智能交通组合拳--飞桨实现车辆类别/车牌/车速检测、跨境头跟踪、车流密度检测、逆行检测
智能交通组合拳–飞桨实现车辆类别/车牌/车速检测、跨境头跟踪、车流密度检测、逆行检测
总体简介
这个项目的代码和文件全部都已经上传到百度aistudio上,有需要的伙伴的可以搜索下面的链接找到,那里已经配置好所有的环境和所需要的文件以及硬件。
https://aistudio.baidu.com/aistudio/projectdetail/3456845?shared=1
这里的项目分别是:
1、车流量+拥堵情况
2、车牌检测
3、车辆种类逆行
4、车辆视觉测速
这个项目是集合了大量的aistudio、BML开源项目以及官方的技术文档后,对交通车辆检测的一些模型的整合与协调使用。这里使用了多个模型和数据集,使用的模型都是飞桨常见的模型架构来训练,请小伙伴们开始前准备好足够的算力时长或者GPUhhhh。
首先这些检测识别跟踪都是由不同的模型负责的,我们需要针对检测的目的单独训练出不同检测的多个模型,然后将这些模型按照一定的优先级,合理地协调工作起来,以实现对交通的监控。为了缩短整体对GPU资源算力的需求,我会在paddleOCR读取车牌这个部分利用GPU进行预训练模型的全流程训练模型,其余部分会尽可能使用paddle的成体模型进行开发,减少整体项目的开发。
同时这些模型各有特点,需求也不一样,所以在管道中使用的频率也不一样。我根据现实中的检测需求猜测智能交通的需求是这样子的:现在有多路摄像头,可以跨镜头识别。在车辆像我们驶来时我们只需要执行一次检测,识别汽车的类型、颜色、行驶方向以及车牌的检测,随后使用的是跟踪模型来处理车辆,这个时候的需求变成了车辆测速测速、和车流量拥堵的统计。

如果时间允许,我将会出第二篇,将这些模型通过Paddle2ONNX导出为ONNX模型,进而通过openVINO转化为IR模型,实现仅在CPU就可以实现多路视频流的检测
对于以下涉及到的六种实际情况:
1、车辆种类识别
2、车辆车牌识别
3、跨境头车辆密度
4、车流密度检测
5、逆行检测
6、车速检测
将会使用到如下四种模型:
1、PP-Tracking
2、PaddleOC
3、PaddleDetection
4、 YOLO v3/2
相信看到这里很多朋友会有疑惑,为什么不用YOLO4/5,或者是faster-rcnn、transformer等这些高精度好模型,为什么用这些比较落后的模型。原因是我考虑到实际交通中,首先YOLO v2/v3这些模型经过改进后性能还算不错,第二个是我们摄像头的实时性需求,一个视频流需要调用多次模型对多个车辆进行车辆图像计算。
有很多地方涵待完善,有兴趣的朋友也可以看看以下这个过程中我主要参考的项目和文档
https://aistudio.baidu.com/aistudio/projectdetail/3022582
https://aistudio.baidu.com/aistudio/projectdetail/2324551
https://aistudio.baidu.com/aistudio/projectdetail/1283019
https://aistudio.baidu.com/aistudio/projectdetail/2312847
https://aistudio.baidu.com/aistudio/projectdetail/2013623
https://aistudio.baidu.com/aistudio/projectdetail/748136
https://aistudio.baidu.com/aistudio/projectdetail/739559
https://aistudio.baidu.com/aistudio/projectdetail/453620
https://keziyi.blog.csdn.net/article/details/121760349
https://keziyi.blog.csdn.net/article/details/122264397
https://keziyi.blog.csdn.net/article/details/121754160
https://keziyi.blog.csdn.net/article/details/122709970
https://ai.baidu.com/ai-doc/AISTUDIO/Tk39ty6ho
模型介绍
1、PP-Tracking简介
PP-Tracking是基于飞桨深度学习框架的业界首个开源实时跟踪系统。PP-Tracking内置行人车辆跟踪、跨镜头跟踪、多类别跟踪、小目标跟踪及流量计数等能力与产业应用,在模型集成多目标跟踪,目标检测,ReID轻量级算法,进一步提升PP-Tracking在服务器端部署性能。同时支持python,C++部署,适配Linux,Nvidia Jetson多平台环境。
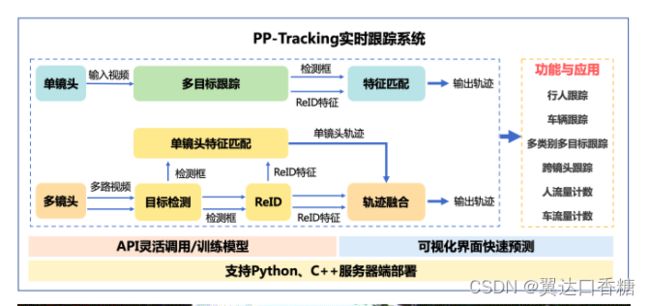
根据上面这张图我来讲一下在多个摄像头这一在交通检测特点下,实现目标的检测。先从一个摄像头说起,至于一个摄像头就对视频流中的动态目标全都跟踪起来,然后把这些目标与我们提前训练好的特征匹配起来。
如果有多路摄像头,可以看作是由多个单个摄像头的组合,每个摄像头都是进行上面的检测匹配好特征,识别出目标的种类。然后我们做的工作就是在每路摄像头中找到这个分类。
举个例子,我们有个想要追踪的车牌是88888,当一个摄像头检测到88888,车辆并不会停留一个摄像头中,他可能在每一路摄像头中出现,888888的轨迹就可能被每个摄像头拍到。
2、PaddleOCR简介
PaddleOCR是最近飞桨开源的一个OCR算法套件,OCR是指一类检查字符的模型,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,PP- OCR包含了各种主流的检测和识别算法,如DB、CRNN等等,有较为出色的检测效果。
3、PaddleDetection简介
PaddleDetection 是飞桨推出的物体检测统一框架。支持现有的RCNN、SSD、YOLO等系列模型、支持 ResNet、ResNet-VD、ResNeXt、ResNeXt-VD、SENet、MobileNet、DarkNet等主干网络。针对不同的业务场景(性能、目标大小、准确率等)可以调用框架下的不同参数(或者是参数文件),实现任务。相比于tensorflow的Object_Detection,优势之一就是将YOLO这一目标检测的快速算法融合到了框架下。
4、 YOLO v3/2简介
YOLO系列是目标检测最常用的算法,效果不错,表现较好。
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
论文:YOLOv3: An Incremental Improvement
与兴趣的朋友可以直接翻阅作者的论文,已经写的非常详细了。
模型建立
1、跨境头车流量密度统计-- PP-tracking
数据集是这里下载:https://aistudio.baidu.com/aistudio/datasetdetail/119110
- 环境准备:下载PaddleDetection
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git -b develop
