【目标检测】基于YOLOv5的目标检测分类(Pytorch)(自定义数据集训练模型)
前言
采用YOLOv5训练自己的数据集。
项目源码:https://github.com/ultralytics/yolov5
数据集制作教程:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
目录
- 一、准备环节
- 二、数据集制作
-
- 2.1 my_dataset.yaml
- 2.2 darknet 格式
- 2.3 voc转darknet代码
- 三、训练
-
- 3.1 模型选择
- 3.2 修改配置文件
- 3.3 train.py
- 四、运行
- 五、检测目标
一、准备环节
计算机环境:Win10 + Python3.8 + cuda10.1
主要依赖:
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
coremltools>=4.1
onnx>=1.8.1
scikit-learn==0.19.2
thop # FLOPS computation
pycocotools>=2.0 # COCO mAP
2021-5-16更新,当前yolov5的最新版本为5.0,一定要用1.7版本以上的pytorch。
二、数据集制作
数据集制作:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
使用Labelbox或CVAT对图片进行标注,博主一直使用的是labelImg,数据集是已经标注好的,使用的是VOC格式,所以需要将其转换为darknet格式。
可参考博客:
VOC数据集格式介绍
图像标注工具labelImg安装教程及使用方法
2.1 my_dataset.yaml
首先仿照voc.yaml制作自己的my_dataset.yaml:

创建my_dataset.yaml之后,建立一个名为dataset的文件夹,用于存放训练集(稍后制作训练集存放于此文件夹)
dataset目录下,建立如下目录:

| 文件夹 | 功能 | 备注 |
|---|---|---|
| data | 存放原数据集,数据集格式为VOC。 | 可去掉 |
| tool | 存放数据集格式转换代码,将data内的数据集转换成yolov5所需的数据集格式(darknet 格式)。 | |
| images | 存放数据集中的图片。train为训练集,val为验证集,test为测试集。 | |
| labels | 存放数据集中的标签 |
2.2 darknet 格式
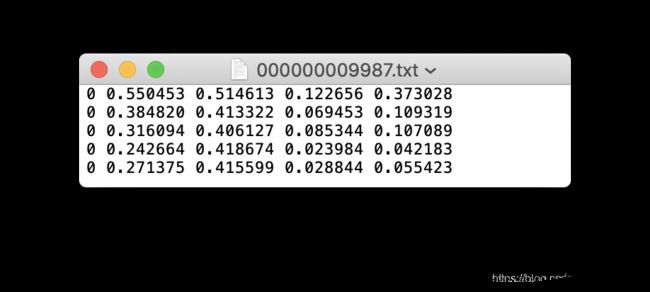
每一张图片需要一个.txt文本,如果图片中不含有目标,可以不创建.txt文本。
.jpg文件和.txt文件需要放在不同目录下,命名相同,扩展名不同:
dataset/image/train/0000001.jpg # image
dataset/label/train/0000001.txt # label
每一个.txt文本的具体格式:
- 一行一个目标。
- 每一行的格式为:class x_center y_center width height。
- 需要标准化xywh,即每一个参数的范围为0-1。
- 类别通过数字进行表示,起始值为1。
2.3 voc转darknet代码
YOLOv5同样使用VOC数据集进行模型训练,那么其中一定包含将voc格式转换darknet格式的脚本。
该代码就写在get_voc.sh脚本内,将其内容复制出来对其进行修改。
根据数据集的不同,对classes内的类别进行修改。
# -*- coding:utf-8 -*-
import xml.etree.ElementTree as ET
import shutil
sets = ['train', 'val', 'test']
classes = ['ore carrier', 'bulk cargo carrier', 'general cargo ship', 'container ship', 'fishing boat', 'passenger ship']
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = "{:.8f}".format(x*dw)
w = "{:.8f}".format(w*dw)
y = "{:.8f}".format(y*dh)
h = "{:.8f}".format(h*dh)
return x, y, w, h
def convert_annotation(image_set, image_id):
in_file = open('../data/Annotations/%s.xml' % image_id)
out_file = open('../labels/%s/%s.txt' % (image_set, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
for image_set in sets:
image_ids = open('../data/ImageSets/Main/%s.txt' % image_set).read().strip().split()
for image_id in image_ids:
print(image_set + ' ' + image_id)
convert_annotation(image_set, image_id)
# 复制图片到指定目录
shutil.copy('../data/JPEGImages/%s.jpg' % image_id, '../images/%s/%s.jpg' % (image_set, image_id))
三、训练
3.1 模型选择

这里优先考虑准确度,选择了YOLOv5x6模型。
根据自己的需求选择下载。https://github.com/ultralytics/yolov5/releases
3.2 修改配置文件
复制data/voc.yaml并重命名为data/may_dataset.yaml,并修改内容。
# Default dataset location is next to YOLOv5:
# /parent_folder
# /VOC
# /yolov5
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /home/work401/ZouQuchen/warship/images/train/
val: /home/work401/ZouQuchen/warship/images/val/
# number of classes
nc: 6
# class names
names: [ "AircraftCarrier", "Destroyer", "FishingBoat", "GaurdShip", "OilTanker", "SupplyShip" ]
3.3 train.py
修改主函数中预训练权重文件和数据集的默认路径。

四、运行
运行train.py开始训练
读取一些基本数据:

读取图片信息:
开始训练
五、检测目标
这里使用源码中提供的模型进行测试。
不得不说,YOLOv5的检测效果真是太棒了!
步骤1:下载模型或将训练好的模型放在weights目录下。(这里使用源码中提供的模型)

步骤2: 运行detect.py进行检测。
这是detect.py的main函数,可修改weights选项选择不同的模型;修改source选择检测文件的路径。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/test-images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
4.2 Colaboratory运行(未成功,有待更新)
将项目文件(包括数据集)复制到Google云盘上。

启动Colaboratory,设置GPU运行:


挂载:

cd到项目目录下:
import os
os.chdir("/content/gdrive/My Drive/Colab Notebooks/yolov5-master/")
安装依赖(只成功安装了PyYaml,可能是其他的依赖这个平台都有)
!pip install -qr requirements.txt

查看配置:
import torch
from IPython.display import Image, clear_output # to display images
from utils.google_utils import gdrive_download # to download models/datasets
clear_output()
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))

运行:
!python train.py
运行失败,但是在笔记本上可以成功运行这一步。

寻找解决方法中……