r 字符串转化为数值_R语言系列3:高级数据管理
R语言系列3:高级数据管理
此文内容为《R语言实战》的笔记,人民邮电出版社出版。
从高中电脑课学VB开始,大一课内开始学习C++,到后来大二为了数模学习Matlab,到大三为了搞深度学习自学Python,到研究生之初学习Stata——选择一门语言对我来说就像是小时候玩冒险岛,到10级的时候是转战士好还是弓箭手好一般的纠结。我查阅了很多B乎的文章,最后觉得可能R比较合适现在的我。
作为从Python转进来R的新手,我把可能会用经常需要用到或经常需要查阅的代码贴上来,主要是为了日后方便查找,就像“字典”一样。推文的顺序与教材不同,为了简洁,我还会删除一些我个人认为不太重要的章节。我还会按照自己的学习进度发布文章,请读者见谅。
本文章仅供学习参考,请勿转载,侵删!
目录
- 5 高级数据管理
- 5.2 数值和字符串处理函数
- 5.2.1 数学函数
- 5.2.2 统计函数
- 5.2.3 概率函数
- 5.2.4 字符处理函数
- 5.2.5 其他实用函数
- 5.4 控制流
- 5.4.1 循环结构
- 5.4.2 判断结构
- 5.4.3 用户自定义函数
- 5.6 整合与重构
- 5.6.1 数据集的转置
- 5.6.2 整合数据
- 5.6.3 reshape2包
- 5.2 数值和字符串处理函数
第5章 高级数据管理
在第4章,我们学习了R中基本的数据处理方法。在第5章,我们主要浏览R中的多种数学、统计和字符处理函数,了解如何自己编写函数来实现数据处理和分析任务,并了解数据的整合和概述方法以及数据集的重塑和重构。
5.2 数值和字符处理函数
R中作为数据处理基石的函数,可以分为数值函数(数学、统计、概率)和字符串处理函数。
5.2.1 数学函数
R中常用的数学函数有:
== 函数 == == 描述 ==abs(x) 绝对值sqrt(x) 平方根ceiling(x) 不小于x的最小整数floor(x) 不大于x的最大整数trunc(x) 向0方向取整round(x, digits=n) 将x舍入为指定小数位数signif(x, digits=n) 将x舍入为指定的有效数字位数cos(x),sin(x),tan(x) 三角函数acos(x),asin(x),... 反三角函数cosh(x),sinh(x),... 双曲三角函数acosh(x),... 反双曲三角函数log(x, base=n) 对x取n为底数的对数log(x) 自然对数log10(x) 常用对数exp(x) 自然指数对数据做变换是这些函数的主要用途。这些函数作用于vector或matrix或data.frame对象会作用于每一个独立的值,见:
V1 = c(1:10)V2 = c(11:20)M = matrix(V1, nrow = 2)D = data.frame(V1, V2)sqrt(V1)## [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427## [9] 3.000000 3.162278sqrt(M)## [,1] [,2] [,3] [,4] [,5]## [1,] 1.000000 1.732051 2.236068 2.645751 3.000000## [2,] 1.414214 2.000000 2.449490 2.828427 3.162278sqrt(D)## V1 V2## 1 1.000000 3.316625## 2 1.414214 3.464102## 3 1.732051 3.605551## 4 2.000000 3.741657## 5 2.236068 3.872983## 6 2.449490 4.000000## 7 2.645751 4.123106## 8 2.828427 4.242641## 9 3.000000 4.358899## 10 3.162278 4.4721365.2.2 统计函数
常用的统计函数如表所示:
== 函数 == == 描述 ==mean(x) 平均值median(x) 中位数sd(x) 样本标准差 (用n-1)var(x) 样本方差 (用n-1)mad(x) 绝对中位数quantile(x, probs) 求分位数range(x) 求值域sum(x) 求和diff(x, lag=n) n阶差分min(x) 最小值max(x) 最大值scale(x, 数据中心化(center=TRUE) cener=TRUE, 数据标准化(center和scale=TRUE) scale=TRUE)上面的函数一般会有na.rm选项,当na.rm=TRUE时会排除缺失值进行计算。具体请参考help(·)。
一个具体的应用是:
x mean(x)## [1] 4.5sd(x)## [1] 2.44949如果冗余地写,那么有:
x n meanx css sdx meanx## [1] 4.5sdx## [1] 2.449495.2.3 概率函数
概率函数通常用来生成特征已知的模拟数据,以及在用于编写的统计函数中计算概率值。
在R中,概率函数形如:
[dpqr]分布名缩写()其中:
- d = 概率密度函数(pdf, density的d)
- p = 累积分布函数(cdf, 给定分位点求概率p(X<=x)的p)
- q = 分位数函数(quantile function的q,给定概率p求分位数数,是p的反函数)
- r = 生成随机数(random)
例如:
x pdf cdf quan layout(matrix(c(1,2,3,3), 2, 2))plot(x, pdf, title("dnorm"))plot(x, cdf, title("pnorm"))plot(pretty(c(0,1), 100), quan, title("qnorm"))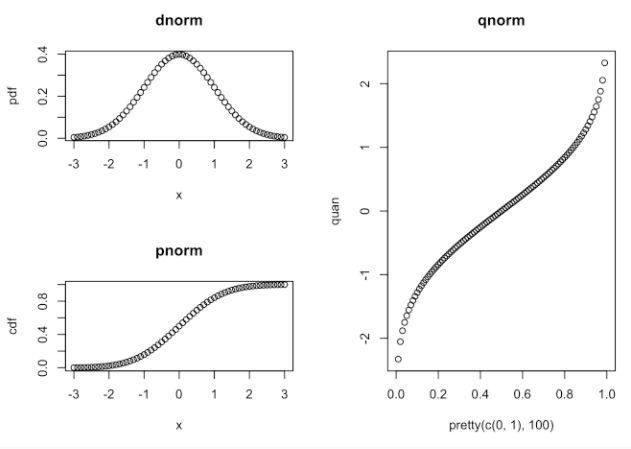
另外:
# 位于 z=1.96 左侧的标准正态分布pdf下方的面积是多少(知道分位点求概率)pnorm(1.96)## [1] 0.9750021# 标准正态分布的0.9分位点值为多少(知道概率求分位点)qnorm(0.9750021)## [1] 1.96关于画图的命令会在下一篇推文介绍。
1.关于设定随机种子
每次生成为随机数的时候,函数都会使用一个不同的种子,因此也会产生不同的结果。你可以通过set.seed()指定某个种子,让随机的结果可以重现(reproducible),见:
runif(5)## [1] 0.9580880 0.9346797 0.5693708 0.6829771 0.6390400runif(5)## [1] 0.2776539 0.6784761 0.8737694 0.8826680 0.9218422set.seed(1234)runif(5)## [1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154set.seed(1234)runif(5)## [1] 0.1137034 0.6222994 0.6092747 0.6233794 0.86091542.多元正态数据
在模拟研究和蒙特卡洛方法中,你经常需要获取来自给定均值向量和协方差的多元正态分布的数据。
MASS包中的mvrnorm()可以让这个问题变得容易,请先安装MASS包:
install.packages("MASS")然后可以使用:
library(MASS)## Warning: package 'MASS' was built under R version 4.0.2options(digits = 3)set.seed(1234)mean sigma 6721.2, 4700.9, -16.5, -47.1, -16.5, .3), nrow = 3, ncol = 3)mydata mydata names(mydata) mydata## Y X1 X2## 1 74.5 90.43 4.16## 2 248.2 196.43 3.46## 3 351.0 236.71 3.15## 4 -56.3 4.26 4.62## 5 299.3 138.24 3.04## 6 291.0 179.52 2.88## 7 151.6 129.12 4.10## 8 148.4 144.53 3.54## 9 147.5 140.93 3.92## 10 161.4 9.96 3.215.2.4 字符处理函数
数学和统计函数是用来处理数值型数据的,而字符处理函数可以从文本中抽取需要的数据信息。常见的字符串处理函数有:
== 函数 == == 描述 ==nchar(x) 计算x中的字符数量substr(x,start,end) 提取或替换字符串中的子串grep(pattern,x) 在x中搜索某种模式sub(pattern, 把x中pattern替换为replacement replacement, x)strsplit(x, split) 在split处分割向量x的元素paste(...,sep="") 连接字符串,分隔符为sep toupper(x) 大写转换tolower(x) 小写转换具体的函数形式请参考help文档。
5.2.5 其他实用函数
== 函数 == == 描述 ==length(x) 对象x的长度seq(from,to,by) 生成从from到to间隔为by的序列rep(x,n) 重复x序列n次cut(x,n) 将连续型变量x分割为有n个水平的因子pretty(x,n) 将连续变量x均匀划分为n个区间cat(..., 连接...中的对象,并输出到屏幕或file中 file="myfile", append=FALSE)使用上面的函数时,请先查看help获取详细信息。
另外,字符串里面该可以使用以下转义字符:
== 字符 == == 描述 ==\n 换行符(回车)\t 制表符(tab)\' 单引号\b 退格可以在Console输入 ?Quotes 了解更多例如:
name cat("Hello", name, "\b.\n", "Isn\'t R", "\t", "GREAT?\n")## Hello Bob .## Isn't R GREAT?在这里,使用\b是因为cat在连接对象时,每个对象都会用空格分开。句号和最后一个单词之间不需要空格,所以先用\b再输入.消除不要的空格。
5.4 控制流
在这里介绍控制流,即判断和循环结构。
5.4.1 循环结构
1. for循环
用for循环重复执行语句,知道某个变量的值不在包含在序列seq中为止,语法是:
for (var in seq) {statement}例如:
for (i in 1:3) {print("Hello world!")}## [1] "Hello world!"## [1] "Hello world!"## [1] "Hello world!"2. while循环
while循环地重复执行一条语句,知道条件不为真为止,语法是:
while (cond) {statement}例如:
i while (i>0) {print("Hello world"); i ## [1] "Hello world"## [1] "Hello world"## [1] "Hello world"5.4.2 判断结构
1. if-else 结构
语法为:
if (cond) {statement}if (cond) {statement1} else {statement2}2. ifelse 结构
语法是:
ifelse(cond, statement1, statement2)如果cond为真,那么执行statement1,否则执行statement2。例如:
ifelse(1>2, {"1更大"}, {"2更大"})## [1] "2更大"如果程序的行为是二元的,或者希望input和output均为向量时,尽量使用ifelse结构
3. switch结构
语法是:
switch(expr, ...)其中,...表示与expr的各种输出值绑定的语句。看下面的代码就一目了然了:
fellings for (i in fellings){ print( switch (i, happy = "I am glad you are happy!", afraid = "There is nothing to fear.", sad = "Cheer up!", angry = "Calm down now." ) )}## [1] "Cheer up!"## [1] "There is nothing to fear."5.4.3 用户自编函数
R最大的优点之一就是用户可以自行添加函数。一个函数的基本结构的语法是:
myfunction statements return(object)}函数的对象只能在内部使用,返回的对象的数据类型是任意的,从标量到列表都可以。比如:
judge return(ifelse(num1>num2, num1, num2))}judge(4,100)## [1] 1005.6 整合与重构
R提供了很多方法用来整合(aggregate)和重构(reshape)数据。后面将使用在R基本安装中的mtcars数据框:
mtcars[1:3,1:3]## mpg cyl disp## Mazda RX4 21.0 6 160## Mazda RX4 Wag 21.0 6 160## Datsun 710 22.8 4 1085.6.1 数据集的转置
转置即反转行和列,直接使用t()就可以直接对一个矩阵或一个数据框进行转置了。对于数据框,行名将变成列名。如果是对向量进行t()函数,那么第一次t()会把向量变成一维矩阵,第二次t(t(·))才会转置。例如:
V class(V)## [1] "integer"class(t(V))## [1] "matrix" "array"M t(M)## [,1] [,2]## [1,] 1 2## [2,] 3 4## [3,] 5 6t(mtcars[1:3,1:3])## Mazda RX4 Mazda RX4 Wag Datsun 710## mpg 21 21 22.8## cyl 6 6 4.0## disp 160 160 108.05.6.2 整合数据
在R中使用一个或多个by和一个预先定义好的函数来折叠(collapse)数据是比较容易的,语法是:
aggregate(x, by=list(...), FUN)其中x是待折叠的对象;by是一个变量名组成的列表;FUN是预先定义好的用来计算描述性统计量的标量函数。
例如,我们根据气缸数(cyl)和档位数(gear)整合mtcars数据,并返回个数值型变量的均值:
options(digits = 3)attach(mtcars)aggdata aggdata## Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb## 1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00## 2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00## 3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08## 4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50## 5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00## 6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00## 7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00## 8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00其中,Group.1表示气缸数(4、6、8);Group.2表示档位数(3、4、5)。这里返回的列表表示,
- 平均来看,有4个气缸,3个档位的的车型每加仑汽油行驶英里数(mpg)为21.5
你也可以在by=list()中指定变量的名称,比如:
options(digits = 3)attach(mtcars)## The following objects are masked from mtcars (pos = 3):## ## am, carb, cyl, disp, drat, gear, hp, mpg, qsec, vs, wtaggdata aggdata## Group.cyl Group.gears mpg cyl disp hp drat wt qsec vs am gear carb## 1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00## 2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00## 3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08## 4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50## 5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00## 6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00## 7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00## 8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.005.6.3 reshape2包
reshape2包是一套重构和整合数据集的万能工具,但用起来有点复杂。我们首先要安装reshape2包:
install.packages("reshape2")然后用下面的例子来简要介绍reshape2包。
ID Time X1 X2 mydata mydata## ID Time X1 X2## 1 1 1 5 6## 2 1 2 3 5## 3 2 1 6 1## 4 2 2 2 41. 融合
数据集的融合是将其重构为这样的格式:
每个测量变量独占一行,行中带有唯一确定这个测量所需的标识符变量
上面的mydata可以使用下面的代码进行重构:
library(reshape2)## Warning: package 'reshape2' was built under R version 4.0.2md md## ID Time variable value## 1 1 1 X1 5## 2 1 2 X1 3## 3 2 1 X1 6## 4 2 2 X1 2## 5 1 1 X2 6## 6 1 2 X2 5## 7 2 1 X2 1## 8 2 2 X2 4注意,必须指定唯一确定每个变量所需的变量(在这里是ID和Time),而表示测量变量名的变量(X1, X2)将由程序为你自动创建。
2. 重构
使用dcast()命令重构融合后的数据,并使用你提供的一个公式和一个(可选的)用于整个数据的函数将其重构,调用的语法是:
newdata 在这里,md是已经融合的数据;formula描述了想要的最后结果;fun.aggregate是数据整合函数。其中,formula的格式为
rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...其中,rowvar1 + rowvar2 + ...定义了行标签,以确定各行的内容;colvar1 + colvar2 + ...则列表标签,定义了各列的内容,比如:
dcast(md, ID+Time~variable)## ID Time X1 X2## 1 1 1 5 6## 2 1 2 3 5## 3 2 1 6 1## 4 2 2 2 4dcast(md, ID+variable~Time)## ID variable 1 2## 1 1 X1 5 3## 2 1 X2 6 5## 3 2 X1 6 2## 4 2 X2 1 4