安全面试、笔试、学习知识点大杂烩
参加了场笔试,发现自己太菜太菜了,下边算是“女娲补天”吧
(都是个人理解,有点乱,不喜勿喷)
linux常用命令
ls :显示文件或目录
-l :列出详细信息
mkdir :创建目录
cd :切换目录
cd/ 转移到根目录中
cd~ 转移到/home/user用户目录下
cd/usr 转移到根目录下的usr目录中---绝对路径
cd test转移到当前目录下的test子目录中---相对路径
绝对路径:例如只要看到这个路径:c:/website/img/photo.jpg我们就知道photo.jpg文件是在c盘的website目录下的img子目录中。类似于这样完整的描述文件位置的路径就是绝对路径
相对路径:所谓相对路径,顾名思义就是自己相对与目标的位置。例如形式:img/photo.jpg
例:cd test(进入test目录)
echo :创建带有内容的文件
例:echo niubi > test.text (创建一个test文本,写入niubi)
cat :查看文件内容
例:cat test.text(查看test.text的内容)
cp :拷贝文件
mv:移动或重命名
rm:删除文件夹(删除目录需要加-r,-f强制删除)
cd…:返回上一层目录
find:在文件系统中搜索某文件
grep:在文本文件中查找某个字符串
pwd:显示当前目录
计算机网络相关
一、OSI7层模型(法定标准)
应用层
表示层
会话层 —上边三层属于资源子网用于数据处理
传输层
网络层 —下边三层属于通信子网用于数据通信
数据链路层
物理层

1、应用层
所有能和用户交互产生网络流量的程序,比如qq
2、表示层
用于处理在两个通信系统中交换信息的表示方式
功能1:数据格式变换(翻译官)
功能2:数据加密解密
功能3:数据压缩和恢复
3、会话层
向表示层实体/用户进程提供建立连接并在连接上有序的传输数据
功能1:建立、管理、终止会话
功能2:使用校验点可使会话在通信失效时从校验点/同步点继续恢复通信,实现数据同步(适用于传输大文件)
4、传输层
负责主机中两个进程的通信,即端到端的通信。传输单位是报文段或用户数据报。
功能1:可靠传输(收到确认才继续发)、不可靠传输
功能2:差错控制
功能3:流量控制
功能4:复用分用(复用:多个应用进程可同时使用下面运输层的服务(一起用)分用:运输层把收到的信息分别交付给上边应用层中相应的进程(各找各妈))
5、网络层
主要任务是把分组从源端传到目的端,为分组交换网上的不同主机提供通信服务。网络层传输单位是数据报。(数据报是分组的爹,即数据报可分成好几个分组)
功能1:路由选择
功能2:流量控制
功能3:差错控制
功能4:拥塞控制(全局拥堵)
6、数据链路层
主要任务是把网络层传下来的数据报组装成帧。传输单位是帧。
功能1:成帧
功能2:差错控制
功能3:流量控制
功能4:访问(接入)控制,控制对信道的访问
7、物理层
主要任务是在物理媒体上实现比特流的透明传输。物理层传输单位是比特。
功能1:定义接口特性
功能2:定义传输模式
功能3:定义传输速率
功能4:比特同步
功能5:比特编码
二、4层tcp/ip参考模型(事实标准)
应用层
传输层
网际层
网络接口层

