Python 爬虫
Python 爬虫
【目录】
-
初识爬虫与HTML基础
-
BeautifulSoup
-
json
-
带参数请求数据
-
csv&excel (所爬数据的存取)
-
cookies
-
Selenium
-
定时与邮件
-
协程
-
Scrapy框架与实操
-
反爬虫

(一)初识爬虫与HTML基础
1.初识爬虫
1.浏览器与爬虫的工作原理


简化一下,即为:

2.爬虫的工作步骤
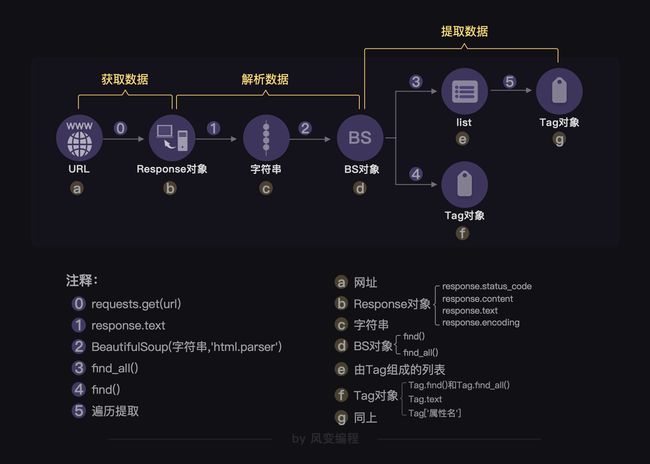
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
2.数据获取:Requests库
接下来我们学习第一步,获取数据
import requests
res=requests.get('url')
print(type(res))
#requests.models.Response
res.encoding='解码形式'

若是字符就用res.text就好,若是图片得用res.content(图片内容需要以二进制wb读写)
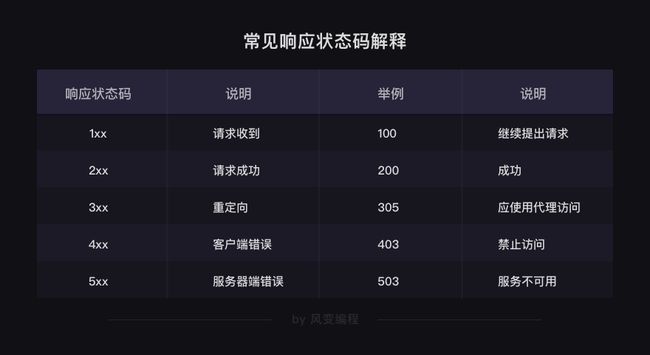
代码汇总
# 调用requests模块
import requests
# 获取网页源代码,得到的res是response对象。
res=requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 检测请求是否正确响应
print(res.status_code)
res.encoding = 'utf-8'
# 正确响应,进行读写操作
# 新建一个名为book的html文档,你看到这里的文件没加路径,它会被保存在程序运行的当前目录下。
# 字符串需要以w读写。你在学习open()函数时接触过它。
if res.status_code == 200:
file = open('book.html','w')
# res.text是字符串格式,把它写入文件内。
file.write(res.text)
# 关闭文件
file.close()
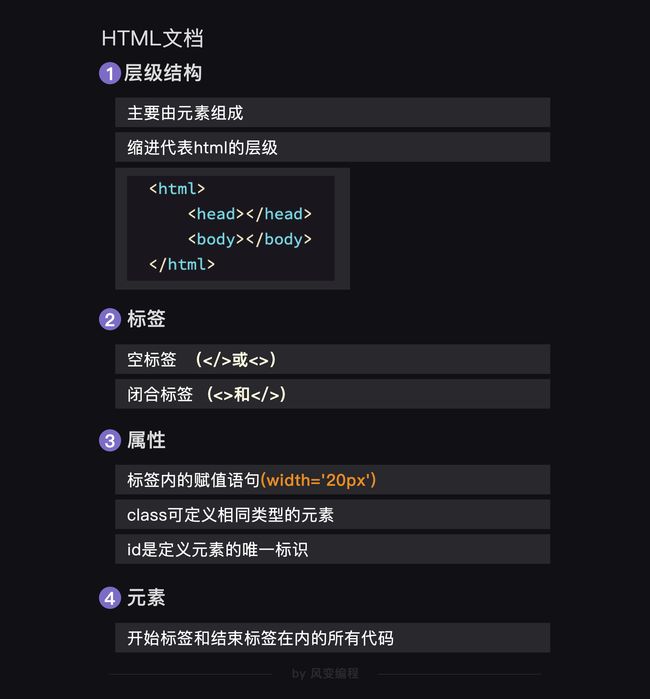
3.HTML基础(Hyper Text Markup Language 超文本标记语言)
-
ctrl-u 显示网页源代码
-
闭合标签,它们绝大多数成对出现(有开始标签
<>,也有结束标签),如:和 是表单标签。空标签,顾名思义,指那些“孤苦伶仃”的单标签,它们“形影单只”只有一个尖括号
<>(斜杠/可省略),标签开始即结束,比如上面的是链接标签,是input标签。
3.值得注意的是,不要把标签与元素混淆,前面说的元素,其实是包含了开始标签与结束标签内的所有代码。如html元素是指包括标签内的所有代码。
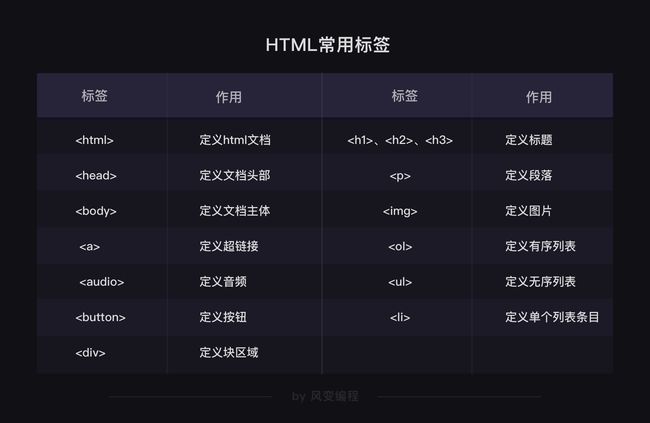
4.结构、常用标签与属性

