用limma包进行多组差异表达分析
写在前面:最近在使用limma包进行差异表达分析,参考了网上许多教程都觉得说的云里雾里,很不清楚。经过我自己一段时间非常痛苦的钻研,弄明白了,解决了我的实际需求。于是决定将我的分析经验写下来,分享给需要的人。
首先加载前期预处理好的表达矩阵。(我的原始表达矩阵文件已附在文后,大家有需要可以下载实践)
setwd("E://Rworkplace")
data<-read.table("GSE98793.txt")表达矩阵格式如下图所示,行名为基因名,列名为样本名。
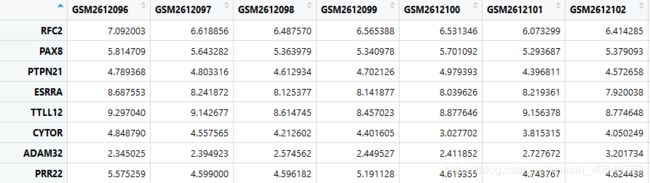
创建样本分类信息表。
所谓样本分类信息表,实际上就是值你的样本名一一对应的属性是什么(譬如case还是control)。
我自己根据GEO数据库中该芯片的分类信息先自己在excel中整理了一张表。因为这张芯片原作者在上传数据的时候,样本分类数据很乱,实验组和对照组的样本有时候交错分布,譬如ID为GSM2612287的样本是第192个样本,是对照组即健康人群。而ID为GSM2612128的样本是第33个样本,取样自重症抑郁症患者。我们在对样本进行差异表达分析之前,一定要做的工作是弄明白每一个样本的属性,我做这个工作,实际上是对样本的属性进行了手工注释。

然后我将上图中的第二第三列,复制单独保存在一个txt文档中。(即gene_list.txt)
第一列(1,2,3,……)只是为了辅助排序的东西,因为这个1,2,3,就是样本在总的样本中的位置,这个表格就是告诉我们第几个样本,它是对照组,第几个样本,取样自重症抑郁症患者。
| 1 | HC |
| 2 | HC |
| 3 | HC |
| 4 | HC |
| …… | …… |
加载上述分类表gene_list.txt。并按照数据框的第一列升序排序。
取第二列,这样处理得到的就是每一个位置所对应的样本属性信息。我们最终想要得到的也就是向量group。(实际情况大家可能不会像我这样麻烦,具体问题具体分析,只要得到一个类如group的向量)
group_list<-read.table("gene_list.txt")
new_group<- group_list[order(group_list[,1]),]
group<-new_group[,2] 注:其中HC代表的是健康对照组,MDD指重症抑郁症;anxiety,即焦虑症。
注:其中HC代表的是健康对照组,MDD指重症抑郁症;anxiety,即焦虑症。
接着,加载limma包,构造如下矩阵。(这一段可以照抄。根据自己的实际情况替换变量)
suppressMessages(library(limma))
design <- model.matrix(~0+factor(group))
colnames(design)=levels(factor(group))
rownames(design)=colnames(data)
然后,我们规定哪一组数据与哪一组数据比较。
这里也是原来我比较困惑的地方,因为我的数据是有MDD,anxiety两个实验组,HC对照组。而我实际只需要比较MDD与HC的差异表达情况,而一般的教程中并未涉及或者介绍模糊。
下面这段的代码的意思就是比较design矩阵中HC与MDD level。(关于多组分析的其它疑惑,可以参考知乎文章)
contrast.matrix<-makeContrasts("HC-MDD",levels=design)

完成以上两个表格之后,就可以直接跑下面的代码,得到差异表达数据了。(有时间具体分析什么意思)
##step1
fit <- lmFit(data,design)
##step2
fit2 <- contrasts.fit(fit, contrast.matrix)
fit2 <- eBayes(fit2)
##step3
tempOutput = topTable(fit2, coef=1, n=Inf)
nrDEG = na.omit(tempOutput) 分析得到的nrDEG如下图所示:
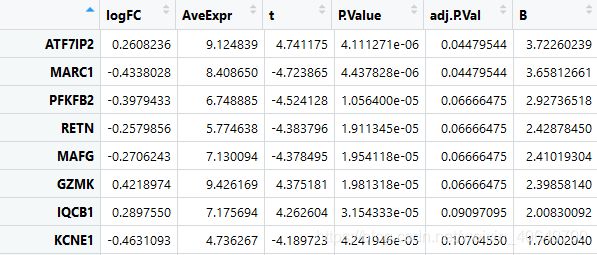
保存分析好的差异表达数据。
write.table(nrDEG,"limma_GSE98793.txt")全部代码:
setwd("E://Rworkplace")
data<-read.table("GSE98793.txt")
group_list<-read.table("gene_list.txt")
new_group<- group_list[order(group_list[,1]),]
group<-new_group[,2]
suppressMessages(library(limma))
design <- model.matrix(~0+factor(group))
colnames(design)=levels(factor(group))
rownames(design)=colnames(data)
contrast.matrix<-makeContrasts("HC-MDD",levels=design)
##step1
fit <- lmFit(data,design)
##step2
fit2 <- contrasts.fit(fit, contrast.matrix)
fit2 <- eBayes(fit2)
##step3
tempOutput = topTable(fit2, coef=1, n=Inf)
nrDEG = na.omit(tempOutput)
write.table(nrDEG,"limma_GSE98793.txt")
熬夜写到这儿,一定会有些疏漏和错误,欢迎指正,共同进步!
【数据链接】https://me.csdn.net/download/weixin_40640700
重新修改了上传数据所需的积分,设置为零。可是系统还是自动调为了1。
如果参考数据不能顺利下载的话,可以邮箱[email protected],我邮箱发送。