Java 面试八股文之基础篇(一)
前言

从今天开始,我将开启一个系列的文章——【 Java 面试八股文】。
这个系列会陆续更新 Java 面试中的高频问题,旨在从问题出发,理解 Java 基础,数据结构与算法,数据库,常用框架等。
首先要做几点说明:
- 【 Java 面试八股文】中的面试题来源于社区论坛,书籍等资源;感谢使我读到这些宝贵的面经的作者们。
- 对于【 Java 面试八股文】中的每个问题,我都会尽可能地写出我自己认为的“完美解答”。但是毕竟我的身份不是一个“真理持有者”,只是一个秉承着开源分享精神的 “knowledge transmitter” & 菜鸡,所以,如果这些答案出现了错误,可以留言写出你认为更好的解答,并指正我。非常感谢您的分享。
- 知识在于“融释贯通”,而非“死记硬背”;现在市面上固然有很多类似于“Java 面试必考 300 题” 这类的文章,但是普遍上都是糟粕,仅讲述其果,而不追其源;希望我的【 Java 面试八股文】可以让你知其然,且知其所以然~
那么,我们正式开始吧!
Java 基础篇(一)
1、分析程序的运行结果,并解释为什么?
程序一:
public class MyTestClass {
private static MyTestClass myTestClass = new MyTestClass();
private static int a = 0;
private static int b;
private MyTestClass() {
a++;
b++;
}
public static MyTestClass getInstance() {
return myTestClass;
}
public int getA() {
return a;
}
public int getB() {
return b;
}
}
public class Test {
public static void main(String[] args) {
MyTestClass myTestClass = MyTestClass.getInstance();
System.out.println("myTestClass.a : " + myTestClass.getA());
System.out.println("myTestClass.b : " + myTestClass.getB());
}
}
程序二:
public class MyTestClass2 {
private static int a = 0;
private static int b;
private MyTestClass2(){
a++;
b++;
}
private static final MyTestClass2 myTestClass2 = new MyTestClass2();
public static MyTestClass2 getInstance(){
return myTestClass2;
}
public int getA() {
return a;
}
public int getB() {
return b;
}
}
public class Test {
public static void main(String[] args) {
MyTestClass2 myTestClass2 = MyTestClass2.getInstance();
System.out.println("myTestClass2.a : " + myTestClass2.getA());
System.out.println("myTestClass2.b : " + myTestClass2.getB());
}
}
答
第一个程序执行的结果为:
myTestClass.a : 0
myTestClass.b : 1
第二个程序执行的结果为:
myTestClass2.a : 1
myTestClass2.b : 1
本题考查的知识点为【类加载的顺序】。一个类从被加载至 JVM 到卸载出内存的整个生命周期为:
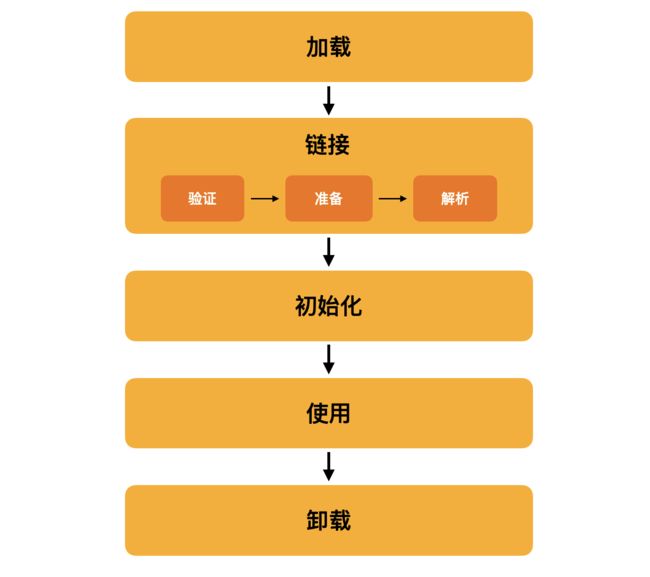
各个阶段的主要功能如下:
-
加载:查找并加载类文件的二进制数据
-
链接:将已经读入内存的类的二进制数据合并到 JVM 的运行时环境中去,包含如下几个步骤:
- 验证:确保被加载类的正确性
- 准备:为类的静态变量分配内存,赋默认值;例如:
public static int a = 1;在准备阶段对静态变量 a 赋默认值 0 - 解析:把常量池中的符号引用转换成直接引用
-
初始化:为类的静态变量赋初始值;例如:
public static int a = 1;这个时候才对静态变量 a 赋初始值 1
我们可以从 Java 类加载的这个过程中看到,类的静态变量在类加载时就已经被加载到内存中并完成赋值了!