5.关于style
①面向对象块的大一统style
style好像是选择了作为标签放到head里面,其格式是:
<style>
h1{
font-weight:bold;/**字体粗细/
text-align:center;/*对齐方式*/
letter-spacing:2px;/*文本字符间距*/
color: #20b2aa;/*元素的颜色*/
}
style>
然后在后面的body里的
…
就不用再规定style了。②不同class定制不同style

class属性的作用是给元素增添类名,多个元素可配置一个类名,类名相同的元素沿袭同一套样式。
③自己的id属性对应特色化style
<head>
<meta charset="UTF-8">
<style>
.book {
padding: 0px;
margin: 0px;
}
#book_info {
/*你看它这个也是像class一样写在style块里的,只是把.变成了#罢辽*/
width: 450px;
font-size: 13px;
}
style>
head>
<body>
<h1 align='center' style='color: #20b2aa;'>这个书苑不太冷h1>
<h2 style=" font-weight: bold;padding-bottom: 3px;margin-bottom: 16px;border-bottom: 1px solid #ddd;">吴枫喜欢的书:h2>
<div class="book">
<img style='float: left;margin-right: 20px;height: 200px;' src="https://res.pandateacher.com/book_qidianyimin.jpg" alt="奇点遗民">
<div class='book' id="book_info">
<h4>《奇点遗民》h4>
<p style='color:#4c4a4a;'>本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。
p>
<a href="https://wordpress-edu-3autumn.localprod.oc.forchange.cn/">点这里看看a>
div>
div>
body>
(二)数据解析和提取(Beautiful soup)
1.数据解析
import requests
# 引入BS库,下面的bs4就是beautifulsoup4
from bs4 import BeautifulSoup
res=requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup(res.text,'html.parser')
如果出现乱码,我们只需要在网页上点击"右键"——“查看网页源代码”,会弹出一个新的标签页,然后搜索(快捷键 CRTL+F)charset,查看一下编码方式,然后加一行(res=request.get()之后,解析网页之前)代码使用 response.encoding 属性就好。
res.encoding='utf-8'
2.数据提取

· find_all()获得的是几个结果形成的列表。
· 括号里的class_,这里有一个下划线,是为了和python语法中的类 class区分,避免程序冲突。当然,除了用class属性去匹配,还可以使用其它属性,比如style属性等。
· 使用“搜索工具”,尝试得到更为合适的区分选项
# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 返回一个Response对象,赋值给res
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把Response对象的内容以字符串的形式返回
html= res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过定位标签和属性提取我们想要的数据
items = soup.find_all(class_='books')
for item in items:
# 打印item
print('想找的数据都包含在此:\n',item)
print(type(item))
#是Tag对象,与find()提取出的数据类型是一样的
· 然而,无论是使用find直接提取出来的tag还是用find_all提取出来的类列表里抽取出来的每一项tag,其都是tag对象,也就是那个带尖括号的东西,我们还可以/需要对其进行处理。

# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 返回一个response对象,赋值给res
res =requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把res解析为字符串
html=res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过匹配属性class='books'提取出我们想要的元素
items = soup.find_all(class_='books')
# 遍历列表items
for item in items:
# 在列表中的每个元素里,匹配标签提取出数据
kind = item.find('h2')
# 在列表中的每个元素里,匹配属性class_='title'提取出数据
title = item.find(class_='title')
# 在列表中的每个元素里,匹配属性class_='info'提取出数据
brief = item.find(class_='info')
# 打印书籍的类型、名字、链接和简介的文字
print(kind.text,'\n',title.text,'\n',title['href'],'\n',brief.text)
3.数据类型转换过程
(三)JSON
1. Network
第0行的左侧,红色的圆钮是启用Network监控(默认高亮打开),灰色圆圈是清空面板上的信息。右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,我们在爬取一些会发生跳转的网页时,会点亮它。
第1行,是对请求进行分类查看。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR,我们等会重点讲它)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识。

夹在第2行和第1行中间的,是一个时间轴。记录什么时间,有哪些请求。
第2行,就是各个请求,你可以看下面这张表来理解(读,但不需要记忆)。
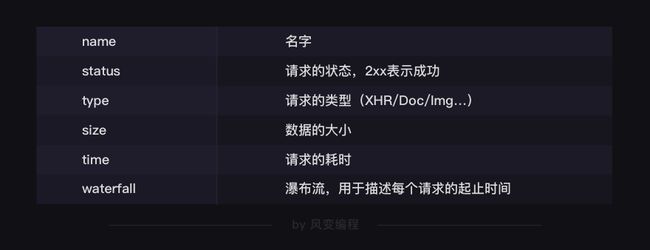
最后一行是个统计:有多少个请求,一共多大,花了多长时间。
2.XHR
①判断方法

②XHR
更新网页内容,而不用重新加载整个网页。这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现,服务器和浏览器之间传输数据。

在这里先只研究Header部分:

这个网址打开之后是这样,列表字典相互嵌套,乱七八糟:

所以我们还是从前面那个比较结构化的Preview那里进行研究:

· 尝试写代码
# 引用requests库
import requests
# 调用get方法,下载这个字典
res = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 把它打印出来
print(res.text)
但在这里,我们遇到一个障碍:使用res.text取到的,是字符串。它不是我们想要的列表/字典,数据取不出来。
3. json
json是一种数据交换的语法。对我们来说,它只是一种规范数据传输的格式,形式有点像字典和列表的结合体。从它的组成上来看,有花括弧、方括弧,冒号和逗号,一种字典和列表相互嵌套的体系。这种特殊的写法决定了,json能够有组织地存储信息。
# 定义一个字典
a = {'name':'吴枫'}
# 定义一张列表
b = [1,2,3,4]
# 定义一个json
c = {
"forchange":
[
{ "name":"吴枫" , "gender":"male"},
{ "name":"酱酱" , "gender":"female"},
{ "name":"延君" , "gender":"male"},
]
}

一般来说,这三条占得越多,数据的结构越清晰;占得越少,数据的结构越混沌。
例如html,它通过标签、属性来实现分层和对应。
json 则是另一种组织数据的格式,长得和Python中的列表/字典非常相像。它和html一样,常用来做网络数据传输。刚刚我们在XHR里查看到的列表/字典,严格来说其实它不是列表/字典,它是json。
这里一定要理解区分清楚!!图一是html,而图二是json,它们虽然同为一层一层的优秀结构化语言,但毕竟还是不一样的东西嗷。然后之前学的最简单的老式网页是get到以后用bs解析再用bs对应的find方法找到对应html标签和特征进行提取,但是如果是这种XHR里面的json结构,那个方法就不适用啦。而且如果我们只是直接res.text得到的也是字符串形式,所以我们就要寻求解决办法啦。

# 引用requests库
import requests
# 调用get方法,下载这个字典
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
json_music = res_music.json()
# 一层一层地取字典,获取歌单列表
list_music = json_music['data']['song']['list']
# list_music是一个列表,music是它里面的元素
for music in list_music:
# 以name为键,查找歌曲名
print(music['name'])
# 查找专辑名
print('所属专辑:'+music['album']['name'])
# 查找播放时长
print('播放时长:'+str(music['interval'])+'秒')
# 查找播放链接
print('播放链接:https://y.qq.com/n/yqq/song/'+music['mid']+'.html\n\n')
不过要注意,我们使用的是res对象的.json()方法,并不是json模块!!!json模块不在教学范围之内,所以不做展开,可阅读它的官方文档来了解,地址:https://docs.python.org/3/library/json.html
(四)带参数请求数据
1.带参数请求数据
① 分析网页与逻辑尝试
每个url都由两部分组成。前半部分大多形如:https://xx.xx.xxx/xxx/xxx ;后半部分,多形如:xx=xx&xx=xxx&xxxxx=xx&……两部分使用?来连接。前半部分是我们所请求的地址,它告诉服务器,我想访问这里。而后半部分,就是我们的请求所附带的参数,它会告诉服务器,我们想要什么样的数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XpwaxnCb-1627913292063)(C:\Users\86133\AppData\Roaming\Typora\typora-user-images\image-20210608175259349.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yY0ngEnL-1627913292065)(C:\Users\86133\AppData\Roaming\Typora\typora-user-images\image-20210608175307411.png)]
尝试以pagenum作为 i 来循环5次,发现,居然把同一段评论爬取了5遍!这是前端的一种特殊的处理机制,这里的pagenum并不是实际意义上的页码。真正令更多精彩评论展示发挥作用的字段其实是pagesize。如果想获得前5页的内容,那就相当于15 * 5 = 75条评论,也就是pagesize = 75。
但不得不说这样有点不太好看,怎么解决呢。
②params(是为了翻页或者一些要求目的,带params就是带参请求数据)
事实上,request模块里的request.get()提供了一个参数params,可以让我们用字典的形式,把参数传进去。

所以,其实我们可以把Query String Parameters里的内容,直接复制下来,封装为一个字典,传递给params。只是有一点要特别注意:要给他们打引号,让它们变字符串。
因此,代码可以是这样的:
import requests
# 引用requests模块
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
# 请求歌曲评论的url参数的前面部分
for i in range(5):
params = {
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'GB2312',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0',
'cid':'205360772',
'reqtype':'2',
'biztype':'1',
'topid':'102065756',
'cmd':'6',
'needmusiccrit':'0',
'pagenum':str(i),
'pagesize':'15',
'lasthotcommentid':'song_102065756_3202544866_44059185',
'domain':'qq.com',
'ct':'24',
'cv':'10101010'
}
# 将参数封装为字典
res_comments = requests.get(url,params=params)
# 调用get方法,下载这个字典
json_comments = res_comments.json()
list_comments = json_comments['comment']['commentlist']
for comment in list_comments:
print(comment['rootcommentcontent'])
print('-----------------------------------')
2.请求头(Request Headers)(是一般爬虫就都要带的)
①请求头
user-agent(中文:用户代理)会记录你电脑的信息和浏览器版本(如我的,就是windows10的64位操作系统,使用谷歌浏览器)。origin(中文:源头)和referer(中文:引用来源)则记录了这个请求,最初的起源是来自哪个页面。它们的区别是referer会比origin携带的信息更多些。
如果我们想告知服务器,我们不是爬虫,而是一个正常的浏览器,就要去修改user-agent。倘若不修改,那么这里的默认值就会是Python,会被服务器认出来。
②伪装请求头

