对象检测目标小用什么模型好_小目标检测技术分析
小目标检测技术分析
小目标检测及跟踪系统分为四个模块:
· 硬件模块
该模块基于标准PCI总线,并配以超大规模可编程芯片(DSP、FPGA),具有极强的运算、处理能力。
· DSP 程序模块
其功能主要实现复杂背景下的小目标检测、跟踪。考虑到系统的实时性要求,复杂背景下的小目标检测采用红外能量积累技术。首先对红外图像进行增强;然后在对小目标进行粗检测;最后在视频序列上分割提取小目标。同时,采用预测技术对目标的可能位置和存在区域进行估计,以实现实时、准确跟踪(或记忆)目标。系统按照搜索、捕获、跟踪、记忆跟踪四个状态及其转换运行,以实现小目标的实时检测与跟踪。
· 驱动程序模块
其主要功能是实现硬件模块与上层应用程序进行数据通信与信息交互。系统采用了PCI 9054 Target 方式的单周期读/写;在图像数据传送的时候为了满足每秒25帧图像的实时传送和处理的要求,采用了PCI 9054的Scatter/Gather DMA方式的数据传输。在整个系统的信息交互中,采用了一次握手协议,也就是请求—应答协议。
· 上层应用程序模块
该模块主要功能是向硬件模块下载DSP跟踪程序,启动/停止DSP,实时显示场景视频,对运动目标序列进行实时存储,对运动目标序列的基本特性进行实时分析和结果显示。

目标检测(object detection),就是在给定的一张图片中精确找到物体所在的位置,并标注出物体的类别。所以,目标检测要解决的问题就是物体在哪里以及是什么的整个流程问题。但是,在实际照片中,物体的尺寸变化范围很大,摆放物体的角度、姿态、在图片中的位置都不一样,物体之间可能还有重叠现象,这使得目标检测的难度变得很大。
目标检测近些年取得了较大发展,主要原因就是卷积神经网络在目标检测任务的应用代替了原有的基于人工规则提取特征的方法。
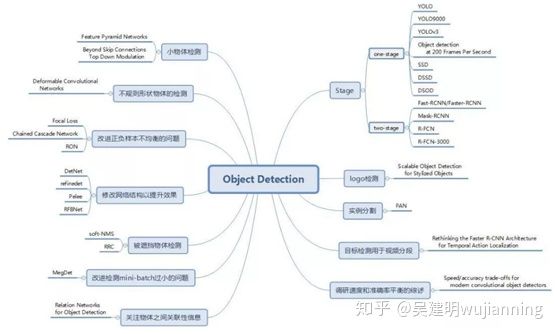

· 传统的目标检测算法:
Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化。
传统的目标检测中,多尺度形变部件模型DPM(Deformable Part Model)表现比较优秀,连续获得VOC(Visual Object Class)2007到2009的检测冠军,。DPM把物体看成了多个组成的部件(比如人脸的鼻子、嘴巴等),用部件间的关系来描述物体,这个特性非常符合自然界很多物体的非刚体特征。DPM可以看做是HOG+SVM的扩展,很好的继承了两者的优点,在人脸检测、行人检测等任务上取得了不错的效果,但是DPM相对复杂,检测速度也较慢,从而也出现了很多改进的方法。
但传统目标检测存在两个主要问题:一个是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;二是手工设计的特征对于多样性的变化并没有很好的鲁棒性。
· 基于深度学习的目标检测算法:
o 以候选区域/框(Region Proposal) + 深度学习分类的算法:
通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,比如R-CNN(Selective Search + CNN + SVM)、SPP-net(ROI Pooling)、Fast R-CNN(Selective Search + CNN + ROI)、Faster R-CNN(RPN + CNN + ROI)、Mask R-CNN(Mask Prediction Branch+RPN + CNN + ROI)等。
o 基于深度学习的回归算法:
YOLO、SSD、YOLOv2、YOLOv3等算法
目前目标检测领域的深度学习方法主要分为两类:two stage 的目标检测算法;one stage 的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优。
小目标检测