下面用三段代码执行下面三步
镜像升级
!pip install --upgrade pip -i https://mirror.baidu.com/pypi/simple
安装paddlepaddle-gpu2.2.0
!pip install paddlepaddle-gpu==2.2.0rc0.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html -i https://mirror.baidu.com/pypi/simple
安装PaddleDetection的相关依赖
!cd PaddleDetection/ && pip install -r requirements.txt && python setup.py install
1.下载预测部署模型,这里为了快速上手和节约算力,我们直接使用官方提供好的训练模型 首先我们下载[wegt]目标检测和ReID预测模型,下载地址,然后统一放[mv]在~/PaddleDetection/output_inference[cd]下,然后解压[tar]
!wget https://paddledet.bj.bcebos.com/models/mot/deepsort/ppyolov2_r50vd_dcn_365e_aic21mtmct_vehicle.tar
!wget https://paddledet.bj.bcebos.com/models/mot/deepsort/deepsort_pplcnet_vehicle.tar
!cd ~/PaddleDetection/ && mkdir -p output_inference
!mv ppyolov2_r50vd_dcn_365e_aic21mtmct_vehicle.tar ~/PaddleDetection/output_inference
!mv deepsort_pplcnet_vehicle.tar ~/PaddleDetection/output_inference
!cd ~/PaddleDetection/output_inference && tar -xvf ppyolov2_r50vd_dcn_365e_aic21mtmct_vehicle.tar && tar -xvf deepsort_pplcnet_vehicle.tar
2.跨镜跟踪预测
在完成模型下载后,需要修改PaddleDetection/deploy/pptracking/python路径下的mtmct_cfg.yml,这份配置文件中包含了跨镜跟踪中轨迹融合的相关参数。首先需要确定cameras_bias中对应的名称与输入视频名称对应;其次,我们本次项目使用轨迹融合中的通用方法,将zone和camera相关的方法设置为False。
设置参数如下:
# config for MTMCT
MTMCT: True
cameras_bias:
c003: 0
c004: 0
# 1.zone releated parameters
use_zone: False #True
zone_path: dataset/mot/aic21mtmct_vehicle/S06/zone
# 2.tricks parameters, can be used for other mtmct dataset
use_ff: True
use_rerank: False #True
# 3.camera releated parameters
use_camera: False #True
use_st_filter: False
# 4.zone releated parameters
use_roi: False #True
roi_dir: dataset/mot/aic21mtmct_vehicle/S06
3.配置完成后即可运行如下命令,输入视频为c004.mp4和c003.mp4两个不同视角的摄像头拍摄结果
跨镜跟踪输出视频保存在PaddleDetection/output/mtmct.vis
!wget https://bj.bcebos.com/v1/paddledet/data/mot/demo/mtmct-demo.tar && mv mtmct-demo.tar ~/PaddleDetection && cd ~/PaddleDetection && tar xvf mtmct-demo.tar
!cd ~/PaddleDetection && python deploy/pptracking/python/mot_sde_infer.py --model_dir=output_inference/ppyolov2_r50vd_dcn_365e_aic21mtmct_vehicle/ --reid_model_dir=output_inference/deepsort_pplcnet_vehicle/ --mtmct_dir=./mtmct-demo --device=GPU --mtmct_cfg=deploy/pptracking/python/mtmct_cfg.yml --scaled=True --save_mot_txts --save_images
txt文件结果保存在output/mot_results/img1.txt,输出格式表示为frame_id(帧数第几帧), id(第几个车), bbox_left, bbox_top, bbox_width, bbox_height(四个坐标), score(分数), x, y, z 掌握这个输出很有必要,你需要通过输出检测到ID来确认车辆的数量,你可以打开看下视频的结果如下图


