译文:FishNet
FishNet:用于图像、区域和像素级的多功能主干网络
摘要 对于预测不同层级的目标对象(如图像级、区域级和像素级),设计卷积神经网络(CNN)结构的基本原则具有多样性。一般来讲,专门为图像分类任务所设计的网络结构,会默认作为其他任务(包括检查和分割)的主干网络结构。但是,多数网络的主干设计并没有考虑统一网络的优势,而为像素级或区域级的预测任务设计主干网络,原因可能是需要更高分辨率的深层特征。为了实现这一目标,本文设计了一个类似鱼形的主干网络,我们称为FishNet。在FishNet中,所有的解决方案信息都会被保留,并在最后的任务进行精炼。除此之外,我们观察到,现存的工作并不能直接将梯度信息从深层网络传递给浅层网络,而本文的设计可以更好地处理该问题。为了验证FishNet的性能表现,我们进行了大量实验。特别地,在ImageNet-1k数据集上,在参数较少的情况下,FishNet的性能可以完全超过DenseNet和ResNet。FishNet已经被应用在赢得2018年COCO检测挑战赛的一个模块中。代码被公开在:https://github.com/kevin-ssy/FishNet。
1 简介
在计算机视觉领域中,卷积神经网络(CNN,Convolutional Neural Network)已经被认为学习更好特征表达的最有效的方法[17, 26, 28, 9, 37, 27, 4]。CNN结构的设计也成为一项基本任务,良好的结构有助于提高许多相关性视觉任务的性能。随着CNN层设计的加深,近来的工作试图通过恒等映射[8]和直连接[13]来改进或重用前一层的网络特征。
此时,对于图像级、区域级和像素级的任务,在设计CNN结构上开始变得多样化。对于图像分类任务,网络往往使用连续下采样来获得低分辨率的深度特征。然而,低分辨率的特征并不适用于像素级任务,甚至是区域级任务。如果直接将高分辨率的浅层特征用于区域和像素级任务,模型应用效果却难以令人满意。为了获得更深层的高分辨率特征,对于像素级任务,已知的较好的网络结构如U-Net和沙漏状网络[22, 24, 30]。近来,对于区域级任务(如目标检测)的研究也使用具有上采样机制的网络结构[21, 19],通过这种方式可以用相对高分辨率的深层特征描述小尺度物体对象。
在已经将高分辨率深层特征用于区域级和像素级任务的基础上,本文提出一种鱼状网络,即FishNet。它可以使高分辨率的深层特征包含高级别语义信息。通过该方式,将经过图像分类任务预训练的特征可以更好的用于区域级和像素级任务。
本文精心设计了一种具有以下三个优点的网络结构。
第一,它是第一个结合了各类网络结构优势的主干网络,并且是为像素级、区域级和图像级三类任务而设计的网络。与仅为图像分类任务而设计的网络相比,本文的主干网络对于处理像素级和区域级任务有更好的效果。
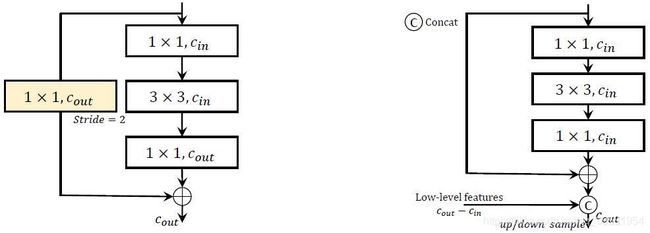
图1. ResNet(图左)和FishNet(图右)的上/下采样模块。黄色显示的为1×1卷积层,由于其为孤立卷积层(孤立卷积层,见章节2),这使得其得其无法通过直接BP完成输出层到浅层网络的梯度下降。
第二,它可以使极深层网络的梯度直接传递给浅层网络,本文称为直接BP。最近的研究表明,有两种设计可以完成直接BP,即通过残差块完成恒等映射[8]和直连接方式[13]。但是,不可否认的事实是现有网络的设计,如[9, 8, 13, 28, 34, 32],仍然无法使用直接BP。造成该问题的原因是卷积层之间的特征分辨率不同。如图1所示,ResNet[9]利用跳跃连接具有步幅的卷积层来处理输入与输出通道数量不一致的问题,这使得恒等映射并没有使用。没有恒等映射或直连接的卷积层降低了输出到浅层网络的梯度。我们的结构设计更好地解决了这个问题,即将不同深度的特征直接连接最后的输出层。我们更加精细的设计了网络中的结构,以保证直接BP。通过本文的设计,特征的语义信息也可以在网络中得以保留。
第三,网络中,不同深度的特征被保留下来,并用于进一步的特征精细化提取。不同深度的特征对于图像的抽象程度不同。所以,对于这些特征都应该予以保存,以提高特征的多样性。同时,这些特征之间具有互补性,它们可以用来进行精细化提取。因此,我们设计了一种特征保持与精细化提取机制,去实现本文的最终目标。
