利用python爬虫技术获取每天每场的每位球员NBA数据以及每日范特西评分
想法来源:虎扑体育app中有个游戏叫做“每日范特西”,此游戏给于NBA每位球员一个与他能力(数据)相符的身价,玩家的任务是给定金额120,根据每位球员的身价以及位置组建一个自己的阵容(阵容总价不能大于120),之后根据当天每位球员的数据表现,来得出当天的真实评分。每位玩家的任务就是组建一套120以下的阵容,以达到阵容的真实评分最大值。真实评分公式如下:

使用工具:最近接触了python比较多,也算是重拾了1年多前的知识,主要是利用了bs4模版。
实现目标:把NBA每天比赛的球员数据按文件夹放在本地,并计算出他的范特西球员评分。
步骤:
- 抓取的NBA数据来源于http://sports.yahoo.com/nba/scoreboard/ 这个网站,网址后面加入日期,就是为当天的比赛场次信息,如(http://sports.yahoo.com/nba/scoreboard/?dateRange=2017-02-27)
- 利用requests.get函数得到网址的html代码,再利用bs4对代码进行解析。
data = requests.get(allurl)
bsdata = BeautifulSoup(data.text, 'lxml')`3.之后在浏览器中对原网址按下F12,得到当天的每场的子网页,如图:
可知整个比赛场次的板块是在class名为’Mb(0px)’的div标签下,之后在此标签下找到所有a标签,因为超链接和文本都存在a标签中。
game_list = bsdata.find('ul', class_='Mb(0px)').find_all('a')4.得到game_list后,对每个a标签里的内容进行筛选,因为里面的a标签还可能是回放的链接:
for game in gamelist:
tarurl = game['href']
if tarurl.find('/nba') == -1:
gamelist.remove(game)5.筛选之后,得到场次的链接和标题,之后再利用requests和bs4,对每场的链接进行同样的方法,之后再对所要的数据进行分析:
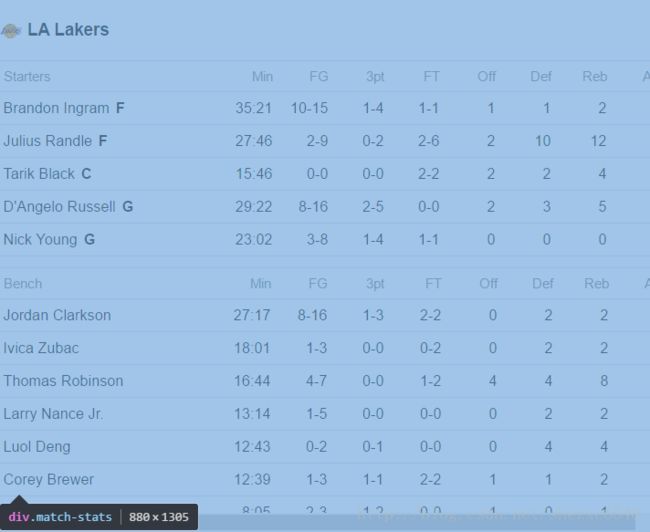
为class名为match-stats的div标签下
6.之后我分析出名字是位于a标签下的文本中(因为球员是可以再点进去一个链接为该球员的详细资料),其他数据是位于td标签下。但是a标签包含的是所有出现的球员名字,td标签是包含了出现了所有数据(包含了球队数据),因此为了完全对应,需要对数据进行处理:
player_name = bsdata.find('div', class_='match-stats').find_all('a')
player_stat = bsdata.find('div', class_='match-stats').find_all('td')
stat_list = ['Min','FG','3pt','FT','Off','Def','Reb','Ast','TO','Stl','Blk','PF','+/-','Pts']
with open(title+".txt",'w') as nbawrite:
count = 0
for p in player_name:
if(player_stat[count].get_text()==''):#对应的是球队数据,删去
count=count+20
if(count>=len(player_stat)):#数据已经读完了,但是之后还有球员名字,应该忽略退出
break
nbawrite.write('Name: '+ p.get_text()+'\n')
nba_list=[]
for i in range(0,14):
nba_list.append(str(player_stat[count].get_text()))
nbawrite.write(stat_list[i]+': '+str(player_stat[count].get_text())+'\n')
count=count+1
nbawrite.write('评分:')
nbawrite.write(str(getfantasy(nba_list)))
nbawrite.write('\n\n')7.得到数据之后就可以加入范特西评分函数,这里就不赘述了。
8.对这些数据建立相对应当天的文件夹,以及对每场再建立一个txt文本。
9.为了可以直接抓到当天的数据,不用手动输入日期,可以利用datetime函数,得到当天时间作为参数传入进去。
效果截图如下:



完整代码如下:
# -*- coding: utf-8 -*-
import requests
import datetime
from bs4 import BeautifulSoup
import os
def getDate(date):
baseurl = "http://sports.yahoo.com/nba/scoreboard/?dateRange="
allurl = baseurl+date
try:
data = requests.get(allurl)
bsdata = BeautifulSoup(data.text, 'lxml')
if os.path.exists(os.path.join("D:\\nba",date)) is not True:
os.makedirs(os.path.join("D:\\nba", date))
os.chdir(os.path.join("D:\\nba", date))
game_list = bsdata.find('ul', class_='Mb(0px)').find_all('a')
return game_list
except:
print(u'网络错误')
def getfantasy(stat_list):
if(stat_list[0]=='-'):
return 0
else:
total = 0.0
FG = stat_list[1]
number = FG.find('-')
FG_succ = FG[:number]
total += int(FG_succ)*0.4
FG_miss = int(FG[number+1:]) - int(FG_succ)
total += FG_miss*(-1)
threept = stat_list[2]
number = threept.find('-')
three_suc = threept[:number]
total += int(three_suc)*0.5
total += int(stat_list[4])
total += int(stat_list[5])*0.7
total += int(stat_list[7])*1.5
total += int(stat_list[8])*(-1)
total += int(stat_list[9])*(2)
total += int(stat_list[10])*1.8
total += int(stat_list[13])*1
return round(total,1)
def handle_single(gamelist):
for game in gamelist:
tarurl = game['href']
if tarurl.find('/nba') == -1:
gamelist.remove(game)
for game in gamelist:
title = game.get_text()
baseurl = "http://sports.yahoo.com"
atturl = game['href']
print(str(atturl))
data = requests.get(baseurl+atturl)
bsdata = BeautifulSoup(data.text, 'lxml')
player_name = bsdata.find('div', class_='match-stats').find_all('a')
player_stat = bsdata.find('div', class_='match-stats').find_all('td')
stat_list = ['Min','FG','3pt','FT','Off','Def','Reb','Ast','TO','Stl','Blk','PF','+/-','Pts']
with open(title+".txt",'w') as nbawrite:
count = 0
for p in player_name:
if(player_stat[count].get_text()==''):#对应的是球队数据,删去
count=count+20
if(count>=len(player_stat)):#数据已经读完了,但是之后还有球员名字,应该忽略退出
break
nbawrite.write('Name: '+ p.get_text()+'\n')
nba_list=[]
for i in range(0,14):
nba_list.append(str(player_stat[count].get_text()))
nbawrite.write(stat_list[i]+': '+str(player_stat[count].get_text())+'\n')
count=count+1
nbawrite.write('评分:')
nbawrite.write(str(getfantasy(nba_list)))
nbawrite.write('\n\n')
print(u'抓取成功')
i = datetime.datetime.now()
today = str(i)[:10]
print(u'今天是%s,将抓取今天的NBA信息'%(today))
game = getDate(today)
handle_single(game)