人工智能实践Tensorflow2.0 第五章--1.卷积神经网络基础--八股法搭建卷积神经网络--北京大学慕课
第五章–卷积神经网络基础–八股法搭建卷积神经网络
本讲目标:
介绍神经网络基本概念,用八股法实现卷积神经网络(以cifar10为例,本节建立的框架作为后续网络的baseline,在baseline中修改实现其他网络)。参考视频。
卷积神经网络基础
- 0.回顾全连接神经网络
- 1.卷积计算过程
-
- 1.1-卷积概念
- 1.2-卷积核的表示
- 1.3-单通道图像卷积计算
- 1.4-RGB通道图像卷积计算
- 2.感受野
-
- 2.1-感受野(Receptive Field)计算
- 3.全零填充
-
- 3.1-全零填充计算
- 3.2-全零填充TF描述
- 4.TF描述卷积层
- 5.批标准化(Batch Normalization,BN)
- 6.池化层
- 7.舍弃层(Dropout)
- 8.搭建卷积神经网络(CBAPB)
-
- 8.1-CBAPB组成
- 8.2-CBAPB示例
- 9.八股法搭建完整卷积神经网络
-
- 9.1-完整代码
- 9.2-输出结果
- 10.总结八股创建神经网络
-
- 10.1 import
- 10.2 train,test
- 10.3搭建神经网络结构----Sequential or class
- 10.4model.compile
- 10.5 model.fit
- 10.6 model.summary
0.回顾全连接神经网络
每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。全连接网络的参数个数为:

第一层参数:784x128+128
第二层参数:128x10+10
总共101770个参数
但在实际应用中,图片大多数高分辨率的多通道图片,如下图所示:

如此直接输入到全连接网络,会使得待优化的参数过多,容易导致模型的过拟合。
为了解决参数量过大而导致模型过拟合的问题,一般不会将原始图像直接输入,而是对图像进行特征提取,再将提取到的特征输入到全连接网络,如下图所示,是将汽车图片经过多次特征提取后再送入全连接网络。

1.卷积计算过程
1.1-卷积概念
卷积计算可认为是一种有效提取图像特征的方法。一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。
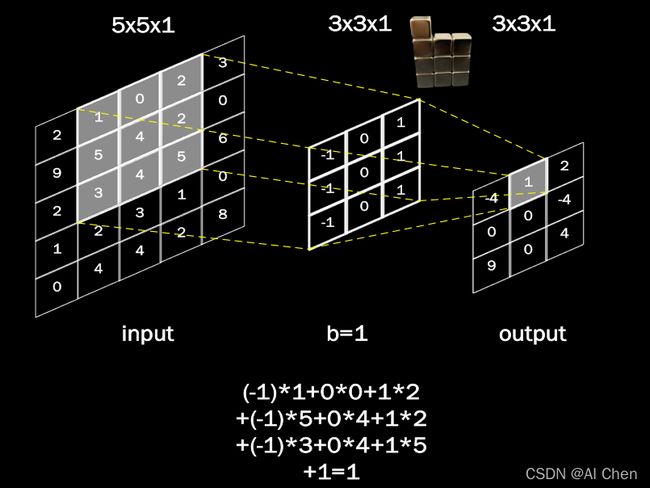
每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点,详细计算如下图所示:

输入特征图的深度(channel),决定了当前层卷积核的深度),当前层卷积核的个数,决定了当前层输出特征图的深度。
1.2-卷积核的表示

左图是单通道的3x3卷积,共10个参数;
中间是三通道的3x3卷积,共28个参数;
右图是三通道的5x5卷积,共76个参数。
1.3-单通道图像卷积计算
1.4-RGB通道图像卷积计算

2.感受野
2.1-感受野(Receptive Field)计算
感受野是指卷积神经网络个输出特征图中的每个像素点,在原始输入图片上映射区域的大小。

感受野的相关概念及大小选型可以参考这篇文章。
3.全零填充
3.1-全零填充计算
为了保持输出图像尺寸与输入图像一致,经常会在输入图像周围进行全零填充,如下图所示,在5x5的输入图像周围填0,则输出的尺寸仍为5x5。
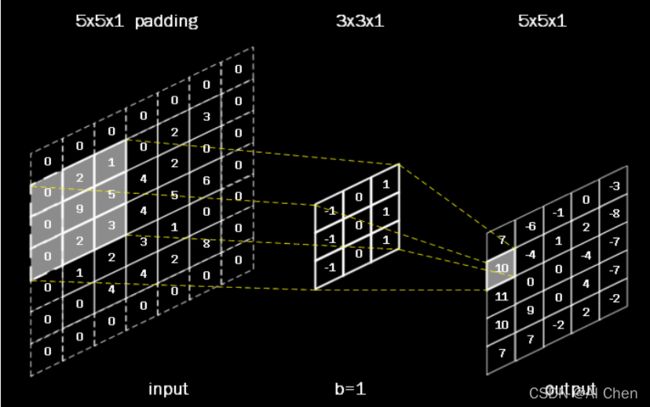
3.2-全零填充TF描述

tensorflow描述全零填充用参数padding=’SAME’或padding=’VALID’表示。

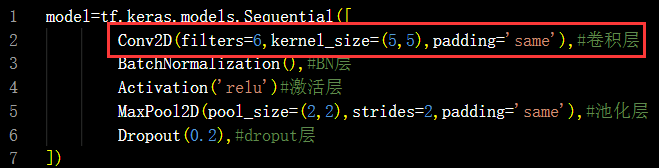
4.TF描述卷积层
tf.keras.layers.Conv2D (
filters = 卷积核个数,
kernel_size = 卷积核尺寸,
strides = 滑动步长,
padding = “same” or “valid”, #使用全零填充是“same”,不使用是“valid”(默认)
activation = “ relu ” or “ sigmoid ” or “ tanh ” or “ softmax”等 , # 如有BN 此处不写
input_shape = (高, 宽 , 通道数) #输入特征图维度,可省略
)
卷积层的表示如下:
5.批标准化(Batch Normalization,BN)
标准化:使数据符合0均值1为标准差的分布
批标准化:对一小批数据(batch),做标准化处理

6.池化层
池化用于减少特征数量;
最大值池化可提取图片纹理;
tf.keras.layers.MaxPool2D(
pool_size= 池化核尺寸,
strides= 池化步长,#默认为pool_size
padding=‘valid’or‘same’ #(默认)“valid”
)
均值池化可保留背景特征;
tf.keras.layers.AveragePooling2D(
pool_size= 池化核尺寸,
strides= 池化步长,#默认为pool_size
padding=‘valid’or‘same’ # (默认)“valid”)
)
7.舍弃层(Dropout)
神经网络训练时,将一部分神经元按照一定概率从神经网络中暂时舍弃。
神经网络使用时,被舍弃的神经元恢复连接。

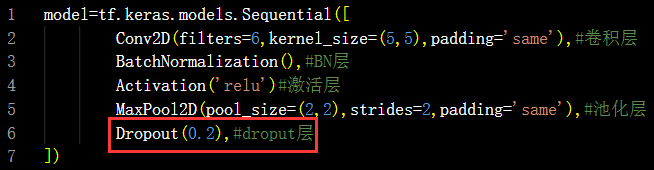
8.搭建卷积神经网络(CBAPB)
8.1-CBAPB组成
利用上述知识,就可以构建出基本的卷积神经网络(CNN)了,其核心思路为在 CNN中利用卷积核(kernel)提取特征后,送入全连接网络。
CNN 模型的主要模块:一般包括上述的卷积层(Conv2D)、BN 层、激活函数(Activation)、池化层(Pooling)、失活(舍弃)层(Dropout)以及全连接层。

故取特征提取部分的各个模块的首字母,组成CBPAB。
牢记以下五个部分组成卷积:

卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
卷积就是特征提取器:CBAPB
Conv2D、BatchNormalization、Activation、Pooling、Dropout
8.2-CBAPB示例
搭建如下网络,记住CBAPB
卷积就是特征提取器,就是CBAPB。

卷积就是特征提取器:CBAPB
9.八股法搭建完整卷积神经网络
9.1-完整代码
#六步法第一步->import导入需要的包
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPool2D,Dropout,Flatten,Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
#六步法第二步->输入train,test
cifar10=tf.keras.datasets.cifar10
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
x_train,x_test=x_train/255.,x_test/255.
#六步法第三步->Model搭建网络结构
class Baseline(Model):
def __init__(self):
super(Baseline,self).__init__()
#卷积就是CBAPD
#C
self.c1=Conv2D(filters=6,kernel_size=(5,5),padding='same')#卷积层
#B
self.b1=BatchNormalization()#BN层
#A
self.a1=Activation('relu')#激活层
#P
self.p1=MaxPool2D(pool_size=(2,2),strides=2,padding='same')#池化层
#D
self.d1=Dropout(0.2)#dropout层
self.flatten=Flatten()
self.f1=Dense(128,activation='relu')
self.d2=Dropout(0.2)
self.f2=Dense(10,activation='softmax')
def call(self,x):
x=self.c1(x)
x=self.b1(x)
x=self.a1(x)
x=self.p1(x)
x=self.d1(x)
x=self.flatten(x)
x=self.f1(x)
x=self.d2(x)
y=self.f2(x)
return y
model=Baseline()
#六步法第四步->compile配置模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
#加载已经有的模型,如果没有则不加载
checkpoint_save_path='./checkpoint/Baseline.ckpt'
if os.path.exists(checkpoint_save_path+'.index'):
print('-------load the model-------')
model.load_weights(checkpoint_save_path)
#编写自动保存模型的回调函数
cp_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True
)
#六步法第五步->fit训练模型
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
#六步法第五步->summary查看网络模型
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1,2,1)
plt.plot(acc,label='Training Accuracy')
plt.plot(val_acc,label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
9.2-输出结果
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 3s 0us/step
170508288/170498071 [==============================] - 3s 0us/step
Epoch 1/5
1563/1563 [==============================] - 19s 6ms/step - loss: 1.6454 - sparse_categorical_accuracy: 0.4035 - val_loss: 1.4076 - val_sparse_categorical_accuracy: 0.5007
Epoch 2/5
1563/1563 [==============================] - 9s 6ms/step - loss: 1.3999 - sparse_categorical_accuracy: 0.4932 - val_loss: 1.2718 - val_sparse_categorical_accuracy: 0.5448
Epoch 3/5
1563/1563 [==============================] - 9s 6ms/step - loss: 1.3375 - sparse_categorical_accuracy: 0.5205 - val_loss: 1.2459 - val_sparse_categorical_accuracy: 0.5546
Epoch 4/5
1563/1563 [==============================] - 9s 6ms/step - loss: 1.2863 - sparse_categorical_accuracy: 0.5368 - val_loss: 1.3322 - val_sparse_categorical_accuracy: 0.5338
Epoch 5/5
1563/1563 [==============================] - 9s 5ms/step - loss: 1.2570 - sparse_categorical_accuracy: 0.5509 - val_loss: 1.1740 - val_sparse_categorical_accuracy: 0.5871
Model: "baseline"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 456
batch_normalization (BatchN multiple 24
ormalization)
activation (Activation) multiple 0
max_pooling2d (MaxPooling2D multiple 0
)
dropout (Dropout) multiple 0
flatten (Flatten) multiple 0
dense (Dense) multiple 196736
dropout_1 (Dropout) multiple 0
dense_1 (Dense) multiple 1290
=================================================================
Total params: 198,506
Trainable params: 198,494
Non-trainable params: 12
________________________________________________________________

10.总结八股创建神经网络
10.1 import
引入tensorflow、keras、numpy、matplotlib等库,可以同时引入keras中的layers、models等库方便调用内部的API。
10.2 train,test
读取数据集,可以来源于框架本身带的数据集,如mnist,fashion,鸢尾花数据集等。或者实际应用中需要自己制作数据集。
10.3搭建神经网络结构----Sequential or class
当网络结构比较简单时,可以利用keras中的tf.keras.Sequential 来搭建顺序网络模型。
但当网络不是简单的顺序模型时(如残差网络),则需要用class来定义自己的网络结构。
10.4model.compile
对搭建好的网络进行编译,需要指定优化器(Adam、sgd、RMSdrop)、损失函数(交叉熵、均方差)以及需要记录的准确率和损失值(acc/loss)
10.5 model.fit
指定训练数据、验证数据、迭代轮数、批量大小等等。由于神经网络的参数量和计算量一般都比较大,训练所需的时间也会比较长,所以会在这里加入断点续训以及模型参数的保存等等,使得训练更加方便。同时防止程序意外停止导致数据丢失的情况。
10.6 model.summary
将神经网络的模型具体信息打印出来,包括网络结构、网络各层参数等,便于对网络进行浏览和检查。