本文的设计可能会有一个反直觉的效果,即在参数数量与图像分类精度的权衡中,它比传统的卷积网络表现得更好。原因如下:(1)保留特征和互补精细化提取,远比设计宽度或深度更大的网络更有用;(2)它有助于直接BP。实验结果表明,我们的紧凑模型FishNet-150的参数量接近于ResNet-50,而在ImageNet-1k数据集上的精度却能超过ResNet-101和DenseNet-161(k=48)。同时,对于区域级和像素级的任务,如目标检测和实例分割,我们的模型作为Mask R-CNN[10]的主干网络与基于ResNet-50的Mask R-CNN相比,在MS COCO数据集上AP值分别提高了2.8%和2.3%。
1. 1相关工作
对于图像分类任务的CNN结构。深层卷积神经网络的结构设计是深度学习中一项基础却极具挑战性的任务。优秀的网络可以有更好的特征提取能力,这也会提高许多处理其他任务的性能。AlexNet[17]在图像识别挑战赛ILSVRC[25]上的显著效果提升,标志着计算机视觉深度学习时代的来临。在此之后,许多网络设计出现,如VGG[26]、Inception[28],所有的这些网络都是通过加深网络来提升其能力。然而,由于梯度消失的问题,此时的网络仍然无法设计过深。近来,在网络中引入跳跃连接[9],极大地缓解了梯度消失问题。在这个方面上有系列正在进行的工作[29, 34, 32, 13, 2, 11, 31, 33]。但是,对于图像分类任务,在已有的所有网络设计中,高分辨率的特征是由感受野较小的浅层网络提取的,缺乏仅能在深层网络中获得的高级语义信息。我们的工作是首次提取高分辨率深层特征和高级语义信息,同时提高图像分类的精度。
采用不同层特征结合的网络结构设计。通过使用嵌套稀疏网络[16]、超列[7]、加法[18]和残差块[22, 21](卷积与反卷积均使用残差块)等方法组合,可以得到不同分辨率或深度的特征。在文献[7]中,超列网络直接将来自不同层的特征进行连接后,用于图像分割和目标定位。但是,这种方法并没有将深层和浅层网络的特征进行相互精细化提取。文献[8]使用直接相加将深层与浅层网络的特征进行融合。然而,该方法只能将不同抽象级的特征进行混合,并不能同时保留或细化该混合特征。同样,采用卷积的串联方法与文献[8]的方法类似[23]。另外,残差块[22, 21]也会被用于组合特征,前提是已完成的工作必须给出一个预定的目标,等待特征的精细化提取。假如跳跃层是为了得到深度特征,那么浅层特征仅起到精细化提取出深度特征的作用,在此情况下,浅层特征也会在经过残差块之后被丢弃。综上所述,在现有的工作中,采用相加和残差块并不能保存浅层和深层的特征,而我们设计的网络却可以很好的保存并精炼这些特征。
使用上采样机制的网络。由于计算机视觉领域还有许多其他任务,如目标检测和目标分割,这些任务都需要较大的特征图来保证分辨率,所以,将上采样方法应用到网络中显得十分必要。这类方法通常包括不同深度的特征之间的信息交互。U-Net[24]、FPN[21]、堆叠沙漏网络[22]等一系列工作都展示了这类方法在像素级[22]和区域级任务[21, 19]的能力。但是,在图像分类任务上,这些方法都没有被证明是有效的。MSDNet[12]尝试保持高分辨率的特征图,这是与我们的网络结构最相似的工作。当然,MSDNet的结构仍然使用不同分辨率的特征,这也造成特征无法保存和表示。此外,该方法并没有采用上采样的方式,让特征具有更大的分辨率和更多的语义信息。DMSNet在结构中引入多尺度机制的目的仅是计算预测。但是,这种设计对于图像分类的准确度并没有显著的提升。我们的工作则保留和精细化了来自浅层和深层的特征,这在现有的上采样网络和MSDNet方法中是无法实现的。
特征/输出之间的信息传递。目前,一些方法可以使用特征之间的信息传递来完成分割[36]、姿态估计[3]和目标检测[35]。这些设计均基于主干网络架构的设计,而FishNet是对于主干网络设计很好的补充。
2 深度残差网络与孤立卷积之间的恒等映射
ResNet的基本构建模块被称为残差块。具有恒等映射[8]的残差块可以表示为
xl+1=xl+F(xl,Wl)![]() (1)
(1)
其中,xl![]() 表示 l
表示 l![]() 层残差块的输入特征,F(xl,Wl)
层残差块的输入特征,F(xl,Wl)![]() 表示输入xl
表示输入xl![]() 与权重参数Wl
与权重参数Wl![]() 的残差函数。我们考虑将分辨率相同的所有残差块进行堆叠,作为一个阶段。用xl,s
的残差函数。我们考虑将分辨率相同的所有残差块进行堆叠,作为一个阶段。用xl,s![]() 表示阶段s
表示阶段s![]() 的第l
的第l![]() 层特征,可以得到:
层特征,可以得到:
xLs,s=x0,s+l=1LsFxl,s,Wl,s,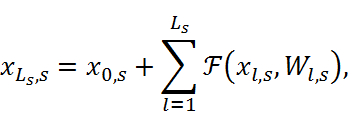
