python-opencv学习笔记(七):滑动窗口与图像金字塔
引言
本节内容是我在实验楼所做实验,结合opencv官方对于这两种方法的例子与说明,想总结一些关于自己的笔记,也算是更系统的学习了yolo的运行方式。
滑动窗口
滑动窗口(Sliding Windows)在目标检测过程中的作用是定位目标(物体、动物等)在图片中的位置。在计算机视觉中滑动窗口是一个矩形框,它沿着从左向右、从上向下的方向在图片上滑动以达到提取出图片中每一个区域的目的。下图就是一个滑动窗口的例子,可以看到一个绿色矩形框沿着从左向右、从上向下的方向在图片上滑动。对于矩形框滑过的每一区域,我们使用分类器来判断该区域中是否存在物体。
滑动窗口的代码比较简单,先导入所需要的包:
import cv2
from matplotlib import pyplot as plt
from IPython import display
%matplotlib inline
然后我们定义一个函数 sliding_window 用于获取滑动窗口。这个函数有三个参数 image、window 和 step。
- 第一个参数
image是输入函数的图片,我们将用矩形框在这个图片上滑动。 - 第二个参数
window是一个元组,表示滑动的矩形框的高和宽。 - 第三个参数
step表示矩形框间隔多少个像素移动一次,这里我们可以称之为步长。
下图中我们用三种颜色表示不同位置的同一矩形框,图中的 n 就表示矩形框每次移动 n 个像素的距离,step 设置的太小或太大都会对目标检测造成负面的影响,一般这个值会设置在 4 到 8 之间。

所以代码为:
def sliding_window(image, window, step):
for y in range(0, image.shape[0] - window[1], step):
for x in range(0, image.shape[1] - window[0], step):
yield (x, y, image[y:y + window[1], x:x + window[0]])
想要实现矩形框在图片上滑动,我们需要知道矩形框每次滑动位于图片中的位置。我们使用两个 for 循环获取矩形框的所有坐标位置。第一个 for 循环控制矩形框以 step 的步长在图片中上下移动,第二个 for 循环控制矩形框以 step 的步长在图中左右移动。最后通过 yield 生成器返回一个元组,其中元组的第一个元素 x 和第二个元素 y 表示矩形框左上角的坐标,元组的第三个元素 image[y:y + window[1], x:x + window[0]] 就是处在图片中不同位置的矩形框。
接下来我们使用 cv2.imread 函数读取图片,pets.jpg 是要读取的图片名。然后我们定义滑动窗口的宽 window_w 为 400 个像素,滑动窗口的高 window_h 为 400 个像素。我们使用 n 来表示滑动窗口的数量。
image = cv2.imread("pets.jpg")
(window_w, window_h) = (400, 400)
接下来使用一个 for 循环来遍历每一个滑动窗口,我们需要传递三个参数给 sliding_window。
- 第一个参数
image是我们读取的图片。 - 第二个参数
(window_w, window_h)表示滑动窗口的宽和高。 - 第三个参数
200表示滑动窗口将每次滑动的步长为200个像素(注意这里为了演示方便将滑动窗口和步长的值设置得都很大,在实际使用中不建议将其设置过大或过小)。
然后我们使用一个 if 语句来判断获得的滑动窗口和我们设定的滑动窗口大小是否一致,如果滑动窗口截取的区域与设定的 (window_w, window_h) 中任意一个元素不同,则执行 continue 跳过该滑动窗口。
for (x, y, window) in sliding_window(image, (window_w, window_h), 200):
if window.shape[0] != window_w or window.shape[1] != window_h:
continue
clone = image.copy()
cv2.rectangle(clone, (x, y), (x + window_w, y + window_h), (0, 255, 0), 2)
clone = clone[:,:,::-1]
plt.imshow(clone)
plt.pause(0.1)
display.clear_output(wait=True)
在循环内我们绘制出图片中每一个滑动窗口了,在绘制前使用 copy 函数复制输入函数的图片,因为接下来的画图操作将会修改源图片,接着我们使用 cv2.rectangle 在 clone 上绘制出每个滑动窗口。因为在 OpenCV 图片是以 B,G,R(蓝,绿,红)的通道顺序存储的,而在 Matplotlib 中图片是以 R,G,B 的通道顺序存储,所以我们使用 clone[:,:,::-1] 切片方法来跳转图片通道的顺序,然后使用 plt.imshow 在页面中呈现绘图后的结果。
因为我们在 for 循环内要绘制多张图片,所以使用 plt.pause(0.1) 让每张图片显示暂停一段时间,函数的参数 0.1 表示暂停 0.1 秒。最后我们使用 display 的 clear_output(wait=True) 方法清除已经显示的图片为下一张图片显示做准备。
在pycharm中可以看到动态图以及右边每一帧对应的组图:
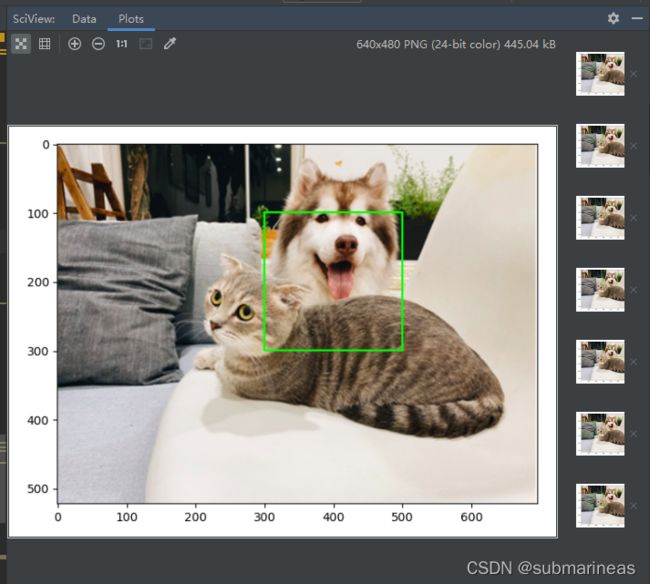
因为我们在 for 循环内要绘制多张图片,所以使用 plt.pause(0.1) 让每张图片显示暂停一段时间,函数的参数 0.1 表示暂停 0.1 秒。最后我们使用 display 的 clear_output(wait=True) 方法清除已经显示的图片为下一张图片显示做准备。
// An highlighted block
var foo = 'bar';
图像金字塔
图像金字塔简单来说就是用多个不同的尺寸来表示一张图片。如下图,最左边的图片是原始图片,然后从左向右图片的尺寸依次缩小直到图片的尺寸达到一个阈值,这个阈值就是多次缩小图片的最小尺寸,不会有比这更小尺寸的图片了,像这种图片的尺寸逐步递增或递减的多张图层就是图像金字塔,每张不同尺寸的图片都称为图像金字塔的一层。图像金字塔的目的就是寻找图片中出现的不同尺寸的目标(物体、动物等)。

图像金字塔一般有两种类型:
- 高斯金字塔(Gaussianpyramid):用来向下采样,是主要的图像金字塔。
- 拉普拉斯金字塔(Laplacianpyramid):用来从金字塔底层图像重建上层未采样图像,在数字图像处理中也就是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。
opencv对此有封装好两种api,分别为cv2.pyrUp()、cv2.pyrDown()函数,我们可以用它生成与上面对应的图片:

所用代码如下:
img = cv2.imread('pets.jpg')
up_img = cv2.pyrUp(img) # 上采样操作
img_1 = cv2.pyrDown(img) # 下采样操作
img_2 = cv2.pyrDown(img_1)
# cv2.imshow('up_img', up_img)
cv2.imshow('img', img)
cv2.imshow('img_1', img_1)
cv2.imshow('img_2', img_2)
cv2.waitKey(0)
cv2.destroyAllWindows()
至于金字塔的原理,我们可以创建了一个名为 pyramid 函数,这个函数将用来生成图像金字塔,这个函数有三个参数,如下所示。
- 第一个参数
image是要进行图像金字塔操作的原始图片。 - 第二个参数
top是图像将会被缩小的最小尺寸,我们将这个参数设置一个默认值为(128, 128),第一个128表示图片的高,第二个128表示图片的宽。 - 第三个参数
ratio表示每次图像将会被缩小ratio倍,我们给这个参数设置了一个默认值为1.2。
def pyramid(image, top = (128, 128), ratio = 1.2):
yield image
while True:
(w, h) = (int(image.shape[1] / ratio), int(image.shape[0] / ratio))
image = cv2.resize(image, (w, h), interpolation = cv2.INTER_AREA)
if w < top[1] or h < top[0]:
break
yield image
在函数内我们首先使用 yield 生成器返回原始图片,因为在图像金字塔的最底端我们需要一张原始图片。然后使用 while 循环来不断缩小图片尺寸。直到缩小后图片的尺寸比前面的 top 参数小为止。在循环内 (w, h) 表示图像金字塔前一层的图像缩小 ratio 倍的宽和高。我们使用 cv2.resize 方法将前一层图片进行缩放,我们将 (w, h) 作为函数的第二个参数,表示缩放后图片的宽和高的值。
随着图片的尺寸不断缩小,我们使用 if 语句判断图片的尺寸是否已经到达了设定的最小尺寸,将每次图片缩放后的宽和高与设定的最小尺寸 top 进行对比,如果小于最小尺寸则使用 break 结束循环。最后使用 yield 生成器返回每次缩放后的图片。至此图像金字塔的函数就构建完成了。
for i in pyramid(image, ratio = 1.5):
i = i[:,:,::-1]
plt.imshow(i)
plt.pause(0.3)
display.clear_output(wait=True)

可以看到坐标轴在变动,分辨率在变模糊因为在下采样,如果想做和上面一样的组图,可以加一个容器copy下每一张变动的图,结束for循环后进行弹出展示,这里就不再演示了。
图像金字塔结合滑动窗口
在传统的目标检测方法中,使用图像金字塔和滑动窗口相结合的方式来检测出图片中不同位置和不同尺寸的目标。使用滑动窗口的方法时,在图片上滑动的矩形框尺寸是固定的,这就导致了如果目标的尺寸相对于矩形框太大或太小都会导致我们无法检测到目标。这种情况下,我们可以在图像金字塔的每层图片上进行滑动窗口的操作来解决这个问题。如下图左边的图片,狗并不能完全被矩形框包围,矩形框只能包住狗的部分面部区域;下图右边的图片,通过运用图像金字塔和滑动窗口相结合的方法,矩形框的尺寸没有变化,但是在经过缩小后的图片中狗完全被矩形框包裹住了。

那么,综合上述滑动窗口 + 图像金字塔两个方法,就能让矩形框的尺寸保持不变,但是随着图片地不断缩小,矩形框逐渐包裹住目标。
for i in pyramid(image, ratio = 1.5):
for (x, y, window) in sliding_window(i, (window_w, window_h), 100):
if window.shape[0] != window_w or window.shape[1] != window_h:
continue
clone = i.copy()
cv2.rectangle(clone, (x, y), (x + window_w, y + window_h), (0, 255, 0), 2)
clone = clone[:,:,::-1]
plt.imshow(clone)
plt.pause(0.01)
display.clear_output(wait=True)
