Windows下Hashcat使用GPU爆破docx密码
1.下载安装最新版HashCat
操作系统是windows10,hashcat版本为6.2.5:

2.安装GPU驱动以及CUDA:

看着多,实际上就是两个安装程序:显卡驱动和CUDA。
这里hashcat对这两个程序的版本有要求:

3.使用office2john将office转换为hash
office2john的代码在这里:
#!/usr/bin/env python
# This software is Copyright (c) 2012-2013 Dhiru Kholia , stream.read(2))[0]
length = unpack(", stream.read(2))[0]
data = stream.read(length)
if type == 0x2f: # FILEPASS
if data[0:2] == b"\x00\x00": # XOR obfuscation
sys.stderr.write("%s : XOR obfuscation detected, key : %s, hash : %s\n" % \
(filename, binascii.hexlify(data[2:4]), binascii.hexlify(data[4:6])))
elif data[0:6] == b'\x01\x00\x01\x00\x01\x00':
# RC4 encryption header structure
data = data[6:]
salt = data[:16]
verifier = data[16:32]
verifierHash = data[32:48]
return (salt, verifier, verifierHash)
elif data[0:4] == b'\x01\x00\x02\x00' or data[0:4] == b'\x01\x00\x03\x00':
# If RC4 CryptoAPI encryption is used, certain storages and streams are stored in Encryption Stream
stm = StringIO(data)
stm.read(2) # unused
# RC4 CryptoAPI Encryption Header
unpack(", stm.read(2))[0] # major_version
unpack(", stm.read(2))[0] # minor_version
unpack(", stm.read(4))[0] # encryptionFlags
headerLength = unpack(", stm.read(4))[0]
unpack(", stm.read(4))[0] # skipFlags
headerLength -= 4
unpack(", stm.read(4))[0] # sizeExtra
headerLength -= 4
unpack(", stm.read(4))[0] # algId
headerLength -= 4
unpack(", stm.read(4))[0] # algHashId
headerLength -= 4
keySize = unpack(", stm.read(4))[0]
if keySize == 40:
typ = 3
else:
typ = 4
headerLength -= 4
unpack(", stm.read(4))[0] # providerType
headerLength -= 4
unpack(", stm.read(4))[0] # unused
headerLength -= 4
unpack(", stm.read(4))[0] # unused
headerLength -= 4
CSPName = stm.read(headerLength)
provider = CSPName.decode('utf-16').lower()
# Encryption verifier
saltSize = unpack(", stm.read(4))[0]
assert(saltSize == 16)
salt = stm.read(saltSize)
encryptedVerifier = stm.read(16)
verifierHashSize = unpack(", stm.read(4))[0]
assert(verifierHashSize == 20)
encryptedVerifierHash = stm.read(verifierHashSize)
sys.stdout.write("%s:$oldoffice$%s*%s*%s*%s\n" % (os.path.basename(filename),
typ, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(encryptedVerifier).decode("ascii"),
binascii.hexlify(encryptedVerifierHash).decode("ascii")))
return None
def find_doc_type(filename, stream):
w_ident = stream.read(2)
assert(w_ident == b"\xec\xa5")
stream.read(9) # unused
flags = ord(stream.read(1))
if (flags & 1) != 0:
F = 1
else:
F = 0
if (flags & 128) != 0:
M = 1
else:
M = 0
if F == 1 and M == 1:
stream.read(2) # unused
i_key = stream.read(4)
sys.stderr.write("%s : XOR obfuscation detected, Password Verifier : %s\n" % \
(filename, binascii.hexlify(i_key)))
return True
if F == 0:
sys.stderr.write("%s : Document is not encrypted!\n" % (filename))
return True
def find_ppt_type(filename, stream):
# read CurrentUserRec's RecordHeader
stream.read(2) # unused
unpack(", stream.read(2))[0] # recType
unpack(", stream.read(4))[0] # recLen
# read rest of CurrentUserRec
unpack(", stream.read(4))[0] # size
unpack(", stream.read(4))[0] # headerToken
offsetToCurrentEdit = unpack(", stream.read(4))[0]
return offsetToCurrentEdit
def find_rc4_passinfo_doc(filename, stream):
major_version = unpack(", stream.read(2))[0]
minor_version = unpack(", stream.read(2))[0]
if major_version == 1 or minor_version == 1:
data = stream.read(48)
salt = data[:16]
verifier = data[16:32]
verifierHash = data[32:48]
return (salt, verifier, verifierHash)
