Python机器学习日记2:鸢尾花分类(持续更新)
Python机器学习日记2:鸢尾花分类
- 一、书目与章节
- 二、 前言
-
- 1. 什么是机器学习
- 2. 熟悉任务和数据
- 3. 本文软件版本
- 4. scikit-learn参考资料
- 三、 问题类型
- 四、 鸢尾花数据集
-
- 1. 导入库
- 2. 数据集初探
-
- 2.1. DESCR
- 2.2. target_names
- 2.3. feature_names
- 2.4. data
- 2.5. target
- 2.6. frame
- 五、衡量模型是否成功
-
- 1. 机器学习目的
- 2. 泛化能力
- 3. 训练集与测试集
- 六、观察数据/检查数据
- 七、k邻近算法
-
- 1. 模型构建
- 2. 进行预测
- 3. 模型评估
一、书目与章节

拜读的是这本《Python机器学习基础教程》,本文选自第一章引言,主要内容为:鸢尾花分类入门案例。
本书全部代码:https://github.com/amueller/introduction_to_ml_with_python
二、 前言
1. 什么是机器学习
机器学习(machine learnin)是从数据中提取知识。它是统计学、人工智能、和计算机科学交叉的研究领域,也被称为预测分析(predictive analytics)或统计学习(statistical learning)
2. 熟悉任务和数据
机器学习中最重要的一部分是理解手头上在处理的数据!以及这些数据与需要解决的问题间的关系!随机选择一个算法并输入数据,这样做是无效的。因此,在建模前理解数据集的内容极其重要!每种算法输入数据类型和最合适解决的问题都是不一样的。以下几个问题都是我们需要预先思考的:
- 需要解决什么问题?现有数据可否解决?
- 用什么机器学习方法最好?
- 提取了什么数据特征?这些特征可否实现正确预测?
- 如何衡量应用是否成功?
- 机器学习解决方案与我的研究或商业产品中的其他部分是如何相互影响的?
3. 本文软件版本
Anaconda3 2021.05
import sys
print(f"Python version:{sys.version}")
print("--"*40)
import sklearn
print(f"scikit-learn version:{sklearn.__version__}")
print("--"*40)
import pandas as pd
print(f"pandas version:{pd.__version__}")
print("--"*40)
import numpy as np
print(f"numpy version:{np.__version__}")
print("--"*40)
import scipy as sp
print(f"Scipy version:{sp.__version__}")
print("--"*40)
import matplotlib
print(f"matplotlib version:{matplotlib.__version__}")
print("--"*40)
Python version:3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)]
--------------------------------------------------------------------------------
scikit-learn version:0.24.1
--------------------------------------------------------------------------------
pandas version:1.2.4
--------------------------------------------------------------------------------
numpy version:1.20.1
--------------------------------------------------------------------------------
Scipy version:1.6.2
--------------------------------------------------------------------------------
matplotlib version:3.3.4
--------------------------------------------------------------------------------
4. scikit-learn参考资料
scikit-learn是最有名的机器学习库,建议学习参考以下内容:
scikit-learn文档
scikit-learn用户指南
三、 问题类型
监督学习问题(有已知品种的鸢尾花的测量数据)+ 三分类问题(在三个鸢尾花品种中预测一个)
四、 鸢尾花数据集
1. 导入库
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
iris = load_iris()
2. 数据集初探
Iris数据集是常用的分类实验数据集,由Fisher于1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
load_iris返回的是一个Bunch对象,与字典类似,包含键和值:
>>> type(iris)
sklearn.utils.Bunch
查看Bunch的键:
>>> iris.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
下面我们分别来看看这些键中的内容是什么:
2.1. DESCR
DESCR键对应的为数据集的基本描述:
>>> print(iris['DESCR'][0:1210]+"\n...")
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
2.2. target_names
target_names中返回的为数据集贡献者所研究的三种鸢尾花的名称,我们称之为“类别”,分别为Iris setosa(山鸢尾)、Iris versicolor(杂色鸢尾)、Iris virginica(维吉尼卡鸢尾):
>>> print(iris.target_names) # iris的种类
['setosa' 'versicolor' 'virginica']

2.3. feature_names
feature_names中返回的是被研究的鸢尾花的4个“特征值”,分别为“花萼长度”、“花萼宽度”、“花瓣长度”、“花瓣宽度”(以cm为单位):
>>> print(iris.feature_names)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
2.4. data
data中返回的是特征值的具体数据(这里仅查看前五行):
>>> iris.data[:5] # iris_datas.values()
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]])
数据类型为numpy.ndarray:
>>> type(iris.data)
numpy.ndarray
该对象含有150行和4列:
>>> iris.data.shape
(150, 4)
机器学习中的个体叫做样本(sample),其属性叫做特征(feature)。data数组的形状(shape)是样本数乘以特征数。
2.5. target
target返回的为鸢尾花种类,上述三个种类鸢尾花每种各50个样本,分别用0、1、2指代,:
>>> iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
数据类型为numpy.ndarray:
>>> type(iris.target)
numpy.ndarray
对象的大小为150行的一维数组:
>>> iris.target.shape #一维数据,后面是n则是n维数据
(150,)
2.6. frame
frame返回值为None
将数据转为dataframe格式看看(列名为4个特征值,数据部分为特征值的大小,索引被我更改为0,1,2三个类型):
X = iris.data
y = iris.target
df = pd.DataFrame(X, columns= iris.feature_names, index = y)
df
五、衡量模型是否成功
1. 机器学习目的
利用现有数据预测新测量的鸢尾花的品种。
2. 泛化能力
不能用构建模型的数据用于评估模型,否则模型的“记忆”总会预测正确的标签,无法评价模型的“泛化”能力(指机器学习算法对新鲜样本的适应能力:泛化能力)
3. 训练集与测试集
因此,需要用新的数据(模型未见过的)来评估模型性能。通常是将现有数据分为两分,一部分用于构建机器学习模型,称为“训练数据/训练集”;另一部分用于评估模型性能,称为“测试数据/测试集”。
train_test_split函数可以利用“伪随机数生成器”将数据集打乱并拆分:默认75%为训练集,25%为测试集(可以自行定义比例),但是一般为3:1。
数据通常用大写的X表示,标签用小写的y表示。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris_datas['data'],iris_datas['target'],random_state=0)
可见150行数据被顺利拆分,比例为112:38 = 3:1。
训练数据X_train与训练标签y_train:
>>> print(f"X_train shape:{X_train.shape}")
>>> print(f"y_train shape:{y_train.shape}")
X_train shape:(112, 4)
y_train shape:(112,)
测试数据X_test与测试标签y_test:
>>> print(f"X_test shape:{X_test.shape}")
>>> print(f"y_test shape:{y_test.shape}")
X_test shape:(38, 4)
y_test shape:(38,)
查看下y_train,确实被打乱了。
>>> y_train