如上,只需要封装一个字典就好了。和写params非常相像。而修改origin或referer也和此类似,一并作为字典写入headers就好。
import requests
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'origin':'https://y.qq.com',
# 请求来源,本案例中其实是不需要加这个参数的,只是为了演示
'referer':'https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html',
# 请求来源,携带的信息比“origin”更丰富,本案例中其实是不需要加这个参数的,只是为了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
# 伪装请求头
params = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'59091538798969282',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'lossless':'0',
'flag_qc':'0',
'p':'1',
'n':'20',
'w':'周杰伦',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0'
}
# 将参数封装为字典
res_music = requests.get(url,headers=headers,params=params)
# 发起请求,填入请求头和参数
如果真的需要爬取成千上万条信息,将for循环执行成百上千次。那么,最好将自己的爬虫伪装成真实的浏览器(填写请求头)—— 因为在那种情况下,服务器很可能拒绝爬虫访问。甚至有的网站,一开始就不允许爬虫访问。如,知乎、猫眼电影。
伪装请求头最大的应用是帮助我们应对“反爬虫”技术,将Python爬虫伪装成真正的浏览器,不为服务器所辨识;同时也可以标记这个请求的来源是什么,最终帮助我们拿到想要的信息。
(五) cookies
1.post
这里的请求方式是post,而不是我们之前学过的get。其实,post和get都可以带着参数请求,不过get请求的参数会在url上显示出来。
(六)Selenium
在遇到页面交互复杂或是URL加密逻辑复杂的情况时,selenium就派上了用场,它可以真实地打开一个浏览器,等待所有数据都加载到Elements中之后,再把这个网页当做静态网页爬取就好了。
1.调用并设置浏览器引擎
from selenium import webdriver
driver=webdriver.Chrome()
2.获取数据
import time
driver.get('URL')
time.sleep(1)
driver.close()
3.解析与提取数据&自动操作浏览器(输入、点击)
①Selenium
selenium库同样也具备解析数据、提取数据的能力。它和BeautifulSoup的底层原理一致,但在一些细节和语法上有所出入。首先明显的一个不同即是:selenium所解析提取的,是Elements中的所有数据,而BeautifulSoup所解析的则只是Network中第0个请求的响应。用selenium把网页打开,所有信息就都加载到了Elements那里,之后,就可以把动态网页用静态网页的方法爬取了。
解析数据是由driver自动完成的,提取数据是driver的一个方法。
1 提取单个元素
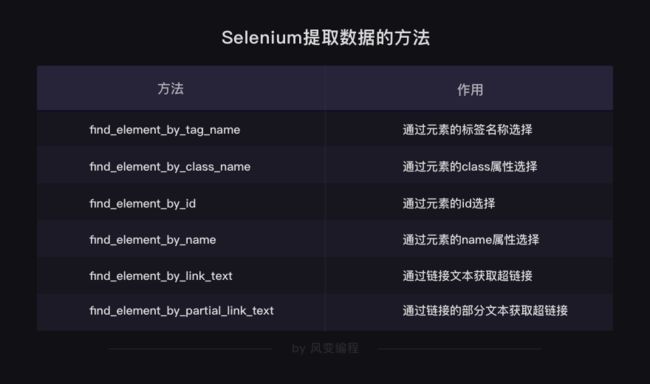
提取出的数据属于WebElement类对象,它与BeautifulSoup中的Tag对象类似,也有一个属性.text,可以把提取出的元素用字符串格式显示。此外,它也有一个方法,可以通过属性名提取属性的值,这个方法是.get_attribute()。

2 提取多个元素
把刚才的element换成复数elements就好了。

提取出的是一个列表,WebElements对象,需要用.text才能返回它的文本内容。既然得到了列表,就可以和find_all返回的结果类似,同样用for循环遍历列表就可以提取出列表中的每一个值了。
3 自动操作浏览器
在 a=find_element_by_xxx(‘xxx’)后,下一句写a.send_keys(‘xxxx’)或者a.click()等,可以达到向文本框里填入内容或点击按钮的效果。

from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/')
time.sleep(2)
teacher=driver.find_element_by_id('teacher')
teacher.send_keys('你')
assistant=driver.find_element_by_id('assistant')
assistant.send_keys('你们')
button=driver.find_elements_by_class_name('sub')
button.click()
time.sleep(2)
driver.close()
②beautifulsoup
BeautifulSoup需要把字符串格式的网页源代码解析为BeautifulSoup对象,然后再从中提取数据。selenium刚好可以获取到渲染完整的网页源代码。是使用driver的一个方法:page_source。
pageSource=driver.page_source()
#它的数据类型是用requests.get()获取到的是Response对象,在交给BeautifulSoup解析之前,需要用到.text的方法才能将Response对象的内容以字符串的形式返回。而使用selenium获取到的网页源代码,本身已经是字符串了。
- 以下是写的一个天气爬虫+定时邮件项目代码:
import requests
from bs4 import BeautifulSoup
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import schedule
import time
#封装天气爬虫
def weather_spider():
#请求头
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41'}
#网址
url='http://www.weather.com.cn/weather/101020100.shtml'
#获取
res=requests.get(url,headers=headers)
res.encoding = 'utf-8'
#解析
soup=BeautifulSoup(res.text,'html.parser')
#提取
temp=soup.find(class_='tem')
tem=temp.text
weat=soup.find(class_='wea')
wea=weat.text
return tem,wea
#封装邮件发送任务
def send_email(tem,wea):
#记录一些重要参数
account='[email protected]'
password=input('qq邮箱授权码:')
receiver='[email protected]'
#建立SMTP链接
mailhost='smtp.qq.com'
qqmail=smtplib.SMTP_SSL(mailhost)
qqmail.connect(mailhost, 465)
#登录
qqmail.login(account, password)
#写邮件
content='今日天气:'+tem+wea
mes=MIMEText(content,'plain','utf-8')
mes['Subject']=Header('今日天气预报','utf-8')
try:
qqmail.sendmail(account,receiver,mes.as_string())
print('邮件发送成功')
except:
print('有内鬼,邮件发送失败')
qqmail.quit()
#封装任务
def job():
print('任务开始')
#传递参数
tem,wea=weather_spider()
send_email(tem,wea)
print('任务完成')
#使用定时器定时执行任务
schedule.every().day.at('15:52').do(job)
while True:
schedule.run_pending()
time.sleep(1)
如果真的需要每天都发送天气信息,需要保持程序一直运行的状态,和电脑在一直开机的状态。因为如果程序结束或者电脑关机了的话,就不会定时爬取天气信息了。事实上,在程序员真实的开发环境中,程序一般都会挂在远端服务器,因为远端服务器24小时都不会关机,就能保证定时功能的有效性了。不过如果想让程序挂在远端服务器的话,需要去做一些额外的学习。
(七)协程
1.gevent库
①开启多协程模式
from gevent import monkey
monkey.patch_all()
②import gevent并使用方法

因为gevent只能处理gevent的任务对象,不能直接调用普通函数,所以需要借助gevent.spawn()来创建任务对象。需要注意:gevent.spawn()的参数需为要调用的函数名及该函数的参数。比如,gevent.spawn(crawler,url)就是创建一个执行crawler函数的任务,参数为crawler函数名和它自身的参数url。调用gevent库里的joinall()方法,能启动执行所有的任务。gevent.joinall(tasks_list)就是执行tasks_list这个任务列表里的所有任务,开始爬取。
2.queue模块(队列)


3.整体代码实现
#1.导入模块,开启多协程模式
from gevent import monkey
monkey.patch_all()
#2.准备工作:
#导入模块
import gevent,time,requests
from gevent.queue import Queue
#开始计时
start=time.time()
#组织好要爬的网站们,放在列表里
url_list=['x','xx','xxx','xxxx','xxxxx']
#3.创建队列对象,并且用其函数.put_nowait()把网址都放进队列里
work=Queue()
for url in url_list:
work.put_nowait(url)
#4.写爬虫函数(在队列不空的时候,把队列中的网址循环取出并get网页)
def crawler():
while not work.empty():
url=get_nowait()
res=requests.get(url)
print(url,work.qsize(),res.status_code)
#5.把函数转化成gevent任务并装入任务列表里,再使用gevent.joinall()方法执行所有任务(就是让爬虫开始爬取网站)
tasks_list=[]
#这里是相当于创建了两个爬虫
for x in range(2):
task=gevent.spawn(crawler)
task_list.append(task)
gevent.joinall(tasks_list)
#停止计时
end=time.time()
爬取时可用图像表示为:

真正大型的爬虫程序不会单单只靠多协程来提升爬取速度的。比如,百度搜索引擎,可以说是超大型的爬虫程序,它除了靠多协程,一定还会靠多进程,甚至是分布式爬虫。
(八)Scrapy 框架
1.Scrapy结构

① Scheduler(调度器):
主要负责处理引擎发送过来的requests对象(即网页请求的相关信息集合,包括params,data,cookies,request headers…等),会把请求的url以有序的方式排列成队,并等待引擎来提取(功能上类似于gevent库的queue模块)。
②Downloader(下载器):
负责处理引擎发送过来的requests,进行网页爬取,并将返回的response(爬取到的内容)交给引擎。它对应的是爬虫流程**【获取数据】**这一步。(也就是它包含了get的功能)
③Spiders(爬虫):
核心业务部门,主要任务是创建requests对象和接受引擎发送过来的response(Downloader部门爬取到的内容),从中解析并提取出有用的数据。它对应的是爬虫流程**【解析数据】和【提取数据】**这两步。
④Item Pipeline(数据管道):
只负责存储和处理Spiders提取到的有用数据,对应的是爬虫流程**【存储数据】**这一步。
⑤Downloader Middlewares(下载中间件):
相当于下载器部门的秘书,比如会提前对引擎发送的诸多requests做出处理。
⑥Spider Middlewares(爬虫中间件)
相当于爬虫部门的秘书,比如会提前接收并处理引擎发送来的response,过滤掉一些重复无用的东西。
其大体协作过程如下:

在Scrapy里,整个爬虫程序的流程都不需要我们去操心,且Scrapy中的程序全部都是异步模式,所有的请求或返回的响应都由引擎自动分配去处理。哪怕有某个请求出现异常,程序也会做异常处理,跳过报错的请求,继续往下运行程序。在一定程度上,Scrapy可以说是非常让人省心的一套爬虫框架。
2.Scrapy用法

