CBNet论文详解
目录
简介
CBNET
CBNET网络架构
其他组合方式
Same Level Composition (SLC)
Adjacent Lower-Level Composition (ALLC)
Dense Higher-Level Composition (DHLC)
实验
检测结果对比
不同组合样式的比较
CBNET的共享权重系数
CBNET的BackBone数量
CBNET的加速版
Effectiveness of basic feature enhancement by CBNet
总结
在现有的基于CNN的检测器中,骨干网是提取基本特征的非常重要的组成部分,检测器的性能很大程度上依赖于骨干网络。CBNET的主要目的是利用现有的主干网络例如ResNet、ResNeXt等构建更强大的主干网络。具体地说,作者提出了一种新的策略,通过相邻主干之间的复合连接组合多个相同的主干网络,从而形成一个更强大的主干网络,称为复合主干网络(Composite Backbone Network:CBNet)。通过这种方式,CBNet将前一个主干网的输出特征,即高级特征,作为输入特征的一部分逐步的传递给后续的主干网络,最后一个主干网(称为Lead backbone),通过这种特征映射的方式进行对象检测。实验证明,CBNet可以很容易地集成到大多数SOTA探测器中,并显著提高它们的性能。在实验过程中,将FPN、Mask R-CNN和Cascae R-CNN在COCO数据集上分别提高了百分之1.5-3.0的AP值。并且,实力分割也有着明显的提升。特别地,通过简单的将所提出的CBNet集成到baseline检测器Cascade Mask R-CNN中,我们在COCO数据集(mAP值为53.3)上用single-scale获得了最新的结果,证明了所提出的CBNet体系结构的巨大有效性。论文远吗:源码。
简介
目标检测是计算机视觉中最基本的问题之一,可广泛应用于自动驾驶、智能视频监控、卫星遥感等领域。近年来,随着深度卷积网络的蓬勃发展,目标检测技术取得了很大进展。一些优秀的探测器已经被提出,例如SSD (Liu et al. 2012)。、Faster R-CNN (Ren et al. 2015)、retanet (Lin et al. 2018)、FPN (Lin et al. 2017a)、Mask R-CNN (He et al. 2017a)、Cascade R-CNN (Cai and Vasconcelos 2018)等。
一般来说,在典型的基于CNN的目标检测器中,骨干网络用于提取检测目标的基本特征,骨干网络通常是为图像分类任务设计的,并在ImageNet数据集上进行预先训练。毫不奇怪,如果主干可以提取更多信息的Feature Map,那么它的宿主检测器将相应的得到更好的目标检测结果。换句话说,更好的主干网络可以为宿主网络提供更好的目标检测性能,如表1所示:
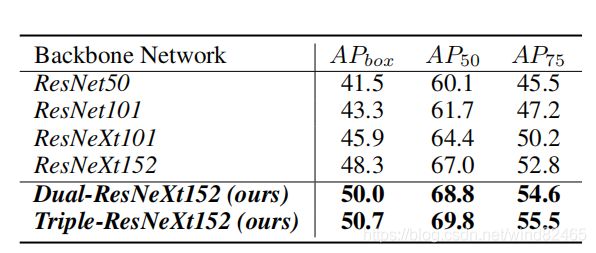
表1
表1是SOTA目标检测模型Cascade Mask R-CNN 利用不同的主干网络在COCO数据集上的测试结果。说明了骨干网越深越大,检测性能越好,而我们的复合骨干网结构可以进一步加强现有的非常强大的目标检测主干网络,如ResNeXt152等可以进一步加强其性能。因此,从AlexNet开始
(Krizhevsky, Sutskever, and Hinton 2012),更深更大(即更强大的)主干已经被最先进的探测器所利用,如VGG (Simonyan和Zisserman 2014)、ResNet (He et al. 2016)、DenseNet (Huang et al. 2017)、ResNeXt (Xie et al. 2017)。尽管基于深度和大型主干网络的SOTA模型取得了令人鼓舞的结果,但仍有很大的性能改进空间。此外,设计一个新的更强大的主干并在ImageNet上对其进行预训练,以达到更好的检测性能,这种代价也是非常巨大的。此外,由于现有的骨干网几乎都是为图像分类任务而设计的,直接使用骨干网提取基本特征进行目标检测可能会导致性能欠佳。
图(1)
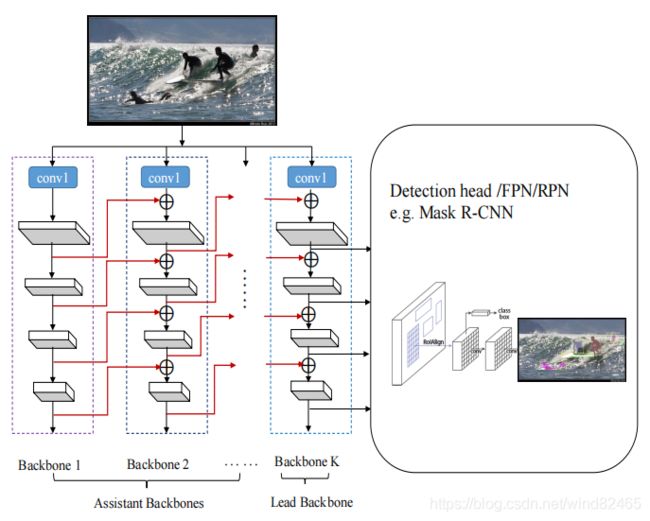
处理上面提到的问题,如图(1)所示,我们提出以一种全新的方式结合多个相同的现有主干网络,以建立一个更强大的主干来进行目标检测。将结合起来的主干网络成为一个全新的“组合主干网络”(Composite Backbone NetWork:CBNet)。反过来说,CBNET包含多个相同的主干网络,其中,前面的网络称之为助理网络,最后输出的网络称之为Lead网络。图(1)中,从左到右,辅助骨干网络中每个阶段的输出,即更高层次的特征,通过复合连接流到后续骨干网络的平行阶段作为输入的一部分。传到最右侧部分的Lead主干网络作为目标检测网络。显然,CBNet提取的目标检测特征融合了多个骨干的高层和低层特征,从而提高了检测性能。值得一提的是,在训练集成CBNet模型的检测器时不需要对CBNet进行预训练。取而代之的是,我们只需要初始化CBNet中的单个网络即可,使用目前广泛且免费可用的单个骨干的预训练模型,如ResNet和ResNeXt等。换句话说,采用CBNet比设计一个新的更强大的骨干网络并在ImageNet上对其进行预训练更经济和有效。
在广泛测试的MS-COCO基准,将CBNET应用到几种最先进的目标探测器,如FPN (Lin et al. 2017a), Mask RCNN (He et al. 2017)和Cascade R-CNN (Cai and Vasconcelos 2018)。实验结果表明,所有监测模型的mAP值一致提高了1.5% ~ 3.0%,从而证明了该复合方法的有效性。同时,对于CBNET,在实力分割中也有着明显的提升,尤其是使用Triple-ResNeXt152模型(![]() 3个ResNeXt152的复合骨干网架构 ),在COCO数据集上实现了SOTA结果,mAP值为53.3,胜过了所有已发布的目标检测模型。
