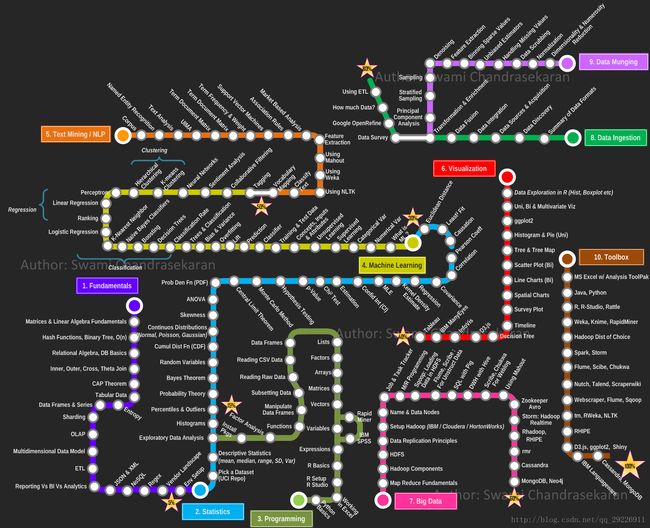
这是Swami Chandrasekaran所绘制的一张地图。名字叫MetroMap to Data Scientist。
Data Science road map
该地图一共十条路线,分别是基础原理、统计学、编程能力、机器学习、文本挖掘/自然语言处理、数据可视化、大数据、数据获取、数据清理、常用工具。
●★● 基本原理:
(1)矩阵和线性代数:涉及到的机器学习应用有SVD、PCA、最小二乘法、共轭梯度法等。
(2)哈希函数,二叉树,时间复杂度,空间复杂度
(3)关系代数(关系型数据库基本操作):抽象的查询语言。基本的代数运算有选择、投影、集合并、集合差、笛卡尔积和更名。关系型数据库就是以关系代数为基础。在SQL语言中都能找到关系代数相应的计算。
(4)Inner、Outer、Cross、Theta Join:内连接、外连接、交叉连接、θ连接。
(5)CAP Theorem:在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
(6)tabular data:列表数据,即二维的表格数据,关系型数据库的基础。
(7)entropy:熵值。
(8)DataFrames & Series:Pandas的数据结构。Series是一个一维数据对象,DataFrames是一个表格型的数据,是Series的多维表现。
(9)Sharding:分片。分片不是一种特定的功能或者工具,而是技术细节上的抽象处理,是水平拓展的解决方法。一般数据库遇到性能瓶颈,采用的是Scale Up,即向上增加性能的方法,但单个机器总有上限,于是水平拓展应运而生。如果能够保证数据量很难超过现有数据库服务器的物理承载量,那么只需利用MySQL5.1提供的分区(Partition)功能来改善数据库性能即可;否则,还是考虑应用Sharding理念。另外一个流传甚广的观点是:我们的数据也许没有那么大,Hadoop不是必需的,用sharding即可。
(10)OLAP:联机分析处理(Online Analytical Processing)。它是数据仓库系统主要的应用,主要用于复杂的分析操作。针对数据分析人员,数据是多维数据。查询均是涉及到多表的复杂关联查询,为了支持数据业务系统的搭建,OLAP可以想象成一个多维度的立方体,以维度(Dimension)和度量(Measure)为基本概念。我们用到的多维分析就是OLAP的具象化应用。
OLAP更偏向于传统企业,互联网企业会灵活变动一些。另外还有一个OLTP的概念。
(11)Multidimensional Data Model:多维数据模型。它是OLAP处理生成后的数据立方体。它提供了最直观观察数据的方法。
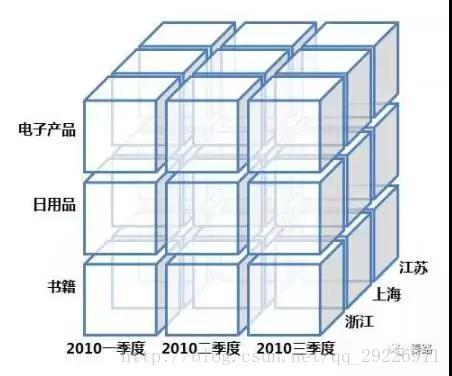
涉及钻取,上卷,切片,切块,旋转等操作,就是把上面的立方体变变变啦。
(12)ETL:ETL是抽取(extract)、转换(transform)、加载(load)的过程。常用在数据仓库。整个流程是从数据源抽取数据,结果数据清洗和转换,最终将数据以特定模型加载到数据仓库中去。
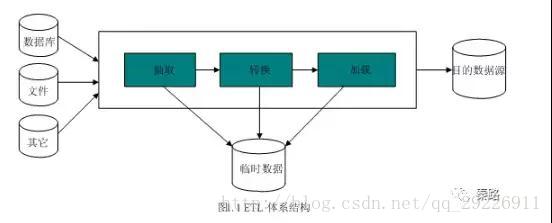
ETL是一个古老的概念,在以前SQL数据仓库时代和OLAP伴随而生,在现在日新月异的技术生态圈,会逐步演进到Hadoop相关的技术了。
(13)Reporting vs BI vs Analytics:报表与商业智能与分析。这是BI的三个组成部分。Reporting是数据报表。利用表格和图表呈现数据。报表通常是动态多样的。数个报表的集合统称为Dashboard。
BI是商业智能,是对企业的数据进行有效整合,通过数据报表快速作出决策。Analytics是数据分析,基于数据报表作出分析。包括趋势的波动,维度的对比等。
(14)JSON & XML:JSON是一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。注意学习JSON的语法规则。XML是可拓展标记语言,被设计用来传输和存储数据,与之对应的HTML则是显示数据。XML和HTML服务于不同目的,XML是不作为的。
(15)NoSQL:泛指非关系型的数据库,意为Not Only SQL。NoSQL主要分为四大类:键值KeyValue数据库、列数据库、文档型数据库、图形数据库。
(16)Regex:正则表达式(Regular Expression)。正则表通常被用来检索、替换那些符合某个模式(规则)的字符串。通过特定字符的组合,对字符串进行逻辑过滤。例如注册账号时检查对方邮件格式对不对啊,手机号格式对不对啊。
(17)Vendor Landscape
(18)Env Setup:环境安装,针对数据科学家,Anaconda + Rstudio用的比较多。
●★● 统计学:
(1)Pick a Dataset(UCI Repo):找数据(UCI数据集)。另外的数据来源是Kaggle竞赛等。
(2)Descriptive Statistics(mean, median, range, SD, Var):描述性统计(均值,中位数,极差,标准差,方差)
(3)Exploratory Data Analysis:探索性数据分析。获得一组数据集时,通常分析师需要掌握数据的大体情况,此时就要用到探索性数据分析。
主要是两类:
1.图形法:通过直方图、箱线图、茎叶图、散点图快速汇总描述数据。
2.数值法:观察数据的分布形态,包括中位数、极值、均值等,观察多变量之间的关系。
探索性数据分析不会涉及到复杂运算,而是通过简单的方式对数据有一个大概的了解,然后才去深入挖掘数据价值,在Python和R中,都有相关的summary函数。
(4)Histograms:直方图。它又称质量分布图,是一种表示数据分布的统计报告图。正常的直方图是中间高、两边低、左右近似对称。而异常型的直方图种类过多,不同的异常代表不同的可能情况。
(5)Percentiles & Outliers:百分位数和极值。百分位数和极值可以用来描绘箱线图。
(6)Probability Theory:概率论,统计学的核心之一,主要研究随机现象发生的可能性。
(7)Bayes Theorem:贝叶斯定理它关于随机事件A和B的条件概率的定理。贝叶斯公式:P(B|A) = P(A|B)*P(B) / P(A),最经典的应用莫过于垃圾邮件的过滤。
(8)Random Variables:随机变量,表示随机试验各种结果的实际值。比如天气下雨的降水量,比如某一时间段商城的客流量。随机变量是规律的反应,随机变量是概率的基石。
(9)Cumul Dist Fn(CDF):累计分布函数(Cumulative Distribution Function)。它是概率密度函数的积分,能够完整描述一个实数随机变量X的概率分布。直观看,累积分布函数是概率密度函数曲线下的面积。
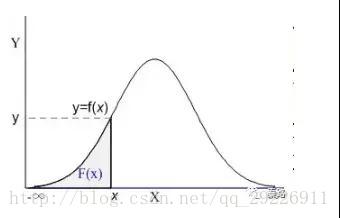
现实生活中,我们描述的很多概率都是累积分布函数,我们说考试90分以上的概率有95%,实际是90分~100分所有的概率求和为95%。
(10)Continuos Distributions(Normal, Poisson, Gaussian):连续分布(正态、泊松、高斯)。分布有两种,离散分布和连续分布。连续分布是随机变量在区间内能够取任意数值。正态分布是统计学中最重要的分布之一,它的形状呈钟型,两头低,中间高,左右对称。泊松分布是离散概率分布。适合描述某个随机事件在单位时间/距离/面积等出现的次数。当n出现的次数足够多时,泊松分布可以看作正态分布。高斯分布就是正态分布。
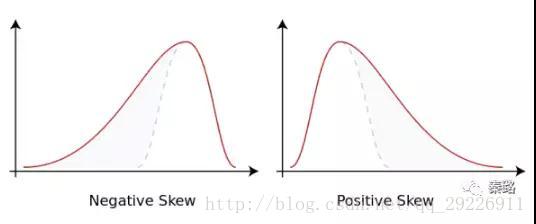
(11)Skewness:偏度。它是数据分布倾斜方向和程度的度量,当数据非对称时,需要用到偏度。正态分布的偏度为0,当偏度为负时,数据分布往左偏离,叫做负偏离,也称左偏态。反之叫右偏态。
(12)ANOVA:方差分析,用于多个变量的显著性检验。基本思想是:通过分析研究不同来源的变异对总变异的贡献大小,从而确定可控因素对研究结果影响力的大小。方差分析属于回归分析的特例。方差分析用于检验所有变量的显著性,而回归分析通常针对单个变量的。
(13)Prob Den Fn(PDF)概率密度函数。PDF是用来描述连续型随机变量的输出值。概率密度函数应该和分布函数一起看:

蓝色曲线是概率密度函数,阴影部分是累积分布函数。我们用概率密度函数在某一区间上的积分来刻画随机变量落在这个区间中的概率。概率等于区间乘概率密度,累积分布等于所有概率的累加。
概率密度函数:f(x) = P(X=x)
累积分布函数:F(x) = P(X<=x)
概率密度函数是累积分布函数的导数,现有分布函数,才有密度函数。累积分布函数即可以离散也可以连续,而密度函数是用在连续分布中的。
(14)Central Limit THeorem:中心极限定理它是概率论中最重要的一类定理。自然届中很多随机变量都服从正态分布,中心极限定理就是理解和解释这些随机变量的。我们有一个总体样本,从中取样本量为n的样本,这个样本有一个均值,当我们重复取了m次时,对应有m个均值,如果我们把数据分布画出来,得到的结果近似正态分布。
(15)Monte Carlo Method:蒙特卡罗方法,它是使用随机数来解决计算问题的方法。我们有时候会因为各种限制而无法使用确定性的方法,此时我们只能随机模拟,用通过概率实验所求的概率来估计我们感兴趣的一个量。最知名的例子有布丰投针试验。它的理论依据是大数定理和中心极限定理。
(16)Hypothesis Testing:假设检验,假设检验有U检验、T检验、F检验等方法。首先根据实际问题作出一个假设,记作H0,相反的假设称为备择假设。它的核心思想是小概率反证法,如果这个假设发生的概率太小以至于不可能发生,结果它发生了,那么我们认为假设是不成立的。
(17)p-Value:P值。它是进行假设检验判定的一个参数。当原假设为真时样本观察结果(或更极端结果)出现的概率。P值很小,说明原假设发生的概率很小,但它确实发生了,那么我们就有理由拒绝原假设。
(18)Chi2 Test:卡方检验,Chi读作卡。通常用作独立性检验和拟合优度检验。
(19)Estimation:估计,统计学里面估计分为参数估计和非参数估计。参数估计需要先明确对样本的分布形态与模型的具体形式做假设。常见的估计方法有极大似然估计法、最小二乘法、贝叶斯估计法等。非参数估计则是不做假设,直接利用样本数据去做逼近,找出相应的模型。
(20)Confid Int(CI):置信区间。它是参数检验中对某个样本的总体参数的区间估计。它描述的是这个参数有一定概率落在测量结果的范围程度。这个概率叫做置信水平。
(21)MLE:极大似然估计。它是建立在极大似然原理的基础上。如果试验如有若干个可能的结果A,B,C…。若在仅仅作一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大。
(22)Kernel Density Estimate:核密度估计。它是概率论中估计未知的密度函数,属于非参数检验。一般的概率问题,我们都会假定数据分布满足状态,是基于假定的判别。这种叫参数检验。如果如果数据与假定存在很大的差异,那么这些方法就不好用,于是便有了非参数检验。核密度估计就是非参数检验,它不需要假定数据满足那种分布。
(23)Regression:回归。回归分析常用来探讨变量之间的关系,在有限情况下,也能推断相关性和因果性。而在机器学习领域中,它被用来预测,也能用来筛选特征。
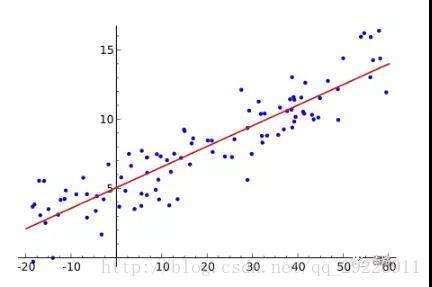
回归包括线性回归、非线性回归、逻辑回归等。上图就是线性回归。
(24)Convariance:协方差。用于衡量两个变量的总体误差,方差是协方差的一种特殊情况,即两个变量相同。
(25)Correlation:相关性。即变量之间的关联性,相关性只涉及数学层面,即一个变量变化,另外一个变量会不会变化,但是两个变量的因果性不做研究。
(26)Pearson Coeff:皮尔逊相关系数。它是度量两个变量线性相关的系数,用r表示,其值介于-1与1之间。1表示完全正相关,0表示完全无关,-1表示完全负相关。
(27)Causation:因果性。和相关性是一堆好基友。相关性代表数学上的关系,但并不代表具有因果性。
(28)Least2 fit:最小二乘法。它是线性回归的一种用于机器学习中的优化技术。最小二乘的基本思想是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。它是基于欧式距离的。
(29)Eculidean Distance:欧氏距离。指在m维空间中两个点之间的真实距离。小学时求的坐标轴轴上两个点的直线距离就是二维空间的欧式距离。很多算法都是基于欧式距离求解的。
●★● 编程:
(1)Python Basics:Python基础知识。人生苦短,我用Python。
(2)Working in Excel:Excel干活。掌握常用函数,懂得数据分析库,会Power系列加分。VBA这种就不用学了。
(3)R Setup, RStudio R:安装R和RStudio。R是一门统计学语言。下列的内容,都是R语言相关。如果不学R语言的话,(4)-(18)可以忽略。
(4)R Basics:R的基础语言
(5)Varibles:变量
(6)Vectors:向量
(7)Matrices:矩阵
(8)Arrays:数组
(9)Factors:因子
(10)Lists:列表
(11)Data Frames:数据框
(12)Reading CSV Data:读取CSV数据
(13)Reading Raw Data:读取原始数据
(14)Subsetting Data:构建数据集
(15)Manipulate Data Frames:操作数据框
(16)Functions:函数
(17)Factor Analysis:因子分析
(18)Install Pkgs:调包侠
●★● 机器学习:
数据科学的终极应用,现在已经是深度学习了。这条路也叫从调包到科学调参。这里的算法属于经典算法,但是向GBDT、XGBoost、RF等近几年竞赛中大发异彩的算法没有涉及,应该是写得比较早的原因。
(1)What is ML?
机器学习,区别于数据挖掘,机器学习的算法基于统计学和概率论,根据已有数据不断自动学习找到最优解。数据挖掘能包含机器学习的算法,但是协同过滤,关联规则不是机器学习,在机器学习的教程上看不到,但是在数据挖掘书本能看到。
(2)Numerical Var:数值变量。在很多模型中,连续性的数值变量不会直接使用,为了模型的泛化能力会将其转换为分类变量。
(3)Categorical Var:分类变量。有时候为了方便和节省存储空间,也会用数值表示,比如1代表男,0代表女。但它们没有计算意义。在输入模型的过程中,会将其转变为哑变量。
(4)Supervised Learning:监督学习。既然从训练集中生成模型,那么训练集的结果Y应该是已知的,知道输入X和输出Y,模型才会建立,这个过程叫做监督学习。如果输出值是离散的,是分类,如果输出值是连续的,是预测。监督学习常见于KNN、线性回归、朴素贝叶斯、随机森林等。
(5)Unsupervied Learning:非监督学习。无监督学习和监督学习,监督学习是知道结果Y,无监督学习是不知道Y,仅通过已有的X,来找出隐藏的结构。无监督学习常见于聚类、隐马尔可夫模型等。
(6)Concepts, Inputs & Attributes:概念、输入和特征。机器学习包括输入空间、输出空间、和特征空间三类。特征选择的目的是筛选出结果有影响的数据。
(7)Traning & Test Data:训练集和测试集。我们会采用随机抽样或者分层抽样的将数据分成大小两个部分,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,通过小样本的预测结果和真实结果做对比,来判断模型优劣。这个叫做交叉验证。交叉验证能够提高模型的稳定性,但不是完全保险的,依旧有过拟合的风险。通常用80%的数据构建训练集,20%的数据构建测试集。
(8)Classifier:分类。监督学习中,如果输出是离散变量,算法称为分类。输出的离散变量如果是二元的,则是二元分类,比如判断是不是垃圾邮件{是,否},很多分类问题都是二元分类。与之相对的是多元分类。
(9)Prediction:预测。监督学习中,如果输出是连续变量,算法称为预测。预测即可以是数值型,比如未来的销量,也可以是介于[0,1]间的概率问题。
(10)Lift:Lift曲线。还有一种常用的叫ROC曲线。
(11)Overfitting:过拟合。过拟合是机器学习中常碰到的一类问题。主要体现在模型在训练数据集上变现优秀,而在真实数据集上表现欠佳。不同的机器学习算法,是否容易拟合的程度也不仅相同。通常采用加大样本数据量、减少共线性、增加特征泛化能力的方法解决过拟合。
与之相反的是欠拟合。
(12)Bias & Variance:偏差和方差。偏差和方差除了统计学概念外,它们也是解释算法泛化能力的一种重要工具。算法在不同训练集上得到的结果不同,我们用偏差度量算法的期望预测和真实结果的偏离程度,这代表算法本身的拟合能力,方差则度量了算法受数据波动造成的影响。偏差越小、越能够拟合数据,方差越小、越能够扛数据波动。
(13)Trees & Classification:树分类。树分类是需要通过多级判别才能确定模式所属类别的一种分类方法。多级判别过程可以用树状结构表示,所以称为树分类器。最经典的便是决策树算法。
(14)Classification Rate:分类正确率。分类正确率即可以判断二分类任务,也适用于多分类任务。我们定义分类错误的样本数占总样本的比率为错误率,精确度则是正确的样本数比率。两者相加为1。
为了更好的判断模型,主要是业务需要,我们还加入了查准率(precision),查全率(recall),查准率是预测为真的数据中有多少是真的。查全率是真的数据中有多少数据被预测对了。算法竞赛就是基于上述指标评分的。
假如我们的预测是病人是否患了某个致死疾病,假设得病为真,我们显然希望把全部都得病的患者找出来,那么此时查全率(得病的患者有多少被准确预测出来)比查准率(预测得病的患者有多少真的得病了)更重要,因为这个会死人,那么肯定是选择有杀错无放过。此时更追求查全率。
(15)Decision Tress:决策树。决策树主流有ID3、C4.5(C5.0也有了)、CART算法。随机森林算法是基于决策树的。
(16)Boosting:提升方法。属于集成学习的一种。提升方法Boosting一般是通过多个弱分类器组成一个强分类器,提高分类性能。简而言之是三个臭皮匠顶一个诸葛亮。
主流方法是AdaBoost,以基分类器做线性组合,每一轮提高前几轮被错误分类的权值。
(17)Naive Bayes Classifiers:朴素贝叶斯分类。它基于贝叶斯定理的分类方法。朴素贝叶斯法的使用条件是各条件互相独立。
(18)K-Nearest Neighbour:K近邻分类。K近邻分类的特点是通过训练数据对特征向量空间进行划分。当有新的数据输入时,寻找距离它最近的K个实例,如果K个实例多数属于某类,那么就把新数据也算作某类。
(19)Logistic Regression:逻辑回归。逻辑回归属于对数线性模型,虽然叫回归,本质却是分类模型。如果我们要用线性模型做分类任务,则找到sigmoid函数将分类目标Y和回归的预测值联系起来,当预测值大于0,判断正例,小于0为反例,等于0任意判别,这个方法叫逻辑回归模型。模型参数通过极大似然法求得。逻辑回归的优点是快速和简单,缺点是高维数据支持不好,容易欠拟合。
(20)Ranking:排序,PageRank。这里应该泛指Google的PageRank算法。PageRank并不是唯一的排名算法,而是最为广泛使用的一种。其他算法还有:Hilltop 算法、ExpertRank、HITS、TrustRank。
(21)Linear Regression:线性回归。线性回归是机器学习的入门级别算法,它通过学习得到一个线性组合来进行预测。
(22)Perceptron:感知机。它是二类分类的线性分类模型。它通过一个wx+b的超平面S划分特征空间。为了找出这个超平面,我们利用损失函数极小化求出。超平面的解不是唯一的,采取不同初值或误分类点将会造成不同结果。最常用的就是支持向量机。
(23)Hierarchical Clustering:层次聚类。层次聚类指在不同层次对数据集进行划分,从而形成树形的聚类结构。它将样本看作一个初始聚类簇,每次运算找出最近的簇进行合并,该过程不断合并,直到满足预设的簇的个数。
(24)K-means Clusterning:K聚类。全称K均值聚类,无监督学习的经典算法。物以类聚人以群分的典型代表。
(25)Neural Networks:神经网络。神经网络是一种模仿生物神经系统的算法,神经网络算法以神经元作为最基础的单位,神经元通过将输入数据转换为0或1的阀值,达到激活与否的目的,但是0和1不连续不光滑,对于连续性数据,往往用sigmoid函数转换成[0,1] 间的范围。
另外,层数越多,参数越多的神经网络复杂度越高,深度学习就是典型的层数很多的神经网络。常见的有CNN、DNN、RNN等算法。
(26)Sentiment Analysis:情感分析,包括情感词的正面负面分类,标注语料,情感词的提取等。
我们也可以用机器学习的方法将其看待为分类问题。讲关键词特征向量化,常用词袋模型(bag-of-words )以及连续分布词向量模型(word Embedding),特征化后,往往用CNN、RNN或者SVM算法。
(27)Collaborative Fitering:协同过滤,简称CF算法。协同过滤不属于机器学习领域,所以你在机器学习的书上看不到,它属于数据挖掘。
(28)Tagging:标签/标注。如果是标签,间接理解为用户画像,涉及到标签系统。用户的男女、性别、出生地皆是标签,越丰富的标签,越能在特征工程中为我们所用。
如果是分类标签/标注,则是数据标注。有监督学习需要训练集有明确的结果Y,很多数据集需要人工添加上结果。比如图像识别,你需要标注图像属于什么分类,是猫是狗、是男是女等。在语音识别,则需要标注它对应的中文含义,如果涉及到方言,则还需要将方言标注为普通话。
数据标注是个苦力活。