第8章 生成式深度学习
生成模型根据一些规则y,来生成新样本x。本章主要介绍常用的两种:变分自动编码器(VAE)和 生成式对抗网络(GAN)及其变种。GAN是基于博弈论,目的是找到达到纳什均衡的判别器网络和生成器网络。而VAE基本根植贝叶斯推理,其目标是潜在地建模,从模型中采样新的数据。
8.1 用变分自编码器生成图像
8.1.1 自编码器
自编码器是通过对输入X进行编码后得到一个低维的向量z,然后根据 这个向量还原出输入X。通过对比X与![]() 的误差,再利用神经网络去训练使得误差逐渐减小,从而达到非监督学习的目的。图8-1为自编码器的架构图。
的误差,再利用神经网络去训练使得误差逐渐减小,从而达到非监督学习的目的。图8-1为自编码器的架构图。
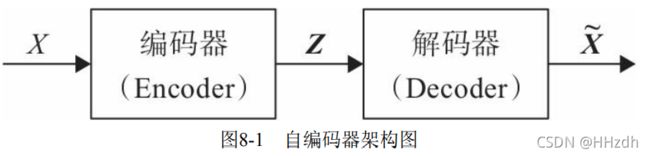
自编码器因不能随意产生合理的潜在变量,从而导致它无法产生新的内容。因为潜在变量Z都是编码器从原始图片中产生的。为解决这一问题,研 究人员对潜在空间Z(潜在变量对应的空间)增加一些约束,使Z满足正态分布,由此就出现了VAE模型,VAE对编码器添加约束,就是强迫它产生服从单位正态分布的潜在变量。正是这种约束,把VAE和自编码器区分开来。
8.1.2 变分自编码器
变分自编码器关键一点就是增加一个对潜在空间Z的正态分布约束。那么如何确定u、σ?用神经网络去拟合。
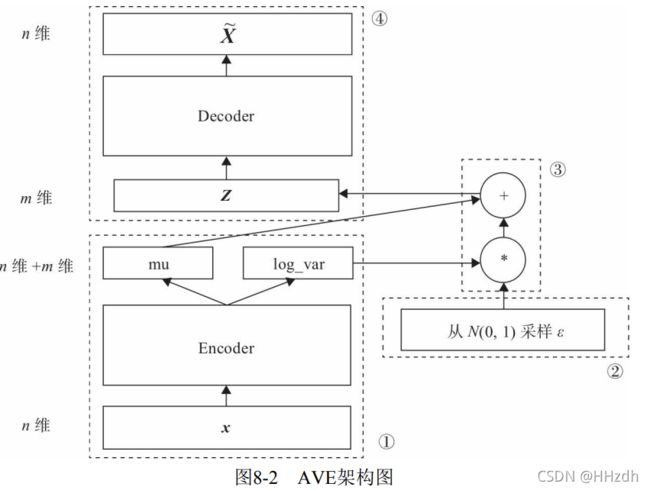
在图8-2中,模块①的功能把输入样本X通过编码器输出两个m维向量 (mu、log_var),这两个向量是潜在空间(假设满足正态分布)的两个参数(相当于均值和方差)。那么如何从这个潜在空间采用一个点Z?这里假设潜在正态分布能生成输入图像,从标准正态分布N(0,I)中采样一个ε(模块②的功能),然后使![]() ,这也是模块③的主要功能。Z是从潜在空间抽取的一个向量,Z通过解码器生成一个样本
,这也是模块③的主要功能。Z是从潜在空间抽取的一个向量,Z通过解码器生成一个样本![]() ,这是 模块④的功能。
,这是 模块④的功能。
这里ε是随机采样的,这就可保证潜在空间的连续性、良好的结构性。 而这些特性使得潜在空间的每个方向都表示数据中有意义的变化方向。 以上这些步骤构成整个网络的前向传播过程,那反向传播应如何进行? 要确定反向传播就会涉及损失函数,损失函数是衡量模型优劣的主要指标。 这里我们需要从以下两个方面进行衡量。
- 生成的新图像与原图像的相似度;
- 隐含空间的分布与正态分布的相似度。
度量图像的相似度一般采用交叉熵(如nn.BCELoss),度量两个分布的相似度一般采用KL散度(Kullback-Leibler divergence)。这两个度量的和构成了整个模型的损失函数。
8.1.3 用变分自编码器生成图像
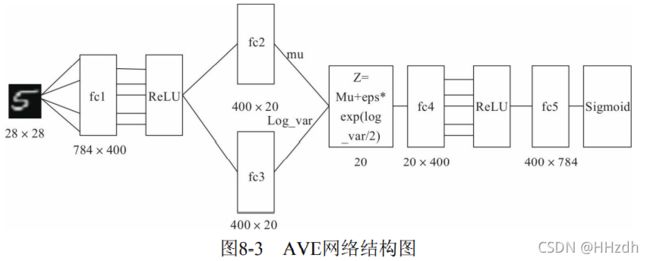
(1)导入必要的包。
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import cv2
import matplotlib.pyplot as plt
#在当前目录,创建不存在的目录ave_samples
sample_dir = 'ave_samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)(2)定义一些超参数。
# 定义一些超参数
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 30
batch_size = 128
learning_rate = 0.001(3)对数据集进行预处理,如转换为Tensor,把数据集转换为循环、可批量加载的数据集。
# 下载MNIST训练集
dataset = torchvision.datasets.MNIST(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
#数据加载
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)(4)构建AVE模型,主要由Encode和Decode两部分组成。
# 定义AVE模型
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc2(h), self.fc3(h)
# 用mu,log_var生成一个潜在空间点z,mu,log_var为两个统计参数,我们假设
# 这个假设分布能生成图像。
def reparameterize(self, mu, log_var):
std = torch.exp(log_var/2)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h))
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
x_reconst = self.decode(z)
return x_reconst, mu, log_var(5)选择GPU及优化器。
# 设置PyTorch在哪块GPU上运行,这里假设使用序号为0的这块GPU.
torch.cuda.set_device(0)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
(6)训练模型,同时保存原图像与随机生成的图像。
#开始训练模型
for epoch in range(num_epochs):
model.train()
for i, (x, _) in enumerate(data_loader):
# 前向传播
model.zero_grad()
x = x.to(device).view(-1, image_size)
x_reconst, mu, log_var = model(x)
# Compute reconstruction loss and kl divergence
# For KL divergence, see Appendix B in VAE paper or http://yunjey47.tistory.com/43
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False)
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
#反向传播及优化器
loss = reconst_loss + kl_div
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Div: {:.4f}"
.format(epoch+1, num_epochs, i+1, len(data_loader), reconst_loss.item(), kl_div.item()))
with torch.no_grad():
# 保存采样图像,即潜在向量Z通过解码器生成的新图像
z = torch.randn(batch_size, z_dim).to(device)
out = model.decode(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch+1)))
# 保存重构图像,即原图像通过解码器生成的图像
out, _, _ = model(x)
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch+1)))(7)展示原图像及重构图像。
原图像:
reconsPath = './ave_samples/reconst-30.png'
Image = cv2.imread(reconsPath)
plt.imshow(Image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
以上是迭代30次的结果,如图8-4所示。奇数列为原图像,偶数列为原图像重构的图像。从这个结果 可以看出重构图像效果还不错。图8-5为由潜在空间通过解码器生成的新图 像,这个图像效果也不错。
genPath = './ave_samples/sampled-30.png'
Image = cv2.imread(genPath)
plt.imshow(Image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
这里构建网络主要用全连接层,有兴趣的读者,可以把卷积层,如果编码层使用卷积层(如nn.Conv2d),解码器需要使用反卷积层 (nn.ConvTranspose2d)。
8.2 GAN简介
初识GAN(Generative Adversarial Nets)网络_HHzdh的博客-CSDN博客
GAN的demo代码注解(基于PyTorch)_HHzdh的博客-CSDN博客
GAN既不依赖标签来优化,也不是根据对结果奖惩来调整参数。它是依据生成器和判别器之间的博弈来不断优化。
8.2.1 GAN架构
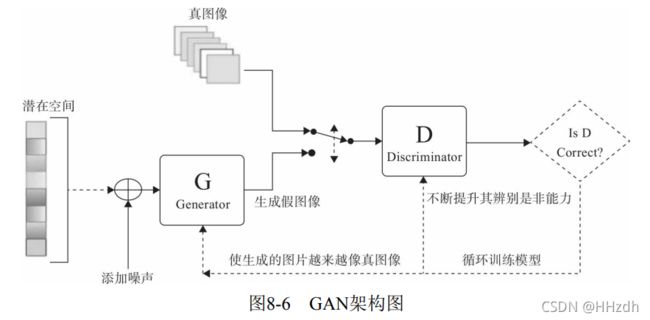
GAN从网络的角度来看,它由两部分组成。
- 生成器网络:它一个潜在空间的随机向量作为输入,并将其解码为 一张合成图像。
- 判别器网络:以一张图像(真实的或合成的均可)作为输入,并预测该图像来自训练集还是来自生成器网络。
图8-6为其架构图。如何不断提升判别器辨别是非的能力?如何使生成的图像越来越像真图 像?这些都通过控制它们各自的损失函数来控制。
8.2.2 GAN的损失函数
如何定义损失函数就成为整个GAN的关键。
为了达到判别器的目标,其损失函数既要考虑识别真图像能力,又要考虑识别假图像能力,而不能只考虑一方面,故判别器的损失函数为两者的和,具体代码如下:D表示判别器、G为生成器、real_labels、fake_labels分别表示真图像标签、假图像标签。images是真图像,z是从潜在空间随机采样的向量,通过生成器得到假图像。
# 定义判断器对真图像的损失函数
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 定义判别器对假图像(即由潜在空间点生成的图像)的损失函数
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
