使用LabelImg准备训练YOLO目标检测所需要的自定义数据集
1.收集数据
构建机器学习系统的关键部分之一是收集高质量的数据集。您可能会在数据上花费大量时间。这是必不可少的,因为我们的模型仅与它从中学习的数据一样好。如果我们将尝试构建一个经过训练的对象检测器,以检测场景中佩戴头盔的人。那么我们如何教机器检测头盔呢?正如您可能已经猜到的那样,通过展示大量示例。有多种方法可以收集数据。对于图像,个人收集图像的最简单方法之一是使用 Google 图片搜索。
但是在搜索结果中手动下载图片是一项繁琐的任务。幸运的是,有一些工具可以提供帮助。有一个名为下载所有图像的 chrome 扩展程序,顾名思义,它可以通过单击按钮下载网页中存在的所有图像。尽可能在搜索结果页面上向下滚动,该工具将捕获滚动的图像。
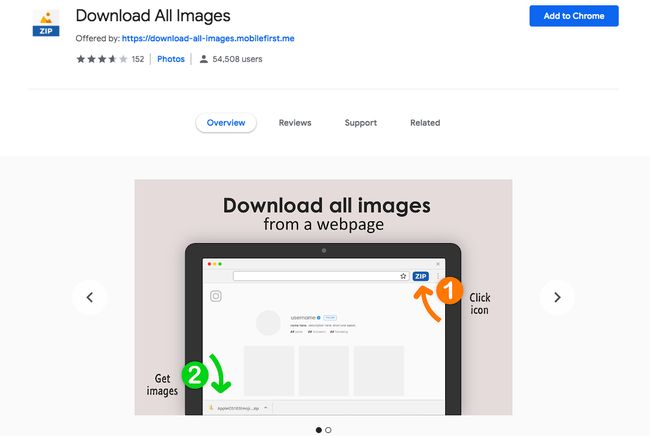
可能还有其他方法可以从 Google 搜索中批量下载图片,这种方法看起来非常简单。下载图像后,请务必检查它们并删除任何不相关的图像。
2.标记数据
一旦我们收集到数据,下一步就是标记它们。在对象检测中,标记意味着在图像中有我们感兴趣的对象,并在感兴趣对象周围绘制边界框,并将它们与相应的对象类别相关联,以便我们可以清楚地将其显示给机器。

这是该过程中劳动强度最大的部分。我们需要一张一张地浏览图像并手动标记每个图像中的对象。有很多工具可以帮助我们注释图像。广泛使用的开源工具之一是LabelImg。
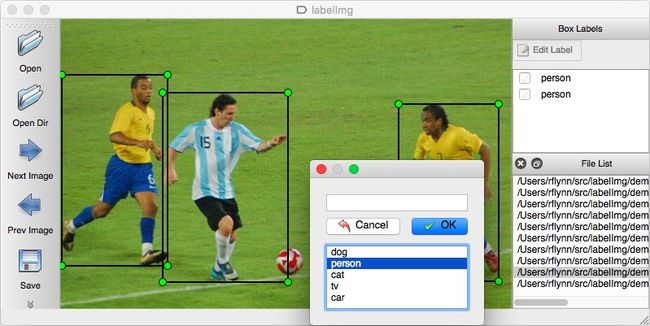
LabelImg 的好处是,它可以让我们将标注直接保存为 YOLO 格式。有些工具不直接这样做。我们需要自己将标注转换成 YOLO 需要的格式。
您可以从终端使用 pip 轻松安装 LabelImg。
pip install labelimg
成功安装 labelImg 后,通过键入以下命令启动它
labelImg [path to image] [classes file]
[path to image]是包含我们要标记的头盔图像的目录路径。
[classes file]是我们列出要标记的对象类别的文件。我们还没有创建它。现在让我们这样做。
创建一个文本文件(例如label.txt)并在文件中添加“helmet”。由于我们只针对这一类别进行训练,这就是我们需要添加的全部内容。如果我们要标记 10 个不同的对象,那么我们应该将它们全部放在这个文件中。
创建文件后,启动 labelImg。例如,
labelImg ./helmet_images/image_1.jpg label.txt
打开窗口后,您可以单击左侧面板上的“打开目录”按钮,然后选择含有所有头盔图像的目录。它将所有图像带到 labelImg 以便我们可以一张一张地浏览。
加载完所有图像后,我们就可以开始标记图像了。
在继续之前,将左侧面板上的 PASCAL VOC 中的注释格式更改为 YOLO。
- 键盘快捷键
W - 开始创建边界框
Ctrl + S - 保存边界框和标签
D - 下一张图片
A - 上一张图片
可以在此处找到完整的快捷方式列表。但这些是我发现自己经常使用的快捷方式。
当您使用**Ctrl + S**保存标签时,labelImg 会为每个图像创建一个与图像同名的文本文件。该图像的所有标注信息都保存在该文件中。
例如,image_1.jpg将在同一目录中有相应的image_1.txt。(如果您希望使用左侧面板中的“更改保存目录”,您可以更改目录)
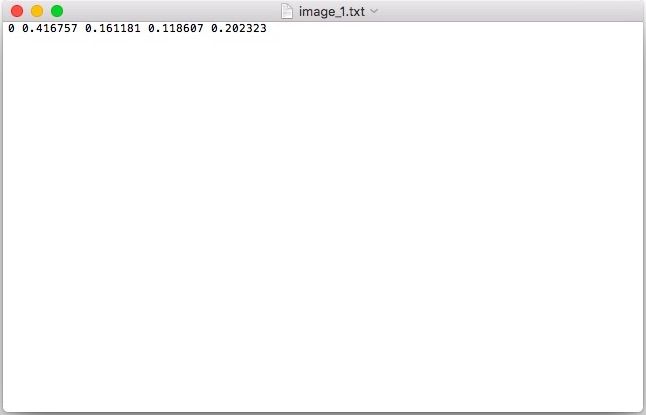
如果您想知道这些神秘数字是什么,它们实际上是以一种通常称为YOLO 格式的特定格式存储的。
object-id center_x center_y width height
object-id表示对应于我们之前在classes.txt中列出的对象类别的数字。
center_x 和 center_y表示边界框的中心点。但是通过除以图像的宽度和高度,它们被归一化为 0 和 1 之间的范围。
例如,(0.25,0.75) 是位于 25% 宽度和 75% 高度的点。我们可以将这个数字(0.25,0.75)乘以图像的原始宽度和高度,得到真实点。事实上,我们将在推理结束后这样做,以在图像上绘制预测。
width 和 height表示边界框的宽度和高度。再次通过除以图像的原始宽度和高度归一化为 0 到 1 的范围。
每个文件表示一张图像,文件中的每一行表示一个边界框及其类别
3.创建必要的文件
除了标注之外,几乎没有与 DarkNet 期望用于训练的数据相关的必要文件。现在让我们创建它们。
-
classes.names- 这与我们之前使用的classes.txt文件相同,包含对象类别(在我们的例子中只是helmet),只是带有.names扩展名。因此,您可以将文件重命名为classes.names。 -
train.txt- DarkNet 需要一个文本文件,列出将用于训练的所有图像。通常人们使用总数据集的60-90%进行训练,并将剩余的用于测试/验证。这里对数字没有真正的共识,视情况而定。
ls "$PWD/"*.jpg | head -100 > train.txt
我总共标记了 120 张图像(实际上很少)。所以我使用 100 张图像进行训练,使用 20 张图像进行验证。转到您拥有头盔图像的目录并运行上述命令。它应该创建一个文本文件,列出目录中前 100 个图像的路径。(随意更改您认为合适的数字)
test.txt- 此文件将包含将用于验证的图像列表。
ls "$PWD/"*.jpg | tail -20 > test.txt
转到您拥有头盔图像的目录并运行上述命令。它应该创建一个文本文件,列出目录中最后 20 个图像的路径。(再次,请随意更改您认为合适的数字)
创建这些文本文件后,您可以将它们从图像目录移动到您正在处理的项目目录中的适当位置,或者您可以将其保留在那里。
obj.data- 该文件将包含以下几行。
classes= 1
train = /path/to/train.txt
valid = /path/to/test.txt
names = /path/to/classes.names
backup = backup/
"classes"是我们训练网络检测的对象类别的数量。"backup"是 DarkNet 为我们保存训练权重的地方。
参考目录
https://www.visiongeek.io/2019/10/preparing-custom-dataset-for-training-yolo-object-detector.html