深度学习中的轻量级网络架构总结与代码实现
点击上方,选择星标或置顶,不定期资源大放送 !
!
阅读大概需要10分钟
Follow小博主,每天更新前沿干货


导读
目前在深度学习领域主要分为两类,一派为学院派(Researcher),研究强大、复杂的模型网络和实验方法,旨在追求更高的性能;另一派为工程派(Engineer),旨在将算法更稳定、更高效的落地部署在不同硬件平台上。
因此,针对这些移动端的算力设备,如何去设计一种高效且精简的网络架构就显得尤为重要。从2017年以来,已出现了很多优秀实用的轻量级网络架构, 但是还没有一个通用的项目把这些网络架构集成起来。本项目可以作为一个即插即用的工具包,通过直接调用就可以直接使用各类轻量级网络结构。
本项目主要提供一个移动端网络架构的基础性工具,避免大家重复造轮子,后续我们将针对具体视觉任务集成更多的移动端网络架构。希望本项目既能让深度学习初学者快速入门,又能更好地服务科研学术和工业研发社区。
(欢迎各位轻量级网络科研学者将自己工作的核心代码整理到本项目中,推动科研社区的发展,我们会在readme中注明代码的作者~)
后续将持续更新模型轻量化处理的一系列方法,包括:剪枝,量化,知识蒸馏等等
Github地址:https://github.com/murufeng/awesome_lightweight_networks https://github.com/murufeng/awesome_lightweight_networks
https://github.com/murufeng/awesome_lightweight_networks
项目目录

MobileNets系列
本小节主要汇总了基于Google 提出来的适用于手机端的网络架构MobileNets的系列改进,针对每个网络架构,我将主要总结每个不同模型的核心创新点,模型结构图以及代码实现.
MobileNetV1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
-
论文地址:https://arxiv.org/abs/1704.04861
MobileNetv1模型是Google针对移动端设备提出的一种轻量级的卷积神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积)。具体结构如下所示:
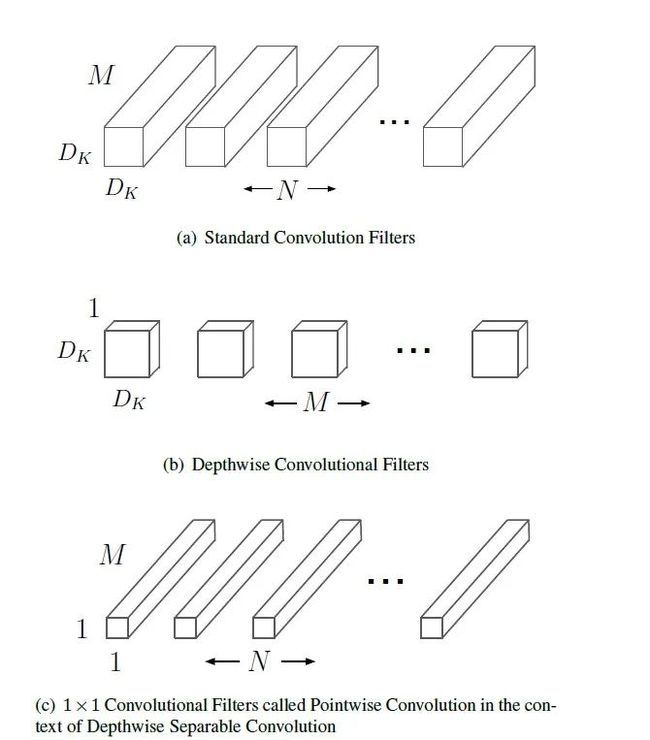
-
代码实现
import torch
from light_cnns import mbv1
model = mbv1()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())MobileNetv2
MobileNetV2: Inverted Residuals and Linear Bottlenecks
-
论文地址:https://arxiv.org/abs/1704.04861
mobilenetv2 沿用特征复用结构(残差结构),首先进行Expansion操作然后再进行Projection操作,最终构建一个逆残差网络模块(即Inverted residual block)。
-
增强了梯度的传播,显著减少推理期间所需的内存占用。
-
使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性。
-
在经过projection layer转换到低维空间后,将第二个pointwise convolution后的 ReLU6改成Linear结构,保留了特征多样性,增强网络的表达能力(Linear Bottleneck)
网络模型结构如下:
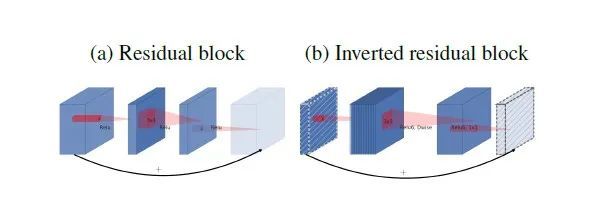
-
代码实现
import torch
from light_cnns import mbv2
model = mbv2()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())MobileNetv3
Searching for MobileNetV3
-
论文地址:https://arxiv.org/abs/1905.02244
核心改进点:
-
网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好)
-
论文推出两个版本:Large 和 Small,分别适用于不同的场景;
-
继承了MobileNetV1的深度可分离卷积
-
继承了MobileNetV2的具有线性瓶颈的倒残差结构
-
引入基于squeeze and excitation结构的轻量级注意力模型(SE)
-
使用了一种新的激活函数h-swish(x)
-
网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt 算法获得卷积核和通道的最佳数量
-
修改了MobileNetV2网络后端输出head部分;
具体网络结构如下:
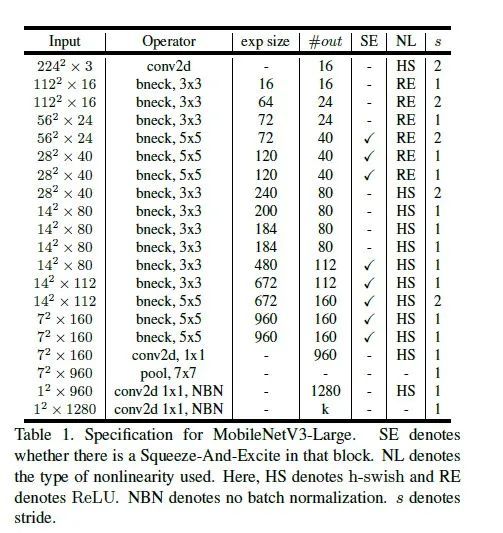
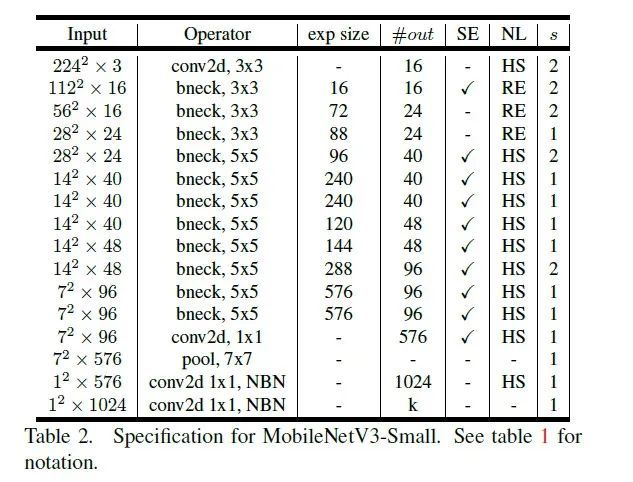
-
代码实现
import torch
from light_cnns import mbv3_small
#from light_cnns import mbv3_large
model_small = mbv3_small()
#model_large = mbv3_large()
model_small.eval()
print(model_small)
input = torch.randn(1, 3, 224, 224)
y = model_small(input)
print(y.size())MobileNext
Rethinking Bottleneck Structure for Efficient Mobile Network Design
- 论文地址:https://arxiv.org/abs/2007.02269
针对MobileNetV2的核心模块逆残差模块存在的问题进行了深度分析,提出了一种新颖的SandGlass模块,它可以轻易的嵌入到现有网络架构中并提升模型性能。Sandglass Block可以保证更多的信息从bottom层传递给top层,进而有助于梯度回传;执行了两次深度卷积以编码更多的空间信息。
网络模型结构如下:

-
代码实现
import torch
from light_cnns import mobilenext
model = mobilenext()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())ShuffleNet系列
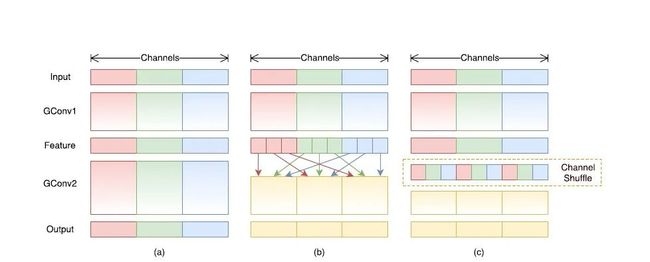
ShuffleNetv1
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
-
论文地址: https://arxiv.org/abs/1707.01083
网络模型结构如下:
-
代码实现
import torch
from light_cnns import shufflenetv1
model = shufflenetv1()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
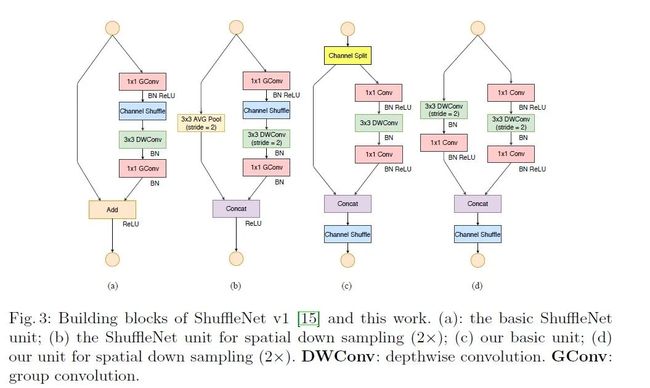
print(y.size())ShuffleNetv2
-
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
-
论文地址 : https://arxiv.org/abs/1807.11164
网络模型结构如下:
import torch
from light_cnns import shufflenetv2
model = shufflenetv2()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())华为诺亚轻量级网络系列
AdderNet:Do We Really Need Multiplications in Deep Learning?
一种几乎不包含乘法的神经网络。不同于卷积网络,本文使用L1距离来度量神经网络中特征和滤波器之间的相关性。由于L1距离中只包含加法和减法,神经网络中大量的乘法运算可以被替换为加法和减法,从而大大减少了神经网络的计算代价。此外,该论文还设计了带有自适应学习率的改进的梯度计算方案,以确保滤波器的优化速度和更好的网络收敛。在CIFAR和ImageNet数据集上的结果表明AdderNet可以在分类任务上取得和CNN相似的准确率。
网络模型结构如下:

import torch
from light_cnns import resnet20
model = resnet20()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())GhostNet:More Features from Cheap Operations
-
论文地址:https://arxiv.org/abs/1911.11907
简介
该论文提供了一个全新的Ghost模块,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列线性变换,以很小的代价生成许多能从原始特征发掘所需信息的“幻影”特征图(Ghost feature maps)。该Ghost模块即插即用,通过堆叠Ghost模块得出Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在ImageNet分类任务,GhostNet在相似计算量情况下Top-1正确率达75.7%,高于MobileNetV3的75.2%
网络模型结构如下:

代码实现
import torch
from light_cnns import ghostnet
model = ghostnet()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())轻量级注意力网络架构
Coordinate Attention for Efficient Mobile Network Design
-
论文地址:https://arxiv.org/abs/2103.02907

针对如何有效提升移动网络的卷积特征表达能力以及通道注意力(如SE)机制能够有效建模通道间相关性但忽视了位置信息的问题,本文提出了一种新颖的注意力机制:Coordinate Attention,它通过提取水平与垂直方向的注意力特征图来建模通道间的长距离依赖关系,而且水平与垂直注意力还可以有效地提供精确的空间位置信息。
Code
import torch
from light_cnns import mbv2_ca
model = mbv2_ca()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())精彩内容待更新
欢迎大家follow和star该项目地址,我们会持续跟踪前沿论文工作,若项目在复现和整理过程中有任何问题,欢迎大家在issue中提出!
Github地址:https://github.com/murufeng/awesome_lightweight_networks