# 得到判别器总的损失函数
d_loss = d_loss_real + d_loss_fake生成器的损失函数如何定义,才能使其越来越向真图像靠近?以真图像为标杆或标签即可。具体代码如下:
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)8.3 用GAN生成图像
8.3.0 准备工作
(1)导入相关工具包
(1)导入必要的包。
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import cv2
import matplotlib.pyplot as plt
#在当前目录,创建不存在的目录ave_samples_GAN
sample_dir = 'ave_samples_GAN'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)(2)定义一些超参数。
# 定义一些超参数
latent_size = 64
hidden_size = 256
image_size = 784
num_epochs = 200
batch_size = 100
sample_dir = 'gan_samples'(3)对数据集进行预处理,如转换为Tensor,把数据集转换为循环、可批量加载的数据集。
# 下载MNIST训练集
dataset = torchvision.datasets.MNIST(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
#数据加载
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)8.3.1 判别器
(4)定义判别器
定义判别器网络结构,这里使用LeakyReLU为激活函数,输出一个节点 并经过Sigmoid后输出,用于真假二分类。
# 构建判断器
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid())
8.3.2 生成器
(5)定义生成器
生成器与AVE的生成器类似,不同的地方是输出为nn.tanh,使用nn.tanh 将使数据分布在[-1,1]之间。其输入是潜在空间的向量z,输出维度与真图像相同。
# 构建生成器,这个相当于AVE中的解码器
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh())
# 把判别器和生成器迁移到GPU上
D = D.to(device)
G = G.to(device)(6)选择GPU和定义损失函数优化器
torch.cuda.set_device(0)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义判别器的损失函数交叉熵及优化器
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)#Clamp函数x限制在区间[min, max]内
def denorm(x):
out = (x + 1) / 2
return out.clamp(0, 1)
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()8.3.3 训练模型
(7)训练网络
# 开始训练
total_step = len(data_loader)
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
images = images.reshape(batch_size, -1).to(device)
# 定义图像是真或假的标签
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# ================================================================== #
# 训练判别器 #
# ================================================================== #
# 定义判断器对真图片的损失函数
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 定义判别器对假图片(即由潜在空间点生成的图片)的损失函数
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
# 得到判别器总的损失函数
d_loss = d_loss_real + d_loss_fake
# 对生成器、判别器的梯度清零
reset_grad()
d_loss.backward()
d_optimizer.step()
# ================================================================== #
# 训练生成器 #
# ================================================================== #
# 定义生成器对假图片的损失函数,这里我们要求
#判别器生成的图片越来越像真图片,故损失函数中
#的标签改为真图片的标签,即希望生成的假图片,
#越来越靠近真图片
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
# 对生成器、判别器的梯度清零
#进行反向传播及运行生成器的优化器
reset_grad()
g_loss.backward()
g_optimizer.step()
if (i+1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'
.format(epoch, num_epochs, i+1, total_step, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item()))
# 保存真图片
if (epoch+1) == 1:
images = images.reshape(images.size(0), 1, 28, 28)
save_image(denorm(images), os.path.join(sample_dir, 'real_images.png'))
# 保存假图片
fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28)
save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch+1)))
# 保存模型
torch.save(G.state_dict(), 'G.ckpt')
torch.save(D.state_dict(), 'D.ckpt')8.3.4 可视化结果
训练65次后的结果:
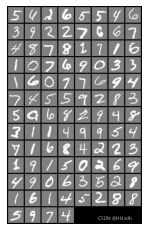

8.4 VAE与GAN的优缺点
VAE和GAN都是生成模型(Generative Model)。所谓生成模型,即能生成样本的模型,利用这类模型,我们可以完成图像自动生成(采样)、图 像信息补全等工作。
VAE是利用已有图像在编码器生成潜在向量,这个向量在服从高斯分布的情况下很好地保留了原图像的特征,在解码器得到的图片会更加的合理与准确。 VAE适合于学习具有良好结构的潜在空间,潜在空间有比较好的连续性,其中存在一些有特定意义的方向。VAE能够捕捉到图像的结构变化 (倾斜角度、圈的位置、形状变化、表情变化等)。这也是VAE的一大优 点,它有显式的分布,能够容易地可视化图像的分布。但是图像在训练的时候损失函数只能用均方误差(MSE)之类的粗略误差衡量,这就导致生成的图像不能很好地保留原图像的清晰度,就会使得图片看上去有点模糊。
GAN生成的潜在空间可能没有良好结构,但GAN生成的图像一般比 VAE的更清晰。 在GAN的训练过程中容易发生崩溃,以及训练时梯度消失情况的发生。生成对抗网络的博弈理论只是单纯的让G生成的图像骗过D,这个会让 G钻空子一旦骗过了D不论图像的合不合理就作为输出,于是模型坍塌 (Generative Model)就发生了。GAN生成器的损失函数(Loss)依赖于判别器Loss后向传递,而不是直接来自距离,因而若判别器总是能准确地判别出真假,则向后传递的信息就非常少,导致生成器无法形成自己的Loss,这是GAN比较难训练的原因。 当然,针对这一不足,近些年人们采用一个新的距离定义(Wasserstein Distance)应用于判别器,而不是原型中简单粗暴的对真伪样本的分辨正确的概率。
8.5 ConditionGAN
(CGAN)Conditional Generative Adversarial Nets原理_HHzdh的博客-CSDN博客
CGAN的demo代码解读(基于PyTorch)_HHzdh的博客-CSDN博客
如果在生成新图像的同时,能加上一个目标控制那就太好了,如果希望 生成某个数字,生成某个主题或类别的图像,实现按需生成的目的,这样的应用应该非常广泛。需求就是最大的生产力,经过研究人员的不懈努力,提 出一个基于条件的GAN,即Condition GAN,简称为CGAN。
8.6 DCGAN
DCGAN(Deep Convolutional GAN)原理_HHzdh的博客-CSDN博客
DCGAN代码demo注释解读(基于PyTorch)_HHzdh的博客-CSDN博客
DCGAN在GAN的基础上优化了网络结构,加入了卷积层(Conv)、转 置卷积(ConvTranspose)、批量正则(Batch_norm)等层,使得网络更容易训练。
8.7 提升GAN训练效果的一些技巧
训练GAN是生成器和判别器互相竞争的动态过程,比一般的神经网络挑战更大。为了克服训练GAN模型的一些问题,人们从实践中总结一些常用方法,这些方法在一些情况下,效果不错。当然,这些方法不一定适合所 有情况,方法如下。
1)批量加载和批规范化,有利于提升训练过程中博弈的稳定性。
2)使用tanh激活函数作为生成器最后一层,将图像数据规范在-1和1之 间,一般不用sigmoid。
3)选用Leaky ReLU作为生成器和判别器的激活函数,有利于改善梯度的稀疏性,稀疏的梯度会妨碍GAN的训练。
4)使用卷积层时,考虑卷积核的大小能被步幅整除,否则,可能导致 生成的图像中存在棋盘状伪影。