在实时检测中拥堵情况需要根据实际的车道来判断,这里给出判断函数,这里的函数并不是一个视觉模型,而是一个输入车数量和车道数的拥挤判断模型。对检测拥挤与否你需要用上面模型的结果和车道数输入到下面的函数中。对于实时视频你只需要调整好输入的格式就可以得到拥堵的自动测试。比如说下面这个,六章张图片代表几种情况来代入检测函数:
{‘index’: 1, ‘detector_count’: 41, ‘pic_name’: ‘7.png’},
{‘index’: 2, ‘detector_count’: 47, ‘pic_name’: ‘4.png’},
{‘index’: 3, ‘detector_count’: 19, ‘pic_name’: ‘12.png’},
{‘index’: 4, ‘detector_count’: 20, ‘pic_name’: ‘11.png’},
{‘index’: 5, ‘detector_count’: 39, ‘pic_name’: ‘1.png’},
{‘index’: 6, ‘detector_count’: 1, ‘pic_name’: ‘5.png’}
#阈值设置
#N 观测路段内某瞬时车辆数,单位:辆
#L 车道数,默认设置为4条车道
L = 4
limit = 10 #设定图中平均每条车道车辆数最大为10辆
data_list = [{'index': 1, 'detector_count': 41, 'pic_name': '7.png'}, {'index': 2, 'detector_count': 47, 'pic_name': '4.png'}, {'index': 3, 'detector_count': 19, 'pic_name': '12.png'}, {'index': 4, 'detector_count': 20, 'pic_name': '11.png'}, {'index': 5, 'detector_count': 39, 'pic_name': '1.png'}, {'index': 6, 'detector_count': 1, 'pic_name': '5.png'}]
#密度计算
def traffic_density(N):
global L
K = N / L #计算公式
return K
#获取交通状况
def Get_traffic_situation():
for i in data_list:
N = i.setdefault('detector_count')
density = traffic_density(N)
if density >= limit-5 and density < limit:
print("index为",i.setdefault('index'),"的路段车流量即将造成交通拥堵,需要及时调控!")
elif density >= limit:
print("index为",i.setdefault('index'),"的路段正处于交通堵塞!")
else:
print("index为",i.setdefault('index'),"的路段交通情况良好!")
Get_traffic_situation()

2、paddleOCR训练车牌识别模型
可以从这个渠道下载数据集:https://aistudio.baidu.com/aistudio/datasetdetail/123686随后下载数据集
!unzip -q /home/work/chepaishibie.zip
生成标签文档
本次使用的数据集为CCPD2019车牌数据集
该数据集在合肥市的停车场采集得来,采集时间早上7:30到晚上10:00。停车场采集人员手持Android POS机对停车场的车辆拍照并手工标注车牌位置。拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、阴雨天、雪天等等。CCPD数据集一共包含将近30万张图片,每种图片大小720x1160x3。一共包含8项,具体如下:

CCPD数据集没有专门的标注文件,每张图像的文件名就是对应的数据标注(label)
例如:025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg 由分隔符’-'分为几个部分:
025为区域
95_113 对应两个角度, 水平95°, 竖直113°
154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473)
386&473_177&454_154&383_363&402对应四个角点坐标
0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y…
仅使用到数据集中正常车牌即ccpd_base的数据
import os, cv2
import random
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9" ]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"]
count = 0
total = []
paths = os.listdir('/home/work/chepaishibie')#真实数据集路径
#for path in paths:
for item in os.listdir(os.path.join('/home/work/chepaishibie')):#真实数据集路径
if item[-3:] =='jpg':
new_path = os.path.join('/home/work/chepaishibie', item) #训练图片路径的路径
_, _, bbox, points, label, _, _ = item.split('-')
points = points.split('_')
points = [_.split('&') for _ in points]
tmp = points[-2:]+points[:2]
points = []
for point in tmp:
points.append([int(_) for _ in point])
label = label.split('_')
con = con_list[int(label[0])]
words = [words_list[int(_)] for _ in label[1:]]
label = con+''.join(words)
line = new_path+'\t'+'[{"transcription": "%s", "points": %s}]' % (' ', str(points))
line = line[:]+'\n'
total.append(line)
random.shuffle(total)
#注意:这里的train.txt/dev.txt都是原来没有的,现创建一个文件夹才可以打开
with open('/home/work/data/train.txt', 'w', encoding='UTF-8') as f:
for line in total[:-200]:
f.write(line)
with open('/home/work/data/dev.txt', 'w', encoding='UTF-8') as f:
for line in total[-200:]:
f.write(line)
检查data下的两个txt文件

配置环境
1.升级PaddlePaddle
!pip install paddlepaddle-gpu==2.2.1.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
2.下载PaddleOCR
!git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
3.下载预训练模型
!cd /home/work/PaddleOCR
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db.tar
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_mv3_tps_bilstm_attn.tar
注意,看下你的下面的预训练模型文件夹在哪里,我是在home/work下,我这里调乱了,路径切换到了其他地方。只要理解下面的操作是解压下载的预训练文件就行
!cd /home/work/pretrain_models
!tar -xf ch_det_mv3_db.tar && rm -rf ch_det_mv3_db.tar
!tar -xf rec_mv3_tps_bilstm_attn.tar && rm -rf rec_mv3_tps_bilstm_attn.tar
cd 切换路径
cd /home/work/PaddleOCR
!ls
安装PaddleOCR相关依赖文件 1.修改requirements文件
删除opencv-contrib-python==4.4.0.46


2.执行以下两个安装命令
!pip install -r requirements.txt
!pip install opencv-contrib-python==4.2.0.32
第三步:修改模型训练的yml文件
进入路径PaddleOCR/configs/det/
打开det_mv3_db.yml

1.修改模型路径和保存路径

2.修改训练数据的路径
训练集:

验证集:

3.设置训练参数
epoch数:

batch_size:

第四步:模型训练
这里的模型训练按照V100的性能大概半个小时就可以完成
CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py -c configs/det/det_mv3_db.yml
第五步:导出文字检测模型
!python3 /home/work/PaddleOCR/tools/export_model.py \
-c /home/work/PaddleOCR/configs/det/det_mv3_db.yml \
-o Global.checkpoints=/home/work/PaddleOCR/output/db_mv3/best_accuracy \
Global.save_inference_dir=/home/work/PaddleOCR/inference/
到这里一个模型的训练就完成了,当然还缺少模型评估这一步,但是这个模型配置的时候训练时间太少,不用评估也知道不行,所以接下来我们会下载一个。 第三步:下载安装文字识别模型
!wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar
!tar -xf ch_ppocr_server_v2.0_rec_infer.tar -C inference
第六步:模型预测
1.上传一张车牌图片作为预测图片

!python /home/work/PaddleOCR/tools/infer/predict_system.py \
--image_dir="/home/work/test.jpg" \
--det_model_dir="/home/work/PaddleOCR/inference/" \
--rec_model_dir="/home/work/PaddleOCR/inference/ch_ppocr_server_v2.0_rec_infer/" \
--use_gpu False
你可以用数据集中任何一张图片,自己输入路径调整一下就可以,路径是test.jpg那个

检测车辆类型、颜色、行驶方向
这里的环境实在是太难配置了,配置完后索性我把所需要的环境文件压缩成为了一个压缩包,只需要将这个文件解压出来,放在与paddleOCR、paddle Detection同一目录下就可以。这些模型都是训练好的模型,打开来就可以使用,不用很多GPU资源。这个压缩包我已经上传到我的CSDN百度网盘链接:https://pan.baidu.com/s/1CQHdYDT2zFj7SbX0TTrnVg 密码:zw9v,如果包丢失可以私信我CSDN个人博客来维护。
解压目录如图:
1、解压文件夹
!unzip work1.zip
导入我们所需要的库,只要上一步做的是正确的,那这步就不会报错。
import cv2
from paddle_model_cls.model_with_code.model import x2paddle_net
import argparse
import functools
import numpy as np
import paddle.fluid as fluid
import matplotlib.pyplot as plt
下面是图像预处理函数:这个函数的作用主要是将图像进行标准化,将图像放缩到224×224像素
def process_img(img, image_shape=[3, 224, 224]):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = cv2.resize(img, (image_shape[1], image_shape[2]))
#img = cv2.resize(img,(256,256))
#img = crop_image(img, image_shape[1], True)
# RBG img [224,224,3]->[3,224,224]
img = img[:, :, ::-1].astype('float32').transpose((2, 0, 1)) / 255
#img = img.astype('float32').transpose((2, 0, 1)) / 255
img_mean = np.array(mean).reshape((3, 1, 1))
img_std = np.array(std).reshape((3, 1, 1))
img -= img_mean
img /= img_std
img = img.astype('float32')
img = np.expand_dims(img, axis=0)
return img
定义预测函数:
功能是将one hot表示的标签转换为颜色、朝向、类别的索引
def get_predict(output):
output = np.squeeze(output)
pred_color = output[:9]
pred_direction = output[9:11]
pred_type = output[11:]
color_idx = np.argmax(pred_color)
direction_idx = np.argmax(pred_direction)
type_idx = np.argmax(pred_type)
return color_idx, direction_idx, type_idx
定义分类器:这里定义了分类器的一个类,用于获取图像输入,并输出预测;你看到下面是use_gpu=False,表示在CPU环境,如果用GPU你可以改成肯定
use_gpu = False
class CarClassifier(object):
def __init__(self):
self.color_attrs = ['Black', 'Blue', 'Brown',
'Gray', 'Green', 'Pink',
'Red', 'White', 'Yellow'] # 车体颜色
self.direction_attrs = ['Front', 'Rear'] # 拍摄位置
self.type_attrs = ['passengerCar', 'saloonCar',
'shopTruck', 'suv', 'trailer', 'truck', 'van', 'waggon'] # 车辆类型
self.init_params()
def inference(self, img):
fetch_list = [self.out.name]
output = self.exe.run(self.eval_program,
fetch_list=fetch_list,
feed={'image': img})
color_idx, direction_idx, type_idx = get_predict(np.array(output))
color_name = self.color_attrs[color_idx]
direction_name = self.direction_attrs[direction_idx]
type_name = self.type_attrs[type_idx]
return color_name, direction_name, type_name
def init_params(self):
# Attack graph
adv_program = fluid.Program()
# 完成初始化
with fluid.program_guard(adv_program):
input_layer = fluid.layers.data(
name='image', shape=[3, 224, 224], dtype='float32')
# 设置为可以计算梯度
input_layer.stop_gradient = False
# model definition
_, out_logits = x2paddle_net(inputs=input_layer)
self.out = fluid.layers.softmax(out_logits[0])
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
self.exe = fluid.Executor(place)
self.exe.run(fluid.default_startup_program())
# 记载模型参数
fluid.io.load_persistables(
self.exe, './paddle_model_cls/model_with_code/')
# 创建测试用评估模式
self.eval_program = adv_program.clone(for_test=True)
def predict(self, im):
im_input = process_img(im)
color_name, direction_name, type_name = self.inference(im_input)
label = '颜色:{}\n朝向:{}\n类型:{}'.format(
color_name, direction_name, type_name)
return label
%matplotlib inline
我把这个分类器名字换个表示,方便后面打出来
classifier = CarClassifier()
导入其他包
主要是一些绘图工具(PIL)和PaddleDetection工具(ppdet),这里不用担心太陌生,所有的环境都配好在压缩这里了,你只需要解压压缩包把其中多个文件夹放在这个文件同一目录下就可以
import ppdet.utils.checkpoint as checkpoint
from ppdet.utils.cli import ArgsParser
from ppdet.utils.eval_utils import parse_fetches
from ppdet.core.workspace import load_config, create
from paddle import fluid
import os
import cv2
import glob
from ppdet.utils.coco_eval import bbox2out, mask2out, get_category_info
import numpy as np
from PIL import Image
from PIL import ImageFont, ImageDraw
定义绘图函数
使用PIL库解决opencv不支持中文的问题
font_path = r'./simsun.ttc' # 新宋体
font = ImageFont.truetype(font_path, 16)
def putText(img, text, x, y, color=(0, 0, 255)):
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
b, g, r = color
a = 0
draw.text((x, y), text, font=font, fill=(b, g, r, a))
img = np.array(img_pil)
return img
这下面这一套函数是干什么的呢?它是如何是被车的种类和方向的呢?是这样子的,有一个分类器函数,我在上面定义过一次,通过检测函数可以检测出图车辆的颜色、车型(car、truck、bus、taix、SUV等)、车的正负面。如果在正向行驶的通道检测到车辆的负面就是违规了。
right_direct = 'Rear'
class new_Det(VehicleDetector):
def __init__(self):
self.size = 608
self.draw_threshold = 0.1
self.cfg = load_config('./configs/vehicle_yolov3_darknet.yml')
self.place = fluid.CUDAPlace(
0) if use_gpu else fluid.CPUPlace()
# self.place = fluid.CPUPlace()
self.exe = fluid.Executor(self.place)
self.model = create(self.cfg.architecture)
self.classifier = classifier
self.init_params()
def init_params(self):
startup_prog = fluid.Program()
infer_prog = fluid.Program()
with fluid.program_guard(infer_prog, startup_prog):
with fluid.unique_name.guard():
inputs_def = self.cfg['TestReader']['inputs_def']
inputs_def['iterable'] = True
feed_vars, loader = self.model.build_inputs(**inputs_def)
test_fetches = self.model.test(feed_vars)
infer_prog = infer_prog.clone(True)
self.exe.run(startup_prog)
if self.cfg.weights:
checkpoint.load_params(self.exe, infer_prog, self.cfg.weights)
extra_keys = ['im_info', 'im_id', 'im_shape']
self.keys, self.values, _ = parse_fetches(
test_fetches, infer_prog, extra_keys)
dataset = self.cfg.TestReader['dataset']
anno_file = dataset.get_anno()
with_background = dataset.with_background
use_default_label = dataset.use_default_label
self.clsid2catid, self.catid2name = get_category_info(anno_file, with_background,
use_default_label)
is_bbox_normalized = False
if hasattr(self.model, 'is_bbox_normalized') and \
callable(self.model.is_bbox_normalized):
is_bbox_normalized = self.model.is_bbox_normalized()
self.is_bbox_normalized = is_bbox_normalized
self.infer_prog = infer_prog
def process_img(self, img):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
shape = img.shape[:2]
img = cv2.resize(img, (self.size, self.size))
# RBG img [224,224,3]->[3,224,224]
img = img[:, :, ::-1].astype('float32').transpose((2, 0, 1)) / 255
img_mean = np.array(mean).reshape((3, 1, 1))
img_std = np.array(std).reshape((3, 1, 1))
img -= img_mean
img /= img_std
img = img.astype('float32')
img = np.expand_dims(img, axis=0)
shape = np.expand_dims(np.array(shape), axis=0)
im_id = np.zeros((1, 1), dtype=np.int64)
return img, im_id, shape
def detect(self, img):
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
raw = img.copy()
img, im_id, shape = self.process_img(img=img)
outs = self.exe.run(self.infer_prog,
feed={'image': img, 'im_size': shape.astype(np.int32), 'im_id': im_id},
fetch_list=self.values,
return_numpy=False)
res = {
k: (np.array(v), v.recursive_sequence_lengths())
for k, v in zip(self.keys, outs)
}
bbox_results = bbox2out(
[res], self.clsid2catid, self.is_bbox_normalized)
result = self.draw_bbox(raw, self.catid2name,
bbox_results, self.draw_threshold)
return result
def draw_bbox(self, image, catid2name, bboxes, threshold):
raw = image.copy()
for dt in np.array(bboxes):
catid, bbox, score = dt['category_id'], dt['bbox'], dt['score']
if score < threshold or catid == 6:
# if score < threshold:
continue
xmin, ymin, w, h = bbox
xmin = int(xmin)
ymin = int(ymin)
xmax = int(xmin + w)
ymax = int(ymin + h)
roi = raw[ymin:ymax, xmin:xmax].copy()
label = self.classifier.predict(roi)
if right_direct in label:
color = (0, 255, 0)
else:
color = (0, 0, 255)
print('检测到违章逆行!')
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), color, 4)
print(label)
print()
return image
你在使用的时候可以直接复制我上面的引用代码和函数代码,然后我你只需要使用一个det就可以检测出车的情况。
det = new_Det()
In [8]
im = cv2.imread('./demo.png')
result = det.detect(im)
plt.imshow(result[:, :, [2, 1, 0]])
plt.show()

车辆车速视觉检测
一、安装并导入包 如果你是已经按照前面的步骤安装下来那就直接补装以下的库就可以,运行补装,如果不是还需要装好paddledetectino和安装环境变量
!pip install --upgrade pip
!pip install paddledet
!pip install cmake
!pip install boost
!pip install dlib
!pip install pycocotools
import os #文件操作库
import ppdet
import dlib #机器学习算法库
import time
import threading #多线程库
import math #数学库
import cv2 #导入CV2库,处理图片或视频,版本号为3.4.13.47
import paddle
import paddle.fluid as fluid
import numpy as np #数学函数库
from PIL import ImageFont, ImageDraw, Image #图像库
import fnmatch
import random
在这里我提供一个例子视频,放在了这个项目的work路径下,你可以在vediopath中按照你自己的路径加入视频,然后os.mkdir是创造一个文件夹方便后面干活
videopath = '/home/work/test/0831_1.mp4'
os.mkdir('/home/work/test/video1')
os.mkdir('/home/work/test/video2')
os.mkdir('/home/work/test/video2.5')
os.mkdir('/home/work/test/video3')
#车速视频识别
#车速检测功能函数
#加载车辆识别文件
#加载车辆识别的分类器
carCascade = cv2.CascadeClassifier('/home/work/myhaar1.xml')
#读取视频文件
video = cv2.VideoCapture(videopath)
carWidht = 1.85
# def carNumber(carNum, cID):
# time.sleep(2)
# carNum[cID] = 'Car ' + str(cID)
def estimateSpeed(location1, location2, mySpeed,fps):
#计算像素距离
d_pixels = math.sqrt(math.pow(location2[0] - location1[0], 2) + math.pow(location2[1] - location1[1], 2))
ppm = location2[2] / carWidht
d_meters = d_pixels / ppm
speed = mySpeed + d_meters * fps
return speed
def trackMultipleObjects():
rectangleColor = (0, 0, 255)
currentCarID = 0
fps = 0
global frameCounter
frameCounter = 0
carTracker = {}
carNumbers = {}
carLocation1 = {}
carLocation2 = {}
while True:
start_time = time.time()
#读取帧
rc, image = video.read()
if(frameCounter == 0): #读取视频分辨率
global WIDTH
global HEIGHT
WIDTH = len(image[0])
HEIGHT = len(image)
#检查是否到达视频文件的末尾
if type(image) == type(None):
break
#转换帧的大小,以加快处理速度
#image = cv2.resize(image, (WIDTH, HEIGHT))
resultImage = image.copy()
frameCounter = frameCounter + 1
#print(frameCounter)
carIDtoDelete = []
for carID in carTracker.keys():
trackingQuality = carTracker[carID].update(image)
if trackingQuality < 7:
carIDtoDelete.append(carID)
for carID in carIDtoDelete:
#print('Removing carID ' + str(carID) + ' from list of trackers.')
#print('Removing carID ' + str(carID) + ' previous location.')
#print('Removing carID ' + str(carID) + ' current location.')
carTracker.pop(carID, None)
carLocation1.pop(carID, None)
carLocation2.pop(carID, None)
# frameCounter为10的倍数的时候,执行
if not (frameCounter % 10):
#将图像转换成灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#检测视频中的车辆,并用vector保存车辆的坐标、大小(用矩形表示)
# x,y表示第n帧第i个运动目标外接矩形的中心横坐标和纵坐标位置,该坐标可以大致描述车辆目标所在的位置。
# w,h表示第n帧第i个运动目标外接矩形的宽度和长度,可以描述车辆目标的大小
cars = carCascade.detectMultiScale(gray, 1.1, 13, 0, (24, 24))
#车辆检测
for (_x, _y, _w, _h) in cars:
x = int(_x)
y = int(_y)
w = int(_w)
h = int(_h)
x_bar = x + 0.5 * w
y_bar = y + 0.5 * h
matchCarID = None
for carID in carTracker.keys():
trackedPosition = carTracker[carID].get_position()
t_x = int(trackedPosition.left())
t_y = int(trackedPosition.top())
t_w = int(trackedPosition.width())
t_h = int(trackedPosition.height())
t_x_bar = t_x + 0.5 * t_w
t_y_bar = t_y + 0.5 * t_h
if ((t_x <= x_bar <= (t_x + t_w)) and (t_y <= y_bar <= (t_y + t_h)) and (x <= t_x_bar <= (x + w)) and (y <= t_y_bar <= (y + h))):
matchCarID = carID
if matchCarID is None:
print('Creating new tracker ' + str(currentCarID))
#构造追踪器
tracker = dlib.correlation_tracker()
# 设置追踪器的初始位置
#如果识别出车辆,会以Rect(x,y,w,h)的形式返回车辆的位置,然后我们可以用一个矩形网格标识车辆
tracker.start_track(image, dlib.rectangle(x, y, x + w, y + h))
carTracker[currentCarID] = tracker
# 用于生成追踪器所需要的矩形框[(startX, startY), (endX, endY)]
carLocation1[currentCarID] = [x, y, w, h]
# t = threading.Thread(target = carNum, args = (carNumbers, currentCarID))
# t.start()
currentCarID = currentCarID + 1
for carID in carTracker.keys():
# 获得追踪器的当前位置
trackedPosition = carTracker[carID].get_position()
t_x = int(trackedPosition.left())
t_y = int(trackedPosition.top())
t_w = int(trackedPosition.width())
t_h = int(trackedPosition.height())
#print([t_y,t_y+t_h,t_x,t_x+t_w])
#cv2.rectangle(resultImage, (t_x, t_y), (t_x + t_w, t_y + t_h), rectangleColor, 2)
# speed estimation
carLocation2[carID] = [t_x, t_y, t_w, t_h]
# if carID in carNumbers.keys():
# cv2.putText(resultImage, carNumbers[carID], (int(t_x + t_w/2), int(t_y)),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# else:
# cv2.putText(resultImage, 'Detecting...', (int(t_x + t_w/2), int(t_y)),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
end_time = time.time()
if not (end_time == start_time):
fps = 1.0/(end_time - start_time)
#print(fps)
cv2.putText(resultImage, 'FPS: ' + str(int(fps)), (620, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
for i in carLocation1.keys():
if frameCounter % 10 == 0:
[x1, y1, w1, h1] = carLocation1[i]
[x2, y2, w2, h2] = carLocation2[i]
#print ('previous location: ' + str(carLocation1[i]) + ', current location: ' + str(carLocation2[i]))
carLocation1[i] = [x2, y2, w2, h2]
#print('new previous location: ' + str(carLocation1[i]))
if [x1, y1, w1, h1] != [x2, y2, w2, h2]:
speed = estimateSpeed([x1, y1, w1, h1], [x2, y2, w2, h2], 100, fps)
#speed = (speed-100)*100
print('CarID ' + str(i) + ' speed is ' + str("%.2f" % round(speed, 2)) + ' km/h')
cv2.putText(resultImage, str("%.2f" % round(speed, 2)) + ' km/h' , (t_x, t_y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
else:
cv2.putText(resultImage, str("%.2f" % round(speed, 2)) + ' km/h' , (t_x, t_y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,255, 0), 2)
#%cd /home/aistudio/
str_name = '/home/work/test/video1/frame'+str(frameCounter)+'.png'
cv2.imwrite(str_name, resultImage)
vediowriter =cv2.VideoWriter('/home/work/test/test1.mp4',cv2.VideoWriter_fourcc(*'mp4v'),30,(WIDTH,HEIGHT))
for i in range(frameCounter):
i=i+1
new_image_name = '/home/work/test/video1/frame'+str(i)+'.png'
img =cv2.imread(new_image_name)
vediowriter.write(img)
trackMultipleObjects()
你可以看到上面的cv2.VideoWriter,这个就是视频保存的地址,你可以根据你的需求来进行调整和查看,我截了一张图

好的,到现在我们已经做出了所有需要用的模型,你只需要简单的一句函数和提前定义好输入的视频流就可以得到想要的输出结果,如何搭配这些函数调用制作一个智能交通方案就得等到下一个项目了hhh。