范围是从零到元素数减去一(即| t | -1)。 因此,选择索引必须在此范围内。 1)
Tuple := [V1,V2,V3,V4]
for i := 0 to |Tuple|-1 by 1
fwrite_string (FileHandle,Tuple[i]+'\n')
endfor
在以下示例中,变量Var包含[2,4,8,16,16,32]:
[1,Var,[64,128]] [1,2,4,8,16,16,32,64,128]
|Var| 6
Var[4] 16
Var[2:4] [8,16,16]
subset(Var,[0,2,4]) [2,8,16]
select_mask(Var,[1,0,0,1,1,1]) [2,16,16,32]
remove(Var,[2,3]) [2,4,16,32]
find(Var,[8,16]) 2
uniq(Var) [2,4,8,16,32]
可以在程序tuple.hdev中找到更多示例。 表8.6中列出了与基本元组运算相对应的HALCON算子。
注意,这些直接运算不能用于图形元组,即,不能使用[ ]从元组中选择图形对象,并且不能使用 | | 直接确定其编号。 但是,为此目的,提供了HALCON算子来执行等效任务。 在表8.7中,您可以看到对控制数据进行运算的元组操作(并通过assign或assign_at应用)以及对图形数据进行处理的元组运算(是独立的算子)。 在表中,符号t表示控制元组,符号p和q表示图形元组。

表8.7:用于控制和图形数据的等价元组运算
1) 请注意,对象的索引(例如select_obj)的范围是从1到元素的数量。
8.5.4 元组创建
创建元组的最简单方法是将常量与算子assign一起使用(如果是图形数据,则使用表8.7中所示的其中一个等效值):
assign ([],empty_tuple)
assign (4711,one_integer)
assign ([4711,0.815],two_numbers)
此代码显示为:
empty_tuple := []
one_integer := 4711
two_numbers := [4711,0.815]
这对于具有固定(较小)长度的恒定元组很有用。 可以通过不断应用串联或assign_at(赋值)算子以及变量,表达式或常量来创建更多通用元组。 如果我们要生成一个长度为100的元组,其中每个元素的值都为4711,则可以这样进行:
tuple := []
for i := 1 to 100 by 1
tuple := [tuple,4711]
endfor
因为这不太方便,所以可以使用一个称为gen tuple_const的特殊函数来构造给定长度的元组,其中每个元素的值都相同。使用此功能,上述程序可简化为:
tuple := gen_tuple_const(100,4711)
创建具有公共增量的值序列的快速方法是使用tuple_gen_sequence。 例如,要创建包含值1…1000的元组,请使用:
tuple_gen_sequence(1,1000,1,Sequence)
上面的另一种语法是这样写:
Sequence := [1:1:1000]
如果增量值为1(如上例所示),则还可以写为:
Sequence := [1:1000]
如果我们想构造一个与给定元组长度相同的元组,有两种方法可以轻松解决。第一个利用gen-tuple-const:
tuple_new := gen_tuple_const(|tuple_old|,4711)
第二个有点麻烦,它使用算术函数:
tuple_new := (tuple_old * 0) + 4711
在这里,我们首先得到一个长度相同的元组,每个元素都设置为零。 然后,我们将常量添加到每个元素。
对于具有不同值的元组,我们必须使用循环版本将值分配给每个位置:
tuple := []
for i := 1 to 100 by 1
tuple := [tuple,i*i]
endfor
在这个例子中,我们构造一个具有1的平方值到100平方值的元组。
8.5.5 运算类型
运算符类型允许测试或查询控制数据的值类型。相应的类型常量见表8.3。
还有相应的运算来测试输入元组的每个元素。
8.5.6基本算术运算
可用的基本算术运算,见表8.10。
除右关联一元减号运算符外,所有操作都是左关联的。测试通常是从左到右进行的。但是,括号可以更改求值顺序,并且某些运算符的优先级高于其他运算符(请参见“Operation Precedence”一节)。
HDevelop中的算术运算与通常的定义相匹配。表达式可以有任意数量的括号。
除法运算符(a1/a2)既可用于实数,也可用于整数。如果至少有一个操作数是实数类型,则结果为实数类型。如果两个操作数都是整数类型,则除法是整数除法。其余的算术运算符(乘法、加法、减法和求反)可以应用于整数或实数。如果至少有一个操作数是实数类型,则结果也是实数。
示例:
简单的例子可以在arithmetic.hdev程序中找到。
8.5.7位运算
本节介绍数字的位处理运算。运算数必须是整数。
lsh(i1,i2)的结果是i1的按位左移,应用i2次。如果没有溢出,这相当于乘以2的i2次方。rsh(i1,i2)的结果是i1的按位右移,应用i2次。对于非负的i1,这相当于除以2i2。对于负i1,结果取决于使用的硬件。对于lsh和rsh,如果第二个运算数为负值或值大于32,则结果未定义。更多的例子可以在bit.dhev程序中找到。
8.5.8字符串运算
有几种字符串运算可用于修改、选择和组合字符串。此外,有些运算允许将数字(实数和整数)转换为字符串。

$(字符串转换)
另请参见:元组字符串。
将 数 字 转 换 为 字 符 串 或 修 改 字 符 串 。 该 运 算 有 两 个 操 作 数 : 第 一 个 操 作 数 ( 将数字转换为字符串或修改字符串。该运算有两个操作数:第一个操作数( 将数字转换为字符串或修改字符串。该运算有两个操作数:第一个操作数(的左边)是必须转换的数字。第二个($的右边)指定转换。它相当于C编程语言中printf()函数的格式字符串。此格式字符串由以下四部分组成
 或者作为正则表达式:[-+ #]?([0-9]+)?(.[0-9]*)?[doxXfeEgGsb]?
或者作为正则表达式:[-+ #]?([0-9]+)?(.[0-9]*)?[doxXfeEgGsb]?
(大致翻译为第一个括号对中的零个或多个字符,后跟零个或多个数字,可选择后跟一个点,后面可能是数字,然后是最后一个括号对中的转换字符)。
一些转换示例可能最能说明这一点:
之后的略
+(字符串连接)
另请参见:tuple_add。
字符串连接(+)可以与字符串或所有数值类型结合使用;如果需要,首先将操作数转换为字符串(根据其标准表示形式)。至少有一个操作数必须已经是字符串,以便运算符可以充当字符串连接器。在下面的示例中,将生成一个文件名(例如“Name5.tiff”)。为此,两个字符串常量(‘Name’和’.tiff’)和一个整数值(循环索引i)连接在一起:for i := 1 to 5 by 1 read_image (Image, 'Name'+i+'.tiff') endfor
str (r)chr
另请参见:tuple_strchr, tuple_strrchr.
str(r)chr(s1,s2)返回字符串s1中s2中某个字符第一次(最后一次)出现的索引,如果字符串中没有任何字符出现,则返回-1。s1可以是单个字符串或字符串的元组。
str ( r)str
另请参阅:tuple_strstr, tuple_strrstr.
str(s1,s2)返回字符串s2在字符串s1中第一次(最后一次)出现的索引,如果s2没有出现在字符串中,则返回-1。s1可以是单个字符串,也可以是字符串的元组。
strlen
另请参阅: tuple_strlen.
strlen(s)返回s中的字符数。
str_firstn
:tuple_str_first_n.
str_firstn(s,t)返回从字符串s开头到位置t的字符。
。。。。之后的略,太多了。。。。
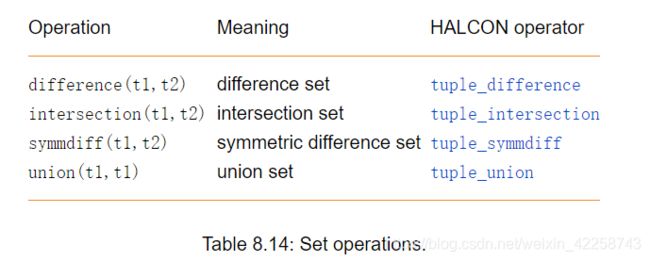
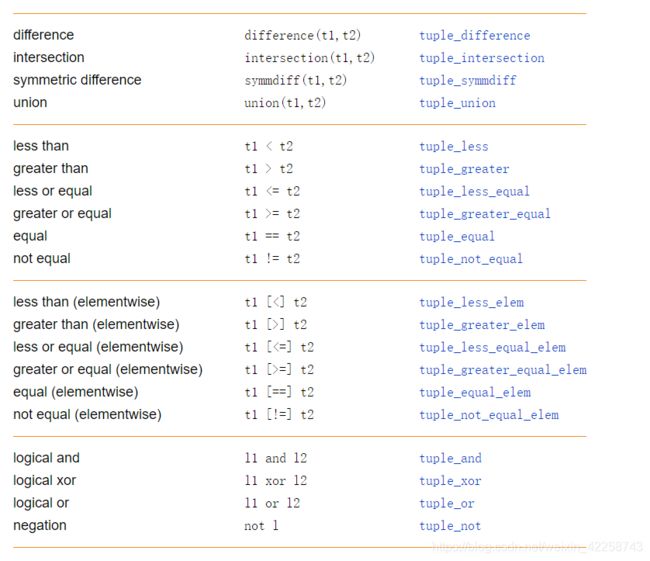
8.5.9 集合运算
8.5.10比较运算
在HDevelop中,比较运算不仅定义在原子值上,还定义在具有任意数量元素的元组上。它们总是返回boolean类型的值。表8.15显示了所有比较运算。 这些比较运算符在元素方面比较输入元组t1和t2。如果两个元组具有相同的长度,则比较两个元组的对应元素。否则t1或者t2的长度一定是1。在本例中,将对长元组的每个元素与其他元组的单个元素进行比较。作为比较元组元素的先决条件,两个对应的元素要么都是(整数或浮点)数字,要么都是字符串。 所有这些函数都将数字元组作为参数。输入的类型可以是整数或实数。然而,得到的类型将是 所有这些函数都将数字元组作为参数。输入的类型可以是 表8.22中显示的数值函数适用于不同的数据类型。 函数 real将整数转换为实数。对于real的输入,它也返回输入。int将实数转换为integer(整数)并将其截断。将实数转换为整数并对值进行四舍五入。对于整数,它返回输入。abs函数总是返回与输入值相同类型的绝对值。 首先计算两个向量V1和V2的欧几里得距离,使用公式: sort按升序对元组值进行排序,这意味着结果元组的第一个值是最小的。但是,字符串不能与数字混淆。 该函数反转元组值的顺序。如果输入为空,如果元组长度为1,或者元组在所有位置上只包含一个值,例如[1,1,…,1],那么sort和inverse都是相同的。 函数number将表示数字的字符串转换为整数或实数,具体取决于数字的类型。注意,以0x开头的字符串被解释为十六进制数字,以0(0)开头的字符串被解释为八进制数字;例如,字符串’20’被转换为整数20,'020’被转换为16,'0x20’被转换为32。如果使用不表示数字的字符串或使用integer或real类型的变量调用number,则会返回输入的副本。 environment返回环境变量的值。Input是环境变量的字符串名称。 ord将字符的ASCII码作为整数提供。chr将ASCII码转换为字符。 ords将字符串的元组转换为(ASCII)整数的元组。chrt将整数元组转换为字符串。 控制数据操作的优先级见表8.24。有些运算符(如函数、| |、t[ ]等)被忽略了,因为它们清楚地标记了它们的参数。 向量是一个容器,可以容纳任意数量的元素,所有元素必须具有完全相同的变量类型(例如元组、图形对象或向量)。变量类型“vector”是特定于HDevelop的。它在HDevelop 12.0或更高版本中可用。请注意,使用矢量变量的程序不能在HDevelop的旧版本中执行。 元组或对象的向量称为一维的,元组或对象的向量的向量称为二维的,依此类推。向量的类型不能在程序中改变。,它的维数必须保持不变,元组的向量不能被分配符号对象,反之亦然。 以下是EBNF(Extended Backus-Naur Form)语法中矢量的定义: 构造向量 这就等同于: 当然,可以使用变量名或任意表达式来代替常量。 下面的示例定义了图形对象的向量。 下面的示例定义了一个二维向量变量。 还可以使用 但是请注意,空向量没有特定的类型。因此,以下三种空赋值都是有效的: 将空向量赋值给向量变量等同于 访问和设置向量元素 使用.at()运算符访问单个向量元素,该运算的参数范围从0到向量元素的数量减1。可以组合几个.at()操作来访问多维向量的子元素。访问不存在的向量元素是一个运行时错误。 .at()运算符还允许在循环中构造一个动态向量: 与.at()操作一样,必要时将自动填充空元素。 获取向量元素的数量 清除向量变量 修改向量运算符 向量运算符 使用特殊算子executable_expression在算子窗口中输入修改向量的操作。 测试向量变量是否相等 便捷算子 保留字:指在高级语言中已经定义过的字,使用者不能再将这些字作为变量名或过程名使用。 表8.25中列出的标识符是保留字,它们的用法严格限制在预定义的含义。它们不能用作变量名。 本节介绍的运算符有条件地或重复地执行运算符块。通常,这些运算符成对出现:一个运算符标记块的开始,而另一个标记块的结束。中间的代码行称为控制流结构的主体。 当您输入控制流运算符来启动块时,HDevelop还默认添加相应的关闭运算符,以保持程序代码平衡。此外,IC放置在控制流运算符之间。这对于输入新的代码块很好。如果希望将控制流运算符添加到现有代码中,还可以单独添加运算符。但是请记住,在输入相应的控制流运算符之前,单个控制流运算符将被视为无效代码。 在下文,是计算一个整数或布尔值的表达式。如果表达式的值为0(零),则条件为假。否则,它就是真的。HDevelop提供了以下运算符来控制程序流程: 要同时输入if和endif,请在运算符窗口中选择操作符if,并确保操作符旁边的复选框被勾选。 另一个简单的控制流结构是可选条件。 这在语法上是等价的,因此是以下代码块的快捷方式 要同时输入while和endwhile,请在算子窗口中选择while操作符,并确保该操作符旁边的复选框被勾选。 要同时输入repeat 和until,请在运算符窗口中选择运算符until,并确保运算符旁边的复选框已勾选。 请注意,for循环在program窗口中的显示与在运算符窗口中输入的显示是不同的。您在运算符窗口中输入的(开始、结束、步骤、索引)在程序窗口中显示为: 要同时输入for和endfor,请在运算符窗口中选择for操作符,并确保该运算符旁边的复选框被勾选。 最初的值被分配给索引变量。只要满足以下条件,循环执行:1)阶跃值(The step value)为正,循环索引小于或等于结束值。2)阶跃值为负,循环索引大于或等于结束值。循环周期结束后,循环索引按阶跃值递增,并再次计算条件。 因此,在执行以下代码行之后, i被设为6 j被设为5,在 i被设为0,j被设为1. 请注意,在HDevelop的旧版本中(HALCON 11之前),开始和终止值的表达式在进入循环时只计算一次。在这些表达式中出现的变量修改对循环的终止没有影响。循环索引的修改也是如此。它对终止也没有影响。每次执行for运算符时,循环值都被赋给正确的值。 如果for循环放置得太早(例如,如果按Stop并设置PC),并且再次进入循环,则将对表达式进行求值,就好像是第一次进入循环一样。 在以下示例中,计算出从0到6π的正弦值并将其打印到图形窗口中(文件名:sine.hdev): 在此示例中,假设窗口的大小为512××512,绘图始终是从最近计算的点到当前点。 在下面的示例中,处理RGB彩色图像的部分。使用运算符continue可跳过不是三通道的图像。另一种方法是反转条件并将处理指令放在if和endif之间。但是,当涉及到非常复杂的处理和大量的代码行时,带有continue的形式往往更具可读性。 运算符break的典型用法是在某个条件变为真时立即终止for循环,如以下示例所示: 在以下示例中,运算符break用于在单击图形窗口后立即终止(无限)while循环: 本节介绍如何在HDevelop程序中处理错误。当发生错误时,HDevelop的默认行为是停止程序执行并显示错误消息框。虽然这在开发程序时肯定是有益的,但在实际部署程序时通常不希望这样做。一个完成的程序应该对错误本身做出反应。如果程序与用户交互,这一点尤为重要。 HDevelop中的错误处理基本上有两种方法: 这些方法之间的一个主要区别是应用领域:第一个方法处理发生错误的过程中的错误。后一种方法允许错误在调用堆栈中一步步向上,直到它们最终被处理为止。 算子operator dev_set_check指定是否显示错误消息框。 要关闭消息框,请使用 与给定错误代码相关的错误消息可通过算子 如果要在调用过程中处理错误,则必须在每个参与过程的接口中添加适当的输出控制变量,或者必须将错误变量定义为全局变量。 HEDebug支持动态异常处理,它与C++和C语言中的异常处理相媲美。 监视一个程序行块是否存在运行时错误。如果发生错误,将引发异常并调用关联的异常处理程序。异常处理程序只是另一个程序行块,除非发生错误,否则程序流对它是不可见的。异常处理程序可以直接处理错误,也可以将相关信息(即异常)传递给父异常处理程序。这也称为重新抛出异常。 与上一节中描述的跟踪方法不同,异常处理需要将HDevelop设置为在出错时停止。这是默认行为。也可以明显打开: HDevelop异常是包含与特定错误相关的数据的元组。它总是将错误代码作为第一项。算子 HDevelop异常处理的应用方式如下: HDevelop语言支持将过程和运算符调用作为主线程的子线程并行执行。一旦启动,子线程就由一个线程ID标识,它是一个整数进程号,具体取决于操作系统。子线程的执行与启动它们的线程无关。因此,无法预测特定威胁结束的确切时间点。如果要访问从一组线程返回的数据,则需要显式地等待相应的线程完成。 HDevelop默认将线程数限制为20。如果需要,可以在首选项中修改此数字。限制并发线程数量的主要原因是防止用户由于编程错误而无意中生成大量线程。在这种情况下,系统负载和内存消耗可能会增长得如此之高,以至于HDevelop可能变得无响应。 请注意,线程计数包括所有“活动”线程。特别是它还包括已经完成但仍被变量引用的线程。在调整螺纹极限时,必须考虑到这一点。 要启动新线程,请在相应的运算符或过程调用前面加上par_start算子: 如果启动一个新的子线程将超过配置的最大线程数(见上文),则会引发异常。 您也可以从operator窗口中作为子线程启动过程或运算符调用(参见图8.3)。为此,请打开“运算符”窗口底部的“高级并行化选项”部分,勾选复选框并输入将保存线程ID的变量的名称。如果双击包含par_start限定符的程序,则并行化选项也将显示在“运算符”窗口中。对于某些程序行(例如,注释、声明、循环或分配),par_start不受支持,相应的选项也不会在操作员窗口中可用。有关操作员窗口的一般说明,请参阅第346页的“Operator Window”一节。 在向量变量中收集线程ID通常更方便: 当子线程返回输出变量中的数据时,必须特别小心。尤其是,当子线程仍在运行时,不能在其他线程中访问输出变量。否则不能保证数据有效。 同样,必须确保多个线程不会干扰其结果。假设算子gather_data是像上述那样作为多个线程启动的,但返回输出控制变量中的数据: 在上面的例子中,所有的线程都会在同一个变量中返回结果,这显然不是我们想要的。Result的最终值将是最后完成的线程的(不可预测的)返回值,其他所有结果都将丢失。 解决此问题的一个简单方法是将返回的数据收集到向量变量中,如前所示,线程ID为: 此处,每次调用collect_data都会在向量变量Result的唯一插槽中返回其结果。 使用算子par_join来等待单个线程或一组线程的完成。 作为一个为什么必须这样做的示例,假设我们要调用一个过程,该过程在后台执行一些神奇运算并返回一个计数值。 在随后的程序行中,我们希望使用该数字进行进一步的计算。 仅仅依靠子线程足够快是最有可能失败的。因此,需要事先直接调用par_join。 注意,在HDevelop中并不严格要求使用par_join,因为主线程总是比子线程长。但是,如果程序要在HDevEngine中执行或导出到编程语言中,省略它可能会导致麻烦。类似地,如果要导出程序,对全局变量的访问可能需要一些额外的同步。 给出上一节中的示例,使用以下几行代码来等待在循环中启动的所有线程的完成。 请注意,线程ID已收集在向量变量中。 因此,为使par_join正常工作,必须转换为元组。 par_join算子将阻止该程序的进一步执行,直到所有指定线程完成为止。 在随后的程序行中,可以可靠地访问相应线程的结果。 一般来说,HDevelop中的线程只有在按F5键后程序连续运行时才并行执行。在所有其他执行模式中,只有选定的线程被启动,而所有其他线程保持停止状态,除非显式的用户交互促进了它们的执行。活动断点、停止指令、运行时错误或未捕获的异常也会导致所有线程停止,以便可以评估其当前状态。此约定支持清晰定义的调试过程,因为它消除了来自其他线程的不可控制的副作用。程序窗口中的任何编辑操作也会导致同时运行的程序停止。 线程不能在外部“终止”。它们可以在操作员调用之间或通过中止可中断运算符来停止。如果任何线程执行一个在HDevelop尝试停止程序执行时无法中断的长时间运行的运算符,则状态行中将显示相应的消息,并且相应的线程最终将在运算符完成后停止。 选定的线程 其中一个线程就是所谓的selected thread;默认情况下,它对应于程序的主线程。PC的位置、调用堆栈的状态以及变量窗口中变量的状态都链接到所选线程。所选线程可以自动更改为停止的线程,例如,通过断点、停止指令、未捕获异常或绘制运算符。 线程和实时编译过程 过程可以作为编译的字节码执行,而不是由HDevelop解释器解释。第90页的“实时编译”一节对此进行了描述。使用编译过程调试线程化HDevelop程序时有一个显著的区别。如果程序连续运行,然后被停止(通过用户操作或断点/停止指令),则无法检查已编译过程(变量,PC)的当前状态。您仍然可以单步执行过程调用,但这将导致相应的线程被重新执行,这可能会导致意外的副作用。注意,当单步执行线程调用时,这不是问题,因为在这种情况下,过程总是由HDevelop解释器执行。 第878页“检查螺纹”一节介绍了如何选择特定螺纹。除连续执行以外的所有运行模式仅适用于选定的线程。与所选线程无关的程序行将在程序窗口中变灰。 线程寿命 只要线程仍被变量引用,就算存在,即使其执行已完成。这对于在par_join指令中引用该线程,或调回相应线程的PC进行调试是必需的。但是,如果在调用前将PC手动设置回程序行,则线程的生存期将结束。除此之外,当使用F2重置程序时,所有子线程的生存期都将结束。在其生命周期中,“线程视图/调用堆栈”窗口中列出了一个线程,从中可以选择和管理该线程。 已完成但仍处于“活动”状态的线程可能会在以后启动新线程时无意中超出配置的线程数限制。同样,如果在执行新线程的同时“杀死”已完成的线程,则可能对运行时行为产生负面影响。要明确地“结束”已完成的线程,就足以重置引用其线程ID的变量,如以下示例所示。 错误处理 每个线程可以指定自己的错误处理,例如,使用dev_set_check(’〜give_error’)。 新的子线程从其父线程继承错误处理模式。 使用try … catch的异常处理仅在线程内起作用,即在主线程中,不可能捕获在子线程中引发的异常。 程序及其线程的当前执行状态显示在组合线程视图/调用堆栈窗口中。 选择执行⇒线程视图/调用堆栈,或在工具栏中单击(另请参阅线程视图/调用堆栈)。 窗口的上半部分列出了所有现有线程,而下半部分显示了所选线程的调用堆栈。 为了说明与该窗口的交互,请考虑以下示例。 按下F5键后,程序将启动五个子线程,并最终到达stop指令,从而使某些子线程仍在运行,而其他子线程已经完成。 相应的线程视图如图8.4所示。 请注意,未完成的线程由于另一个线程而处于停止状态(在这种情况下,这是由主线程中的stop指令引起的)。 线程视图的列的含义如下: 线程可以在“线程视图”窗口中显式地挂起和恢复。挂起线程只在运算符调用之间起作用,即,如果线程当前正在运行,则仍将在线程冻结之前执行当前运算符。 要挂起线程,右键单击线程条目并选择suspendthread。挂起的威胁在其当前状态下“冻结”,并将推迟后续的运行命令,直到线程再次恢复,即运行命令将更改挂起线程的运行状态,但实际执行将被阻止。 要再次恢复挂起的线程,请右键单击线程条目并选择resume thread。 21000 HALCON操作员错误 21001用户定义的异常(‘throw’) 21002执行过程中用户定义的错误 21003用户定义运算符未实现执行接口 21010 HALCON许可证错误 21011 HALCON启动错误 21012 HALCON操作员错误 21020格式错误:文件不是有效的HDevelop程序或过程 21021文件不是HDevelop程序或版本错误 21022无法解压缩受保护的过程 21023无法压缩和加密受保护的过程以进行保存 21024格式错误:文件不是有效的HDevelop程序 21025格式错误:文件不是有效的HDevelop过程 21026格式错误:文件不是有效的HDevelop过程库 21030程序在HDevelop外部被不一致地修改。 21031程序在HDevelop外部被修改:过程行不一致。 21032程序在HDevelop之外被修改:不匹配的控制语句 21033重命名过程失败 21034所选操作不支持锁定过程。 21034密码保护/锁定程序 21035并行执行语句、标志性赋值或标志性比较 21035所选操作不支持具有高级语言元素的过程。 21036所选操作不支持包含向量变量的过程。 21036矢量变量 21040无法打开文件 21041无法读取文件 21042无法写入文件 21043无法重命名文件 21044无法打开文件:文件名无效 21050对于此运算符,不支持par_start的并行执行 21051线程创建失败 21052线程创建失败:超过了最大子线程数 21060图标变量未实例化 21061控制变量未实例化(无值) 21062控制值数量错误 21063控制参数值类型错误 21064控制参数值错误 21065控制参数不包含变量 21066控制参数必须是常量 21067条件变量中的控制值数目错误 21068类型错误:条件变量必须是整数或布尔值 21070变量名不能为空 21071变量名不能以数字开头 21072变量名无效 21073控制变量的名称无效:该名称已用于图标变量 21074图标变量的名称无效:该名称已用于控制变量 21075在错误的上下文中使用了一个标志性变量:应为控制变量或向量 21076在错误的上下文中使用了一个控制变量:需要一个标志性变量或一个向量 21077在错误的上下文中使用了一个标志性的向量变量:应为控制变量或单个值 21078控制向量变量在错误的上下文中使用:需要一个标志性变量或单个值 21080 For循环变量必须是数字 21081 for循环的步骤参数必须是数字 21082 for循环的结束参数必须是数字 21083变量名不能是保留表达式 21084案例标签值已经出现在开关块中 21085默认标签已出现在开关块中 21086无法确定变量的类型(找不到正确的类型定义) 21087无法确定变量的类型(找到冲突的类型定义) 21090已定义具有指定名称但类型不同的全局变量 21091访问未知全局变量 21092访问无效的全局变量 21093全局变量的名称无效:该名称已用于过程参数 21100访问错误表达式 21101表达式列表中的索引错误 21102空表达式 21103空表达式参数 21104表达式语法错误 21105表达式中的函数参数太少 21106表达式中的函数参数太多 21107表达式没有返回值 21108表达式的类型错误 21110表达式的类型错误:应为图标表达式 21112表达式的类型错误:应为控件表达式 21114表达式的向量维数错误 21116需要矢量表达式 21118应为单值或元组值表达式,而不是向量 应输入21120表达式 21121需要左值表达式 应输入21122变量 21123应为一元表达式 21124需要表达式列表 21125需要括号中的函数参数 21126需要一个括号中的函数参数 21127括号中应有两个函数参数 21128括号中应有三个函数参数 21129需要括号中有四个函数参数 21130需要括号中有五个函数参数 21131应为右括号“)” 21132需要右大括号“}” 21133应为右方括号“]” 21134找到不匹配的右括号“)” 21135找到不匹配的右大括号“}” 21136找到不匹配的右方括号“]” 21137应输入第二个条“|” 21138函数名应为
在所有类型上都定义了t1 == t2和t1!= t2。 如果两个元组具有相同的长度,并且每个索引位置上的所有数据项均相等,则它们是相等的(true)。 如果运算数具有不同的类型(整数和实数),则首先将整数值转换为实数。 字符串类型的值不能与数字混淆,即字符串值被认为不等于其他类型的值。
四个比较运算计算元组的字典序。在相同的索引位置上,类型必须相同,但是类型为integer、real和boolean的值会自动调整。字典顺序适用于字符串,布尔值false被认为小于boolean true(false8.5.11元素比较运算符

8.5.12布尔运算符

布尔运算and、xor、or和not只针对定义的长度为1的元组。如果两个操作数都为true(1),11和12被设为true(1),而如果两个操作数中有一个为真,11 xor12将返回的是真(1)。l1或l2如果至少有一个操作数为true(1),则返回true(1)。如果输入为false(0),则返回true(1),如果输入为true(1),则返回false(0)。8.5.13三角函数
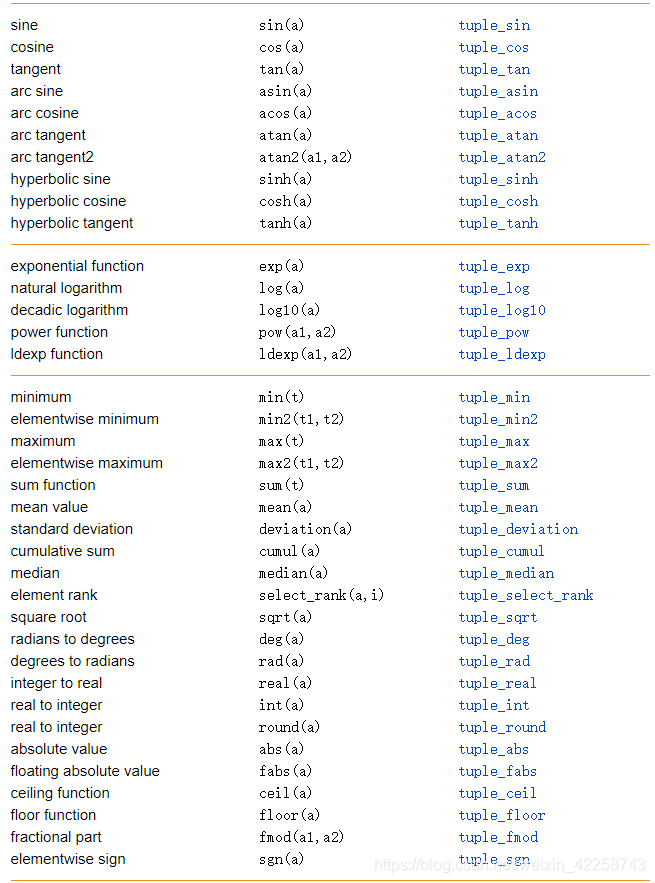
real类型。这些函数应用于所有元组值,结果元组与输入元组具有相同的长度。对于atan2,两个输入元组必须具有相同的长度。表8.20显示了所提供的三角函数。对于三角函数,角度用弧度表示。
8.5.14指数函数
整数或实数。然而,得到的类型将是实数。这些函数应用于所有元组值,结果元组与输入元组具有相同的长度。对于pow和ldexp,两个输入元组长度必须相等。所提供的指数函数见表8.21。
8.5.15数值函数
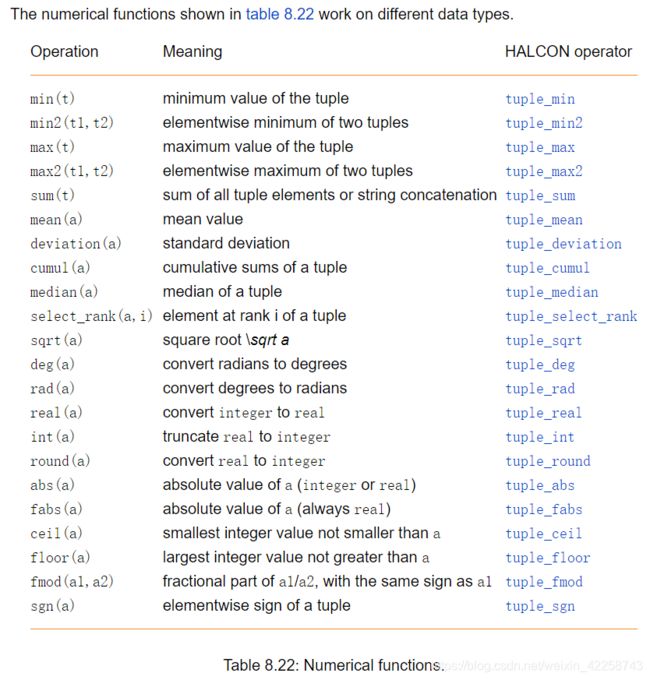
函数min和max选定元组的最小值和最大值。所有这些值要么是string类型,要么是integer/real类型。不允许将字符串与数值混合使用。如果至少有一个元素是实数,则结果值将为实数类型。如果所有元素都是integer类型,那么结果值也是integer类型。这同样适用于决定所有值的和的函数sum。如果输入参数是字符串,将使用字符串并置而不是加法。mean(均值)、deviation(偏差)、sqrt(根号下)、deg、rad、fabs、ceil、floor、fmod具有inter(整数)和real(实数);结果总是real型。mean(均值)函数计算的平均数和偏差的标准偏差的数字。sqrt(根号)下计算的是一个数的平方根。
cumul返回输入元组对应元素的不同累积和,median (中值)计算元组的中值。对于这两个函数,如果至少有一个元素是real类型,则结果值将为real类型。如果所有元素都是integer类型,那么结果值也是integer类型。select_rank返回第i级的元素,并对包含int整型或real实值的元组有效。索引i的类型是int。deg和rad分别将数值从弧度转换为角度,从角度转换为弧度。
下面的示例(文件名:euclid_distance.hdev)展示了一些数值函数的使用: V1 := [18.8,132.4,33,19.3]
V2 := [233.23,32.786,234.4224,63.33]
Diff := V1 - V2
Distance := sqrt(sum(Diff * Diff))
Dotvalue := sum(V1 * V2)
![]()
差和乘(平方)依次应用于两个向量的每个元素。然后sum计算平方和。然后计算和的平方根。之后由公式确定V1和V2的点积:

8.5.16其他功能

sort_index按升序对元组值进行排序,但与sort相反,它返回已排序值的索引位置(0…)。is_number对于integer或real类型的变量以及表示数字的string类型的变量都返回true。8.5.17操作优先级

8.6 向量
vector = "{" list "}" ;
list = tuplelist | objectlist | vectorlist ;
tuplelist = tuple, {",", tuple} ;
objectlist = object, {",", object} ;
vectorlist = vector, {",", vector} ;
tuple = "[" control "]" ;
control = string | integer | real | boolean ;
向量是通过提供一个逗号分隔的花括号中的元素列表来定义的。 vectorT := {[1], [2], [3]} // one-dimensional vector 一维向量
vectorT := {1, 2, 3} // tuples of length 1 do not require square brackets 长度为1的元组不需要方括号
t1 := 1
vectorT := {t1, t1 * 2, 3}
read_image (Image, 'clip')
threshold (Image, Region, 0, 63)
connection (Region, ConnectedRegions)
vectorO := {Image, Region, ConnectedRegions}
vectorV := {vectorT, {[4,5,6,7], [8,9]}}
.at( )和.insert( )运算符定义向量变量(见下文)
向量的元素列表也可以是空的,即,空向量{}如下例所示有效: vectorV2 := {{1,2}, {}}
vectorO2 := vectorO
vectorT2 := vectorT
vectorV2 := vectorV
vectorO2 := {}
vectorT2 := {}
vectorV2 := {}
.clear()运算符(请见下文)。另一方面,这意味着给变量赋空向量不足以定义变量的类型(参见第798页的“Variable Types变量类型”一节)。这样的变量将具有未定义的类型(因此是无效的),除非在程序的其他地方正确地定义了它的类型。 tuple := vectorT.at(0) // tuple := 1
region := vectorO.at(1) // region := Region
vector := vectorV.at(0) // vector := {[1,2,3]}
tuple := vectorV.at(1).at(1) // tuple := [8, 9]
.at()运算符还用于设置向量元素。允许写入不存在的向量元素。如果需要,向量会自动填充空元素。 vectorT.at(2) := 33 // vectorT := {[1], [2], [33]}
vectorE.at(4) := 'text' // vectorE := {[], [], [], [], 'text'}
for i:= 0 to 5 by 1
vecT.at(i) := gen_tuple_const(i,5)
endfor
.insert()运算符指定了索引位置和一个值。它将值从给定索引移到末尾一个位置,并将索引处的值设置为新值。
.remove()运算符执行相反的运算。它删除指定位置的值,并将后面的所有值移动到左侧。 vectorT.insert(1, 99) // vectorT := {[1], [99], [2], [33]}
vectorT.remove(2) // vectorT := {[1], [99], [33]}
vectorNew.insert(2, 3) // vectorNew := {[], [], [3]}
.concat()运算符并置两个相同类型和维数的向量。vectorC := vectorT.concat(vectorNew) // vectorC := {[1], [99], [33], [], [], [3]}
使用length()运算符查询向量元素的数量。 i := vectorT.length() // i := 3
j := vectorV.length() // j := 2
k := vectorV.at(0).length() // k := 3
.clear()运算符从相应的向量变量中删除所有元素。但是请注意,已清除的向量仍然保持其变量类型。 vectorT.clear()
* vectorT := vectorO // illegal: vectorT is a tuple vector
* vectorT := vectorV // illegal: vectorT is one-dimensional
.clear()、.insert()和.remove()是特殊的,因为它们修改输入向量。因此,它们只能在一个独立的程序语句(一个所谓的可执行表达式)中使用,而不能用于赋值或输入参数的表达式中。但是,允许在可执行表达式中链接多个修改向量运算符,例如:v := {1, 2, 3}
v.insert(1, 5).insert(2, 4).remove(0) // sets v to {5, 4, 2, 3}
运算符==和!=分别用于测试两个向量变量是否相等或不相等。
将向量转换为元组,反之亦然
可以使用便捷算子convert_vector_to_tuple将向量变量简化为元组。它将存储在输入向量中的所有元组值串联起来,并将它们存储在输出元组中。 convert_vector_to_tuple (vectorV, T) // T := [1, 2, 3, 4, 5, 6, 7, 8, 9]
convert_tuple_to_vector_1d将输入元组的元素存储为一维输出向量的单个元素。 convert_tuple_to_vector_1d (T, 1, V) // V := {[1],[2],[3],[4],[5],[6],[7],[8],[9]}
8.7 保留字

8.8控制流运算符
if ... endif
这个控制流结构有条件地执行一个代码块。操作符if接受一个条件作为其输入参数。如果条件为真,则执行主体。否则,在运算符endif后面的操作符继续执行。 if (<condition>)
...
endif
if ... else ... endif如果条件为真,则执行If和else之间的块。如果条件为假,则执行else和endif之间的部分。
要同时输入三个运算符,请在运算符窗口中选择运算符ifelse,并确保运算符旁边的复选框已勾选。if (<condition>)
...
else
...
endif
elseif
这个运算符类似于前面控制流结构的其他部分。但是,它允许测试附加条件。如果为假,为真,则执行elseif和endif之间的块。elseif后面可能跟着任意数量的其他elseif指令。最后的elseif后面可能跟一个单个的else指令。 if (<condition1>)
...
elseif (<condition2>)
...
endif
if (<condition1>)
...
else
if (<condition2>)
...
endif
endif
while ... endwhile
这是一个循环控制流结构。只要条件为真,就执行循环体。为了进入循环,条件首先必须为真。循环可以通过分别使用continue和break操作符重新启动和立即终止(见下文)。while (<condition>)
...
endwhile
repeat ... until
此循环与while循环类似,只是在循环结束时测试条件。因此,身一个repeat…until至少执行一次循环为止。与while循环相反的是,如果条件为假,则重复循环,直到它最终成真。 repeat
...
until (<condition>)
for ... endfor
for循环由一个开始值、一个结束值和一个增量值控制,接着该值决定了循环的步骤数。这些值也可以是表达式,在进入循环之前对其求值。表达式也可以是integer型或real型。如果所有的输入值都是integer型,那么循环变量也将是integer型。在所有其他情况下,循环变量的将是real型。 for <index> := <start> to <end> by <step>
...
endfor
for i := 1 to 5 by 1
j := i
endfor
for i := 5 to 1 by -1
j := i
endfor
循环可以通过分别使用continue和break操作符重新启动和立即终止。(见下文)。old_x := 0
old_y := 0
dev_set_color ('red')
dev_set_part(0, 0, 511, 511)
for x := 1 to 511 by 1
y := sin(x / 511.0 * 2 * 3.1416 * 3) * 255
disp_line (WindowID, -old_y+256, old_x, -y+256, x)
old_x := x
old_y := y
endfor
continue
运算符continue强制执行for、while或repeat循环的下一个循环。测试循环条件,并根据测试结果执行循环。 i := |Images|
while (i)
Image := Images[i]
count_channels (Image, Channels)
if (Channels != 3)
continue
endif
* extensive processing of color image follows
endwhile
break
break运算符允许您退出for、while和repeat循环。然后,程序在循环结束后的下一行继续。 Number := |Regions|
AllRegionsValid := 1
* check whether all regions have an area <= 30
for i := 1 to Number by 1
ObjectSelected := Regions[i]
area_center (ObjectSelected, Area, Row, Column)
if (Area > 30)
AllRegionsValid := 0
break ()
endif
endfor
while (1)
grab_image (Image, FGHandle)
dev_error_var (Error, 1)
dev_set_check ('~give_error')
get_mposition (WindowHandle, R, C, Button)
dev_error_var (Error, 0)
dev_set_check ('give_error')
if ((Error = H_MSG_TRUE) and (Button != 0))
break ()
endif
endwhile
switch ... case ... endswitch
开关块允许通过多路分支控制程序流。分支目标用case语句指定,后跟一个整数常量。根据整型控制值,程序执行跳转到匹配的case语句,并继续执行下一个break语句或结束endswitch语句。可选的default语句可以定义为开关块中的最后一个跳转标签。如果前面没有case语句与控件表达式匹配,则程序执行将跳转到默认标签。 ...
switch (Grade)
case 1:
Result := 'excellent'
break
case 2:
Result := 'good'
break
case 3:
Result := 'acceptable'
break
case 4:
case 5:
Result := 'unacceptable'
break
default:
Result := 'undefined'
endswitch
...
stop
执行运算后,运算符停止会停止程序。 可以通过按Step Over或Run按钮继续执行程序。exit
退出运算终止HDevelop会话。return
运算符返回从当前过程调用返回到调用过程。如果在主程序中调用return,则PC会跳到程序的末尾,即程序结束。try ... catch ... endtry
这种控制流结构支持HDevelop中的动态异常处理。监视try和catch运算符之间的程序块是否有异常,即运行时错误。如果发生异常,有关导致异常的诊断数据存储在异常元组中。异常元组被传递给catch运算符,程序从那里继续执行。catch和endtry之间的程序块用于分析异常数据并对其作出相应的反应。如果没有发生异常,则不会执行此程序块。throw
运算符throw允许生成用户定义的异常。8.9 错误处理
1)跟踪操作员调用的返回值(错误代码)
2)使用异常处理8.9.1跟踪运算符调用的返回值
dev_set_check('~give_error')
然后HDevelop将忽略程序中的任何错误。因此,程序员必须处理错误处理。每个运算符调用都提供一个返回值(或错误代码),该值指示执行的成功或失败。可以通过指定的错误变量访问此错误代码:dev_error_var(ErrorCode, 1)
此运算符调用实例化变量ErrorCode。它存储最后执行的运算符的错误代码。使用此错误代码,程序可以将其进一步的流程依赖于操作的成功。 ...
if (ErrorCode != H_MSG_TRUE)
* react to error
endif
* continue with program
...
get_error_text获得。这在向程序用户报告错误时非常有用。 global tuple ErrorCode
dev_error_var(ErrorCode, 1)
...
8.9.2异常处理
dev_set_check('give_error')
此外,HDevelop可以配置为允许用户选择是否抛出异常,或者自动抛出异常。此行为在“首选项”选项卡“常规选项”->“经验丰富的用户”中设置。dev_get_exception_data提供对异常元组元素的访问。 ...
try
* start block of watched program lines
...
catch(Exception)
* get error code
ErrorCode := Exception[0]
* react to error
endtry
* program continues normally
...
8.10并行执行
8.10.1启动子线程
par_start
此调用在后台启动假设算子gather_data()作为新的子线程,并继续执行后续的程序行。线程ID在变量ThreadID中返回,该变量必须在尖括号中指定。请注意par_start不是一个实际的运算符,而只是一个修改调用行为的限定符。因此,无法在操作员窗口中选择par_start。
支持在一个循环中启动多个线程。在这种情况下,需要收集线程ID,以便以后可以引用所有线程: ThreadIDs := []
for Index := 1 to 5 by 1
par_start <ThreadID> : gather_data()
ThreadIDs := [ThreadIDs, ThreadID]
endfor
for Index := 1 to 5 by 1
par_start <ThreadIDs.at(Index - 1)> : gather_data()
endfor
for Index := 1 to 5 by 1
par_start <ThreadIDs.at(Index - 1)> : gather_data(Result) // BEWARE!!!
endfor
for Index := 1 to 5 by 1
par_start <ThreadIDs.at(Index - 1)> : gather_data(Result.at(Index - 1))
endfor
8.10.2等待子线程完成
par_start <ThreadID> : count_objects(num)
...
for i := 1 to num by 1 // BEWARE: num might be uninitialized
...
endfor
par_start <ThreadID> : count_objects(num)
...
par_join(ThreadID)
for i := 1 to num by 1
...
endfor
convert_vector_to_tuple(ThreadIDs, Threads)
par_join(Threads)
8.10.3在HDevelop中执行线程
for Index := 0 to 4 by 1
par_start <ThreadIDs.at(Index)> : gather_data()
endfor
...
convert_vector_to_tuple (ThreadIDs, Threads)
par_join (Threads)
...
ThreadIDs := {}
Threads := []
8.10.4检查线程
for Index:= 1 to 5 by 1
par_start <ThreadIDs.at(Index - 1)> : wait_seconds(Index)
endfor
wait_seconds(2)
stop()

Figure 8.4: Inspecting threads.
线程视图列出了表中所有线程的属性。 每个线程第一列中的状态图标显示当前的执行状态。 当前选择的线程(1)在状态图标中用黄色箭头标记,并且也以粗体突出显示。 其他五个线程是从主线程开始的子线程。 要选择另一个线程,请在线程视图中双击它。 这还将根据所选线程更新PC,调用堆栈和变量。 所选线程的活动过程将显示在程序窗口中。

在包含par_start的程序行上单步执行将初始化相应的线程,而无需实际启动它。 要调试特定线程,请在PC处于相应的par_start行时按F7键。 这将自动使新的子线程成为所选线程。 如果PC已经超过调用行,请首先在线程视图窗口中选择线程。 如果线程是通过过程调用启动的,这将自动在程序窗口中显示正确的过程,并且PC会显示在第一行。 对于像上述示例中那样由操作员调用启动的线程,PC将位于相应的调用上,而程序的其余部分将显示为灰色(见图8.5)。 程序窗口中的通知行(1)显示所选子线程的线程ID,并允许快速访问线程视图窗口(2)。 单击(3)切换回主线程。
图8.5:程序窗口中的选定子线程8.10.5暂停和恢复线程
8.11 HDevelop元组操作摘要


8.12 HDevelop错误代码