小目标有两种定义方式,一种是相对尺寸大小,如目标尺寸的长宽是原图像尺寸的0.1,即可认为是小目标,另外一种是绝对尺寸的定义,即尺寸小于32*32像素的目标即可认为是小目标。
小目标检测在深度学习卷积神经网络模型中一直是一个难题。早期的目标检测框架大多数是针对通用的目标来进行检测,如经典的单阶段方法yolo和ssd,两阶段方法faster-rcnn等,这些方法主要是针对通用目标数据集来设计的解决方案,因此对于图像中的小目标来说,检测效果不是很理想。
为了解决小目标问题提出的方法有:
· 图像的缩放。也是最琐碎的一个方向——是在检测前对图像进行缩放。但是,由于大图像变得太大,无法装入GPU进行训练,因此单纯的升级并不有效。ao等[2017]首先下采样图像,然后利用强化学习训练基于注意力的模型,动态搜索图像中感兴趣的区域。然后对选定的区域进行高分辨率的研究,并可用于预测较小的目标。这避免了对图像中每个像素进行同等关注分析的需要,节省了一些计算成本。一些论文[Dai等,2016b,2017年,Singh和Davis, 2018年]在目标检测上下文中训练时使用图像金字塔,而[Ren et al., 2017]在测试时使用。
· 浅网络。小物体更容易被接受场较小的探测器预测。较深的网络具有较大的接受域,容易丢失关于较粗层中较小对象的一些信息。Sommer等[2017b]提出了一种非常浅的网络,只有四个卷积层和三个完全连接的层,用于检测航空图像中的目标。当期望的实例类型很小时,这种类型的检测器非常有用。但是,如果预期的实例具有不同的大小,则效果更好上下文信息。利用围绕小对象实例的上下文。Gidaris和Komodakis [2015], Zhu等[2015b]使用上下文来提高性能,Chen等[2016a]则专门使用上下文来提高小对象的性能。他们使用上下文补丁对R-CNN进行了扩展,与区域建议网络生成的建议补丁并行。Zagoruyko等人[2016]将他们的方法与深度掩模对象建议相结合,使信息通过多条路径流动。
· 超分辨率。还有针对小目标的图像增强等。最典型的是利用生成对抗性网络选择性地提高小目标的分辨率。
· 它的生成器学会了将小对象的不佳表示增强为超分辨对象,这些超分辨对象与真实的大对象非常相似,足以欺骗竞争的鉴别器。
近两年提出了利用多层特征图的方法(特征金字塔、RNN思想、逐层预测),对小目标检测的效果产生了显著的提升。
现阶段主流算法有:
图像金字塔:较早提出对训练图片上采样出多尺度的图像金字塔。通过上采样能够加强小目标的细粒度特征,在理论上能够优化小目标检测的定位和识别效果。但基于图像金字塔训练卷积神经网络模型对计算机算力和内存都有非常高的要求。计算机硬件发展至今也难有胜任。故该方法在实际应用中极少。
逐层预测:该方法对于卷积神经网络的每层特征图输出进行一次预测,最后综合考量得出结果。同样,该方法也需要极高的硬件性能。
特征金字塔:参考多尺度特征图的特征信息,同时兼顾了较强的语义特征和位置特征。该方法的优势在于,多尺度特征图是卷积神经网络中固有的过渡模块,堆叠多尺度特征图对于算法复杂度的增加微乎其微。
RNN思想:参考了RNN算法中的门限机制、长短期记忆等,同时记录多层次的特征信息(注:和特征金字塔有本质区别)。但RNN固有的缺陷是训练速度较慢(部分操作无法矩阵化)。
所谓的小目标,要看是绝对小目标(像素),和相对小目标(相对原图的长宽来看的)。大目标小目标只跟receptive field(感受野)有关,cnn本身可以检测任何尺度的物体。ssd对小目标检测不太适用,但R-FCN速度和鲁棒存在问题。
小目标分为很多种,背景单一还是比较好做的。有一篇小人脸检测用的是 fullyconvolutionalnetwork(FCN) + ResNet ,此篇论文检测小目标用了其周边的信息,如头发,肩膀。
首先,小目标像素少特征不明显,因此和大目标相比,小目标的检测率低,这个用任何算法上都是无法避免的。那不同算法之间的小目标检测的区别呢?SSD,YOLO等单阶段多尺度算法,小目标检测需要较高的分辨率,SSD对于高分辨率的底层特征没有再利用,而这些层对于检测小目标很重要,因此主要在底部的特征层进行检测,比如SSD中的conv4_3,但底部特征层的语义信息不够丰富,这是一个矛盾,但卷积层加足够深的话影响其实没这么大。我觉得最重要的因素还是因为scale设置的不好导致的,SSD中默认最低一层的anchor为 0.1~0.2,对于720p的图像最小检测尺寸就有72个像素,还是太大了。事实上SSD的源码允许一个特征层做多个尺度的滑窗,将参数min_sizes里的每个元素初始化为一个列表,就可以在相应特征层中生成不同尺度的anchor,如果你设计的足够仔细,基本就可以覆盖足够小的目标了,不过此时anchor的数量估计会涨不少,速度也会降下来。
faster rcnn,yolo,ssd对小目标检测结果都不好,原因在于卷积网络结构的最后一层feature map太小,例如32*32的目标经过vgg后变成2*2,导致之后的检测和回归无法满足要求。卷积网络越深语义信息越强,而越低层则是描述的局部外观信息越多,而且我想VGG16卷积层设计成这么多肯定是有意义的,如果靠前的效果好,VGG的研究者应该想到减少层数了,我觉得可以考虑提取多层的特征这样表达能力强些。比如样本猫狗图像,较小的猫的ground truth只是出现在底层,高层没有猫的ground truth,而较大物体狗匹配到的ground truth在高层feature map上),其他层的信息只是简单拼接(所以小物体检测的语义信息,contex信息差一些)。
SSD是多尺度的特征图进行paopasal提取,ssd相对于yolo来说对小目标更稳定。yolo则是通过全局特征去直接得到预测结果,完全要靠数据堆积起来,对待小目标我觉得要考虑减少pooling
SSD里负责检测小目标的层为conv4_3(38*38)对应的尺度为0.2(可人为设置)。这就对应了SSD所能检测的尺度大概为0.2上下。在这种情况下,如果物体过于小的话,甚至在训练阶段,GT都没法找到相应的的default box与它匹配,效果怎么可能会好。如果不介意整体检测效果的话,可以把尺度调低,看看对于小目标的检测效果是否有提升。另外,利用多尺度进行检测也能提高小物体的检测效果。
SSD使用的VGG16作为特征抽取,在conv4_3 feature map 的分辨率已经缩小了8倍,在conv5_3缩小了16倍,比如一个32*32大小的物体,在vgg16 的 conv5_3的feature map 对应仅为2*2,位置信息有较大的损失。有两种方法可决绝这个问题:1.使用不同层的特征,比如hyperNet,MultiPath。2.保证感受也不缩小的情况下feature map的分辨率不至于缩小太多,如采用DeepLab中采用的Hole algorithm,在保证感受野的同时分辨变化较小。
他们对小目标检测不好的原因主要是,SSD/YOLO 对原图做了缩放,因为感受野的原因,导致“相对尺寸小”目标检测困难。如果说RCNN系列,并没有对原图进行缩放,但是如果”绝对尺寸小“的话,也没有办法,因为到了一定深度的Feature map,小目标可能已经丢失response了。1.小目标往往更依赖浅层特征,因为浅层特征有更高的分辨率,然而对语义区分较差。2.SSD检测和分类一起做,会把一些检测到但是分类模糊,分数不高的结果过滤掉。而rpn不会,前200个候选继续分类,都会有个结果。3.为了速度,本来是全卷积网络,却也固定了输入尺寸,对大图的小目标影响很大。
一些比较好的观点
CNN特征的分辨率较差,这点不比其它low-level(浅层)的特征,证据就是在pedestrian detection(行人检测)上, 一些hand-crafted features(手工制作特征)的效果还是不错的;Faster-rcnn和SSD本身的问题,原始的Faster-rnn在RPN中将input的最短边固定resize到600>SSD512>SSD300,SSD使用300和512的原因是为了提高detection speed,所以SSD才这样快;同时为保证精度,SSD才加上了multi-scale和data augmentation(尤其值得注意这个augmentation,数据增强)。
yolo和ssd确实对小物体很无力,而有些普通的图像算法对小物体检测反而好的多,只是不太鲁棒。可以尝试下R-FCN,我测试了几张,好像对小物体还可以,但是速度慢些。在970下0.18s一张的样子。我之前在VGG16上做过R-FCN的实验,使用相同的res101-proposal(只关注detection的效果所以使用的一样),效果不如fast rcnn。同理,在google-v1上(也是全卷积)也是不如,我估计是浅网络的overfitting问题(因为用VGG的proposal去做效果很不好)。
SSD是一种基于全卷积的网络的检测器,用不同层检测不同大小的物体。这中间有个矛盾,前面的 feature map大,但semantic(语义)不够,后面的sematic够了,但经过太多的pooling,feature map太小了。要检测小物体,既需要一张足够大的feature map来提供更加精细的特征和做更加密集的采样,同时也需要足够的semantic meaning来与背景区分开。参会时问过SSD的作者,如果将最后的feature map放大接上前面的话,是不是能够改善性能,作者说值得一试。
SSD is a class aware RPN with a lot of bells and whistles。每一个feature map上面的pixel对应几个anchor,这个网络对anchor进行训练,以此驱动对feature进行训练。这是前言。作为小物体,其所对应的anchor比较少 (gt overlap > 0.5 的 anchor),也就是说对应feature map上的pixel难以得到充分训练。读者可以脑补每一个大的ROI可能覆盖很多 anchor,那么这些 anchor 均有机会得到训练。然而一个小物体并不能覆盖很多 anchor。没有得到充分训练有什么问题?在test的时候这个pixel的预测结果可能就是乱的,会极大干扰正常结果。为什么SSD的data augmentation能涨这么多点,就是因为通过randomly crop,让每一个anchor都得到充分训练(也就是说,crop出一个小物体,在新图里面就变成大物体了)只能说这种without region propisal的结果 naturally 不擅长小物体。通过往上堆 hack 才能慢慢比上吧。
我试过SSD最前面的卷积为深度残差网络,检测小物体效果还不错,比YOLO要好得多。另外SSD原论文中,多级别的物体基本尺寸从0.1到0.8,实际上0.1的比例还是很大的,如1024*1024的输入,0.1都到102了,其实不小。可以根据需求调整级别,我使用的为1/64~1,即不同级别格子本身大小。当然,级别从线性分割变成指数分割后,在基本大小之上的各个变形也需要调整一下(主要是变大),不然有可能覆盖不到有些位于两个格子中间的某些大小的物体。YOLO比较坑的地方在于倒数第二层为全连接,后面的7*7格子不能扩张太大,不然前面的全连接要爆。格子大了,同一个格子可能会包括多个小物体,检测就不好搞了。而YOLO全连接的作用又是整合全局信息,要去掉全连接,就需要增加最后点的感受野,所以深度残差就非常适合。提到深度残差,再说另外一点。在深度残差的作者kaiming大神另一篇文章R-FCN: Object Detection via Region-based Fully Convolutional Networks,中有使用空间pooling,发现深度残差就是天然的自带空间pooling效果的结构啊。补充一点,SSD前面的CNN结构,一定要是全对称的,特别是pooling的时候,这样最后输出点的感受野中心才与每个格子的中心是重合的。如果是非对称的,CNN前面特征提取的时候,它会纠结,造成大量的小物体不好学习。而YOLO最后有全连接都还好,问题不大。最后一句,深度残差就是自带空间pooling结构,这个怎么理解呢。深度残差中的最小单元,一边为两个卷积垒在一起,假设作用只是把图像平移,另一个为直连,那最后接合在一起,就是一个空间相关的组合了嘛。