- 系统学习Python——并发模型和异步编程:进程、线程和GIL
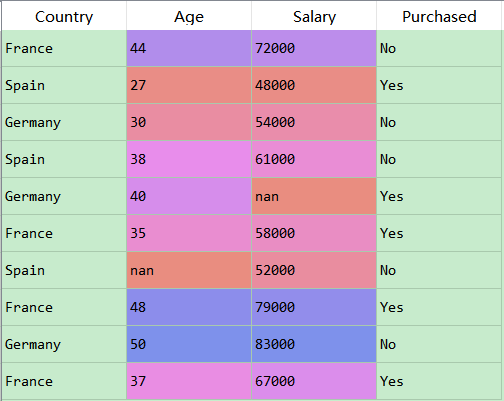
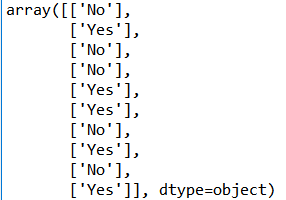
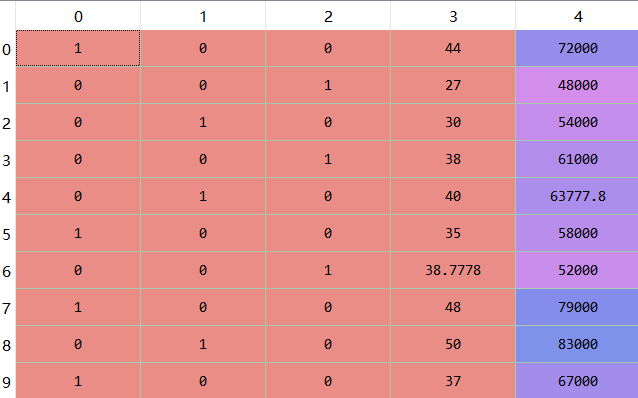
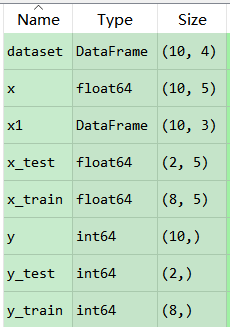
分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种
- C++11堆操作深度解析:std::is_heap与std::is_heap_until原理解析与实践
文章目录堆结构基础与函数接口堆的核心性质函数签名与核心接口std::is_heapstd::is_heap_until实现原理深度剖析std::is_heap的验证逻辑std::is_heap_until的定位策略算法优化细节代码实践与案例分析基础用法演示自定义比较器实现最小堆检查边缘情况处理性能分析与实际应用时间复杂度对比典型应用场景与手动实现的对比注意事项与最佳实践迭代器要求比较器设计C++标
- Flask框架入门:快速搭建轻量级Python网页应用
「已注销」
python-AIpython基础网站网络pythonflask后端
转载:Flask框架入门:快速搭建轻量级Python网页应用1.Flask基础Flask是一个使用Python编写的轻量级Web应用框架。它的设计目标是让Web开发变得快速简单,同时保持应用的灵活性。Flask依赖于两个外部库:Werkzeug和Jinja2,Werkzeug作为WSGI工具包处理Web服务的底层细节,Jinja2作为模板引擎渲染模板。安装Flask非常简单,可以使用pip安装命令
- 求是网:“内卷式”竞争的突出表现和主要危害有哪些?
