TiDB Online DDL 在 TiCDC 中的应用丨TiDB 工具分享
引言
TiCDC 作为 TiDB 的数据同步组件,负责直接从 TiKV 感知数据变更同步到下游。其中比较核心的问题是数据解析正确性问题,具体而言就是如何使用正确的 schema 解析 TiKV 传递过来的 Key-Value 数据,从而还原成正确的 SQL 或者其他下游支持的形式。本文主要通过对 TiDB Online DDL 机制原理和实现的分析,引出对当前 TiCDC 数据解析实现的讨论。
背景和问题
数据同步组件是数据库生态中不可或缺的生态工具,比较知名的开源单机数据库 MySQL 就将数据同步作为 Server 能力的一部分,并基于 MySQL binlog 实现异步/半同步/同步的主从复制。由于 MySQL 悲观事务模型和表元数据锁的存在,我们总是可以认为 MySQL binlog 中存在因果关系的 data 和 schema 符合时间先后顺序的,即:
New data commitTs > New schema commitTs
但是对于 TiDB 这种存储计算分离的架构而言,schema 的变更在存储层持久化,服务层节点作为多缓存节点,总是存在一个 schema 状态不一致的时间段。为了保证数据一致性和实现在线 DDL 变更,现有的分布式数据库大都采用或者借鉴了 Online, Asynchronous Schema Change in F1 机制。所以我们要回答的问题变成了,在 TiDB Online DDL 机制下,TiCDC 如何正确处理 data 和 schema 的对应关系,存在因果关系的 data 和 schema 是否仍然满足:
New data commitTs > New schema commitTs
为了回答这个问题,我们首先需要先阐述原始的 F1 Online Schema Change 机制的核心原理,然后描述当前 TiDB Online DDL 实现,最后我们讨论在当前 TiCDC 实现下,data 和 schema 的处理关系和可能出现的不同的异常场景。
F1 Online Schema Change 机制
F1 Online Schema Change 机制要解决的核心问题是,在单存储多缓存节点的架构下,如何实现满足数据一致性的 Online Schema 变更,如图 1 所示:

图 1: 单存储多缓存节点的架构下的 schema 变更
这里我们定义数据不一致问题为数据多余(orphan data anomaly)和数据缺失(integrity anomaly),Schema 变更结束后出现数据多余和数据缺失我们就认为数据不一致了。这类系统的 schema 变更问题特点可以总结成以下 3 点:
-
一份 schema 存储,多份 schema 缓存
-
部分 new schema 和 old schema 无法共存
-
直接从 old schema 变更到 new schema 时,总是存在一个时间区间两者同时存在
特点 1 和特点 3 是系统架构导致的,比较容易理解。特点 2 的一个典型例子是 add index,加载了 new schema 的服务层节点插入数据时会同时插入索引,而加载了 old schema 的服务层节点执行删除操作只会删除数据,导致出现了没有指向的索引, 出现数据多余。
Schema 变更问题的特点 2 和特点 3 看起来是互相矛盾的死结,new schema 和 old schema 无法共存,但又必然共存。而 F1 Online Schema 机制提供的解决方案也很巧妙,改变不了结果就改变条件。所以该论文的解决思路上主要有 2 点,如图 2 所示:

图 2: F1 Online DDL 解决方案
1. 引入共存的中间 schema 状态,比如 S1->S2’->S2, S1 和 S2’ 可以共存,S2’ 和 S2 可以共存;
2. 引入确定的隔离时间区间,保证无法共存的 schema 不会同时出现;
具体来讲:
- 引入共存的中间 schema 状态
因为直接从 schema S1 变更到 schema S2 会导致数据不一致的问题,所以引入了 delete-only 和 write-only 中间状态,从 S1 -> S2 过程变成 S1 -> S2+delete-only -> S2+write-only -> S2 过程,同时使用 lease 机制保证同时最多有 2 个状态共存。这时只需要证明每相临的两个状态都是可以共存的,保证数据一致性,就能推导出 S1 到 S2 变更过程中数据是一致的。
- 引入确定的隔离时间区间
定义 schema lease,超过 lease 时长后节点需要重新加载 schema,加载时超过 lease 之后没法获取 new schema 的节点直接下线,不提供服务。所以可以明确定义 2 倍 lease 时间之后,所有节点都会更新到下一个的 schema。
引入共存的中间状态
我们需要引入什么样的中间状态呢?那要看我们需要解决什么问题。这里我们仍然使用 add index 这个 DDL 作为例子,其他 DDL 细节可以查阅 Online, Asynchronous Schema Change in F1 。
Delete-only 状态
我们可以看到 old schema 是无法看到索引信息的,所以会导致出现删除数据,遗留没有指向的索引这种数据多余的异常场景,所以我们要引入的第一个中间状态是 delete-only 状态,赋予 schema 删除索引的能力。在 delete-only 状态下,schema 只能在 delete 操作的时候对索引进行删除,在 insert/select 操作的时候无法操作索引,如图 3 所示:

图 3: 引入 delete-only 中间状态
原始论文对于 delete-only 的定义如下:

假设我们已经引入了明确的隔离时间区间(下一个小节会细讲),能保证同一时刻最多只出现 2 个 schema 状态。所以当我们引入 delete-only 状态之后,需要考虑的场景就变成:
-
old schema + new schema(delete-only)
-
new schema(delete-only) + new schema
-
对于场景 1,所有的服务层节点要么处于 old schema 状态,要么处于 new schema(delete-only) 状态。由于 index 只能在 delete 的时候被操作,所以根本没有 index 生成,就不会出现前面说的遗留没有指向的索引问题,也不会有数据缺失问题,此时数据是一致的。我们可以说 old schema 和 new schema(delete-only) 是可以共存的。
-
对于场景 2,所有的服务层节点要么处于 new schema(delete-only) 状态,要么处于 new schema 状态。处于 new schema 状态的节点可以正常插入删除数据和索引,处于 new schema( delete-only) 状态的节点只能插入数据,但是可以删除数据和索引,此时存在部分数据缺少索引问题,数据是不一致的。
引入 delete-only 状态之后,已经解决了之前提到的索引多余的问题,但是可以发现,处于 new schema( delete-only) 状态的节点只能插入数据,导致新插入的数据和存量历史数据都缺少索引信息,仍然存在数据缺失的数据不一致问题。
Write-only 状态
在场景 2 中我们可以看到,对于 add index 这种场景,处于 new schema( delete-only) 状态节点插入的数据和存量数据都存在索引缺失的问题。而存量数据本身数量是确定且有限的,总可以在有限的时间内根据数据生成索引,但是 new insert 的数据却可能随时间不断增加。为了解决这个数据缺失的问题,我们还需要引入第二个中间状态 write-only 状态,赋予 schema insert/delete 索引的能力。处于 write-only 状态的节点可以 insert/delete/update 索引,但是 select 无法看到索引,如图 4 所示:

图 4: 引入 write-only 状态
原始论文中对于 write-only 状态的定义如下:

引入 write-only 状态之后,上述的场景 2 被切分成了场景 2‘ 和场景 3:
2’: new schema(delete-only) + new schema(write-only)
3: new schema(write-only) + new schema
-
对于场景 2‘,所有的服务层节点要么处于 new schema(delete-only) 状态,要么处于 new schema(write-only) 。处于 new schema(delete-only) 状态的服务层节点只能插入数据,但是可以删除数据和索引,处于 new schema(write-only) 可以正常插入和删除数据和索引。此时仍然存在索引缺失的问题,但是由于 delete-only 和 write-only 状态下,索引对于用户都是不可见的,所以在用户的视角上,只存在完整的数据,不存在任何索引,所以内部的索引缺失对用户而言还是满足数据一致性的。
-
对于场景 3,所有的服务层节点要么处于 new schema(write-only) 状态,要么处于 new schema。此时 new insert 的数据都能正常维护索引,而存量历史数据仍然存在缺失索引的问题。但是存量历史数据是确定且有限的,我们只需要在所有节点过渡到 write-only 之后,进行历史数据索引补全,再过渡到 new schema 状态,就可以保证数据和索引都是完整的。此时处于 write-only 状态的节点只能看到完整的数据,而 new schema 状态的节点能看到完整的数据和索引,所以对于用户而言数据都是一致的。
小节总结
通过上面对 delete-only 和 write-only 这两个中间状态的表述,我们可以看到,在 F1 Online DDL 流程中,原来的单步 schema 变更被两个中间状态分隔开了。每两个状态之间都是可以共存的,每次状态变更都能保证数据一致性,全流程的数据变更也能保证数据一致性。

引入确定的隔离时间区间
为了保证同一时刻最多只能存在 2 种状态,需要约定服务层节点加载 schema 的行为:
-
所有的服务层节点在 lease 之后都需要重新加载 schema;
-
如果在 lease 时间内无法获取 new schema,则下线拒绝服务;
通过对服务层节点加载行为的约定,我们可以得到一个确定的时间边界,在 2*lease 的时间周期之后,所有正常工作的服务层节点都能从 schema state1 过渡到 schema state2, 如图 5 所示:

图 5: 最多 2*lease 时长后所有的节点都能过渡到下一个状态
中间状态可见性
要正确理解原始论文的中间状态,需要正确理解中间状态的可见性问题。前面小节为了方便我们一直使用 add index 作为例子,然后表述 delete-only 和 write-only 状态下索引对于用户 select 是不可见的,但是 write-only 状态下,delete/insert 都是可以操作索引的。如果 DDL 换成 add column,那节点处于 write-only 状态时,用户 insert 显式指定新增列可以执行成功吗?答案是不能。
总得来说,中间状态的 delete/insert 可见性是内部可见性,具体而言是服务层节点对存储层节点的可见性,而不是用户可见性。对于 add column 这个 DDL,服务层节点在 delete-only 和 write-only 状态下就能看到 new column,但是操作受到不同的限制。对用户而言,只有到 new schema 状态下才能看到 new column,才能显式操作 new column,如图 6 所示:

图 6: 中间状态可见性
为了清晰表述可见性,我们举个例子,如图 7 所示。原始的表列信息为 , DDL 操作之后表列信息为


图 7: 中间状态过渡
-
小图 (1) 中,服务层节点已经过渡到了场景 1,部分节点处于 old schema 状态,部分节点处于 new schema(delete-only) 状态。此时 c2 对用户是不可见的,不管是 insert
-
小图 (2) 中,服务层节点已经过渡到了场景 2,部分节点处于 new schema(delete-only) 状态,部分节点处于 new schema(write-only) 状态,此时 c2 对用户仍是不可见的,不管是 insert
-
小图 (3) 中,服务层所有节点都过渡到 write-only 之后,c2 对用户仍是不可见的。此时开始进行数据填充,将历史数据中缺失 c2 的行进行填充(实现时可能只是在表的列信息中打上一个标记,取决于具体的实现)。
-
小图 (4) 中,开始过渡到场景 3,部分节点处于 new schema(write-only) 状态,部分节点处于 new schema 状态。处于 new schema(write-only) 状态的节点,c2 对用户仍是不可见的。处于 new schema 状态的节点,c2 对用户可见。此时连接在不同服务层节点上的用户,可以看到不同的的 select 结果,不过底层的数据是完整且一致的。
总结
上面我们通过 3 个小节对 F1 online Schema 机制进行了简要描述。原来单步 schema 变更被拆解成了多个中间变更流程,从而保证数据一致性的前提下实现了在线 DDL 变更。

对于 add index 或者 add column DDL 是上述的状态变更,对于 drop index 或者 drop column 则是完全相反的过程。比如 drop column 在 write-only 阶段及之后对用户都不可见了,内部可以正确 insert/delete,可见性和之前的论述完全一样。
TiDB Online DDL 实现
TiDB Online DDL 是基于 F1 Online Schema 实现的,整体流程如图 8 所示:
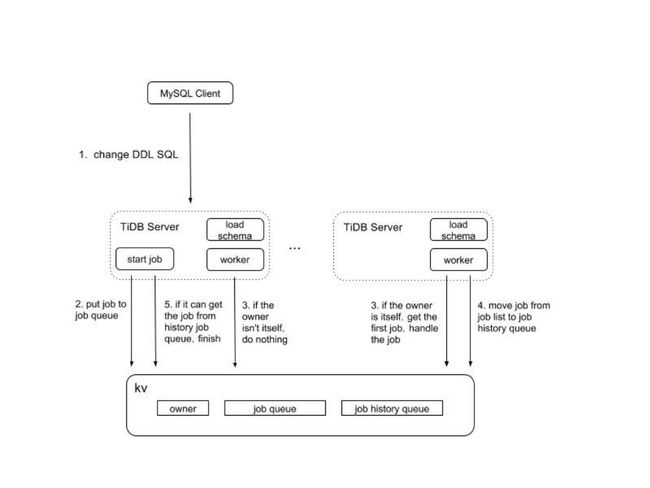
图 8 TiDB Online DDL 流程
简单描述如下:
-
TiDB Server 节点收到 DDL 变更时,将 DDL SQL 包装成 DDL job 提交到 TIKV job queue 中持久化;
-
TiDB Server 节点选举出 Owner 角色,从 TiKV job queue 中获取 DDL job,负责具体执行 DDL 的多阶段变更;
-
DDL 的每个中间状态(delete-only/write-only/write-reorg)都是一次事务提交,持久化到 TiKV job queue 中;
-
Schema 变更成功之后,DDL job state 会变更成 done/sync,表示 new schema 正式被用户看到,其他 job state 比如 cancelled/rollback done 等表示 schema 变更失败;
-
Schema state 的变更过程中使用了 etcd 的订阅通知机制,加快 server 层各节点间 schema state 同步,缩短 2*lease 的变更时间。
-
DDL job 处于 done/sync 状态之后,表示该 DDL 变更已经结束,移动到 job history queue 中;
详细的 TiDB 处理流程可以参见: schema-change-implement.md 和 TiDB ddl.html
TiCDC 中 Data 和 Schema 处理关系
前面我们分别描述了 TiDB Online DDL 机制的原理和实现,现在我们可以回到最一开始我们提出的问题:在 TiDB Online DDL 机制下,是否还能满足:
New data commitTs > New schema commitTs
答案是否定的。在前面 F1 Online Schema 机制的描述中,我们可以看到在 add column DDL 的场景下,当服务层节点处于 write-only 状态时,节点已经能够插入 new column data 了,但是此时 new column 还没有处于用户可见的状态,也就是出现了 New data commitTs < New schema commitTs,或者说上述结论变成了:
New data commitTs > New schema(write-only) commitTs
但是由于在 delete-only + write-only 过渡状态下,TiCDC 直接使用 New schema(write-only) 作为解析的 schema,可能导致 delete-only 节点 insert 的数据无法找到对应的 column 元信息或者元信息类型不匹配,导致数据丢失。所以为了保证数据正确解析,可能需要根据不同的 DDL 类型和具体的 TiDB 内部实现,在内部维护复杂的 schema 策略。
在当前 TiCDC 实现中,选择了比较简单的 schema 策略,直接忽略了各个中间状态,只使用变更完成之后的 schema 状态。为了更好表述在 TIDB Online DDL 机制下,当前 TiCDC 需要处理的不同场景,我们使用象限图进行进一步归类描述。
| Old schema | New schema | |
|---|---|---|
| Old schema data | 1 | 2 |
| New schema data | 3 | 4 |
-
1 对应 old schema 状态
此时 old schema data 和 old schema 是对应的*;*
-
4 对应 new schema public 及之后
此时 new schema data 和 new schema 是对应的;
-
3 对应 write-only ~ public 之间数据
此时 TiCDC 使用 old schema 解析数据,但是处于 write-only 状态的 TiDB 节点已经可以基于 new schema insert/update/delete 部分数据,所以 TiCDC 会收到 new schema data。不同 DDL 处理效果不同,我们选取 3 个常见有代表性的 DDL 举例。
- add column: 状态变更 absent -> delete-only -> write-only -> write-reorg -> public。由于 new schema data 是 TiDB 节点在 write-only 状态下填充的默认值,所以使用 old schema 解析后会被直接丢弃,下游执行 new schema DDL 的时候会再次填充默认值。对于动态生成的数据类型,比如 auto_increment 和 current timestamp,可能会导致上下游数据不一致。
- change column:有损状态变更 absent -> delete-only -> write-only -> write-reorg -> public, 比如 int 转 double,编码方式不同需要数据重做。在 TiDB 实现中,有损 modify column 会生成不可见 new column,中间状态下会同时变更新旧 column。对于 TiCDC 而言,只会处理 old column 下发,然后在下游执行 change column,这个和 TiDB 的处理逻辑保持一致。
- drop column:状态变更 absent-> write-only -> delete-only -> delete-reorg -> public。write-only 状态下新插入的数据已经没有了对应的 column,TiCDC 会填充默认值然后下发到下游,下游执行 drop column 之后会丢弃掉该列。用户可能看到预期外的默认值,但是数据能满足最终一致性。
-
2 对应直接从 old schema -> new schema
说明这类 schema 变更下,old schema 和 new schema 是可以共存的,不需要中间状态,比如 truncate table DDL。TiDB 执行 truncate table 成功后,服务层节点可能还没有加载 new schema,还可以往表中插入数据,这些数据会被 TiCDC 直接根据 tableid 过滤掉,最终上下游都是没有这个表存在的,满足最终一致性。
总结
TiCDC 作为 TiDB 的数据同步组件,数据解析正确性问题是保证上下游数据一致性的核心问题。为了能充分理解 TiCDC 处理 data 和 schema 过程中遇到的各种异常场景,本文首先从 F1 Online Schema Change 原理出发,详细描述在 schema 变更各个阶段的数据行为,然后简单描述了当前 TiDB Online DDL 的实现。最后引出在当前 TiCDC 实现下在 data 和 schema 处理关系上的讨论。