elif major_version >= 2 and minor_version == 2:
# RC4 CryptoAPI Encryption Header
unpack(", stream.read(4))[0] # encryptionFlags
headerLength = unpack(", stream.read(4))[0]
unpack(", stream.read(4))[0] # skipFlags
headerLength -= 4
unpack(", stream.read(4))[0] # sizeExtra
headerLength -= 4
unpack(", stream.read(4))[0] # algId
headerLength -= 4
unpack(", stream.read(4))[0] # algHashId
headerLength -= 4
keySize = unpack(", stream.read(4))[0] # keySize
headerLength -= 4
unpack(", stream.read(4))[0] # providerType
headerLength -= 4
unpack(", stream.read(4))[0] # unused
headerLength -= 4
unpack(", stream.read(4))[0] # unused
headerLength -= 4
CSPName = stream.read(headerLength)
provider = CSPName.decode('utf-16').lower()
if keySize == 128:
typ = 4
elif keySize == 40:
typ = 3
else:
sys.stderr.write("%s : invalid keySize\n" % filename)
# Encryption verifier
saltSize = unpack(", stream.read(4))[0]
assert(saltSize == 16)
salt = stream.read(saltSize)
encryptedVerifier = stream.read(16)
verifierHashSize = unpack(", stream.read(4))[0]
assert(verifierHashSize == 20)
encryptedVerifierHash = stream.read(verifierHashSize)
if not have_summary:
sys.stdout.write("%s:$oldoffice$%s*%s*%s*%s\n" % (os.path.basename(filename),
typ, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(encryptedVerifier).decode("ascii"),
binascii.hexlify(encryptedVerifierHash).decode("ascii")))
else:
sys.stdout.write("%s:$oldoffice$%s*%s*%s*%s:::%s::%s\n" % (os.path.basename(filename),
# this code was developed while listening to The Wedding Present "Sea Monsters"
typ, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(encryptedVerifier).decode("ascii"),
binascii.hexlify(encryptedVerifierHash).decode("ascii"), summary, filename))
else:
sys.stderr.write("%s : Cannot find RC4 pass info, is document encrypted?\n" % filename)
def find_rc4_passinfo_ppt(filename, stream, offset):
stream.read(offset) # unused
# read UserEditAtom's RecordHeader
stream.read(2) # unused
recType = unpack(", stream.read(2))[0]
recLen = unpack(", stream.read(4))[0]
if recLen != 32:
sys.stderr.write("%s : Document is not encrypted!\n" % (filename))
return
if recType != 0x0FF5:
sys.stderr.write("%s : Document is corrupt!\n" % (filename))
return
# read reset of UserEditAtom
unpack(", stream.read(4))[0] # lastSlideRef
unpack(", stream.read(2))[0] # version
ord(stream.read(1)) # minorVersion
ord(stream.read(1)) # majorVersion
unpack(", stream.read(4))[0] # offsetLastEdit
offsetPersistDirectory = unpack(", stream.read(4))[0]
unpack(", stream.read(4))[0] # docPersistIdRef
unpack(", stream.read(4))[0] # persistIdSeed
unpack(", stream.read(2))[0] # lastView
unpack(", stream.read(2))[0] # unused
encryptSessionPersistIdRef = unpack(", stream.read(2))[0]
# if( offset.LowPart < userAtom.offsetPersistDirectory ||
# userAtom.offsetPersistDirectory < userAtom.offsetLastEdit )
# goto CorruptFile;
# jump and read RecordHeader
stream.seek(offsetPersistDirectory, 0)
stream.read(2) # unused
recType = unpack(", stream.read(2))[0]
recLen = unpack(", stream.read(4))[0]
# BUGGY: PersistDirectoryAtom and PersistDirectoryEntry processing
i = 0
stream.read(4) # unused
while i < encryptSessionPersistIdRef:
i += 1
persistOffset = unpack(", stream.read(4))[0]
# print persistOffset
# go to the offset of encryption header
stream.seek(persistOffset, 0)
# read RecordHeader
stream.read(2) # unused
recType = unpack(", stream.read(2))[0]
recLen = unpack(", stream.read(4))[0]
major_version = unpack(", stream.read(2))[0]
minor_version = unpack(", stream.read(2))[0]
if major_version >= 2 and minor_version == 2:
# RC4 CryptoAPI Encryption Header
unpack(", stream.read(4))[0] # encryptionFlags
headerLength = unpack(", stream.read(4))[0]
unpack(", stream.read(4))[0] # skipFlags
headerLength -= 4
unpack(", stream.read(4))[0] # sizeExtra
headerLength -= 4
unpack(", stream.read(4))[0] # algId
headerLength -= 4
unpack(", stream.read(4))[0] # algHashId
headerLength -= 4
unpack(", stream.read(4))[0] # keySize
headerLength -= 4
unpack(", stream.read(4))[0] # providerType
headerLength -= 4
unpack(", stream.read(4))[0]
headerLength -= 4
unpack(", stream.read(4))[0]
headerLength -= 4
CSPName = stream.read(headerLength)
provider = CSPName.decode('utf-16').lower()
if "strong" in provider:
typ = 4
else:
typ = 3
# Encryption verifier
saltSize = unpack(", stream.read(4))[0]
assert(saltSize == 16)
salt = stream.read(saltSize)
encryptedVerifier = stream.read(16)
verifierHashSize = unpack(", stream.read(4))[0]
assert(verifierHashSize == 20)
encryptedVerifierHash = stream.read(verifierHashSize)
sys.stdout.write("%s:$oldoffice$%s*%s*%s*%s\n" % (os.path.basename(filename),
typ, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(encryptedVerifier).decode("ascii"),
binascii.hexlify(encryptedVerifierHash).decode("ascii")))
else:
sys.stderr.write("%s : Cannot find RC4 pass info, is document encrypted?\n" % filename)
from xml.etree.ElementTree import ElementTree
import base64
def process_new_office(filename):
# detect version of new Office used by reading "EncryptionInfo" stream
ole = OleFileIO(filename)
stream = ole.openstream("EncryptionInfo")
major_version = unpack(", stream.read(2))[0]
minor_version = unpack(", stream.read(2))[0]
encryptionFlags = unpack(", stream.read(4))[0] # encryptionFlags
if encryptionFlags == 16: # fExternal
sys.stderr.write("%s : An external cryptographic provider is not supported!\n" % filename)
return -1
if major_version == 0x04 and minor_version == 0x04:
# Office 2010 and 2013 file detected
if encryptionFlags != 0x40: # fAgile
sys.stderr.write("%s : The encryption flags are not consistent with the encryption type\n" % filename)
return -2
# rest of the data is in XML format
data = StringIO(stream.read())
tree = ElementTree()
tree.parse(data)
for node in tree.getiterator('{http://schemas.microsoft.com/office/2006/keyEncryptor/password}encryptedKey'):
spinCount = node.attrib.get("spinCount")
assert(spinCount)
saltSize = node.attrib.get("saltSize")
assert(saltSize)
blockSize = node.attrib.get("blockSize")
assert(blockSize)
keyBits = node.attrib.get("keyBits")
hashAlgorithm = node.attrib.get("hashAlgorithm")
if hashAlgorithm == "SHA1":
version = 2010
elif hashAlgorithm == "SHA512":
version = 2013
else:
sys.stderr.write("%s uses un-supported hashing algorithm %s, please file a bug! \n" \
% (filename, hashAlgorithm))
return -3
cipherAlgorithm = node.attrib.get("cipherAlgorithm")
if not cipherAlgorithm.find("AES") > -1:
sys.stderr.write("%s uses un-supported cipher algorithm %s, please file a bug! \n" \
% (filename, cipherAlgorithm))
return -4
saltValue = node.attrib.get("saltValue")
assert(saltValue)
encryptedVerifierHashInput = node.attrib.get("encryptedVerifierHashInput")
encryptedVerifierHashValue = node.attrib.get("encryptedVerifierHashValue")
encryptedVerifierHashValue = binascii.hexlify(base64.decodestring(encryptedVerifierHashValue.encode()))
sys.stdout.write("%s:$office$*%d*%d*%d*%d*%s*%s*%s\n" % \
(os.path.basename(filename), version,
int(spinCount), int(keyBits), int(saltSize),
binascii.hexlify(base64.decodestring(saltValue.encode())).decode("ascii"),
binascii.hexlify(base64.decodestring(encryptedVerifierHashInput.encode())).decode("ascii"),
encryptedVerifierHashValue[0:64].decode("ascii")))
return 0
else:
# Office 2007 file detected, process CryptoAPI Encryption Header
stm = stream
headerLength = unpack(", stm.read(4))[0]
unpack(", stm.read(4))[0] # skipFlags
headerLength -= 4
unpack(", stm.read(4))[0] # sizeExtra
headerLength -= 4
unpack(", stm.read(4))[0] # algId
headerLength -= 4
unpack(", stm.read(4))[0] # algHashId
headerLength -= 4
keySize = unpack(", stm.read(4))[0]
headerLength -= 4
unpack(", stm.read(4))[0] # providerType
headerLength -= 4
unpack(", stm.read(4))[0] # unused
headerLength -= 4
unpack(", stm.read(4))[0] # unused
headerLength -= 4
CSPName = stm.read(headerLength)
provider = CSPName.decode('utf-16').lower()
# Encryption verifier
saltSize = unpack(", stm.read(4))[0]
assert(saltSize == 16)
salt = stm.read(saltSize)
encryptedVerifier = stm.read(16)
verifierHashSize = unpack(", stm.read(4))[0]
encryptedVerifierHash = stm.read(verifierHashSize)
sys.stdout.write("%s:$office$*%d*%d*%d*%d*%s*%s*%s\n" % \
(os.path.basename(filename), 2007, verifierHashSize,
keySize, saltSize, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(encryptedVerifier).decode("ascii"),
binascii.hexlify(encryptedVerifierHash)[0:64].decode("ascii")))
def xml_metadata_parser(data, filename):
# Assuming Office 2010 and 2013 file
data = StringIO(data)
tree = ElementTree()
tree.parse(data)
for node in tree.getiterator('{http://schemas.microsoft.com/office/2006/keyEncryptor/password}encryptedKey'):
spinCount = node.attrib.get("spinCount")
assert(spinCount)
saltSize = node.attrib.get("saltSize")
assert(saltSize)
blockSize = node.attrib.get("blockSize")
assert(blockSize)
keyBits = node.attrib.get("keyBits")
hashAlgorithm = node.attrib.get("hashAlgorithm")
if hashAlgorithm == "SHA1":
version = 2010
elif hashAlgorithm == "SHA512":
version = 2013
else:
sys.stderr.write("%s uses un-supported hashing algorithm %s, please file a bug! \n" \
% (filename, hashAlgorithm))
return -3
cipherAlgorithm = node.attrib.get("cipherAlgorithm")
if not cipherAlgorithm.find("AES") > -1:
sys.stderr.write("%s uses un-supported cipher algorithm %s, please file a bug! \n" \
% (filename, cipherAlgorithm))
return -4
saltValue = node.attrib.get("saltValue")
assert(saltValue)
encryptedVerifierHashInput = node.attrib.get("encryptedVerifierHashInput")
encryptedVerifierHashValue = node.attrib.get("encryptedVerifierHashValue")
encryptedVerifierHashValue = binascii.hexlify(base64.decodestring(encryptedVerifierHashValue.encode()))
sys.stdout.write("%s:$office$*%d*%d*%d*%d*%s*%s*%s\n" % \
(os.path.basename(filename), version,
int(spinCount), int(keyBits), int(saltSize),
binascii.hexlify(base64.decodestring(saltValue.encode())).decode("ascii"),
binascii.hexlify(base64.decodestring(encryptedVerifierHashInput.encode())).decode("ascii"),
encryptedVerifierHashValue[0:64].decode("ascii")))
return 0
have_summary = False
summary = []
import re
def remove_html_tags(data):
p = re.compile(r'<.*?>', re.DOTALL)
return p.sub('', str(data))
def remove_extra_spaces(data):
p = re.compile(r'\s+')
return p.sub(' ', data)
def process_file(filename):
# Test if a file is an OLE container:
try:
f = open(filename, "rb")
data = f.read(81920) # is this enough?
if data[0:2] == b"PK":
sys.stderr.write("%s : zip container found, file is " \
"unencrypted?, invalid OLE file!\n" % filename)
f.close()
return 1
f.close()
# ACCDB handling hack for MS Access >= 2007 (Office 12)
accdb_magic = "Standard ACE DB"
accdb_xml_start = '
accdb_xml_trailer = ''
if accdb_magic in data and accdb_xml_start in data:
# find start and the end of the XML metadata stream
start = data.find(accdb_xml_start)
trailer = data.find(accdb_xml_trailer)
xml_metadata_parser(data[start:trailer+len(accdb_xml_trailer)], filename)
return
if not isOleFile(filename):
sys.stderr.write("%s : Invalid OLE file\n" % filename)
return 1
except Exception:
e = sys.exc_info()[1]
import traceback
traceback.print_exc()
sys.stderr.write("%s : OLE check failed, %s\n" % (filename, str(e)))
return 2
# Open OLE file:
ole = OleFileIO(filename)
stream = None
# find "summary" streams
global have_summary, summary
have_summary = False
summary = []
for streamname in ole.listdir():
streamname = streamname[-1]
if streamname[0] == "\005":
have_summary = True
props = ole.getproperties(streamname)
for k, v in props.items():
if v is None:
continue
if not PY3:
if not isinstance(v, unicode): # We are only interested in strings
continue
else:
if not isinstance(v, str): # We are only interested in strings
continue
v = remove_html_tags(v)
v = v.replace(":", "")
v = remove_extra_spaces(v)
#words = v.split()
#words = filter(lambda x: len(x) < 20, words)
#v = " ".join(words)
summary.append(v)
summary = " ".join(summary)
summary = remove_extra_spaces(summary)
if ["EncryptionInfo"] in ole.listdir():
# process Office 2003 / 2010 / 2013 files
return process_new_office(filename)
if ["Workbook"] in ole.listdir():
stream = "Workbook"
elif ["WordDocument"] in ole.listdir():
stream = "1Table"
elif ["PowerPoint Document"] in ole.listdir():
stream = "Current User"
else:
sys.stderr.write("%s : No supported streams found\n" % filename)
return 2
try:
workbookStream = ole.openstream(stream)
except:
import traceback
traceback.print_exc()
sys.stderr.write("%s : stream %s not found!\n" % (filename, stream))
return 2
if workbookStream is None:
sys.stderr.write("%s : Error opening stream, %s\n" % filename)
(filename, stream)
return 3
if stream == "Workbook":
typ = 0
passinfo = find_rc4_passinfo_xls(filename, workbookStream)
if passinfo is None:
return 4
elif stream == "1Table":
typ = 1
sdoc = ole.openstream("WordDocument")
ret = find_doc_type(filename, sdoc)
if not ret:
passinfo = find_rc4_passinfo_doc(filename, workbookStream)
if passinfo is None:
return 4
else:
return 5
else:
sppt = ole.openstream("Current User")
offset = find_ppt_type(filename, sppt)
sppt = ole.openstream("PowerPoint Document")
find_rc4_passinfo_ppt(filename, sppt, offset)
return 6
(salt, verifier, verifierHash) = passinfo
if not have_summary:
sys.stdout.write("%s:$oldoffice$%s*%s*%s*%s\n" % (os.path.basename(filename),
typ, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(verifier).decode("ascii"),
binascii.hexlify(verifierHash).decode("ascii")))
else:
sys.stdout.write("%s:$oldoffice$%s*%s*%s*%s:::%s::%s\n" % (os.path.basename(filename),
typ, binascii.hexlify(salt).decode("ascii"),
binascii.hexlify(verifier).decode("ascii"),
binascii.hexlify(verifierHash).decode("ascii"),
summary, filename))
workbookStream.close()
ole.close()
return 0
if __name__ == "__main__":
if len(sys.argv) < 2:
sys.stderr.write("Usage: %s \n" % sys.argv[0])
sys.exit(1)
#set_debug_mode(1)
for i in range(1, len(sys.argv)):
if not PY3:
ret = process_file(sys.argv[i].decode("utf8"))
else:
ret = process_file(sys.argv[i])
这里我是用linux来做的
![]()
4.将得到的hash转换成hashcat支持的形式
awk -F “:” ‘{print $2}’ hash.txt > hashhc.txt
![]()
5.爆破
hashcat -m 9500 hashhc.txt -a 3 ?b?b?b?b?b -w 3 -o out.txt
这里-m意为选择哈希的类型,见下表:

-w 选择掩码模式,hashcat内置有字符集,可以在这些字符集基础上使用–custom-charset再进行自定义:
-m 指定哈希类型
-a 指定破解模式
-V 查看版本信息
-o 将输出结果储存到指定文件
--force 忽略警告
--show 仅显示破解的hash密码和对应的明文
--remove 从源文件中删除破解成功的hash
--username 忽略hash表中的用户名
-b 测试计算机破解速度和相关硬件信息
-O 限制密码长度
-T 设置线程数
-r 使用规则文件
-1 自定义字符集 -1 0123asd ?1={0123asd}
-2 自定义字符集 -2 0123asd ?2={0123asd}
-3 自定义字符集 -3 0123asd ?3={0123asd}
-i 启用增量破解模式
--increment-min 设置密码最小长度
--increment-max 设置密码最大长度
hashcat破解模式介绍
0 straight 字典破解
1 combination 将字典中密码进行组合(1 2>11 22 12 21)
3 brute-force 使用指定掩码破解
6 Hybrid Wordlist + Mask 字典+掩码破解
7 Hybrid Mask + Wordlist 掩码+字典破解
?l = abcdefghijklmnopqrstuvwxyz 代表小写字母
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ 代表大写字母
?d = 0123456789 代表数字
?s = !”#$%&’()*+,-./:;<=>?@[\]^_`{|}~ 代表特殊字符
?a = ?l?u?d?s 大小写数字及特殊字符的组合
?b = 0×00 – 0xff
所以命令还可以这样写:
hashcat.exe -m 9600 old.txt --custom-charset1 ?d?l -a3 ?1?1?1?1?1?1 -w 3 -o out.txt -O
-O是指使用优化的内核以加快速度。
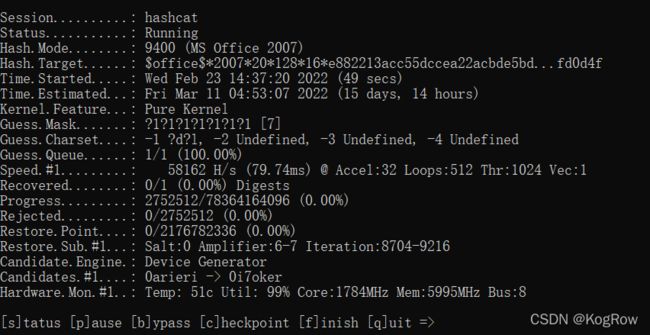
能不能爆破得到密码就看运气以及人品了。
此外HashCat还支持分布式破解,但是分布式我没有研究,因为没钱买显卡