array([1, 1, 2, 0, 2, 0, 0, 1, 2, 2, 2, 2, 1, 2, 1, 1, 2, 2, 2, 2, 1, 2,
1, 0, 2, 1, 1, 1, 1, 2, 0, 0, 2, 1, 0, 0, 1, 0, 2, 1, 0, 1, 2, 1,
0, 2, 2, 2, 2, 0, 0, 2, 2, 0, 2, 0, 2, 2, 0, 0, 2, 0, 0, 0, 1, 2,
2, 0, 0, 0, 1, 1, 0, 0, 1, 0, 2, 1, 2, 1, 0, 2, 0, 2, 0, 0, 2, 0,
2, 1, 1, 1, 2, 2, 1, 1, 0, 1, 2, 2, 0, 1, 1, 1, 1, 0, 0, 0, 2, 1,
2, 0])
六、观察数据/检查数据
构建模型之前,检查数据有以下几个好处:
- 帮助我们判断机器学习是否可以轻松完成任务。
- 查看需要的信息是否包含于数据中。
- 发现异常值和特殊值的好方法。
最佳方法为“数据可视化”:
!pip install mglearn
散点矩阵图(pair plot)是个不错的选择,适用于大于三个特征的数据集作图,函数为scatter_matrix:
import mglearn
iris_dataframe = pd.DataFrame(X_train, columns = iris.feature_names) # 选择的是训练集的数据绘图
grr = pd.plotting.scatter_matrix(iris_dataframe, c = y_train, figsize = (15,15), marker = 'o',
hist_kwds = {'bins':20}, s = 60, alpha = 0.8, cmap = mglearn.cm3)
矩阵的对角线是每个特征的直方图。
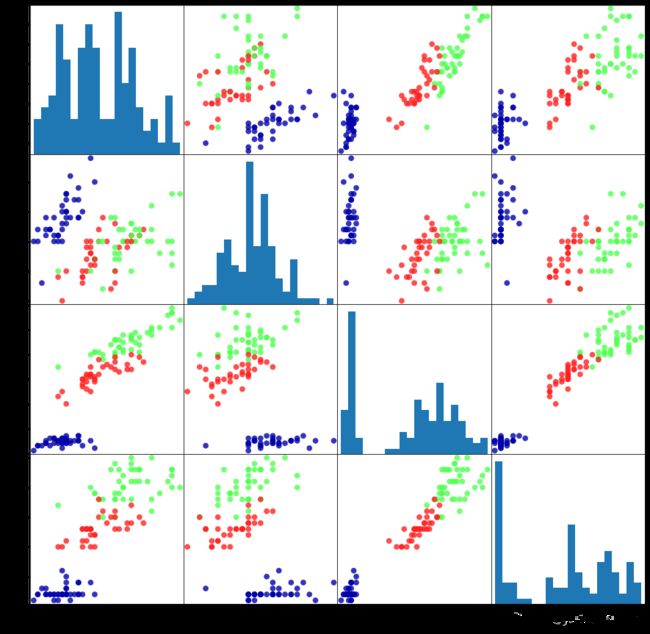
从图中可以观察出,利用花瓣和花萼的数据基本可以将三个类别区分开,这说明机器学习模型很可能可以学会区分它们。
七、k邻近算法
1. 模型构建
选择的是“k邻近分类器”:若要对一个新的数据点做出预测,算法会在训练集中寻找出与这个新数据点距离最近的数据点,然后将找的数据点的标签赋值给这个新数据点。
其中k的含义为:可以考虑训练集这两个与新数据点最近的任意k个邻居(比如,最近的3个或5个),而非只考虑最近的那一个。接着,用这些邻居中数量最多的类别做出预测。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 1) # 此处设置邻居数目为1
这个模型只需要保存训练集即可:
>>> knn.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=1, p=2,
weights='uniform')
2. 进行预测
假设一朵新发现的鸢尾花的数据为:花萼长5cm宽2.9cm;花瓣长1cm宽0.2cm。将数据保存于NumPy数组中:
>>> X_new = np.array([[5,2.9,1,0.2]])
>>> X_new.shape
(1, 4)
进行预测:
>>> prediction = knn.predict(X_new)
>>> print('Prediction:', prediction)
Prediction: [0]
该新数据的预测结果为setosa:
>>> print('Predicted target name:',iris['target_names'][prediction])
Predicted target name: ['setosa']
但我们并不知道是否该去相信这个模型,因此需要对模型的预测准确性进行评估。
3. 模型评估
对测试集的数据进行标签预测:
>>> y_pred = knn.predict(X_test)
>>> print(y_pred)
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]
可以通过计算精度(accuracy)来衡量模型优劣:
>>> np.mean(y_pred == y_test)
0.9736842105263158
or
>>> knn.score(X_test,y_test)
0.9736842105263158
模型准确率达到了97%以上,说明可信度较高。后续还会学习如何提高准确率,以及调参的注意事项。
To be continued…
欢迎继续浏览:第二章监督学习第1、2节