【分布式系列01期】常见的分布式ID生成方案浅析及大厂方案调研

本文已收录到1.4 K+ Star 数的开源学习指南—《大厂面试指北》,如果想要了解更多,可以访问Github项目主页:https://github.com/NotFound9/interviewGuide
在日常的业务开发中,通常需要对一些数据做唯一标识,例如为大量抓取的文章入库时分配一个唯一的id,为用户下的订单分配订单号等等。并发量小的时候,通常会使用数据库自增的主键id作为唯一id。并发量大的时候就会考虑使用一些分布式ID的生成方案来生成id。由于一些特殊的业务需求,我们的业务中也使用到了分布式ID的生成,对分布式ID的各种方案进行了调研。所以这里给大家分享一些我们在实践过程中进行的调研和实践优化经验,因为篇幅比较长,我们主要分为三篇:
【分布式系列01期】常见的分布式ID生成方案浅析及大厂方案调研
【分布式系列02期】开源分布式ID生成框架Leaf和uid-generator的原理分析
【分布式系列03期】开源分布式ID生成框架Leaf和uid-generator存在的问题及优化改进
摘要
本文是【分布式系列01期】中的第一篇,主要包含分布式ID生成方案简介和当前大公司的ID生成方案研究两部分
一、分布式ID生成方案简介
目前常用的分布式ID生成方案主要有以下几种:
1.使用UUID算法生成唯一id。
2.利用单机数据库主键自增来生成唯一id。
3.多数据库主键自增生成唯一id。(设置步长区分不同数据库)
4.数据库分段发号生成唯一id。(例如美团的Leaf框架中的segement模式)
5.基于snowflake算法生成唯一id(例如美团的Leaf框架中的snowflake模式,百度的uid-generator)
这是我总结的表,大家可以先看看表,然后再看下面每种方案具体的分析。
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 使用UUID算法生成唯一id | 无任何依赖 | ID太长,且不是数字类型 | 生成seesion_id |
| 利用单机数据库主键自增来生成唯一id | 方便接入,单调递增 | 生成效率低,强依赖于数据库,id是连续的 | 适用于并发量不高的业务。 |
| 多数据库主键自增生成唯一id | 方便接入,单调递增,生成效率比单机数据库高 | 不方便扩容,强依赖于数据库,id是连续的 | 适合分库分表的架构生成id |
| 数据库分段发号生成唯一id | 效率高 | 强依赖于数据库,id是连续的 | 适合id生成并发量高的业务,并且id连续 不会破坏信息安全的业务。 |
| 基于snowflake算法生成唯一id | 效率高,运行期间可以不依赖其他组件 | id分布不均,对有些业务会造成数据倾斜的问题 | 适合id生成并发量高的业务 |
1.UUID
简单的来说,UUID是服务器在不需要任何外界依赖(像类Snowflake算法的方案都需要注册中心)的情况下,基于当前时间、计数器(counter)和硬件标识等等信息生成的唯一ID。
优点
无任何依赖
其他的技术方案都是有依赖的,比如单机数据库主键自增生成ID强依赖数据库,类Snowflake算法的方案至少启动时都需要注册中心,Leaf框架Snowflake模式需要定时上传时间戳到注册中心,的UUID生成不需要任何外界依赖,
缺点
ID太长,且不是数字类型
当然为了唯一性,带来的牺牲就是生成的结果一般是32位的字符串。由于字符串太长,并且不是数字类型,所以不适合作为数据库的主键。
(字符串作为主键id,插入数据时会是在聚集索引中是随机插入,容易造成页分离。而且字符串的比较比数字类型的开销更大,字符串作为主键id查询效率会低于数字类型的主键。)
适用场景
通常可以作为一些临时性唯一标识,例如用户登陆后,生成一个UUID作为登录的会话ID,作为key存储在Redis中,Value是用户相关的信息。
2.单机数据库主键自增
业务量不大时普遍采用这种方案来生成id。
优点
方便接入
因为一般的项目不一定会用到Zookeeper等这些组件,但是基本都会用到数据库,所以项目接入会比较简单,也没有增加额外的维护成本。
单调递增
是绝对的单调递增的,就是从时间线上看,后面生成的id肯定比前面生成的id要大。
缺点
生成id效率有限
因为id生成依赖于单机数据库的主键自增,所以无法满足id并发量很大的业务需求。
强依赖于数据库
一旦单机数据库发生宕机,就没法生成id,导致整个系统不可用。如果数据库是主从架构的,主库发生故障,切换成从库,如果从库还没来得及收到主库最新的插入id的更新,就有可能导致从库当前的自增id不是最新的,从而生成出重复的id。
id是连续的
id是连续的有可能会成为缺点,竞争对手在当天12点下一个订单,然后在第二天12点下一个订单,可能根据订单id的差就可以推测出每天的订单量。像猫眼电影就使用了这种方法来生成电影的id。一般我们日常使用时,其实为了让我们生成id的方式更难被竞争对手猜测出,一般是不会从1开始的,但是猫眼电影这里是从1开始的,而且是连续的,所以我们使用二分法很快就确定了8875是最大的值,也就是总共有8875部电影,而且由于是连续的,爬取也会比较方便。猫眼电影的id——也是使用单机数据库生成的,连续自增的
https://maoyan.com/films/1
https://maoyan.com/films/2
https://maoyan.com/films/8874
https://maoyan.com/films/8875
https://maoyan.com/films/8876
(1到8875可以请求到数据,8876及后面的id
请求不到数据,没有这些id对应的电影,说明总共有8875部电影)
除非去做额外的处理(例如定时去获取当前的自增起始值a,然后生成一个随机数b,使用alter table users AUTO_INCREMENT=a+b;命令对自增起始值修改,也就是跳过一些id。)
适用场景
适用于并发量不高的业务。
3.多数据库主键自增生成唯一id。(设置步长区分不同数据库)
可以使用以下命令设置MySQL中表每次自增时的步长,通过将不同数据库的步长设置为一样,可以让不同数据库生成的id进行区分。
CREATE TABLE table (...) AUTO_INCREMENT = n;
alter table auto_increment=2;
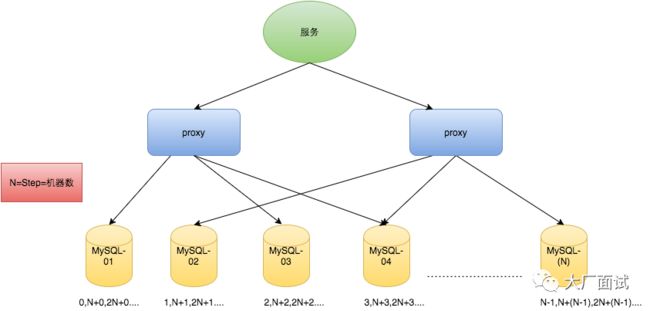 例如,步长是等于数据库的数量,例如有N台数据库, 第一台数据库的起始值是0,那么生成的id就是0,N,2N,3N等等。
例如,步长是等于数据库的数量,例如有N台数据库, 第一台数据库的起始值是0,那么生成的id就是0,N,2N,3N等等。
第一台数据库的起始值是1,那么生成的id就是1,N+1,2N+1,3N+1等等。这样各个数据库生成的id就不会冲突,并且每个数据库可以单独生成id。
优点
生成id的效率比单台数据库要高,因为可以多台数据库同时发号。
缺点
是解决了每次自增是1的问题,缺点是一旦设置了步长,就不方便扩容了,因为分库分表的表的数量已经定下来了。
使用场景
在没有分库分表的框架以前,那些分库分表就是使用这种方案来实现的。
4.数据库分段发号生成唯一id。(例如美团的Leaf框架中的segement模式)
简单来说,就是像下图一样,用一个数据库表来充当发号器, 表中字段介绍如下:
biz_tag字段用于区分每种id应用的业务,
max_id字段记录了当前已生成的最大的id,
step字段代表每次可以获取id的数量
 id生成项目每次使用下面这条语句从数据库获取step数量的id,并且更新max_id的值,将step数量的id存储在内存中,供业务方通过HTTP,RPC,Client等方式来获取。
id生成项目每次使用下面这条语句从数据库获取step数量的id,并且更新max_id的值,将step数量的id存储在内存中,供业务方通过HTTP,RPC,Client等方式来获取。
UPDATE leaf_alloc SET max_id = max_id + step WHERE biz_tag = #{tag}
优点
效率高
生成id的效率取决于step的大小,不会像主键自增生成id那样再受限于数据库的数量。
缺点
强依赖于数据库
还是强依赖于数据库,数据库宕机后,虽然id生成系统靠内存中还未使用完id,可以维持系统正常运行一段时间,但是数据库不可用还是会导致整个系统不可用。
id是连续的
容易造成被爬取,以及被竞争对手猜测出一天的订单量
5.基于snowflake算法生成唯一id
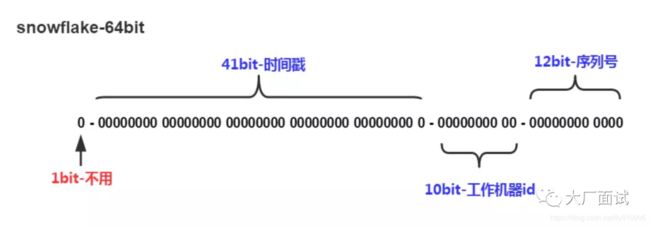
snowflake是推特开源分布式ID生成算法,一共有64位,
第一位是0,是标志位,因为在二进制数中,第一位是0,代表是正数。
接下来41位是13位的毫秒时间戳,最大可以到2039年9月。
再接下来10个二进制位是workID,也就是服务器的id。
最后面12位是业务序列号
 意味着每毫秒最大可以生成2的12次方个id,4096个,支持每个机器每毫秒生成4096个id,每秒可以生成400多万的id
意味着每毫秒最大可以生成2的12次方个id,4096个,支持每个机器每毫秒生成4096个id,每秒可以生成400多万的id
优点
效率高
生成id的效率比较快,最高在1ms内可以生成2的12次方,也就是4096个id。
不依赖其他组件
生成id的过程中,主要是根据时间戳,workID,序列号来进行生成,可以做到不额外依赖其他组件,只依赖于本地系统时间独立地生成id。
缺点
易造成数据倾斜的问题
举例:一个数据库中总共有10个id,分别是
0,25,26,27,28,29,30,31,32,100
id的最小值是0,最大值是100,按照id最大值减去最小值,进行范围切分,分成四段的话,范围是以下四个范围:
[0,25), 存在1个id,值分别是0
[25,50) 存在8个id,值分别是25,26,27,28,29,30,31,32
[50,75),存在0个id
[75,100] 存在1个100,值是100
这样明显就会存在数据倾斜的问题,就是[25,50) 这个区间存在的id数量特别多,而其他区间存在的id数量特别少。如果我们用Sqoop将MySQL中的数据导入到Hive中去时,就是按照这种id最大值减去最小值,进行范围切分实现方法进行数据分片,然后多线程进行数据导入,每个线程负责一个分片的数据,数据不均匀的话,导入的时间就会变长,有些线程分配的数据量少,导入很快,有些线程分配的数据量大导入很慢。总导入时间取决于最慢的那个线程的时间。
使用Snowflake生成的id,id值的大小因为取决于生成id时的时间戳,如果某一个时间段爬取了大量文章进行入库,在很短的时候内生成了很多id,而其他时间段生成id数量很少,在使用Sqoop导入数据时就会有数据倾斜的问题,需要单独自己进行数据切分,让数据变均匀,然后进行导入。
二、当前大公司的ID生成方案研究
头条
头条的内容主要分为文章,图集,视频,这三种内容的数据来源主要由编辑发布,及从其他网站抓取。
调研方法
这是一篇头条的一篇文章 https://www.toutiao.com/a6841306705796530700/
id是19位,因为19位的id其实从数量级是上看已经是2的9次方 亿级别了,所以不太可能有这么多文章入库,然后通过数据库主键id递增生成的,所以有很大的可能性是通过snowflake算法生成的,
我们将6841306705796530700转换为二进制数后是
10111 10111 10001 00110 10000 11001 11011 11101 00000 00000 00010 00001 100
一共是63位,因为原始的snowflake算法是1标志位+41位毫秒时间戳+10位机器位+12位序列号,所以我们取前41位
10111 10111 10001 00110 10000 11001 11011 11101 0
去转换成10进制数,得到
1631094623994
转换为毫秒时间戳,是
2021-09-08 17:50:23
这是未来的时间,所以不太可能是这种方案,因为其实1ms的ID并发量其实根本不需要2的12次方,也就是4096那么大,1s内的QPS能有几百都是量特别大了,
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
问:每天300w PV 的在单台机器上,这台机器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
根据这个原理来算的话,假设每天有300万个请求,摊到峰值时间,每秒的QPS峰值也就是139。而且每天也很难有300万篇文章入库,导致需要300万个id,所以QPS其实是很小的。头条有可能是使用的是1标志位+31位秒级时间戳+32为自己定义的机器位和序列位,所以我们取了前31位
10111 10111 10001 00110 10000 11001 1
转换为10进制数是
1592865843
按照秒级时间戳换算也就是
2020-06-23 06:44:03
跟文章的发文时间2020-06-23 06:44:52是很相近。有一定的时间差可能是因为id里面的时间戳是入库的创建时间(编辑点击新建文章按钮进入编辑页面),而界面显示的是文章的发布时间。
详细的调研结果
我们通过抽取了一些id转换为二进制后,猜测id二进制位组成是31位秒级时间戳+10位的序列位+18位的预留位+4位的机器位,其实看表里面发现18位的预留位都是000000000000100000。最多支持32台ID生成机器同时运行,单台机器QPS最高可达到1024,总QPS最高可以达到32768。(目前不知道18位预留位的作用)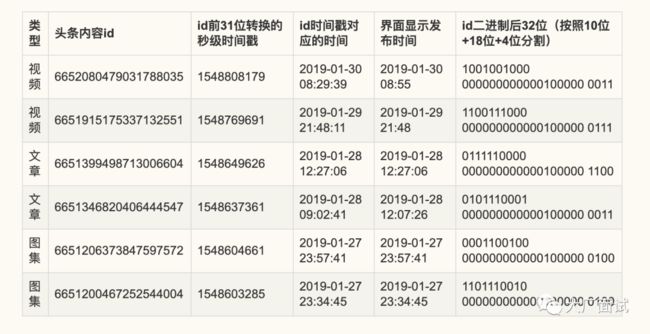
美团
猫眼电影
猜测是单机数据库连续自增实现的,id范围是1到8875,一共8875部电影。
https://maoyan.com/films/1
https://maoyan.com/films/2
https://maoyan.com/films/428
https://maoyan.com/films/429
榛果民宿——不连续自增
发现id是从2500000后才有数据的,而且很多id都不是连续的,猜测是使用Leaf-Segement模式来生成的id,每次从数据库取一个id号段,将可用id存储到内存中,然后等业务系统请求进行发放。并且自己额外做了id抛弃策略,让id不连续保证信息安全性及提高抓取难度。
https://phoenix.meituan.com/housing/2680748 //无数据
https://phoenix.meituan.com/housing/2680749 //有数据
https://phoenix.meituan.com/housing/2680750 //有数据
https://phoenix.meituan.com/housing/2680751 //无数据
https://phoenix.meituan.com/housing/2680752 //有数据
美团外卖订单号
肯定是使用snowflake算法来生成的,但是由于它们的时间位使用的是时间差(就是时间戳减去一个指定的时间点),而且位数分配可能做了额外的处理,所以不太好推断。
| 外卖 | 下单时间 |
|---|---|
| 5026 0271 7642 2612 7 | 2018-09-02 17:46:03 |
| 6233 7340 1594 0462 | 2018-07-17 18:34:11 |
| 3962 9431 3190 0632 1 | 2018-07-15 11:52:55 |
| 2273 5322 6921 7033 5 | 2017-06-30 11:39:01 |
汽车之家
使用的就是自增id,现有数据从4位到6位,目前最大320w+,实现原理应该就是数据库主键自增,由于他们的量比较大,应该是采用的多数据库设置步长,来多数据库生成id的。
下面是统计表
| 作品id | URL | 类型 |
|---|---|---|
| 9999 | https://chejiahao.autohome.com.cn/info/9999 | 轻文 |
| 3200292 | https://chejiahao.autohome.com.cn/info/3200292 | 轻文 |
| 3200293 | https://chejiahao.autohome.com.cn/info/3200293 | 视频 |
| 3200294 | https://chejiahao.autohome.com.cn/info/3200294 | 文章 |
| 3292759 | https://chejiahao.autohome.com.cn/info/3292759 | 车单 |
| 2037191 | https://chejiahao.autohome.com.cn/info/2037191 | 音频 |
总结
感觉目前大公司还是使用Snowflake作为分布式ID生成方案的比较多,一方面可以满足并发量很高的id获取需求,一方面id连续性很低,可以保证信息安全,提高爬虫难度。除此以外,可能有一些业务刚起步时并发量小直接采用单机数据库主键自增生成id,使用4.数据库分段发号生成唯一id这种方案也能满足高并发量,但主要还是id是连续的,即便是额外开发id丢弃逻辑,也容易被竞争对手一个一个id请求来推测出订单量信息。

精彩回顾:
【大厂面试08期】谈一谈你对HashMap的理解?
【大厂面试07期】说一说你对synchronized锁的理解?
【大厂面试06期】谈一谈你对Redis持久化的理解?
【大厂面试05期】说一说你对MySQL中锁的理解?
【大厂面试04期】讲讲一条MySQL更新语句是怎么执行的?
【大厂面试03期】MySQL是怎么解决幻读问题的?
【大厂面试02期】Redis过期key是怎么样清理的?
【大厂面试01期】高并发场景下,如何保证缓存与数据库一致性?
建了一个技术群,欢迎大家进群交流,一起学习进步!进群还领取《大厂面试指北》PDF版(如果二维码失效了,大家可以去公众号菜单栏获取进群二维码)