1.创建项目
① 打开cmd
d:
cd python3.7.7
cd pythoncode
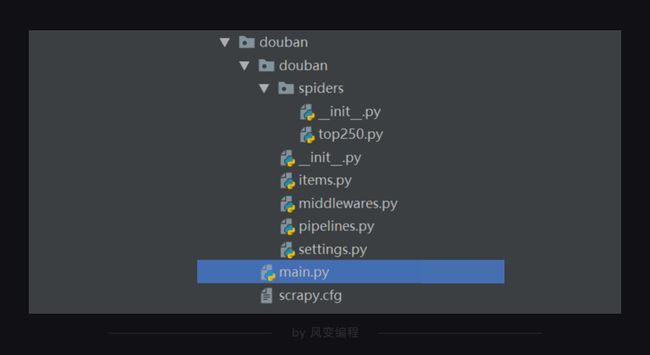
scrapy startproject xxx(项目总文件夹名称)
②可以用vscode打开项目,其结构如下所示:

Scrapy项目里每个文件都有特定的功能,比如settings.py 是scrapy里的各种设置。items.py是用来定义数据的,pipelines.py是用来处理数据的,它们对应的就是Scrapy的结构中的Item Pipeline(数据管道)。
③创建爬虫文件(后面的大部分代码都需要在这里面编写)

