动手实现深度神经网络2 增加批处理
动手实现深度神经网络2 增加批处理
在上一部分中,我们构造了一个简单的两层神将网络,上文中那个网络使用数值微分计算梯度,没有实现批处理,所以可以认为时不可用的。在着一部分中,批处理将会被实现。
得益于numpy的广播属性,我们要实现批处理不难。简单来说,我们原来的网络中,每次输入都是一个有784个元素的二维矩阵,而加入我们每次输入一批数据(例如200条),那输入就是一个200*784的二维矩阵。
那么我们来看看代码中有哪些地方需要为批处理的实现做修改
1.对神经网络类的修改
下面是原来实现的神经网络的主要代码
# 经过两层运算
def predict(self,x):
# 取出参数
w1,b1=self.params['w1'],self.params['b1']
w2,b2=self.params['w2'],self.params['b2']
a1=np.dot(x,w1)+b1
#一 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
z1=sigmoid(a1)
a2=np.dot(z1,w2)+b2
#一 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
y=softmax(a2)
return y
# 求损失函数值
def loss(self,x,t):
y=self.predict(x)
#二 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
return cross_entropy_error(y,t)
# 求个损失函数值关于各个参数的梯度
def gradient_numerical(self,x,t):
loss_W=lambda w:self.loss(x,t)
grads={}
#三 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
grads['w1'] = numerical_gradient_2d(loss_W, self.params['w1'])
grads['b1'] = numerical_gradient_onenumber(loss_W, self.params['b1'])
grads['w2'] = numerical_gradient_2d(loss_W, self.params['w2'])
grads['b2'] = numerical_gradient_onenumber(loss_W, self.params['b2'])
return grads
# 计算准确率
def accuracy(self, x, t):
y = self.predict(x)
#四 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
y=np.argmax(y)
t=np.argmax(t)
return y==t
得益于numpy的广播机制,例如np.dot等操作就不需要修改了,可能需要修改的部分我都已经用感叹号做了标注,接下来我们一个一个来看看。
1.1 sigmoid和softmax
我们先来看一下之前实现的sigmoid和softmax源代码
def sigmoid(x):
return 1 / (1 + np.exp(-x))
sigmoid只是简单的做矩阵运算,不管一维矩阵还是二维矩阵都不影响,所以sigmoid不需要修改。
def softmax(x):
# 这里就需要修改了
max = np.max(x)
x = x - max
return np.exp(x) / np.sum(np.exp(x))
**softmax中涉及到np.max操作这就需要修改了。**因为对二维矩阵做np.max操作只会返回最大的一个值,而我们需要的是每一条数据中的最大值。
幸好,np.max提供了 axis 参数,具体来说就是对于二维矩阵np.max(x,axis=0)返回每列的最大值,np.max(x,axis=1)返回每行的最大值。
a_2d=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
print(np.max(a_2d))
print(np.max(a_2d,axis=0)) #每列的做大值
print(np.max(a_2d,axis=1)) #每行的最大值

那我们接下来来实现二维矩阵的softmax
def softmax(x):
if x.ndim==2:
max = np.max(x,axis=1)
x = x - max
return np.exp(x) / np.sum(np.exp(x),axis=1)
然后我们来测试一下,
#测试一下
x=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
softmax(x)
额。。。。。报错了

原因是max=np.max(x,axis=1)取到的max是一个3元素的一维矩阵,而x是3*10的二维矩阵,他们二者之间无法相减。一个简单的解决办法就是把max转换成3*1的二维矩阵,代码如下:
max = np.max(x,axis=1)
print(max) # [0.6 0.8 1.5]
max=max.reshape(max.size,1)
print(max) #[[0.6]
# [0.8]
# [1.5]]
我们再试一次:
def softmax(x):
if x.ndim==2:
max = np.max(x,axis=1)
max=max.reshape(max.size,1)
x = x - max
return np.exp(x) / np.sum(np.exp(x),axis=1)
#测试一下
x=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
softmax(x)
 h
h
还是出问题了,这次是“np.exp(x) / np.sum(np.exp(x),axis=1)”,其实你很快就会发现,这次的错误更上次本质上是一样的:
np.sum(np.exp(x),axis=1) 的结果是一个3元素的一维矩阵 而让3*10二维矩阵np.exp(x)去除以一个一维矩阵显然做不到。怎么办呢?更上面解决办法一样,再讲=将一维矩阵装换为二维矩阵就可以了。
不过这样总感觉非常的麻烦,有没有一种便捷的方法呢?看下面的代码:
def softmax(x):
if x.ndim == 2:
x = x.T # 转置
x = x - np.max(x, axis=0) # 溢出对策
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
#测试一下
x=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
softmax(x)
执行成功了!!
其实,上面的两个矩阵“不能相减”和“无法相除”都是因为它们的位置对应不上。而将x装置之后变为10*3的矩阵就可以轻松运算了
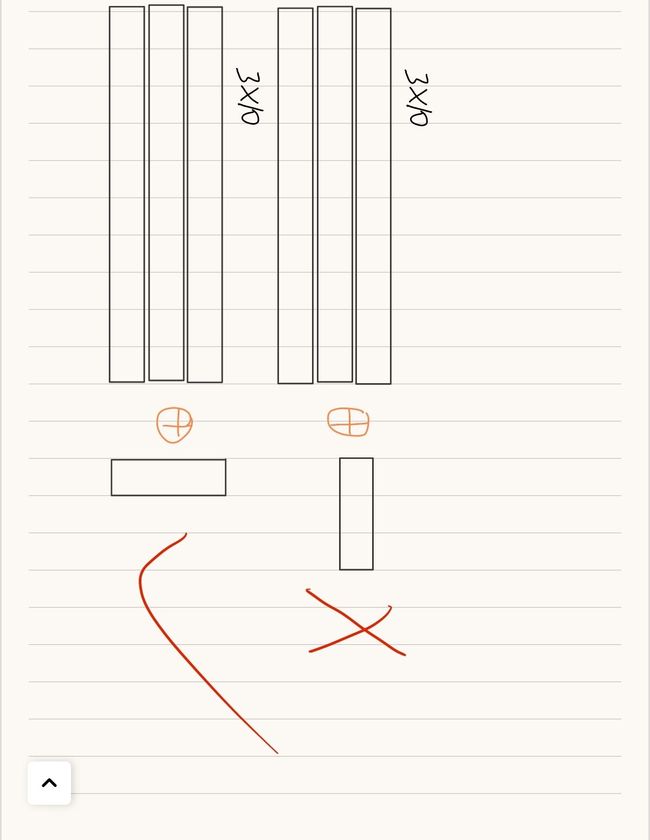
`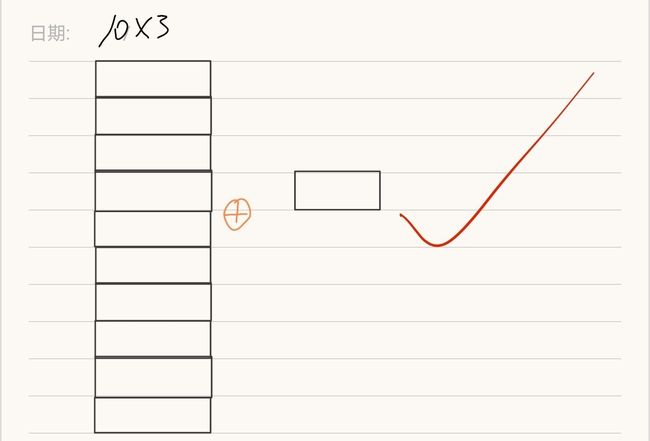
好的,二维矩阵softmax解决了,之后我们整理成一个同时支持一维和二维的方法:
def softmax(x):
if x.ndim==1:
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
if x.ndim == 2:
x = x.T # 转置
x = x - np.max(x, axis=0) # 溢出对策
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
1.2 cross_entropy_error
def cross_entropy_error_batch_1(y, t):
if y.ndim == 1:
# 改变t和y的形状,使得它们与批处理情况一致 即每批次1条数据
# 一维矩阵变为二维矩阵,统一操作
# t.size-->(1,t.size)
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
其实还是一维矩阵和二维矩阵的问题,我们这里首先把一维矩阵转换为二维矩阵,方便之后统一处理。
然后计算一个平均损失函数值。
-np.sum(t * np.log(y + 1e-7)) / batch_size实际上相当于先对每一条数据求损失值,再求平均值。
#-np.sum(t * np.log(y + 1e-7)) / batch_size 相当于
a = -np.sum(t * np.log(y + 1e-7),axis=1)
return np.max(a) / batch_size
交叉熵损失函数现在也完成了批处理的支持啦,我在这里再补充一种情况,那就是“监督数据是标签形式”,所谓标签形式就是像“2”“7”这样的标签,看下面的表就能轻易理解啦
| 监督数据(表明图片是几) | one-hot形式(独热编码) | 标签形式 |
|---|---|---|
| 1 | [0,1,0,0,0,0,0,0,0,0] | 1 |
| 5 | [0,0,0,0,0,1,0,0,0,0] | 5 |
| (批处理 假设一批3条数据)监督数据 | one-hot形式(独热编码) | 标签形式 |
|---|---|---|
| [4,2,5] | [ [0,0,0,0,1,0,0,0,0,0] [0,0,1,0,0,0,0,0,0,0] [0,0,0,0,0,1,0,0,0,0] ] | [4,2,5] |
对于“监督数据是标签形式”我们这样处理:
# 监督数据是标签形式(非one-hot表示,而是像“2”“7”这样的标签)时
def cross_entropy_error_batch_2(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
假设batch_size=3 假设测试数据是[4,2,5],那么y[np.arange(batch_size), t]实际上就是 [y[0,4], y[1,2], y[2,5]],也就是y中所有正确解标签的对应的输出的自然对数。根据上一篇文章中的推导就知道:交叉熵误差的值是由正确解标签所对应的输出结果决定的。因此可以用这种方法处理“监督数据是标签形式”的情况。
最后整理成一个包含所有情况的方法:
def cross_entropy_error_batch_all(y, t):
# 把非批处理数据改为批处理数据格式
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 如果测试数据是one-hot格式,将它转换为标签形式
if t.size == y.size:
# argmax返回最大值的索引 例如one-hot下[[0,1,0.....0],[0,0,0.....1]]会转换为[2,9]
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
1.3 求梯度
因为在所求的梯度是“损失函数值关于参数的梯度”,所以与输入的形式无关,所以不需要修改。
1.4 accuracy
计算准确率的方法做一下简单修改就可以啦
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0]) # shape返回形状 shape[0]行数 shape[1]列数
return accuracy
np.argmax(y, axis=1)返回每一行中最大值的索引。最后准确率就是 每批次总准确数/每批次总数。2.
2.对网络的使用代码的修改
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network=Myself_Two_Layer_Net(input_size=784, hidden_size=50, output_size=10,weight_init_std=0.01)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
learning_rate = 0.1 # 学习率
iters_num = 100 # 适当设定循环的次数 因为暂时没有实现自动微分,所以循环次数太多会很慢
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 二
# 这里说一下epoch,我们说批处理,在深度学习中往往使用minibatch
# epoch是一个单位。一个 epoch表示学习中所有训练数据均被使用过一次时的更新次数。
# 比如,对于 10000笔训练数据,用大小为 100笔数据的mini-batch进行学习时,重复随机梯度下降法 100次,所
# 有的训练数据就都被“看过”了A。此时,100次就是一个 epoch。
# 因此iter_per_epoch就是训练数据大小/每一批大小
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
#、一
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.gradient_numerical(x_batch, t_batch)
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
源代码中有两个点需要注意的:
一是np.random.choice(train_size, batch_size)从60000条训练数据中挑选100条数据出来,np.random.choice返回的是选中的下标(位置)
batch_mask=np.random.choice(100, 5)
print(batch_mask) # [31 60 43 54 40]
要注意使用随机选择的mini batch数据进行梯度下降的方法就叫做随机梯度下降法(stochastic gradient descent)。 深度学习的很多框架中,随机梯度下降法一般由一个名为SGD的函数来实现。
二是我们说批处理,在深度学习中往往使用的是mini batch方法:神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小 批量),然后对每个mini-batch进行学习。比如,从60000个训练数据中随机 选择100笔,再用这100笔数据进行学习。这种学习方式称为mini-batch学习。
而epoch是一个单位。一个 epoch表示学习中所有训练数据均被使用过一次时的更新次数。比如,对于 10000笔训练数据,用大小为 100笔数据的mini-batch进行学习时,重复随机梯度下降法 100次,所有的训练数据就都被“看过”了A。此时,100次就是一个 epoch。
因此iter_per_epoch就是训练数据大小/每一批大小,而经过iter_per_epoch训练,可以认为所有训练数据均被使用过,这时一般会计算一下精确率。