对于第一个程序来说:
首先,在链接的准备阶段,JVM 会为类的静态变量分配内存,并赋默认值,这里面我们也可以使用更加专业的计算机词汇——“缺省值”来形容,即:
myTestClass = null;
a = 0;
b = 0;
接着,在类的初始化阶段,JVM 会为这些静态变量真正地赋初始值。
private static MyTestClass myTestClass = new MyTestClass();
对静态变量 myTestClass 赋初始值时会回调构造器,构造器中执行 a++ 与 b++,使得静态变量 a 与 b 的结果均为 1 。
对 myTestClass 这个静态变量赋值完毕后,接下来代码会继续执行,对 a 和 b 这两个静态变量赋初始值,继而又将 a 变为了 0,而 b 则没有初始值,所以其结果仍然为 1。
综上所示,程序一的输出结果为:
myTestClass.a : 0
myTestClass.b : 1
程序二的分析过程和程序一是一样的,这里我就不再赘述了。
总结
本题考查的知识点是童鞋们对类加载的理解。一定要铭记的是:静态变量的加载与初始化发生在【类加载阶段】。
2、普通内部类与静态内部类有什么区别?
答
普通内部类:
- 可以访问外部类的所有属性和方法
- 普通内部类中不能包含静态的属性和方法
静态内部类:
- 静态内部类只能访问外部类的静态属性及方法,无法访问外部类的普通成员(变量和方法)
- 静态内部类可以包含静态的属性和方法
本题回答到这里并非完美,面试官可能会继续提问:你知道为什么普通内部类可以访问到外部类的成员变量么?或者是:我应该优先选用普通内部类还是静态内部类,为什么?
我们先来看一个示例:
Home
package com.github.test;
public class Home {
class A {
}
}
Home2
package com.github.test;
public class Home2 {
static class A {
}
}
执行编译后,我们来到 target 目录下,并执行反编译命令:
javap -private 'Home$A'
Home$A.class
class com.github.test.Home$A {
final com.github.test.Home this$0;
com.github.test.Home$A(com.github.test.Home);
}
执行命令:
javap -private 'Home2$A'
Home2$A.class
class com.github.test.Home2$A {
com.github.test.Home2$A();
}
我们可以看到 Home 类当中含有普通内部类 A,而 Home2 这个类中含有静态内部类 A 。并且我们对这两个内部类执行了反解析。
执行javap命令后,我们看到普通内部类 A 比静态内部类 A 多了一个特殊的字段:com.github.test.Home this$0。
普通内部类多出的这个字段是 JDK “偷偷”为我们添加的,它指向了外部类 Home。
所以,我们也就搞清楚了,之所以普通内部类可以直接访问外部类的所有成员,是因为 JDK 为普通内部类偷偷添加了这么一个隐式的变量 this$0,指向外部类。
那么,我们应该优先选择普通内部类还是静态内部类呢?
《Effective java》 Item 24 的内容是:Favor static member classes over nonstatic,即:优先考虑使用静态内部类。
因为非静态内部类会持有外部类的一个隐式引用(this$0), 存储这个引用需要占用时间和空间。更严重的是有可能会导致宿主类在满足垃圾回收的条件时却仍然驻留在内存中,由此引发内存泄漏的问题。
所以,在需要使用内部类的情况下,我们应该尽可能选择使用静态内部类。
总结
怎么样?一道看似非常简答的问题也可能暗藏杀机。如果不知道的小伙伴们,不妨敲一下代码,自己按照流程执行一遍,这样才会加深你的印象哦~
3、分析程序的运行结果,并解释为什么?
