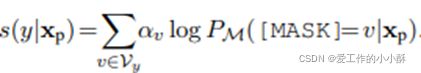Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
【摘要】
用特定任务prompt,在基于预训练语言模型在上进行微调在文本分类任务上已经显示效果很好。特别,最近的研究发现在小样本场景上的效果尤为突出。Prompt turning的核心是插入文本片段,也叫作template。将原来的分类问题转化为掩码语言模型问题。其中一个关键的步骤是在标签集合和标签词之间做一个映射,或者叫做verbalizer。一个verbalizer经常是手工设计或者基于梯度下降法搜索,这些方法可能不容易收敛,并且会给结果带来大的偏差和高的方差。在本文中,我们把外部知识引入到verbalizer中,形成knowledgeable prompttuning (KPT),从而提高prompt turning的稳定性。具体的,我们使用外部知识库扩展标签词空间,并使用PLM修正标签词空间。

【引言】
基于预训练模型进行微调的方法在各个任务上都取得了很好的结果,为了研究PLM的有效性,研究者作出了很多深入的研究,并观察到PLM在预训练的过程中可以获取丰富的知识。因此如何更好的利用这些知识收到越来越多的关注。一个传统的方法使用这种知识是微调,就是在PLM上层再加一个分类器,在特定分类目标上进一步训练模型。微调的方法在很多任务上都取得了很好的效果。然而,由于使用额外的分类器的话,需要大量的数据进行训练,这在少样本和零样本场景任务上就比较困难。起源于GPT-3和LAMA,一系列使用prompt进行微调模型的研究弥补了预训练和微调之间的gap。并且在少样本和零样本任务上验证了这种离散或连续的prompt可以得到更好的结果。
一种经典的使用prompt turning的方法是把输入转化为语言template,然后让PLM做掩码语言模型任务。例如,对于输入:“What’s the relation between speed and acceleration?”,和其标签”SCIENCE“,我们可以得到一个template:“A [MASK] question: x”。模型最终预测[MASK]位置预测“science”的概率。这种标签词(“science”)到特定类别(“SCIENCE”)的映射叫做verbalizer。 Verbalizer代表了词典和标签词之间的映射,并验证这种映射对结果的影响较大。
目前很多工作使用手工设计的verbalizer,一般都是一个标签词对应一个类别。然而,这种方法导致预测是基于有限的信息的,例如,在上述的例子中,普通的verbalizer:{science->SCIENCE}代表只有[MASK]预测为science的时候,其预测的类别才是正确的,忽略其相关词,例如“physics”、“maths”,这些词同样具有丰富的信息。这种一对一的映射限制了标签词的覆盖面,因此导致在预测的时候缺少足够的信息,并且也会给verbalizer带来误导。因此,手工设计的verbalizer很难在prompt turning上优化,因为在prompt turning 方法上标签词的语义信息对预测很重要。
一些研究为了缓解手工设计Verbalizer带来的问题,提出使用梯度下降法搜索最好的Verbalizer。这种方法可以找出和标签词在词义上相似的词。但是这种基于优化的方法很难找到多个粒度的词,例如从“science”到“physics”。如果我们把Verbalizer定义为{science, physics} -> “SCIENCE”。那么预测正确标签的概率将会大大增强。因此,为了提高Verbalizer的覆盖度和减少其偏差,我们把外部知识引入到Verbalizer中,并将其命名为knowledgeable prompt-tuning (KPT),因为我们的扩展方法不是基于优化的,它将会对零样本学习非常有效。
KPT一共包括三个步骤:构建、修正、使用。首先,在构建阶段,我们使用外部知识库针对每个类别标签生成一系列的标签词,这些标签词并不只是相互之间的同义词,而是包含了不同粒度和视角的词,因此比类别名更全面和更公正。其次,我们使用PLM给这些扩展的标签词降噪,对于少样本学习,我们使用contextualized prior 移除具有低的先验概率的词。因此从知识库中找出的词具有非常不同的先验概率,我们提出了一个强大的校准方法,叫做contextualized calibration,以增强零样本的结果。对于少样本学习,我们为每一个标签词赋予一个可学习的权重,以降噪知识库生成的标签词。最后,我们使用普通的平均损失函数或带权损失函数,得到标签词在特定类别上的分数。
【模型】
设M为预训练语言模型,在文本分类任务中,给定一个输入x,其将会被分到一个标签。Prompt turning 就是要把分类问题转化为掩码语言模型。具体的,其把输入改为:
![]()
M预测[MASK]位置上词的概率:
![]()
我们定义一个verbalizer,用于构造词典V到类别标签Y的映射,![]() 代表特定类别标签y的标签词集合,那么对于特定的类别标签,其预测概率就为:
代表特定类别标签y的标签词集合,那么对于特定的类别标签,其预测概率就为:
![]()
这里的g代表把标签词的概率转化为标签的概率的一个函数,在上述的例子中,常规的prompt turning方法可能定义V1={science},V2={sports},g为identity function,如果预测的science的概率大于sports,我们将其归类为SCIENCE。
在KPT方法中,我们使用知识库生成类别的相关词。然后使用情景化校准(contextualized calibration)方法筛选词。最终,我们使用平均或者带权均值的方法得到其对应特定类别的得分。
1、构建verbalizer:在使用掩码语言模型预测被mask的词的时候,存在多个词都合适的情况。因此使用verbalizer得到的标签词应该具有两个属性:覆盖面广、偏差小。而额外的结构化的知识可以满足这个要求,这一部分,我们将要介绍如何使用外部知识库完成两项任务:话题分类和情感分类。对于话题分类,关键是从多个方面和多个粒度找出和话题相关的标签词。在这里,我们选择了相关词,可以从多个方法(word embeddings、ConceptNet、WordNet)中得到知识图G。其作为我们的外部知识库。其边代表“relevance”关系,代表了话题和标签词之间的相关性得分。我们使用话题词作为核心节点,用一个阈值筛选其邻居节点作为候选词。对于情感分类任务,要筛选出表达正向情感和负向情感的词,在这里,我们使用之前研究者提出的情感字典,这样就可以得到将多个标签词映射到同一个类别标签。
2、优化verbalizer:虽然得到了多个标签词对应一个类别标签,但这些标签词具有很大的噪音,因此需要去除低相关的词,保留高质量的词。在零样本场景中,需要解决三个问题,第一,标签词中可能会有OOV的词,但是这些词对分类也很重要,不能直接移除,我们对其tokenizers后,取平均得到OOV词的概率。第二,标签词中可能会有稀有词,这样会导致预测的概率不准确,我们不使用词频词典,而是使用标签词的上下文先验(contextualized prior)移除这些词。具体的,给定文本分类任务,令D为句子x在语料库中的分布。对于在这个分布中的每个句子,我们把它转化为一个template,计算对于每个标签词v在[MASK]位置的概率:
![]()
经过试验发现,从训练集中筛选出一个小集合,并去掉标签作为支撑集![]() ,会得到上面期望的结果,假设输入样本{x属于
,会得到上面期望的结果,假设输入样本{x属于![]() }具有统一的先验分布,那么上下文先验可以近似为:
}具有统一的先验分布,那么上下文先验可以近似为:
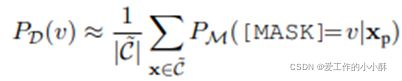
然后移除低于这个概率值的标签词。第三,标签词的先验概率具有很大的差异性,这在以前的研究中就已经被提出,一些标签词相对于其他一些标签词很少被预测到,就会导致一个有偏差的预测。在我们的方法中,从知识库获得的标签词具有更加不同的先验概率。因此,我们使用标签词的上下文先验去校准预测的概率分布,将其叫做contextualized calibration (CC)。
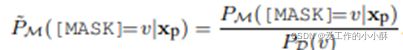
3、少样本修正:在少样本学习中,这种修正比较简单,因为我们可以得到每个标签词对于预测的影响。从知识库中得到标签词后,我们首先移除那些可以分为多个token的词,因此这些词在训练的时候比较麻烦。为了缓解噪音标签词的影响,我们为每个标签词v赋予一个可学习的权重![]() 。然后对每个权重进行归一化:
。然后对每个权重进行归一化:

直观上,在训练的时候,噪音标签词会有一个小的权重,从而减轻其对预测的影响。
4、Verbalizer的使用:现在要把标签词映射到特定类别,就是上文中的函数g。这有两种方式,平均和带权平均。平均就认为每个标签词对类别标签的共享相等,这种方法使用在零样本学习中。公式为:
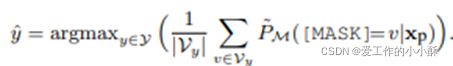
带权平均认为不同的标签词对最终的类别标签的贡献概率不相等,这个应用在少样本学习中,就使用上面的标签词的归一化权重。最终计算公式为: