数据基础---《利用Python进行数据分析·第2版》第11章 时间序列
之前自己对于numpy和pandas是要用的时候东学一点西一点,直到看到《利用Python进行数据分析·第2版》,觉得只看这一篇就够了。非常感谢原博主的翻译和分享。
时间序列(time series)数据是一种重要的结构化数据形式,应用于多个领域,包括金融学、经济学、生态学、神经科学、物理学等。在多个时间点观察或测量到的任何事物都可以形成一段时间序列。很多时间序列是固定频率的,也就是说,数据点是根据某种规律定期出现的(比如每15秒、每5分钟、每月出现一次)。时间序列也可以是不定期的,没有固定的时间单位或单位之间的偏移量。时间序列数据的意义取决于具体的应用场景,主要有以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒钟饼干的直径。
本章主要讲解前3种时间序列。许多技术都可用于处理实验型时间序列,其索引可能是一个整数或浮点数(表示从实验开始算起已经过去的时间)。最简单也最常见的时间序列都是用时间戳进行索引的。
提示:pandas也支持基于timedeltas的指数,它可以有效代表实验或经过的时间。这本书不涉及timedelta指数,但你可以学习pandas的文档(http://pandas.pydata.org/)。
pandas提供了许多内置的时间序列处理工具和数据算法。因此,你可以高效处理非常大的时间序列,轻松地进行切片/切块、聚合、对定期/不定期的时间序列进行重采样等。有些工具特别适合金融和经济应用,你当然也可以用它们来分析服务器日志数据。
11.1 日期和时间数据类型及工具
Python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到datetime、time以及calendar模块。datetime.datetime(也可以简写为datetime)是用得最多的数据类型:
from datetime import datetime
now = datetime.now()
now
datetime.datetime(2018, 10, 16, 17, 39, 7, 590407)
now.year,now.month,now.day
(2018, 10, 16)
datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差
datetime(2011, 1, 7)
datetime.datetime(2011, 1, 7, 0, 0)
delta = datetime(2011,1,7)-datetime(2008,6,24,8,15)
delta
datetime.timedelta(926, 56700)
表示926天又56700秒(大约15.75个小时)
delta.days
926
delta.seconds
56700
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象:
from datetime import timedelta
start = datetime(2011, 1, 7)
start + timedelta(12)#默认时间间隔的单位是天,也可以自己进行设置
datetime.datetime(2011, 1, 19, 0, 0)
start - 2 * timedelta(12)
datetime.datetime(2010, 12, 14, 0, 0)
datetime模块中的数据类型参见表10-1。虽然本章主要讲的是pandas数据类型和高级时间序列处理,但你肯定会在Python的其他地方遇到有关datetime的数据类型。
| 类型 | 说明 |
|---|---|
| date | 以公历形式存储日历日期(年、月、日) |
| time | 将时间存储为时、分、秒、毫秒 |
| datetime | 存储日期和时间 |
| timedelta | 表示两个 datetime值之间的差(日、秒、毫秒) |
| tzinfo | 存储时区信息的基本类型 |
字符串和datetime的相互转换
stamp = datetime(2011, 1, 3)
str(stamp)
'2011-01-03 00:00:00'
stamp.strftime('%Y-%m-%d')#我一般固定使用这种方法转换,就不会跟更种其他用法产生混乱
'2011-01-03'
datetime格式定义可参考其他资料
datetime.strptime可以用这些格式化编码将字符串转换为日期:
value = '2011-01-03'
datetime.strptime(value,'%Y-%m-%d')
datetime.datetime(2011, 1, 3, 0, 0)
datestrs = ['7/6/2011', '8/6/2011']
[datetime.strptime(x,'%m/%d/%Y') for x in datestrs]
[datetime.datetime(2011, 7, 6, 0, 0), datetime.datetime(2011, 8, 6, 0, 0)]
datetime.strptime是通过已知格式进行日期解析的最佳方式。但是每次都要编写格式定义是很麻烦的事情,尤其是对于一些常见的日期格式。这种情况下,你可以用dateutil这个第三方包中的parser.parse方法(pandas中已经自动安装好了):
from dateutil.parser import parse
parse('2011-01-03')
datetime.datetime(2011, 1, 3, 0, 0)
dateutil可以解析几乎所有人类能够理解的日期表示形式:
parse('Jan 31, 1997 10:45 PM')
datetime.datetime(1997, 1, 31, 22, 45)
在国际通用的格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决这个问题:
parse('6/12/2011',dayfirst=True)
datetime.datetime(2011, 12, 6, 0, 0)
parse('6/12/2011')
datetime.datetime(2011, 6, 12, 0, 0)
pandas通常是用于处理成组日期的,不管这些日期是DataFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快:
import pandas as pd
datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']
pd.to_datetime(datestrs)
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
自动处理完后变成了DatetimeIndex对象
它还可以处理缺失值(None、空字符串等):
idx=pd.to_datetime(datestrs + [None])
idx
DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None)
pd.isnull(idx)
array([False, False, True])
NaT(Not a Time)是pandas中时间戳数据的null值。
注意:dateutil.parser是一个实用但不完美的工具。比如说,它会把一些原本不是日期的字符串认作是日期(比如"42"会被解析为2042年的今天)。
datetime对象还有一些特定于当前环境(位于不同国家或使用不同语言的系统)的格式化选项。例如,德语或法语系统所用的月份简写就与英语系统所用的不同。表11-3进行了总结。
| 代码 | 说明 |
|---|---|
| %a | 星期几的简写 |
| %A | 星期几的全称 |
| %b | 月份的简写 |
| %B | 月份的全称 |
| %c | 完整的日期和时间,例如“Tue 01 May 2012 04:20:57PM |
| %p | 不同环境中的AM或PM |
| %x | 适合于当前环境的日期格式,例如,在美国,“May1,2012”会产生05/01/2012 |
| %X | 适合于当前环境的时间格式,例如“04:24:12 PM” |
11.2 时间序列基础
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series:
from datetime import datetime
import numpy as np
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),datetime(2011, 1, 7), datetime(2011, 1, 8), datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts=pd.Series(np.random.randn(6),index=dates)
ts
2011-01-02 1.367002
2011-01-05 -1.075364
2011-01-07 1.177715
2011-01-08 0.235663
2011-01-10 -0.404561
2011-01-12 -0.279518
dtype: float64
可以看到直接将datetime对象赋给了index,但其实这些datetime对象实际上是被放在一个DatetimeIndex中的,从结果看DatetimeIndex有对datetime对象作进一步的规整:
ts.index
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐:
ts+ts[::2]#ts[::2] 是每隔两个取一个。
2011-01-02 2.734004
2011-01-05 NaN
2011-01-07 2.355430
2011-01-08 NaN
2011-01-10 -0.809121
2011-01-12 NaN
dtype: float64
pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳:
ts.index.dtype
dtype('DatetimeIndex中的各个标量值是pandas的Timestamp对象:
stamp=ts.index[0]
stamp
Timestamp('2011-01-02 00:00:00')
只要有需要,TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话),且知道如何执行时区转换以及其他操作。稍后将对此进行详细讲解。
索引、选取、子集构造
当你根据标签索引选取数据时,时间序列和其它的pandas.Series很像:
stamp=ts.index[2]
ts[stamp]
1.1777148947786458
还有一种更为方便的用法:传入一个可以被解释为日期的字符串:其实道理是一样的,如上面那样,我们可以用时间戳来索引数据,我们可以看成这里日期的字符串先转成了时间戳索引
ts['1/10/2011']
-0.4045606741689914
ts['20110110']
-0.4045606741689914
对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
longer_ts=pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods=1000))
longer_ts
2000-01-01 -0.695152
2000-01-02 0.490721
2000-01-03 0.057702
2000-01-04 -0.144661
2000-01-05 0.854743
2000-01-06 -0.620803
2000-01-07 -0.544654
2000-01-08 -0.975185
2000-01-09 1.932819
2000-01-10 0.939155
2000-01-11 -0.467155
2000-01-12 0.406459
2000-01-13 0.442194
2000-01-14 0.190556
2000-01-15 0.426418
2000-01-16 0.967863
2000-01-17 0.675566
2000-01-18 0.106862
2000-01-19 -1.975229
2000-01-20 1.097981
2000-01-21 1.801745
2000-01-22 2.113984
2000-01-23 0.958273
2000-01-24 -1.089947
2000-01-25 -0.693382
2000-01-26 -1.230901
2000-01-27 -1.178079
2000-01-28 -0.261554
2000-01-29 0.385875
2000-01-30 -1.129497
...
2002-08-28 0.123033
2002-08-29 -1.364800
2002-08-30 0.108372
2002-08-31 0.105880
2002-09-01 -0.184650
2002-09-02 -1.394003
2002-09-03 0.099957
2002-09-04 0.595101
2002-09-05 1.687308
2002-09-06 1.718821
2002-09-07 1.313495
2002-09-08 0.747596
2002-09-09 2.477120
2002-09-10 -1.145726
2002-09-11 -1.157853
2002-09-12 -2.349212
2002-09-13 1.927618
2002-09-14 -1.527638
2002-09-15 0.494005
2002-09-16 -0.708996
2002-09-17 -1.187589
2002-09-18 -1.226050
2002-09-19 1.596807
2002-09-20 -2.539985
2002-09-21 0.471234
2002-09-22 -2.177011
2002-09-23 -0.448872
2002-09-24 -0.527784
2002-09-25 1.006599
2002-09-26 -1.892320
Freq: D, Length: 1000, dtype: float64
longer_ts['2001']
2001-01-01 -0.309328
2001-01-02 -0.612142
2001-01-03 -0.118255
2001-01-04 1.110361
2001-01-05 0.375092
2001-01-06 1.097576
2001-01-07 0.633201
2001-01-08 0.560926
2001-01-09 0.089869
2001-01-10 1.774513
2001-01-11 0.451253
2001-01-12 0.750574
2001-01-13 -0.227574
2001-01-14 -0.121207
2001-01-15 1.168656
2001-01-16 0.076074
2001-01-17 -1.484041
2001-01-18 0.715347
2001-01-19 -0.499619
2001-01-20 1.209174
2001-01-21 -1.257921
2001-01-22 0.498747
2001-01-23 0.487024
2001-01-24 0.451236
2001-01-25 -0.464199
2001-01-26 0.969991
2001-01-27 1.385279
2001-01-28 1.190629
2001-01-29 -0.666683
2001-01-30 -1.328294
...
2001-12-02 -1.077133
2001-12-03 -1.287080
2001-12-04 2.895630
2001-12-05 -1.306801
2001-12-06 1.088254
2001-12-07 0.176656
2001-12-08 1.391077
2001-12-09 0.776549
2001-12-10 -0.715340
2001-12-11 -0.220713
2001-12-12 -0.854277
2001-12-13 -1.304135
2001-12-14 -0.691430
2001-12-15 -0.562327
2001-12-16 1.081123
2001-12-17 1.566561
2001-12-18 0.469260
2001-12-19 -0.151059
2001-12-20 -0.203601
2001-12-21 -0.454817
2001-12-22 -0.406576
2001-12-23 0.305009
2001-12-24 -0.177214
2001-12-25 0.776997
2001-12-26 -0.611962
2001-12-27 -1.042043
2001-12-28 -0.017181
2001-12-29 -1.381223
2001-12-30 -0.089794
2001-12-31 0.254798
Freq: D, Length: 365, dtype: float64
这里,字符串“2001”被解释成年,并根据它选取时间区间。指定月也同样奏效:这样就很方便了,不需要自己去截取一部字符串
longer_ts['2001-05']
2001-05-01 -2.291270
2001-05-02 -0.956773
2001-05-03 -0.364571
2001-05-04 0.369068
2001-05-05 0.696646
2001-05-06 -1.237324
2001-05-07 1.548785
2001-05-08 1.659536
2001-05-09 -0.344854
2001-05-10 1.108528
2001-05-11 0.183657
2001-05-12 -0.454190
2001-05-13 -0.305806
2001-05-14 -0.392677
2001-05-15 -0.080647
2001-05-16 0.072310
2001-05-17 -0.155399
2001-05-18 1.541267
2001-05-19 -1.478289
2001-05-20 -0.213289
2001-05-21 0.286438
2001-05-22 -0.446343
2001-05-23 -0.942977
2001-05-24 0.282540
2001-05-25 0.615960
2001-05-26 -1.003852
2001-05-27 1.004090
2001-05-28 1.585460
2001-05-29 -0.311037
2001-05-30 0.107670
2001-05-31 0.420645
Freq: D, dtype: float64
datetime对象也可以用来切片:
ts[datetime(2011, 1, 7):]
2011-01-07 1.177715
2011-01-08 0.235663
2011-01-10 -0.404561
2011-01-12 -0.279518
dtype: float64
由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询):
ts
2011-01-02 1.367002
2011-01-05 -1.075364
2011-01-07 1.177715
2011-01-08 0.235663
2011-01-10 -0.404561
2011-01-12 -0.279518
dtype: float64
ts['1/6/2011':'1/11/2011']
2011-01-07 1.177715
2011-01-08 0.235663
2011-01-10 -0.404561
dtype: float64
跟之前一样,你可以传入字符串日期、datetime或Timestamp。注意,这样切片所产生的是原时间序列的视图,跟NumPy数组的切片运算是一样的。
这意味着,没有数据被复制,对切片进行修改会反映到原始数据上。
此外,还有一个等价的实例方法也可以截取两个日期之间TimeSeries:
ts.truncate(after='1/9/2011')
2011-01-02 1.367002
2011-01-05 -1.075364
2011-01-07 1.177715
2011-01-08 0.235663
dtype: float64
这些操作对DataFrame也有效。例如,对DataFrame的行进行索引:
dates=pd.date_range('1/1/2000',periods=100,freq='W-WED')
dates
DatetimeIndex(['2000-01-05', '2000-01-12', '2000-01-19', '2000-01-26',
'2000-02-02', '2000-02-09', '2000-02-16', '2000-02-23',
'2000-03-01', '2000-03-08', '2000-03-15', '2000-03-22',
'2000-03-29', '2000-04-05', '2000-04-12', '2000-04-19',
'2000-04-26', '2000-05-03', '2000-05-10', '2000-05-17',
'2000-05-24', '2000-05-31', '2000-06-07', '2000-06-14',
'2000-06-21', '2000-06-28', '2000-07-05', '2000-07-12',
'2000-07-19', '2000-07-26', '2000-08-02', '2000-08-09',
'2000-08-16', '2000-08-23', '2000-08-30', '2000-09-06',
'2000-09-13', '2000-09-20', '2000-09-27', '2000-10-04',
'2000-10-11', '2000-10-18', '2000-10-25', '2000-11-01',
'2000-11-08', '2000-11-15', '2000-11-22', '2000-11-29',
'2000-12-06', '2000-12-13', '2000-12-20', '2000-12-27',
'2001-01-03', '2001-01-10', '2001-01-17', '2001-01-24',
'2001-01-31', '2001-02-07', '2001-02-14', '2001-02-21',
'2001-02-28', '2001-03-07', '2001-03-14', '2001-03-21',
'2001-03-28', '2001-04-04', '2001-04-11', '2001-04-18',
'2001-04-25', '2001-05-02', '2001-05-09', '2001-05-16',
'2001-05-23', '2001-05-30', '2001-06-06', '2001-06-13',
'2001-06-20', '2001-06-27', '2001-07-04', '2001-07-11',
'2001-07-18', '2001-07-25', '2001-08-01', '2001-08-08',
'2001-08-15', '2001-08-22', '2001-08-29', '2001-09-05',
'2001-09-12', '2001-09-19', '2001-09-26', '2001-10-03',
'2001-10-10', '2001-10-17', '2001-10-24', '2001-10-31',
'2001-11-07', '2001-11-14', '2001-11-21', '2001-11-28'],
dtype='datetime64[ns]', freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4), index=dates,columns=['Colorado', 'Texas','New York', 'Ohio'])
long_df.loc['5-2001']
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2001-05-02 | 0.502144 | -0.675565 | 0.010877 | -0.141896 |
| 2001-05-09 | 0.686185 | -1.244643 | 0.737462 | 0.603310 |
| 2001-05-16 | 2.093320 | -1.844095 | -1.557235 | 1.336359 |
| 2001-05-23 | 0.052609 | -0.263812 | -0.963784 | 0.452913 |
| 2001-05-30 | -0.856077 | 1.726397 | 0.556801 | -0.699935 |
带有重复索引的时间序列
在某些应用场景中,可能会存在多个观测数据落在同一个时间点上的情况。下面就是一个例子:
dates=pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000','1/2/2000', '1/3/2000'])
dup_ts = pd.Series(range(5),index=dates)
dup_ts
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int64
通过检查索引的is_unique属性,我们就可以知道它是不是唯一的:
dup_ts.index.is_unique
False
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复:
dup_ts['1/3/2000']#直接用字符串也能索引
4
dup_ts['1/2/2000']
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int64
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法是使用groupby,并传入level=0:
grouped = dup_ts.groupby(level=0)
grouped.mean()
2000-01-01 0
2000-01-02 2
2000-01-03 4
dtype: int64
11.3 日期的范围、频率以及移动
pandas中的原生时间序列一般被认为是不规则的,也就是说,它们没有固定的频率。对于大部分应用程序而言,这是无所谓的。但是,它常常需要以某种相对固定的频率进行分析,比如每日、每月、每15分钟等(这样自然会在时间序列中引入缺失值)。幸运的是,pandas有一整套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具。例如,我们可以将之前那个时间序列转换为一个具有固定频率(每日)的时间序列,只需调用resample即可:
ts
2011-01-02 1.367002
2011-01-05 -1.075364
2011-01-07 1.177715
2011-01-08 0.235663
2011-01-10 -0.404561
2011-01-12 -0.279518
dtype: float64
resampler = ts.resample('D')
resampler
DatetimeIndexResampler [freq=, axis=0, closed=left, label=left, convention=start, base=0]
字符串“D”是每天的意思。
频率的转换(或重采样)是一个比较大的主题,稍后将专门用一节来进行讨论(11.6小节)。这里,我将告诉你如何使用基本的频率和它的倍数。
生成日期范围
虽然我之前用的时候没有明说,但你可能已经猜到pandas.date_range可用于根据指定的频率生成指定长度的DatetimeIndex:
index=pd.date_range('2012-04-01', '2012-06-01')
index
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:
pd.date_range(start='2012-04-01',periods=20)
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM"频率(表示business end of month,表11-4是频率列表),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
pd.date_range('2000-01-01', '2000-12-01',freq='BM')
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
| 别名 | 偏移量类型 | 说明 |
|---|---|---|
| D | Day | 每日历日 |
| B | BusinessDay | 每工作日 |
| H | Hour | 每小时 |
| T或min | Minute | 每分 |
| S | Second | 每秒 |
| L或ms | Mili | 每毫秒(即每千分之一秒) |
| U | Micro | 每微秒(即每百万分之一秒) |
| M | MonthEnd | 每月最后一个日历日 |
| BM | Businessmonth End | 每月最后一个工作日 |
| MS | MonthBegin | 每月第一个日历日 |
| BMS | BusinessMonth Begin | 每月第一个工作日 |
| W-MON、W-TUE | Week | 从指定的星期几(MON、TUE、WED、THU、FRI、SAT、SUN)开始算起,每周 |
| WOM-1MON、WOM-2MoN… | WeekOfMonth | 产生每月第一、第二、第三或第四周的星期几。例如,WOM-3FRI表示每月第3个星期五 |
| Q-JAN、Q-FEB | QuarterEnd | 对于以指定月份(JAN、FEB、MAR、APR、MAY、JUN、JUL、AUG、SEP、OCT、NOV、DEC)结束的年度,每季度最后一月的最后一个日历日 |
| BQ-JAN、BQ-FEB | BusinessQuarter End | 对于以指定月份结束的年度,每季度最后一月的最后一个工作日 |
| QS-JAN、 QS-FEB | QuarterBegin | 对于以指定月份结束的年度,每季度最后一月的第一个日历日 |
| BQS-JAN、 BQS-FEB | BusinessQuarterBegin | 对于以指定月份结束的年度,每季 |
| A-JAN、A-FEB | YearEnd | 每年指定月份(JAN、FEB、MAR、APR、MAY、JUN、JUL、AUG、SEP、OCT、NOV、DEC)的最后一个日历日 |
| BA-JAN、BA-FEB… | BusinessYearEnd | 每年指定月份的最后一个工作日 |
| AS-JAN、AS-FEB | YearBegin | 每年指定月份的第一个日历日 |
| BAS-JAN、BAS-FEB | BusinessYearBegin | 每年指定月份的第一个工作日 |
pandas.date_range freq参数枚举
扩展已有的日期范围
已有日期范围可能不是datetimeindex模式
#生成日期范围
esindex=pd.date_range(df.index[-1],periods=1000,freq='30S')
#将日期范围转换成字符型(分两步走)
esindex=list(esindex.to_pydatetime())
esindex=list(map(lambda x:datetime.strftime(x,'%Y-%m-%d %H:%M:%S'),list(esindex)))
#将新旧日期范围合并
indexT=list(df.index)
indexT.extend(esindex[1:-1])
WOM日期
WOM(Week Of Month)是一种非常实用的频率类,它以WOM开头。它使你能获得诸如“每月第3个星期五”之类的日期:
rng=pd.date_range('2012-01-01', '2012-09-01',freq='WOM-3FRI')
rng
DatetimeIndex(['2012-01-20', '2012-02-17', '2012-03-16', '2012-04-20',
'2012-05-18', '2012-06-15', '2012-07-20', '2012-08-17'],
dtype='datetime64[ns]', freq='WOM-3FRI')
list(rng)
[Timestamp('2012-01-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-02-17 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-08-17 00:00:00', freq='WOM-3FRI')]
移动(超前和滞后)数据
移动(shifting)指的是沿着时间轴将数据前移或后移。Series和DataFrame都有一个shift方法用于执行单纯的前移或后移操作,保持索引不变:
ts=pd.Series(np.random.randn(4),index=pd.date_range('1/1/2000',periods=4,freq='M'))
ts
2000-01-31 0.600662
2000-02-29 0.357738
2000-03-31 0.687984
2000-04-30 -0.515376
Freq: M, dtype: float64
ts.shift(2)
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 0.600662
2000-04-30 0.357738
Freq: M, dtype: float64
ts.shift(-2)
2000-01-31 0.687984
2000-02-29 -0.515376
2000-03-31 NaN
2000-04-30 NaN
Freq: M, dtype: float64
当我们这样进行移动时,就会在时间序列的前面或后面产生缺失数据。
shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的百分比变化。可以这样表达:
ts/ts.shift(1)
2000-01-31 NaN
2000-02-29 0.595572
2000-03-31 1.923151
2000-04-30 -0.749111
Freq: M, dtype: float64
ts / ts.shift(1) - 1
2000-01-31 NaN
2000-02-29 -0.404428
2000-03-31 0.923151
2000-04-30 -1.749111
Freq: M, dtype: float64
由于单纯的移位操作不会修改索引,所以部分数据会被丢弃。因此,如果频率已知,则可以将其传给shift以便实现对时间戳进行位移而不是对数据进行简单位移:
ts.shift(2,freq='M')
2000-03-31 0.600662
2000-04-30 0.357738
2000-05-31 0.687984
2000-06-30 -0.515376
Freq: M, dtype: float64
这里还可以使用其他频率,于是你就能非常灵活地对数据进行超前和滞后处理了:
ts.shift(3,freq='D')
2000-02-03 0.600662
2000-03-03 0.357738
2000-04-03 0.687984
2000-05-03 -0.515376
dtype: float64
ts.shift(1,freq='90T')
2000-01-31 01:30:00 0.600662
2000-02-29 01:30:00 0.357738
2000-03-31 01:30:00 0.687984
2000-04-30 01:30:00 -0.515376
Freq: M, dtype: float64
通过偏移量对日期进行位移
pandas的日期偏移量还可以用在datetime或Timestamp对象上:这个跟timedelta实现的功能好像没什么大的区别
from pandas.tseries.offsets import Day,MonthEnd
now=datetime(2011,11,17)
now+3*Day()
Timestamp('2011-11-20 00:00:00')
如果加的是锚点偏移量(比如MonthEnd),第一次增量会将原日期向前滚动到符合频率规则的下一个日期:
now+MonthEnd()
Timestamp('2011-11-30 00:00:00')
now+MonthEnd(2)
Timestamp('2011-12-31 00:00:00')
通过锚点偏移量的rollforward和rollback方法,可明确地将日期向前或向后“滚动”:
offset=MonthEnd()
offset.rollforward(now)
Timestamp('2011-11-30 00:00:00')
offset.rollback(now)
Timestamp('2011-10-31 00:00:00')
日期偏移量还有一个巧妙的用法,即结合groupby使用这两个“滚动”方法:
ts = pd.Series(np.random.randn(20),index=pd.date_range('1/15/2000', periods=20, freq='4d'))
ts
2000-01-15 -0.752742
2000-01-19 -1.414074
2000-01-23 -1.162491
2000-01-27 0.534581
2000-01-31 -0.377659
2000-02-04 -1.685432
2000-02-08 -1.782411
2000-02-12 -1.219173
2000-02-16 -0.961443
2000-02-20 -0.864551
2000-02-24 0.315910
2000-02-28 0.531089
2000-03-03 -2.682542
2000-03-07 1.436291
2000-03-11 1.613283
2000-03-15 1.448720
2000-03-19 0.442549
2000-03-23 0.538157
2000-03-27 -1.225652
2000-03-31 -0.762207
Freq: 4D, dtype: float64
ts.groupby(offset.rollforward).mean()
2000-01-31 -0.634477
2000-02-29 -0.809430
2000-03-31 0.101075
dtype: float64
当然,更简单、更快速地实现该功能的办法是使用resample(11.6小节将对此进行详细介绍):
ts.resample('M').mean()
2000-01-31 -0.634477
2000-02-29 -0.809430
2000-03-31 0.101075
Freq: M, dtype: float64
11.4 时区处理
时间序列处理工作中最让人不爽的就是对时区的处理。许多人都选择以协调世界时(UTC,它是格林尼治标准时间(Greenwich Mean Time)的接替者,目前已经是国际标准了)来处理时间序列。时区是以UTC偏移量的形式表示的。例如,夏令时期间,纽约比UTC慢4小时,而在全年其他时间则比UTC慢5小时。
在Python中,时区信息来自第三方库pytz,它使Python可以使用Olson数据库(汇编了世界时区信息)。这对历史数据非常重要,这是因为由于各地政府的各种突发奇想,夏令时转变日期(甚至UTC偏移量)已经发生过多次改变了。就拿美国来说,DST转变时间自1900年以来就改变过多次!
有关pytz库的更多信息,请查阅其文档。就本书而言,由于pandas包装了pytz的功能,因此你可以不用记忆其API,只要记得时区的名称即可。时区名可以在shell中看到,也可以通过文档查看:
import pytz
pytz.common_timezones[-5:]
['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
要从pytz中获取时区对象,使用pytz.timezone即可:
tz = pytz.timezone('America/New_York')
tz
pandas中的方法既可以接受时区名也可以接受这些对象。
时区本地化和转换
rng=pd.date_range('3/9/2012 9:30',periods=6,freq='D')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2012-03-09 09:30:00 -1.202927
2012-03-10 09:30:00 -0.880422
2012-03-11 09:30:00 1.126177
2012-03-12 09:30:00 1.116623
2012-03-13 09:30:00 0.954839
2012-03-14 09:30:00 2.791434
Freq: D, dtype: float64
其索引的tz字段为None:
print(ts.index.tz)
None
可以用时区集生成日期范围:
pd.date_range('3/9/2012 9:30',periods=10,freq='D',tz='UTC')#tz体现在dtype上
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00', '2012-03-16 09:30:00+00:00',
'2012-03-17 09:30:00+00:00', '2012-03-18 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
从单纯(tz为none)到本地化的转换是通过tz_localize方法处理的:
ts_utc = ts.tz_localize('UTC')
ts_utc
2012-03-09 09:30:00+00:00 -1.202927
2012-03-10 09:30:00+00:00 -0.880422
2012-03-11 09:30:00+00:00 1.126177
2012-03-12 09:30:00+00:00 1.116623
2012-03-13 09:30:00+00:00 0.954839
2012-03-14 09:30:00+00:00 2.791434
Freq: D, dtype: float64
ts_utc.index
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
一旦时间序列被本地化到某个特定时区,就可以用tz_convert将其转换到别的时区了:
ts_utc.tz_convert('America/New_York')
2012-03-09 04:30:00-05:00 -1.202927
2012-03-10 04:30:00-05:00 -0.880422
2012-03-11 05:30:00-04:00 1.126177
2012-03-12 05:30:00-04:00 1.116623
2012-03-13 05:30:00-04:00 0.954839
2012-03-14 05:30:00-04:00 2.791434
Freq: D, dtype: float64
对于上面这种时间序列(它跨越了美国东部时区的夏令时转变期),我们可以将其本地化到EST,然后转换为UTC或柏林时间:
ts_eastern = ts.tz_localize('America/New_York')
ts_eastern.tz_convert('UTC')
2012-03-09 14:30:00+00:00 -1.202927
2012-03-10 14:30:00+00:00 -0.880422
2012-03-11 13:30:00+00:00 1.126177
2012-03-12 13:30:00+00:00 1.116623
2012-03-13 13:30:00+00:00 0.954839
2012-03-14 13:30:00+00:00 2.791434
Freq: D, dtype: float64
ts_eastern.tz_convert('Europe/Berlin')
2012-03-09 15:30:00+01:00 -1.202927
2012-03-10 15:30:00+01:00 -0.880422
2012-03-11 14:30:00+01:00 1.126177
2012-03-12 14:30:00+01:00 1.116623
2012-03-13 14:30:00+01:00 0.954839
2012-03-14 14:30:00+01:00 2.791434
Freq: D, dtype: float64
tz_localize和tz_convert也是DatetimeIndex的实例方法:
ts.index.tz_localize('Asia/Shanghai')
DatetimeIndex(['2012-03-09 09:30:00+08:00', '2012-03-10 09:30:00+08:00',
'2012-03-11 09:30:00+08:00', '2012-03-12 09:30:00+08:00',
'2012-03-13 09:30:00+08:00', '2012-03-14 09:30:00+08:00'],
dtype='datetime64[ns, Asia/Shanghai]', freq='D')
注意:对单纯时间戳的本地化操作还会检查夏令时转变期附近容易混淆或不存在的时间。
操作时区意识型Timestamp对象
跟时间序列和日期范围差不多,独立的Timestamp对象也能被从单纯型(naive)本地化为时区意识型(time zone-aware),并从一个时区转换到另一个时区:
stamp=pd.Timestamp('2011-03-12 04:00')
stamp
Timestamp('2011-03-12 04:00:00')
stamp_utc = stamp.tz_localize('utc')
stamp_utc
Timestamp('2011-03-12 04:00:00+0000', tz='UTC')
stamp_utc.tz_convert('America/New_York')
Timestamp('2011-03-11 23:00:00-0500', tz='America/New_York')
在创建Timestamp时,还可以传入一个时区信息:
stamp_moscow=pd.Timestamp('2011-03-12 04:00',tz='Europe/Moscow')
stamp_moscow
Timestamp('2011-03-12 04:00:00+0300', tz='Europe/Moscow')
时区意识型Timestamp对象在内部保存了一个UTC时间戳值(自UNIX纪元(1970年1月1日)算起的纳秒数)。这个UTC值在时区转换过程中是不会发生变化的:
stamp_utc.value
1299902400000000000
stamp_utc.tz_convert('America/New_York').value
1299902400000000000
当使用pandas的DateOffset对象执行时间算术运算时,运算过程会自动关注是否存在夏令时转变期。这里,我们创建了在DST转变之前的时间戳。首先,来看夏令时转变前的30分钟:
from pandas.tseries.offsets import Hour
stamp=pd.Timestamp('2012-03-12 01:30',tz='US/Eastern')
stamp
Timestamp('2012-03-12 01:30:00-0400', tz='US/Eastern')
stamp+Hour()
Timestamp('2012-03-12 02:30:00-0400', tz='US/Eastern')
然后,夏令时转变前90分钟:
stamp = pd.Timestamp('2012-11-04 00:30', tz='US/Eastern')
stamp
Timestamp('2012-11-04 00:30:00-0400', tz='US/Eastern')
stamp + 2 * Hour()
Timestamp('2012-11-04 01:30:00-0500', tz='US/Eastern')
不同时区之间的运算
如果两个时间序列的时区不同,在将它们合并到一起时,最终结果就会是UTC。由于时间戳其实是以UTC存储的,所以这是一个很简单的运算,并不需要发生任何转换:
rng=pd.date_range('3/7/2012 9:30',periods=10,freq='B')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2012-03-07 09:30:00 0.331669
2012-03-08 09:30:00 0.165117
2012-03-09 09:30:00 -1.618416
2012-03-12 09:30:00 0.068494
2012-03-13 09:30:00 -2.143064
2012-03-14 09:30:00 -1.511929
2012-03-15 09:30:00 -0.720633
2012-03-16 09:30:00 -2.511504
2012-03-19 09:30:00 -0.946298
2012-03-20 09:30:00 0.163231
Freq: B, dtype: float64
ts1=ts[:7].tz_localize('Europe/London')
ts1
2012-03-07 09:30:00+00:00 0.331669
2012-03-08 09:30:00+00:00 0.165117
2012-03-09 09:30:00+00:00 -1.618416
2012-03-12 09:30:00+00:00 0.068494
2012-03-13 09:30:00+00:00 -2.143064