三、五层体系结构


四、三次握手
自己的理解描述:
第一次:客户端发送连接请求到服务端
第二次:服务端收到连接请求后,发送确认信息到客户端(但此时服务端只知道客户端发送能力正常,并不知道客户端接收信息是否正常。如果此请求是由于网络故障滞留的早之前的请求,可能此时客户端已关闭,不能接收)
第三次:客户端发送确认信息到服务端,表明接收信息正常,正式建立连接。
五、四次挥手
自己理解描述:
第一次:客户端发送断开连接请求到服务端。
第二次:服务端发送确认收到请求信息到客户端。(此时可能服务端往客户端发送的信息还没有全部发送完,所以第二次和第三次不能一起)
第三次:服务端发送可以断开信息到客户端。
第四次:客户端发送确认断开信息到服务端,服务端断开连接。(在客户端发送之后需要等待超时时间原因:因为如果第四次发送的包信息丢失,服务端会一直处于等待断开状态,有等待超时时间服务端会重发第三次的包信息,此时客户端就会再次发送信息到服务端)
漏洞相关
一、漏洞扫描工具nmap
1、nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。确定哪些服务运行在哪些连接端,并且推断计算机运行哪个操作系统(这是亦称 fingerprinting)。利用nmap来搜集目标电脑的网络设定,从而计划攻击的方法。Nmap 以隐秘的手法,避开闯入检测系统的监视,并尽可能不影响目标系统的日常操作。
2、基本功能:
(1)探测一组主机是否在线;
(2)扫描 主机端口,嗅探所提供的网络服务;
(3)推断主机所用的操作系统 。
3、操作:
进行ping扫描,打印出对扫描做出响应的主机,不做进一步测试(如端口扫描或者操作系统探测):
nmap -sP 192.168.1.0/24
仅列出指定网络上的每台主机,不发送任何报文到目标主机:
nmap -sL 192.168.1.0/24
探测目标主机开放的端口,可以指定一个以逗号分隔的端口列表(如-PS22,23,25,80):
nmap -PS 192.168.1.234
使用UDP ping探测主机:
nmap -PU 192.168.1.0/24
使用频率最高的扫描选项:SYN扫描,又称为半开放扫描,它不打开一个完全的TCP连接,执行得很快:
SYN扫描是恶意黑客不建立完全连接,用来判断通信端口状态的一种手段。
这种方法是最老的一种攻击手段,有时用来进行拒绝服务攻击。
SYN扫描也称半开放扫描。在SYN扫描中,恶意客户企图跟服务器在每个可能的端口建立TCP/IP连接。
这通过向服务器每个端口发送一个SYN数据包,装作发起一个三方握手来实现。
如果服务器从特定端口返回SYN/ACK(同步应答)数据包,则意味着端口是开放的。
然后,恶意客户程序发送一个RST数据包。
结果,服务器以为存在一个通信错误,以为客户端决定不建立连接。
开放的端口因而保持开放,易于受到攻击。
如果服务器从特定端口返回一个RST数据包,这表示端口是关闭的,不能攻击。
通过向服务器连续发送大量的SYN数据包,黑客能够消耗服务器的资源。
由于服务器被恶意客户的请求所淹没,不能或者只能跟很少合法客户建立通信。
nmap -sS 192.168.1.0/24
当SYN扫描不能用时,TCP Connect()扫描就是默认的TCP扫描:
nmap -sT 192.168.1.0/24
UDP扫描用-sU选项,UDP扫描发送空的(没有数据)UDP报头到每个目标端口:
nmap -sU 192.168.1.0/24
确定目标机支持哪些IP协议 (TCP,ICMP,IGMP等):
nmap -sO 192.168.1.19
探测目标主机的操作系统:
nmap -O 192.168.1.19
nmap -A 192.168.1.19
-p (只扫描指定的端口)
单个端口和用连字符表示的端口范 围(如 1-1023)都可以。当既扫描TCP端口又扫描UDP端口时,可以通过在端口号前加上T: 或者U:指定协议。 协议限定符一直有效直到指定另一个。 例如,参数 -p U:53,111,137,T:21-25,80,139,8080 将扫描UDP 端口53,111,和137,同时扫描列出的TCP端口。
-F (快速 (有限的端口) 扫描)
xss漏洞
1、跨站脚本攻击(XSS),是最普遍的Web应用安全漏洞。这类漏洞能够使得攻击者嵌入恶意脚本代码到正常用户会访问到的页面中,当正常用户访问该页面时,则可导致嵌入的恶意脚本代码的执行,从而达到恶意攻击用户的目的。
2、分类
(1)反射型XSS:<非持久化> 攻击者事先制作好攻击链接, 需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容)
(2)存储型XSS:<持久化> 代码是存储在服务器中的,如在个人信息或发表文章等地方,加入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,每当有用户访问该页面的时候都会触发代码执行
(3)DOM based XSS与前两者完全不同,是纯前端的XSS漏洞,XSS直接通过浏览器进行解析,就完成攻击。
注意:反射型和存储型都是通过后台输出
3、例
反射型的XSS
(1)low等级
当你在用户框输入时会回显

现在输入 看看
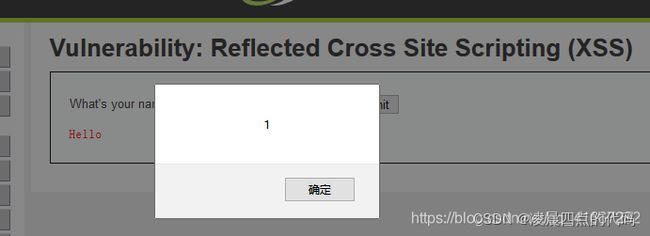
这说明存在XSS漏洞,如何分别时反射型还是存储型漏洞,只要刷新这个页面,观察是否会弹窗就知道了,如果能会弹窗证明是存储型,反之是反射型
(2)medium等级
当你输入,会发现出现下图,这有可能是的页面源码,发现