2.定义item数据
3.编写Spider文件
①代码大体结构
在Scrapy中,每个爬虫的代码结构基本都如下所示:
import scrapy
import bs4
#从scrapy里的一个基础类继承和定制一个属于该项目的子类
class DoubanSpider(scrapy.Spider):
#相关参数(新加/修改)
name='douban'
allowed_domains=['book.douban.com']
start_urls=['xx']#也常常会有很多个叭
#定义其专属的解析方法(注意,这里不需要get嗷,因为其他部件会做好get任务并把response给到我们)
def parse(self,response):
soup=Bxxxx略
-
name是定义爬虫的名字,这个名字是爬虫的唯一标识。name = 'douban'意思是定义爬虫的名字为douban。等会我们启动爬虫的时候,要用到这个名字。 -
allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。如果网址的域名不在这个列表里,就会被过滤掉。当你在爬取大量数据时,经常是从一个URL开始爬取,然后关联爬取更多的网页。比如,假设我们今天的爬虫目标不是爬书籍信息,而是要爬豆瓣图书top250的书评。我们会先爬取书单,再找到每本书的URL,再进入每本书的详情页面去抓取评论。allowed_domains就限制了,我们这种关联爬取的URL,一定在book.douban.com这个域名之下,不会跳转到某个奇怪的广告页面。 -
start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。在此,allowed_domains的设定对start_urls里的网址不会有影响。 -
parse是Scrapy里默认处理response的一个方法,中文是解析。
②较为具体的构建(基本包括了实现思路及事情发生的流程)
class DoubanSpider(scrapy.Spider):
name='douban'
allowed_domains=['book.douban.com']
start_urls=[]
for x in range(3):
url='https://book.douban.com/top250?start='+str(x*25)
start_urls.append(url)
#这是根据网址结构,得到的网址的变化规律,从而使得写入网址变得清晰美观了
写进url的部分应该接着就被调度器像队列那样排了起来,然后被下载器下载了网页,接下来,就需要对解析部分函数进行构建啦。也就是,我们要借助parse方法处理response,借助BeautifulSoup来提取我们想要的内容。
class DoubanSpider(scrapy.Spider):
name='douban'
allowed_domains=['book.douban.com']
start_urls=[]
for x in range(3):
url='https://book.douban.com/top250?start='+str(x*25)
start_urls.append(url)
def parse(self,response):
#解析
soup=bs4.BeautifulSoup(response.text,'html.parser')
datas=soup.find_all('a')[1]['title']
for data in datas:
title=data.find('a')[1]['title']
publish=data.find('p',class_='pl').text
score=data.find('span',class_='rating_nums')
print([title,publish,score])
#这里我们暂时先只做打印操作
在scrapy中,我们会专门定义一个用于记录数据的类。当我们每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个对象,利用这个对象来记录数据。每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。定义这个类的py文件,正是items.py。
已知,我们要爬取的数据是书名、出版信息和评分,我们看看如何在items.py里定义这些数据:
#items.py
import scrapy
class DoubanItem(scrapy.Item):
title=scrapy.Field()
publish=scrapy.Field()
score=scrapy.Field()
导入scrapy,目的是,等会所创建的类将直接继承scrapy中的scrapy.Item类,其中许多属性和方法就可直接使用。如引擎能将item类的对象发给Item Pipeline(数据管道)处理。
然后我们定义了一个DoubanItem类。它继承自scrapy.Item类,可以理解为一个自定义的字典,然后后面title=scrapy.Field()就是把各个数据以类似字典的形式记录下来,这样我们就可以在自己写的爬虫部分代码里使用这个类,即实例化然后以类似字典的方式填入各个对应关系啦.
import scrapy
import bs4
from ..items import DoubanItem
# 需要引用DoubanItem,它在items里面。因为是items在top250.py的上一级目录,所以要用..items,这是一个固定用法。
class DoubanSpider(scrapy.Spider):
name='douban'
allowed_domains=['book.douban.com']
start_urls=[]
for x in range(3):
url='https://book.douban.com/top250?start='+str(x*25)
start_urls.append(url)
def parse(self,response):
#解析
soup=bs4.BeautifulSoup(response.text,'html.parser')
datas=soup.find_all('a')[1]['title']
for data in datas:
item=DoubanItem()
item['title']=data.find('a')[1]['title']
item['publish']=data.find('p',class_='pl').text
item['score']=data.find('span',class_='rating_nums')
print(item['title'])
yield item
#最后这一句是把获得的item传递给引擎,它有点类似return,不过它和return不同的点在于,它不会结束函数,且能多次返回信息。
4. 修改setting设置
实际运行时, Scrapy里的默认设置需要修改, 比如需要修改请求头。点击settings.py文件,你能在里面找到如下的默认设置代码:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
-
把
USER _AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头。 -
又因为Scrapy是遵守robots协议的,如果是robots协议禁止爬取的内容,Scrapy也会默认不去爬取,所以我们还得修改Scrapy中的默认设置。把
ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。
5. 运行scrapy
运行Scrapy有两种方法:
-
一种是在本地电脑的终端跳转到scrapy项目的文件夹(跳转方法:cd+文件夹的路径名),然后输入命令行:
scrapy crawl douban(douban 就是我们爬虫的名字)。 -
另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。
我们只需要在这个main.py文件里,输入以下代码,点击运行,Scrapy的程序就会启动。
#导入cmdline模块,可以实现控制终端命令行。
from scrapy import cmdline
#用execute()方法,输入运行scrapy的命令。
cmdline.execute(['scrapy','crawl','douban'])
在Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,我们就能操控终端。:在cmdline模块中,有一个execute方法能执行终端的命令行,不过这个方法需要传入列表的参数。我们想输入运行Scrapy的代码scrapy crawl douban,就需要写成['scrapy','crawl','douban']这样。
6.存储
1.存储成csv
存储成csv文件的方法比较简单,只需在settings.py文件里,添加如下的代码即可。
FEED_URI='./storage/data/%(name)s.csv'
FEED_FORMAT='csv'
FEED_EXPORT_ENCODING='ansi'
-
FEED_URI是导出文件的路径。'./storage/data/%(name)s.csv',就是把存储的文件放到与main.py文件同级的storage文件夹的data子文件夹里。 -
FEED_FORMAT是导出数据格式,写csv就能得到csv格式。 -
FEED_EXPORT_ENCODING是导出文件编码,ansi是一种在windows上的编码格式,你也可以把它变成utf-8用在mac电脑上。
2.存储成excel
存储成Excel文件的方法要稍微复杂一些
①需要先在settings.py里设置启用ITEM_PIPELINES
#需要修改`ITEM_PIPELINES`的设置代码:(以下为原本的样子)
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'jobui.pipelines.JobuiPipeline': 300,
# }
只要取消ITEM_PIPELINES的注释(删掉#)即可。
#取消`ITEM_PIPELINES`的注释后:
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jobui.pipelines.JobuiPipeline': 300,
}
②编辑 pipelines.py 文件
存储为Excel文件,我们依旧是用openpyxl模块来实现,代码如下:
import openpyxl
class JobuiPipeline(object):
#定义一个JobuiPipeline类,负责处理item
def __init__(self):
#初始化函数 当类实例化时这个方法会自启动
self.wb=openpyxl.Workbook() #创建工作薄
self.ws=self.wb.active #定位活动表
self.ws.append(['公司','职位','地址','招聘信息']) #用append函数往表格添加表头
#然后,其实下面这个函数,我觉得可以考虑一下它在存储时与那个提取并yield的函数的对接,就比如说是一个个的还是怎么之类的
def process_item(self,item,spider):
#process_item是默认的处理item的方法,就像parse是默认处理response的方法
line=[item['company'],item['position'],item['adress'],item['details']]
#把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给line
self.ws.append(line)
#用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格
return item
#将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度
def close_spider(self,spider):
#close_spider是当爬虫结束运行时,这个方法就会执行
self.wb.save('./jobui.xlsx')
#保存文件
self.wb.close()
#关闭文件
③修改Scrapy中settings.py文件里的默认设置
-
添加请求头
-
把
ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False。 -
取消
DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,我们要把下载延迟的时间改成0.5秒。
暂时仍需学习:
1.scrapy框架的更多知识
2.MySQL模块
3.正则化表达式(re模块)