2012-03-14 09:30:00+00:00 -1.511929
2012-03-15 09:30:00+00:00 -0.720633
Freq: B, dtype: float64
ts2=ts[2:].tz_localize('Europe/Moscow')
ts2
2012-03-09 09:30:00+04:00 -1.618416
2012-03-12 09:30:00+04:00 0.068494
2012-03-13 09:30:00+04:00 -2.143064
2012-03-14 09:30:00+04:00 -1.511929
2012-03-15 09:30:00+04:00 -0.720633
2012-03-16 09:30:00+04:00 -2.511504
2012-03-19 09:30:00+04:00 -0.946298
2012-03-20 09:30:00+04:00 0.163231
Freq: B, dtype: float64
result = ts1 + ts2
result
2012-03-07 09:30:00+00:00 NaN
2012-03-08 09:30:00+00:00 NaN
2012-03-09 05:30:00+00:00 NaN
2012-03-09 09:30:00+00:00 NaN
2012-03-12 05:30:00+00:00 NaN
2012-03-12 09:30:00+00:00 NaN
2012-03-13 05:30:00+00:00 NaN
2012-03-13 09:30:00+00:00 NaN
2012-03-14 05:30:00+00:00 NaN
2012-03-14 09:30:00+00:00 NaN
2012-03-15 05:30:00+00:00 NaN
2012-03-15 09:30:00+00:00 NaN
2012-03-16 05:30:00+00:00 NaN
2012-03-19 05:30:00+00:00 NaN
2012-03-20 05:30:00+00:00 NaN
dtype: float64
result.index
DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
'2012-03-09 05:30:00+00:00', '2012-03-09 09:30:00+00:00',
'2012-03-12 05:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 05:30:00+00:00', '2012-03-13 09:30:00+00:00',
'2012-03-14 05:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 05:30:00+00:00', '2012-03-15 09:30:00+00:00',
'2012-03-16 05:30:00+00:00', '2012-03-19 05:30:00+00:00',
'2012-03-20 05:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq=None)
11.5 时期及其算术运算
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。Period类所表示的就是这种数据类型,其构造函数需要用到一个字符串或整数,以及表11-4中的频率:
p=pd.Period(2007,freq='A-DEC')
p
Period('2007', 'A-DEC')
这里,这个Period对象表示的是从2007年1月1日到2007年12月31日之间的整段时间。只需对Period对象加上或减去一个整数即可达到根据其频率进行位移的效果:
p+5
Period('2012', 'A-DEC')
p-2
Period('2005', 'A-DEC')
如果两个Period对象拥有相同的频率,则它们的差就是它们之间的单位数量:
pd.Period('2014', freq='A-DEC') - p
7
period_range函数可用于创建规则的时期范围:跟date_range比,date_range是按某种频率,取到天;而period_range则是取到相应的频率处,比如freq='M’表示取到每月
rng=pd.period_range('2000-01-01', '2000-06-30',freq='M')
rng
PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]', freq='M')
PeriodIndex类保存了一组Period,它可以在任何pandas数据结构中被用作轴索引:
pd.Series(np.random.randn(6),index=rng)
2000-01 1.099364
2000-02 0.621087
2000-03 -1.493983
2000-04 1.088655
2000-05 0.425609
2000-06 -0.964186
Freq: M, dtype: float64
如果你有一个字符串数组,你也可以使用PeriodIndex类:
values=['2001Q3', '2002Q2', '2003Q1']
index=pd.PeriodIndex(values,freq='Q-DEC')
index
PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]', freq='Q-DEC')
时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。假设我们有一个年度时期,希望将其转换为当年年初或年末的一个月度时期。该任务非常简单:
p=pd.Period('2007',freq='A-DEC')
p
Period('2007', 'A-DEC')
p.asfreq('M',how='start')
Period('2007-01', 'M')
p.asfreq('M',how='end')
Period('2007-12', 'M')
你可以将Period(‘2007’,‘A-DEC’)看做一个被划分为多个月度时期的时间段中的游标。图11-1对此进行了说明。对于一个不以12月结束的财政年度,月度子时期的归属情况就不一样了:
p=pd.Period('2007',freq='A-JUN')
p
Period('2007', 'A-JUN')
p.asfreq('M',how='start')
Period('2006-07', 'M')
p.asfreq('M',how='end')
Period('2007-06', 'M')
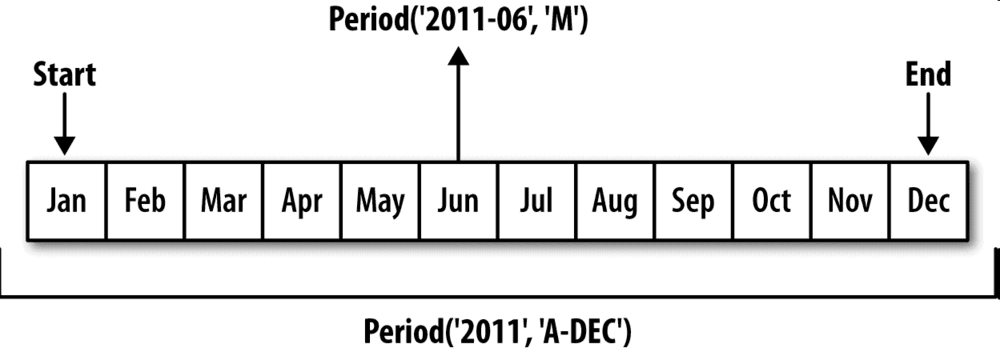
在将高频率转换为低频率时,超时期(superperiod)是由子时期(subperiod)所属的位置决定的。例如,在A-JUN频率中,月份“2007年8月”实际上是属于周期“2008年”的:
p=pd.Period('Aug-2007','M')
p
Period('2007-08', 'M')
p.asfreq('A-JUN')
Period('2008', 'A-JUN')
完整的PeriodIndex或TimeSeries的频率转换方式也是如此:
rng=pd.period_range('2006', '2009',freq='A-DEC')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2006 0.572281
2007 -0.396348
2008 -1.075598
2009 0.120835
Freq: A-DEC, dtype: float64
ts.asfreq('M',how='start')
2006-01 0.572281
2007-01 -0.396348
2008-01 -1.075598
2009-01 0.120835
Freq: M, dtype: float64
这里,根据年度时期的第一个月,每年的时期被取代为每月的时期。如果我们想要每年的最后一个工作日,我们可以使用“B”频率,并指明想要该时期的末尾:
ts.asfreq('B',how='end')
2006-12-29 0.572281
2007-12-31 -0.396348
2008-12-31 -1.075598
2009-12-31 0.120835
Freq: B, dtype: float64
按季度计算的时期频率
季度型数据在会计、金融等领域中很常见。许多季度型数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,时期"2012Q4"根据财年末的不同会有不同的含义。pandas支持12种可能的季度型频率,即Q-JAN到Q-DEC:
p=pd.Period('2012Q4',freq='Q-JAN')
p
Period('2012Q4', 'Q-JAN')
在以1月结束的财年中,2012Q4是从11月到1月(将其转换为日型频率就明白了)。图11-2对此进行了说明:
p.asfreq('D','start')
Period('2011-11-01', 'D')
p.asfreq('D','end')
Period('2012-01-31', 'D')
可以想见,2012Q1,2012Q2,2012Q3都是在2011年度的时间范围。

因此,Period之间的算术运算会非常简单。例如,要获取该季度倒数第二个工作日下午4点的时间戳,你可以这样:
(p.asfreq('B','e')-1).asfreq('T','s')
Period('2012-01-30 00:00', 'T')
p4pm=(p.asfreq('B','e')-1).asfreq('T','s')+16*60
p4pm
Period('2012-01-30 16:00', 'T')
p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')
period_range可用于生成季度型范围。季度型范围的算术运算也跟上面是一样的:
rng=pd.period_range('2011Q3', '2012Q4',freq='Q-JAN')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2011Q3 -0.080515
2011Q4 -1.632083
2012Q1 0.149433
2012Q2 0.238756
2012Q3 -0.474650
2012Q4 1.691028
Freq: Q-JAN, dtype: float64
new_rng=(rng.asfreq('B','e')-1).asfreq('T','s')+16*60
ts.index=new_rng.to_timestamp()
ts
2010-10-28 16:00:00 -0.080515
2011-01-28 16:00:00 -1.632083
2011-04-28 16:00:00 0.149433
2011-07-28 16:00:00 0.238756
2011-10-28 16:00:00 -0.474650
2012-01-30 16:00:00 1.691028
dtype: float64
将Timestamp转换为Period(及其反向过程)
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引:
rng=pd.date_range('2000-01-01',periods=3,freq='M')
ts=pd.Series(np.random.randn(3),index=rng)
ts
2000-01-31 0.846405
2000-02-29 1.105645
2000-03-31 -0.008082
Freq: M, dtype: float64
pts = ts.to_period()
pts
2000-01 0.846405
2000-02 1.105645
2000-03 -0.008082
Freq: M, dtype: float64
由于时期指的是非重叠时间区间,因此对于给定的频率,一个时间戳只能属于一个时期。新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何别的频率。结果中允许存在重复时期:
rng=pd.date_range('1/29/2000',periods=6,freq='D')
ts2=pd.Series(np.random.randn(6),index=rng)
ts2
2000-01-29 -0.646100
2000-01-30 -0.800691
2000-01-31 0.805243
2000-02-01 0.044954
2000-02-02 -0.791839
2000-02-03 -0.012402
Freq: D, dtype: float64
ts2.to_period('M')
2000-01 -0.646100
2000-01 -0.800691
2000-01 0.805243
2000-02 0.044954
2000-02 -0.791839
2000-02 -0.012402
Freq: M, dtype: float64
要转换回时间戳,使用to_timestamp即可:
pts=ts2.to_period()
pts
2000-01-29 -0.646100
2000-01-30 -0.800691
2000-01-31 0.805243
2000-02-01 0.044954
2000-02-02 -0.791839
2000-02-03 -0.012402
Freq: D, dtype: float64
pts.to_timestamp(how='end')
2000-01-29 -0.646100
2000-01-30 -0.800691
2000-01-31 0.805243
2000-02-01 0.044954
2000-02-02 -0.791839
2000-02-03 -0.012402
Freq: D, dtype: float64
通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。例如,在下面这个宏观经济数据集中,年度和季度就分别存放在不同的列中:
data = pd.read_csv('examples/macrodata.csv')
data.head(5)
| year | quarter | realgdp | realcons | realinv | realgovt | realdpi | cpi | m1 | tbilrate | unemp | pop | infl | realint | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1959.0 | 1.0 | 2710.349 | 1707.4 | 286.898 | 470.045 | 1886.9 | 28.98 | 139.7 | 2.82 | 5.8 | 177.146 | 0.00 | 0.00 |
| 1 | 1959.0 | 2.0 | 2778.801 | 1733.7 | 310.859 | 481.301 | 1919.7 | 29.15 | 141.7 | 3.08 | 5.1 | 177.830 | 2.34 | 0.74 |
| 2 | 1959.0 | 3.0 | 2775.488 | 1751.8 | 289.226 | 491.260 | 1916.4 | 29.35 | 140.5 | 3.82 | 5.3 | 178.657 | 2.74 | 1.09 |
| 3 | 1959.0 | 4.0 | 2785.204 | 1753.7 | 299.356 | 484.052 | 1931.3 | 29.37 | 140.0 | 4.33 | 5.6 | 179.386 | 0.27 | 4.06 |
| 4 | 1960.0 | 1.0 | 2847.699 | 1770.5 | 331.722 | 462.199 | 1955.5 | 29.54 | 139.6 | 3.50 | 5.2 | 180.007 | 2.31 | 1.19 |
通过将这些数组以及一个频率传入PeriodIndex,就可以将它们合并成DataFrame的一个索引:
index=pd.PeriodIndex(year=data.year,quarter=data.quarter,freq='Q-DEC')
index
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203, freq='Q-DEC')
data.index=index
data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
1960Q4 1.21
1961Q1 -0.40
1961Q2 1.47
1961Q3 0.80
1961Q4 0.80
1962Q1 2.26
1962Q2 0.13
1962Q3 2.11
1962Q4 0.79
1963Q1 0.53
1963Q2 2.75
1963Q3 0.78
1963Q4 2.46
1964Q1 0.13
1964Q2 0.90
1964Q3 1.29
1964Q4 2.05
1965Q1 1.28
1965Q2 2.54
1965Q3 0.89
1965Q4 2.90
1966Q1 4.99
1966Q2 2.10
...
2002Q2 1.56
2002Q3 2.66
2002Q4 3.08
2003Q1 1.31
2003Q2 1.09
2003Q3 2.60
2003Q4 3.02
2004Q1 2.35
2004Q2 3.61
2004Q3 3.58
2004Q4 2.09
2005Q1 4.15
2005Q2 1.85
2005Q3 9.14
2005Q4 0.40
2006Q1 2.60
2006Q2 3.97
2006Q3 -1.58
2006Q4 3.30
2007Q1 4.58
2007Q2 2.75
2007Q3 3.45
2007Q4 6.38
2008Q1 2.82
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
11.6 重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。并不是所有的重采样都能被划分到这两个大类中。例如,将W-WED(每周三)转换为W-FRI既不是降采样也不是升采样。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数。resample有一个类似于groupby的API,调用resample可以分组数据,然后会调用一个聚合函数:
rng=pd.date_range('2000-01-01',periods=100,freq='D')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2000-01-01 0.056120
2000-01-02 0.687046
2000-01-03 1.297674
2000-01-04 0.438949
2000-01-05 -2.177416
2000-01-06 0.520937
2000-01-07 0.313375
2000-01-08 -0.671625
2000-01-09 -0.472504
2000-01-10 -0.829958
2000-01-11 0.098554
2000-01-12 0.420290
2000-01-13 -1.405471
2000-01-14 -0.084818
2000-01-15 0.354263
2000-01-16 -0.199593
2000-01-17 -0.975966
2000-01-18 -0.143984
2000-01-19 1.273856
2000-01-20 -1.505989
2000-01-21 0.238649
2000-01-22 -1.357768
2000-01-23 0.435551
2000-01-24 -1.482784
2000-01-25 -2.055547
2000-01-26 -1.199536
2000-01-27 0.078807
2000-01-28 0.609357
2000-01-29 -5.055947
2000-01-30 0.004632
...
2000-03-11 -0.606520
2000-03-12 -1.954108
2000-03-13 0.086835
2000-03-14 -0.243083
2000-03-15 2.035382
2000-03-16 0.560586
2000-03-17 1.385685
2000-03-18 -1.492227
2000-03-19 1.030039
2000-03-20 0.612335
2000-03-21 -0.144010
2000-03-22 0.810405
2000-03-23 -0.330377
2000-03-24 0.145672
2000-03-25 -1.349750
2000-03-26 0.324336
2000-03-27 -0.906184
2000-03-28 -0.666729
2000-03-29 -1.762257
2000-03-30 0.217625
2000-03-31 1.829157
2000-04-01 -0.180056
2000-04-02 1.393246
2000-04-03 0.215341
2000-04-04 -0.625347
2000-04-05 -1.223850
2000-04-06 0.883217
2000-04-07 0.657237
2000-04-08 2.050064
2000-04-09 1.209046
Freq: D, Length: 100, dtype: float64
ts.resample('M')
DatetimeIndexResampler [freq=, axis=0, closed=right, label=right, convention=start, base=0]
可以看到先产生了一个DatetimeIndexResampler 对象,有点像grouped对象,然后可以对其调用聚合函数。
ts.resample('M').mean()
2000-01-31 -0.346521
2000-02-29 0.156539
2000-03-31 -0.039219
2000-04-30 0.486544
Freq: M, dtype: float64
ts.resample('M', kind='period').mean()
2000-01 -0.346521
2000-02 0.156539
2000-03 -0.039219
2000-04 0.486544
Freq: M, dtype: float64
resample是一个灵活高效的方法,可用于处理非常大的时间序列。我将通过一系列的示例说明其用法。表11-5总结它的一些选项。
降采样
将数据聚合到规律的低频率是一件非常普通的时间序列处理任务。待聚合的数据不必拥有固定的频率,期望的频率会自动定义聚合的面元边界,这些面元用于将时间序列拆分为多个片段。例如,要转换到月度频率(‘M’或’BM’),数据需要被划分到多个单月时间段中。各时间段都是半开放的。一个数据点只能属于一个时间段,所有时间段的并集必须能组成整个时间帧。在用resample对数据进行降采样时,需要考虑两样东西:
- 各区间哪边是闭合的。
- 如何标记各个聚合面元,用区间的开头还是末尾。
为了说明,我们来看一些“1分钟”数据:
rng=pd.date_range('2000-01-01',periods=12,freq='T')
ts=pd.Series(np.arange(len(rng)),index=rng)
ts
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int32
假设你想要通过求和的方式将这些数据聚合到“5分钟”块中:
ts.resample('5min',closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int32
传入的频率将会以“5分钟”的增量定义面元边界。默认情况下,面元的右边界是包含的,因此00:00到00:05的区间中是包含00:05的。传入closed='left’会让区间以左边界闭合:
ts.resample('5min',closed='left').sum()
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
如你所见,最终的时间序列是以各面元右边界(应该是左边界)的时间戳进行标记的。传入label='right’即可用面元的右边界对其进行标记:
ts.resample('5min',closed='right',label='right').sum()
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int32
图11-3说明了“1分钟”数据被转换为“5分钟”数据的处理过程。

最后,你可能希望对结果索引做一些位移,比如从右边界减去一秒以便更容易明白该时间戳到底表示的是哪个区间。只需通过loffset设置一个字符串或日期偏移量即可实现这个目的:loffset只是对时间索引进行了偏移
ts.resample('5min',closed='right',label='right',loffset='-1s').sum()
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
2000-01-01 00:09:59 40
2000-01-01 00:14:59 11
Freq: 5T, dtype: int32
此外,也可以通过调用结果对象的shift方法来实现该目的,这样就不需要设置loffset了。
OHLC重采样
金融领域中有一种无所不在的时间序列聚合方式,即计算各面元的四个值:第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)。传入how='ohlc’即可得到一个含有这四种聚合值的DataFrame。整个过程很高效,只需一次扫描即可计算出结果:
ts.resample('5min').ohlc()
| open | high | low | close | |
|---|---|---|---|---|
| 2000-01-01 00:00:00 | 0 | 4 | 0 | 4 |
| 2000-01-01 00:05:00 | 5 | 9 | 5 | 9 |
| 2000-01-01 00:10:00 | 10 | 11 | 10 | 11 |
升采样和插值
在将数据从低频率转换到高频率时,就不需要聚合了。我们来看一个带有一些周型数据的DataFrame:
frame = pd.DataFrame(np.random.randn(2, 4),index=pd.date_range('1/1/2000', periods=2, freq='W-WED'),columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-12 | 0.253645 | 0.312748 | 0.369506 | -0.194079 |
当你对这个数据进行聚合,每组只有一个值,这样就会引入缺失值。我们使用asfreq方法转换成高频,不经过聚合:
frame.resample('D')
DatetimeIndexResampler [freq=, axis=0, closed=left, label=left, convention=start, base=0]
df_daily = frame.resample('D').asfreq()
df_daily
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-06 | NaN | NaN | NaN | NaN |
| 2000-01-07 | NaN | NaN | NaN | NaN |
| 2000-01-08 | NaN | NaN | NaN | NaN |
| 2000-01-09 | NaN | NaN | NaN | NaN |
| 2000-01-10 | NaN | NaN | NaN | NaN |
| 2000-01-11 | NaN | NaN | NaN | NaN |
| 2000-01-12 | 0.253645 | 0.312748 | 0.369506 | -0.194079 |
假设你想要用前面的周型值填充“非星期三”。resampling的填充和插值方式跟fillna和reindex的一样:
frame.resample('D').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-06 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-07 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-08 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-09 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-10 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-11 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-12 | 0.253645 | 0.312748 | 0.369506 | -0.194079 |
同样,这里也可以只填充指定的时期数(目的是限制前面的观测值的持续使用距离):
frame.resample('D').ffill(limit=2)
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-05 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-06 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-07 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-08 | NaN | NaN | NaN | NaN |
| 2000-01-09 | NaN | NaN | NaN | NaN |
| 2000-01-10 | NaN | NaN | NaN | NaN |
| 2000-01-11 | NaN | NaN | NaN | NaN |
| 2000-01-12 | 0.253645 | 0.312748 | 0.369506 | -0.194079 |
注意,新的日期索引完全没必要跟旧的重叠:
frame.resample('W-THU').asfreq()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-06 | NaN | NaN | NaN | NaN |
| 2000-01-13 | NaN | NaN | NaN | NaN |
frame.resample('W-THU').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01-06 | -0.317084 | -1.241827 | 0.212329 | 0.500163 |
| 2000-01-13 | 0.253645 | 0.312748 | 0.369506 | -0.194079 |
通过时期进行重采样
对那些使用时期索引的数据进行重采样与时间戳很像:
frame = pd.DataFrame(np.random.randn(24, 4),index=pd.period_range('1-2000', '12-2001',freq='M'),columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame[:5]
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000-01 | -0.047982 | -0.126923 | -0.322961 | 0.761645 |
| 2000-02 | 1.040223 | -0.624666 | 0.651559 | 1.646052 |
| 2000-03 | -1.437336 | 0.264324 | -0.794073 | -0.341784 |
| 2000-04 | 0.057083 | 0.716689 | -1.972372 | -0.289167 |
| 2000-05 | -0.523607 | 0.884701 | -0.310363 | 0.208832 |
annual_frame = frame.resample('A-DEC').mean()
annual_frame
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2001 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
升采样要稍微麻烦一些,因为你必须决定在新频率中各区间的哪端用于放置原来的值,就像asfreq方法那样。convention参数默认为’start’,也可设置为’end’:
annual_frame.resample('Q-DEC').asfreq()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q1 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2000Q2 | NaN | NaN | NaN | NaN |
| 2000Q3 | NaN | NaN | NaN | NaN |
| 2000Q4 | NaN | NaN | NaN | NaN |
| 2001Q1 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q2 | NaN | NaN | NaN | NaN |
| 2001Q3 | NaN | NaN | NaN | NaN |
| 2001Q4 | NaN | NaN | NaN | NaN |
annual_frame.resample('Q-DEC').ffill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q1 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2000Q2 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2000Q3 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2000Q4 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2001Q1 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q2 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q3 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q4 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
annual_frame.resample('Q-DEC',convention='end').asfreq()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2001Q1 | NaN | NaN | NaN | NaN |
| 2001Q2 | NaN | NaN | NaN | NaN |
| 2001Q3 | NaN | NaN | NaN | NaN |
| 2001Q4 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
annual_frame.resample('Q-DEC',convention='end').bfill()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2001Q1 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q2 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q3 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2001Q4 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
由于时期指的是时间区间,所以升采样和降采样的规则就比较严格:
- 在降采样中,目标频率必须是源频率的子时期(subperiod)。
- 在升采样中,目标频率必须是源频率的超时期(superperiod)。
如果不满足这些条件,就会引发异常。这主要影响的是按季、年、周计算的频率。例如,由Q-MAR定义的时间区间只能升采样为A-MAR、A-JUN、A-SEP、A-DEC等:
annual_frame.resample('Q-MAR').asfreq()
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2000Q4 | -0.041797 | 0.273154 | -0.145205 | 0.211796 |
| 2001Q1 | NaN | NaN | NaN | NaN |
| 2001Q2 | NaN | NaN | NaN | NaN |
| 2001Q3 | NaN | NaN | NaN | NaN |
| 2001Q4 | 0.527899 | 0.017573 | 0.338176 | -0.319188 |
| 2002Q1 | NaN | NaN | NaN | NaN |
| 2002Q2 | NaN | NaN | NaN | NaN |
| 2002Q3 | NaN | NaN | NaN | NaN |
11.7 移动窗口函数
在移动窗口(可以带有指数衰减权数)上计算的各种统计函数也是一类常见于时间序列的数组变换。这样可以圆滑噪音数据或断裂数据。我将它们称为移动窗口函数(moving window function),其中还包括那些窗口不定长的函数(如指数加权移动平均)。跟其他统计函数一样,移动窗口函数也会自动排除缺失值。
开始之前,我们加载一些时间序列数据,将其重采样为工作日频率:
close_px_all = pd.read_csv('examples/stock_px_2.csv',parse_dates=True,index_col=0)
close_px =close_px_all[['AAPL', 'MSFT', 'XOM']]
close_px.head(5)
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.40 | 21.11 | 29.22 |
| 2003-01-03 | 7.45 | 21.14 | 29.24 |
| 2003-01-06 | 7.45 | 21.52 | 29.96 |
| 2003-01-07 | 7.43 | 21.93 | 28.95 |
| 2003-01-08 | 7.28 | 21.31 | 28.83 |
close_px.resample('B').asfreq()#这里有些日期数据因为不是工作日会被丢掉,有些是工作但原数据中没有,则会是空
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.40 | 21.11 | 29.22 |
| 2003-01-03 | 7.45 | 21.14 | 29.24 |
| 2003-01-06 | 7.45 | 21.52 | 29.96 |
| 2003-01-07 | 7.43 | 21.93 | 28.95 |
| 2003-01-08 | 7.28 | 21.31 | 28.83 |
| 2003-01-09 | 7.34 | 21.93 | 29.44 |
| 2003-01-10 | 7.36 | 21.97 | 29.03 |
| 2003-01-13 | 7.32 | 22.16 | 28.91 |
| 2003-01-14 | 7.30 | 22.39 | 29.17 |
| 2003-01-15 | 7.22 | 22.11 | 28.77 |
| 2003-01-16 | 7.31 | 21.75 | 28.90 |
| 2003-01-17 | 7.05 | 20.22 | 28.60 |
| 2003-01-20 | NaN | NaN | NaN |
| 2003-01-21 | 7.01 | 20.17 | 27.94 |
| 2003-01-22 | 6.94 | 20.04 | 27.58 |
| 2003-01-23 | 7.09 | 20.54 | 27.52 |
| 2003-01-24 | 6.90 | 19.59 | 26.93 |
| 2003-01-27 | 7.07 | 19.32 | 26.21 |
| 2003-01-28 | 7.29 | 19.18 | 26.90 |
| 2003-01-29 | 7.47 | 19.61 | 27.88 |
| 2003-01-30 | 7.16 | 18.95 | 27.37 |
| 2003-01-31 | 7.18 | 18.65 | 28.13 |
| 2003-02-03 | 7.33 | 19.08 | 28.52 |
| 2003-02-04 | 7.30 | 18.59 | 28.52 |
| 2003-02-05 | 7.22 | 18.45 | 28.11 |
| 2003-02-06 | 7.22 | 18.63 | 27.87 |
| 2003-02-07 | 7.07 | 18.30 | 27.66 |
| 2003-02-10 | 7.18 | 18.62 | 27.87 |
| 2003-02-11 | 7.18 | 18.25 | 27.67 |
| 2003-02-12 | 7.20 | 18.25 | 27.12 |
| ... | ... | ... | ... |
| 2011-09-05 | NaN | NaN | NaN |
| 2011-09-06 | 379.74 | 25.51 | 71.15 |
| 2011-09-07 | 383.93 | 26.00 | 73.65 |
| 2011-09-08 | 384.14 | 26.22 | 72.82 |
| 2011-09-09 | 377.48 | 25.74 | 71.01 |
| 2011-09-12 | 379.94 | 25.89 | 71.84 |
| 2011-09-13 | 384.62 | 26.04 | 71.65 |
| 2011-09-14 | 389.30 | 26.50 | 72.64 |
| 2011-09-15 | 392.96 | 26.99 | 74.01 |
| 2011-09-16 | 400.50 | 27.12 | 74.55 |
| 2011-09-19 | 411.63 | 27.21 | 73.70 |
| 2011-09-20 | 413.45 | 26.98 | 74.01 |
| 2011-09-21 | 412.14 | 25.99 | 71.97 |
| 2011-09-22 | 401.82 | 25.06 | 69.24 |
| 2011-09-23 | 404.30 | 25.06 | 69.31 |
| 2011-09-26 | 403.17 | 25.44 | 71.72 |
| 2011-09-27 | 399.26 | 25.67 | 72.91 |
| 2011-09-28 | 397.01 | 25.58 | 72.07 |
| 2011-09-29 | 390.57 | 25.45 | 73.88 |
| 2011-09-30 | 381.32 | 24.89 | 72.63 |
| 2011-10-03 | 374.60 | 24.53 | 71.15 |
| 2011-10-04 | 372.50 | 25.34 | 72.83 |
| 2011-10-05 | 378.25 | 25.89 | 73.95 |
| 2011-10-06 | 377.37 | 26.34 | 73.89 |
| 2011-10-07 | 369.80 | 26.25 | 73.56 |
| 2011-10-10 | 388.81 | 26.94 | 76.28 |
| 2011-10-11 | 400.29 | 27.00 | 76.27 |
| 2011-10-12 | 402.19 | 26.96 | 77.16 |
| 2011-10-13 | 408.43 | 27.18 | 76.37 |
| 2011-10-14 | 422.00 | 27.27 | 78.11 |
2292 rows × 3 columns
close_px = close_px.resample('B').ffill()
现在引入rolling运算符,它与resample和groupby很像。可以在TimeSeries或DataFrame以及一个window(表示期数,见图11-4)上调用它:
%matplotlib notebook
import matplotlib.pyplot as plt
close_px.AAPL.plot()
close_px.AAPL.rolling(250).mean().plot()

表达式rolling(250)与groupby很像,但不是对其进行分组,而是创建一个按照250天分组的滑动窗口对象。然后,我们就得到了苹果公司股价的250天的移动窗口。
默认情况下,rolling函数需要窗口中所有的值为非NA值。可以修改该行为以解决缺失数据的问题。其实,在时间序列开始处尚不足窗口期的那些数据就是个特例(见图11-5):
appl_std250 = close_px.AAPL.rolling(250, min_periods=10).std()
appl_std250[5:12]
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 0.077496
2003-01-16 0.074760
2003-01-17 0.112368
Freq: B, Name: AAPL, dtype: float64
%matplotlib notebook
appl_std250.plot()

要计算扩展窗口平均(expanding window mean),可以使用expanding而不是rolling。“扩展”意味着,从时间序列的起始处开始窗口,增加窗口直到它超过所有的序列。apple_std250时间序列的扩展窗口平均如下所示:
expanding_mean = appl_std250.expanding().mean()
对DataFrame调用rolling_mean(以及与之类似的函数)会将转换应用到所有的列上(见图11-6):
%matplotlib notebook
close_px.rolling(60).mean().plot(logy=True)

rolling函数也可以接受一个指定固定大小时间补偿字符串,而不是一组时期。这样可以方便处理不规律的时间序列。这些字符串也可以传递给resample。例如,我们可以计算20天的滚动均值,如下所示:
close_px.rolling('20D').mean()
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | 7.400000 | 21.110000 | 29.220000 |
| 2003-01-03 | 7.425000 | 21.125000 | 29.230000 |
| 2003-01-06 | 7.433333 | 21.256667 | 29.473333 |
| 2003-01-07 | 7.432500 | 21.425000 | 29.342500 |
| 2003-01-08 | 7.402000 | 21.402000 | 29.240000 |
| 2003-01-09 | 7.391667 | 21.490000 | 29.273333 |
| 2003-01-10 | 7.387143 | 21.558571 | 29.238571 |
| 2003-01-13 | 7.378750 | 21.633750 | 29.197500 |
| 2003-01-14 | 7.370000 | 21.717778 | 29.194444 |
| 2003-01-15 | 7.355000 | 21.757000 | 29.152000 |
| 2003-01-16 | 7.350909 | 21.756364 | 29.129091 |
| 2003-01-17 | 7.325833 | 21.628333 | 29.085000 |
| 2003-01-20 | 7.304615 | 21.520000 | 29.047692 |
| 2003-01-21 | 7.283571 | 21.423571 | 28.968571 |
| 2003-01-22 | 7.250714 | 21.347143 | 28.851429 |
| 2003-01-23 | 7.225000 | 21.304286 | 28.728571 |
| 2003-01-24 | 7.203333 | 21.190000 | 28.608667 |
| 2003-01-27 | 7.160000 | 20.980000 | 28.316429 |
| 2003-01-28 | 7.160714 | 20.827857 | 28.178571 |
| 2003-01-29 | 7.170000 | 20.662143 | 28.067143 |
| 2003-01-30 | 7.155714 | 20.446429 | 27.948571 |
| 2003-01-31 | 7.157333 | 20.326667 | 27.960667 |
| 2003-02-03 | 7.147857 | 19.959286 | 27.846429 |
| 2003-02-04 | 7.153571 | 19.707857 | 27.828571 |
| 2003-02-05 | 7.147143 | 19.472143 | 27.772143 |
| 2003-02-06 | 7.159286 | 19.358571 | 27.720000 |
| 2003-02-07 | 7.153333 | 19.288000 | 27.716000 |
| 2003-02-10 | 7.172857 | 19.110714 | 27.647857 |
| 2003-02-11 | 7.190000 | 18.982857 | 27.654286 |
| 2003-02-12 | 7.197857 | 18.819286 | 27.625714 |
| ... | ... | ... | ... |
| 2011-09-05 | 375.711429 | 25.276429 | 72.607857 |
| 2011-09-06 | 375.661429 | 25.295000 | 72.392857 |
| 2011-09-07 | 376.938571 | 25.390000 | 72.586429 |
| 2011-09-08 | 378.946429 | 25.545000 | 72.802143 |
| 2011-09-09 | 378.848667 | 25.558000 | 72.682667 |
| 2011-09-12 | 380.902143 | 25.754286 | 72.731429 |
| 2011-09-13 | 381.505000 | 25.835714 | 72.596429 |
| 2011-09-14 | 382.617857 | 25.973571 | 72.658571 |
| 2011-09-15 | 383.287857 | 26.097857 | 72.756429 |
| 2011-09-16 | 384.435333 | 26.166000 | 72.876000 |
| 2011-09-19 | 385.585714 | 26.259286 | 72.772143 |
| 2011-09-20 | 387.630000 | 26.286429 | 72.771429 |
| 2011-09-21 | 389.852143 | 26.270714 | 72.662857 |
| 2011-09-22 | 391.835714 | 26.217857 | 72.455714 |
| 2011-09-23 | 392.666667 | 26.140667 | 72.246000 |
| 2011-09-26 | 395.670000 | 26.160000 | 72.294286 |
| 2011-09-27 | 396.765000 | 26.136429 | 72.241429 |
| 2011-09-28 | 397.684286 | 26.090714 | 72.187857 |
| 2011-09-29 | 398.619286 | 26.070000 | 72.392857 |
| 2011-09-30 | 397.466000 | 25.991333 | 72.408667 |
| 2011-10-03 | 398.002143 | 25.890714 | 72.413571 |
| 2011-10-04 | 396.802143 | 25.807857 | 72.427143 |
| 2011-10-05 | 395.751429 | 25.729286 | 72.422857 |
| 2011-10-06 | 394.099286 | 25.673571 | 72.375714 |
| 2011-10-07 | 392.479333 | 25.712000 | 72.454667 |
| 2011-10-10 | 389.351429 | 25.602143 | 72.527857 |
| 2011-10-11 | 388.505000 | 25.674286 | 72.835000 |
| 2011-10-12 | 388.531429 | 25.810000 | 73.400714 |
| 2011-10-13 | 388.826429 | 25.961429 | 73.905000 |
| 2011-10-14 | 391.038000 | 26.048667 | 74.185333 |
2292 rows × 3 columns
指数加权函数
另一种使用固定大小窗口及相等权数观测值的办法是,定义一个衰减因子(decay factor)常量,以便使近期的观测值拥有更大的权数。衰减因子的定义方式有很多,比较流行的是使用时间间隔(span),它可以使结果兼容于窗口大小等于时间间隔的简单移动窗口(simple moving window)函数。
由于指数加权统计会赋予近期的观测值更大的权数,因此相对于等权统计,它能“适应”更快的变化。
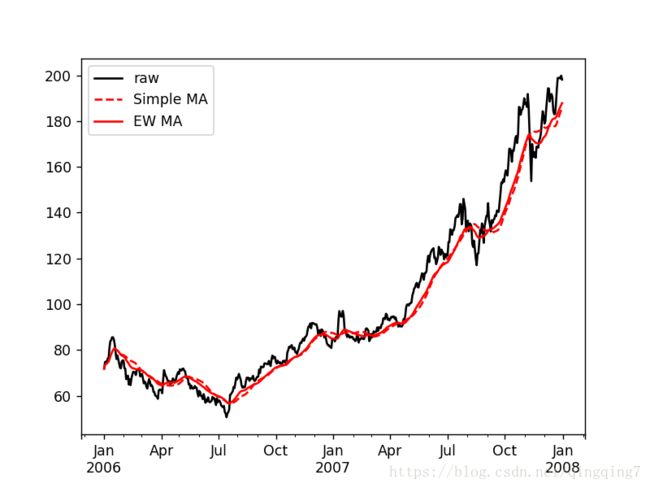
除了rolling和expanding,pandas还有ewm运算符。下面这个例子对比了苹果公司股价的30日移动平均和span=30的指数加权移动平均(如图11-7所示):
aapl_px = close_px.AAPL['2006':'2007']
aapl_px
2006-01-02 71.89
2006-01-03 74.75
2006-01-04 74.97
2006-01-05 74.38
2006-01-06 76.30
2006-01-09 76.05
2006-01-10 80.86
2006-01-11 83.90
2006-01-12 84.29
2006-01-13 85.59
2006-01-16 85.59
2006-01-17 84.71
2006-01-18 82.49
2006-01-19 79.04
2006-01-20 76.09
2006-01-23 77.67
2006-01-24 76.04
2006-01-25 74.20
2006-01-26 72.33
2006-01-27 72.03
2006-01-30 75.00
2006-01-31 75.51
2006-02-01 75.42
2006-02-02 72.10
2006-02-03 71.85
2006-02-06 67.30
2006-02-07 67.60
2006-02-08 68.81
2006-02-09 64.95
2006-02-10 67.31
...
2007-11-20 168.85
2007-11-21 168.46
2007-11-22 168.46
2007-11-23 171.54
2007-11-26 172.54
2007-11-27 174.81
2007-11-28 180.22
2007-11-29 184.29
2007-11-30 182.22
2007-12-03 178.86
2007-12-04 179.81
2007-12-05 185.50
2007-12-06 189.95
2007-12-07 194.30
2007-12-10 194.21
2007-12-11 188.54
2007-12-12 190.86
2007-12-13 191.83
2007-12-14 190.39
2007-12-17 184.40
2007-12-18 182.98
2007-12-19 183.12
2007-12-20 187.21
2007-12-21 193.91
2007-12-24 198.80
2007-12-25 198.80
2007-12-26 198.95
2007-12-27 198.57
2007-12-28 199.83
2007-12-31 198.08
Freq: B, Name: AAPL, Length: 521, dtype: float64
ma30=aapl_px.rolling(30,min_periods=20).mean()
ma30
2006-01-02 NaN
2006-01-03 NaN
2006-01-04 NaN
2006-01-05 NaN
2006-01-06 NaN
2006-01-09 NaN
2006-01-10 NaN
2006-01-11 NaN
2006-01-12 NaN
2006-01-13 NaN
2006-01-16 NaN
2006-01-17 NaN
2006-01-18 NaN
2006-01-19 NaN
2006-01-20 NaN
2006-01-23 NaN
2006-01-24 NaN
2006-01-25 NaN
2006-01-26 NaN
2006-01-27 78.158500
2006-01-30 78.008095
2006-01-31 77.894545
2006-02-01 77.786957
2006-02-02 77.550000
2006-02-03 77.322000
2006-02-06 76.936538
2006-02-07 76.590741
2006-02-08 76.312857
2006-02-09 75.921034
2006-02-10 75.634000
...
2007-11-20 175.307000
2007-11-21 175.362667
2007-11-22 175.570333
2007-11-23 175.713333
2007-11-26 175.898667
2007-11-27 176.073000
2007-11-28 176.322000
2007-11-29 176.681667
2007-11-30 177.075000
2007-12-03 177.225000
2007-12-04 177.013333
2007-12-05 176.999000
2007-12-06 177.238000
2007-12-07 177.558000
2007-12-10 177.862000
2007-12-11 177.913333
2007-12-12 177.943667
2007-12-13 178.090000
2007-12-14 178.174000
2007-12-17 178.114667
2007-12-18 177.821000
2007-12-19 177.715000
2007-12-20 178.106333
2007-12-21 179.057667
2007-12-24 180.559000
2007-12-25 181.520333
2007-12-26 182.615000
2007-12-27 183.757333
2007-12-28 184.872000
2007-12-31 186.009667
Freq: B, Name: AAPL, Length: 521, dtype: float64
ewma30=aapl_px.ewm(span=30).mean()
ewma30
2006-01-02 71.890000
2006-01-03 73.367667
2006-01-04 73.937767
2006-01-05 74.059619
2006-01-06 74.569360
2006-01-09 74.859024
2006-01-10 75.896932
2006-01-11 77.145698
2006-01-12 78.166996
2006-01-13 79.150958
2006-01-16 79.950115
2006-01-17 80.507644
2006-01-18 80.728233
2006-01-19 80.548765
2006-01-20 80.093788
2006-01-23 79.855407
2006-01-24 79.492441
2006-01-25 79.003919
2006-01-26 78.404534
2006-01-27 77.846161
2006-01-30 77.602477
2006-01-31 77.427025
2006-02-01 77.261930
2006-02-02 76.844719
2006-02-03 76.447500
2006-02-06 75.730780
2006-02-07 75.102414
2006-02-08 74.622252
2006-02-09 73.892783
2006-02-10 73.401672
...
2007-11-20 170.393741
2007-11-21 170.268984
2007-11-22 170.152275
2007-11-23 170.241806
2007-11-26 170.390076
2007-11-27 170.675233
2007-11-28 171.291024
2007-11-29 172.129668
2007-11-30 172.780657
2007-12-03 173.172872
2007-12-04 173.601074
2007-12-05 174.368747
2007-12-06 175.373989
2007-12-07 176.595022
2007-12-10 177.731472
2007-12-11 178.428797
2007-12-12 179.230810
2007-12-13 180.043661
2007-12-14 180.711166
2007-12-17 180.949156
2007-12-18 181.080178
2007-12-19 181.211779
2007-12-20 181.598761
2007-12-21 182.393035
2007-12-24 183.451549
2007-12-25 184.441771
2007-12-26 185.377786
2007-12-27 186.228897
2007-12-28 187.106387
2007-12-31 187.814362
Freq: B, Name: AAPL, Length: 521, dtype: float64
%matplotlib notebook
aapl_px.plot(style='k-', label='raw')
ma30.plot(style='r--', label='Simple MA')
ewma30.plot(style='r-', label='EW MA')
plt.legend()
更多移动窗口函数
python | pandas | 移动窗口函数rolling
rolling_count 计算各个窗口中非NA观测值的数量
rolling_sum 移动窗口的和
rolling_mean 移动窗口的均值
rolling_median 移动窗口的中位数
rolling_std 移动窗口的标准差
rolling_min 移动窗口的最小值
rolling_max 移动窗口的最大值
rolling_corr 移动窗口的相关系数
rolling_corr_pairwise 配对数据的相关系数
rolling_cov 移动窗口的协方差
rolling_skew 移动窗口的偏度(三阶矩)
rolling_kurt 移动窗口的峰度(四阶矩)
rolling_apply 对移动窗口应用普通数组函数
rolling_quantile 移动窗口分位数函数
rolling_window 移动窗口
ewma 指数加权移动
ewmstd 指数加权移动标准差
ewmvar 指数加权移动方差
ewmcorr 指数加权移动相关系数
ewmcov 指数加权移动协方差
二元移动窗口函数
有些统计运算(如相关系数和协方差)需要在两个时间序列上执行。例如,金融分析师常常对某只股票对某个参考指数(如标准普尔500指数)的相关系数感兴趣。要进行说明,我们先计算我们感兴趣的时间序列的百分数变化:
spx_px = close_px_all['SPX']
spx_rets = spx_px.pct_change()
returns = close_px.pct_change()
spx_rets
2003-01-02 NaN
2003-01-03 -0.000484
2003-01-06 0.022474
2003-01-07 -0.006545
2003-01-08 -0.014086
2003-01-09 0.019386
2003-01-10 0.000000
2003-01-13 -0.001412
2003-01-14 0.005830
2003-01-15 -0.014426
2003-01-16 -0.003942
2003-01-17 -0.014017
2003-01-21 -0.015702
2003-01-22 -0.010432
2003-01-23 0.010224
2003-01-24 -0.029233
2003-01-27 -0.016160
2003-01-28 0.013050
2003-01-29 0.006779
2003-01-30 -0.022849
2003-01-31 0.013130
2003-02-03 0.005399
2003-02-04 -0.014088
2003-02-05 -0.005435
2003-02-06 -0.006449
2003-02-07 -0.010094
2003-02-10 0.007569
2003-02-11 -0.008098
2003-02-12 -0.012687
2003-02-13 -0.001600
...
2011-09-02 -0.025282
2011-09-06 -0.007436
2011-09-07 0.028646
2011-09-08 -0.010612
2011-09-09 -0.026705
2011-09-12 0.006966
2011-09-13 0.009120
2011-09-14 0.013480
2011-09-15 0.017187
2011-09-16 0.005707
2011-09-19 -0.009803
2011-09-20 -0.001661
2011-09-21 -0.029390
2011-09-22 -0.031883
2011-09-23 0.006082
2011-09-26 0.023336
2011-09-27 0.010688
2011-09-28 -0.020691
2011-09-29 0.008114
2011-09-30 -0.024974
2011-10-03 -0.028451
2011-10-04 0.022488
2011-10-05 0.017866
2011-10-06 0.018304
2011-10-07 -0.008163
2011-10-10 0.034125
2011-10-11 0.000544
2011-10-12 0.009795
2011-10-13 -0.002974
2011-10-14 0.017380
Name: SPX, Length: 2214, dtype: float64
returns
| AAPL | MSFT | XOM | |
|---|---|---|---|
| 2003-01-02 | NaN | NaN | NaN |
| 2003-01-03 | 0.006757 | 0.001421 | 0.000684 |
| 2003-01-06 | 0.000000 | 0.017975 | 0.024624 |
| 2003-01-07 | -0.002685 | 0.019052 | -0.033712 |
| 2003-01-08 | -0.020188 | -0.028272 | -0.004145 |
| 2003-01-09 | 0.008242 | 0.029094 | 0.021159 |
| 2003-01-10 | 0.002725 | 0.001824 | -0.013927 |
| 2003-01-13 | -0.005435 | 0.008648 | -0.004134 |
| 2003-01-14 | -0.002732 | 0.010379 | 0.008993 |
| 2003-01-15 | -0.010959 | -0.012506 | -0.013713 |
| 2003-01-16 | 0.012465 | -0.016282 | 0.004519 |
| 2003-01-17 | -0.035568 | -0.070345 | -0.010381 |
| 2003-01-20 | 0.000000 | 0.000000 | 0.000000 |
| 2003-01-21 | -0.005674 | -0.002473 | -0.023077 |
| 2003-01-22 | -0.009986 | -0.006445 | -0.012885 |
| 2003-01-23 | 0.021614 | 0.024950 | -0.002175 |
| 2003-01-24 | -0.026798 | -0.046251 | -0.021439 |
| 2003-01-27 | 0.024638 | -0.013783 | -0.026736 |
| 2003-01-28 | 0.031117 | -0.007246 | 0.026326 |
| 2003-01-29 | 0.024691 | 0.022419 | 0.036431 |
| 2003-01-30 | -0.041499 | -0.033656 | -0.018293 |
| 2003-01-31 | 0.002793 | -0.015831 | 0.027768 |
| 2003-02-03 | 0.020891 | 0.023056 | 0.013864 |
| 2003-02-04 | -0.004093 | -0.025681 | 0.000000 |
| 2003-02-05 | -0.010959 | -0.007531 | -0.014376 |
| 2003-02-06 | 0.000000 | 0.009756 | -0.008538 |
| 2003-02-07 | -0.020776 | -0.017713 | -0.007535 |
| 2003-02-10 | 0.015559 | 0.017486 | 0.007592 |
| 2003-02-11 | 0.000000 | -0.019871 | -0.007176 |
| 2003-02-12 | 0.002786 | 0.000000 | -0.019877 |
| ... | ... | ... | ... |
| 2011-09-05 | 0.000000 | 0.000000 | 0.000000 |
| 2011-09-06 | 0.015212 | -0.011240 | -0.013723 |
| 2011-09-07 | 0.011034 | 0.019208 | 0.035137 |
| 2011-09-08 | 0.000547 | 0.008462 | -0.011270 |
| 2011-09-09 | -0.017337 | -0.018307 | -0.024856 |
| 2011-09-12 | 0.006517 | 0.005828 | 0.011688 |
| 2011-09-13 | 0.012318 | 0.005794 | -0.002645 |
| 2011-09-14 | 0.012168 | 0.017665 | 0.013817 |
| 2011-09-15 | 0.009401 | 0.018491 | 0.018860 |
| 2011-09-16 | 0.019188 | 0.004817 | 0.007296 |
| 2011-09-19 | 0.027790 | 0.003319 | -0.011402 |
| 2011-09-20 | 0.004421 | -0.008453 | 0.004206 |
| 2011-09-21 | -0.003168 | -0.036694 | -0.027564 |
| 2011-09-22 | -0.025040 | -0.035783 | -0.037932 |
| 2011-09-23 | 0.006172 | 0.000000 | 0.001011 |
| 2011-09-26 | -0.002795 | 0.015164 | 0.034771 |
| 2011-09-27 | -0.009698 | 0.009041 | 0.016592 |
| 2011-09-28 | -0.005635 | -0.003506 | -0.011521 |
| 2011-09-29 | -0.016221 | -0.005082 | 0.025114 |
| 2011-09-30 | -0.023683 | -0.022004 | -0.016919 |
| 2011-10-03 | -0.017623 | -0.014464 | -0.020377 |
| 2011-10-04 | -0.005606 | 0.033021 | 0.023612 |
| 2011-10-05 | 0.015436 | 0.021705 | 0.015378 |
| 2011-10-06 | -0.002327 | 0.017381 | -0.000811 |
| 2011-10-07 | -0.020060 | -0.003417 | -0.004466 |
| 2011-10-10 | 0.051406 | 0.026286 | 0.036977 |
| 2011-10-11 | 0.029526 | 0.002227 | -0.000131 |
| 2011-10-12 | 0.004747 | -0.001481 | 0.011669 |
| 2011-10-13 | 0.015515 | 0.008160 | -0.010238 |
| 2011-10-14 | 0.033225 | 0.003311 | 0.022784 |
2292 rows × 3 columns
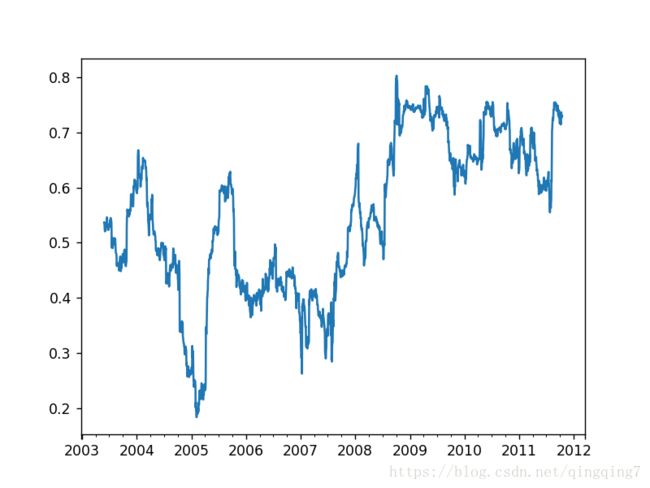
corr = returns.AAPL.rolling(125,min_periods=100).corr(spx_rets)
corr
2003-01-02 NaN
2003-01-03 NaN
2003-01-06 NaN
2003-01-07 NaN
2003-01-08 NaN
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 NaN
2003-01-16 NaN
2003-01-17 NaN
2003-01-20 NaN
2003-01-21 NaN
2003-01-22 NaN
2003-01-23 NaN
2003-01-24 NaN
2003-01-27 NaN
2003-01-28 NaN
2003-01-29 NaN
2003-01-30 NaN
2003-01-31 NaN
2003-02-03 NaN
2003-02-04 NaN
2003-02-05 NaN
2003-02-06 NaN
2003-02-07 NaN
2003-02-10 NaN
2003-02-11 NaN
2003-02-12 NaN
...
2011-09-05 0.752357
2011-09-06 0.745761
2011-09-07 0.741550
2011-09-08 0.738944
2011-09-09 0.746317
2011-09-12 0.743924
2011-09-13 0.745615
2011-09-14 0.748272
2011-09-15 0.747067
2011-09-16 0.748199
2011-09-19 0.731196
2011-09-20 0.731751
2011-09-21 0.728798
2011-09-22 0.735271
2011-09-23 0.740145
2011-09-26 0.731302
2011-09-27 0.725213
2011-09-28 0.725128
2011-09-29 0.715894
2011-09-30 0.721275
2011-10-03 0.725977
2011-10-04 0.715843
2011-10-05 0.718517
2011-10-06 0.714363
2011-10-07 0.718846
2011-10-10 0.736464
2011-10-11 0.729906
2011-10-12 0.728404
2011-10-13 0.727165
2011-10-14 0.729858
Length: 2292, dtype: float64
%matplotlib notebook
corr.plot()
假设你想要一次性计算多只股票与标准普尔500指数的相关系数。虽然编写一个循环并新建一个DataFrame不是什么难事,但比较啰嗦。其实,只需传入一个TimeSeries和一个DataFrame,rolling_corr就会自动计算TimeSeries(本例中就是spx_rets)与DataFrame各列的相关系数。结果如图11-9所示:
corr =returns.rolling(125, min_periods=100).corr(spx_rets)
%matplotlib notebook
corr.plot()
用户定义的移动窗口函数
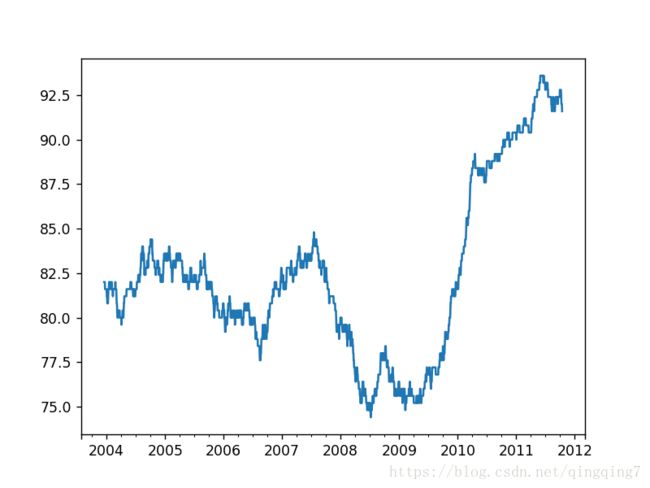
rolling_apply函数使你能够在移动窗口上应用自己设计的数组函数。唯一要求的就是:该函数要能从数组的各个片段中产生单个值(即约简)。比如说,当我们用rolling(…).quantile(q)计算样本分位数时,可能对样本中特定值的百分等级感兴趣。scipy.stats.percentileofscore函数就能达到这个目的(结果见图11-10):
from scipy.stats import percentileofscore
score_at_2percent = lambda x: percentileofscore(x, 0.02)
result = returns.AAPL.rolling(250).apply(score_at_2percent)
%matplotlib notebook
result.plot()
c:\users\qingt\miniconda2\envs\python35\lib\site-packages\ipykernel_launcher.py:3: FutureWarning: Currently, 'apply' passes the values as ndarrays to the applied function. In the future, this will change to passing it as Series objects. You need to specify 'raw=True' to keep the current behaviour, and you can pass 'raw=False' to silence this warning
This is separate from the ipykernel package so we can avoid doing imports until
11.8 总结
与前面章节接触的数据相比,时间序列数据要求不同类型的分析和数据转换工具。
在接下来的章节中,我们将学习一些高级的pandas方法和如何开始使用建模库statsmodels和scikit-learn。
pandas中shift和diff函数
pandas常用函数之diff
pandas常用函数之diff
pandas中shift和diff函数关系