程序一:
public class Polymorphic {
public static void main(String[] args) {
Animal cat = new Cat();
System.out.println(cat.name);
}
}
class Animal {
String name = "animal";
}
class Cat extends Animal{
String name = "cat";
}
程序二:
public class Polymorphic {
public static void main(String[] args) {
Animal cat = new Cat();
cat.speak();
}
}
class Animal {
public void speak(){
System.out.println("我是一个动物");
}
}
class Cat extends Animal{
@Override
public void speak() {
System.out.println("我是一只猫");
}
}
答
程序一的输出结果为:
animal
程序二的输出结果为:
我是一只猫
本题考查的知识点为多态。需要知道,多态分为编译时的多态性与运行时的多态性。
- 多态的应用中,对于成员变量访问的特点为:
- 编译看左边,运行看左边
- 多态的应用中,对于成员方法调用的特点为:
- 编译看左边,运行看右边
对于程序一,在程序编译时期,首先 JVM 会看向 Animal cat = new Cat(); 这句话等号左边的父类 Animal 是否有该变量(name)的定义,如果有则编译成功,如果没有则编译失败;在程序运行时期,对于成员变量,JVM 仍然会看向左边的所属类型,获取的是父类的成员变量。
对于程序二,在程序编译时期,首先 JVM 会看向 Animal cat = new Cat(); 这句话等号左边的类是否有该方法的定义,如果有则编译成功,如果没有则编译失败;在程序运行时,则是要看等号右边的对象是如何实现该方法的,所以最终呈现的结果为右边对象对这个方法重写后的结果。
总结
这是一道非常经典(老掉牙)的面试笔试题了,考察 Java 多态的基础,答错的小伙伴可要好好回顾复习下了~
4、请谈一下值传递与引用传递?Java 中只有值传递么?
答
值传递(Pass by value)与引用传递(Pass by reference)属于函数调用时,参数的求值策略(Evaluation Strategy)。求值策略的关注点在于,求值的时间以及传值方式:
| 求值策略 | 求值时间 | 传值方式 |
|---|---|---|
| Pass by value | 函数调用前 | 原值的副本 |
| Pass by reference | 函数调用前 | 原值(原始对象) |
所以,区别值传递与引用传递的实质并不是传递的类型是值还是引用,而是传值方式,传递的是原值还是原值的副本。
如果传递的是原值(原对象),就是引用传递;如果传递的是一个副本(拷贝),就是值传递。再次强调一遍,值传递和引用传递的区别在于传值方式,和你传递的类型是值还是引用没有一毛钱关系!
Java 语言只有值传递。
Java 语言之所以只有值传递,是因为:传递的类型无论是值类型还是引用类型,Java 都会在调用栈上创建一个副本,不同的是,对于值类型而言,这个副本就是整个原始值的复制;而对于引用类型而言,由于引用类型的实例存储在堆中,在栈上只有它的一个引用,指向堆的实例,其副本也只是这个引用的复制,而不是整个原始对象的复制。
我们通过两个程序来理解下:
程序一:
public class Test {
public static void setNum1(int num){
num = 1;
}
public static void main(String[] args) {
int a = 2;
setNum1(a);
System.out.println(a);
}
}
程序二:
public class Test2 {
public static void setArr1(int[] arr){
Arrays.fill(arr,1);
}
public static void main(String[] args) {
int[] arr = {1,2,3,4,5};
setArr1(arr);
System.out.println(Arrays.toString(arr));
}
}
程序一输出的结果为:2;
程序二输出的结果为:[1,1,1,1,1]。
程序一中,Java 会将原值复制一份放在栈区,并将这个拷贝传递到方法参数中,方法里面仅仅是对这个拷贝进行了修改,并没有影响到原值,所以程序一的输出结果为 2。
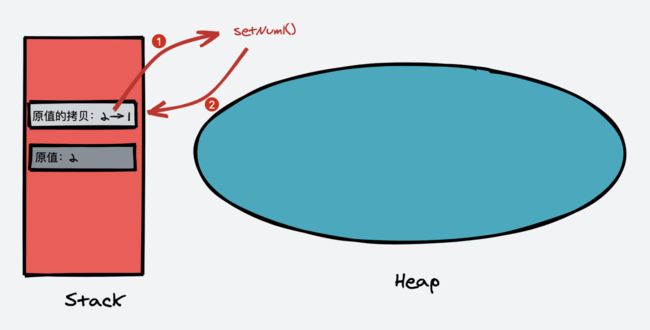
程序二中,Java 会将引用的地址复制一份放在栈区,复制的拷贝和原始引用都指向堆区的同一个对象。方法通过拷贝地址找到堆区的实例,对堆区的实例进行修改,而此时,原始引用仍然指向着堆区的实例,所以程序二的输出结果为:[1,1,1,1,1]

总结
这实际上也是一个老掉牙的问题了。
不过,请不要忽视它,它也许没有你想的那么简单。绝大部分初学者很难搞懂究竟什么是值传递,什么是引用传递。
很多博客中,作者不仅没有解释清楚“值传递”与“引用传递”,还混淆了很多错误的引导。
这些错误的理解包括:
- 【观点1】Java 中既有值传递也有引用传递
- 【观点2】Java 中只有值传递,因为引用的本质就是指向堆区的一个地址,也是一个值。
如果你的观点符合上述两种观点的其中一种,那么你多半没有理解值传递和引用传递到底是啥子东西~
5、请描述当我们 new 一个对象时,发生了什么?
答
new 一个对象时,可以将发生的活动分为以下的几个过程:
- 类加载
- 为对象分配内存空间
- 完善对象内存布局信息
- 调用对象的实例化方法
- 在栈中新建对象的引用,并指向堆中的实例
类加载
当 JVM 遇到一条 new 指令时,首先会去检查该指令的参数是否能在常量池中定位到一个类的符号引用(Symbolic Reference),并检查这个符号引用代表的类是否已经被加载,解析,初始化过。如果该类是第一次被使用,那么就会执行类的加载过程。
注:符号引用是指,一个类中引入了其他的类,可是 JVM 并不知道引入其他类在什么位置,所以就用唯一的符号来代替,等到类加载器去解析时,就会使用符号引用找到引用类的具体地址,这个地址就是直接引用
类的加载过程在上文中已经有提过,我们再不厌其烦地复习一下:
一个类从被加载至 JVM 到卸载出内存的整个生命周期为:
各个阶段的主要功能如下:
-
加载:查找并加载类文件的二进制数据
-
链接:将已经读入内存的类的二进制数据合并到 JVM 的运行时环境中去,包含如下几个步骤:
- 验证:确保被加载类的正确性
- 准备:为类的静态变量分配内存,赋默认值;例如:
public static int a = 1;在准备阶段对静态变量 a 赋默认值 0 - 解析:把常量池中的符号引用转换成直接引用
-
初始化:为类的静态变量赋初始值;例如:
public static int a = 1;这个时候才对静态变量 a 赋初始值 1
谈到了类加载,就不得不提类加载器(ClassLoader)。
以 HotSpot VM 举例,从 JDK 9 开始,其自带的类加载器如下:
- BootstrapClassLoader
- PlatformClassLoader
- AppClassLoader
而 JDK 8 虚拟机自带的加载器为:
- BootstrapClassLoader
- ExtensionClassLoader
- AppClassLoader
除了虚拟机自带的类加载器以外,用户也可以自定义类加载器(UserClassLoader)。
这些类加载器的加载顺序具有一定的层级关系:

JVM 中的 ClassLoader 会按照这样的层级关系,采用一种叫做双亲委派模型的方式去加载一个类:
那么什么是双亲委派模型呢?
双亲委托模型就是:如果一个类加载器(ClassLoader)收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委托给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器(BootstrapClassLoader)中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需要加载的类)时,子加载器才会尝试自己去加载。
使用双亲委托机制的好处是:能够有效确保一个类的全局唯一性,当程序中出现多个限定名相同的类时,类加载器在执行加载时,始终只会加载其中的某一个类。
为对象分配内存空间
在类加载完成后,JVM 就可以完全确定 new 出来的对象的内存大小了,接下来,JVM 会执行为该对象分配内存的工作。
为对象分配空间的任务等同于把一块确定大小的内存从 JVM 堆中划分出来,目前常用的有两种方式(根据使用的垃圾收集器的不同而使用不同的分配机制):
- Bump the Pointer(指针碰撞)
- Free List(空闲列表)
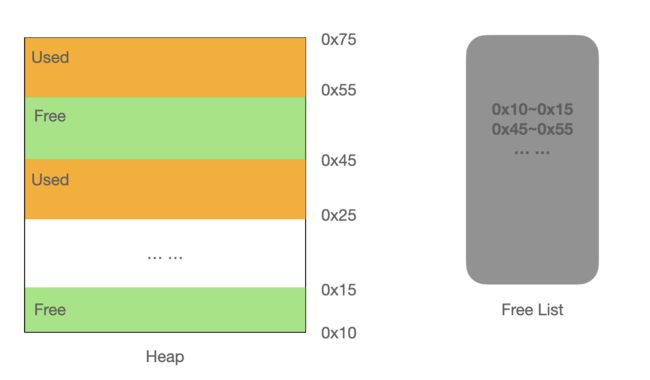
所谓的指针碰撞是指:假设 JVM 堆内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一半,中间有一个指针指向分界点,那新的对象分配的内存就是把那个指针向空闲空间挪动一段与对象大小相等的距离。

而如果 JVM 堆内存并不是规整的,即:已用内存空间与空闲内存相互交错,JVM 会维护一个空闲列表,记录哪些内存块是可用的,在为该对象分配空间时,JVM 会从空闲列表中找到一块足够大的空间划分给对象使用。