3个ResNeXt152的复合骨干网架构 ),在COCO数据集上实现了SOTA结果,mAP值为53.3,胜过了所有已发布的目标检测模型。
CBNET的主要贡献如下:
1、作者提出了一个叫做CBNET的联合主干网络模型,可以在不需要提出新的主干网络的情况下,只需组织现有的主干网络即可大大提升目标检测的精度。
2、CBNET取得了在MSCOCO数据集的single-scale的SOTA结果,将目标检测的mAP提升到了53.3%。
CBNET
本节详细阐述了所提出的CBNet。我们首先描述它的架构和变体。然后,我们在详细解释基于CBNet的检测网络的结构。
CBNET网络架构
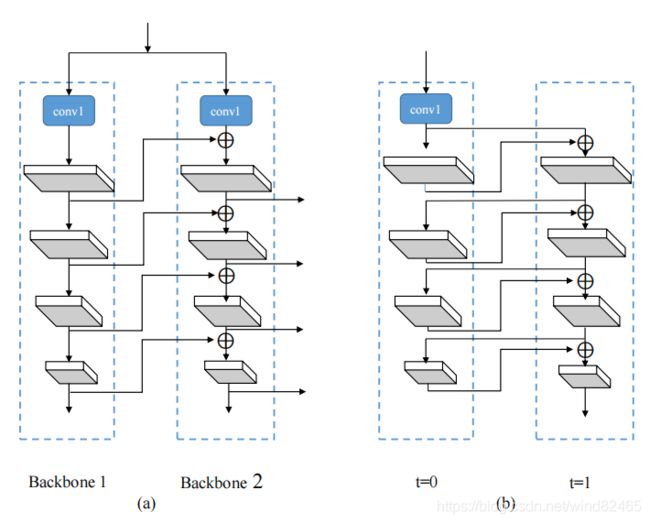
图2:(a).CBNet体系结构(K = 2)和(b).给予RCNN的网络架构(T = 2)
CBNET包含K个网络相同的主干网络(![]() )。当K=2时,称之为Dual-Backbone (DB) 。当K=3时,称之为Triple- Backbone (TB)。
)。当K=2时,称之为Dual-Backbone (DB) 。当K=3时,称之为Triple- Backbone (TB)。
正如图(1)所示,CBNET中有两种主干网络,分别是Lead主干网络和助理主干网络。最后的主干网络(Backbone K)![]() 称之为Lead主干网络,
称之为Lead主干网络,![]() 之前的所有网络
之前的所有网络![]() 称之为助理主干网络。每个主干网络由L个阶段组成(一般L = 5),每个阶段由几个具有相同大小的特征图的卷积层组成。 主干的第l阶段实现了非线性变换
称之为助理主干网络。每个主干网络由L个阶段组成(一般L = 5),每个阶段由几个具有相同大小的特征图的卷积层组成。 主干的第l阶段实现了非线性变换![]() 。
。
在只有一个主干网络的传统卷积网络中,第l-1阶段的输出作为第l阶段的输入,可以表示为:
![]() (1)
(1)
与单个网络模型不同的是,在CBNet体系结构中,我们采用了新的方法助理骨干![]() 用来增强Lead Backbone
用来增强Lead Backbone ![]() 的功能,通过迭代地将前一个主干网络的输出功能作为后续网络的一部分输入传递后续主干。具体而言,
的功能,通过迭代地将前一个主干网络的输出功能作为后续网络的一部分输入传递后续主干。具体而言,![]() 的第l阶段的输入是
的第l阶段的输入是![]() 的l-1阶段的输出和
的l-1阶段的输出和![]() 网络l阶段的输出共同组成。这个过程可以整合成公式(2)。如下:
网络l阶段的输出共同组成。这个过程可以整合成公式(2)。如下:
![]() (2)
(2)
式中,g(·)为复合连接,由1×1卷积层和批处理归一化层组成,用于减少通道和上采样操作。
因此,![]() 第l层的输出作为了
第l层的输出作为了![]() 层第l层的输入,并添加到原始输入的特征图中去通过相应的层。考虑到这种组合风格将前一个主干网络的相邻的更高层次阶段的输出提供给后续网络,称之为相邻高级成分(AHLC)。
层第l层的输入,并添加到原始输入的特征图中去通过相应的层。考虑到这种组合风格将前一个主干网络的相邻的更高层次阶段的输出提供给后续网络,称之为相邻高级成分(AHLC)。
在双阶段目标检测任务中,CBNET只有 Lead主干网络作为RPN的输入,其余的助理网络将每个阶段自己的输出转发到下一相邻网络的输入。并且这些助理网络据用广泛的普适性,可以选择很多不同的网络作为主干网络,例如ResNeXt 等。
其他组合方式
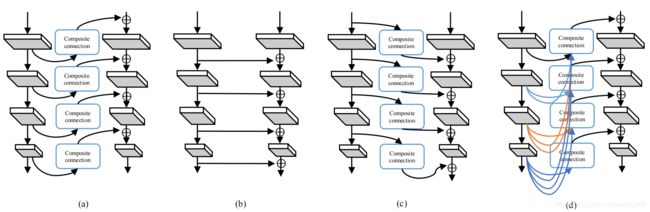
图(3)
图3:双主干架构的四种组合样式(辅助主干和Lead主干网络)。(a)相邻高级合成(AHLC)。(b)同层构成(SLC)。(c)相邻的低水平构成(ALLC)。(d)高密度高级成分(DHLC)。蓝色框中表示的复合连接表示一些简单的操作,即元素操作、缩放、1×1 Conv层和BN层等。
Same Level Composition (SLC)
SLC的主要思想就是将前一个主干网络的l-1层的输出作为后续网络的l层的输入,与AHLC的不同。AHLC是将前一个主干网络的l层作为后续网络的输入。其过程可以整合成公式(3)如下所示:
![]() (3)
(3)
从公式(3)可以看出,SLC所谓的相同阶段的意思是前一个主干网络和后续主干网络的相同l-1层作为后续主干网络l层的输入。SLC模型具体架构可以参看图(3)b,K=2。
Adjacent Lower-Level Composition (ALLC)
Dense Higher-Level Composition (DHLC)
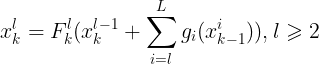 (5)
(5)
实验
实验部分采用MSCOCO数据集,通过目标检测和实例分割进行结果对比。本文中的baseline方法是我们基于Detectron框架。除Cascade Mask R-CNN ResNeXt152外,所有baseline均采用single-scale进行训练。输入的图片被resize成1333*800。对于大多数原始baseline,单个GPU上的批处理大小是两个图像。由于GPU内存的限制,在每块GPU上放置一幅图像,使用CBNet训练检测器。同时,将初始学习率设置为默认值的一半,并与原始baseline训练相同的epoch。在训练CBNET时,没有改变原始baseline的任何信息,除了学习率和batch size。
