【数据库原理及应用教程】【数据模型】【1.7-1.10】
2022年3月9日14:12:23
文章目录
- 2022年3月9日14:12:23
- 第一章 数据库系统概述
-
- 复习
- 1.7 数据模型
-
- 1.7.1 数据模型的概念及分类
-
- 1.数据处理的抽象与转换
- 2.数据模型的分类
- 1.7.2数据模型的组成要素
-
- 1.数据结构
- 2.数据操作
- 3.数据的完整性约束
- 1.8 三大世界与其有关概念
-
- 1.8.1现实世界
- 1.8.2信息世界
-
- 1.信息世界及其有关概念
- 2.两个实体型间的联系
- 3.两个以上实体型间的联系
- 4.单个实体型内部的联系
- 1.8.3计算机世界
- 1.9 四种数据模型
-
- 1.9.1层次模型
-
- 1.层次模型的数据结构
-
- 层次模型的特点:
- 2.层次模型的数据操纵与数据完整性约束
- 3.层次模型的优缺点
- 1.9.3关系模型
-
- 1.关系模型的数据结构及有关概念
- 2.关系模型的数据操纵与完整性约束
- 3.关系模型的优缺点
- 1.9.4面向对象模型
-
- 1.对象(Object)和对象标识(Object Identifier,OID)
- 2.类(Class)和继承(Inheritance)
- 1.10 数据库领域的新技术
-
- 1.10.1 分布式数据库
- 1.10.2 数据仓库与数据挖掘技术
- 1.10.3 多媒体数据库
- 1.10.4 大数据技术
第一章 数据库系统概述
复习
【数据库原理及应用教程】【数据库系统概述】【1.1-1.3】
【数据库原理及应用教程】【数据库系统的体系结构】【1.4-1.6】
1.7 数据模型
1.7.1 数据模型的概念及分类
数据模型是数据库的框架,该框架描述了数据及其联系的组织方式、表达方式和存取路径,各种机器上实现的DBMS软件都是基于某种数据模型的,它的数据结构直接影响到数据库系统的其他部分的性能,也是数据定义和数据操纵语言的基础。
因此,数据模型的选择是设计数据库时的一项首要任务。
1.数据处理的抽象与转换
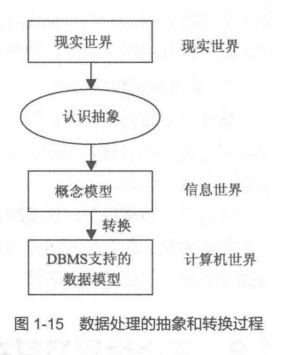
为了把现实世界中的具体事物抽象、组织为某一DBMS支持的数据模型,在实际的数据处理过程中,首先将现实世界的事物及联系抽象成信息世界的概念模型,然后再抽象成计算机世界的数据模型。
概念模型并不依赖于具体的计算机系统,不是某一个DBMS所支持的数据模型,它是计算机内部数据的抽象表示;概念模型经过抽象,转换成计算机上某一DBMS支持的数据模型。
所以说,数据模型是现实世界的两级抽象的结果。在数据处理中,数据加工经历了现实世界、信息世界和计算机世界三个不同的世界,经历了两级抽象和转换,这一过程如图1-15所示。
2.数据模型的分类
根据模型应用的不同目的,可以将这些模型划分为两类,它们分属于两个不同的抽象级别。
第一类模型是概念模型,也称为信息模型,它是按用户的观点对数据和信息建模,是对现实世界的事物及其联系的第一级抽象,它不依赖于具体的计算机系统,不涉及信息在计算机内如何表示、如何处理等问题,只是用来描述某个特定组织所关心的信息结构。因此,概念模型属于信息世界中的模型,不是一个DBMS支持的数据模型,而是概念级的模型。
第二类模型是逻辑模型(或称数据模型)和物理模型。逻辑模型是属于计算机世界中的模型,这一类模型是按计算机的观点对数据建模,是对现实世界的第二级抽象,有严格的形式化定义,以便于在计算机中实现。
任何一个DBMS都是根据某种逻辑模型有针对性地设计出来的,即数据库是按DBMS规定的数据模型组织和建立起来的,因此逻辑模型主要用于DBMS的实现。
从概念模型到逻辑模型的转换可以由数据库设计人员完成,也可以用数据设计工具协助设计人员完成。
比较成熟地应用在数据库系统中的逻辑模型主要包括层次模型(Hierarchical Model)、网状模型(Network Model)、关系模型(Relational Model)和面向对象模型(Object–oriented Model)等。
物理模型是对数据最底层的抽象,它描述数据在磁盘或磁带上的存储方式和存取方法,是面向计算机系统的。物理模型的具体实现是DBMS的任务,用户一般不必考虑物理级细节。从逻辑模型到物理模型的转换是由DBMS自动完成的。
1.7.2数据模型的组成要素
由于数据模型是现实世界中的事物及其联系的一种模拟和抽象表示,是一种形式化描述数据、数据间联系以及有关语义约束规则的方法,这些规则规定数据如何组织以及允许进行何种操作,因此,数据模型通常由数据结构、数据操作和数据的完整性约束三个要素组成。
1.数据结构
数据结构或数据组织结构,描述了数据库的组成对象以及对象间的联系,也就是说数据结构一方面描述的是数据对象的类型、内容、性质等,另一方面描述了数据对象间的联系。因此,数据结构描述的是数据库的静态特性,是数据模型中最基本的部分,不同的数据模型采用不同的数据结构。
例如,在关系模型中,用字段、记录、关系(二维表)等描述数据对象,并以关系结构的形式进行数据组织。因此,在数据库中,人们通常按照其数据结构的类型来命名数据模型。例如,数据结构有层次结构、网状结构和关系结构三种类型,按照这三种结构命名的数据模型分别称为层次模型、网状模型和关系模型。
2.数据操作
数据操作是指对数据库中的各种数据允许执行的操作的集合,包括操作及相应的操作规则,描述了数据库的动态特性。数据库有查询和更新(包括插入、删除和修改)两类操作。数据模型必须定义这些操作的确切含义、操作符号、操作规则(如优先级)以及实现操作的语言。
3.数据的完整性约束
数据的完整性约束条件是一组完整性规则的集合。完整性规则是给定的数据模型中数据及其联系所具有的制约和依存规则,用以限定符合数据模型的数据库状态以及状态的变化,以保证数据的正确、有效、相容。
一方面,数据模型应该反映和规定本数据模型必须遵守的基本的和通用的完整性约束条件。
另一方面,数据模型还应该提供定义完整性约束条件的机制,以反映具体应用所涉及的数据必须遵守的特定的语义约束条件。
1.8 三大世界与其有关概念
1.8.1现实世界
现实世界,即客观存在的世界。其中存在着各种事物及它们之间的联系,每个事物都有自己的特征或性质。人们总是选用感兴趣的最能表征一个事物的若干特征来描述该事物。
客观世界中,事物之间是相互联系的,而这种联系可能是多方面的,但人们只选择那些感兴趣的联系,无需选择所有的联系。
1.8.2信息世界
1.信息世界及其有关概念
信息世界是现实世界在人们头脑中的反映,经过人脑的分析、归纳和抽象,形成信息,人们把这些信息进行记录、整理、归类和格式化后,就构成了信息世界。在信息世界中,常用的主要概念如下。
(1)实体(Entity)。客观存在并且可以相互区别的“事物”称为实体。实体可以是具体的人、事和物,如一个学生、一本书、一辆汽车、一种物资等;也可以是抽象的事件,如一堂课、一次比赛、学生选修课程等。
(2)属性(Attribute)。实体所具有的某一特性称为属性。一个实体可以由若干个属性共同来刻画。如学生实体由学号、姓名、性别、年龄、系等方面的属性组成。属性有“型”和“值”之分。“型”即为属性名,如姓名、年龄、性别都是属性的型;“值”即为属性的具体内容,如学生(990001、张立、20、男、计算机),这些属性值的集合表示了一个学生实体。
(3)实体型(Entity Typ)。具有相同属性的实体必然具有共同的特征。所以,用实体名及其属性名集合来抽象和描述同类实体,称为实体型。如学生(学号,姓名,年龄,性别,系)就是一个实体型,它描述的是学生这一类实体。
(4)实体集(Entity Set)。同型实体的集合称为实体集。如所有的学生、所有的课程等。
(5)码(Ky)。在实体型中,能唯一标识一个实体的属性或属性集称为实体的码。如学生的学号就是学生实体的码,而学生实体的姓名属性可能有重名,不能作为学生实体的码。注意:在有些教材中该概念称为键。
(6)域(Domain)。某一属性的取值范围称为该属性的域。如学号的域为6位整数,姓名的域为字符串集合,年龄的域为小于40的整数,性别的域为男或女等。
(7)联系(Relationship)。在现实世界中,事物内部以及事物之间是有联系的,这些联系同样也要抽象和反映到信息世界中来,在信息世界中将被抽象为单个实体型内部的联系和实体型之间的联系。单个实体型内部的联系通常是指组成实体的各属性之间的联系;实体型之间的联系通常是指不同实体集之间的联系,可分为两个实体型之间的联系以及两个以上实体型之间的联系。
2.两个实体型间的联系
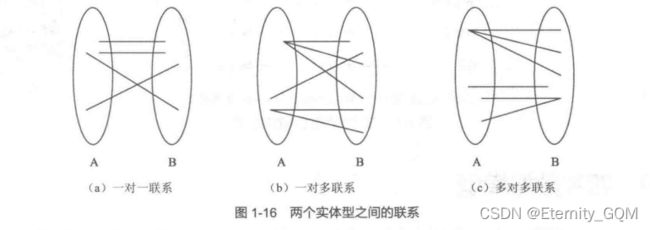
两个实体型之间的联系是指两个不同的实体集间的联系,有如下三种类型。
(1)一对一联系(1:1)。实体集A中的一个实体至多与实体集B中的一个实体相对应,反之,实体集B中的一个实体至多与实体集A中的一个实体相对应,则称实体集A与实体集B为一对一的联系,记作1:1.如,班级与班长、观众与座位、病人与床位之间的联系。
(2)一对多联系(1:n)。实体集A中的一个实体与实体集B中的n(n≥0)个实体相联系,反之,实体集B中的一个实体至多与实体集A中的一个实体相联系,记作1:。例如,班级与学生、公司与职员、省与市之间的联系。
(3)多对多联系(m:n)。实体集A中的一个实体与实体集B中的n(n≥0)个实体相联系,反之,实体集B中的一个实体与实体集A中的m(m≥0)个实体相联系,记作m:。如,教师与学生、学生与课程、工厂与产品之间的联系。
实际上,一对一联系是一对多联系的特例,而一对多联系又是多对多联系的特例。
可以用图形来表示两个实体型之间的这三类联系,如图1-16所示。
3.两个以上实体型间的联系
两个以上的实体型之间也存在着一对一、一对多和多对多的联系。
例如,对于课程、教师与参考书三个实体型,如果一门课程可以有若干个教师讲授,使用若干本参考书,而每一个教师只讲授一门课程,每一本参考书只供一门课程使用,则课程与教师、参考书之间的联系是一对多的联系。
4.单个实体型内部的联系
同一个实体集内的各个实体之间存在的联系,也可以有一对一、一对多和多对多的联系。
1.8.3计算机世界
计算机世界是信息世界中信息的数据化,就是将信息用字符和数值等数据表示,便于存储在计算机中并由计算机进行识别和处理。在计算机世界中,常用的主要概念有如下几个。
(1)字段(Fild)。标记实体属性的命名单位称为字段,也称为数据项。字段的命名往往和属性名相同。如学生有学号、姓名、年龄、性别和系等字段。
(2)记录(Record)。字段的有序集合称为记录。通常用一个记录描述一个实体,因此,记录也可以定义为能完整地描述一个实体的字段集。如一个学生(990001,张立,20,男,计算机)为个记录。
(3)文件(Fil)。同一类记录的集合称为文件。文件是用来描述实体集的。如,所有学生的记录组成了一个学生文件。
(4)关键字。能唯一标识文件中每个记录的字段或字段集,称为记录的关键字,或简称键。例如,在学生文件中,学号可以唯一标识每一个学生记录,因此,学号可作为学生记录的关键字。
在计算机世界中,信息模型被抽象为数据模型,实体型内部的联系抽象为同一记录内部各字段间的联系,实体型之间的联系抽象为记录与记录之间的联系。
现实世界是信息之源,是设计数据库的出发点,实体模型和数据模型是现实世界事物及其联系的两级抽象。而数据模型是实现数据库系统的根据。
总结出三个世界中各术语的对应关系,如图1-17所示。

1.9 四种数据模型
目前,在数据库领域中常用的数据模型主要有层次模型(Hierarchical Model)、网状模型(Network Model)、关系模型(Relational Model)和面向对象模型(Object–oriented Model)四种。
1.9.1层次模型
层次模型是数据库系统中最早出现的数据模型,采用层次模型的数据库的典型代表是BM公司的MS数据库管理系统。此系统是BM公司于1968年推出的第一个大型的商用数据库管理系统,曾经得到广泛的应用。
1.层次模型的数据结构
层次模型用树形数据结构(有根树)来表示各类实体以及实体间的联系。
在这种树形结构中,每个结点表示一个记录型,每个记录型可包含若干个字段,记录型描述的是实体,字段描述实体的属性,各个记录型及其字段都必须命名。结点间的带箭头的连线(或边)表示记录型间的联系,连线上端的结点是父结点或双亲结点,连线下端的结点是子结点或子女结点,同一双亲的子女结点称为兄弟结点,没有子女结点的结点称为叶结点,如图1-18所示。

层次模型的特点:
(1)每棵树有且仅有一个结点没有双亲,该结点就是根结点。
(2)根结点以外的其他结点有且仅有一个双亲结点。
(3)父子结点之间的联系是一对多(1:n)的联系。父结点中的一个记录值可能对应n个子结点中的记录值,而子结点中的一个记录值只能对应父结点中一个记录值。因此,任何一个给定的记录值只有按其路径查看时,才能显出它的全部意义,没有一个子女记录值能够脱离双亲记录值而独立存在。
2.层次模型的数据操纵与数据完整性约束
层次模型的数据操纵主要有查询、插入、删除和修改,进行插入、删除和修改操作时要满足层次模型的完整性约束条件。
进行插入操作时,如果没有相应的双亲结点值就不能插入子女结点值。若新进一名教师,如果没有确定他在哪个教研室,则该教师不能插入到数据库中。
进行删除操作时,如果删除双亲结点值,则相应的子女结点值也被同时删除。若删除一个教研室,则该教研室的所有教师都将被删除。
修改操作时,应修改所有相应的记录,以保证数据的一致性。
3.层次模型的优缺点
层次模型的主要优点如下:
-
(1)层次模型结构比较简单,层次分明,便于在计算机内实现。
-
(2)结点间联系简单,从根结点到树中任一结点均存在一条唯一的层次路径,当要存取某个结点的记录值时,沿着这条路径很快就能找到该记录值,因此,以该种模型建立的数据库系统查询效率很高。
-
(3)它提供了良好的数据完整性支持。
层次模型的缺点主要有以下几点:
-
(1)不能直接表示两个以上的实体型间的复杂联系和实体型间的多对多联系,只能通过引入冗余数据或创建虚拟结点的方法来解决,易产生不一致性。
-
(2)对数据插入和别除的操作限制太多。
-
(3)查询子女结点必须通过双亲结点。
1.9.3关系模型
关系模型是发展较晚的一种模型。1970年美国IBM公司的研究员E.E.Codd首次提出了数据库系统的关系模型。他发表了题为《大型共享数据银行数据的关系模型》(A Relation Model of Data for Large Shared Data Banks)的论文。在文中解释了关系模型,定义了某些关系代数运算,研究了数据的函数相关性,定义了关系的第三范式,从而开创了数据库的关系方法和数据规范化理论的研究。为此他获得了1981年的图灵奖。此后许多人把研究方向转到关系方法上,陆续出现了关系数据库系统。1977年IBM公司研制的关系数据库的代表System R开始运行,其后又进行了不断的改进和扩充,出现了基于System R的数据库系统SQL/DB。
20世纪80年代以后,计算机厂商新推出的数据库管理系统几乎都支持关系模型,非关系数据库管理系统的产品也都加上了关系接口。数据库领域当前的研究工作也都是以关系方法为基础的。关系数据库已成为目前应用最广泛的数据库系统,如现在广泛使用的小型数据库管理系统Foxpro、Access,开源数据库管理系统MySQL、MongoDB,商业数据库管理系统Oracle、SQL Server、Informix和Sybase等都是关系数据库系统。
1.关系模型的数据结构及有关概念
关系模型的数据结构是一张规范化的二维表,它由表名、表头和表体三部分构成。表名即二维表的名称,表头决定了二维表的结构(即表中列数及每列的列名、类型等),表体即二维表中的数据。
每个二维表又可称为关系。关系模型与层次模型、网状模型不同,它是建立在严格的数学概念之上的。
(1)关系(Relation)与关系实例。一个关系实例对应一张由行和列组成的二维表。
(2)元组(Tuple)。元组是二维表格中的一行,如S表中的一个学生记录即为一个元组。
(3)属性(Attribute)。二维表格中的一列,给每一个属性起一个名称即属性名。
(4)域(Domain)。属性的取值范围。
(5)分量。每一行元组对应的列的属性值,即为元组中的一个属性值。
(6)候选码。如果一个属性或若干属性的组合,并可唯一标识一个关系的元组,且该属性的组合中不包含多余的属性,则称该属性或属性的组合为候选码。一个关系中可有多个候选码。在最简单的情况下,候选码只包含一个属性。在极端的情况下,候选码由关系中的所有属性组成,此时称为全码。
(7)主码。当一个关系中有多个候巡码时,可以从中选择一个候选码作为主码。一个关系上只能有一个主码。
(8)关系模式。关系模式是对关系的描述,一般表示为:关系名(属性1,属性2,…,属性n),关系模式是关系模型的“型”,是关系的框架结构。如学生关系S的关系模式可表示为:学生(学号,姓名,性别,年龄,系别)。
在关系模型中,实体是用关系来表示的,如:
学生(学号,姓名,性别,年龄,系别)
课程(课程号,课程名,课时)
实体间的联系也是用关系来表示的,如学生和课程 之间的联系可表示为:
选课(学号,课程号,成绩)
(9)关系实例。关系实例是关系模式的“值”,是关系的数据,相当于二维表中的数据。
2.关系模型的数据操纵与完整性约束
关系模型的数据操纵主要包括查询、插入、删除和修改数据。这些操作必须满足关系的完整性约束条件,即满足实体完整性、参照完整性和用户定义的完整性。在非关系模型中,操作对象是单个记录,而关系模型中的数据操作是集合操作,操作对象和操作结果都是关系,即若干元组的集合;另外,关系模型把对数据的存取路径隐蔽起来,用户只要指出“干什么”,而不必详细说明“怎么干”,从而大大地加强了数据的独立性,提高了用户操作效率。
3.关系模型的优缺点
关系模型的优点主要有以下三点。
(1)关系模型与非关系模型不同,它有严格的数学理论根据。
(2)数据结构简单、清晰,用户易懂、易用,不仅用关系描述实体,而且用关系描述实体间的联系。此外,对数据的操纵结果也是关系。
(3)关系模型的存取路径对用户透明,从而具有更高的数据独立性、更好的安全保密性,也简化了程序员的工作和数据库建立和开发的工作。
关系模型的缺点是查询效率不如非关系模型。因此,为了提高性能,必须对用户的查询进行优化,增加了开发数据库管理系统的负担。
1.9.4面向对象模型
虽然关系模型比层次、网状模型简单灵活,但是现实世界存在着许多含有复杂数据结构的应用领域,如CAD数据、图形数据等,它们需要更高级的数据库技术表达这类信息。
面向对象的概念最早出现在1968年的Smalltalk语言中,随后迅速渗透到计算机领域的每一个分支,现已使用在数据库技术中。面向对象数据库是面向对象概念与数据库技术相结合的产物。
面向对象模型中最基本的概念是对象和类。
1.对象(Object)和对象标识(Object Identifier,OID)
对象是现实世界中实体的模型化。
每一对象都由唯一的对象标识来识别,用于确定和检索这个对象,它把对象的状态(State)和行为(Behavior)封装(Encapsulate)在一起。其中,对象的状态是该对象属性值的集合,对象的行为是在对象状态上操作的方法集。
对象标识独立于对象的内容和存储位置,是一种逻辑标识符,通常由系统产生,它在整个系统范围内是唯一的。两个对象即使内部状态值和方法都相同,如标识符不同,仍认为是两个相等而不同的对象。如同一型号的两个零件,在设计图上被用在不同的地方,这两个零件是“相等”的,但被视为不同的对象,具有不同的标识符。在这一点上,面向对象的模型与关系模型不同,在关系模型中,如果两个元组的属性值完全相同,则被认为是同一元组。
每个对象都包含一组属性和一组方法。属性用来描述对象的状态、组成和特性,它是对象的静态特征。一个简单对象如一个整数,其值本身就是其状态的完全描述,不再需要其他属性,这样的对象称为原子对象。属性的值也可以是复杂对象。一个复杂对象包含若干个属性,而这些属性作为一种对象,又可能包含多个属性,这样就形成了对象的递归引用,从而组成各种复杂对象。
方法用以描述对象的行为特性。一个方法实际是一段可对对象操作的程序。方法可以改变对象的状态,所以称为对象的动态特征。如一台计算机,它不仅具有描述其静态特征的属性:CPU型号、硬盘大小和内存大小等,还具有开机、关机和睡眠等动态特征。由此可见,每个对象都是属性和方法的统一体。与关系模型相比,对象模型中的对象概念更为全面,因为关系模型主要描述对象的属性,而忽视了对象的方法,因此会产生“结构与行为相分离”的缺陷。
2.类(Class)和继承(Inheritance)
具有同样属性和方法集的所有对象构成了一个对象类(简称类),一个对象是某一类的实例(Instance)。如把学生定义为一个类,则某个学生(张三、李四等)则是学生类中的对象。类是“型”,对象是某一类的“值”。
类的属性域可以是基本数据类型(如整型、实型、字符型等),也可以是类,或由上述值域组成的记录或集合。也就是说,类可以有嵌套结构。
此外,类的表示具有层次性。在面向对象模型中,可以继承操作形成新的类,新的类是对已有的类定义的扩充和细化,从而形成了一种类间的层次结构,有了超类和子类的概念。超类是子类的父类,规定了子类可以实现或扩展的方法和行为,子类继承了父类的方法和属性,可用于扩展并形成功能更加具体的对象。
一个类可以有多个子类,也可以有多个超类。因此,一个类可以直接继承多个类,这种继承方式称为多重继承。如果一个类至多只有一个超类,则一个类只能从单个超类继承属性和方法,这种继承方式称为单重继承。在多重继承情况下,类的层次结构不再是一棵树,而是一个网络结构。
面向对象模型能完整地描述现实世界的数据结构,具有丰富的表达能力,但模型相对比较复杂,涉及的知识比较多,因此,面向对象数据库尚未达到关系数据库的普及程度。