【算法岗面试】某小厂D机器学习
文章目录
- 1.__call__魔法方法(完成)
-
- (1)使实例对象变为可调用对象
- (2)弥补hasattr()函数短板
- (3)再来一个栗子
- 2.yield的用法
- 3.C++的左值和右值引用(没答上)
- 4.input=8*8,filter=3*3,stride=1,padding=1卷积结果
- 5.GBDT的特征怎么选择
- 6.智能指针怎么解决交叉引用,造成的内存泄漏
-
- (1)交叉引用的栗子:
- (2)解决方案
- 7. C++多线程了解不?
-
- (1)并行和并发的概念:
- (2)并发的基本方法
- (3)C++11中的并发与多线程
- 8.头文件functional(C++11特性)
- 9.小结
- Reference
1.__call__魔法方法(完成)
(1)使实例对象变为可调用对象
__call__类似在类中重载()运算符,使得类实例对象可以像调用普通函数一样,即使用对象名():
class Pig:
# 定义__call__方法
def __call__(self,name,add):
print("调用__call__()方法",name,add)
pig = Pig()
pig("你是猪吗?","不是哦")
# 调用__call__()方法 你是猪吗? 不是哦
通过在Pig类中实现__call__方法,使得实例对象pig变为可调用对象。对于可调用对象,名称()等价于名称.__call__。即上面的代码等价于为pig.__call__("你是猪吗?", "不是哦")。
- python中的可调用对象:
- 自定义函数
- python内置函数
- 上面的类实例对象
(2)弥补hasattr()函数短板
hasattr(当前对象, 属性)函数能够判断当前对象是否包含对应的属性 or 方法,但是不能判断同名情况,是指类属性 还是 类方法。
类实例对象包含的方法,也是可调用对象(有__call__()方法),但是类属性不是可调用对象。所以如下栗子的say类方法是可调用对象,拥有__call__()方法。
class CLanguage:
def __init__ (self):
self.name = "language"
self.add = "english"
def say(self):
print("hello world!")
clangs = CLanguage()
if hasattr(clangs,"name"):
print(hasattr(clangs.name,"__call__"))
print("**********")
if hasattr(clangs,"say"):
print(hasattr(clangs.say,"__call__"))
(3)再来一个栗子
class Entity:
'''调用实体来改变实体的位置。'''
def __init__(self, x):
self.x = x
def __call__(self):
'''改变实体的位置'''
print('self.x:', self.x)
entity = Entity(1)
entity()
================================
output:
self.x: 1
2.yield的用法
一个打印斐波那契数列的栗子:
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 使用 yield
# print b
a, b = b, a + b
n = n + 1
for n in fab(5):
print (n)
-
yield的作用就是把一个函数变成一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个iterable对象! -
在 for 循环执行时,每次循环都会执行
fab函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。 -
也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法):
>>>f = fab(5)
>>> f.next()
1
>>> f.next()
1
>>> f.next()
2
>>> f.next()
3
>>> f.next()
5
>>> f.next()
Traceback (most recent call last):
File "" , line 1, in <module>
StopIteration
3.C++的左值和右值引用(没答上)
这玩意还要好好学学:C++11的左值引用与右值引用总结
4.input=88,filter=33,stride=1,padding=1卷积结果
padding后是9乘9,然后和卷积核运算后是7乘7。
5.GBDT的特征怎么选择
决策树常用于分类,目标就是将具有 P P P 维特征的 n n n 个样本分到 C C C 个类别中,相当于做一个映射 C = f ( n ) C = f(n) C=f(n) ,将样本经过一种变换赋予一个 l a b e l label label。可以把分类的过程表示成一棵树,每次通过选择一个特征 p i pi pi 来进行进一步分叉分类。
决策树中的特征重要性,不像线性回归一样可以用系数表示特征重要性。而根据每次分叉选择哪个特征对样本进行划分,能够又快又准地对样本进行分类,即根据不同的特征选择方案,我们分为了:ID3、C4.5、CART等算法。
| ID3树 | C4.5树 | CART算法 | |
|---|---|---|---|
| 评价标准 | 信息增益 | 信息增益比 | 基尼指数 |
| 样本类型 | 离散型变量 | 连续型变量 | 连续型变量 |
| 任务 | 分类 | 分类 | 分类and回归(回归树使用最小平方误差) |
6.智能指针怎么解决交叉引用,造成的内存泄漏
结论:创建对象时使用shared_ptr强智能指针指向,其余情况都使用weak_ptr弱智能指针指向。
(1)交叉引用的栗子:
当A类中有一个指向B类的shared_ptr强类型智能智能,B类中也有一个指向A类的shared_ptr强类型智能指针。
main函数执行后有两个强智能指针指向了对象A,对象A的引用计数为2,B类也是:
#include 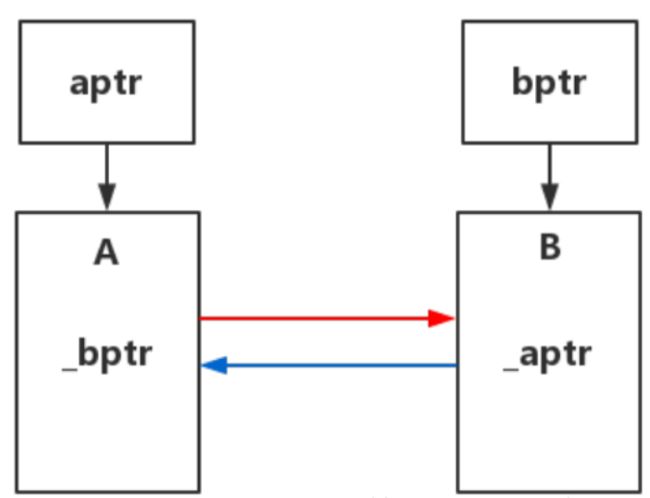
而当主函数main的return返回后,对象A的引用计数减一变为1(aptr没指向A对象了),B对象也是,引用计数不为0,即不能析构2个对象释放内存,造成内存泄漏。
(2)解决方案
将类A和类B中的shared_ptr强智能指针都换成weak_ptr弱智能指针;
class A{
public:
weak_ptr<B> _bptr;
};
class B{
public:
weak_ptr<A> _aptr;
};
weak_ptr弱智能指针,虽然有引用计数,但实际上它并不增加计数,而是只观察对象的引用计数。所以此时对象A的引用计数只为1,对象B的引用计数也只为1。

7. C++多线程了解不?
多线程指的是在一个程序进程中处理控制流的多路并行通道,它在所有操作系统上为运行该程序提供了相同程度的并发性。C++ 11 之后添加了新的标准线程库 std::thread,std::thread 在
(1)并行和并发的概念:
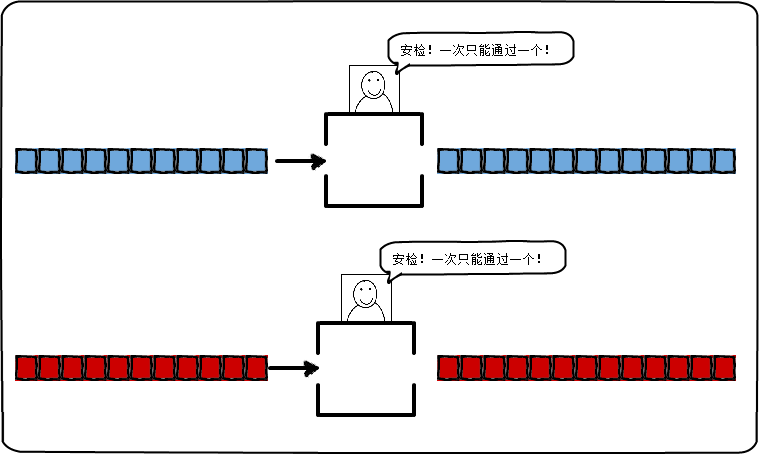
- 并行:同时执行,计算机在同一时刻,在某个时间点上处理两个或以上的操作。(如下图)
判断一个程序是否并行执行,只需要看某个时刻上是否多两个或以上的工作单位在运行。一个程序如果是单线程的,那么它无法并行地运行。利用多线程与多进程可以使得计算机并行地处理程序(当然 ,前提是该计算机有多个处理核心)。
- 并发:同一时间段内可以交替处理多个操作。如下图。每个队列都有自己的安检窗口,两个队列中间没有竞争关系,队列中的某个排队者只需等待队列前面的人安检完成,然后再轮到自己安检。