推理阶段,同样没有改变任何baseline的网络配置,只有对Cascade Mask R-CNN使用了single-scale和multi-scale分别测试,其他模型全部single-scal进行测试。图片大小与训练时候一致,都限制到了1333*800。值得注意的是,我们并没有对后续进行NMS处理。
检测结果对比
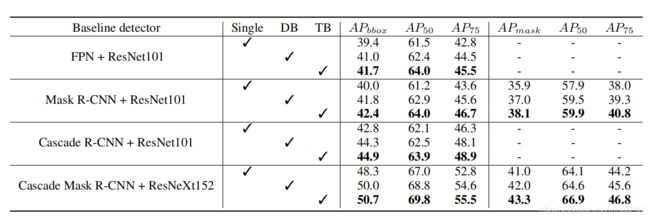
从上表可以看出来,作者用了四中不用的模型验证CBNET的有效性,并且在目标检测和实例分割都取得了SOTA的结果。Single:表示baseline模型;DB:表示CBNET的Dual-Backbone模式;
TB:表示CBNET的Triple-Backbone模式。5-7列表示目标检测结果,8-10列表示实例分割结果。
在表2的每一行,我们比较一个baseline及CBNet,可以看到我们的CBNet不断地以显著的幅度改进所有这些baseline的结果。CBNET将baseline的mAP提升了1.5-3%。
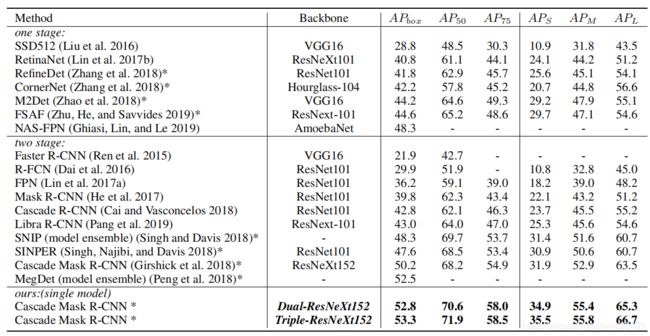
在上表中的目标检测的比较,CBNET和最先进的目标检测模型在COCO数据集的实验结果对比。*:表示multi-scale方式。
不同组合样式的比较
除了与原有的baseline模型进行对比,作者也与提出的几种组合模式进行了对比,结果如下表所示:
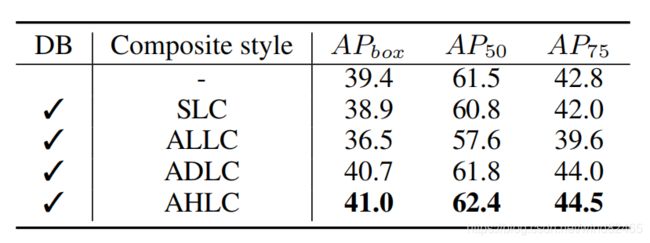
上表中,比较不同组合样式,baseline为FPN ResNet101 。DB:Dual-Backbone模式。SLC”表示相同级别组成;“ALLC”表示邻接的低级构成;“ADLC”是相邻的密集层次构成;“AHLC”是相邻的高级层次构成。
从上面表格中可以看出来,肃然DHLC(ADLC)是稠密连接,但是它的结果并没有比AHLC结果精度更好,这几种模式中AHLC是结果最好的。
CBNET的共享权重系数
由于使用了更多的骨干网络,CBNet带来了网络参数的急剧增加。为了进一步证明检测性能的提高主要来自于其复合体系结构,而不是网络参数的增加,我们在FPN上进行了实验,配置为两主干网络共享权重Dual-ResNet101,结果如下表所示:
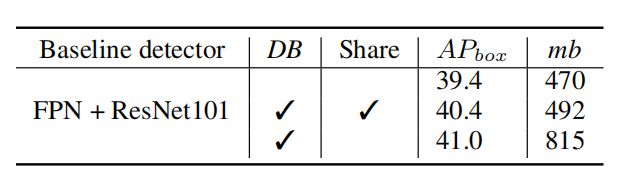
可以看到,当在CBNet中共享骨干权重时,参数的增量可以忽略不计,但检测结果仍然比baseline的mAP好很多(40.4 vs 39.4)。但是,当我们不共享权值时,性能的提高就不是很大(mAP从40.4提高到41.0),这说明主要是复合架构提高了性能,而不是网络参数的增加。
CBNET的BackBone数量
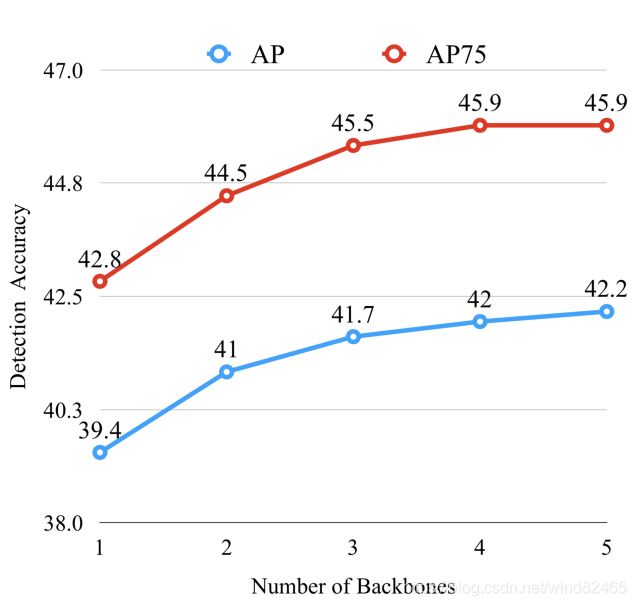
我们以FPN-ResNet101为baseline,进行实验,研究CBNet中骨干数量与检测性能之间的关系。结果如下图所示。可以看出,检测mAP随着骨干数量的增加而稳步增加,当骨干数量达到3时趋于收敛。因此,考虑到速度和存储成本,我们建议采用双骨干网和三重骨干网架构,也就是论文中的DB和TB模式。
CBNET的加速版
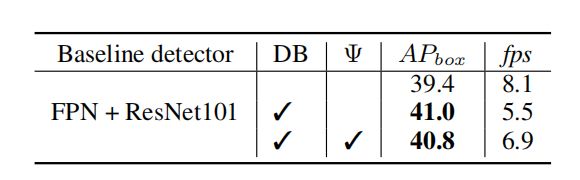
CBNET的主要不足还是检测速度上,因为它用了更多的主干网络进行特征提取,加大了模型的计算复杂度,请见下表:
表(5)
使用CBNET的DB模式,AP上升了1.6个百分点,但是帧率从8.1下降到了5.5。为了解决这个问题,CBNET从提出了一个CBNET的加速版本,它移除了助理主干网络中的前两个阶段,如下图所示:
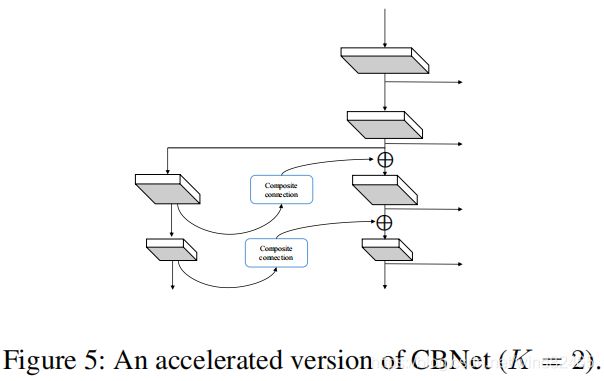
这个加速版本是表(5)的最后一行,可以看到它的精度只下降了0.2%,但是帧率从5.5上升到了6.9。
Effectiveness of basic feature enhancement by CBNet
作者认为CBET因为比传统的单模型的检测网络结构相比,CBNET可以提取更好的图像的基础特征,为了验证这一点,如图6所示,在一些例子中,作者可视化并比较了CBNet提取的特征图和原始单一模型的主干网络的提取结果。图6中,包含两个前景目标:人和网球。非常明显,人是大目标,而网球是小目标。因此,相应地可视化了CBNet和原始单一主干网络提取的大比例尺特征图(用于检测小目标)和小比例尺特征图(用于检测大目标)。图(6)中明显的看到,CBNET加强了前景目标的提取,并且弱化了背景信息。
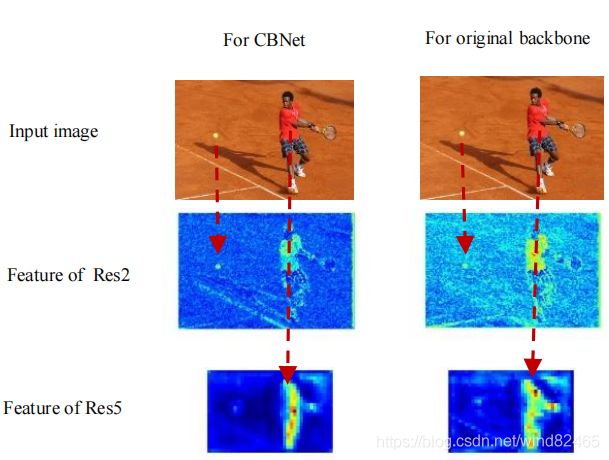
图(6)
图6:CBNet (Dual-ResNet101)和原始主干网络提取的特征的可视化对比(ResNet101)。baseline检测器为FPN-ResNet101。对于每个主干网络,根据前景对象的大小可视化Res2和Res5,沿着通道维度平均Feature map。值得注意的是,来自CBNet的特征图更具有代表性,因为它们在前景物体上具有较强的激活值,而在背景物体上具有较弱的激活值。
总结
这篇peper提出了一种新的网络结构,称为复合骨干网(CBNet),以提高最先进的目标探测器的性能。CBNet由一系列具有相同网络结构的主干网络组成,并使用复合连接将这些主干连接起来。具体地说,前一级主干中每一级的输出通过复合连接流到后续主干的平行级作为输入的一部分。最后,利用最后一个主干网络即Lead主干网的特征图进行目标检测。作者做了大量的实验,结果表明,CBNet对于许多先SOTA检测器,如FPN、Mask R-CNN和Cascade R-CNN,都是有益的,以提高它们的检测精度。更具体地说,上述目标检测模型在COCO数据集上的mAP值增加了约1.5 - 3%,通过简单地将CBNet集成到Cascade Mask R-CNN基线中,就可以在COCO上获得mAP值为53.3的最新结果。同时,实验结果表明,该方法对提高实例分割性能也非常有效。