加百力
财经研究科技知识人工智能大数据
"内卷式"竞争主要表现为:企业层面的低价竞争、同质化竞争和营销"逐底竞争";地方政府层面的违规优惠政策、盲目重复建设和设置市场壁垒。危害体现在三个层面:微观上导致"劣币驱逐良币",损害消费者利益;中观上破坏行业生态,挤压产业链利润空间;宏观上扭曲资源配置,抑制创新活力。什么是“内卷式”竞争?概括其一般特征,是指经济主体为了维持市场地位或争夺有限市场,不断投入大量精力和资源,却没有带来整体收益增长的
- 发票合并工具
小朋的软件园
前端javascriptjavahtml服务器
"发票合并工具"是一款专为高效整理票据设计的实用工具,支持将来自不同渠道的发票文件(如PDF文档、各类图片格式)快速整合为排版规范的PDF文件,尤其适用于财务报销场景下的批量票据处理需求。核心功能亮点多格式兼容:无缝导入PDF文件及常见图片格式(.png/.jpg/.jpeg/.bmp),适配多来源发票整合需求。智能布局配置:提供灵活的页面布局选项(每页2/3/4张发票),其中"2合1"模式针对报
- Python Flask 框架入门:快速搭建 Web 应用的秘诀
Python编程之道
Python人工智能与大数据Python编程之道pythonflask前端ai
PythonFlask框架入门:快速搭建Web应用的秘诀关键词Flask、微框架、路由系统、Jinja2模板、请求处理、WSGI、Web开发摘要想快速用Python搭建一个灵活的Web应用?Flask作为“微框架”代表,凭借轻量、可扩展的特性,成为初学者和小型项目的首选。本文将从Flask的核心概念出发,结合生活化比喻、代码示例和实战案例,带你一步步掌握:如何用Flask搭建第一个Web应用?路由
- JavaScript 树形菜单总结
Auscy
microsoft
树形菜单是前端开发中常见的交互组件,用于展示具有层级关系的数据(如文件目录、分类列表、组织架构等)。以下从核心概念、实现方式、常见功能及优化方向等方面进行总结。一、核心概念层级结构:数据以父子嵌套形式存在,如{id:1,children:[{id:2}]}。节点:树形结构的基本单元,包含自身信息及子节点(若有)。展开/折叠:子节点的显示与隐藏切换,是树形菜单的核心交互。递归渲染:因数据层级不固定,
- python_虚拟环境
阿_焦
python
第一、配置虚拟环境:virtualenv(1)pipvirtualenv>安装虚拟环境包(2)pipinstallvirtualenvwrapper-win>安装虚拟环境依赖包(3)c盘创建虚拟目录>C:\virtualenv>配置环境变量【了解一下】:(1)如何使用virtualenv创建虚拟环境a、cd到C:\virtualenv目录下:b、mkvirtualenvname>创建虚拟环境nam
- 全面触摸屏输入法设计与实现
长野君
本文还有配套的精品资源,点击获取简介:触摸屏输入法是针对触摸设备优化的文字输入方案,包括虚拟键盘、手写、语音识别和手势等多种输入方式。本方案通过提供主程序文件、用户手册、界面截图、示例图、说明文本和音效文件,旨在为用户提供一个完整的、多样的文字输入体验。开发者通过持续优化算法和用户界面,使用户在无物理键盘环境下也能高效准确地进行文字输入。1.触摸屏输入法概述简介在现代信息技术飞速发展的今天,触摸屏
- 精通Canvas:15款时钟特效代码实现指南
烟幕缭绕
本文还有配套的精品资源,点击获取简介:HTML5的Canvas是一个用于绘制矢量图形的API,通过JavaScript实现动态效果。本项目集合了15种不同的时钟特效代码,帮助开发者通过学习绘制圆形、线条、时间更新、旋转、颜色样式设置及动画效果等概念,深化对Canvas的理解和应用。项目中的CSS文件负责时钟的样式设定,而JS文件则包含实现各种特效的逻辑,通过不同的函数或类处理时间更新和动画绘制,提
- 高效批量单词翻译工具的设计与应用
本文还有配套的精品资源,点击获取简介:在信息技术飞速发展的今天,批量单词翻译工具通过计算机的数据处理能力,大大提高了语言学习和文字处理的效率。用户通过简单输入单词列表到一个文本文件,并运行翻译程序,即可获得翻译结果并保存至指定文件。该工具集成了内置或外部翻译引擎,利用自然语言处理技术实现快速准确的翻译,并可能提供词性识别等附加功能。尽管机器翻译无法完全取代人工校对,但它为用户提供了一种高效的翻译解
- 嵌入式系统LCD显示模块编程实践
本文还有配套的精品资源,点击获取简介:本文档提供了一个具有800x480分辨率的3.5英寸液晶显示模块LW350AC9001的驱动程序代码,以及嵌入式系统中使用C/C++语言进行硬件编程的实践指南。该模块的2mm厚度使其适用于空间受限的便携式设备。内容包括驱动程序源代码、硬件控制接口使用方法,以及如何在嵌入式系统中进行图形处理、电源管理与性能优化。1.嵌入式系统原理1.1嵌入式系统概念嵌入式系统是
- 深入剖析OpenJDK 18 GA源码:Java平台最新发展
想法臃肿
本文还有配套的精品资源,点击获取简介:OpenJDK18GA作为Java开发的关键里程碑,提供了诸多新特性和改进。本文章深入探讨了OpenJDK18GA源码,揭示其内部机制,帮助开发者更好地理解和利用这个版本。文章还涵盖了PatternMatching、SealedClasses、Records、JEP395、JEP406和JEP407等特性,以及HotSpot虚拟机、编译器、垃圾收集器、内存模型