∂L∂x0,s=∂L∂xLs,s(1+∂∂x0,sl=1LsFxl,s,Wl,s)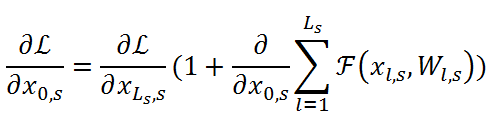
(2)
式中,Ls![]() 表示阶段s
表示阶段s![]() 堆叠的残差块数量,L
堆叠的残差块数量,L![]() 是一个损失函数。式子(2)中的附加项∂L∂xLs,s
是一个损失函数。式子(2)中的附加项∂L∂xLs,s![]() 是确保xLs,s
是确保xLs,s![]() 的梯度直接传递给x0,s
的梯度直接传递给x0,s![]() 。我们认为不同分辨率的特征处于不同的阶段。在之前的ResNet中,不同分辨率的特征在信道数量上是不同的。因此,需要转换函数h(∙)
。我们认为不同分辨率的特征处于不同的阶段。在之前的ResNet中,不同分辨率的特征在信道数量上是不同的。因此,需要转换函数h(∙)![]() 在下采样之前改变信道数量:
在下采样之前改变信道数量:
x0,s+1'=hxLs,s=σ(λs⊗xLs,s+bLs,s)![]()
(3)

图2. FishNet概述。它由三部分组成。尾部使用现有的工作从输入图像中获取深度低分辨率特征。身体部位获取包含高级语义信息的高分辨率特征。头部保留并精细化提取从这三部分中获得的特征。
式中,σ(∙)![]() 是一个激活函数。λs
是一个激活函数。λs![]() 和bLs,s
和bLs,s![]() 分别是阶段s
分别是阶段s![]() 过渡层的滤波器和偏置。符号⊗
过渡层的滤波器和偏置。符号⊗![]() 代表卷积运算。由于xLs,s
代表卷积运算。由于xLs,s![]() 和x0,s+1'
和x0,s+1'![]() 的信道数量不同,所以恒等映射并不适用。
的信道数量不同,所以恒等映射并不适用。
孤立卷积(I-conv)的梯度传递问题。孤立卷积(I-conv)是式子(3)中没有恒等映射和直连接的卷积层。通过文献[8]中的实验分析与验证,它希望将深层网络的梯度直接传递到浅层网络。采用恒等映射的残差块[8]和采用直连接的密集块[13]都会促进直接梯度传递。如果存在I-conv,则深层的梯度并不能直接传递到浅层。而ResNet[8]在不同分辨率的特征之间存在I-conv,I-conv(在文献[13]中被称为过渡层)也存在于相邻的密集块之间,但是,这些方式均会阻碍梯度的直接传递。由于ResNet和DenseNet仍然存在I-conv,来自输出层的梯度并不能直接传递给浅层网络,这也类似于文献[17, 26]中的网络。文献[15]中的可逆下采样放大通过将当前阶段所有特征用于下一阶段的方式避免该问题。但是,这种方式的问题是,随着阶段数量的增加(在文献[15]中为188M),参数量将随着指数形式进行增加。通过分析,我们已经确定了现有网络中I-conv的梯度传递问题。因此,为了解决该问题,我们提出一种新的网络结构,即FishNet。
3 鱼网(FishNet)
图2展示FishNet的概述。整个网络分为三个部分:尾部、身部和头部。鱼尾部为一个现有的CNN结构,例如ResNet,随着CNN的深入,特征的分辨率会越来越小。鱼身体部位包含上采样和精细化提取块,用于精炼提取尾部和身部的特征。鱼头部包含下采样和精细化提取块,用于保存和精炼提取尾部、身部和头部的特征。头部的最后一个卷积层的精细化特征被用于最终的任务决策。
本文中的阶段是指提取相同分辨率特征的一组卷积块。根据输出特征的分辨率,FishNet的各个部分可以分为多个阶段。随着特征分辨率的减小,阶段的ID也会变高。例如,输出分辨率为56×56和28×28的卷积块分别位于FishNet三个部分中的第1阶段和第2阶段。因此,在鱼尾部和头部中,在完成网络前向传播时的阶段ID会越来越高,而在鱼身部的阶段ID会越来越小。
图3显示两个阶段的特征在尾部、身部和头部之间的相互作用。图3(a)中的鱼尾部可以看做残差网络。来自尾部的特征通过几个残差块后,也通过水平箭头传递到身部。图3(a)中的身部通过直连接既保留尾部特征,又保留身部上一阶段的特征。之后,这些特征将被用于上采样和精细化提取,具体细节如图3(b)所示,关于UR块的细节将在第3.1节中进行探讨。经过精细化后的特征随后被用于身部和头部的下一阶段。头部会保留和精细化身部和头部上一阶段的所有特征。然后,头部的下一阶段会使用精细化过的特征。头部的信息传递的详细表示如图3(c)以及在3.1节中继续探讨。水平连接表示尾部、身部和头部之间的信息传输模块。在图3(a)中,我们使用残差块作为
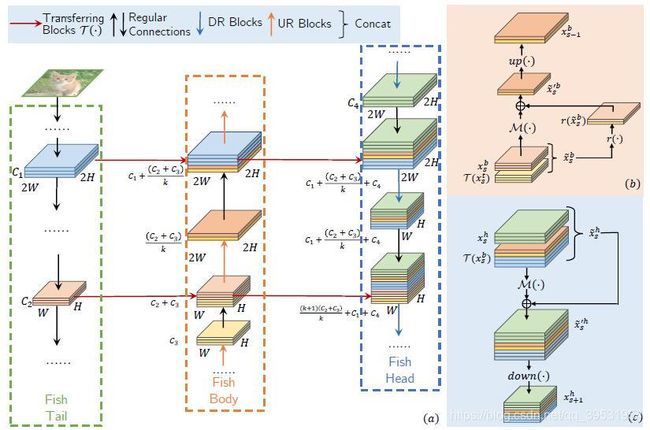
图3. (可以使用放大,以更好的看清颜色)(a)两个阶段的特征在尾部、身部和头部之间的相互作用,右侧所列两张图显示(b)上采样过程和精细化块(UR块),(c)下采样过程和精细化块(DR块)。在图(a)中,当垂直与水平箭头相交时,使用特征直连接。符号C*![]() 、*H
、*H![]() 和*W
和*W![]() 分别表示图像信道数、高度和宽度。k
分别表示图像信道数、高度和宽度。k![]() 表示3.1节中方程式8中所数的信道数递减率。注意:鱼身部和头部并没有孤立卷积层(I-conv)。因此,损失的梯度可以直接传递到尾部、身部和头部的浅层网络。
表示3.1节中方程式8中所数的信道数递减率。注意:鱼身部和头部并没有孤立卷积层(I-conv)。因此,损失的梯度可以直接传递到尾部、身部和头部的浅层网络。
传输块。
3. 1特征精细化
在FishNet中,有两个模块用于上/下采样和特征精细化:上采样和精细化模块(UR块),下采样和精细化块(DR块)。
UR块。使用xst![]() 和xsb
和xsb![]() 分别表示尾部和身部在s
分别表示尾部和身部在s![]() 阶段第一层的输出特征。s∈{1, 2,…,min(Nt-1,Nb-1)}
阶段第一层的输出特征。s∈{1, 2,…,min(Nt-1,Nb-1)}![]() ,Nt
,Nt![]() 和Nb
和Nb![]() 分别代表尾部和身部的阶段数量。将特征的直连接表示为concat(∙)
分别代表尾部和身部的阶段数量。将特征的直连接表示为concat(∙)![]() 。UR块可以表示为:
。UR块可以表示为:
xs-1b=URxsb,Txst=up(xs'b)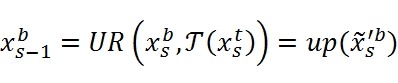 (4)
(4)
式中,T![]() 表示将尾部的特征xs-1t
表示将尾部的特征xs-1t![]() 转移到身部的残差块。up(xs'b)
转移到身部的残差块。up(xs'b)![]() 表示在鱼身部对前一阶段的特征进行精细化。下一阶段的输出特征xs-1b
表示在鱼身部对前一阶段的特征进行精细化。下一阶段的输出特征xs-1b![]() 是由xst
是由xst![]() 和xsb
和xsb![]() 共同精炼得到:
共同精炼得到:
xs-1b=up(xs'b)![]() (5)
(5)
xs'b=rxsb+M(xsb)![]() (6)
(6)
xsb=concat(xsb,T(xst))![]() (7)
(7)
式子中,up(∙)![]() 表示上采样函数。总结,UR块在式子(7)中将来自身部和尾部的特征进行直连接并在式子(6)中完成精细化,之后,在式子(5)中进行上采样获得输出特征xs-1b
表示上采样函数。总结,UR块在式子(7)中将来自身部和尾部的特征进行直连接并在式子(6)中完成精细化,之后,在式子(5)中进行上采样获得输出特征xs-1b![]() 。式子(6)中的M
。式子(6)中的M![]() 为从特征xsb
为从特征xsb![]() 中提取信息函数,我们将M
中提取信息函数,我们将M![]() 作为卷积运算。类似于式子(1)中的残差函数F
作为卷积运算。类似于式子(1)中的残差函数F![]() ,式子(6)中的M
,式子(6)中的M![]() 也是由三层卷积构成的残差单元实现。式子(6)中的信道衰减函数r
也是由三层卷积构成的残差单元实现。式子(6)中的信道衰减函数r![]() 可以如下表示:
可以如下表示:
rx=x=x1,x2,…,xcout,![]()
xn=j=0kxk∙n+j, n∈{0,1,..,cout}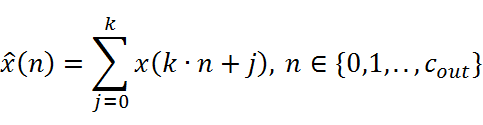
(8)
式子中,x={x1, x2,…,x(cin)}![]() 表示输入特征图的cin
表示输入特征图的cin![]() 个信道,x
个信道,x![]() 表示函数r
表示函数r![]() 的输出特征图的cout
的输出特征图的cout![]() 个信道,cincout=k
个信道,cincout=k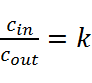 。整体式子是从相邻的k
。整体式子是从相邻的k![]() 信道到1信道的特征图像素级的求和。我们使用这样的简单操作使得信道数减少到1/ k
信道到1信道的特征图像素级的求和。我们使用这样的简单操作使得信道数减少到1/ k![]() ,这种方式让连接前一阶段的信道数量减少,以减小计算量和参数量。
,这种方式让连接前一阶段的信道数量减少,以减小计算量和参数量。
DR块。位于头部的DR块与UR块类似。在它们之间仅有两种不同的实现方式。第一种,我们在DR块中使用2×2最大池化层进行下采样。第二种,在DR块中,并不使用UR块中的信道衰减函数,因此在当前阶段的梯度可以直接传递给上一阶段的参数。在式子(5)-(7)的UR块基础上,DR块的可以用下式表示:
xs+1h=down(xs'h)![]()
xs'h=xsh+M(xsh)![]() (9)
(9)
xsh=concat(xsh,T(xsb))![]()
式子中,xs+1h![]() 表示阶段s+1
表示阶段s+1![]() 的头部特征。这样,整个网络的各个阶段的特征都能够通过直连接、跳跃连接和最大池化连接到最后一层。注意,我们并没有使用式子(6)中的信道求和操作r(∙)
的头部特征。这样,整个网络的各个阶段的特征都能够通过直连接、跳跃连接和最大池化连接到最后一层。注意,我们并没有使用式子(6)中的信道求和操作r(∙)![]() 从式子(9)中DR块的xsh
从式子(9)中DR块的xsh![]() 来获取xsh
来获取xsh![]() 。因此,在DR块的xsh
。因此,在DR块的xsh![]() 获取xsh
获取xsh![]() 的网络层实际上可以被看作为一个残差块[8]。
的网络层实际上可以被看作为一个残差块[8]。
3. 2 详细设计与讨论
FishNet对于梯度传递问题的设计。在FishNet中设计了鱼身部和鱼头部,在鱼尾部和鱼身部的所有阶段的特征都被直连在鱼头部。我们精心设计了鱼头部的网络层,使其不存在I-conv层。鱼部的网络层由直连接、附带恒等映射的卷积层和最大池化层组成。因此,FishNet解决了之前主干网络在尾部的梯度传递问题,具体措施为(1)移除头部的I-conv层;(2)在身部和头部使用直连接。
上/下采样的选择。对于下采样,卷积核尺寸为2×2,步幅为2,以避免像素之间重叠。模型简化测试将会显示不同尺寸卷积核对网络的影响。为了避免I-conv影响,尽量不要在上采样阶段采用权重反卷积计算。为减少计算量,我们采用最近邻插值法进行上采样。由于在上采样过程中会以较低的分辨率稀释输入特征,因此,我们在精细化模块中使用扩张卷积。
鱼身部和尾部之间的桥连接模型。由于尾部将图像进行下采样得到分辨率为1×1的特征图,所以,需要在身部将1×1的特征上采样到7×7。我们在这里使用了一个SE模块[11],即采用信道注意力机制将特征分辨率从1×1上升到7×7。
4 实验与结果
4. 1图像分类任务的实现细节
对于图像分类任务,在包含1000类的ImageNet2012数据集[25]上,我们对本文提出的网络进行了验证。此数据集包含120万张训练集和5万张验证集图像(以ImageNet-1k val表示)。我们使用目前流行的深度学习框架PyTorch[23]实现了FishNet。对于训练,我们对图像进行随机裁剪并统一分辨率为224×224,批量大小为256,并选择随机梯度下降算法作为优化方法,基础学习率为0.1。权重的衰减值和冲量值分别为10-4和0.9。我们对网络进行了100个轮次的训练,学习率每30轮次下降10倍。对于正则化过程,我们首先将每个像素值约束到[0,1]之间,然后,再减去平均值以及除以RGB模型每个信道的方差。为了公平比较,我们使用了文献[9]中的数据增强方法(随机裁剪、水平翻转和标准色增强[17])。本文所有的实验结果都是在ImageNet-1k数据集上通过单目标验证过程得出。较为特殊的是,尺寸为224×224的图像区域会从输入图像的中心进行剪切出来,而该区域的短边会被放缩到256。224×224的图像区域为网络的输入尺寸。
FishNet是一个框架。它没有特定的构建模块。对于本文的实验验证结果,FishNet使用带有恒等映射的残差块[8]作为基础构建模块,FishNeXt使用带有恒等映射和组正则的残差块[29]作为基础构建模块。
4. 2 ImageNet数据集实验结果
图4展示了在ImageNet-1k验证数据集上,ResNet、DenseNet和FishNet三种方法的参数量与Top-1错误率的对比。当我们的网络使用预训练的ResNet参数作为FishNet尾部初始参数时,FishNet的性能远高于ResNet和DenseNet。
FishNet vs. ResNet。为了公平的对比,我们重新部署了ResNet,并在图4中展示了ResNet-50和ResNet-101的结果。在我们的报告中,带有恒等映射的ResNet-50和ResNet-101对于单目标识别的结果要高于原文[9]中的结果,主要原因是我们选择预训练的残差块参数作为网络的基本构建模型。与ResNet相比,FishNet显著地降低了错误率。而FishNet-150(错误率21.93%,参数量26.4M),其参数量仅接近ResNet-50(错误率23.78%,参数量25.5M),但是其性能却超过ResNet-101(错误率22.30%,参数量44.5M)。依据FLOPs(每秒浮点运算次数),如图4右所示,对比ResNet,FishNet也可以通过较低的FLOPs实现更好的识别效果。
FishNet vs. DenseNet。DenseNet通过直连接以迭代方式融合相同分辨率的特征,之后,通过过渡层减少每个密集块之间的维度。根据图4的结果,DenseNet可以使用更少的参数却能在识别精度上超越ResNet。由于FishNet保留了更好的多样性特征,以及合理的解决梯度传递问题,所以,FishNet比DenseNet的参数更少,而性能更好。此外,FishNet的存储成本也低于DenseNet。以FishNet-150为例,当在单个GPU上将批量大小设置为32时,FishNet-150的内存占有量为6506M,比DenseNet-161(9269M)的内存占有
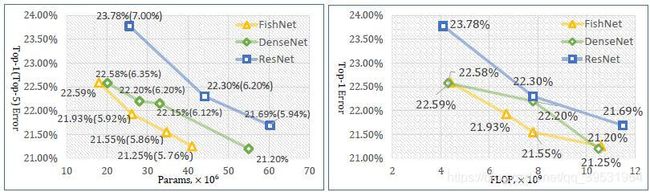
图4. 分类任务Top-1(Top-5)错误率对比展示,采用方法为FishNet、DenseNet和ResNet。使用数据集为ImageNet验证集(单目标测试)。左图为参数量作为横轴,右图为FLOPs作为横轴。
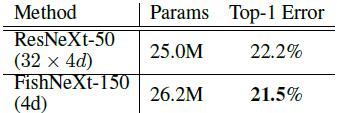
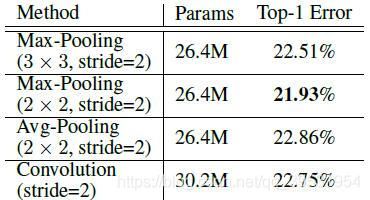
表1:对于ResNeXt的结构,其在ImageNet-1k数据集的验证集上的Top-1错误率。FishNeXt-150(4d)中的4d表示一个组中最小的信道数量为4。 表2:对于FishNet-150,采用不同下采样方法在ImageNet-1k数据集的验证集上的Top-1错误率。
量减小了2764M。
FishNeXt vs. ResNeXt。FishNet的结构可以与其他类型网络设计相结合,例如ResNet Xt采用的信道分组。我们的网络遵循的标准是,同一阶段的一组中每个模块(UR/DR模块和传输模块)的信道数应相同。当阶段指数增加1时,单个组的宽度增加1倍。这样,基于ResNet的FishNet可以构建成基于ResNeXt的网络,即FishNeXt。我们使用2600万个参数构建了紧凑模型FishNeXt-150。FishNeXt-150的参数量接近与ResNeXt-50。从表1中看出,与相应的ResNeXt框架相比,我们的网络将Top-1的错误率减少了0.7%。
4. 3消融学习
池化 vs. 卷积步长。我们探究了基于FishNet-150网络的四种下采样方式,包括卷积法、采用核尺寸为2×2和3×3的最大池化法、采用核尺寸为2×21的平均池化法。如表2所示,采用核尺寸为2×2的最大池化方法要优于其他方法。跨步卷积将会阻止梯度直接传递到浅层网络,而池化操作不会。我们还发现使用核尺寸为3×3的最大池化的识别效果要低于核尺寸为2×2的最大池化方法,原因是3×3的池化层内核存在池化重叠问题,可能会干扰网络的结构信息。
扩张卷积。Yu等人[32]发现空间视敏度的损失可能会限制图像分类的准确度。在FishNet中,UR块会稀疏原有的低分辨率特征,因此,在FishNet中采用扩张卷积。当在鱼身部使用扩张卷积核进行上采样时,对于FishNet-150网络的Top-1误差率下降了0.13%。但是,与未引入扩张卷积的模型相比,在鱼身部和头部均采用扩张卷积的情况下,绝对误差增加了0.1%。此外,我们将第一层的7×7的步幅卷积替换为两个残差块,这将Top-1误差率减小了0.18%。
4. 4 MS COCO数据集的实验研究
我们在MS COCO[20]数据集上评估了FishNet对目标检测和实例分割的泛化能力。为了公平对比,我们复现的所有模型实验均采用相同的设置,除了主干网络的参数设置不同。关于目标检测和实例分割任务,本文实验结果的代码与记录均公布在文献[1]中。
数据集与评价。MS COCO数据集[20]是目标检测和实例分割任务中最具有挑战性的数据集之一。数据集包含80个类别,并带有包围框和像素实例标注。
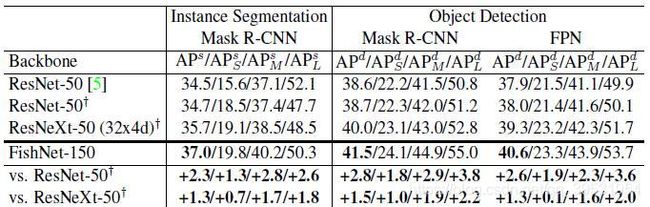
表3. MS COCO val-2017数据集,对于不同算法的的检测和分割平均精度(AP, Average Precision(%))。APs![]() 和APd
和APd![]() 分别表示分割和检测的平均精度。APS
分别表示分割和检测的平均精度。APS![]() 、APM
、APM![]() 和APL
和APL![]() 分别表示对于小目标、中目标和大目标的AP值。本文设计的主干网络分别应用与两种不同的分割和检测方法,例如Mask R-CNN[10]和FPN[21]。我们使用符号†
分别表示对于小目标、中目标和大目标的AP值。本文设计的主干网络分别应用与两种不同的分割和检测方法,例如Mask R-CNN[10]和FPN[21]。我们使用符号†![]() 表示我们复现的网络模型。FishNet-150不使用信道分组,以及它的总体参数量接近与ResNet-50和ResNeXt-50。
表示我们复现的网络模型。FishNet-150不使用信道分组,以及它的总体参数量接近与ResNet-50和ResNeXt-50。
数据集由11.8万张训练图像(train-2017)和5千张验证图像(val-2017)组成。我们在train-2017数据上进行模型训练并在val-2017数据上得出实验结果。我们使用标准的COCO评估指标AP(不同IOU阈值下的平均mAP)[10]和APs![]() 、APM
、APM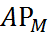 、APL
、APL![]() (不同尺度的AP值)评价所有模型。
(不同尺度的AP值)评价所有模型。
实验细节。我们在PyTorch[23]框架下重新复现了图像金字塔网络(FPN)和Mask R-CNN,并在表3中公布了复现的实验结果。我们复现的实验结果与Detectron[5](官方公布的源码)实验结果相近。包括FishNet在内,我们在16个GPU上对所有网络进行训练,批量大小为16(每一个GPU包含一批),共训练32个总轮次。训练优化方法采用SGD,初始学习率为0.02,在第20轮和第28轮次学习率衰减10倍。因为批量尺寸较小,我们整个训练过程的网络中BN层[14]为固定设置。在第1个轮次进行预训练,在前2个轮次,梯度被限制在最大超参数5.0以下,用以处理初始训练阶段较大的梯度值下降。网络的输入尺寸被固定为224×224.我们使用0.0001的权重衰减值和0.9的冲量值。网络以端到端的方式进行训练和测试。实验中的所有其他超参数均遵循文献[5]的设置。
基于FPN的目标检测结果。我们将FishNet-150作为FPN主干网络对Val-2017数据进行了验证实验,以供对比。我们将FPN自上而下的路径与侧向连接与鱼头部连接,构成整体检测网络。如图3所示,相比于ResNet-50和ResNeXt-50,FishNet-150分别取得了2.6%和1.3%的AP值增加。
基于Mask R-CNN的实例分割与目标检测结果。与FPN采用类似的处理,我们将FishNet融入Mask R-CNN同时完成目标的分割与检测。如表3所示,对于实例分割任务,与ResNet-50和ResNeXt-50相比,获得了2.3%和1.3%的AP值增加。此外,当网络以这种多任务的方式进行训练时,目标检测的性能会更好。对于目标检测任务,使用FishNet的Mask R-CNN方法,相比于ResNet-50和ResNeXt-50,AP值分别提高了2.8%和1.5%。
需要注意的是,FishNet-150不使用信道分组,FishNet-150的参数量与ResNet-50和ResNeXt-50接近。与ResNeXt-50相比,对于图像分类任务,FishNet-150仅降低了0.2%d的绝对错误率,而对于目标检测和实例分割,它分别提高了1.3%和1.5%的AP值。由此可见,FishNet为目标检测区域级任务和分割的像素级任务提供了更加有效的特征。
2018年的COCO检测挑战赛。FishNet是获胜方法的主干网络之一。通过将FishNet嵌入我们的框架中,单模型FisNeXt-229可以在测试集上对实例分割任务实现43.4%的精度。
5 结论
在本文中,我们提出新的CNN网络结构,该结构结合了针对不同级别目标识别任务的网络设计的优势。特征保存和精细化处理设计不仅有助于解决直接梯度传递问题,而且对于像素级和区域级的任务更加适用。实验结果验证了我们的网络的优点。对于未来的工作,我们将对网络进行更加细致的设置,例如每个信道/模块的数量选择,以及与其他架构的网络的集成方式。未来,我们还将会报告在两个数据集上较大模型的性能结果。
参 考 文 献
- K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, C. C. Loy, and D. Lin. mmdetection. https://github.com/ open-mmlab/mmdetection, 2018.
- Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng. Dual path networks. In Advances in Neural Information Processing Systems, pages 4470–4478, 2017.
- X. Chu, W. Ouyang, X. Wang, et al. Crf-cnn: Modeling structured information in human pose estimation. In Advances in Neural Information Processing Systems, pages 316–324, 2016.
- P. Gao, H. Li, S. Li, P. Lu, Y. Li, S. C. Hoi, and X. Wang. Question-guided hybrid convolution for visual question answering. arXiv preprint arXiv:1808.02632, 2018.
- R. Girshick, I. Radosavovic, G. Gkioxari, P. Dollár, and K. He. Detectron. https://github.com/facebookresearch/detectron, 2018.
- P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch sgd: training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and finegrained localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 447–456, 2015.
- K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In European Conference on Computer Vision, pages 630–645. Springer, 2016.
- K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEE International Conference on, pages 2980–2988. IEEE, 2017.
- J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507, 2017.
- G. Huang, D. Chen, T. Li, F.Wu, L. van der Maaten, and K. Q.Weinberger. Multi-scale dense convolutional networks for efficient prediction. arXiv preprint arXiv:1703.09844, 2017.
- G. Huang, Z. Liu, K. Q. Weinberger, and L. van der Maaten. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017.
- S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
- J.-H. Jacobsen, A. Smeulders, and E. Oyallon. i-revnet: Deep invertible networks. arXiv preprint arXiv:1802.07088, 2018.
- E. Kim, C. Ahn, and S. Oh. Nestednet: Learning nested sparse structures in deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8669–8678, 2018.
- A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- G. Larsson, M. Maire, and G. Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. arXiv preprint arXiv:1605.07648, 2016.
- H. Li, Y. Liu, W. Ouyang, and X. Wang. Zoom out-and-in network with map attention decision for region proposal and object detection. International Journal of Computer Vision, Jun 2018. ISSN 1573-1405. doi: 10.1007/s11263-018-1101-7. https://doi.org/10.1007/s11263-018-1101-7.
- T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
- A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision, pages 483–499. Springer, 2016.
- A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch. 2017.
- O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, 2015.
- K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- S. Sun, Z. Kuang, L. Sheng, W. Ouyang, and W. Zhang. Optical flow guided feature: A fast and robust motion representation for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1390–1399, 2018.
- C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, et al. Going deeper with convolutions. In CVPR, 2015.
- S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pages 5987–5995. IEEE, 2017.
- W. Yang, S. Li, W. Ouyang, H. Li, and X. Wang. Learning feature pyramids for human pose estimation. In arXiv preprint arXiv:1708.01101, 2017.
- Y. Yang, Z. Zhong, T. Shen, and Z. Lin. Convolutional neural networks with alternately updated clique. arXiv preprint arXiv:1802.10419, 2018.
- F. Yu, V. Koltun, and T. Funkhouser. Dilated residual networks. In Computer Vision and Pattern Recognition, volume 1, 2017.
- F. Yu, D. Wang, and T. Darrell. Deep layer aggregation. arXiv preprint arXiv:1707.06484, 2017.
- S. Zagoruyko and N. Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
- X. Zeng, W. Ouyang, B. Yang, J. Yan, and X. Wang. Gated bi-directional cnn for object detection. In European Conference on Computer Vision, pages 354–369. Springer, 2016.
- S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 1529–1537, 2015.
37. H. Zhou, W. Ouyang, J. Cheng, X. Wang, and H. Li. Deep continuous conditional random fields with asymmetric inter-object constraints for online multi-object tracking. IEEE Transactions on Circuits and Systems for Video Technology, 2018
论文格式有问题,日后改进