轻量级神经网络:ShuffleNetV1到ShuffleNetV2
论文名:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文地址:https://arxiv.org/abs/1707.01083v1
CVPR:2017
论文名:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
论文地址:https://arxiv.org/abs/1807.11164
会议:ECCV2018
大规模的神经网络和小规模的神经的网络的之间有什么区别? 为什么有了大规模神经网络的精度后还要去研究小规模的神经网络呢?(大网络:存储空间,GPU,机房,散热、成本高)
主要包括三部分:FLOPs、Practical Guidelines、ShuffleNet V2
摘要
目前,网络架构设计主要由**计算复杂度的间接度量(如FLOPs)**测量。然而,直接度量(例如,速度)还取决于诸如存储器访问成本和平台特性的其他因素。因此,这项工作建议评估目标平台上的直接度量,而不仅仅考虑FLOPs。基于一系列对照实验,这项工作为高效的网络设计提供了几个实用指南。此外,提出了一种称为ShuffleNetV2的新架构。利用消融实验验证了我们的模型在速度和准确度方面是最好的。
一、FLOPs

FLOPS: 全大写,指每秒浮点运算次数,可以理解为计算的速度。是衡量**硬件性能**的一个指标。(硬件)
FLOPs: s小写,指浮点运算数,理解为计算量。可以用来衡量**算法/模型**的复杂度。(模型) 在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)
感兴趣的可以移步CNN模型所需的计算力(flops)和参数(parameters)数量是怎么计算的? - 知乎
https://www.zhihu.com/question/65305385
在此推荐一个神器(pytorch):torchstat
https://github.com/Swall0w/torchstat
可以用来计算pytorch构建的网络的参数,空间大小,MAdd,FLOPs等指标,简单好用。
比如:我想知道alexnet的网络的一些参数。
只需要:
from torchstat import stat
import torchvision.models as models
model = model.alexnet()
stat(model, (3, 224, 224))
作者认为FLOPs是一种间接的测量指标,是一个近似值,并不是我们真正关心的。我们需要的是直接的指标,比如速度和延迟。


图c是经典小网络在GPU上的MFLOPs与速度(Batches/sec)的关系。 图d是经典小网络在ARM上的MFLOPs与速度(Batches/sec)的关系。
我们可以发现,具有相似的FLOPs的网络,执行的速度却不一样。有的相差还挺大。
作者在此提出了第一个观点:因此,使用FLOP作为计算复杂度的唯一指标是不充分的。
理由:1) FLOPs没有考虑几个对速度有相当大影响的重要因素。 2)计算平台的不同。
1) FLOPs没有考虑几个对速度有相当大影响的重要因素:MAC和并行度
MAC(内存访问成本),计算机在进行计算时候要加载到缓存中,然后再计算,这个加载过程是需要时间的。其中,分组卷积(group convolution)是对MAC消耗比较多的操作。
并行度,在相同的FLOPs下,具有高并行度的模型可能比具有低并行度的另一个模型快得多。如果网络的并行度较高,那么速度就会有显著的提升。
2)计算平台的不同
不同的运行平台,得到的FLOPs也不相同。有的平台会对操作进行优化,比如:cudnn加强了对3×3conv计算的优化。这样一来,不同平台的FLOPs大小确实没有什么说服力。
效率对比准则
提出了2个网络执行效率对比的设计准则:
1 使用直接度量方式如速度代替FLOPs。
2 要在目标计算平台上计算,不然结果不具有代表性。
二、高效网络设计实用指南(Practical Guidelines)
分析对比两个具有代表性的最先进网络的运行时性能(ShuffleNetV1,MobileNetV2)。
分别在GPU和CPU上去对ShuffleNetV1,MobileNetV2的运行时间进行了测试
GPU使用单个NVIDIA GeForce GTX 1080Ti。卷积库是CUDNN 7.0。
CPU使用高通骁龙 810.
测试结果如下:
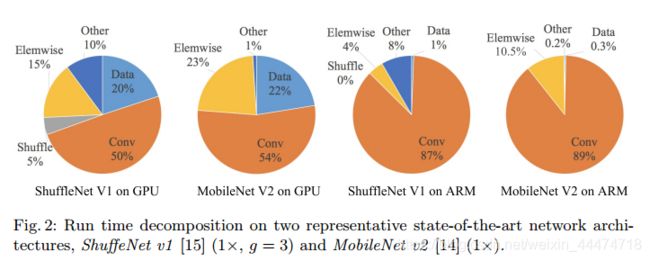
可以看到,整个运行时被分解用于不同的操作。处理器在运算的时候,不光只是进行卷积运算,也在进行其他的运算,特别是在GPU上,卷积运算只占了运算时间的一般左右。
我们将卷积部分认为是FLOPs操作。虽然这部分消耗的时间最多,但其他操作包括数据IO,数据混洗和逐元素操作(AddTensor,ReLU等)也占用了相当多的时间。因此,再次确认了模型使用FLOPs指标对实际运行时间的估计不够准确。
基于这一观察,作者从几个不同的方面对运行时间(或速度)进行了详细分析,并为高效的网络架构设计提出了几个实用指南。
推出了四个高效网络设计指南,这些指南不仅仅考虑了FLOP。
a、输入输出具有相同channel的时候,内存消耗是最小的
可以看出当c1和c2比例越接近时,速度越快,尤其是在c1:c2比例为1:1时速度最快。这与a所提出的当c1和c2相等时MAC达到最小值相所对应。
b、过多的分组卷积操作会增大MAC,从而使模型速度变慢
之前有提到,分组卷积操作会减少参数,这样一来网络的计算量也就减少了。但是呢,认为网络的计算量减少,不代表模型的速度也会减少。MAC主要的消耗来源就来自分组卷积,分组卷积一多,MAC消耗的越多,模型速度也就变慢了。
很清楚的看到,g越小,速度越快。因此,作者建议应根据目标平台和任务仔细选择组号。虽然组卷积能增加模型的准确度,但是作者认为盲目使用较大的组号是不明智的,因为这将会使得计算成本增加带来的缺点大于准确度增加带来的优点
c、模型中的分支数量越少,模型速度越快
作者认为,模型中的网络结构太复杂(分支和基本单元过多)会降低网络的并行程度,模型速度越慢。

结果: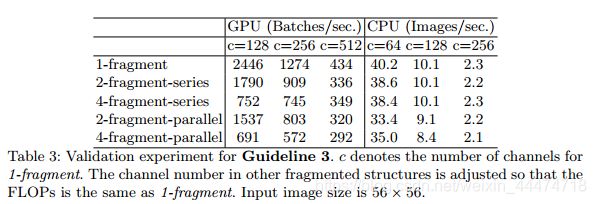
其中, 2-fragment-series表示一个block中有2个卷积层串行,也就是简单的叠加; 4-fragment-parallel表示一个block中有4个卷积层并行,类似Inception的整体设计。 可以看出在相同FLOPs的情况下,单卷积层(1-fragment)的速度最快。
d、Element-wise操作不能被忽略
Element-wise包括Add/Relu/short-cut/depthwise convolution等操作。
元素操作类型操作虽然FLOPs非常低,但是带来的时间消耗还是非常明显的,尤其是在GPU上。元素操作操作虽然基本上不增加FLOPs,但是所带来的时间消耗占比却不可忽视。也即Small FLOPs heavy MAC。
总结:
G1 卷积层使用相同的输入输出通道数。
G2 注意到使用大的分组数所带来的坏处。
G3 减少分支以及所包含的基本单元。
G4 减少Element-wise操作。
三、ShuffleNet V2
在shufflenetV1的基础上进行修改,得到了shuffleNetV2。首先,简要的回顾一下V1,看看V1的网络结构中有什么地方违反了四条设计指南,再进行修改。
shuffleNet在resnext单元基础上进行改进。下图所示:
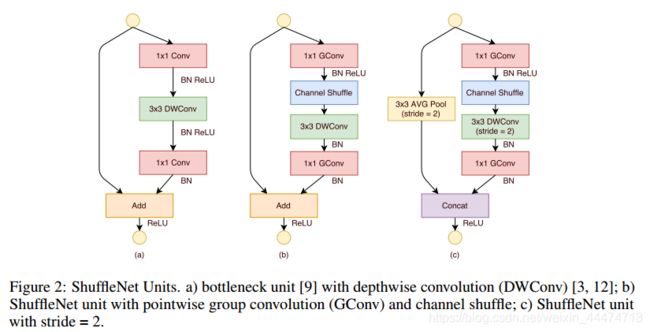
shuffleNet主要拥有两个创新点:
(1)pointwise group convolution 逐点分组卷积
(2)channel shuffle
原因:
1。逐点卷积占了很大的计算量————> 逐点分组卷积
2。不同组之间特征通信问题 ————> channel shuffle
逐点组卷积,就是带分组的卷积核为1×1的卷积,也就是说逐点组卷积是卷积核为1×1的分组卷积。
于是shuffleNetV1从最初的a到了b。首先用带group的1×1卷积代替原来的1×1卷积,同时跟一个channel shuffle操作。然后是3×3 dwc,然后去掉了两个ReLU层,这个在Xception和mobileNetV2中有所介绍。
V1有何不好?
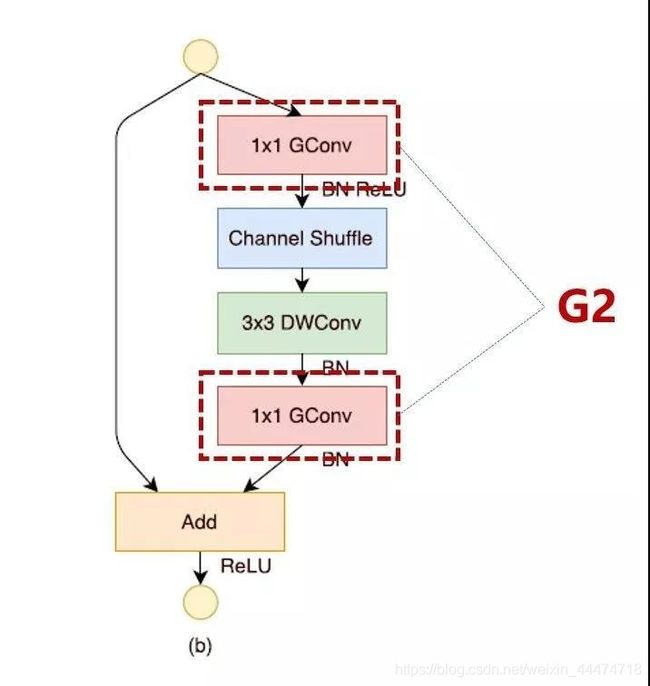
如第二节的结论所述,逐点组卷积增加了MAC违背了G2。这个成本不可忽视,特别是对于轻量级模型。另外,使用太多分组也违背了 G3。

瓶颈结构违背了G1与多单位违背了G3。
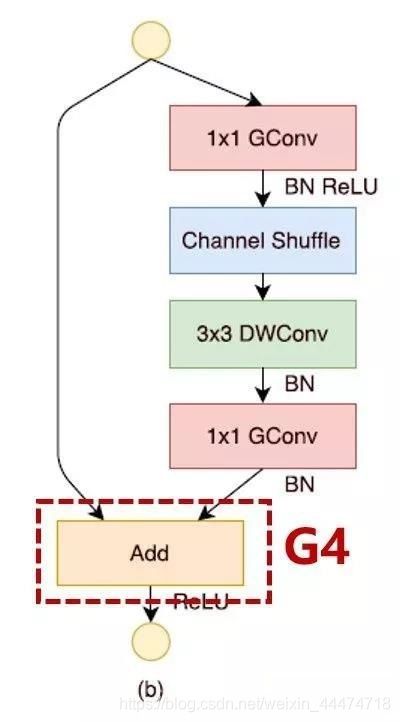
为了实现较高的模型容量和效率,关键问题是如何保持大量且同样宽的通道,既没有密集卷积也没有太多的分组Add操作是元素级加法操作也不可取违反了G4。因此,为了实现较高的模型容量和效率,关键问题是如何保持大量且同样宽的通道,既没有密集卷积也没有太多的分组。
为此,作者引入了channel split
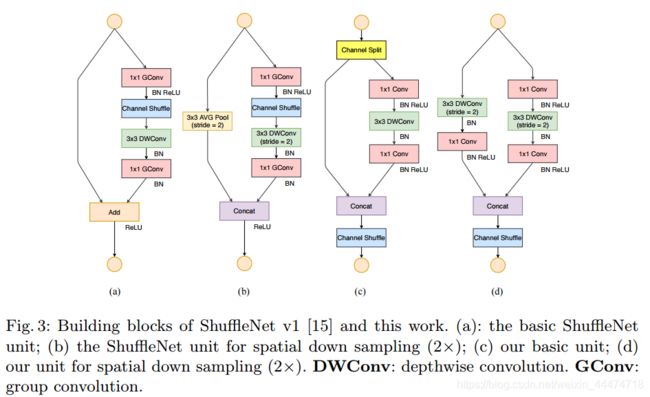
a图是V1,c图是V2。
1.在每个单元的开始,通过Channel split将c特征通道的输入被分为两支,分别带有 c−c’ 和c’个通道。按照准则G3,一个分支的结构仍然保持不变。另一个分支由三个卷积组成, 为满足G1,令输入和输出通道相同。与 ShuffleNet V1 不同的是,两个 1×1 卷积不再是组卷积(GConv),因为Channel Split分割操作已经产生了两个组。
2.卷积之后,把两个分支拼接(Concat)起来,从而通道数量保持不变 (G1),而且也没有Add操作(element-wise操作)(G4)。然后进行与ShuffleNetV1相同的Channel Shuffle操作来保证两个分支间能进行信息交流。
3.depthwise convolution保留
上述构建模块被重复堆叠以构建整个网络,被称之为 ShuffleNet V2。基于上述分析,本文得出结论:由于对上述四个准则的遵循,shuffleNetV2架构设计非常的高效。
总结:
