大二C语言总结
前言
Linux C语言2020大二上半学期总结,整理到吐血
内存管理
- 整数页为4096 = 4K
-
进程和程序
- 程序 - 硬盘上的可执行文件
- 进程 - 在内存中运行的程序
-
进程中的内存区域划分
- –代码区-来存放可执行文件的操作指令-不可写的
- –只读常量区- 存放字符串常量,以及const修饰的全局变量
- –全局区/数据区 - 存放已经初始化的全局变量和static修饰的局部变量
- –BSS段- 存放没有初始化的全局变量和静态局部变量,该区域会在main函数执行之前进行自动清零
- –堆区 - 使用malloc/calloc/realloc/free函数处理的内存,该区域的内存需要程序员手动申请和手动释放
- –栈区 - 存放局部变量、形参、const修饰的局部变量,以及块变量,该区域的内存由操作系统负责分配和回收,程序员尽管放心使用即可
-
总结
-
–按照地址从小到大进行排列,进程中的内存区域依次为:代码区、只读常量区、全局区/数据区、BSS段、 堆区、栈区
-
–其中代码区和只读常量区一般统称为代码区;其中全局区/数据区和BSS段一般统称为全局区/数据区
-
–栈区和堆区之间并没有严格的分割线,可以进行微调,并且堆区的分配一般按照地址从小到大进行,而栈区的分配一般按照地址从大到小进行分配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t53oGpVP-1615732028953)(http://img.wangzun233.top/uc00.png)]
-
地址分类
•物理地址:
也就是内存单元的实际地址,用于芯片级内存单元寻址。 物理地址也由32位无符号整数表示。
•逻辑地址:
程序代码经过编译后出现在 汇编程序中地址。每个逻辑地址都由一个段和偏移量组成。
•线性地址(虚拟地址):
在32位CPU架构下,可以表示4G的地址空间,用16进制表示就是0x00000000—0Xffff ffff
寄存器
•16位处理器:即80386之前的系列,一般以8086为代表,8086 CPU 中寄存器总共为 14 个,且均为 16 位 。
•32位处理器:以80386为代表,除了段寄存器位数仍为16位之外,其他的寄 存器都为32位,同时新增FS,GS两个段寄存器,即:
–4个数据寄存器(EAX、EBX、ECX和EDX)
–2个变址和指针寄存器(ESI和EDI)
–2个指针寄存器(ESP和EBP)
–6个段寄存器(ES、CS、SS、DS、FS和GS)
–1个指令指针寄存器(EIP)
–1个标志寄存器(EFlags)
ALU
•算术逻辑单元 (Arithmetic Logic Unit, ALU)是中央处理器(CPU)的执行单元,是所有中央处理器的核心组成部分,基本操作包括加、减、乘、除四则运算,与、或、非、异或等逻辑操作,以及移位、比较和传送等操作.我们通常说的一个CPU是16位或者是32位,指的是ALU 的宽度,即字长,它是CPU在同一时间内能处理的二进制的位数。字长反映了CPU的计算精度。
三大总线
•数据总线DB:
用于传送数据信息。数据总线是双向三态形式的总线,即他既可以把CPU的数据传送到存储器或I/O接口等其它部件,也可以将其它部件的数据传送到CPU。
•地址总线AB:
是专门用来传送地址的,由于地址只能从CPU传向外部存储器或I/O端口,所以地址总线总是单向三态的,这与数据总线不同。地址总线的位数决定了CPU可直接寻址的内存空间大小。一般来说,若地址总线为n位,则可寻址空间为2^n字节。
•控制总线CB:
用来传送控制信号和时序信号。控制信号中,有的是微处理器送往存储器和I/O接口电路的,也有是其它部件反馈给CPU的,因此,控制总线的传送方向由具体控制信号而定,一般是双向的,控制总线的位数要根据系统的实际控制需要而定。
虚拟内存
•每个进程的用户空间都是完全独立、互不相干的。不信的话,你可以把上面的程序同时运行10次(当然为了同时运行,让它们在返回前一同睡眠100秒吧),你会看到10个进程占用的线性地址一模一样。
•本质上说,虚拟内存地址剥夺了应用程序自由访问物理内存地址的权利。进程对物理内存的访问,必须经过操作系统的审查。只要操作系统把两个进程的进程空间对应到不同的内存区域,就让两个进程空间成为“老死不相往来”的两个小王国。两个进程就不可能相互篡改对方的数据,进程出错的可能性就大为减少。
•另一方面,有了虚拟内存地址,内存共享也变得简单。操作系统可以把同一物理内存区域对应到多个进程空间。共享库也是类似。对于任何一个共享库,计算机只需要往物理内存中加载一次,就可以通过操纵对应关系,来让多个进程共同使用
地址转换
•逻辑地址经段机制转化成线性地址;线性地址又经过页机制转化为物理地址。
•在 8086 的实模式下, 通过(段基址:段偏移量)计算出内存单元的物理地址,在IA32的保护模式下,这个逻辑地址不是被直接送到内存总线而是被送到内存管理单元(MMU)。MMU由一 个或一组芯片组成, 其功能是把逻辑地址映射为物理地址,即进行地址转换,如图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XWOzkg89-1615732028957)(http://img.wangzun233.top/uc01.png)]
实模式(16位处理器寻址)
•早期8088CPU时期.当时由于CPU的性能有限,一共只有20位地址线(地址空间只有1MB),但是一个尴尬的问题出现了,ALU的宽度只有16位,也就是说ALU不能计算20位的地址。为了解决这个问题,分段机制被引入.为了构成20位的主存地址,8088处理器设置了4个段寄存器以及8个通用寄存器,每个寄存器都是16位的,同时访问内存的指令中的地址也是16位的,当某个指令想要访问某个内存地址时,它通常需要用(段基址:段偏移量)这种格式来表示。这样就形成一个20位的实际地址,也就实现了从16位内存地址到20位实际地址的转换,或者叫“映射”。
malloc 函数
char*a=NULL;
a=(char*)malloc(100*sizeof(char));
free(a);
malloc函数详解
•使用malloc函数申请内存时,除了申请所需要的内存大小之外,可能还会申请额外的12个字节,用于存储一些管理内存的相关信息,比如内存的大小等等。使用malloc申请的内存,一定要注意不要对所申请的内存空间进行越界访问,避免造成数据结构的破坏。
•一般来说,使用malloc申请比较小的动态内存时,操作系统会一次性分配33个内存页的大小,最终的目的就是为了提高效率而已。
•可以使用命令cat /proc/查看某个进程占用的内存区域。 (pid是进程号,proc下的各个进程目录占磁盘大小都是0,因为其数据都存在于内存,该文件只是一个映射,并且maps文件中的内存地址为已经映射了物理内存的虚拟内存地址)
•每行数据格式如下:
•(内存区域)开始-结束 访问权限 偏移 主设备号:次设备号 i节点 文件。
注意,你一定会发现进程空间只包含三个内存区域,似乎没有上面所提到的堆、bss等,其实并非如此,程序内存段和进程地址空间中的内存区域是种模糊对应,也就是说,堆、bss、数据段(初始化过的)都在进程空间中由数据段内存区域表示
free详解
•使用free函数释放动态内存 一般来说,使用malloc申请比较大的的内存时,系统会分配34个内存页,当所申请的内存超过34个内存页时,系统会再次分配33个内存页(也就是按照33个内存页为基本单位分配) 而对于使用free释放内存时,则释放多少就减少多少,当使用free释放完毕所有内存时,系统可能会保留33个内存页以备再次申请使用,以此提高效率。
获取进程ID号
- •./可运行文件
& Ps –aux- 在程序中加入
#includegetpid()
#include size命令
•使用命令size查看程序的内存分配情况:
• size a.out
•text(代码区) data(数据区) bss(BSS段) dec(十进制的总和) hex(十六进制的总和) filename(文件名)
文件
•在Unix/linux系统中,几乎所有的一切都可以看作文件,因此,对于文件的操作适用于各种输入输出设备等等,当然目录也可以看作文件。一切皆文件。
•开发者仅需要使用一套 API 和开发工具即可调取 Linux 系统中绝大部分的资源•在Unix/linux系统中,几乎所有的一切都可以看作文件,因此,对于文件的操作适用于各种输入输出设备等等,当然目录也可以看作文件。一切皆文件。
•开发者仅需要使用一套 API 和开发工具即可调取 Linux 系统中绝大部分的资源
文件的分类
-
普通文件:Linux中最多的一种文件类型, 包括纯文本文件、二进制文件(binary);数据格式的文件(data);各种压缩文件.第一个属性为 [-]
-
目录文件就是目录, 能用 # cd 命令进入的。第一个属性为 [d],例如 [drwxrwxrwx]
-
块设备文件 : 就是存储数据以供系统存取的接口设备,简单而言就是硬盘。例如一号硬盘的代码是 /dev/hda1等文件。第一个属性为 [b]
-
字符设备文件:即串行端口的接口设备,例如键盘、鼠标等等。第一个属性为 [c]
-
套接字文件这类文件通常用在网络数据连接。可以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信。第一个属性为 [s],最常在 /var/run目录中看到这种文件类型
-
管道文件FIFO也是一种特殊的文件类型,它主要的目的是,解决多个程序同时存取一个文件所造成的错误。FIFO是first-in-first-out(先进先出)的缩写。第一个属性为 [p]
-
链接文件类似Windows下面的快捷方式。第一个属性为 [l],例如 [lrwxrwxrwx]
文件操作函数
fopen()/fclose()/fread()/fwrite()/fseek()
文件描述符
–文件描述符是内核为了高效管理已被打开的文件所创建的索引,用于指向被打开的文件,所有执行I/O操作的系统调用都通过文件描述符;文件描述符是一个简单的非负整数,用以表明每个被进程打开的文件
-
内核缺省为每个进程打开三个文件描述符:
-
stdin,标准输入,默认设备是键盘,文件编号为0
-
stdout,标准输出,默认设备是显示器,文件编号为1,也可以重定向到文件
-
stderr,标准错误,默认设备是显示器,文件编号为2,也可以重定向到文件
-
ll /proc/11990/fd – 查看所有文件打开的文件描述符
open函数
–#include
–#include
–#include
–int open(const char *pathname, int flags);
–int open(const char *pathname, int flags, mode_t mode);
–int creat(const char *pathname, mode_t mode);
-
函数功能:主要用于打开/创建 一个 文件/设备
-
返回值:成功返回新的文件描述符,失败返回-1 描述符就是一个小的非负整数,用于表示当前文件
- 第一个参数:字符串形式的文件路径和文件名
- 第二个参数:操作标志 必须包含以下访问模式中的一种:
- O_RDONLY - 只读
- O_WRONLY - 只写
- O_RDWR - 可读可写
- O_APPEND - 追加,写入到文件的尾部
- O_CREAT - 文件不存在则创建,存在则打开 O_EXCL - 与O_CREAT搭配使用,存在则open失败 O_TRUNC - 文件存在且允许写,则清空文件
- 第三个参数:操作模式,权限 当创建新文件时,需要指定的文件权限, 如: 0644
creat函数
–#include
–#include
–#include
–int creat(const char *pathname, mode_t mode);
- 函数功能:用于创建文件,存在则更新,不存在则创建
- 参数:第一个参数路径
- 第二个参数权限:成功返回文件描述符,失败返回-1。
- creat函数是通过调用open实现的
close函数
–#include
–int close(int fd);
- 函数功能:主要用于关闭参数fd指定的文件描述符,也就是让描述符fd不再关联任何一个文件,以便于下次使用
read函数
–#include
–ssize_t read(int fd, void *buf, size_t count);
- 第一个参数:文件描述符(从哪里读)
- 第二个参数:缓冲区的首地址(存到哪里去)
- 第三个参数:读取的数据大小
- 返回值:成功返回读取到的字节数,返回0表示读到文件尾失败返回-1
- 函数功能:表示从指定的文件中读取指定大小的数据
write函数
–#include
– ssize_t write(int fd,const void *buf,size_t count);
- 第一个参数:文件描述符(写入到哪里去)
- 第二个参数:缓冲区的首地址(数据从哪里来)
- 第三个参数:写入的数据大小
-
返回值:成功返回写入的数据大小,0表示没有写入, 失败返回-1
-
函数功能:表示将指定的数据写入到指定的文件中
-
注意:read和write函数一般默认以二进制形式进行读写操作
lseek函数
–#include
–off_t lseek(int fd,off_t offset,int whence);
- 第一个参数:文件描述符(表示在哪个文件中操作)
- 第二个参数:偏移量(正数表示向后,负数向前)
- 第三个参数:起始位置(从什么地方开始偏移) SEEK_SET - 文件开头位置 SEEK_CUR - 文件当前位置 SEEK_END - 文件结尾位置
-
返回值:成功返回距离文件开头位置的偏移量, 失败返回-1
-
函数功能:主要用于调整文件的读写位置
access函数
•#include
•int access ( const char* pathname, // 文件路径 int mode // 访问模式 );
-
函数功能:按实际用户ID和实际组ID(而非有效用户ID和有效组ID),进行访问模式测试。
参数:
- 路径
- mode取R_OK/W_OK/X_OK的位或, 测试调用进程对该文件, 是否可读/可写/可执行, 或者取F_OK,测试该文件是否存在。
-
返回值:成功返回0,失败返回-1。
dup函数
–#include
–int dup(int oldfd);
-
功能:复制一个文件描述符
-
参数:oldfd:源描述符
-
返回值: 错误返回-1,errno被设置为相应的错误码成功返回新的文件描述符
dup2函数
–int dup2(int oldfd, int newfd);
- 功能:复制一个文件描述符
- 参数:oldfd:指定源描述符
- newfd:指定新的描述符 如果这个描述符原来是打开的,使用之前先关闭.
- 返回值: 错误返回-1errno被设置为相应的错误码成功返回新的文件描述符
获取文件元数据
-
文件有两部分构成 文件的内容 文件的属性
-
文件的元数据就是文件的属性
-
每个文件都有一个对应的i节点,这个I节点里面保存了文件的元数据和所在的硬盘位置。中文译名为"索引节点"。
-
系统打开文件这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block。
命令
–ls –i查看I节点
–inode编号 文件的类型 文件的权限 硬链接数 属主 属组 大小 最后修改时间
stat 文件名 查看文件的元数据
stat函数
–#include
–#include
–#include
–int stat(const char *pathname, struct stat *buf);功能:获取文件的身份信息
-
参数:
pathname:指定了文件的名字 -
buf:将文件的身份信息存储到buf指定的空间里 -
返回值:成功 0错误 -1 errno被设置为相应错误码
fstat函数
–#include
–#include
–#include
–int fstat (int fd, struct stat* buf);
-
功能:获取文件的身份信息
-
参数:fd:文件描述符
-
buf:将文件的身份信息存储到buf指定的空间里
-
返回值:成功 0错误 -1 errno被设置为相应错误码
struct stat
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M6dnFudr-1615732028958)(http://img.wangzun233.top/uc02.png)]
st_mode
•t_mode成员,该成员描述了文件的类型和权限两个属性。
•15-12 位保存文件类型
•11-9位保存执行文件时设置的信息
•8-0 位保存文件访问权限
st_mode的文件类型
-
S_IFMT 0170000 文件类型的位遮罩
-
S_IFSOCK 0140000 套接字文件
-
S_IFLNK 0120000 链接文件
-
S_IFREG 0100000 一般文件
-
S_IFBLK 0060000 块设备文件
-
S_IFDIR 0040000 目录
-
S_IFCHR 0020000 字符设备文件
-
S_IFIFO 0010000 管道文件
计算文件类型
S_IFMT是一个掩码,它的值是0170000(注意这里用的是八进制), 可以用来过滤出前四位表示的文件类型。
通过掩码S_IFMT把其他无关的部分置0,再与表示目录的数值比较,从而判断这是否是一个目录
计算文件类型宏
•为了简便操作,
- S_ISDIR() - 是否目录
- S_ISREG() - 是否普通文件
- S_ISLNK() - 是否软链接
- S_ISBLK() - 是否块设备
- S_ISCHR() - 是否字符设备
- S_ISSOCK() - 是否Unix域套接字
- S_ISFIFO() - 是否有名管道
文件权限
-
st_mode字段的最低9位,代表文件的许可权限,它标识了文件所有者、组用户、其他用户的读(r)、写(w)、执行(x)权限。
-
目录的权限与普通文件的权限是不同的。
-
目录读权限。读权限允许我们通过opendir()函数读取目录,进而可以通过readdir()函数获得目录内容,即目录下的文件列表
-
写权限。写权限代表的是可在目录内创建、删除文件,而不是指的写目录本身。
-
执行权限。可访问目录中的文件。
文件权限位
- S_IRUSR(S_IREAD) 00400 文件所有者具可读取权限
- S_IWUSR(S_IWRITE)00200 文件所有者具可写入权限
- S_IXUSR(S_IEXEC) 00100 文件所有者具可执行权限
- S_IRGRP 00040 用户组具可读取权限
- S_IWGRP 00020 用户组具可写入权限
- S_IXGRP 00010 用户组具可执行权限
- S_IROTH 00004 其他用户具可读取权限
- S_IWOTH 00002 其他用户具可写入权限
- S_IXOTH 00001 其他用户具可执行权限
获取文件权限
struct stat st;
stat(path, &st);
st.st_mode & S_IXUSR == 1; *//**可以判断是否可执行*
其他位
- S_ISUID 04000 用户的id
- S_ISGID 02000 用户组的id
- S_ISVTX 01000 文件的sticky位
- 若一目录具有sticky 位 (S_ISVTX), 则表示在此目录下的文件只能被该文件所有者、此目录所有者或root 来删除或改名.
时间函数
#include
char *ctime(const time_t *timep);
-
功能:将秒数转换为正常的字符串格式的日历时间
-
参数:timep,这是指向 time_t 对象的指针,该对象包含了一个日历时间。
-
返回值:该函数返回一个 C 字符串,该字符串包含了可读格式的日期和时间信息
•案例
• char* time = ctime(&st.st_mtime);//获取最后一次修改时间
Linux下用户的信息
•在/etc/passwd 文件下保存了用户的信息
•第一列 用户的名字
•第二列 用户是不是有密码
•第三列 用户的id uid
•第四列 用户的初始组id gid
•第五列 用户的注释信息
•第六列 用户的家目录
•第七列 用户执行的第一个程序
•一个用户可以属于多个组 一个用户组包含多个用户
获取用户信息
•getpwuid(3)
•#include
•#include
•struct passwd *getpwuid(uid_t uid);
•功能:找到跟uid匹配的用户信息
•参数:uid:指定要找的用户的id
•返回值:找不到uid指定的用户或者错误产生NULL如果是错误产生errno的值被设置为相应错误码,找到非NULL
Linux下的组信息
•Linux下在/etc/group文件中保存了组的信息
•第一列 用户组的名字
•第二列 用户组是否有密码
•第三列 用户组的组id
第四列 用户组的成员
获取组信息
•#include
•#include
•struct group *getgrgid(gid_t gid);
•功能:getgrgid()用来依参数gid 指定的组识别码逐一搜索组文件
•参数:gid-组id号
•返回值:返回 group 结构数据, 如果返回NULL 则表示已无数据, 或有错误发生.
struct group {
char *gr_name; /* group name */
char *gr_passwd; /* group password */
gid_t gr_gid; /* group ID */
char **gr_mem; /* NULL-terminated array of pointer to names of group members */
};
chmod/fchmod
•#include
•int chmod ( const char* path, // 文件路径 mode_t mode // 文件权限 );
•int fchmod ( int fd, // 文件路径 mode_t mode // 文件权限 );
•成功返回0,失败返回-1。
•mode为以下值的位或(直接写八进制整数形式亦可, 如07654 - rwSr-sr-T):
•S_IRUSR(S_IREAD) - 属主可读
•S_IWUSR(S_IWRITE) - 属主可写
•S_IXUSR(S_IEXEC) - 属主可执行
•S_IRGRP - 属组可读
•S_IWGRP - 属组可写
•S_IXGRP - 属组可执行
•S_IROTH - 其它可读
•S_IWOTH - 其它可写
•S_IXOTH - 其它可执行
rename重命名
•#include
•int rename(char * oldname, char * newname);
功能:用于重命名文件、改变文件路径或更改目录名称,其原型为
•参数:oldname为旧文件名,newname为新文件名。
•返回值:修改文件名成功则返回0,否则返回-1。
ftruncate函数
•#include
•int ftruncate(int fd, off_t length) 。
•功能:改变文件length的大小
•参数:fd打开的文件描述符,
• length想要扩展的文件大小,如果length小于原文件大小,则原文件超过length的内容被删除
•返回值:成功返回0,失败返回-1,errno被设置
文件的映射
- mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程
mmap函数
#include
•void* mmap (
• void* start, // 映射区内存起始地址// NULL系统自动选定,
• size_t length, // 字节长度,自动按页(4K)对齐
• int prot, // 映射权限
• int flags, // 映射标志
• int fd, // 文件描述符
off_t offset // 文件偏移量,自动按页(4K)对齐
);
•功能:将文件或设备映射到进程的虚拟地址空间
•成功返回映射区内存起始地址,失败返回MAP_FAILED(-1)。
mmap函数参数
•prot取值:
•PROT_EXEC - 映射区域可执行。
•PROT_READ - 映射区域可读取。
•PROT_WRITE - 映射区域可写入。
•PROT_NONE - 映射区域不可访问。
•flags取值:
•MAP_SHARED - 对映射区域的写入操作直接反映到文件中。共享映射
•MAP_PRIVATE - 对映射区域的写入操作只反映到缓冲区中, 不会真正写入文件。
MAP_ANONYMOUS - 匿名映射,将虚拟地址映射到物理内存而非文件,忽略fd
munmap函数参数
•int munmap(void *addr, size_t length);
•功能:解除文件或设备到进程的虚拟地址空间的映射
•参数:addr:指定了映射区域的起始地址
• length:指定了映射区域的长度
返回值:成功 返回0错误 -1 errno被设置。
mmap
-
一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射5000字节到虚拟内存中。
•分析:因为单位物理页面的大小是4096字节,虽然被映射的文件只有5000字节,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域8192个 字节,5000~8191的字节部分用零填充。但是5000-8191写入的字节不会再文件中显示。
-
一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射15000字节到虚拟内存中,即映射大小超过了原始文件的大小。
•分析:由于文件的大小是5000字节,和情形一一样,其对应的两个物理页。那么这两个物理页都是合法可以读写的,只是超出5000的部分不会体现在原文件中。由于程序要求映射15000字节,而文件只占两个物理页,因此8192字节~15000字节都不能读写,操作时会返回异常。总线错误
-
一个文件初始大小为0,使用mmap操作映射了10004K的大小,即1000个物理页大约4M字节空间,mmap返回指针ptr
•分析:如果在映射建立之初,就对文件进行读写操作,由于文件大小为0,并没有合法的物理页对应,如同情形二一样,会返回SIGBUS错误。
•但是如果,每次操作ptr读写前,先增加文件的大小,那么ptr在文件大小内部的操作就是合法的。
目录函数
opendir函数
#include
#include
DIR *opendir(const char *name);
-
功能:打开一个文件夹
-
参数:name:指定了要打开的文件夹的名字
-
返回值:错误 NULL errno被设置成功 返回一个指向文件夹流的地址文件夹流的读写位置定位在文件夹的第一个条目
closedir函数
#include
#include
int closedir(DIR *dirp);
-
功能:关闭一个文件夹
-
参数:dirp:指定要关闭的文件夹流
-
返回值:成功 0错误 -1 errno被设置为合适的错误码
readdir函数
#include
struct dirent *readdir(DIR *dirp);
-
函数功能:表示根据参数指定的位置读取目录中的内容,
-
返回值:成功返回struct dirent类型的指针,失败返回NULL
•struct dirent {
• ino_t d_ino; /*i节点编号*/
• off_t d_off; /*在目录文件中的偏移*/
• unsigned short d_reclen;/*文件名长*/
• unsigned char d_type;/*文件的类型*/
• char d_name[256]; /*文件名称*/
•};
其他目录操作函数
-
getcwd() - 获取当前程序所在的工作目录
-
mkdir() - 创建一个目录
-
rmdir() - 删除一个空目录
-
chdir() - 切换目录,它只对该进程有效,而不能影响调用它的那个进程。在退出程序时,shell还会返回开始时的那个工作目录。
进程管理
进程的相关概念
•程序:主要指存放在硬盘上的可执行文件 ,用来描述要完成的功能。
•进程:进程是程序实体的运行过程,是系统进行资源分配和调度的一个独立单位。
•同样一个程序,同一时刻被两次运行,那么他们就是两个独立的进程。
•系统资源以进程为单位分配,如内存、文件等,操作系统为每个独立的进程分配了独立的地址空间
•系统采用PID唯一标识一个进程,在每一个时刻都可以保证PID的唯一性,采用延迟重用的策略
•操作系统将CPU调度给需要的进程,即将CPU的控制权交给某个进程就称为调度。
•系统中存放进程的管理和控制信息的数据结构称为进程控制块(PCB Process Control Block)
时间片轮转算法
•时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它被移到队列的末尾。
进程控制块-PCB
•PCB是系统感知进程存在的唯一标志:进程与PCB一一对应;
•是进程管理和控制的最重要的数据结构(进程描述信息 、处理机状态信息、进程调度信息、进程控制信息);
•进程描述信息
–进程标识符(pid),这个标识是唯一的,通常是一个整数
–进程名,通常基于可执行文件名,这是不唯一的
–用户标识符(uid)
–进程组关系
进程的控制信息
•当前状态
•优先级
•代码执行入口地址
•程序的磁盘地址
•运行统计信息(执行时间、页面调度)
•进程间同步和通信
•进程的队列指针
•进程的消息队列指针
进程三种基本状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4noztRQJ-1615732028960)(http://img.wangzun233.top/uc04.png)]
进程的五状态模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b4xPnISh-1615732028962)(http://img.wangzun233.top/uc05.png)]
进程的相关命令
•ps - 查看当前终端中的进程
•whereis 命令 表示查看指定命令所在的位置
•ps -aux 表示显示所有包含其他使用者的进程
•ps -aux | more 表示分屏显示命令执行的结果
•USER - 用户名,也就是进程的属主 PID - 进程的进程号 %CPU - 进程占用的CPU百分比 %MEM - 进程占用的内存百分比 STAT - 进程的状态信息 TIME - 消耗CPU的时间 COMMAND - 进程的名称
•其中进程的状态信息主要有: S 休眠状态 s 进程的领导者 Z 僵尸进程 R 正在运行的 O 可运行状态 T 挂起状态 < 优先级高的进程 N 优先级低的进程 L 有些页被锁进内存, + 位于后台的进程组;
•ps -ef 表示以全格式的方式显示进程
•kill -9 进程号 表示杀死指定的进程
父子进程
•如果进程A启动了进程B,那么进程A叫做进程B的父进程,而进程B叫做进程A的子进程
•一般来说,进程0是系统内部的进程,负责启动进程1和进程2,而其他的所有进程都是直接/间接地由进程1和进程2启动起来,而进程1也就是init进程
•父进程终止子进程也会被终止。
•如果父进程终止,子进程没终止,这种进程成为孤儿进程,子进程的父进程ID会自动指向init进程
•如果子进程死亡,父进程存活,并且没有回收子进程的资源,这种子进程被称为僵尸进程。
•前台后台进程。
进程的ID获取
#include
#include
getpid() - 表示获取当前进程的进程号
getppid() - 表示获取当前进程的父进程ID
getuid() - 表示获取用户ID
getgid() - 表示获取组ID 。
#include
#include
int main(){
pid_t pid = getpid();//获取当前程序的进程号
pid_t ppid = getppid();//获取当前进程的父进程
printf("当前进程ID%d,父进程ID%d\n",pid,ppid);
while(1);
return 0;
}
//ps -ef
进程的创建-frok
#include
pid_t fork(void);
•函数功能:表示以复制当前运行进程的方式去创建一个新的子进程。
•返回值:如果成功父进程返回子进程的PID,子进程返回0,失败返回-1
#include 代码执行的方式
•fork函数之前的代码,父进程执行1次
•fork函数之后的代码,父子进程各自执行1次
•fork函数的返回值,父子进程各自返回1次,也就是父进程返回子进程的PID,子进程返回0,可以通过返回值区分父子进程
•父子进程之间的执行顺序是不确定的,由操作系统决定。
父子进程的资源
•使用fork创建的进程,也会分配4G的虚拟空间,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程,两者的虚拟空间不同,但其对应的物理空间是同一个。
•当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,内核也会给子进程的数据段、堆栈段分配相应的物理空间,而代码段继续共享父进程的物理空间(两者的代码完全相同)
•总结:使用fork创建的子进程会复制父进程中除了代码区之外的其他内存区域,而代码区和父进程共享
父子进程的关系
•父进程启动了子进程之后,父子进程同时执行,如果子进程先结束,会给父进程发信号,父进程负责帮助子进程回收子进程的资源(善后)
•如果父进程先结束,子进程会变成孤儿进程,子进程会变更父进程为init进程,也就是进程1,init进程叫做孤儿院 ,(Ubuntu会被upstart回收,upstart是在图形化界面下的一个后台的守护程序)
•如果子进程先结束,但是父进程由于各种原因没有收到子进程发来的信号,没有进行资源的回收,那么子进程变成僵尸进程
fork函数扩张
•如何创建4个进程?
–fork(); fork(); 调用两次
–1个父进程 2个子进程 1个孙子进程
•如何创建3个进程?也就是1个父进程 2个子进程
–fork(); 1个父进程 和 1个子进程
–if(父进程) { fork(); 1个父进程 又创建 1个子进程 }
•俗称:fork炸弹
–while(1) {
–fork(); //进程数采用指数级增长方式
– }
进程的终止
•正常终止
–在main函数中执行了return 0
–调用exit()函数
–调用_exit()/_Exit()函数
–最后一个线程返回
–最后一个线程调用了pthread_exit()函数
•非正常终止
–采用信号终止进程
–最后一个线程被其他线程取消
//vim exit.c
#include 进程终止函数
#include
void _exit(int status); => UC函数
#include
void _Exit(int status); => 标C函数
•函数功能:表示立即终止当前进程。
•参数为退出状态信息,用于返回给父进程,一般给0表示正常退出,给-1表示非正常退出
#include
void exit(int status); => 标C函数
•函数功能:表示引起当前进程的终止。
•调用exit函数终止进程的同时,会调用由atexit()和on_exit()函数注册过的函数-遗言函数
什么是遗言函数?
•进程终止的时候执行的函数,进程调用return或者exit(3)从main函数返回的时候,执行的函数。
•遗言函数需要在进程还没有终止以前向进程注册,在进程终止的时候调用。
•遗言函数的注册顺序和调用顺序相反
•遗言函数注册一次会被调用一次
•子进程继承父进程的遗言函数
atexit和on_exit
#include
int atexit(void (*function)(void));
•功能:向进程注册遗言函数function
•参数:function:指定遗言函数的入口地址
•返回值:成功 0 错误 非0
int on_exit(void (*function)(int , void *), void *arg);
•功能:向进程注册遗言函数function
•参数:function:指定遗言函数的入口地址
• arg:传递给function函数的唯一参数
•返回值:成功 0 错误 非0
#include 挂起进程
•挂起进程在操作系统中可以定义为暂时被淘汰出内存的进程,机器的资源是有限的,在资源不足的情况下,操作系统对在内存中的程序进行合理的安排,其中有的进程被暂时调离出内存,当条件允许的时候,会被操作系统再次调回内存,重新进入等待被执行的状态即就绪态
进程的阻塞,挂起和睡眠
•进程运行必然要进行IO操作,IO操作势必要引起等待,在资源未读取完成,进程必然要等待,那么在等待IO完成这个部分就是阻塞状态。所以阻塞是一种被动的方式,由于获取资源获取不到而引起的等待。
•睡眠就是一种主动的方式,可以用于阻塞,更多的,我们可以在适当的时候设置让进程睡眠/等待一定的时间,这段时间过后,进程必须返回来工作。
•挂起也是一种主动的行为,挂起是系统层面对进程作出的合理调度。在内存资源不足时,需要把一些进程换出到外存,给着急运行的进程腾地方。挂起倾向于换出阻塞态的进程,也可以是就绪态的进程。只是这个转换几乎不会采用,因为任意时刻,肯定可以找到在内存中的阻塞态进程,但也不能缺少这种直接把就绪转换到挂起的能力。
wait函数
#include
#include
pid_t wait(int *status);
•函数功能:表示挂起当前正在运行的进程,直到该进程的子进程状态发生改变,而子进程的终止也属于状态发生改变的一种,
•参数status用于获取子进程终止时的退出状态,
•成功返回终止的子进程pid,失败返回-1
•WIFEXITED(status) - 判断子进程是否正常终止,如果是,它会返回一个非零值。
• WEXITSTATUS(status) - 获取子进程的正常退出状态信息,如果WIFEXITED返回0,这个值就毫无意义。
#include wait函数详解
•子进程退出时,内核将子进程置为僵尸状态,这个进程成为僵尸进程,它只保留最小的一些内核数据结构,以便父进程查询子进程的退出状态
•父进程一旦调用了wait,就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
waitpid函数
pid_t waitpid(pid_t pid, int *status, int options);
•第一个参数:进程号 <-1 表示等待进程组ID为pid绝对值的任何一个子进程(了解) -1 表示等待任意一个子进程(掌握) 0 表示等待和调用进程同一个进程组的任何一个子进程(了解) >0 表示等待进程号为PID的子进程(具体某一个,掌握)
•第二个参数:获取退出状态信息
•第三个参数:选项,一般给0即可,WNOHANG表示不阻塞
•返回值:成功返回状态发生改变的子进程PID,失败返回-1
•函数功能: 表示按照指定的方式等待指定的子进程状态发生改变,并且采用第二个参数获取退出状态信息
#include wait/waitpid工作方式
•调用wait()/waitpid()函数后,父进程开始等待子进程,而父进程自身进入阻塞状态
•如果没有子进程,父进程立即返回
•如果有子进程,但是没有已经结束的子进程,父进程保持阻塞状态,直到有一个符合要求的子进程结束为止
•如果有符合要求的子进程结束,那么父进程会获取子进程的退出状态信息并且返回
vfork函数
#include
#include
pid_t vfork(void);
•函数功能:该函数功能与fork基本相似,所不同的是不会拷贝父进程的内存区域,而是直接占用父进程的存储空间,使得父进程进入阻塞状态,直到子进程结束为止,也就是说子进程先于父进程执行
•注意: vfork()创建子进程成功后是严禁使用return的,只能调用exit()或者exec族的函数,否则后果不可预料
#include fork和vfork的区别
•fork():子进程拷贝父进程的数据段,堆栈段
•vfork():子进程与父进程共享数据段
•fork()父子进程的执行次序不确定
•vfork 保证子进程先运行,在调用exec 或exit 之前与父进程数据是共享的,在它调用exec或exit 之后父进程才可能被调度运行。
exec函数族
•fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程(子进程将获得父进程数据空间,堆,栈等资源。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程不共享这些存储空间。linux将复制父进程的地址空间内容给子进程,因此,子进程由了独立的地址空间。),也就是这两个进程做完全相同的事。
•在fork后的子进程中使用exec函数族,可以装入和运行其它程序(子进程替换原有进程,和父进程做不同的事)。
•exec函数族可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段。在执行完后,原调用进程的内容除了进程号外,其它全部被新程序的内容替换了。另外,这里的可执行文件既可以是二进制文件,也可以是Linux下任何可执行脚本文件。
exec函数原型
int execl(const char*path,const char*arg,…);
int execle(const char * path,const char * arg,char * const envp[]);
int execlp(const char*file,const char*arg,…);
int execv(const char*path,char*const argv[]);
int execve(const char * path,char * const argv[],char * const envp[]);
int execvp(const char * file,char * const argv[]);
#include - 成功:函数不会返回 失败:返回-1;
exec函数参数说明
•path:要执行的程序路径。可以是绝对路径或者是相对路径。
•file:要执行的程序名称。如果该参数中包含“/”字符,则视为路径名直接执行;否则视为单独的文件名,系统将根据PATH环境变量指定的路径顺序搜索指定的文件。
•argv:命令行参数的矢量数组。
•envp:带有该参数的exec函数调用时指定环境变量数组。其他不带该参数的exec函数则使用调用进程的环境变量。
•arg:程序的第0个参数,即程序名自身。相当于argv[O]。
exec函数族一般规律
•exec函数一旦调用成功即执行新的程序,不返回。只有失败才返回,错误值-1。
•exec函数族名字很相近,使用起来也很相近,它们的一般规律如下:
•l (list) 命令行参数列表
•p (path) 搜素file时使用path变量
•v (vector) 使用命令行参数数组
•e(environment) 使用环境变量数组,不使用进程原有的环境变量,设置新加载程序运行的环境变量
execl使用案列
/*创建子进程并调用函数execl execl 中希望接收以逗号分隔的参数列表,并以NULL指针为结束标志 */
if( fork() == 0 ) {
//execl("/bin/ls", "ls","-a", “/home", NULL );
if( execl( "/bin/ls", "ls","-a", NULL ) == -1 ){
perror( "execl error " );
exit(1); 28
}
}
execv使用案列
/*创建子进程并调用函数execv,execv中希望接收一个以NULL结尾的字符串数组的指针*/
char *arg[] = {"ls", "-a", NULL};
if( fork() == 0 ){
if( execv( "/bin/ls",arg) < 0){
perror("execv error ");
exit(1);
}
}
execlp使用案列
/*创建子进程并调用execlp,execlp中希望接收以逗号分隔的参数列表,并以NULL指针为结束标志,函数进程PATH变量查找子程序文件*/
if( fork() == 0 ){
if(execlp("ls","ls","-a",NULL)<0){
perror( "execlp error " );
exit(1);
}
}
execvp使用案列
if( fork() == 0 ){
if( execvp( "ls", arg ) < 0 ){
perror( "execvp error " );
exit( 1 );
}
}
execle使用案列
/*e 函数传递指定环境变量,允许改变子进程的环境,为NULL时,子进程使用当前进程的环境*/
if( fork() == 0 ){
if(execle("/bin/ls","ls","-a",NULL,NULL)==-1){
perror("execle error ");
exit(1);
}
}
execve使用案列
if( fork() == 0 ){
char *envp[] = {"AA=11", "BB=22", NULL};
if(execve("/bin/ls",arg,envp)==0){
perror("execve error ");
exit(1);
}
}
system()函数
#include
int system(const char *command);
•函数功能: 表示执行参数指定的shell命令/文件
•详解
•system()会调用fork()产生子进程,由子进程来调用/bin/sh-c string来执行参数string字符串所代表的命令,此命令执行完后随即返回原调用的进程
•注意:system()函数要慎用要少用,能不用则不用,system()函数不稳定?
信号
中断
•中断指计算机CPU获知某些事,暂停正在执行的程序,转而去执行处理该事件的程序,当这段程序执行完毕后再继续执行之前的程序。整个过程称为中断处理,简称中断,而引起这一过程的事件称为中断事件。中断是计算机实现并发执行的关键,也是操作系统工作的根本。
•硬件中断是由与系统相连的外设(比如网卡 硬盘 键盘等)自动产生的
•软件中断不会直接中断CPU, 也只有当前正在运行的代码(或进程)才会产生软中断. 软中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求.
信号
•信号是提供异步事件处理机制的软件中断。这些异步事件可能来自硬件设备,如用户同时按下了Ctrl键和C键,也可能来自系统内核,如试图访问尚未映射的虚拟内存,又或者来自用户进程,如尝试计算整数除以0的表达式
•信号的异步特性不仅表现为它的产生是异步的,对它的处理同样也是异步的。程序的设计者不可能也不需要精确地预见什么时候触发什么信号,也同样无法预见该信号究竟在什么时候会被处理。一切都在内核的操控下,异步地运行。信号是在软件层面对中断机制的一种模拟
•可以使用kill -l 查看系统提供的信号。
信号本质
•信号本质就是整数值,信号的名称都是以SIG开头,其中linux系统一般表示的信号范围是:1 ~ 64,unix系统一般表示的信号范围是1~48之间
•掌握的信号:
•ctrl + c SIGINT 2 默认处理是终止进程
•ctrl + \ SIGQUIT 3 默认处理是终止进程
•kill -9 SIGKILL 9 默认处理也是终止,不允许被捕获
信号的处理过程
信号有一个非常明确的生命周期
- – 首先,信号被生成,并被发送至系统内核
- – 其次,系统内核存储信号,直到可以处理它
- – 最后,一旦有空闲,内核即按以下三种方式之一处理信号
信号的处理方式
• 忽略信号:什么也不做。SIGKILL和SIGSTOP信号不能忽略
• 捕获信号:内核暂停收到信号的进程正在执行的代码,跳转到事先注册的信号处理函数,执行该函数并返回,跳回到捕获信号的地方继续执行。SIGKILL和SIGSTOP信号不能捕获
• 默认操作:不同信号有不同的默认操作,通常是终止收到信号的进程,但也有一些信号的默认操作是视而不见,即忽略。
信号的诞生
•信号事件的发生有两个来源:
•硬件来源(比如我们按下了键盘或者其它硬件故障);
•软件来源,最常用发送信号的系统函数是aignal, raise, alarm和setitimer以及sigqueue函数,软件来源还包括一些非法运算等操作。
发出信号的原因简单分类
•与进程终止相关的信号。当进程退出,或者子进程终止时,发出这类信号。
•与进程例外事件相关的信号。如进程越界,或企图写一个只读的内存区域(如程序正文区)
•与在系统调用期间遇到不可恢复条件相关的信号。如执行系统调用exec时,原有资源已经释放,而目前系统资源又已经耗尽。
•与执行系统调用时遇到非预测错误条件相关的信号。如执行一个并不存在的系统调用。
•在用户态下的进程发出的信号。如进程调用系统调用kill向其他进程发送信号。
•与终端交互相关的信号。如用户关闭一个终端
•跟踪进程执行的信号。
信号在进程中注册
•在进程表的表项中有一个软中断信号域,该域中每一位对应一个信号。内核给一个进程发送软中断信号的方法,是在进程所在的进程表项的信号域设置对应于该信号的位。如果信号发送给一个正在睡眠的进程,如果进程睡眠在可被中断的优先级上,则唤醒进程;否则仅设置进程表中信号域相应的位,而不唤醒进程。如果发送给一个处于
•信号在进程中注册指的就是信号值加入到进程的未决信号集每个信号占用一位)中,并且信号所携带的信息被保留到未决信号信息链的某个结构中。只要信号在进程的未决信号集中,表明进程已经知道这些信号的存在,但还没来得及处理,或者该信号被进程阻塞。可运行状态的进程,则只置相应的域即可。
可靠信号和不可靠信号
•当一个实时信号发送给一个进程时,不管该信号是否已经在进程中注册,都会被再注册一次,因此,信号不会丢失,因此,实时信号又叫做"可靠信号"。
•当一个非实时信号发送给一个进程时,如果该信号已经在进程中注册,则该信号将被丢弃,造成信号丢失。因此,非实时信号又叫做"不可靠信号"。
•信号注册与否,与发送信号的函数(如kill()或sigqueue()等)以及信号安装函数(signal()及sigaction())无关,只与信号值有关(信号值小于SIGRTMIN的信号最多只注册一次,信号值在SIGRTMIN及SIGRTMAX之间的信号,只要被进程接收到就被注册)
可靠信号/不可靠信号
•对于linux系统中的信号来说,其中1 ~ 31之间的信号叫做不可靠信号,也就是不支持排队,可能丢失;其中34~64之间的信号叫做可靠信号,支持排队,不会丢失;而不可靠信号又叫做非实时信号,可靠信号叫做实时信号
信号的注册
•如果进程要处理某一信号,那么就要在进程中注册该信号。注册信号主要用来确定进程将要处理哪个信号;该信号被传递给进程时,将执行何种操作。
•linux主要通过signal()函数实现信号的注册。
•signal()只有两个参数,不支持信号传递信息,主要是用于前32种非实时信号的安装;
Signal函数
#include
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
•功能:表示对指定的信号设置指定的处理方式
•参数:signum: 指定信号的编号
• handle: 信号处理函数的入口地址
•返回值:成功 返回原来的信号处理函数的地址
• 失败 SIG_ERR 将错误的编号设置到error中
•注意:SIGKILL和SIGSTOP两个信号不能被捕获和忽略。
Signal详解
•signal首先是一个函数名为signal的函数,具有两个参数,第一个是int类型,第二个是函数指针类型 返回值类型也是函数指针类型
•参数和返回值类型都是函数指针类型 指向一个具有Int类型参数,和void类型返回值的函数
•Signal函数的第二个参数
–SIG_DFL - 默认处理,绝大多数都是终止进程
–SIG_IGN - 忽略处理
–函数地址 - 按照指定的函数进行自定义处理
#include 父子进程处理信号
•对于vfork/fork创建的子进程来说,完全照搬父进程对信号的处理方式,也就是说父进程自定义,子进程也自定义处理;父进程忽略,子进程也忽略处理;父进程默认,子进程也默认处理;
•如果子进程调用exec族函数,代码将跳转出去,不在和父进程的处理方式一样。
信号的发送方式
•采用键盘发送方式(只能发送部分比较特殊的信号) ctrl+c SIGINT 2 ctrl+\ SIGQUIT 3 …
•程序出错的发送方式(只能发送部分比较特殊的信号) 段错误 SIGSEGV 11 总线错误 SIGBUS 7 …
•kill -信号值 进程号(可以发送所有信号)
• 采用系统函数发送信号 raise()/kill()/alarm()/sigqueue()
raise函数
#include
int raise(int sig);
•函数功能:表示给调用进程/线程发送指定的信号sig.
•成功返回0,失败返回非0
•Sig是信号值,当为0时(即空信号),实际不发送任何信号,但照常进行错误检查,因此,可用于检查目标进程是否存在,以及当前进程是否具有向目标发送信号的权限(root权限的进程可以向任何进程发送信号,非root权限的进程只能向属于同一个session或者同一个用户的进程发送信号)。
kill函数函数
#include
#include
int kill(pid_t pid, int sig);
•第一个参数:进程号> 0 表示给进程号为pid的进程发送信号sig(掌握) 0 表示给与当前进程同一个进程组的每个进程发信号 (了解) -1 表示给当前进程拥有发送信号权限的每个进程发信 号,进程1除外 (了解) <-1 表示发送信号给进程组ID为PID的每一个进程(了解)第二个参数:信号值 0 表示不发送信号,而是检查指定进程/进程组是否存在
•函数功能:表示向指定的进程发送指定的信号
alarm函数
·#include
unsigned int alarm(unsigned int seconds);
•函数功能:系统调用alarm安排内核为调用进程在指定的seconds秒后发出一个SIGALRM的信号。如果指定的参数seconds为0,则不再发送 SIGALRM信号。后一次设定将取消前一次的设定。该调用返回值为上次定时调用到发送之间剩余的时间,或者因为没有前一次定时调用而返回0。
•注意,在使用时,alarm只设定为发送一次信号,如果要多次发送,就要多次使用alarm调用。
pause函数
#include
int pause(void);
•功能:令目前的进程暂停(进入睡眠状态), 直到被信号(signal)所中断。
•返回值:
•信号被捕获,信号处理函数被调用之后,猜返回,返回-1,errno被设置
信号函数总结
#include 信号集
•多个信号组成的信号集合称为信号集
•系统内核用sigset_t类型表示信号集
•sigset_t类型是一个结构体,但该结构体中只有一个成员,是一个包含32个元素的整数数组
–在
#define _SIGSET_NWORDS (1024 /(8 * sizeof (unsigned long int)))
typedef struct {
unsigned long int __val[_SIGSET_NWORDS];
} __sigset_t;
–在
typedef __sigset_t sigset_t;
•可以把sigset_t类型看成一个由1024个二进制位组成的大整数
–其中的每一位对应一个信号,其实目前远没有那么多信号
–某位为1就表示信号集中有此信号,反之为0就是无此信号
–当需要同时操作多个信号时,常以sigset_t作为函数的参数或返回值的类型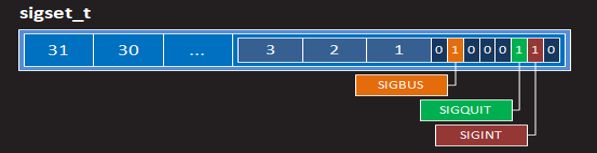
信号集基本操作
•#include
•sigemptyset() - 清空信号集,本质上就是将二进制置为0
•sigfillset()- 填满信号集,本质就是二进制置为1
•sigaddset() - 填充指定信号到信号集,也就是二进制置为1
•sigdelset() - 删除指定信号,也就是指定二进制置为0
•sigismember()- 判断信号集中是否存在某个信号,存在返回1,不存在返回0,出错返回-1
sigfillset
•#include
•int sigfillset (sigset_t* *sigset*);
–函数功:能填满信号集,即将信号集的全部信号位置1
–参数:信号集
–返回值:成功返回0,失败返回-1
sigset_t sigset;
if (sigfillset (&sigset) == -1) {
perror ("sigfillset");
exit (EXIT_FAILURE);
}
sigemptyset
•#include
•int sigemptyset (sigset_t* sigset);
–函数功能:清空信号集,即将信号集全部信号位清0
–参数:信号机
–返回值:成功返回0,失败返回-1
sigset_t sigset;
if (sigemptyset (&sigset) == -1) {
perror ("sigemptyset");
exit (EXIT_FAILURE);
}
sigaddset
•#include
•int sigaddset (sigset_t* sigset, int signum);
–函数功能:加入信号,即将信号集中与指定信号编号对应的信号位置1
–参数:信号集,信号编号
–返回值:成功返回0,失败返回-1
if (sigaddset (&sigset, SIGINT) {
perror ("sigaddset");
exit (EXIT_FAILURE);
}
sigdelset
•#include
•int sigdelset (sigset_t* *sigset*, int *signum*);
–函数功能:删除信号,即将信号集中与指定信号编号对应的信号位清0
–参数:信号集,信号编号
–返回值:函成功返回0,失败返回-1
if (sigdelset (&sigset, SIGINT) {
perror ("sigdelset");
exit (EXIT_FAILURE);
}
sigismember
•#include
•int sigismember (const sigset_t* *sigset*, int *signum*);
–函数功能:判断信号集中是否有某信号,即检查信号集中与指定信号编号对应的信号位是否为1
–参数:信号集,信号编号
–返回值:有则返回1,没有返回0,失败返回-1
•例如
if (sigismember (&sigset, SIGINT) == 1)
printf ("信号集中有SIGINT信号\n");
递送、未决与掩码
•当信号产生时,系统内核会在其所维护的进程表中,为特定的进程设置一个与该信号相对应的标志位,这个过程就叫做递送
•信号从产生到完成递送之间存在一定的时间间隔,处于这段时间间隔中的信号状态称为未决
•每个进程都有一个信号掩码,它实际上是一个信号集,位于该信号集中的信号一旦产生,并不会被递送给相应的进程,而是会被阻塞在未决状态
屏蔽信号
•当进程正在执行类似更新数据库这样的敏感任务时,可能不希望被某些信号中断。这时可以通过信号掩码暂时屏蔽而非忽略掉这些信号。在信号处理函数执行期间,这个正在被处理的信号总是处于信号掩码中,如果又有该信号产生,则会被阻塞,直到上一个针对该信号的处理过程结束以后才会被递送
-
可以通过sigprocmask函数,检测和修改调用进程的信号掩码。
-
也可以通过sigpending函数, 获取调用进程当前处于未决状态的信号集
-
在信号处理函数的执行过程中, 这个正在被处理的信号总是处于信号掩码中。
sigprocmask函数
•#include
•int sigprocmask (int how, const sigset_t* set, sigset_t* oldset);
•how - 修改信号掩码的方式,可取以下值:
-
SIG_BLOCK: 新掩码是当前掩码和set的并集 (将set加入信号掩码);ABC+CDE => ABCDE
-
SIG_UNBLOCK: 新掩码是当前掩码和set补集的交集 (从信号掩码中删除set);ABC-CDE => AB
-
SIG_SETMASK: 新掩码即set(将信号掩码设为set)。ABC CDE => CDE
•set - NULL则忽略。
•oset - 备份以前的信号掩码,NULL则不备份。
sigpending函数
•#include
•int sigpending(sigset_t *set);
•函数功能:表示获取信号屏蔽期间来过的信号,通过参数set带出去
定时器
•运行一个进程所消耗的时间包括三个部分
-
用户时间:进程消耗在用户态的时间
-
内核时间:进程消耗在内核态的时间
-
睡眠时间: 进程消耗在等待I/O、睡眠等不被调度的时间
•系统内核为系统中的每个进程维护三个计时器
-
真实计时器:统计进程的执行时间
-
虚拟计时器:统计进程的用户时间
-
实用计时器:统计进程的用户时间和内核时间之和
为进程设定计时器
•三个系统计时器除了统计进程的各种时间以外,还可以按照各自的计时规则,以定时器的方式工作,向进程周期性地发送不同的信号
–SIGALRM (14):真实定时器到期
–SIGVTALRM (26):虚拟定时器到期
–SIGPROF (27):实用定时器到期
•定时器在可以发送信号之前,必须先行设置。每个定时器均包括两个属性,需要在设置时初始化好
–初始间隔:从设置定时器到它首次发出信号的时间间隔
–重复间隔:定时器发出的两个相邻信号之间的时间间隔
设置计时器
•#include
•int setitimer (int which, const struct itimerval* new_value, struct itimerval* old_value);
•设置计时器。成功返回0,失败返回-1。
•which - 指定哪个计时器,取值:
–ITIMER_REAL: 真实计时器;
–ITIMER_VIRTUAL: 虚拟计时器;
–ITIMER_PROF: 实用计时器。
•new_value - 新的设置。
•old_value - 旧的设置(可为NULL)。
设定计时器
•struct itimerval {
–struct timeval it_interval; // 重复间隔(每两个时钟信号的时间间隔), // 取0将使计时器在发送第一个信号后停止
–struct timeval it_value; // 初始间隔(从调用setitimer函数到第一次发送 // 时钟信号的时间间隔),取0将立即停止计时器
–};
struct timeval {
–long tv_sec; // 秒数
–long tv_usec; // 微秒数
–};
进程间通信
概念
•进程间通信(Interprocess Communication, IPC)是指两个, 或多个进程之间进行数据交换的过程。
•XSI(System Interface and Headers),代表一种Unix/Linux系统的标准
进程间的通信方式
•(1)文件
•(2)信号
•(3)管道
•(4)共享内存
•(5)消息队列(重点)
•(6)信号量
•(7)网络(重点)
管道
•管道是Unix系统最古老的进程间通信方式。
•管道本质还是文件,是一种比较特殊的文件。
•管道的特质
–其本质是一个伪文件(实为内核缓冲区,管道文件在磁盘上只有i节点没有数据块,也不保存数据)
–由两个文件描述符引用,一个表示读端,一个表示写端。可定义一个文件描述符数组,存取。
–规定数据从管道的写端流入管道,从读端流出。
–数据自己读不能自己写,数据一旦被读走,便不在管道中存在,不可反复读取。 由于管道采用半双工通信方式。因此,数据也只能在一个方向上流动。
管道的分类
•管道分为两大类:有名管道 和 无名管道
•有名管道:主要由程序员手动创建一个管道文件,实现任意两个进程间的通信
•无名管道:主要由系统创建,用于父子进程之间的通信
•历史上的管道通常是指半双工管道,只允许数据单向流动。
•现代系统大都提供全双工管道, 数据可以沿着管道双向流动。
有名管道
•有名管道(fifo):基于有名文件(管道文件)的管道通信。它的路径名存在于文件系统中。
•可以通过mkfifo命令可以创建管道文件
–形式:mkfifo 管道文件名
•可以通过管道文件让两个shell之间通信
–1打开两个终端,工作路径切换到一致
–2在其中任意一个终端创建文件
–3在A终端中使用 cat 管道文件
–4在B终端中使用 echo 文件 > 管道文件
编程模型
•基于有名管道实现进程间通信的编程模型
| 步骤 | 进程A | 函数 | 进程B | 步骤 |
|---|---|---|---|---|
| 1 | 创建管道 | mkfifo | —— | —— |
| 2 | 打开管道 | open | 打开管道 | 1 |
| 3 | 读写管道 | read/write | 读写管道 | 2 |
| 4 | 关闭管道 | close | 关闭管道 | 3 |
| 5 | 删除管道 | unlink | —— | —— |
•其中除了mkfifo函数是专门针对有名管道的,其它函数都与操作普通文件没有任何差别
•有名管道是文件系统的一部分,如不删除,将一直存在
创建有名管道文件
•#include
•int mkfifo(const char* *pathname*, mode_t *mode*);
•函数功能:创建有名管道文件
•参数
–pathname:文件路径
–mode:权限模式
•返回值:成功返回0,失败返回-1
无名管道
•无名管道(pipe):适用于父子进程之间的通信。
•#include
•int pipe (int pipefd[2]);
•函数功能:通过输出参数pipefd返回两个文件描述符,其中pipefd[0]用于读,pipefd[1]用于写
•返回值:成功返回0,失败返回-1。
无名管道的使用
•A. 调用该函数在内核中创建管道文件,并通过其输出参数, 获得分别用于读和写的两个文件描述符;
•B. 调用fork函数,创建子进程;
•C. 写数据的进程关闭读端(pipefd[0]), 读数据的进程关闭写端(pipefd[1]);
•D. 传输数据;
•E. 父子进程分别关闭自己的文件描述符。
XSI进程间通信
•XSI IPC源自于system V的IPC功能。
•有三种IPC我们称作XSI IPC,即消息队列、信号量以及共享存储器,它们之间有很多相似之处。
•共享内存,消息队列,信号量它们三个都是找一个中间介质,来进行通信的,这种介质多的是。但是必须保证唯一,就像身份证。
IPC对象的标识符和键
•为了实现进程之间的数据交换,系统内核会为参与通信的诸方维护一个内核对象(类似一个结构体变量),记录和通信有关的各种配置参数和运行时信息,谓之IPC对象。
•系统中的每个IPC对象都有唯一的,非负整数形式的标识符(ID),所有与IPC相关的操作,都需要提供IPC对象标识符。IPC对象通过它的标识符来引用和访问通信通道
•与文件描述符不同,IPC标识在使用时会持续加1, 当达到最大值时,向0回转。(65535)
IPC对象的标识符和键
•IPC的标识符只解决了内部访问一个IPC对象的问题,如何让多个进程都访问某一个特定的IPC对象还需要一个外部键(key),每一个IPC对象都与一个键相关联 。
•无论何时,只要创建IPC对象,就必须指定一个键值。
•键值的数据类型在sys/types.h头文件中被定义为key_t,其原始类型就是长整型。
IPC对象的会(汇)合
•键值到标识符的转换是由系统内核来维护的。当有了一个IPC对象的键值,如何让多个进程知道这个键?大致有三种方式
IPC对象的会合方式
•服务器进程可以用IPC_PRIVATE宏(通常被定义为0)作为键创建一个新的IPC对象,将返回的标识符放在某处,例如一个文件中,以方便客户机取用。IPC_PRIVATE宏可以保证所得到的IPC对象一定是新建的,而不是现有的
–IPC对象标识符可以被fork函数产生的子进程直接引用,也可以作为命令行参数或者环境变量的一部分被exec函数传递给新创建的进程,这样就避免了读写文件之类的开销。
•将键作为宏或者外部变量定义在一个公共头文件中。服务器和客户机都包含该头文件,服务器用这个键创建IPC对象,而客户机用这个键获取服务器所创建的IPC对象
–键可能已经与某个现有的IPC对象结合,服务器在创建IPC对象时必须处理这种情况,比如删除现有的对象后再重试
•服务器和客户机用一对约定好的路径和项目ID(0-255),通过ftok函数合成一个键,用于创建和获取IPC对象
•#include
•key_t ftok (const char* pathname, int proj_id);
•成功返回可用于创建或获取IPC对象的键,失败返回-1
–pathname:一个真实存在的路径名
–proj_id:项目ID,仅低8位有效,取0到255之间的数
ftok函数详解
•ftok创建的键通常是下列方式构成的:
–获取第一个参数的stat结构从该结构中取st_dev和st_ino字段,然后再与项目ID组合起来。
•ftok的参数注意
–ftok根据路径名,提取文件信息,再根据这些文件信息及id合成key,该路径可以随便设置。
–pathname指定的目录或文件必须存在的,ftok只是根据文件inode在系统内的唯一性来取一个数值,和文件的权限无关。
–id是可以根据自己的约定,随意设置。在UNIX系统上,它的取值是1到255。
XSI ipc的实现步骤
•获取ipc对象的键值(通过IPC_PRIVATE宏,指定公共文件,ftok函数生成)
•创建/获取IPC对象(共享内存,消息队列,信号量),获取ipc标识
•加载通信内存/队列/信号
•读写操作
•销毁通信内存/队列/信号
相关命令
•ipcs可用来显示当前Linux系统中的共享内存段、信号量集、消息队列等的使用情况。命令示例:
•ipcs -a或ipc 显示当前系统中共享内存段、信号量集、消息队列的使用情况;
•ipcs -m 显示共享内存段的使用情况;
•ipcs -s 显示信号量集的使用情况;
•ipcs -q 显示消息队列的使用情况;
•ipcs –p 命令可以得到与共享内存、消息队列相关进程之间的消息
•ipcs -u命令可以查看各个资源的使用总结信息。
•ipcs -l命令可以查看各个资源的系统限制信息。
共享内存
•两个或者更多进程,共享同一块由系统内核负责维护的内存区域,其地址空间通常被映射到堆和栈之间(MMAP)

•多个进程通过共享内存通信,所传输的数据通过各个进程的虚拟内存被直接反映到同一块物理内存中,这就避免了在不同进程之间来回复制数据的开销。因此,基于共享内存的进程间通信,是速度最快的进程间通信方式
•共享内存本身缺乏足够的同步机制,这就需要程序员编写额外的代码来实现。例如服务器进程正在把数据写入共享内存,在这个写入过程完成之前,客户机进程就不能读取该共享内存中的数据。为了建立进程之间的这种同步,可能需要借助于其它的进程间通信机制,如信号或者信号量等,甚至文件锁,而这无疑会增加系统开销
编程模型
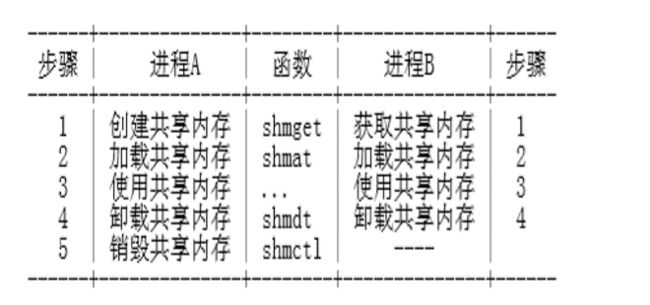
shmget
•#include
•int shmget (key_t key, size_t size, int shmflg);
•函数功能:创建新的或获取已有的共享内存
•成功返回共享内存标识符,失败返回-1。
shmget参数详解
•Key:该函数以key参数为键值创建共享内存, 或获取已有的共享内存。Key为ftok返回值
•size参数为共享内存的字节数,建议取内存页字节数(4096)的整数倍。若希望创建共享内存,则必需指定size参数。若只为获取已有的共享内存,则size参数可取0。
•shmflg取值:
–0 - 获取,不存在即失败。
–IPC_CREAT - 创建,不存在即创建,已存在即获取,
–IPC_EXCL - 排斥,已存在即失败
–mode: - 权限
shmat
•#include
•void *shmat(int shmid, const void *addr, int flag);
•功能:加载共享内存
•shmid:共享存储的id shmget函数的返回值
•addr:一般为0,表示连接到由内核选择可用地址上,否则,如果flag没有指定SHM_RND,则连接到addr所指定的地址上.
Flag:0- 以读写方式使用共享内存.SHM_RDONLY - 以只读方式使用共享内存.SHM_RND - 只在shmaddr参数非NULL时起作用。 表示对该参数向下取内存页的整数倍作为映射地址。
返回值:如果成功,返回共享存储段地址,出错返回-1
•shmat函数负责将给定共享内存映射到调用进程的虚拟内存空间,返回映射区的起始地址,同时将系统内核中共享内存对象的加载计数(shmid_ds::shm_nattch)加一
•调用进程在获得shmat函数返回的共享内存起始地址以后,就可以象访问普通内存一样访问共享内存中的数据
shmdt
•#include
•int shmdt(void *addr);
•功能:shmdt函数负责从调用进程的虚拟内存中解除shmaddr所指向的映射区到共享内存的映射,同时将系统内核中共享内存对象的加载计数(shmid_ds::shm_nattch)减一。
•成功返回0,失败返回-1。
shmctl
•#include
•int shmctl (int shmid, int cmd, struct shmid_ds* buf);
•功能:销毁或控制共享内存
•返回值:成功返回0,失败返回-1
Shmctl参数
–cmd:控制命令,可取以下值
IPC_STAT-获取共享内存的属性,通过buf参数输出
IPC_SET-设置共享内存的属性,通过buf参数输入,仅以下三个属性可以设置
shmid_ds::shm_perm.uid** // 拥有者用户ID**
shmid_ds::shm_perm.gid // 拥有者组ID**
shmid_ds::shm_perm.mode** // 权限**
IPC_RMID - 销毁共享内存。其实并非真的销毁,而只是做一个销毁标记,禁止任何进程对该共享内存形成新的加载,但已有的加载依然保留。只有当其使用者们纷纷卸载,直至其加载计数降为0时,共享内存才会真的被销毁
–buf:shmid_ds类型的共享内存属性结构
shmid_ds结构
• shmid_ds数据结构表示每个新建的共享内存。
struct shmid_ds {
struct ipc_perm shm_perm; // 所有者及其权限
size_t shm_segsz; // 大小(以字节为单位)
time_t shm_atime; // 最后加载时间
time_t shm_dtime; // 最后卸载时间
time_t shm_ctime; // 最后改变时间
pid_t shm_cpid; // 创建进程PID
pid_t shm_lpid; // 最后加载/卸载进程PID
shmatt_t shm_nattch; // 当前加载计数 有多少个进程正在使用这块内存
};
ipc_perm结构
•对于每个IPC对象,系统共用一个struct ipc_perm的数据结构来存放权限信息,以确定一个ipc操作是否可以访问该IPC对象。
struct ipc_perm {
–key_t __key; // 键值
–uid_t uid; // 有效属主ID
–gid_t gid; // 有效属组ID
–uid_t cuid; // 有效创建者ID
–gid_t cgid; // 有效创建组ID
–unsigned short mode; // 权限字
–unsigned short __seq; // 序列号
};
消息队列
•消息队列是由消息组成由消息队列标识符标识的链表,存放在内核中由系统内核负责存储和管理.(消息队列,就是一个消息的链表,把每次要进行传递的消息/数据按照固定的格式写成一个结构体,由内核存储,维护成一个队列链表)。
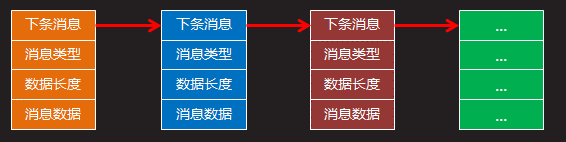
•消息队列中的每个消息单元除包含消息数据外,还包含消息类型和数据长度。内核为每个消息队列,维护一个msqid_ds结构体形式的消息队列对象。
•相较于其它几种IPC机制,消息队列具有明显的优势
•流量控制
–如果系统资源(内存)短缺或者接收消息的进程来不及处理更多的消息,则发送消息的进程会在系统内核的控制下进入睡眠状态,待条件满足后再被内核唤醒,继续之前的发送过程
•面向记录
–每个消息都是完整的信息单元,发送端是一个消息一个消息地发,接收端也是一个消息一个消息地收,而不象管道那样收发两端所面对的都是字节流,彼此间没有结构上的一致性
消息队列特点
•类型过滤
–先进先出是队列的固有特征,但消息队列还支持按类型提取消息的做法,这就比严格先进先出的管道具有更大的灵活性
•天然同步
–消息队列本身就具备同步机制,空队列不可读,满队列不可写,不发则不收,无需象共享内存那样编写额外的同步代码
编程模型
| 步骤 | 进程A | 函数 | 进程B | 步骤 |
|---|---|---|---|---|
| 1 | 创建消息队列 | msgget | 获取消息队列 | 1 |
| 2 | 发送接收消息 | msgsnd/msgrcv | 发送接收消息 | 2 |
| 3 | 销毁消息队列 | msgctl | ---- |
•可以通过msgget函数创建一个新的消息队列,或获取一个已有的消息队列。通过msgsnd函数向消息队列的后端追加消息,通过msgrcv函数从消息队列的前端提取消息。
创建/获取消息队列 msgget
•#include
•int msgget (key_t key, int msgflg);
•功能:该函数以key参数为键值创建消息队列,或获取已有的消息队列。
•msgflg取值:
•0 - 获取,不存在即失败。
•IPC_CREAT - 创建,不存在即创建,已存在即获取,除非…
•IPC_EXCL - 排斥,已存在即失败。
•成功返回消息队列标识,失败返回-1
向消息队列发送消息msgsnd
•int msgsnd (int msqid, const void* msgp, size_t msgsz, int msgflg);
•msgp参数指向一个包含消息类型和消息数据的内存块。该内存块的前4个字节必须是一个大于0的整数, 代表消息类型,其后紧跟消息数据。消息数据的字节长度用msgsz参数表示。
•注意:msgsz参数并不包含消息类型的字节数(4)。
向消息队列发送消息1
•若内核中的消息队列缓冲区有足够的空闲空间,则此函数会将消息拷入该缓冲区并立即返回0,表示发送成功,否则此函数会阻塞,直到内核中的消息队列缓冲区有足够的空闲空间为止(比如有消息被接收)。
•若msgflg参数包含IPC_NOWAIT位,则当内核中的消息队列缓冲区没有足够的空闲空间时,此函数不会阻塞,而是返回-1,errno为EAGAIN。
•成功返回0,失败返回-1
从消息队列接受消息
•ssize_t msgrcv (int msqid, void* msgp, size_t msgsz, long msgtyp, int msgflg);
•msgp参数指向一个包含消息类型(4字节),和消息数据的内存块,其中消息数据缓冲区的字节大小用msgsz参数表示。
•若所接收到的消息数据字节数大于msgsz参数,即消息太长,且msgflg参数包含MSG_NOERROR位,则该消息被截取msgsz字节返回,剩余部分被丢弃。
•若msgflg参数不包含MSG_NOERROR位,消息又太长, 则不对该消息做任何处理,直接返回-1,errno为E2BIG。
从消息队列接受消息1
•msgtyp参数表示期望接收哪类消息:
•=0 - 返回消息队列中的第一条消息。
•>0 - 若msgflg参数不包含MSG_EXCEPT位,则返回消息队列中第一个类型为msgtyp的消息;若msgflg参数包含MSG_EXCEPT位,则返回消息队列中第一个类型不为msgtyp的消息。
•<0 - 返回消息队列中类型小于等于msgtyp的绝对值的消息。若有多个,则取类型最小者。
•E. 若消息队列中有可接收消息,则此函数会将该消息移出消息队列并立即返回0,表示接收成功,否则此函数会阻塞,直到消息队列中有可接收消息为止。
从消息队列接受消息2
•F. 若msgflg参数包含IPC_NOWAIT位, 则当消息队列中没有可接收消息时,此函数不会阻塞, 而是返回-1,errno为ENOMSG。
•成功返回所接收到的消息数据的字节数,失败返回-1。
销毁/控制消息队列msgctl
•int msgctl (int msqid, int cmd, struct msqid_ds* buf);
•cmd取值:IPC_STAT - 获取消息队列的属性,通过buf参数输出。IPC_SET - 设置消息队列的属性,通过buf参数输入,
–msqid_ds::msg_perm.uid msqid_ds::msg_perm.gid msqid_ds::msg_perm.mode msqid_ds::msg_qbytes
•IPC_RMID - 立即删除消息队列。此时所有阻塞在对该消息队列的,msgsnd和msgrcv函数调用,都会立即返回失败,errno为EIDRM。
•成功返回0,失败返回-1。
销毁/控制消息队列msqid_ds
struct msqid_ds {
–struct ipc_perm msg_perm; // 权限信息
–time_t msg_stime; // 随后发送时间
–time_t msg_rtime; // 最后接收时间
–time_t msg_ctime; // 最后改变时间
–unsigned long __msg_cbytes; //消息队列中的字节数
–msgqnum_t msg_qnum; // 消息队列中的消息数
–msglen_t msg_qbytes; //消息队列能容纳最大字节数
–pid_t msg_lspid; // 最后发送进程PID
–pid_t msg_lrpid; // 最后接收进程PID
};
销毁/控制消息队列
struct ipc_perm {
–key_t __key; // 键值
–uid_t uid; // 有效属主ID
–gid_t gid; // 有效属组ID
–uid_t cuid; // 有效创建者ID
–gid_t cgid; // 有效创建组ID
–unsigned short mode; // 权限字
–unsigned short __seq; // 序列号
};
网络编程
什么是计算机网络?
计算机网络,是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统、网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统
什么是网络协议?
网络协议是一种特殊的软件,是计算机网络实现其功能的最基本的机制。网络协议的本质就是规则,即各种硬件和软件必须遵循的共同守则。网络协议并不是一套单独的软件,它融合于其它所有的软件甚至硬件系统中,因此可以说协议在网络中无所不在
什么是协议栈?
为了减少网络设计的复杂性,绝大多数网络采用分层设计的方法。所谓分层设计,就是按照信息的流动过程将网络的整体功能分解为一个个的功能层,不同机器上的同等功能层之间采用相同的协议,同一机器上的相邻功能层之间通过接口进行信息传递。各层的协议和接口统称为协议栈
ISO/OSI网络协议模型
描述计算机网络各协议层的一般方法是采用国际标准化组织(International Standardization Organization, ISO)的计算机通信开放系统互连(Open System Interconnection, OSI)模型,简称ISO/OSI网络协议模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zrwShKcu-1615732028969)(E:\2020大二\uc10png.png)]
TCP/IP协议族
- TCP/IP不是个单一的网络协议,而是由一组具有层次关系的网络协议组成的协议家族,简称TCP/IP协议族
- TCP:传输控制协议,面向连接,可靠的全双工的字节流
- UDP:用户数据报协议,无连接,不如TCP可靠但速度快
- ICMP:网际控制消息协议,处理路由器和主机间的错误和控制消息
- IGMP:网际组管理协议,用于多播
- IPv4:网际协议版本4,使用32位地址,为TCP、UDP、CMP和IGMP提供递送分组服务
- IPv6:网际协议版本6,使用128位地址,为TCP、UDP和ICMPv6提供递送分组服务通常所说的TCP、UDP和ICMP等协议都是工作在IP协议之上的,IP协议作为它们的基础协议为其提供服务支撑
消息包与消息流
-
应用程序负责组织的通常都是与业务相关的数据内容,而要想把这些数据内容通过网络发送出去,就要将其自上向下地压入协议栈,每经历一个协议层,就会对数据做一层封包,每一层输出的封包都是下一层输入的内容,消息包沿着协议栈的运动形成了消息流
-
当从网络上接收数据时,过程刚好相反,消息包自下向上地流经协议栈,每经历一个协议层,就会对输入的数据解一层封包,经过层层解包以后,应用程序最终得到的将只是与业务相关的数据内容
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lZ6rMWG4-1615732028970)(E:\2020大二\uc11.png)]
IP地址
什么是IP地址?
- IP地址,全称网际协议地址(Internet Protocol Address),是IP协议提供的一种统一的地址格式,为互联网上的每个网络和每台主机分配一个逻辑地址,借以消除物理地址差异性所带来的影响
IP地址如何表示?
-
在计算机内部,IP地址用一个32位无符号整数表示,如:0x01020304。如无特别说明本课程只讨论IPv4的情况
-
人们更习惯使用点分十进制字符串表示,如:1.2.3.4。字符串形式的从左到右,对应整数形式的从高字节到低字节。注意这里所说的高低指的是数位高低而非地址高低。
IP地址分级
- 什么是IP地址分级?
- A级地址:以0为首的8位网络地址+24位本地地址
- B级地址:以10为首的16位网络地址+16位本地地址
- C级地址:以110为首的24位网络地址+8为本地地址
- D级地址:以1110为首的32位多播地址
-
例如:某台计算机的IP地址:192.168.182.48,写成整数形式:11000000 10101000 10110110 00110000,C级地址,网络地址:192.168.182.0,本地地址:48
-
INADDR_ANY:0.0.0.0
Mac地址
- MAC地址也叫物理地址、硬件地址,由网络设备制造商生产时烧录在网卡上的。
- MAC地址的长度为48位(6B),通常表示为12个16进制数,如:00-16-EA-AE-3C-40就是一个MAC地址,其中前3个字节,16进制数00-16-EA代表网络硬件制造商的编号,它由IEEE分配,而后3个字节,16进制数AE-3C-40代表该制造商所制造的网卡的系列号。只要不更改自己的MAC地址,MAC地址在世界是唯一的。
- IP地址是指Internet协议使用的地址,而MAC地址是Ethernet协议使用的地址。在OSI模型中,第三层网络层负责IP地址,第二层数据链路层则负责MAC地址。因此一个主机会有一个MAC地址,而每个网络位置会有一个专属于它的IP地址。IP就像是房间号,MAC地址就像是身份证号码。
端口号
-
如前所述,通过IP地址可以定位网络上的一台主机,但一台主机上可能同时有多个网络应用在运行,究竟想跟哪个网络应用通信呢?这就需要靠所谓的端口号来区分,因为不同的网络应用会使用不同的端口号。用IP地址定位主机,再用端口号定位运行在这台主机上一个具体的网络应用,这样一种对通信主体的描述才是唯一确定的
-
套接字接口库中的端口号被定义为一个16位的无符号整数,其值介于0到65535,其中0到1024已被系统和一些网络服务占据,比如21端口用于ftp服务、23端口用于telnet服务、80端口用于www服务等,因此一般应用程序最好选择1024以上的端口号,以避免和这些服务冲突
字节序
-
电脑的大小端
- 小端系统:使用低位内存地址存放低位字节数据
- 大端系统:使用低位内存地址存放高位字节数据
- 如: 0x12345678
- 小端系统中按照地址从小到大:0x78 0x56 0x34 0x12
- 大端系统中按照地址从小到大:0x12 0x34 0x56 0x78
-
网络字节序:
- 为了兼容不同的系统对多字节整数的存放问题,一般来说,在发送数据之前需要将原始数据转换为网络字节序,而在接受数据之后,需要将接受到的数据转换为主机字节序其中网络字节序,本质就是大端系统的字节序。
伯克利套接字
美国加利福尼亚大学伯克利分校(University of California-Berkeley, UC Berkeley)于1983年发布4.2BSD Unix系统。其中包含一套用C语言编写的应用程序开
发库。该库既可用于在同一台计算机上实现进程间通信,也可用于在不同计算机上实现网络通信。当时的Unix还受AT&T的专利保护,因此直到1989年,伯克利大学才能自由发布他们的操作系统和网络库,而后者即被称为伯克利套接字应用编程接口(Berkeley Socket APIs)伯克利套接字接口的实现完全基于TCP/IP协议,因此它是构建一切互联网应用的基石。几乎所有现代操作系统都或多或少有一些源自伯克利套接字接口的实现。它已成为应用程序连接互联网的标准接口
套接字?
- 套接字(socket)的本意是指电源插座,这里将其引申为一个基于TCP/IP协议可实现基本网络通信功能的逻辑对象机器与机器的通信,或者进程与进程的通信,在这里都可以被抽象地看作是套接字与套接字的通信应用程序编写者无需了解网络协议的任何细节,更无需知晓系统内核和网络设备的运作机制,只要把想发送的数据写入套接字,或从套接字中读取想接收的数据即可
- 从这个意义上讲,套接字就相当于一个文件描述符,而网络就是一种特殊的文件,面向网络的编程与面向文件的编程已没有分别,而这恰恰是Unix系统一切皆文件思想的又
- 一例证。套接字是对ISO/OSI网络协议模型中传输层及其以下诸层的逻辑抽象,是对TCP/IP网络通信协议的高级封装,因此无论所依赖的是什么硬件,所运行的什么操作系统,所使用的是什么编程语言,只要是基于套接字构建的应用程序,只要是在互联网环境中通信,就不会存在任何障碍。这被称为套接字的异构性。
绑定
如前所述,套接字是一个提供给程序员使用的逻辑对象,它表示对ISO/OSI网络协议模型中传输层及其以下诸层的抽象。但真正发送和接收数据的毕竟是那些实实在在的物理设备。这就需要在物理设备和逻辑对象之间建立一种关联,使后续所有针对这个逻辑对象的操作,最终都能够反映到实际的物理设备上。建立这种关联关系的过程就叫做绑定
链接
绑定只是把套接字对象和一个代表自己的物理设备关联起来。但为了实现通信还需要把自己的物理设备与对方的物理设备关联起来。只有这样才能建立起一种以物理设备为媒介的,跨越不同进程甚至机器的,多个套接字对象之间的联系。建立这种联系的过程就叫做连接
通信模式-单播模式
每个数据包发往单个目的主机,目的地址指明单个接收者服务器可以及时响应客户机的请求
服务器可以针对不同客户的不同请求提供个性化的服务
通信模式-多播模式
网络中的主机可以向路由器请求加入或退出某个组,路器和交换机有选择地复制和转发数据,只将组内数据转发给那些加入组的主机需要相同信息的客户机只要加入同一个组即可共享同一份数据,降低了服务器和网络的流量负载既能一次将数据传输给多个有需要的主机,又能保证不影响其它不需要的主机多播包可以穿越路由器,并在穿越中逐渐衰减缺乏纠错机制,丢包错包在所难免
通信模式-广播模式
一台主机向网上的所有其它主机发送数据无需路径选择,设备简单,维护方便,成本低廉服务器不用向每个客户机单独发送数据,流量负载极低无法针对具体客户的具体要求,及时提供个性化服务网络无条件地复制和转发每一台主机产生的信息所有的主机可以收到所有的信息,而不管是否需要,网络资源利用率低,带宽浪费严重禁止广播包穿越路由器,防止在更大范围内泛滥
网络编程函数
socket
#include
int socket(int domain,int type,int protocol);
•功能:简历socket通信对象
•第一个参数:域/协议族 决定是本地通信还是网络通信AF_UNIX/AF_LOCAL-本地通信AF_INET-基于IPv4的网络通信AF_INET6-基于IPv6的网络通信
•第二个参数:类型,决定是采用的通信协议 SOCK_STREAM - 数据流方式的通信,基于TCP协议 SOCK_DGRAM - 数据报方式的通信,基于UDP协议
•第三个参数:特殊协议,一般给0即可
•返回值:成功返回新的描述符,失败返回-1函数功能:主要用于创建socket来进行通信
通信地址的结构体类型-基本结构体类型
•基本地址结构,本身没有实际意义,仅用于泛型化参数
struct sockaddr {
sa_family_t sa_family; //协议族
char sa_data[14];//字符串的地址数据
}
注意: 该结构体主要用于作为函数的参数类型,很少去定义结构体变量进行使用。
通信地址的结构体类型-本地通信结构体类型
•本地地址结构,用于AF_LOCAL/AF_UNIX域的本地通信
include
struct sockaddr_un{
sa_family_t sun_family;//协议族
char sun_path[];//socket文件的路径
};
通信地址的结构体类型-网络通信结构体类型*
•网络地址结构,用于AF_INET域的IPv4网络通信
#include
struct sockaddr_in{
sa_family_t sin_family;//AF_INET.
in_port_t sin_port;//端口号
struct in_addr sin_addr;//IP地址
};
struct in_addr{
in_addr_t s_addr;//整数类型的IP地址
};
bind函数
#include
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
•函数功能:主要用于绑定socket和通信地址
•第一个参数:socket描述符,socket函数的返回值
•第二个参数:通信地址,需要做类型转换
•第三个参数:通信地址的大小,使用sizeof计算即可。
•返回值:成功返回0,失败返回-1
•注意:套接字接口库中的很多函数都用到地址结构,但为了同时支持不同的地址结构类型,其参数往往都会选择更一般化的sockaddr类型的指针,使用时需要强制类型转换
connect函数
#include
int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
•函数功能:主要用于连接socket和通信地址
•第一个参数:socket描述符,socket函数的返回值
•第二个参数:通信地址,需要做类型转换
•第三个参数:通信地址的大小,使用sizeof计算即可。
•返回值:成功返回0,失败返回-1
•注意:套接字接口库中的很多函数都用到地址结构,但为了同时支持不同的地址结构类型,其参数往往都会选择更一般化的sockaddr类型的指针,使用时需要强制类型转换
write函数
#include
ssize_t write (int sockfd, const void* buf, size_t count);
•函数功能:通过套接字发送字节流
•第一个参数:socket描述符,socket函数的返回值
•第二个参数:内存缓冲区,要发送的数据
•第三个参数:期望发送的数据的字节数。
•返回值:成功返回实际发送的字节数,失败返回-1
read函数
#include
ssize_t write (int sockfd, const void* buf, size_t count);
•函数功能:通过套接字读取发送来字节流
•第一个参数:socket描述符,socket函数的返回值
•第二个参数:内存缓冲区,保存读取的数据
•第三个参数:期望读取的数据的字节数。
•返回值:成功返回实际读取的字节数,失败返回-1
字节转换
#include
uint32_t htonl(uint32_t hostlong); => 主要用于将32位的主机字节序转换为网络字节序
uint16_t htons(uint16_t hostshort); => 主要用于将16位的主机字节序转换为网络字节序
uint32_t ntohl(uint32_t netlong); => 主要用于将32位的网络字节序转换为主机字节序
uint16_t ntohs(uint16_t netshort); => 主要用于将16位的网络字节序转换为主机字节序
IP地址相关
#include
#include
in_addr_t inet_addr(const char *ip);
•函数功能:主要用于将字符串形式的IP地址转换为整数类型
•参数:点分十进制字符串形式的IP地址
•返回值:网络字节序32位无符号整数
char* inet_ntoa (struct in_addr in);
•函数功能:网络字节序32位无符号整数->点分十进制字符串
•参数: 32位无符号整数形式IP地址
•返回值:返回点分十进制字符串形式的IP地址
基于socket进程间通信模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IbK1teh5-1615732028971)(E:\2020大二\uc12.png)]
网络通信模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UtD11jdY-1615732028971)(E:\2020大二\uc13.png)]
TCP
TCP协议
•TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议
•在简化的计算机网络OSI模型中,它完成第四层传输层所指定的功能。
TCP提供客户机与服务器的连接
•一个完整TCP通信过程需要依次经历三个阶段
- 首先,客户机必须建立与服务器的连接,所谓虚电路
- 然后,凭借已建立好的连接,通信双方相互交换数据
- 最后,客户机与服务器双双终止连接,结束通信过程
TCP保证数据传输的可靠性
TCP的协议栈底层在向另一端发送数据时,会要求对方在一个给定的时间窗口内返回确认。如果超过了这个时间窗口仍没有收到确认,则TCP会重传数据并等待更长的时间。只有在数次重传均告失败以后,TCP才会最终放弃。TCP含有用于动态估算数据往返时间(Round-Trip Time, RTT)的算法,因此它知道等待一个确认需要多长时间
TCP提供流量控制
TCP的协议栈底层在从另一端接收数据时,会不断告知对方它能够接收多少字节的数据,即所谓通告窗口。任何时候,这个窗口都反映了接收缓冲区可用空间的大小,从而确保不会因为发送方发送数据过快而导致接收缓冲区溢出
TCP是全双工的
在给定的连接上,应用程序在任何时候都既可以发送数据也可以接收数据。因此,TCP必须跟踪每个方向上数据流的状态信息,如序列号和通告窗口的大小
TCP建立连接过程*
- 被动打开
服务器必须首先做好准备随时接受来自客户机的连接请求
- 三路握手
客户机的TCP协议栈向服务器发送一个SYN分节,告知对方自己将在连接中发送数据的初始序列号,谓之主动打开服务器的TCP协议栈向客户机发送一个单个分节,其中不仅包括对客户机SYN分节的ACK应答,还包含服务器自己的SYN分节,以告知对方自己在同一连接中发送数据的初始序列号客户机的TCP协议栈向服务返回ACK应答,以表示对服务器所发SYN的确认
TCP数据交换过程
- 一旦连接建立,客户机即可构造请求包并发往服务器
- 服务器接收并处理来自客户机的请求包,构造响应包服务器向客户机发送响应包,同时捎带对客户机请求包的ACK应答。但如果服务器处理请求和构造响应的时间长于200毫秒,则应答也可能先于响应发出
- 客户机接收来自服务器的响应包,同时向对方发送ACK应答
TCP终止连接的过程
-
客户机或者服务器主动关闭连接,TCP协议栈向对方发送FIN分节,表示数据通信结束。如果此时尚有数据滞留于发送缓冲区中,则FIN分节跟在所有未发送数据之后
-
接收到FIN分节的另一端执行被动关闭,一方面通过TCP协议栈向对方发送ACK应答,另一方面向应用程序传递文件结束符。如果此时接收缓冲不空,则将所接收到的FIN分节追加到接收缓冲区的末尾
-
一段时间以后,方才接收到FIN分节的进程关闭自己的连接,同时通过TCP协议栈向对方发送FIN分节
-
对方在收到FIN分节后发送ACK应答
侦听
启动侦听
#include
int listen (int sockfd, int **backlog);
成功返回0,失败返回-1
•在指定套接字上启动对连接请求的侦听
-
sockfd:套接字描述符
-
backlog:未决连接请求的最大值
-
socket函数所创建的套接字一律被初始化为主动套接字,即可以通过后续connect函数调用向服务器发起连接请求的客户机套接字。listen函数可以将一个这样的主动套接字转换为被动套接字,即可以等待并接受来自客户机的连接请求的服务器套接字
- 被listen函数启动侦听的套接字将由CLOSED状态转入LISTEN状态
- 客户机调用connect函数即开启了TCP连接建立的第一路握手:通过协议栈向服务器发送SYN分节。服务器的LISTEN套接字一旦收到该分节,即创建一个新的处于SYN_RCVD状态的套接字,并将其排入未完成连接队列
- 服务器的TCP协议栈不断监视未完成连接队列的状态,并在适当的时机依次处理其中等待连接的套接字。一旦某个套接字上的第二、三路握手完成,由SYN_RCVD状态转入ESTABLISHED状态,即被移送到已完成连接队列
- 两个队列中的套接字个数之和不能超过backlog参数值
- 若未完成连接队列和已完成连接队列中的套接字个数之和已经达到backlog,此时又有客户机通过connect函数发起连接请求,则该请求所产生的SYN分节将被服务器的TCP协议栈直接忽略。客户机的TCP协议栈会因第一路握手应答超时而重发SYN分节,期望不久能在未决队列中找到空闲位置。若多次重发均告失败,则客户机放弃,connect函数返回失败
- 客户机对connect函数的调用在第二路握手完成时即返回,而此时服务器连接套接字可能还在未完成连接队列(第三路握手尚未完成)或已完成连接对列(套接字尚未返回给用户进程)中。这种情况下客户机发送的数据,会被服务器的TCP协议栈排队缓存,直到接收缓冲区满为止
等待连接
#include
int accept (int sockfd, struct socklen_t* addr,socklen_t* addrlen)
成功返回连接套接字描述符,失败返回-1
•在指定套接字上等待并接受连接请求
•sockfd:侦听套接字描述符
•addr:输出连接请求发起者地址结构
•addrlen:输入/输出,连接请求发起者地址结构长度(以字节为单位)
- accept函数由TCP服务器调用,返回排在已完成连接队列首部的连接套接字对象的描述符,若队列为空则阻塞
- 若accept函数执行成功,则通过addr和addrlen向调用者输出发起连接请求的客户机的协议地址及其字节长度。注意addrlen既是输入参数也是输出参数。调用accept函数时,指针addrlen所指向的变量被初始化为addr结构体的字节大小;等到该函数返回时,该指针的目标则被更新为系统内核保存在addr结构体内的实际字节数
- accept函数成功返回的是一个有别于其参数套接字,由系统内核自动生成的全新套接字描述符。它代表与客户机的TCP连接,因此被称为连接套接字,而该函数的第一个参数则被称为侦听套接字。通常一个服务器只有一个侦听套接字,且一直存在直到服务器关闭,而连接套接字则是一个客户机一个,专门负责与该客户机的通信
接收数据
#include
ssize_t recv (int sockfd, void* buf, size_t len, int flags);
成功返回连接套接字描述符,失败返回-1
–sockfd:套接字描述符
–buf:应用程序接收缓冲区
–len:期望接收的字节数
•通过指定套接字接收数据
flags:接收标志,一般取0,还可取以下值
MSG_DONTWAIT - 以非阻塞方式接受数据
MSG_OOB - 接收带外数据
MSG_PEEK - 只查看可接收的数据,函数返回后数据依然留在接收缓冲区中
MSG_WAITALL - 等待所有数据,即不接收到len字节的数据,函数就不返回
-
如前所述,客户机或者服务器主动关闭连接,TCP协议栈向对方发送FIN分节,表示数据通信结束,接收到FIN分节的另一端执行被动关闭,一方面通过TCP协议栈向对方发送ACK应答,另一方面向应用程序传递文件结束符,此时recv函数返回0
-
阻塞与非阻塞
- 套接字I/O的缺省方式都是阻塞的。对于TCP而言,如果接收缓冲区中没有数据,recv函数将会阻塞,直到有数据到来并被复制到buf缓冲区时才会返回。此时所接收到的数据可能比len参数期望接收的字节数少。除非调用recv函数时使用MSG_WAITALL标志,不接收到len字节的数据,函数就不返回。但即便使用了MSG_WAITALL标志,实际接收到的字节数在以下三种情况下仍然可能比期望的少
- 函数被信号中断
- 连接被对方终止
- 发生套接字错误
- 套接字I/O的缺省方式都是阻塞的。对于TCP而言,如果接收缓冲区中没有数据,recv函数将会阻塞,直到有数据到来并被复制到buf缓冲区时才会返回。此时所接收到的数据可能比len参数期望接收的字节数少。除非调用recv函数时使用MSG_WAITALL标志,不接收到len字节的数据,函数就不返回。但即便使用了MSG_WAITALL标志,实际接收到的字节数在以下三种情况下仍然可能比期望的少
-
MSG_DONTWAIT标志令接收过程以非阻塞方式进行,即便收不到数据,recv函数也会立即返回,返回值为-1,errno为EAGAIN或EWOULDBLOCK
char buf[1024];
ssize_t rcvd = recv (connfd, buf, sizeof (buf), 0);
if (rcvd == -1)
{
perror ("recv");
exit (EXIT_FAILURE);
}
if (rcvd == 0)
{
printf ("客户机已关闭连接\n");
exit (EXIT_SUCCESS);
}
buf[rcvd] = '\0';
printf ("%s\n", buf);
发送数据
#include
ssize_t send(int sockfd,const void *buf,size_t len,int flags);
–sockfd:套接字描述符
–buf:应用程序发送缓冲区
–len:期望发送的字节数
•通过指定套接字发送数据
–flags:发送标志,一般取0,还可取以下值
MSG_DONTWAIT - 以非阻塞方式发送数据
MSG_OOB - 发送带外数据
MSG_DONTROUTE - 不查路由表,直接在本地网络中寻找目的主机
•阻塞与非阻塞
–套接字I/O的缺省方式都是阻塞的。对于TCP而言,如果发送缓冲区中没有足够的空闲空间,send函数将会阻塞,直到其空闲空间足以容纳len字节的待发送数据,并在将全部待发送数据复制到发送缓冲区后才会返回
–MSG_DONTWAIT标志令发送过程以非阻塞方式进行,即便发送缓冲区中一个字节的空闲空间都没有,send函数也会立即返回,返回值为-1,errno为EAGAIN或EWOULDBLOCK
–在非阻塞方式下,如果发送缓冲区中尚有少量空闲空间,则会将部分待发送数据复制到发送缓冲区,同时返回复制到发送缓冲区中的字节数
char buf[1024];
gets (buf);
ssize_t sent = send (connfd, buf, strlen (buf) *sizeof (buf[0]), 0);
if (sent == -1){
perror ("send");
exit (EXIT_FAILURE);
}
模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IUbV4pee-1615732028973)(E:\2020大二\uc14.png)]
迭代服务
•服务器在单线程中以循环迭代的方式依次处理每个客户机的业务需求。迭代模型的前提是针对每个客户机的处理时间必须足够短暂,否则会延误对其它客户机的响应
并发服务
•主进程阻塞在accept函数上。每当一个客户机与服务器建立连接,accept函数返回,即通过fork函数创建子进程,主进程继续等待新的连接,子进程处理客户机业务
•首先服务器主进程阻塞于针对侦听套接字的accept调用,客户机进程通过connect函数向服务器发起连接请求
•客户机的连接请求被系统内核接受,服务器主进程从accept函数中返回,同时得到可用于通信的连接套接字
•服务器主进程调用fork函数创建子进程,子进程复制父进程的文件描述符表,因此子进程也有侦听和连接两个套接字描述符
•服务器主进程关闭连接套接字;服务器子进程关闭侦听套接字。主进程通过循环继续阻塞于针对侦听套接字的accept调用,而子进程则通过连接套接字与客户机通信
•套接字描述与普通的文件描述符一样,是带有引用计数的。在一个套接字描述符上调用close函数,并不一定真的关闭了该套接字,而只是将其引用计数减一。只有当套接字描述符的引用计数被减到零时,才真的会释放该套接字对象所占用的资源,并向对方发送FIN分节。因此服务器主进程关闭连接套接字,并不会影响子进程通过该套接字与客户机通信。同理,服务器子进程关闭侦听套接字也不会影响主进程通过该套接字继续等待连接
•如果服务器主进程在创建子进程后不关闭连接套接字,一方面将耗尽其可用文件描述符;另一方面在子进程结束通信关闭连接套接字时,其描述符上的引用计数只会由2变成1,而不会变成0,TCP协议栈将永远保持此连接
UDP
UDP不提供客户机与服务器的连接
UDP的客户机与服务器不必存在长期关系。一个UDP的客户机在通过一个套接字向一个UDP服务器发送了一个数据报之后,马上可以通过同一个套接字向另一个UDP服务器发送另一个数据报。同样,一个UDP服务器也可以通过同一个套接字接收来自不同客户机的数据报
UDP不保证数据传输的可靠性和有序性
UDP的协议栈底层不提供诸如确认、超时重传、RTT估算以及序列号等机制。因此UDP数据报在网络传输的过程中,可能丢失,也可能重复,甚至重新排序。应用程序必须自己处理这些情况
UDP不提供流量控制
UDP的协议栈底层只是一味地按照发送方的速率发送数据,全然不顾接收方的缓冲区是否装得下
UDP是记录式传输协议
-
每个UDP数据报都有一定长度,一个数据报就是一条记录。如果数据报正确地到达了目的地,那么数据报的长度将被传递给接收方的应用进程
-
发送方逐个数据报地发送,接收方逐个数据报地接收,不存在一次接收部分数据报或多个数据报的可能
UDP是全双工的
在一个UDP套接字上,应用程序在任何时候都既可以发送数据也可以接收数据
UDP函数调用
接收数据
#include
ssize_t recvfrom(int sockfd,void *buf,size_t len,socklen_t *addrlen)
成功返回实际接收到的字节数,失败返回-1
–sockfd:套接字描述符
–buf:应用程序接收缓冲区
–len:期望接收的字节数
•从指定的地址结构接收数据
–flags:接收标志,一般取0,还可取以下值
MSG_DONTWAIT - 以非阻塞方式接受数据
MSG_OOB - 接收带外数据
MSG_PEEK - 只查看可接收的数据,函数返回后数据依然留在接收缓冲区中
MSG_WAITALL - 等待所有数据,即不接收到len字节的数据,函数就不返回
–src_addr:输出数据报发送者的地址结构,可置NULL
–addrlen:输入src_addr参数所指向内存块的字节数,输出数据报发送者地址结构的字节数,可置NULL
•recvfrom函数返回0,表示接收到一个空数据报(只有IP和UDP包头而无数据内容),与对方是否关闭套接字无关
char buf[1024];
struct sockaddr_in addrcli = {};
socklen_t addrlen = sizeof (addrcli);
ssize_t rcvd = recvfrom (sockfd, buf, sizeof (buf), 0,(struct sockaddr*)&addrcli, &addrlen);
if (rcvd == -1)
{
perror ("recvfrom");
exit (EXIT_FAILURE);
}
buf[rcvd] = '\0';
printf ("%s\n", buf);
发送数据
#include
ssize_t sendto (int sockfd,const void *buf,size_t len,int flags,const struct sockaddr *dest_addr,socklen_t addrlen)
成功返回实际接收到的字节数,失败返回-1
–sockfd:套接字描述符
–buf:应用程序接收缓冲区
–len:期望接收的字节数
•向指定的地址结构发送数据
–flags:发送标志,一般取0,还可取以下值
MSG_DONTWAIT - 以非阻塞方式发送数据
MSG_OOB - 发送带外数据
MSG_DONTROUTE - 不查路由表,直接在本地网络中寻找目的主机
–dest_addr:数据报接收者的地址结构
addrlen:数据报接收者地址结构的字节数
char buf[1024];
gets (buf);
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons (8888);
addr.sin_addr.s_addr = inet_addr ("192.168.182.48");
ssize_t sent = sendto (sockfd, buf, strlen (buf) *sizeof (buf[0]), 0, (struct sockaddr*)&addr, sizeof (addr));
if (sent == -1)
{
perror ("send");
exit (EXIT_FAILURE);
}
编程模型
- 基于UDP协议的无连接编程模型
| 步骤 | 服务器 | 客户机 | 步骤 | ||
|---|---|---|---|---|---|
| 1 | 创建套接字 | socket | socket | 创建套接字 | 1 |
| 2 | 准备地址结构 | sockaddr_in | sockaddr_in | 准备地址结构 | 2 |
| 3 | 绑定地址 | bind | —— | —— | —— |
| 4 | 接收请求 | recvfrom | sendto | 发送请求 | 3 |
| 5 | 发送响应 | sendto | recvfrom | 接收响应 | 4 |
| 6 | 关闭套接字 | close | close | 关闭套接字 | 5 |
编程模型
- 基于UDP协议的有连接编程模型
- UDP的connect函数与TCP的connect函数完全不同,既无三路握手,亦无虚拟电路,而仅仅是将传递给该函数的对方地址结构缓存在套接字对象中。此后收发数据时,可不使用recvfrom/sendto函数,而是使用recv/send或者read/write函数,直接和所连接的对方主机通信
| 步骤 | 服务器 | 客户机 | 步骤 | ||
|---|---|---|---|---|---|
| 1 | 创建套接字 | socket | socket | 创建套接字 | 1 |
| 2 | 准备地址结构 | sockaddr_in | sockaddr_in | 准备地址结构 | 2 |
| 3 | 绑定地址 | bind | connect | 建立连接 | 3 |
| 4 | 接收请求 | recvfrom | send/write | 发送请求 | 4 |
| 5 | 发送响应 | sendto | recv/read | 接收响应 | 5 |
| 6 | 关闭套接字 | close | close | 关闭套接字 | 6 |
迭代服务
- 基于UDP协议建立通信的客户机和服务器,不需要维持长期的连接。因此UDP服务器在一个单线程中,以循环迭代的方式即可处理来自不同客户机的业务需求
多线程
线程的基本概念
- 线程就是程序的执行路线,即进程内部的控制序列,或者说是进程的子任务
- 一个进程可以同时拥有多个线程,即同时被系统调度的多条执行路线,但至少要有一个主线程
- 一个进程的所有线程都共享进程的代码区、数据区、堆区(注意没有栈区)、环境变量和命令行参数、文件描述符、信号处理函数、当前目录、用户ID和组ID等
- 一个进程的每个线程都拥有独立的ID、寄存器值、栈内存、调度策略和优先级、信号掩码、errno变量以及线程私有数据(Thread Specific Data, TSD)等
线程调度
- 系统内核中专门负责线程调度的处理单元被称为调度器
- 调度器将所有处于就绪状态(没有阻塞在任何系统调用上)的线程排成一个队列,即所谓就绪队列
- 调度器从就绪队列中获取队首线程,为其分配一个时间片,并令处理机执行该线程,过了一段时间该线程的时间片耗尽,调度器立即中止该线程,并将其排到就绪队列尾端,接着从队首获取下一个线程该线程的时间片未耗尽,但需阻塞于某系统调用,比如等待I/O或者睡眠。调度器会中止该线程,并将其从就绪队列移至等待队列,直到其等待的条件满足后,再被移回就绪队列
- 在低优先级线程执行期间,有高优先级线程就绪,后者会抢占前者的时间片
- 若就绪队列为空,则系统内核进入空闲状态,直至其非空
时间片
- 调度器分配给每个线程的时间片长短,对系统的行为和性能影响很大
- 如果时间片过长,线程必须等待很长时间才能重新获得处理机,这就降低了整个系统运行的并行性,用户会感觉到明显的响应延迟
- 如果时间片过短,大量时间会浪费在线程切换上,同时降低了虚拟内存的存储命中率,线程的时间局部性无法得到保证
- 某些Unix系统倾向于为线程分配较长的时间片,希望通过扩大系统吞吐率来改善其整体表现;而另一些Unix系统则更倾向于为线程分配较短的时间片,以提升系统的交互性
- Linux系统根据线程在不同时间的具体表现,为其动态分配时间片,在吞吐率和交互性之间寻求最佳平衡点
处理机约束与I/O约束
- 一些线程总是持续地消耗掉分配给它们的全部时间片,比如那些专门负责科学计算、图像处理等任务的线程。这些线程被称为处理机约束型线程。它们通常可以得到较长的时间片,通过提高虚拟内存的存储命中率,保证线程的时间局部性,以尽可能快的速度完成任务
- 另一些线程则多数时间处于为等待资源而阻塞的状态,比如那些专门负责文件读写、网络通信或者人机交互的线程。这些线程被称为I/O约束型线程。它们通常只能得到较短的时间片,因为它们在发出I/O请求并阻塞于内核资源之前,只会运行很短的时间
- 另一方面,调度器又会适度降低处理机约束型线程的优先级,同时提高I/O约束型线程的优先级,于其间寻求平衡
创建线程
POSIX线程
早期Unix厂商各自提供私有的线程库版本,无论是接口还是实现,差异都非常大,代码移植非常困难
IEEE POSIX 1003.1c (1995)标准,定义了统一的线程编程接口,遵循该标准的线程实现被统称为POSIX线程,即pthread
使用pthread需要包含一个头文件:·thread.h
同时连一个共享库:libpthread.so
#include
gcc ... -lpthread
创建线程
#include
int pthread_create(pthread_t *thread,const pthread_attr_t* attr,void *(*start_routine)(void *),void * arg);
–thread:输出线程ID。pthread_t即unsigned long int
–attr:线程属性,NULL表示缺省属性。 pthread_attr_t可能是整型也可能是结构体,因实现而异
–start_routine:线程过程函数指针。参数和返回值的类型都是void*。启动线程其实就是调用一个函数,只不过是在一个独立的线程中调用的,函数一旦返回,线程即告结束
•创建新线程
–arg:传递给线程过程函数的参数。线程过程函数的调用者是系统内核,因此需要预先将参数存储到系统内核中
•在pthread.h头文件中声明的函数,通常以直接返回错误码的方式表示失败,而非返回-1并设置errno
•main函数可以被视为主线程的线程过程函数。main函数一旦返回,主线程即告结束。主线程一旦结束,进程即告结束。进程一旦结束,其所有的子线程统统结束
•应设法保证在线程过程函数执行期间,传递给它的参数arg所指向的目标持久有效
线程参数
•传递给线程过程函数的参数是一个泛型指针void*,它可以指向任何类型的数据:基本类型变量、结构体型变量或者数组型变量等等,但必须保证在线程过程函数执行期间,该指针所指向的目标变量持久有效,直到线程过程函数不再使用它为止
•调用pthread_create函数的代码在用户空间,线程过程函数的代码也在用户空间,但偏偏创建线程的动作由系统内核完成。因此传递给线程过程函数的参数也不得不经由系统内核传递给线程过程函数。pthread_create函数的arg参数负责将线程过程函数的参数带入系统内核
汇合线程
•等待线程终止并与之汇合,同时回收该线程的相关资源
#include
int pthread_t thread,void ** retval)
成功返回0,失败返回错误码
–thread:线程ID
–retval:输出线程过程函数的返回值。为了获得线程过程函数返回的一级泛型指针,可以同样定义一个一级泛型指针,并将其地址通过pthread_join函数的二级泛型指针参数retval传入该函数,并由该函数在thread线程终止以后,将其线程过程函数返回的一级指针填入该二级指针的目标
•从线程过程函数中返回值的方法
–线程过程函数将所需返回的内容放在一块内存中,返回该内存的地址,同时保证这块内存,在函数返回即线程结束以后依然有效
–若retval参数非NULL,则pthread_join函数将线程过程函数所返回的指针,拷贝到该参数所指向的内存中
–若线程过程函数所返回的指针指向动态分配的内存,则还需保证在用过该内存之后释放之
分离线程
•使指定线程进入分离状态\
#include
int pthread_detach(pthread_t thread);
成功返回0,失败返回错误码
•pthread_detach函数使thread线程进入分离状态(DETACHED)。处于分离状态的线程一旦终止,其线程资源即被系统自动回收。处于分离状态的线程不能被pthread_join函数汇合
•例如
pthread_detach (pthread_self ());
线程ID
获取调用线程的ID
#include
pthread_t pthread_self(void);
成功返回调用线程ID,不会失败
pthread_t thread = pthread_self ();
printf ("线程ID:%lu\n", thread);
判断线程ID是否相等
#include
int pthread_equal(pthread_t t1,pthread_t t2);
若t1和t2所表示的线程ID相等,则返回非零,否则返回零
–t1:线程ID
–t2:线程ID
•并非所有实现的pthread_t都是unsigned long int类型,有些可能是结构体类型,不能用“==”判断其是否相等
•例如
printf (%d\n", pthread_equal (t1, t2));