- Android 开源组件和第三方库汇总
gyyzzr
AndroidAndroid开源框架
转载1、github排名https://github.com/trending,github搜索:https://github.com/search2、https://github.com/wasabeef/awesome-android-ui目录UIUI卫星菜单节选器下拉刷新模糊效果HUD与Toast进度条UI其它动画网络相关响应式编程地图数据库图像浏览及处理视频音频处理测试及调试动态更新热更新
- FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)
阿牛的药铺
算法移植部署fpga开发verilog
FPGA小白到项目实战:Verilog+Vivado全流程通关指南(附光学类岗位技能映射)引言:为什么这个FPGA入门路线能帮你快速上岗?本文设计了一条**"Verilog语法→工具链操作→光学项目实战→岗位技能对标"的阶梯式学习路径。不同于泛泛而谈的FPGA教程,我们聚焦光学类产品开发**核心能力(时序接口设计、图像处理算法移植、高速接口应用),通过3个递进式项目(从LED闪烁到图像边缘检测),
- PyTorch & TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)
阿牛的药铺
算法移植部署pytorchtensorflowfpga开发
PyTorch&TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)引言:为什么算法移植工程师必须掌握框架基础?针对光学类产品算法FPGA移植岗位需求(如可见光/红外图像处理),深度学习框架是算法落地的"桥梁"——既要用PyTorch/TensorFlow验证算法可行性,又要将训练好的模型(如CNN、目标检测)转换为FPGA可部署的格式(ONNX、TFLite)。本文采用"
- Android ViewBinding 使用与封装教程
积跬步DEV
Android开发实战大全android
AndroidViewBinding使用与封装教程:一、ViewBinding是什么?核心功能:为每个XML布局文件自动生成一个绑定类(如ActivityMainBinding),直接暴露所有带ID的视图引用。优点:避免繁琐的findViewById(),类型安全且编译时检查。对比DataBinding:ViewBinding仅处理视图引用,无数据绑定功能。DataBinding支持双向数据绑定,
- 【超硬核】JVM源码解读:Java方法main在虚拟机上解释执行
HeapDump性能社区
java开发语言后端jvm
本文由HeapDump性能社区首席讲师鸠摩(马智)授权整理发布第1篇-关于Java虚拟机HotSpot,开篇说的简单点开讲Java运行时,这一篇讲一些简单的内容。我们写的主类中的main()方法是如何被Java虚拟机调用到的?在Java类中的一些方法会被由C/C++编写的HotSpot虚拟机的C/C++函数调用,不过由于Java方法与C/C++函数的调用约定不同,所以并不能直接调用,需要JavaC
- 算法学习笔记:15.二分查找 ——从原理到实战,涵盖 LeetCode 与考研 408 例题
呆呆企鹅仔
算法学习算法学习笔记考研二分查找
在计算机科学的查找算法中,二分查找以其高效性占据着重要地位。它利用数据的有序性,通过不断缩小查找范围,将原本需要线性时间的查找过程优化为对数时间,成为处理大规模有序数据查找问题的首选算法。二分查找的基本概念二分查找(BinarySearch),又称折半查找,是一种在有序数据集合中查找特定元素的高效算法。其核心原理是:通过不断将查找范围减半,快速定位目标元素。与线性查找逐个遍历元素不同,二分查找依赖
- (Python基础篇)循环结构
EternityArt
基础篇python
一、什么是Python循环结构?循环结构是编程中重复执行代码块的机制。在Python中,循环允许你:1.迭代处理数据:遍历列表、字典、文件内容等。2.自动化重复任务:如批量处理数据、生成序列等。3.控制执行流程:根据条件决定是否继续或终止循环。二、为什么需要循环结构?假设你需要打印1到100的所有偶数:没有循环:需手动编写100行print()语句。print(0)print(2)print(4)
- (Python基础篇)字典的操作
EternityArt
基础篇python开发语言
一、引言在Python编程中,字典(Dictionary)是一种极具灵活性的数据结构,它通过“键-值对”(key-valuepair)的形式存储数据,如同现实生活中的字典——通过“词语(键)”快速查找“释义(值)”。相较于列表和元组的有序索引访问,字典的优势在于基于键的快速查找,这使得它在处理需要频繁通过唯一标识获取数据的场景中极为高效。掌握字典的操作,能让我们更高效地组织和管理复杂数据,是Pyt
- vue keep-alive标签的运用
