常用唯一ID生成方案分析(从单机到分布式)
目录
- 1 前言
- 2 通过 UUID 生成
-
- 2.1 概念
- 2.2 优点
- 2.3 缺点
- 2.4 拓展
- 3 通过业务规则生成
-
- 3.1 概念
- 3.2 优点
- 3.3 缺点
- 4 通过数据库生成
-
- 4.1 主键自增
-
- 4.1.1 概念
- 4.1.2 优点
- 4.1.3 缺点
- 4.2 Flickr 的全局主键生成方案
-
- 4.2.1 概念
- 4.2.2 优点
- 4.2.3 缺点
- 4.2.4 拓展
- 5 通过 Redis 生成
-
- 5.1 概念
- 5.2 优点
- 5.3 缺点
- 6 通过 snowflake(雪花算法)生成
-
- 6.1 概念
- 6.2 开源项目分析
-
- 6.2.1 hutool
-
- 6.2.1.1 引入依赖
- 6.2.1.2 使用
- 6.2.1.3 源码分析
- 6.2.2 美团 leaf
-
- 6.2.2.1 打包自己的start
- 6.2.2.2 引入依赖
- 6.2.2.3 配置leaf.properties到你的classpath下面
- 6.2.2.4 利用注解启动leaf,并使用api
- 6.2.2.5 源码分析
1 前言
本文主要对常见的几种唯一ID生成方案做了分析,包括UUID、业务规则生成、数据库生成、Redis生成、雪花算法及其开源框架实现。
2 通过 UUID 生成
2.1 概念
UUID,英文全称 Universally Unique Identifier,翻译成中文就是通用唯一识别码。
使用 JDK 自带的工具类,就能生成,代码如下
public static void main(String[] args) {
UUID uuid = UUID.randomUUID();
System.out.println(uuid);
}
输出结果
9ddf5b2d-de13-4116-b9d9-6e67a8163898
2.2 优点
他的优点是非常突出的,本地生成,性能极高,且不会存在并发问题。
2.3 缺点
他的缺点同样也是非常明显的,那就是他太长了。不利于持久化落库。
2.4 拓展
UUID 不适合作为 MySQL 数据库的主键,因为无序过长的主键,会频繁造成页分裂,对性能的损耗是非常大的。对 MySQL 知识感兴趣的小伙伴可以移步小七的另一篇文章,这里就不再展开了。

3 通过业务规则生成
3.1 概念
这种方案,极度依赖于业务场景。
比如下单买东西的订单号,就完全可以通过以下规则生成【身份证号(客户 ID) + 业务发生时间戳 + 顺序号】,按这种规则生成的订单号,正常情况下根本不可能重复,除非客户恶意刷单。
再举个例子,比如我们使用打车软件打车。如果使用【时间戳 + 车牌号 + 起点编号】生成订单号,你觉得在这种场景下,id 会重复吗?
3.2 优点
本地生成,实现简单,且不会存在并发问题。
3.3 缺点
极度依赖业务场景,且没有统一发号器,不好维护。
4 通过数据库生成
4.1 主键自增
4.1.1 概念
这种方案就是使用数据库的自增主键作为唯一 ID。
如果你想搞一个全局唯一 ID,还可以在你自己的库里专门搞一张表,然后用这一张表专门生成 ID。
也可以进一步升级,专门搞一个库,里面只有一张表去生成 ID。
4.1.2 优点
实现超简单,基本不用动脑子。
4.1.3 缺点
承载的并发低,且单表数据会越来越大,水平扩展困难,在分布式数据库环境下,无法保证唯一性。
4.2 Flickr 的全局主键生成方案
4.2.1 概念

该方案其实也是通过数据库生成 ID 的一种变种方案。他的核心思想是使用 replace into 语法替代insert into,这样可以避免表中的行数过大。last_insert_id()函数是 connection 级别的,客户端之间相互不影响,代表你这个连接最近生成的ID。
注意:不存在事务问题,存储引擎使用MyISAM更高效。
CREATE TABLE `id_generator` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
REPLACE INTO id_generator(stub) VALUES ('a');
SELECT LAST_INSERT_ID();
4.2.2 优点
实现简单,如果对并发要求不高,可以用于生产。
4.2.3 缺点
同样存在数据库瓶颈问题,扛不住高并发,并且扩容困难,分库分表困难。
4.2.4 拓展
以上说的数据库方案,原则上都需要进行高可用升级和集群部署,也就是说,可以根据不同的步长部署机器。
5 通过 Redis 生成
5.1 概念
我们知道分布式锁是可以通过 redis 实现的,那么同理 redis 是否可以用来生成分布式唯一 ID 呢?
我们可以利用Redis的单线程特性,使用他的自增命令,想要获取ID,直接通过客户端拿就行了。但是在Redis集群下,需要设置每台机器的步长,比如5台机器,每台机器的初始值依次为1、2、3、4、5,那么每台机器的自增步长是5。
5.2 优点
不用额外开发,直接用就行,高性能,高并发,高可用,全局唯一。
5.3 缺点
存在极大的扩容问题,比如5台Redis扛不住了,我们现在想要再增加一台,那么增加以后步长就是6,以前的ID怎么办?而且一旦上了主从同步和高可用,我们也要考虑主从同步是异步的这个问题。
6 通过 snowflake(雪花算法)生成
6.1 概念
Snowflake算法是由Twitter公司,开源出来的一种生成全局唯一ID的算法,github地址如下:

原生Snowflake算法使用一个64 bit的整型数据,根据当前的时间来生成ID。 结果如下:
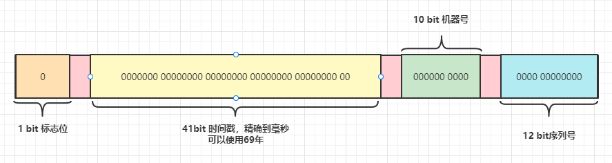
通过观察以上数据结构,我们可以知道该算法主要依赖时间戳和机器号。
那么现在摆在我们眼前的问题就是如何确定时间戳和机器号。
机器号,好解决,最笨的方法,每个jia包单独指定一个机器号,或者在磁盘上持久化一个机器号也行,启动的时候取加载他就好了,当然如果你有使用zookeeper等注册中心,直接使用zookeeper来获取就行了。
机器号解决了,那时间戳呢?服务器存在时钟回拨的问题。什么是时间回拨,说通俗一点就是,多台机器的时间不一致了,他们需要同步成一样的时间,如果是当前时间慢了,需要往后拨,这是没什么问题的。但是如果时间快了,那么这个时候就需要把时间往前拨了,那么时间戳必然就会有重复,那么同一台机器的机器号也是相同的,就有可能会生成重复的ID了,这个是原生雪花算法没有解决的问题。
接下来我们分析一下,常见的两个开源项目
6.2 开源项目分析
6.2.1 hutool
6.2.1.1 引入依赖
<dependency>
<groupId>cn.hutoolgroupId>
<artifactId>hutool-allartifactId>
<version>5.5.7version>
dependency>
6.2.1.2 使用
//参数1为终端ID
//参数2为数据中心ID
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
long id = snowflake.nextId();
6.2.1.3 源码分析
IdUtil
public static Snowflake getSnowflake(long workerId, long datacenterId) {
// 这个方法保证我们获取到的对象是单例的
return Singleton.get(Snowflake.class, workerId, datacenterId);
}
Snowflake
public synchronized long nextId() {
// 当前时间戳
long timestamp = genTime();
// 上一个时间戳,比当前时间戳还大,说明发生了时钟回拨
if (timestamp < this.lastTimestamp) {
if(this.lastTimestamp - timestamp < 2000){
// 容忍2秒内的回拨,避免NTP校时造成的异常
timestamp = lastTimestamp;
} else{
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
}
// 如果上次时间与当前时间相等(回拨后,也是相等的)
if (timestamp == this.lastTimestamp) {
final long sequence = (this.sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
this.sequence = sequence;
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) | (dataCenterId << dataCenterIdShift) | (workerId << workerIdShift) | sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = genTime();
// 循环直到操作系统时间戳变化
while (timestamp == lastTimestamp) {
timestamp = genTime();
}
if (timestamp < lastTimestamp) {
// 如果发现新的时间戳比上次记录的时间戳数值小,说明操作系统时间发生了倒退,报错
throw new IllegalStateException(
StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
return timestamp;
}
通过阅读以上代码我们可以知道hutool解决时间回拨的办法是比较暴力的,在2秒之内的回拨是循环等待时钟追上的。
6.2.2 美团 leaf

美团leaf有很多种使用方式,这里我们讲解一种:使用leaf-starter注解来启动leaf。
注:除了雪花算法的优化实现,leaf还有另外一种基于数据库号段的模式(相当于Flickr 的全局主键生成方案的优化实现,感兴趣的同学可以参考上面的github连接)
6.2.2.1 打包自己的start
git clone [email protected]:Meituan-Dianping/Leaf.git
git checkout feature/spring-boot-starter
cd leaf
mvn clean install -Dmaven.test.skip=true
6.2.2.2 引入依赖
<dependency>
<artifactId>leaf-boot-starterartifactId>
<groupId>com.sankuai.inf.leafgroupId>
<version>1.0.1-RELEASEversion>
dependency>
6.2.2.3 配置leaf.properties到你的classpath下面
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=false
#leaf.segment.url=
#leaf.segment.username=
#leaf.segment.password=
leaf.snowflake.enable=false
#leaf.snowflake.address=
#leaf.snowflake.port=
6.2.2.4 利用注解启动leaf,并使用api
//EnableLeafServer 开启leafserver
@SpringBootApplication
@EnableLeafServer
public class LeafdemoApplication {
public static void main(String[] args) {
SpringApplication.run(LeafdemoApplication.class, args);
}
}
//直接使用 spring注入
public class T {
@Autowired
private SegmentService segmentService;
@Autowired
private SnowflakeService snowflakeService;
}
6.2.2.5 源码分析
Leaf-snowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
时钟回拨关键代码如下:
//发生了回拨,此刻时间小于上次发号时间
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
//时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen();
if (timestamp < lastTimestamp) {
//还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else {
//throw
throwClockBackwardsEx(timestamp);
}
}
//分配ID