C语言复习?C语言二级考试?不要怕,从常考知识点到常考算法,C语言基础看我这一篇就足够了
C语言复习总结!!!
一、C语言程序结构:
从解析一个C语言源文件开始
#include1、内容
① 预处理命令:#include
② 函数定义:
- 函数首部: 函数类型 函数名(参数)
- 函数体:函数体可以存在引用函数的声明,变量的声明,函数的执行
2、运行步骤
编辑源程序:敲代码
使用预处理器对源程序进行编译:将头文件中的内容读入该源程序,检查有无语法错误,无语法错误则转换为二进制目标文件
进行连接处理:二进制目标文件不能供计算机执行,需要将编译得到的所有目标文件连接起来,生成一个可执行程序exe
运行可执行程序
3、算法
对数据操作的步骤便是算法
程序 = 算法 + 数据结构
可分为两类:数值运算算法和非数值运算算法
设计结构化程序:自顶向下,逐步细化:即先搭建框架,再填充框架内容
二、数据类型、及其运算与输出
1、数据表现形式
① 常量:
-
整型常量:整数
-
实型常量:小数
-
字符常量:普通字符,如’A’;转义字符,如’\t’,’\n’,’\a’,’\b’,’\r’,’\o’,’\v’,’\f’,’"’
//转义字符,如
'\t':水平制表符,'\n':换行符,'\a':警告,'\b':退格,'\r':回车-光标移到本行开头,'\v':垂直制表符,'\f':换页,'\"':双引号,'\?':问号,'\'':单引号,'\xh[h...]':十六进制,'\o':八进制
-
字符串常量:如"sos"
-
符号常量:#define指令自己定义的常量
#define PI 3.1415926 //行末无分号
② 常变量:
用const关键字修饰的变量
#define float pi=3.1415926;
//常变量占用存储单位,有变量值。符号常量不分配存储单元
③ 变量:先定义使用
④ 标识符:即名字:由字母、数字、下划线组成,且第一个字符必须为字母或下划线
2、数据类型
C语言数据类型的大小会根据操作系统的变化而变化,不必记忆
整型:
① 基本整型(int)
大小:一般为4个字节
存储方式:用整数的补码式存放,正数的补码是此数的二进制形式,负数的补码是此数绝对值的二进制形式,按位取反再加1。
② 短整型(short int\short)
大小:一般为2个字节
存储方式:同基本整型的存储方式
③ 长整型(long int\long)
大小:一般为4个字节
④ 双长整型(long long int\long long)
大小:一般为8个字节
属性:
该属性只有整型和字符型有,且在java语言中无该表达形式
unsigned可修饰整型变量,表示为无符号,即正整数
整型变量默认被signed修饰,表示有符号
2、字符型:
表示:
char c = 'x';
//c称为字符变量
//'x':在''中放置一个字符的数据类型称为字符型
范围:
所有的ASCII代码最多用7个二进制就可以表示
signed:-128~127
unsigned:0~255
3、浮点型
① 单精度浮点型(float型)
大小:4个字节,得到6位有效数字
② 双精度浮点型(double型)
C编译系统把浮点型常量都按双精度处理
大小:8个字节,得到15位有效数字
③长双精度浮点型(long double型)
大小:16个字节或者8个字节,15或者19位有效数字
3、运算符
1、运算符优先级需要牢记
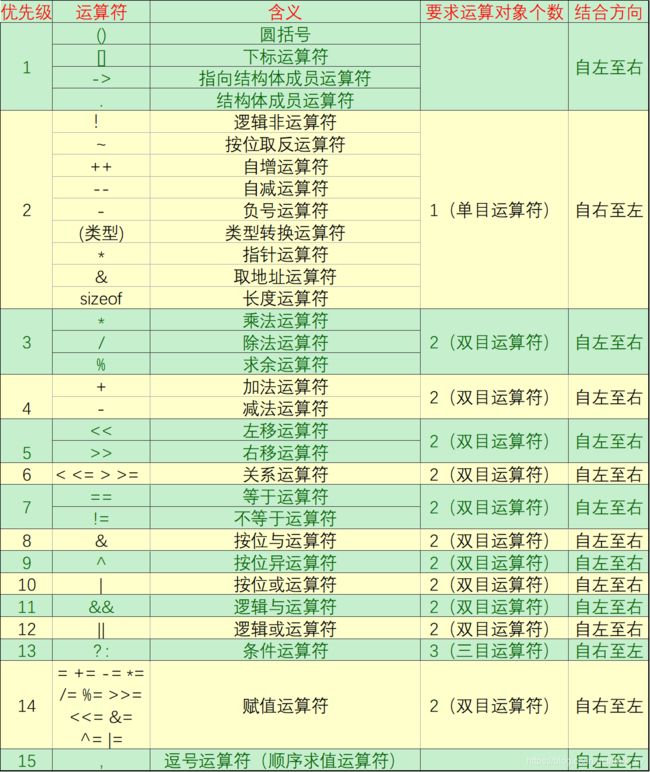
2、混合运算规则
在算术运算中,计算的数据有多个类型时,以精度最高者为准
当字符型与整型进行运算时,字符会自动转换为对应的整型:‘A’:65 ; ‘a’:97
3、强制类型转换运算符:(数据类型)
进行强制类型转换时,得到一个所需的中间数据,对原变量无影响
(int)x + y;//该语句是先将x转换为整型再+y
4、赋值过程中的类型转换:
类型一致直接赋值,可在声明变量时赋初值
类型不一致,由系统自动进行(在java语言中,从高精度到低精度需要强制转换,但在c语言中由系统自动完成)
当double型赋值给float型如果超出了其范围,则会报错;
要避免把占字节多的整型数据,向占字节少的整型变量赋值,因为赋值后可能失真,例如
int a = 32767;
short b;
b = a+1;
//理论上b应该为32768,但是输出为-32768
4、数据的输入输出
c语言不提供输入输出函数,所以需要#include"stdio.h"
1、输入符:scanf
scanf("%x",&a);
//变量a前需要使用地址符&,这样输入的数据会找到该存储单元,赋值给变量a
//输入时,如果有多个变量,在两个数之间用空格隔开,输入后会根据%后面的数据类型输入
输入时:
scanf("a=%f,b=%f,c=%f",&a,&b,&c);//a=1,b=3,c=2:当遇到除了格式声明以外还有其它字符时,则在输入数据时在对应的位置上应输入与这些字符相同的字符,其中的逗号是与前者中的逗号对应
scanf("%c%c%c",&a,&b,&c);//abc,不得有空格因为空格也算一个字符
scanf("%d%c%f",&a,&b,&c);//遇到非法字符结束当前输入
2、输出符:print
printf("%x",a);
//输出与出入不同,此处只需要传入变量,这样print函数只会输出其值,不会对a进行内容的修改
当输入变量时,必须使用该格式,不能直接输出
3、格式符
%d,i:用来输出有符号的十进制整数(包括char类型)
%u:用来输出无符号的十进制整数(包括char类型)
%o:用来输出无符号的八进制整数
%x,X:用来输出无符号的十六进制整数
%c:用来输出单个字符
%s:用来输出一个字符串
%f:用来输出小数形式的十进制浮点数(输入时小数形式和指数形式都可以识别)
%e,E:用来输出指数形式的十进制浮点数(输入时小数形式和指数形式都可以识别)
%g,G:用来输出指数形式和小数形式两者中较短的十进制浮点数(输入时小数形式和指数形式都可以识别)
print中的格式附加符
① - :有-表示左对齐输出,如省略表示右对齐输出。
② 0 :有0表示指定空位填0,如省略表示指定空位不填。
③ m.n :m指域宽,若数据的位数小于m,则左端补空格,若大于m,则按实际位数输出。
n指精度,用于说明输出的实型数的小数位数。未指定n时,隐含的精度为n=6位。
④ l或h :l对整型指long型,对实型指double型。h用于将整型的格式字符修正为short型。可加在格式符d\o\x\u前
4、字符输入输出函数
输出:putchar©;
输入:getchar();输入时,按先后顺序输入,再按下enter键,不要输入完一个字符就按下enter键,这样enter键也会作为一个字符进行输入。
三、数组
1、数组的定义
//一维数组的定义:类型符 数组名[常量表达式]
int a[10];
//二维数组的定义:类型符 数组名[常量表达式][常量表达式]
int a[10][2];
注意:
C语言不允许对数组的大小作动态定义,即数组的大小不依赖程序允许过程中变量的值。即int a[n]不合法。
数组中的下标从0开始。
2、数组的初始化
//一维数组的初始化
//全部赋予初始值
int a[5] = {1,1,1,1,1};
//给一部分赋值
int a[5] = {1,1};//自动给后面三个元素赋初值0
//全部赋初始值时:
int a[] = {1,1,1,1,1};//默认a的大小为5
//二维数组的初始化
//分行给二维数组赋值
int a[3][2] = {{1,2},{3,4},{5,6}}
//不分行给二维数组赋值
int a[3][2] = {1,2,3,4,5,6};//自动按顺序分行,结果同上
//给一部分赋值
int a[3][4] = {{1},{1},{1}}//相当于一维数组中放置一维数组
int a[3][4] = {{1},{},{1}}
//当赋初值时,可以通过给第一层数组赋值而省略其长度,第二维的长度不可省略
int a[][4] = {{1},{},{1}}
注意:
如果是字符型数组则初始化的默认初始值为’\0’,如果是指针型则初始化为NULL。
3、数组的引用
//引用形式 数组名[下标]
t = a[2];
a[2][1] = b[3][1];
注意:
数组元素的下标从0开始,定义数组时
定义数组时的 int a[3] [2] 与引用时的a[3] [2]不同,一个定义大小,一个指向具体的内存空间
4、字符数组
① 字符数组的定义
char a[10];
//合法但浪费空间:因为字符型也是整数形式存放,因此可以用整型数组存放字符数据
int c[10];
c[0] = 'a';
② 字符数组的初始化
//将字符依次赋值
char a[3] = {'i','l','u'};
//部分赋值
char a[3] = {'i'};//会自动将后面的元素默认为'\0'
//省略定义的大小
char a[] = {'i','l','u'};
③ 字符数组的引用
//同一般数组,通过下标进行引用
for(i=0;i<3;i++)
printf("%c",a[i]);
④ 字符串和字符串结束的标志
在C语言中,将字符串作为字符数组来处理,并不像java中有String类可以定义字符串。
在实际工作中,字符串的有效长度往往与字符数组的有效长度不同,所以C语言规定了一个“字符串结束标志”——’\0’
例如
//1
char c[] = "cnm";
//这里使用字符串作为初始值,此时数组的长度为4而不是3,因为字符串常量的最后由系统默认增加'\0',相当于:
char c[] = {'c','n','m','\0'}
//2
char c[5] = {"cnm"};
//相当于:
char c[] = {'c','n','m','\0','\0'}
//3
char c[3] = {'c','n','m'}
//这样的表示完全合法,是否需要加'\0'根据需求而定
//4
char c[5] = {"cnm"};
c[0] = 'h';
c[1] = '\0';
//在输出字符串时,遇到'\0'就停止输出
⑥ 字符串的输入与输出
输入
//逐个输出
printf(%c,c[0]);
//整个字符串输出
printf("%s",c);
//执行实际:系统按字符数组名c找到该数组第一个元素的地址,然后逐个输出其中的字符,知道遇到'\0'
printf("%o",c);//可输出该数组的起始地址
注意:
输出的字符不包括’\0’
用%s输出字符串时,输出项必须是字符串数组名,而不是数组元素名,即c是字符串数组名与c[0]是数组元素名
当数组长度大于字符串实际长度时,遇到’\0’停止输出
如果字符数组包含多个’\0’,遇到第一个便停止输出
输出
char c[6];
scanf("%s",c);
注意:
输入项为已定义的字符数组名,输入的字符应短于已定义的字符数组的长度,系统会自动在后面加’\0’,如果依次输入多个字符串时,输入时用空格分隔,数组中未被赋值的元素的值自动为’\0’。
当输入单个字符串时,空格会作为一次输入的结束标志,即针对上述代码,输入:c n m,只会存入c, n m不会存入。
数组输入输出,数组名前不加&,因为数组名在C语言中代表该数组第一个元素的地址。
⑦ 使用字符串处理函数
//puts(一个字符数组):输出字符串
char str[]={"i love\nyou"}
//puts将结束标志转换为\n,即输出完自动换行
//gets(一个字符数组):输入字符串
gets(str);
//输入的字符个数:输入个数+1
//strcat(字符数组1,字符数组2):字符串连接
strcat(str1,str2);
//将str2拼接到str1中,所以str1要足够大到可以容纳str2,连接时str1的'\0'取消
//strcpy(字符数组1,字符串2):将字符串2赋值到字符数组1中,所以字符数组1要足够大
//strncpy(字符数组1,字符串2,n):将字符串2的前n个字符赋值到字符数组1中,所以字符数组1要足够大
//strcmp(字符串1,字符串2):比较两字符数组大小,逐个字符比较知道不相同或到'\0'
//相同返回0,前者大返回正整数,后者大返回负整数
//stelen(字符数组)
//返回字符串的实际长度,即不包含'\0'
//strlwr(字符串):转换并返回小写
//struor(字符串):转换并返回大写
四、选择与循环结构
1、if
if(表达式),表达式可以为关系表达式、逻辑表达式、还可以是数值表达式,最直观的为关系表达式,以下同理
#include<stdio.h>
int main(){
int a=0;
scanf("%d",&a);
if(a>10){
printf("%d",a);
}
printf("if 语句已经执行完毕");
}
2、if - else
#include<stdio.h>
int main(){
int a=0;
scanf("%d",&a);
if(a>10){
printf("条件成立,输入值是 %d",a);
}else{
printf("条件错误,输入值是 %d",a);
}
}
3、if - else if
#include<stdio.h>
int main(){
int a=0;
scanf("%d",&a);
if(a==1){
printf("a是 %d",a);
}else if(a==2){
printf("a是 %d",a);
} else if(a==3){
printf("a是 %d",a);
} else if(a==4){
printf("a是 %d",a);
} else{
printf("条件都不对");
}
}
依次判断表达式的值,当出现某个值为真时,则执行对应代码块,否则执行else后的代码块。
注意:当某一条件为真的时候,则不会向下执行该分支结构的其他语句。
4、while
#include<stdio.h>
int main(){
int a=0;
while(a<10){
printf("重复\n");
a=a+1;
}
}
5、for
for可在表达式1中初始化循环变量,在表达式2中设立循环结束条件,在表达式三中使循环趋于结束
-
省略“表达式1(循环变量赋初值)”,表示不对循环变量赋初始值。
-
省略“表达式2(循环条件)”,不做其它处理,循环一直执行(死循环)。
-
省略“表达式3(循环变量增减量)”,不做其他处理,循环一直执行(死循环)。
-
表达式1可以是设置循环变量的初值的赋值表达式,也可以是其他表达式。
-
表达式1和表达式3可以是一个简单表达式也可以是多个表达式以逗号分割。
#include<stdio.h>
int main(){
int a=0;
for(a=0;a<10;a++){
printf("重复\n");
}
}
它的执行过程如下:
- 执行表达式1,对循环变量做初始化;
- 判断表达式2,若其值为真(非0),则执行for循环体中执行代码块,然后向下执行;若其值为假(0),则结束循环;
- 执行表达式3,(i++)等对于循环变量进行操作的语句;
- 执行for循环中执行代码块后执行第二步;第一步初始化只会执行一次。
- 循环结束,程序继续向下执行。
注意:for循环中的两个分号一定要写
6、do - while
while和dowhile中循环变量的初始化操作应该在其语句前完成,使用do-while结构语句时,while括号后必须有分号。
#include "stdio.h"
void main()//求各
{
//定义变量并初始化
int i=1;
int sum=0;
do
{
sum+=i;
i+=1; //步长
} while(i<=100); //条件表达式
printf("和是%d",sum);
}
7、switch
switch(表达式)中,表达式应该为整数类型(包括字符类型),在case后的各常量表达式的值不能相同,否则会出现错误。在case后,允许有多个语句,可以不用{}括起来。
若无break,会持续进行之后的语句
可以没有default语句(如果case一个都没执行,转向default语句),且default语句中可以不加入break语句,
#include8、continue与break
只希望终止本次循环:continue
希望提前终止整个循环:break
终止只针对所在的循环体中,例如嵌套循环语句,如果break在内循环体中,则只对内循环有效。
五、函数
1、函数的定义
① 定义方法
类型名 函数名(void){
函数体();
}//无参数时,void可以省略,有参数可替换
2、函数的调用
在一个函数中调用另外一个函数需要:
- 被调用函数必须是已经定义了的函数
- 使用库函数时,应在开头使用#include指令将库导入
- 如果使用自己定义的函数,当该函数的位置在调用它的函数(即主调函数)之后,应在主调函数中对被调函数作声明。
//函数声明:不包含参数体,只有函数首部
类型名 函数名(形参类型1 参数名1,形参类型2 参数名2);
类型名 函数名(形参类型1,形参类型2);//声明时可省略参数名
//函数调用
函数名(实参);
3、函数的参数(调用时的数据传递)
① 参数传递
虚实结合:实参与形参之间的数据传递
实参向形参的数据传递是“值传递”,单向传递。只能由实参传给形参,而不能由形参传给实参。
函数调用过程:在函数发生调用时,函数的形参临时分配内存>>>将实参的值拷贝传递给对应形参>>>通过return语句将函数值带到主调函数(void类型函数不执行),形参单元被释放。
② 函数的返回值
函数类型决定返回值类型
- 返回值通过return获得
- 定义函数时,指定的函数类型一般应该和return语句中的表达式一致
- 如果函数类型和return语句的类型不一致,以函数类型为准,对数组型数据自动进行转换
- 无返回值函数,应定义为void类型
4、数组作为函数参数
① 数组元素作实参
数组元素可用作函数实参,不能作形参:因为形参在函数被调用时临时分配存储单元,不能为一个数组元素单独分配存储单元。在用数组元素作函数实参时,把实参的值传给形参,是值传递的方式。
② 数组名作实参和形参
-
用数组名作函数实参时,向形参传递的是数组首元素地址
-
用数组名声明形参时,不需要指定大小,因为C语言编译系统不检查形参数组的大小,只是将实参数组的首元素的地址传给形参数组名。所以形参数组可以不指定大小,在定义数组时在数组名后跟一个空的方括号。
-
用指针变量或者数组作为形参,二者等价。
③ 多维数组名作函数参数
-
在多维数组作函数参数时,可以省略第一维的大小说明,但是第二维以及更高维的大小声明不能省略。
因为在内存中,多维数组是按行存放,定义二维数组时必须指定列数,由于形参数组与实参数组类型相同,所以它们应是具有相同长度的一维数组组成。
-
在第二维大小相同的前提下,形参数组的第一维可以与实参数组不同。
5、局部变量与全局变量
局部变量:函数内部定义的变量,只在本函数范围内有效。所以不同函数中的变量同名也互不干扰,形参也是局部变量。
全局变量:函数外部定义的变量,有效范围从定义的范围到源文件结束为止。
6、变量的存储方式和生存期
用户使用的存储空间分为程序区、静态存储区、动态存储区
① 动态存储方式和静态存储方式
静态存储区:全局变量
动态存储区:形参、无static关键字的局部变量,即自动变量、函数调用时的现场保护和返回地址
② 局部变量的存储类别
| 存储类别 | ||
|---|---|---|
| 自动变量(auto变量) | 动态存储类别—动态存储区 | 在函数被调用时分配存储空间,在调用结束时释放存储空间 |
| 静态局部变量(static局部变量) | 静态存储类别—静态存储区 | 整个运行期间都不释放,在编译时赋初值一次,每次被函数被调用不重新赋值,保留上一次函数调用结束时的值,不赋初值的话,编译时自动赋值0或’\0’。但是依旧属于局部变量,属于不允许其它函数引用它。 |
| 寄存器变量(register变量) | 存储在CPU的寄存器中 | 方便多次重复性调用该变量 |
③ 全局变量的存储类别
对于全局变量来说,都是存储在静态存储区,但是其作用域有整个文件范围和文件部分范围之分。
-
在文件内扩展:
如果外部变量不在文件开头定义,其有效范围只限于其定义处到文件结束。如果在其定义前想使用该外部变量,则需要使用extern对该变量作外部变量声明,表示将该外部变量作用域扩展到此处。
int main(){ extern int A; return A; } int A; -
扩展到其它文件:
一个C程序可由多个源文件组成,如果两个文件中要用到同一个外部变量,不能分别定义
是在一个文件中定义一个外部变量,再在另外一个文件中使用extern对该外部变量进行重新声明,即作“外部变量声明”。这样可以将另外一个文件的外部变量的作用域扩展到本文件。
当编译遇到extern时,先在本文件找到外部变量的定义,找到就引用本文件的变量,找不到则在连接时从其它文件中找外部变量的定义。
-
将外部变量作用域限制在本文件
在定义外部变量时加一个static声明,这样就算再另外一个文件中使用是extern也不能扩展其作用域,这样只能用于本文件的外部变量称为静态外部变量。
static对外部变量产生的作用是作用域的限制(本文件),而对局部变量是存储类别的变化(变为静态存储,不释放)
结论注意:在函数中出现的对变量的声明(除了用extern声明的以外)都是定义。在函数中对其它函数的声明不是函数的定义。
④ 内部函数与外部函数
-
内部函数:
static 类型名 函数名(形参){}
在定义函数时,再类型名前加static使之不能被其它文件引用,称为内部函数
-
外部函数:
extern 类型名 函数名(形参){}
在定义函数时,在函数首部最左端加上extern,则该函数可以为其它文件所调用。在需要调用此函数的其它文件中,依然需要对函数作声明。由于函数在本质上是外部的,所以可以省略extern
六、指针
1、指针与指针变量
① 概念
指针 = 变量的地址 >指针指向变量的内容
指针变量 = 存放地址的变量 >指针变量指向变量的地址
② 定义
指针变量与其它变量一样,在定义时可以赋值,即初始化。也可以赋值“NULL”或“0”,如果赋值“0”,此时的“0”含义并不是数字“0”,而是 NULL 的字符码值。
//类型名 *指针变量
int *pointer = 0;
int a = 100;
int *pointer;
pointer = &a;
*pointer = 6;
指针变量是基本数据类型派生的类型,不能离开基本类型而独立存在,所以定义指针变量时必须指定其“基类型”
此处 pointer是指针变量的名字,int *pointer是表示定义了一个指针变量名为pointer, *pointer = 6表示指向该地址的内容更改为6,相当于把6赋值给a
指针变量只能存放地址,不能赋其它的值
③ 指针变量作为函数参数
当指针作为函数的参数时,它的作用是将一个变量的地址传送到另一个函数中,因为函数传值的机制是拷贝值,当拷贝的值为地址时,就能操作到“原件”。函数的调用至多能得到一个返回值,而使用指针变量作为参数,可以得到多个变化的值。
但是不能企图通过改变指针形参的值,而使指针的实参改变。
//错误
void swap(int *p1,int *p2){
int *p;
p=p1;
p1=p2;
p2=p;
}
//正确
void swap(int *p1,int *p2){
int p;
p = *p1;
*p1 = *p2;
*p2 = temp;
}
在指针变量作为形参时,应当给该参数传地址,这样通过*运算符,才能修改到具体的内存空间中的内容
④ 取地址运算符与指针运算符
* :指针运算符——间接访问运算符
& :取址符,&变量名 即可取到该变量的地址
- 取地址运算符&:单目运算符&是用来取操作对象的地址。例:&i 为取变量 i 的地址。对于常量表达式、寄存器变量不能取地址(因为它们存储在存储器中,没有地址)。
- 指针运算符*(间接寻址符):与&为逆运算,作用是通过操作对象的地址,获取存储的内容。例:x = &i,x 为 i 的地址,*x 则为通过 i 的地址,获取 i 的内容。
“&”和“*”都是右结合的。假设有变量 x = 10,则&x 的含义是,先获取变量 x 的地址,再获取地址中的内容。因为“&”和“”互为逆运算,所以 x = &x。
⑤ 指针运算
- 指针变量可以互相赋值,也可以赋值某个变量的地址,或者赋值一个具体的地址
- 指针变量的自增自减运算。指针加 1 或减 1 运算,表示指针向前或向后移动一个单元(不同类型的指针,单元长度不同,即不同类型,地址的值加不同的字节数)。这个在数组中非常常用。
- 指针变量加上或减去一个整形数。和第一条类似,具体加几就是向前移动几个单元,减几就是向后移动几个单元。
- px > py 表示 px 指向的存储地址是否大于 py 指向的地址
- px == py 表示 px 和 py 是否指向同一个存储单元
- px == 0 和 px != 0 表示 px 是否为空指针
2、指针与数组
① 数组元素的指针
数组元素的指针=数组元素的地址:数组名代表数组首元素的地址
所以数组名是一个指针型常量
int *p;
int a[3];
p = a;
//这是将a[0]的地址赋给p
② 指针指向数组元素时的运算
- 当指针变量p指向数组的某一个元素时,p+1表示指向下一个元素:此处不是简单的将地址加1,而是加上一个数组元素所占用的字节数。
- 当p=&a[0]时,*(p+i)= *(a + i) = a[i]:[]实际上是变址运算符,即将a[i]按a+i计算地址
- 当p1、p2指向同一个数组,p2-p1的结果是两地址的差值除以数组元素的长度,这代表p2和p1之间差2个元素,即他们的相对距离,但是两个地址(p1+p2)之间不能相加,无意义。
③ 通过指针引用数组元素
//1、下标法
a[i];
//2、指针法
*(a+i);//a为数组名
*(p+i);//p为指向数组元素的指针变量,初值为p=a
注意:可以通过p++来实现对数组的遍历,而不能通过a++来实现,是因为a作为数组名实际是一个指针型常量,而不是变量,所以a++是无意义的。
如果定义数组int a[9];在数组中引用数组元素a[10],虽然不存在改元素,但是系统将按照*(a+10)处理
p为指向数组元素的指针变量时,p[i]表示*(p+i),所以要搞清楚p当前指向的元素是谁,是在此基础上加减。此处与作为指针型常量的a不同。
int a[10];
int *p = &a[6];
p[3] == *(p+3) == a[6+3]
奇怪写法:看自增自减运算符的位置
*p++ == *(p++);//先取*p的值,然后再使p+1
*(++p) ==*(p+1);//先使p加1,再取*p
++(*p);//先取*p,p指向的值加1
*(p--);//先进行*p取值,再使p自减
*(++p);//先使p自加,再进行*运算
*(--p);//先使p自减,再进行*运算
④ 用数组名作函数参数
C编译器都是将形参数组名作为指针变量来处理,当形参含有数组名的函数被调用时,系统会再该函数中建立一个指针变量用来存放从主调函数传递过来的实参数组首元素的地址。
fun(int arr[],int n);
//与下列写法等价
fun(int * arr,int n);
注意:实参数组名代表一个固定的地址即指针常量,但是形参数组名不是固定地址,代表指针变量。
3、指针与字符串
① 字符串的引用方式
在C程序中,字符串是存放在字符数组中的,想引用字符串有两种方法:
- 通过数组名和下标引用字符串中的一个字符,或者通过数组名和格式声明"%s"输出该字符
- 用字符指针变量指向一个字符串常量,通过字符指针变量引用
void main(){
char * sring = "cnm";
printf("%s",string);
}
//等同于
void main(){
char * sring = "cnm";
sring = "cnm";//是将字符串的第一个元素的地址赋值给指针变量string
printf("%s",string);
}
区别:通过字符数组名可输出一个字符串,但是通过数值型数组,只能逐个输出。
② 字符指针作函数参数
void copy_string(char from[],char to[]){
int i = 0;
while(from[i]!='\0'){
to[i] = from[i];
i++;
}
to[i]='\0';
}
//指针作形参
void copy_string(char *from,char *to){
for(;*from!='\0';from++,to++)
*to = *from;
*to='\0';
}
用字符数组作为函数参数
char a[] = "bi";
char b[] = "lili";
copy_string(a,b);
用字符型指针变量作实参
char a[] = "bi";
char b[] = "lili";
char *from = a;
char *to = b;
copy_string(from,to);
③ 使用字符指针变量和字符数组的比较
- 字符数组由若干元素组成,每个元素存放一个字符,而字符指针变量存放的是地址
- 可以对字符指针变量赋值,不能对数组名赋值
- 对字符指针变量赋初值,相当于把字符串第一个元素的地址赋值给该指针变量;而对字符数组赋初值时,不能将字符串赋给数组个元素
//错误
char str[14];
str[] = "i love china";
- 编译时字符数组会分配若干存储单元,而对字符指针变量只分配一个存储单元
- 指针变量的值可以改变,而字符数组名代表的是固定的值
七、自建数据类型—结构体
1、定义和使用结构体变量
① 声明结构体类型的一般形式
struct 结构体名{
类型名 成员名;
};
② 定义结构体类型变量
//再定义类型后定义变量
结构体名 变量名;
//在声明类型的同时定义变量
struct 结构体名{
类型名 成员名;
}变量名1,变量名2;
//不指定类型名而直接定义结构体类型变量
struct{
类型名 成员名;
}变量名1,变量名2;//因为无名所以不能再去定义其它变量
注意:
当结构体类型中的成员名和程序中的变量名相同时,二者代表的是不同对象。
③ 结构体变量的初始化和引用
#include- 在定义结构体变量时可以对它的成员初始化,用花括号进行赋值
- 可以使用:结构体变量名"."成员名来引用操作该变量中的成员变量,不能直接输出所有成员的值
- 如果成员本身是结构体类型,要一级一级通过"."(成员运算符)访问只能对最低级的成员进行操作
- 对结构体变量的成员等价于普通变量,可以进行各种运算
- 同类的结构体变量可以相互赋值
- 可以引用结构体变量成员的地址,也可以引用结构体变量的地址,但不能用结构体变量的地址进行整体读入
2、使用结构体数组
① 结构体数组的定义
//在声明时定义并初始化
struct Student{
int no;
char[10] name;
}students[2]={10086,"yd",10000,"lt"};
//在声明时定义不初始化
struct Student{
int no;
char[10] name;
}students[2];
//先声明后定义
struct Student{
int no;
char[10] name;
};
struct Student students[2];//在声明结构体变量时,要加struct
struct Student students[2] = {10086,"yd",10000,"lt"};//在声明结构体变量时,要加struct
② 结构体数组的引用
struct Student{
int no;
char[10] name;
}students[2]={10086,"yd",10000,"lt"};//实际上这样写更好理解{{10086,"yd"},{10000,"lt"}};
struct Student student1;
student1 = students[1];
3、结构体指针
① 指向结构体变量的指针
struct Student{
int no;
char[10] name;
}student1={10000,"lt"};
struct Student *p;
p = &student1;
printf("%d,%s",(*p).no,(*p).name);
printf("%d,%s",p->no,->name);
(*p).no与p->no等价,->代表p所指向的结构体变量的no成员,所以这两种表达方式与student1.no等价。
② 指向结构体数组的指针
struct Student{
int no;
char[10] name;
}students[2]={10086,"yd",10000,"lt"};
struct Student *p;
p = students;
for(;p<stu+2;p++){
printf("%d,%s",p->no,p->name)
结构体数据类型和一般的数据类型本质上相同,其定义的变量数组名也代表了该数组的地址,但是不能直接给该类型的指针变量赋值给类型的成员变量里的数组的数目名,因为类型不同,需要强制转换。
p = (struct Student*)students[0].name;
此时p的值是students[0].name成员的起始地址,可以用printf("%s",p);输出students[0].name的值,p依旧是原来的类型,p+1代表的是students[1].name成员的起始地址。因为此时,p一次增量为struct Student的长度。
4、枚举类型
① 枚举类型以及其变量的声明
//方式一
enum 枚举名{枚举元素列表}枚举类型变量;
//方式二
enum 枚举名{枚举元素列表};
enum 枚举名 枚举变量名;
//方式三
enum {枚举元素列表}枚举类型变量;
C语言对枚举类型的枚举元素按常量处理,故称枚举常量,不能对其赋值。
每个枚举元素都代表一个整数,C语言编译按定义时的顺序默认它们的值为0,1,2,3…。
enum Weekday{mon,tue,wed,thu,fri,sat,sun};
enum Weekday workday;
workday = mon;//相当于赋值workday = 0;
//也可以在定义时给元素常量赋值
enum Weekday{mon=7,tue=1,wed,thu,fri,sat,sun};
//指定mon的值为7,tue为1,后面的常量顺次加1,则fri代表4。
② 使用例子
enum Weekday{mon,tue,wed,thu,fri,sat,sun};
eunm Weekday workday;
for(workday=mon;workday<=fri;workday++){
switch(workday){
case mon:printf("%s","mon");break;
case tue:printf("%s","tue");break;
case wed:printf("%s","wed");break;
case thu:printf("%s","thu");break;
case fri:printf("%s","fri");break;
default:printf("%s","weekend")
}
}
5、用typedef声明新类型名
可以用typedef指定新的类型名来代替已经有的类型名
① 简单地用一个新的类型名代替原有的类型名
typedef int INT007;
INT007 x;
② 命名一个简单的类型名代替复杂的类型表示
为struct创建的新数据类型取别名,这样声明时就不用重复书写: struct 数据类型名
typedef struct 新数据结构名{
数据结构体;
}数据结构别名;
typedef struct DataType {
float coe;//系数
int exp;//指数
}X;
//这是声明了一个新的类型,别名为X,实际为struct DataType
//同理:
struct DataType {
float coe;//系数
int exp;//指数
};
typedef struct DataType X;
③ 使用案例
typedef struct DataType {
float coe;//系数
int exp;//指数
};
typedef struct Node {
DataType data;
struct Node* next;
struct Node* pre;
int size;
}DLList;
//构造一个空的一元n次多项式
void Initiate(DLList** P) {
*P = (DLList*)malloc(sizeof(DLList));
(*P)->pre = *P;
(*P)->next = *P;
(*P)->size = 0;
(*P)->data.coe = 0;
(*P)->data.exp = 0;
}
在一元n次多项式中插入新的一项item
void Insert(DLList* P, DataType item) {
DLList* q, * temp;
q = P;
while (q->next != P && q->next->data.exp <= item.exp)//q的下一项指数小于等于插入项
{
q = q->next;
}
temp = (DLList*)malloc(sizeof(DLList));
temp->data.coe = item.coe;
temp->data.exp = item.exp;
temp->pre = q;
temp->next = q->next;
q->next->pre = temp;
q->next = temp;
P->size++;
}
八、C文件的有关基本知识
参考原文链接:https://blog.csdn.net/qq_38410730/article/details/80242624
来自
1、文件
主要类型:程序文件、数据文件
数据流:文件输入与输出,表示信息从源到目的端的移动
数据文件的分类:ASCII文件、二进制文件
文件缓冲区:系统自动在内存区为程序中每一个正在使用的文件开辟一个文件缓冲区,便于节省存取时间
C语言中的文件类型
该类型的结构体定义在studio.h头文件中:
//文件类型的定义
typedof atruct
{
int _fd; /* 文件号 */
int _cleft; /* 缓冲区剩下的字符 */
int _mode; /* 文件操作模式 */
char* _nextc; /* 下一个字符的位置 */
char* _buff; /* 文件缓冲区位置 */
}FILE;
//声明变量:
FILe file1;
FILE *file_p;
2、文件的打开与关闭
① fopen(“文件名”,“使用文件方式”)
fopen返回的是指向该文件的指针。文件的指针不是指向一段内存空间,而是指向描述有关这个文件的相关信息的一个文件信息结构体。
FILE *file_p;
file_p = fopen("a1","r");

② fclose(文件指针)
FILE *file_p;
file_p = fopen("a1","r");
//关闭的方式很简单,只用给fclose传递文件的指针就行
fclose(file_p);
如果不关闭文件就结束结束程序运行将会导致数据丢失,因为执行fclose函数会将文件缓冲区的数据输出到磁盘文件,省略该步骤可能导致数据流失。
3、文件的顺序读写
① 向文本文件读入或写入一个字符
-
fgetc()函数的功能是从指定的文件中读取一个字符,其调用的形式为:
字符变量 = fgetc (文件指针);
如果在执行fgetc()函数时遇到文件结束符,函数会返回一个文件结束符标志EOF(-1)。
-
fputc()函数的功能是把一个字符写入指定的文件中,其一般调用的格式为:
fput(字符,文件指针);
#include ② 向文本文件读入或写入一个字符串
-
fgets()函数的功能是从指定的文件中读取一个字符串,其调用的形式为:
fgets(字符数组名,n,文件指针);
其中,n是一个正整数,表示从文件中读出的字符串不超过n-1个字符。在读入一个字符串后加上字符串结束标志’\0’。
如果在执行fgets()函数时如果文件内的字符串读取完毕,函数会返回0。
-
fputs()函数的功能是把一个字符串写入指定的文件中,其一般调用的格式为:
fputs(字符串,文件指针);
其中,字符串可以是字符串常量、字符数组、字符指针变量。
#include ③ 格式化读取文件
格式化读/写函数fscanf()和fprintf()
格式化读/写函数与标准的格式输入/输出函数功能相同,只不过它们的读/写对象不是键盘和显示器,而是文件。
fprintf()函数只适用于ASCII码文件的读/写。
两个函数的格式如下:
fscanf(文件指针,格式字符串,输入列表);
fprintf(文件指针,格式字符串,输出列表);
fscanf()和fprintf()函数对文件进行读/写,使用方便,容易理解。但由于在输入时需要将ASCII码转换为二进制格式,在输出时又要将二进制格式转换为字符,花费时间较长,所以在内存与磁盘交换数据频繁的时候,最好不要用这两个函数。
④ 二进制的方式向文件读写一组数据
数据块读/写函数fread()和fwrite():
-
读数据块函数fread(),其调用的一般形式为:
fread(buffer,size,n,文件指针);
fread()函数的功能是从文件中读取字节长度为size的n个数据,并存放到buffer指向的内存地址中去。
函数的返回值为实际读出的数据项个数。比如:
fread(fa,4,5,fp);
其意义是从fp所指向的文件中,每次读4个字节长度(int)送入到fa指向的内存地址中去,连续读5次。也就是说,读5个int类型的数据到fa指向的内存中。
-
写数据块函数fwrite(),其调用的一般形式为:
fwrite(buffer,size,n,文件指针);
fread()函数的功能是将buffer(是一个文件的地址)中存放的size*n个字节的数据输出到文件指针所指向的文件中去。
函数的返回值为实际写入的数据项个数。
fread()和fwrite()函数一般适用于二进制文件,它们是按数据块的大小来处理输入/输出的。
4、随机读写数据文件
在C语言中,打开文件时,文件指针指向文件头,即文件的起始位置。在读写文件时,需要从文件头开始,每次读写完一个数据后,文件指针会自动指向下一个数据的位置。但有时不想从文件头开始读取文件,而是读取文件中某个位置的数据。这时,系统提供了定位到某个数据存储位置的函数。
-
文件头定位函数rewind()
rewind()函数用于把文件指针移动到文件首部,其调用的一般形式为:rewind(文件指针);
-
当前读/写位置函数ftell()
ftell()函数用于确定文件指针的当前读/写位置,其调用的一般形式为:
ftell(文件指针);
此函数有返回值,若成功定位,则返回当前位置;否则返回-1。
-
随机定位函数fseek()
fseek()函数用于将文件指针移动到某个确定的位置,其调用的一般形式为:
fseek(文件指针,位移量,起始点);
此函数有返回值,若成功移动,则返回当前位置;否则返回-1。
其中:位移量指从起始点向前移动的字节数,大多数C版本要求该位移量为long型数据;起始点有三种选择,具体的含义见下表:

5、文件读写的出错检测
C语言还提供了一些检测函数,用于在文件打开、关闭以及读/写操作过程中对有可能会发生的一些情况进行检测。
-
文件结束检测函数feof()
feof()函数用于判断文件是否处于文件结束为止,其调用的一般格式为:
feof(文件指针);
该函数有返回值,如果文件结束,函数的返回值为1;否则返回值为0。
-
读/写文件出错检测函数ferror()
ferror()函数用于检查文件在使用各种读/写函数时是否出错,其调用的一般格式为:
ferror(文件指针);
该函数有返回值,如果没有错误,函数的返回值为0;否则返回值非0。
-
文件出错标志清除函数clearerr()
clearerr()函数用于清除出错标志,其调用的一般格式为:
clearerr(文件指针);
在ferror()函数值为非0时,在调用此函数后,ferror()函数的值变为0。
九、基础常见算法
1、选择排序法
int main()
{
int i = 0; //定义一个i并且赋初值为0,i作为数组的下标
int j = 0; //定义j并且赋初值为0,j作为找到最大值时所对应的下标
int k; //定义一个k,用来保存此次循环中最大值的下标
int temp; //定义一个中间变量temp,供以后交换值的时候使用
int a[]={4,5,6,72,1,7,9,3,}; //定义了一个9个数的数组,并且初始化
int len = sizeof(a)/sizeof(a[0]); //len是数组的大小
for(i = 0;i<len;i++) //判断i是否小于len,执行下面的语句
{
k = i; //假设此次循环中的最大值就是当前的值
for(j = i+1;j<len;j++)
{
if(a[j]>a[k]) //将假设的当前最大值与后面的值比较
{
k = j; //若后面的值更大,则交换下标
}
},当前最大值
if(k != i) //比较之后如果此次循环中最大值并非当前值
{
temp = a[i]; //将此次循环中的最大值与a[k]交换
a[i] = a[k];
a[k] = temp;
}
}
for(i=0;i<len;i++) //利用for循环将结果依次输出
{
printf("%d ",a[i]);
}
return 0;
}
2、冒泡排序法
int main()
{
int i = 0;
int j = 0;
int temp;
int a[10] = {9,8,7,6,5,4,3,2,1,0};
int len = sizeof(a)/sizeof(a[0]);
for(i = 0;i<len-1;i++)
{
for(j = 0;j< len-1-i;j++)
{
if(a[j+1]>a[j])
{
temp = a[j+1];
a[j+1] = a[j];
a[j] = temp;
i++;
}
}
}
for(i = 0;i<len;i++)
{
printf("%d ",a[i]);
}
return 0;
}
3、二分查找法
#include
high=mid-1;
}
return -1; //如果数组中无目标值key,则返回 -1 ;
}
int main()
{
int arr[]={1,2,3,4,5,6,7,8,9,10,11}; //首先要对数组arr进行排序
printf("%d \n",BinSearch(arr,(sizeof(arr)/sizeof(arr[0])),7));
return 0;
}
4、有序数组归并
#include 5、矩阵转置
#include 6、迭代求解法
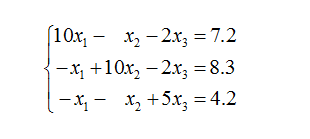
//高斯-赛德尔迭代法:
#include7、数组元素的循环移位
#include 8、最大公约数
/*
枚举法
1. 设最大公约数ret为1
2.如果a和b都能被i整除 记录下i并令ret = i
3. i++后重复第2步 直到i等于a或b
4. ret即为最大公约数
*/
#include 9、最小公倍数
//1.常规暴力求解法
#include 10、打印素数(质数)
#include "stdio.h"
int IsPrimeNumber()
{
for(int i=100;i<1000;i++)
{
for(int j=2;j<i;j++)
{
if(i%j==0)
break;
if(i==j+1)
printf("%d ",i);
}
}
}
int main()
{
IsPrimeNumber();
return 0;
}
11、闰年判断
#include12、矩阵上三角化
#include 上三角判断
#include13、矩阵下三角求和
#include14、泰勒展开求sin
![]()
#include 15、输出杨辉三角前十行
void PascalTriangle()
{
#define ROW 10
int arr[ROW][ROW];
for(int i=0;i<ROW;i++)
{
for(int j=0;j<=i;j++)
{
if(j==0 || i==j)
{
arr[i][j] = 1; //定义第一列和对角线上的数字为1
}
else
{
arr[i][j] = arr[i-1][j-1] + arr[i-1][j];
}
}
}
for(int i=0;i<ROW;i++)
{
for(int j=0;j<=i;j++)
{
printf("%-4d",arr[i][j]);
}
printf("\n");
}
}
16、矩阵对角线求和
#include