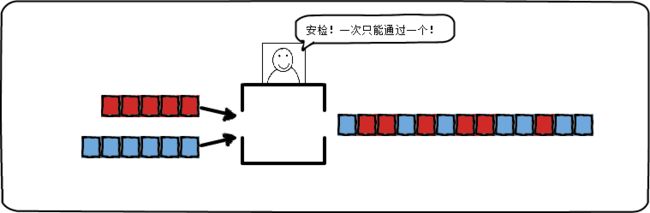
如果我们将程序的结构设计为可以并发执行的,那么在支持并行的机器上,我们可以将程序并行地执行。因此,并发重点指的是程序的设计结构,而并行指的是程序运行的状态。并发编程,是一种将一个程序分解成小片段独立执行的程序设计方法。
(2)并发的基本方法
- 多进程:
- 如你和小伙伴要开发一个项目,但是已经放假回家了,所以通过wechat联系,各自工作时互不干扰。这里的小伙伴代表线程,工作地点代表一个处理器,这个场景的每个小伙伴是一个单线程的进程(拥有独立的处理器)。
- 多个进程独立地运行,它们之间通过进程间常规的通信渠道传递讯息(信号,套接字,文件,管道等),这种进程间通信不是设置复杂就是速度慢,这是因为为了避免一个进程去修改另一个进程,操作系统在进程间提供了一定的保护措施,当然,这也使得编写安全的并发代码更容易。运行多个进程也需要固定的开销:进程的启动时间,进程管理的资源消耗。
- 多线程:
- 上学时,你和小伙伴在实验室共同讨论问题,头脑风暴,更有效地沟通项目。这里的场景即只有一个处理器,所有小伙伴都是属于同一进程的线程。
C++11 标准提供了一个新的线程库,内容包括了管理线程、保护共享数据、线程间的同步操作、低级原子操作等各种类。标准极大地提高了程序的可移植性,以前的多线程依赖于具体的平台,而现在有了统一的接口进行实现。 - 在当个进程中运行多个线程也可以并发。线程就像轻量级的进程,每个线程相互独立运行,但它们共享地址空间,所有线程访问到的大部分数据如指针、对象引用或其他数据可以在线程之间进行传递,它们都可以访问全局变量。进程之间通常共享内存,但这种共享通常难以建立且难以管理,缺少线程间数据的保护。因此,在多线程编程中,我们必须确保每个线程锁访问到的数据是一致的。
- 上学时,你和小伙伴在实验室共同讨论问题,头脑风暴,更有效地沟通项目。这里的场景即只有一个处理器,所有小伙伴都是属于同一进程的线程。
(3)C++11中的并发与多线程
C++11 新标准中引入了几个头文件来支持多线程编程:(所以我们可以不再使用 CreateThread 来创建线程,简简单单地使用 std::thread 即可。)
< thread > :包含std::thread类以及std::this_thread命名空间。管理线程的函数和类在 中声明.
< atomic > :包含std::atomic和std::atomic_flag类,以及一套C风格的原子类型和与C兼容的原子操作的函数。
< mutex > :包含了与互斥量相关的类以及其他类型和函数
< future > :包含两个Provider类(std::promise和std::package_task)和两个Future类(std::future和std::shared_future)以及相关的类型和函数。
< condition_variable > :包含与条件变量相关的类,包括std::condition_variable和std::condition_variable_any。
8.头文件functional(C++11特性)
- 以及用于绑定函数对象的实参值的绑定器(binder)。这些类模板的实例是具有函数调用运算符(function call operator)的C++类,这些类的实例可以如同函数一样调用。不必写新的函数对象,而仅是组合预定义的函数对象与函数对象适配器(function object adaptor),就可以执行非常复杂的操作。
9.小结
算法项目,C++11特性问了几个,常见机器学习算法都问。
Reference
[1] C++11多线程的三种创建方式
[2] Linux c++线程同步的四种方式:互斥锁,条件变量,读写锁,信号量
[3] 菜鸟教程—C++ std::thread
[4] https://www.cnblogs.com/yskn/p/9355556.html(重点)
[5] 菜鸟教程—C++多线程
[6] C++/C++11中头文件functional的使用