java基础面试题(2022)
目录
1.JDK、JRE、JVM三者的关系?
2.Java的基本数据类型?
3.在进行小数计算的时候,可以使用double吗?
4.什么是逻辑与和短路与(&和&&)?
5.switch...case判断条件可以使用字符串类型吗?
6.如何定义一个方法?
7.你能说明方法中return的用法吗?
8.请你说一下面向对象的特征?那什么是封装、什么是继承、什么是多态?
9.重写和重载有什么区别?
10.抽象类和接口有什么区别?
11.Java中常用的循环方式有哪些?你能说说他们的区别吗?
12.break和continue有什么区别?
13.什么是嵌套循环?如何跳出嵌套循环?你觉得嵌套循多了有什么样的问题?
14.不写类的构造方法可以吗?如果写了类的有参构造方法,还会有缺省构造方法吗?
15.类的构造器可以被重写吗?那可以被重载吗?
16.基本类型画“==”号和引用类型画“==”号有什么区别?那引用类型要判断内容是否相等应该怎么办?
17.你能说说java中的this和super关键字吗?
18.请你说一下java中的final关键字?
19.请你说一下java中的static关键字?
20.什么是内部类?内部类分类有哪些?
21.通过字面量创建字符串和new一个字符串对象有什么区别?那什么是常量池呢?
22.做字符串拼接的时候可以用String吗?StringBuilder和StringBuffer有什么区别呢?
23.子类重写父类含有抛出异常的方法时,有哪些要求?
24.final、finally、finalize有什么区别?
25.List集合和Set集合有什么区别?
26.集合中的泛型有什么用?
27.常用的List集合有哪些呢?有什么区别?
28.什么是队列?什么是栈?它们遵循什么原则?
29.HashMap的底层数据结构是什么?那什么时候变为红黑树呢?
30.HashMap、HashTable、ConcurrentHashMap有什么区别?
31.什么是CAS算法?
32.HashMap的初始长度是多少?在什么时候进行扩容?
33.我们能否使用任何类作为HashMap的key?
34.你能说说sleep、wait、notify的作用吗?
35.你有用过java中的线程池吗?Java中的线程池(创建线程池的方式)有哪些?那你最常用的线程池是哪种?
36.你能介绍一下ThreadPoolExcutor各参数的含义吗?你觉得核心线程数设置多大比较合理?
37.什么是字节码?采用字节码的好处是什么?
38.有了解过Java类加载器
39.线程的生命周期?线程有几种状态
40.Thread、Runable的区别
41.对守护线程的理解
42.并发、并行、串行的区别
43.线程池中阻塞队列的作用?为什么是先添加列队而不是先
创建最大线程?
44.线程池中线程复用原理
45.用最有效率的方法计算 2 乘以 8
.46.Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
47.访问修饰符 public,private,protected,以及不写(默认)时的区别
48.面向对象五大基本原则是什么
49.对象实例与对象引用有何不同?
50.java 中 IO 流分为几种?
51.synchronized和lock区别
52.synchronized实现原理
53.ThreadLocal使用场景与原理
1.JDK、JRE、JVM三者的关系?
JVM是Java虚拟机,是虚拟出来的一个系统,我们常说的hotsport是JVM的一种实现;JRE是Java的最小运行环境,它包含JVM和系统类库;JDK是Java的最小开发环境,它包含JRE+编译运行工具。
2.Java的基本数据类型?
byte(1个字节)
short(2个字节)
char(2个字节)
int(4个字节)
long(8个字节)
double(8个字节)
float(4个字节)
boolean(1个字节)
3.在进行小数计算的时候,可以使用double吗?
如果是对精确度要求不高的时候可以使用double进行小数计算,但如果是对精度要求高的时候则不能使用,例如在银行项目中对资金的一些计算,如果使用double可能会丢失精度,导致结果不正确。(我们可以使用JDK提供的BigDecimal进行计算)
4.什么是逻辑与和短路与(&和&&)?
逻辑与和短路与都是需要整个判断都为true的时候表达式才为true,当某一个判断为false时逻辑与会继续执行后续判断,短路与则不会再继续执行了。(逻辑或和短路或也是如此)
5.switch...case判断条件可以使用字符串类型吗?
在jdk1.7之前只能使用整形,在jdk1.7开始可以使用字符串类型。
6.如何定义一个方法?
修饰词,返回值类型,方法名,参数列表,方法体
7.你能说明方法中return的用法吗?
无返回值方法时,return用于结束方法;有返回值方法时,return用于结束方法并返回值给调用方。
8.请你说一下面向对象的特征?那什么是封装、什么是继承、什么是多态?
封装、继承、多态;
我们把一些具有相同属性或行为的类抽取出来,就是封装;对类的封装,就是封装的对象的属性和行为;对方法的封装,封装的是具体的功能。
继承是为了代码的重用,Java中的继承是单继承的,一旦继承子类就具有父类+子类的属性和行为;
我们声明一个父类型的引用指向子类型的对象,就是多态。多态的主要表现形式就是重写和重载。
9.重写和重载有什么区别?
重写发生在父子类中,方法名称相同,参数列表相同;
重载发生在同一个类中,方法名称相同,参数列表不同;
10.抽象类和接口有什么区别?
接口只能包含常量和抽象方法,接口之间可以继承,接口可以被多实现
抽象类可以包含抽象方法,也可以包含非抽象方法,必须被继承,因为java是单继承的,所以在继承一个类时我觉得应该要慎重考虑。
11.Java中常用的循环方式有哪些?你能说说他们的区别吗?
while循环、do...while循环、for循环,while循环可能一次都不执行、do...while循环至少会执行一次,for循环也有可能一次都不执行,但是我们最常用的循环方式。
12.break和continue有什么区别?
break用于结束循环,continue用于跳过本次循环。
13.什么是嵌套循环?如何跳出嵌套循环?你觉得嵌套循多了有什么样的问题?
嵌套循环就是循环中套循环,外层循环控制行,内层循环控制列,运行规则遵循外层循环走一次,内层循环走所有次;当我们想跳出整个嵌套循环的时候,可以使用outer:标签来定义循环,使用break outer来跳出整个循环;嵌套循环我觉得一般需要控制在3层以内,如果嵌套太多可读性不好,并且可能存在设计问题。
14.不写类的构造方法可以吗?如果写了类的有参构造方法,还会有缺省构造方法吗?
不写类的构造方法,java编译器默认会有缺省无参构造方法;如果写了类的有参构造方法,不会生成缺省方法。
15.类的构造器可以被重写吗?那可以被重载吗?
类的构造器不可以被重写,但可以被重载。
16.基本类型画“==”号和引用类型画“==”号有什么区别?那引用类型要判断内容是否相等应该怎么办?
基本类型画“==”号是判断两个值是否相等;
引用类型画“==””号是判断两个对象在堆的内存地址是否相同;
如果引用类型需要判断内容是否相等,应该使用equals方法;
17.你能说说java中的this和super关键字吗?
java中的this代表的是指向对象本身的一个指针,super是发生在继承关系中的,代表的是指向父类对象的一个指针。
this.成员变量名,是访问本类的成员变量;如果参数super.成员变量名,是访问的父类的成员变量。
this.方法名,是访问本类的方法,我们在调用方法时,可以不写this,编译器会自动生成一个隐式的this;super.方法名,是访问父类的方法。
this(),是访问的本类的构造方法;super()是访问父类的构造方法,并且在初始化子类时,一定会先初始化父类。默认子类中的构造器会隐式的调用super()方法。
18.请你说一下java中的final关键字?
final关键字用于修饰变量、方法、类;
被final修饰的变量,不可以被重新赋值;
被final修饰的类不可被继承;
被final修饰的方法不能被重写。
19.请你说一下java中的static关键字?
static修饰的变量,称为静态变量,存在于方法区(元空间)中;通过类名.变量来访问,当所有对象数据都一样时使用。
static修饰的方法,称为静态方法,存在于方法区(元空间)中;通过类名.方法名来访问,当方法的操作仅与参数有关而与对象无关时使用,例如咱们常写的工具类当中的方法。
还有一种static静态块,在被类加载时自动执行,存在于方法区(元空间)中,常常用于加载静态资源,例如图片,音频,读取文档等。
20.什么是内部类?内部类分类有哪些?
在Java中,可以将一个类的定义放在另外一个类的定义内部,这就是内部类 ;
内部类可以分为四种:成员内部类、局部内部类、匿名内部类和静态内部类。
21.通过字面量创建字符串和new一个字符串对象有什么区别?那什么是常量池呢?
内存的分配方式不一样,通过字面量创建的字符串对象会分配到常量池中,通过new一个字符串对象会分配到堆中。常量池我的理解是,它存在于方法区(元空间中),使用字面量创建的字符串会直接缓存到常量池中,若再次使用该字面量创建新字符串时,不再创建新对象,而是从常量池中获取。
22.做字符串拼接的时候可以用String吗?StringBuilder和StringBuffer有什么区别呢?
不建议直接用String做拼接,最好使用StringBuilder或者StringBuffer来做拼接。StringBuilder是非线程安全的,效率更高。StringBuffer是线程安全的,效率低一些,但安全。
23.子类重写父类含有抛出异常的方法时,有哪些要求?
不再抛出任何异常;
仅抛出部分异常;
抛出子类异常;
不可以抛出额外异常;
不可以抛出父类异常;
24.final、finally、finalize有什么区别?
final用于修饰类、变量、方法,修饰类表示该类不可被继承,修饰方法表示该方法不可被重写,修饰变量表示变量不可被重新赋值。
finally一般作用在try-catch捕获异常代码块中,不论代码是否发生异常,finally中的代码一定会被执行,通常用来关闭一些资源时使用。
finalize属于Object类中的一个方法,当对象被回收的时候,会调用此方法。
25.List集合和Set集合有什么区别?
List集合是可重复集,而且有序。Set集合是不可重读集,而且无序。
26.集合中的泛型有什么用?
集合中的泛型是用来约束元素的类型的。
27.常用的List集合有哪些呢?有什么区别?
常用的List集合有ArrayList、LinkedList、Vector。ArrayList底层是数组,它的查询速度快,增删速度慢;LinkedList底层是链表,它查询速度慢,增删速度快。ArrayList和LinkedList都是非线程安全的,Vector底层是数组,是线程安全的。
28.什么是队列?什么是栈?它们遵循什么原则?
队列是用于存储一组元素的数据结构,但是存取元素必须遵循先进先出原则。
栈也是用于存储一组元素,存取必须遵循先进后出原则。
29.HashMap的底层数据结构是什么?那什么时候变为红黑树呢?
在JDK1.7的时候是数组+链表;在JDK1.8的时候是数组+链表+红黑树;当链表的长度大于8的时候,就会变为红黑树。
30.HashMap、HashTable、ConcurrentHashMap有什么区别?
HashMap是线程不安全的;HashTable是线程安全的,其内部使用synchronized关键字进行加锁;ConcurrentHashMap结合了HashMap和HashTable,是线程安全的,在JDK1.7其内部使用了分段锁的思想来进行加锁,每一把锁只锁容器中的一部分数据,降低了锁的力度,提高了效率。在JDK1.8的时候使用了CAS+synchronized来保证并发安全
31.什么是CAS算法?
CAS算法的全称是:compareAndSwap的意思,是能保证当操作的线程安全和原子性的算法。CAS算法将预期值和更新值传入方法中进行比较,如果内存值和预期值不同,那么此次操作失败,继续循环获取新的内存值,预期值,更新值,直到这次操作成功,我们称这种操作为线程的自旋,其中的算法我们称为CAS算法。
32.HashMap的初始长度是多少?在什么时候进行扩容?
HashMap的初始长度是16。当容量达到加载因子0.75的时候进行扩容,扩容后的大小一定是2的N次方。
33.我们能否使用任何类作为HashMap的key?
可以,但需要注意的是,如果类重写了equals方法,我们就应当连同重写hashcode方法;因为hashcode的值应当与equals的结果相对应,两个对象若equals比较为true,hashcode值应当相同。两个对象equals比较结果为false,hashcode值最好不同。若依然相同,那么作为key存入HashMap中时会产生链表情况,影响HashMap查询性能。
扩充:认识树
算法动画演示:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉搜索树
特点:左子树的键值小于根的键值,右子树的键值大于根的键值;
对该二叉树的节点进行查找发现深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为3的查找次数为3,深度为n的节点的查找次数为n,因此查找时间复杂度依赖于节点深度,如果节点很深,则查找效率降低;
平衡二叉查找树(AVL树)
为了提高二叉查找树的的查找效率,人们又引入了平衡二叉查找树
1.在满足二叉查找树的条件下,还需满足任何节点的两个子树的高度最大差为1,所以它呈现出是一种左右平衡的状态;
下图中左边的是AVL树,它的任何节点的左右两个子树的高度差<=1;而右边的不是AVL树,其根节点的左子树高度为3,而右子树高度为1,两个子树的高度差为2;
2.当我们向平衡二叉树(AVL Tree)插入新的节点(或者删除新的节点),有可能打破它原有的平衡,那么它会通过旋转使其恢复平衡;
3.当插入新节点,失去平衡的二叉树可以概括为四种状态:LL(左左)、RR(右右)、LR(左右)、RL(右左):
4.LL: LeftLeft,也称“左左”,插入或删除一个节点后,根节点的左孩子(Left Child)的左孩子(Left Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡;
5.RR: RightRight,也称“右右”,插入或删除一个节点后,根节点的右孩子(Right Child)的右孩子(Right Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡;
6.LR: LeftRight,也称“左右”,插入或删除一个节点后,根节点的左孩子(Left Child)的右孩子(Right Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡;
7.RL:RightLeft,也称“右左”,插入或删除一个节点后,根节点的右孩子(Right Child)的左孩子(Left Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡;
红黑树
为了解决AVL树需要维护平衡的条件而导致的每次进行增加、删除和修改后对树的结构调整较大,较为耗时的情况,所以红黑树的平衡条件就没有那么的苛刻,这样既降低了增删改对树的结构的调整的耗时,但是也是相对来说是平衡的,所以其也需要旋转。如下图就是一个标准的红黑树
红黑树的性质:
1.每个节点不是红色就是黑色
2.不可能有连在一起的红色节点
3.根节点都是黑色
4.每个红色节点的两个子节点都是黑色
旋转和颜色变换规则:
变色
条件:
(1)当前节点的父亲节点是红色
(2)当前节点的叔叔节点也是红色
步骤:
把父亲节点设置为黑色
把叔叔也设置为黑色
把爷爷节点设为红色
左旋:
条件:
当前节点的父亲节点是红色
当前节点的叔叔节点是黑色
当前节点是右子树
步骤
当前父亲节点是红色,
叔叔是黑色的时候,且当前节点是右子树。
以父亲节点作为左旋。
右旋:当前父亲节点是红色,叔叔是黑色的时候,且当前节点是左子树,进行右旋。
把父亲节点变为黑色
把爷爷节点变为红色
以爷爷节点旋转
34.你能说说sleep、wait、notify的作用吗?
Sleep(Thread的方法)用于线程的休眠,可以指定休眠的时长,如果在一个同步块中,sleep不会释放锁。
wait是Object提供的一个方法,可以对象来进行线程的休眠,如果在一个同步块中,wait会释放锁。
notify也是Object提供的一个方法,可以唤醒处于wait状态的线程,如果在一个同步块中,wait不会释放锁。
35.你有用过java中的线程池吗?Java中的线程池(创建线程池的方式)有哪些?那你最常用的线程池是哪种?
有用过,java中的线程池有4种:
动态的线程池:newCachedThreadPool
固定线程数的线程池:newFixedThreadPool
固定只有一条线程的线程池:newSingleThreadExecutorPool
以固定频率执行的线程池:newScheduledThreadPool
一般来说,这4种线程池都不使用,一般使用ThreadPoolExecutor来自定义线程池。
36.你能介绍一下ThreadPoolExcutor各参数的含义吗?你觉得核心线程数设置多大比较合理?
corePoolSize:核心线程数,指线程池不关闭就一直存活的线程数。maximumPoolSize:最大线程数,指线程池能同时存活的最大线程数。
keepAliveTime:空闲的线程保留的时间,指非核心线程空闲的最大时间,超过这个时间就会将这些空闲的非核心线程销毁掉。
unit:空闲线程的保留时间单位。
workQueue:工作的阻塞队列,存储等待执行的任务。
threadFactory:线程工厂,指定了线程池中的线程的创建方式和销毁方式。
handler:拒绝策略{CallerRunsPolicy(调用者运行策略),AbortPolicy(中止策略),DiscardPolicy(丢弃策略),DiscardOldestPolicy(弃老策略)},指线程池在达到上限(达到最大线程数且任务队列也满了)的情况下的执行逻辑。
最大核心线程数设置为:CPU的核心数 * 2 +1 最为合适
37.什么是字节码?采用字节码的好处是什么?
38.有了解过Java类加载器
39.线程的生命周期?线程有几种状态
40.Thread、Runable的区别
41.对守护线程的理解
42.并发、并行、串行的区别
43.线程池中阻塞队列的作用?为什么是先添加列队而不是先
创建最大线程?
44.线程池中线程复用原理
45.用最有效率的方法计算 2 乘以 8
.46.Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
47.访问修饰符 public,private,protected,以及不写(默认)时的区别
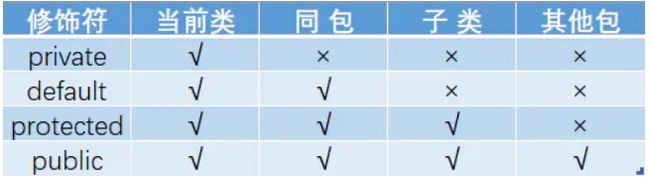
48.面向对象五大基本原则是什么
49.对象实例与对象引用有何不同?
50.java 中 IO 流分为几种?
51.synchronized和lock区别
区别:1、lock是一个接口,而synchronized是java的一个关键字。2、synchronized在发生异常时会自动释放占有的锁,因此不会出现死锁;而lock发生异常时,不会主动释放占有的锁,必须手动来释放锁,可能引起死锁的发生。在分布式开发中,锁是线程控制的重要途径。Java为此也提供了2种锁机制,synchronized和lock。
52.synchronized实现原理
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
普通同步方法,锁是当前实例对象
静态同步方法,锁是当前类的class对象
同步方法块,锁是括号里面的对象
53.ThreadLocal使用场景与原理
ThreadLocal 用作保存每个线程独享的对象,为每个线程都创建一个副本,这样每个线程都可以修改自己所拥有的副本, 而不会影响其他线程的副本,确保了线程安全。
ThreadLocal 用作每个线程内需要独立保存信息,以便供其他方法更方便地获取该信息的场景。每个线程获取到的信息可能都是不一样的,前面执行的方法保存了信息后,后续方法可以通过 ThreadLocal 直接获取到,避免了传参,类似于全局变量的概念。