keep-alive,想必大家都不会很陌生,在一些选项卡中会使用到。其实,它的作用大概就是把组件的数据给缓存起来。比如果我有一个选项卡,标签一,标签二,标签三。现在,我需要实现,当我在标签一的表单中输入内容后,点击标签二,再回到标签一,表单的内容依然存在。如果按以往的做法,不使用keep-alive,那是不能实现的。然而,我们只需要在选项卡的内容最外层包一个keep-alive标签即可。但这儿有一
- 霍夫变换(Hough Transform)算法原来详解和纯C++代码实现以及OpenCV中的使用示例
点云SLAM
算法图形图像处理算法opencv图像处理与计算机视觉算法直线提取检测目标检测霍夫变换算法
霍夫变换(HoughTransform)是一种经典的图像处理与计算机视觉算法,广泛用于检测图像中的几何形状,例如直线、圆、椭圆等。其核心思想是将图像空间中的“点”映射到参数空间中的“曲线”,从而将形状检测问题转化为参数空间中的峰值检测问题。一、霍夫变换基本思想输入:边缘图像(如经过Canny边缘检测)输出:一组满足几何模型的形状(如直线、圆)关键思想:图像空间中的一个点→参数空间中的一个曲线参数空
- Java特性之设计模式【责任链模式】
Naijia_OvO
Java特性java设计模式责任链模式
一、责任链模式概述顾名思义,责任链模式(ChainofResponsibilityPattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推主要解决:职责链上的处理者负责处理请求,客户只需要将
- Linux操作系统磁盘管理
CZZDg
linux运维服务器
目录一.硬盘介绍1.硬盘的物理结构2.CHS编号3.磁盘存储划分4.开机流程5.要点6.磁盘存储数据的形式二.Linux文件系统1.根文件系统2.虚拟文件系统3.真文件系统4.伪文件系统三.磁盘分区与挂载1.磁盘分区方式2.分区命令3.查看与识别命令4.格式化命令5.挂载命令四.LVM逻辑卷1.概述2.管理命令五.磁盘配额1.概述usrquota:支持对用户的磁盘配额grpquota:支持对组的磁
- 计算机网络技术
CZZDg
计算机网络
目录一.网络概述1.网络的概念2.网络发展是3.网络的四要素4.网络功能5.网络类型6.网络协议与标准7.网络中常见的概念8.网络拓补结构二.网络模型1.分层思想2.OSI七层模型3.TCP/IP五层模型4.数据的封装与解封装过程三.IP地址1.进制转换2.IP地址定义3.IP地址组成成分4.IP地址分类5.地址划分6、相关概念一.网络概述1.网络的概念两个主机通过传输介质和通信协议实现通信和资源
- 日历插件-FullCalendar的详细使用
老马聊技术
JavaScript前端javascript
一、介绍FullCalendar是一个功能强大、高度可定制的JavaScript日历组件,用于在网页中显示和管理日历事件。它支持多种视图(月、周、日等),可以轻松集成各种框架,并提供丰富的事件处理功能。二、实操案例具体代码如下:FullCalendar日期选择body{font-family:Arial,sans-serif;margin:20px;}#calendar{max-width:900
- Kafka系列之:Dead Letter Queue死信队列DLQ
快乐骑行^_^
KafkaKafka系列DeadLetterQueue死信队列DLQ
Kafka系列之:DeadLetterQueue死信队列DLQ一、死信队列二、参数errors.tolerance三、创建死信队列主题四、在启用安全性的情况下使用死信队列更多内容请阅读博主这篇博客:Kafka系列之:KafkaConnect深入探讨-错误处理和死信队列一、死信队列死信队列(DLQ)仅适用于接收器连接器。当一条记录以JSON格式到达接收器连接器时,但接收器连接器配置期望另一种格式,如
- 入门html这篇文章就够了
ξ流ぁ星ぷ132
html前端
HTML笔记文章目录HTML笔记html介绍什么是htmlhtml的作用HTML标签介绍常用标签标签and标签and标签u标签del删除线br标签用于换行pre标签,预处理标签span标签div标签sub标签andsup标签hr标签h1,h2...h6标签:HTML5中的语义标签:特殊字符img标签a标签第一种用法:超链接第二种用法:锚点video标签表格标签:form标签input标签selec
- Spring Cloud Gateway 的执行链路详解
愤怒的代码
SpringCloudspringcloud
SpringCloudGateway的执行链路详解核心目标明确SpringCloudGateway的请求处理全过程(从接收到请求→到转发→到返回响应),方便你在合适的生命周期节点插入你的逻辑。核心执行链路图(执行顺序)┌──────────────┐│客户端请求│└────┬─────────┘↓┌────┴─────────────┐│NettyHttpServer│←→ReactorNetty
- Java实现的简单双向Map,支持重复Value
superlxw1234
java双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
- PL/SQL触发器基础及例子
百合不是茶
oracle数据库触发器PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
- [时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
- easy ui datagrid上移下移一行
商人shang
js上移下移easyuidatagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
- Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
- springMVC 使用JSR-303 Validation验证
杨白白
springmvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
- log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
- 使用ajax和history.pushState无刷新改变页面URL
agevs
jquery框架Ajaxhtml5chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
- centos中文乱码
AILIKES
centosOSssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
- 触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
- JS正则表达式的i m g
bijian1013
JavaScript正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
- HTML5模式和Hashbang模式
bijian1013
JavaScriptAngularJSHashbang模式HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
- [Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
- 【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
- 记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
- 巧用视错觉-UI更有趣
brotherlamp
UIui视频ui教程ui自学ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
- 线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构算法线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
- HTTP协议详解
chicony
http协议
引言
- Scala设计模式
chenchao051
设计模式scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
- 安装mysql
daizj
mysql安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
- HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
- asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
- C语言中,关键字static的作用
e200702084
C++cC#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
- win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
- Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
- Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转递归反转二分交换反转java字符串反转栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
- 代码实现任意容量倒水问题
home198979
PHP算法倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
- Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
- 两种启动监听器ApplicationListener和ServletContextListener
spjich
javaspring框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
- JavaScript Rounding Methods of the Math object
何不笑
JavaScriptMath
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen