python机器学习 多项式回归模型正则化(拉索,岭,弹性网)
多项式回归模型正则化(拉索,岭,弹性网)
目录
- 多项式回归模型正则化(拉索,岭,弹性网)
- 一、多项式回归模型正则化:
-
- 1.L1正则化(lasso)回归
- 2.L2正则化(Ridge)回归
- 3.弹性网(ElasticNet)回归
- 二、python可视化
-
- 1.导入包
- 2.产生数据
- 3.模型对比及可视化
- 总结
过拟合指学习时选择的模型所包含的参数过多,以至于出现模型对已知数据预测的很好,但对未知数据预测得很差得现象
——李航.《统计学习方法》
通常来说,我们收集到得数据是包含噪声的,朴素多项式回归对数据有很好的拟合效果,以导致其过多的拟合出了噪音关系,结果导致训练出的模型对训练数据集的拟合很好,但是对测试数据集的拟合能力就变的很差,此时模型的泛化能力就很差。因此,文章介绍了三种降低过拟合现象以增加泛化能力的方式并且用代码进行了可视化。
一、多项式回归模型正则化:
多项式回归模型减少过度拟合的方法之一对模型正则化,模型复杂度越低,模型就越不容易过拟合,通常做法是降低多项式各式的权重。主要有三种正则化方法:L1正则化,L2正则化,L1+L2正则化。
假设函数为:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n = [ θ 0 ⋮ θ n ] T ⋅ [ 1 x 1 x 2 ⋯ x n ] h_{\theta}\left( x \right) =\theta _0+\theta _1x_1+\theta _2x_2+\cdots +\theta _nx_n \\ =\left[ \begin{array}{c} \theta _0\\ \vdots\\ \theta _n\\ \end{array} \right] ^T\cdot \left[ \begin{matrix} 1& x_1& x_2\,\,\\ \end{matrix}\cdots \,\,x_n \right] hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn=⎣⎢⎡θ0⋮θn⎦⎥⎤T⋅[1x1x2⋯xn]
1.L1正则化(lasso)回归
在原损失函数的基础上加上带训练参数θ的L1范数:
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) + λ ∑ j = 1 m ∥ θ j ∥ 1 ] J\left( \theta \right) =\frac{1}{2m}\left[ \sum_{i=1}^m{\left( h_{\theta}\left( x^{\left( i \right)} \right) -y^{\left( i \right)} \right)}+\lambda \sum_{j=1}^m{\left\| \theta _j \right\| _1} \right] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))+λj=1∑m∥θj∥1]
特点:
(1)它将系数收缩为零(正好为零),这有助于特征选择;
(2)如果一批预测变量高度相关,则Lasso只挑选其中一个,并将其他缩减为零。
2.L2正则化(Ridge)回归
在原损失函数的基础上加上带训练参数θ的L2范数:
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) + λ ∑ j = 1 m ∥ θ j ∥ 2 ] J\left( \theta \right) =\frac{1}{2m}\left[ \sum_{i=1}^m{\left( h_{\theta}\left( x^{\left( i \right)} \right) -y^{\left( i \right)} \right)}+\lambda \sum_{j=1}^m{\left\| \theta _j \right\| _2} \right] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))+λj=1∑m∥θj∥2]
特点:
(1)收缩系数的值,但不会达到零,这表明没有特征选择特征;
3.弹性网(ElasticNet)回归
ElasticNet是Lasso和Ridge回归技术的混合模型。它是用L1和L2作为正则化训练的。当有多个相关的特征时,Lasso可能随机选择其中一个,Elastic-net很可能两个都选择。
其损失函数为:
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) + λ ∑ j = 1 m ∥ θ j ∥ 1 + 1 − λ 2 ∑ j = 1 m ∥ θ j ∥ 2 ] J\left( \theta \right) =\frac{1}{2m}\left[ \sum_{i=1}^m{\left( h_{\theta}\left( x^{\left( i \right)} \right) -y^{\left( i \right)} \right)}+\lambda \sum_{j=1}^m{\left\| \theta _j \right\| _1+\frac{1-\lambda}{2}\sum_{j=1}^m{\left\| \theta _j \right\| _2}} \right] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))+λj=1∑m∥θj∥1+21−λj=1∑m∥θj∥2]
弹性网络是岭回归和Lasso回归的结合,其正则项就是岭回归和Lasso回归的正则项的混合,混合比例通过r来控制,当r=0时,弹性网络即等同于岭回归,而当r=1时,即相当于Lasso回归。
在Lasso和Ridge之间折衷的实际优点是它允许Elastic-Net继承一些Ridge的稳定性。
二、python可视化
代码如下:
1.导入包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures##特征扩展器
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,Ridge,ElasticNet,Lasso
2.产生数据
代码如下:
##生成原始数据
np.random.seed=21
x=(np.linspace(-3,3,50)).reshape((-1,1))
def Y():
return 0.2+x**2
y=Y()
y_train=y+np.random.normal(0,2,size=len(x)).reshape((-1,1))
###多项式特征扩展
poly=PolynomialFeatures(degree=20)
poly.fit(x)
x_train=poly.transform(x)
3.模型对比及可视化
##--------数据标准化及模型选择,给polynomial regression,不加正则化
model1 = Pipeline([
('sca', StandardScaler()),
('lin_reg', LinearRegression()),
])
##--------数据标准化及模型选择,给polynomial regression加入L2正则化
model2 = Pipeline([
('sca', StandardScaler()),
('ridge', Ridge(solver='cholesky')),
])
##--------数据标准化及模型选择,给polynomial regression加入L1正则化
model3 = Pipeline([
('sca', StandardScaler()),
('lasso', Lasso()),
])
##--------数据标准化及模型选择,给polynomial regression加入L2+L1正则化(弹性网回归 ElasticNet Regression)
model4 = Pipeline([
('sca', StandardScaler()),
('elasticnet', ElasticNet()),
])
model1.fit(x_train,y_train)
model2.fit(x_train,y_train)
model3.fit(x_train,y_train)
model4.fit(x_train,y_train)
plt.ylim(-2,11)
plt.plot(x,y,'r')###无噪音原始函数关系
plt.scatter(x,y_train)##加入噪音后的散点图
plt.plot(x,model1.predict(x_train),'b')##无正则项的多项式回归
plt.plot(x,model2.predict(x_train),'g')##L2正则化的多项式回归
plt.plot(x,model3.predict(x_train),'black')##L1正则化的多项式回归
plt.plot(x,model4.predict(x_train),'m')##加入弹性网的多项式回归
plt.show()
features=x_train.shape[1]
print(features)
x_train.shape
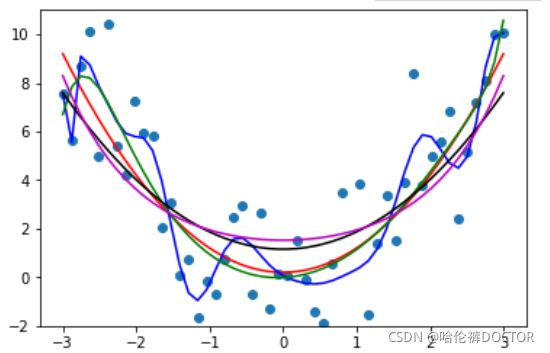
上图红线为期望,输出蓝色线为无正则项的多项式回归结果,过拟合现象很严重,在加入正则项后过拟合现象基本消失。
总结
对于多项式回归过拟合现象,在其损失函数中加入正则项可有效缓解过拟合,降低模型复杂度。
参考:
- 多项式回归下的过拟合和欠拟合原理解释
- 机器学习算法(8)之多元线性回归分析理论详解
- normal linear model