完善对象内存布局信息
在我们为对象分配好内存空间后,JVM 会设置对象的内存布局的一些信息。
对象在内存中存储的布局(以 HotSpot 虚拟机为例)分为:对象头,实例数据以及对齐填充。
-
对象头
对象头包含两个部分:
- Mark Word:存储对象自身的运行数据,如:Hash Code,GC 分代年龄,锁状态标志等等
- 类型指针:对象指向它的类的元数据的指针
-
实例数据
- 实例数据是真正存放对象实例的地方
-
对齐填充
- 这部分不一定存在,也没有什么特别含义,仅仅是占位符。因为 HotSpot 要求对象起始地址都是 8 字节的整数倍,如果不是就对齐
JVM 会为所有实例数据赋缺省值,例如整型的缺省值为 0,引用类型的缺省值为 null 等等。
并且,JVM 会为对象头进行必要的设置,例如这个对象是哪个类的实例,如何才能找到类的元数据信息,对象的 Hash Code,对象的 GC 分带年龄等等,这些信息都存放在对象的对象头中。
调用对象的实例化方法
在 JVM 完善好对象内存布局的信息后,会调用对象的
我们在上面介绍了类加载的过程(加载 -> 链接 -> 初始化),在初始化这一步骤,JVM 为类的静态变量进行赋值,并且执行了静态代码块。实际上这一步骤是由 JVM 生成的
- 父类静态变量初始化
- 父类静态代码块
- 子类静态变量初始化
- 子类静态代码块
而我们在创建实例 new 一个对象时,会调用该对象类构造器进行初始化,这里面就会执行
- 父类变量初始化
- 父类普通代码块
- 父类构造函数
- 子类变量初始化
- 子类普通代码块
- 子类构造函数
关于
- 有多少个构造器就会有多少个
- 非静态代码赋值操作与非静态代码块的执行是从上至下顺序执行,构造器在最后执行
关于
在栈中新建对象的引用,并指向堆中的实例
这一点没什么好解释的,我们是通过操作栈的引用来操作一个对象的。
总结
如果可以这么详细地将 new 一个对象的过程表达出来,这个回答我想应该是满分了。其实也不难,我们只需要记住,new 一个对象可以分为:
- 类加载
- 为对象分配内存空间
- 完善对象内存布局信息
- 调用对象的实例化方法
- 在栈中新建对象的引用,并指向堆中的实例
以上这五个步骤,并对每个步骤进行细分与归纳即可~
6、Java 对象的访问方式有哪些?
答
在 JVM 规范中只规定了 reference 类型是一个指向对象的引用,但没有规定这个引用具体如何去定位,访问堆中对象,因此对象的访问取决于 JVM 的具体实现,目前主流的访问对象的方式有两种:句柄间接访问 与 直接指针访问。
句柄间接访问
所谓的句柄间接访问是指,JVM 堆中会划分一块内存来作为句柄池,reference 中存储句柄的地址,句柄中则存储对象的实例数据以及类的元数据的地址,所以我们通过访问句柄进而达到访问对象的目的。

句柄的英文是 “Handle”。这个词的翻译最早追述于 David Gries所著的《Compiler Construction for Digital Computer》(1971)有句话 “A handle of any sentential form is a leftmost simple phrase.” 。该书中译本,《数字计算机的编译程序构造》(仲萃豪译, 1976 版)翻译成 “任一句型的句柄就是此句型的最左简单短语”。
直接指针访问
直接指针访问对象的方式为:JVM 堆中会存放访问访问类的元数据的地址,reference存储的是对象实例的地址:
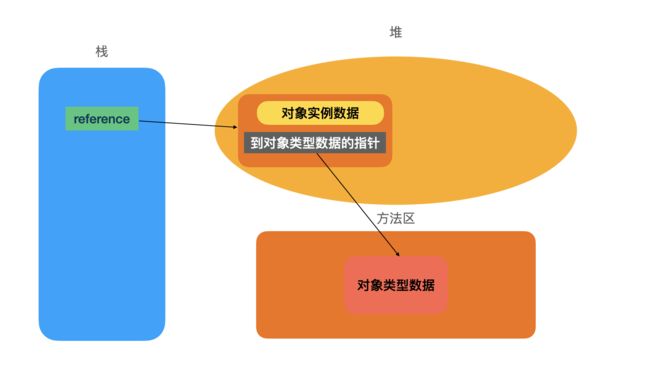
我们看到,通过句柄访问对象使用的是一种间接引用(2次引用)的方式来进行访问堆内存的对象,它导致的缺点是运行的速度稍微慢一些;通过直接指针的方式则速度快一些,因为它少了一次指针定位的开销,所以,当前最主流的 JVM: HotSpot 采用的就是直接指针这种方式来访问堆区的对象。
总结
本题考查的是 JVM 比较基础的问题,看示意图就非常容易理解哦~
7、分析程序的运行结果,并解释为什么?
程序一:
public class Main {
public static void main(String[] args) {
int a = 1000;
int b = 1000;
System.out.println(a == b);
}
}
程序二:
public class Main {
public static void main(String[] args) {
Integer a = 1000;
Integer b = 1000;
System.out.println(a == b);
}
}
程序三:
public class Main {
public static void main(String[] args) {
Integer a = 1;
Integer b = 1;
System.out.println(a == b);
}
}
程序四:
public class Main {
public static void main(String[] args) {
Integer a = new Integer(1);
Integer b = new Integer(1);
System.out.println(a == b);
}
}
答
- 程序一输出结果为:true
- 程序二输出结果为:false
- 程序三输出结果为:true
- 程序四输出结果为:false
首先,程序一输出结果为 true 肯定没什么好解释的,本题考察的重点在于对后面程序输出结果的分析。
Integer 是 int 的装箱类型,它修饰的是一个对象。当我们使用 Integer a = xxx; 的方式声明一个变量时,Java 实际上会调用 Integer.valueOf() 方法。
我们来看下 Integer.valueOf() 的源代码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
JDK 文档中的说明:
* This method will always cache values in the range -128 to 127,
* inclusive, and may cache other values outside of this range.
也就是说,由于 -128 ~ 127 这个区间的值使用频率非常高,Java 为了减少申请内存的开销,将这些对象存储在 IntegerCache 中。
所以,如果使用 Integer 声明的值在 -128 ~ 127 这个区间内的话,就会直接从常量池中取出并返回,于是我们看到,程序二输出的结果为 false,因为 Integer = 1000;Integer b = 1000; a 和 b 的值并不是从常量池中取出的,它们指向的是堆中两块不同的内存区域。而程序三:Integer a = 1;Integer b = 1; 中的 a 和 b 指向的都是常量池中同一块内存,所以结果返回 true。
对于程序四的输出结果,我们需要知道,当 new 一个对象时,则一定会在堆中开辟一块新的内存保存对象,所以 a 和 b 指向的是不同的内存区域,结果自然返回 false~
总结
还是一道老掉牙的题目,不过一些走排场的笔试题中还是有出现过的。
8、说一下 Error 和 Exception 的区别?
答
先上图:

首先,Error类和Exception类都继承自Throwable类。
先谈一下 Error 吧~
Error表示系统级的错误,一般是指与虚拟机相关的问题,由虚拟机生成并抛出,常见的虚拟机错误有:OutOfMemoryError,StackOverflowError 等等。
OutOfMemoryError,StackOverflowError 这两种错误是要求大家务必掌握的。
StackOverflowError,即栈溢出错误,一般无限制地递归调用会导致 StackOverflowError 的发生,所以,再一次提醒大家,在写递归函数的时候一定要写 base case,否则就会导致栈溢出错误的发生。
如程序:
public class StackOverflowErrorTest {
public static void foo(){
System.out.println("StackOverflowError");
foo();
}
public static void main(String[] args) {
foo();
}
}
该程序会导致抛出 StackOverflowError。
OutOfMemoryError,即堆内存溢出错误,导致 OutOfMemoryError 可能有如下几点原因:
- JVM启动参数内存值设定过小
- 代码中存在死循环导致产生过多对象实体
- 内存中加载的数据量过于庞大,一次从数据库取出过多的数据也会导致堆溢出
- 集合类中有对对象的引用,使用完后未清空,使得JVM无法回收
如程序:
public class OutOfMemoryErrorTest {
public static void main(String[] args) {
while (true){
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) { }
}).start();
}
}
}
该程序为一个不断创建新线程的死循环,运行会抛出 OutOfMemoryError。
接下来,我们再来谈一下什么 Exception?(一本正经)
Exception表示异常,通俗地讲,它表示如果程序运行正常,则不会发生的情况。
Exception可以划分为
- 运行时异常(RuntimeException)
- 非运行时异常
或者也可以划分为:
- 受检查异常(CheckedException)
- 不受检查异常(UncheckedException)
实际上,运行时异常就是不受检查异常。
什么是运行时异常(RuntimeException),或者说什么是不受检查异常(UncheckedException)呢?
通俗地讲,不受检查异常是指程序员没有细心检查代码,造成例如:空指针,数组越界等情况导致的异常。这些异常通常在编码过程中是能够避免的。并且,我可以在代码中直接抛出一个运行时异常,程序编译不会出错,譬如这段代码:
public class Test {
public static void main(String[] args) {
throw new IllegalArgumentException("wrong");
}
}
什么是受检查异常呢?
受检查异常是指在编译时被强制检查的异常。受检查异常要么使用try-catch语句进行捕获,要么使用throws向上抛出,否则是无法通过编译的。常见的受检查异常有:FileNotFoundException,SQLException等等。
总结
细心的小伙伴一定会发现,我的解答中实际上涵盖了很多的考点,面试官可以采用多种问法来考察你对 Java 异常体系的了解程度。譬如:哪些情况会发生 OutOfMemoryError?什么是运行时异常,什么是受检查异常?请列举一些常见的运行时异常和受检查异常?等等…
在这道题目的回答中,我已经将上述问题的答案都写进去了,慢慢寻找吧~
9、当代码执行到 try 块时,finally 块一定会被执行么?
答
不一定。
有两种情况会导致即便代码执行到 try 块,finally 块也有可能不执行:
- 系统终止
- 守护线程被终止
示例程序一:
package com.github.test;
public class Test {
public static void main(String[] args) {
foo();
}
public static void foo() {
try {
System.out.println("In try block...");
System.exit(0);
} finally {
System.out.println("In finally block...");
}
}
}
该程序运行的结果为:
In try block...
原因在于,try 块中,我们使用了 System.exit(0) 方法,该方法会终止当前正在运行的虚拟机,也就是终止了系统,既然系统被终止,自然而然也就执行不到 finally 块的代码了。
示例程序二:
package com.github.test;
public class Test {
public static void main(String[] args) {
Thread thread = new Thread(new Task());
thread.setDaemon(true);
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Task implements Runnable {
@Override
public void run() {
try {
System.out.println("In try block...");
Thread.sleep(5000); // 阻塞线程 5 s
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("In finally block");
}
}
}
该程序的输出结果为:
In try block...
Java 的线程可以分为两大类:
- Daemon Thread(守护线程)
- User Thread(用户线程)
所谓的守护线程就是指程序运行的时候,再后台提供一种通用服务的线程,比如垃圾回收线程就是一个守护线程。守护线程并不属于程序中不可或缺的部分,因此,当所有的用户线程结束,程序也就终止,程序终止的同时也会杀死进程中所有的守护线程。
上面的实例程序中,main 执行完毕,程序就终止了,所以守护线程也就被杀死,finally 块的代码也就无法执行到了。
总结
现在 finally 使用的很少了,关闭资源都会选择 try with resources。不过这道题仍然是一个比较经典的题目~
10、谈一谈你对 Java 异常处理的心得?
答
本题是一道开放性问答题,答案并不唯一。面试官旨在考察面试者对 Java 异常的理解,本回答为我个人对异常处理的心得体会,并非标准答案,如果大家有更好的回答,可以评论提醒我进行查漏补缺。
原则一:使用 try-with-resources 来关闭资源
《Effective Java》中给出的一条最佳实践是:Prefer try-with-resources to try-finally 。
我们知道,Java 类库中包含许多必须通过调用 close 方法手动关闭资源的类,比如:InputStream,OutputStream,java.sql.Connection 等等。在 JDK 1.7 以前,try-finally 语句是保证资源正确关闭的最佳实践。
不过,try-finally 带来的最大问题有两点:
- 有一些资源需要保证按顺序关闭
- 当我们的代码中引入了很多需要关闭的资源时,代码就会变得冗长难以维护
从 JDK 1.7 开始,便引入了 try-with-resources,这些问题一下子都得到了解决。使用 try-with-resouces 这个构造的前提是,资源必须实现了 AutoCloseable 接口。Java 类库和第三方类库中的许多类和接口现在都实现或继承了 AutoCloseable 接口。
所以,我们应该使用 try-with-resources 代替 try-finally 来关闭资源。
原则二:如果你需要使用到 finally,那么请避免在 finally 块中使用 return 语句
我们来看两个示例程序
程序一:
package com.github.test;
public class Test {
public static int test() {
int i = 1;
try {
Integer.valueOf("abc");
} catch (NumberFormatException e) {
i++;
return i;
} finally {
i++;
return i;
}
}
public static void main(String[] args) {
System.out.println(test());
}
}
程序二:
package com.github.test;
public class Test {
public static int test() {
int i = 1;
try {
Integer.valueOf("abc");
i++;
} catch (NumberFormatException e) {
i++;
return i;
} finally {
i++;
}
return i;
}
public static void main(String[] args) {
System.out.println(test());
}
}
程序一的输出结果为:
3
程序二的输出结果为:
2
导致两个程序输出不同结果的原因在于:程序一,我们将 return 语句写在了 finally 块中;而程序二则是将 return 语句写在了代码的最后部分。
在 finally 块中写 return 语句是一种非常不好的实践,因为程序会将 try-catch 块里面的语句,或者是抛出的异常全部丢弃掉。如上面的代码,Integer.valueOf("abc"); 会抛出一个 NumberFormatException ,该异常被 catch 捕获处理,我们的本意是,在 catch 块中将异常处理并返回,但是由于示例一 finally 块中有 return 语句,导致 catch 块的返回值被丢弃。
我们需要铭记一点,如果 finally 代码块中有 return 语句,那么程序会优先返回 finally 块中 return 的结果。
为了避免这样的事情发生,我们应该避免在 finally 块中使用 return 语句。
原则三:Throw early,Catch late
关于异常处理,有一个非常著名的原则叫做:Throw early,Catch late。
原文链接
微信公众号防链接丢失:
https://howtodoinjava.com/best-practices/java-exception-handling-best-practices
Remember “Throw early catch late” principle. This is probably the most famous principle about Exception handling. It basically says that you should throw an exception as soon as you can, and catch it late as much as possible. You should wait until you have all the information to handle it properly.
This principle implicitly says that you will be more likely to throw it in the low-level methods, where you will be checking if single values are null or not appropriate. And you will be making the exception climb the stack trace for quite several levels until you reach a sufficient level of abstraction to be able to handle the problem.
上文的含义是,遇到异常,你应该尽早地抛出,并且尽可能晚地捕获它。如果当前方法会抛出一个异常,我们应该判断,该异常是否应该交给这个方法处理,如果不是,那么最好的选择是将这个异常向上抛出,交给更高的调用级去处理它。
这样做的好处是,我们可以打印出更多的异常栈轨迹(Stacktrace),从最顶层的逻辑开始逐步向下,清楚地看到方法调用关系,以便我们理清报错原因。
原则四:捕获具体的异常,而不是它的父类
如果某个被调用的模块抛出了多个异常,那么只捕获这些异常的父类是非常不好的实践。
例如,某一个模块抛出了 FileNotFoundException 和 IOException ,那么调用这个模块的代码最好使用 catch 语句的级联分别捕获这两个异常,而不是只写一个 Exception 的 catch 块。
try {
// ...
}catch(FileNotFoundException e) {
// handle
}catch(IOException e) {
// handle
}
总结
这个问题是一个非常好的问题,我们其实可以发挥更多的空间,譬如谈一下如何避免 OOM ——当我们的内存中加载的数据量过于庞大,一次从数据库取出过多的数据或者是读取一个非常大的文件时很容易导致 OOM,所以我们可以使用 Buffer 来缓冲避免一次读取太多的数据,从而达到避免 OOM 的发生…
总结
今天我主要分享了 Java 基础部分的一些常考题和知识点,虽然只有十道题,但是也涵盖了非常多的知识点,希望看到这篇文章的你能受益良多。
后续的内容我会尽快更新,不过为了保证内容的质量,也可能没那么快

好啦,至此为止,这篇文章就到这里了~欢迎大家关注我的公众号,在这里希望你可以收获更多的知识,我们下一期再见!
