(tensorflow笔记)神经网络中的一些关键概念(学习率、激活函数、损失函数、欠拟合和过拟合、正则化和优化器)
目录
- 1.神经网络复杂度
-
- 空间复杂度
- 时间复杂度
- 2.学习率策略
-
- 指数衰减学习率
- 分段常数衰减
- 3.激活函数
-
- sigmoid
- tanh
- ReLU
- Leaky ReLU
- 建议
- 4.损失函数
-
- 均方误差损失函数
- 交叉熵损失函数
- 自定义损失函数
- 5.欠拟合与过拟合
- 6.正则化减少过拟合
-
- 概念
- 可视化
- 7.优化器更新网络参数
-
- SGD
-
- vanilla SGD
- SGD with Momentum (SGDM)
- SGD with Nesterov Acceleration(NAG)
- AdaGrad
- RMSProp
- AdaDelta
- Adam
- 优化器算法可视化
- 优化器选择
- 优化算法的常用tricks
1.神经网络复杂度
神经网络的复杂度,多用神经网络的层数和神经网络中待优化参数的个数表示。以下图为例说明

空间复杂度
神经网络的层数=隐藏层的层数+1个输出层
统计神经网络的层数时,只统计具有运算能力的层,输入层仅把数据传输过来,没有运算,不算到神经网络的层数中。输入层和输出层之间的所有层都叫做隐藏层。上图有2层神经网络
总参数=总w + 总b
(第一层)3×4+4 + (第二层)4×2+2 = 26
时间复杂度
神经网络中乘加运算的次数表示。有几条权重线,就有几次乘加运算
(第一层)3×4 + (第二层)4×2 = 20
2.学习率策略
参数更新公式如下,公式中的lr即为学习率,表示参数每次更新的幅度。

当学习率设置过小时,更新过慢,当学习率设置过大时,不收敛,那么学习率设置多少合适
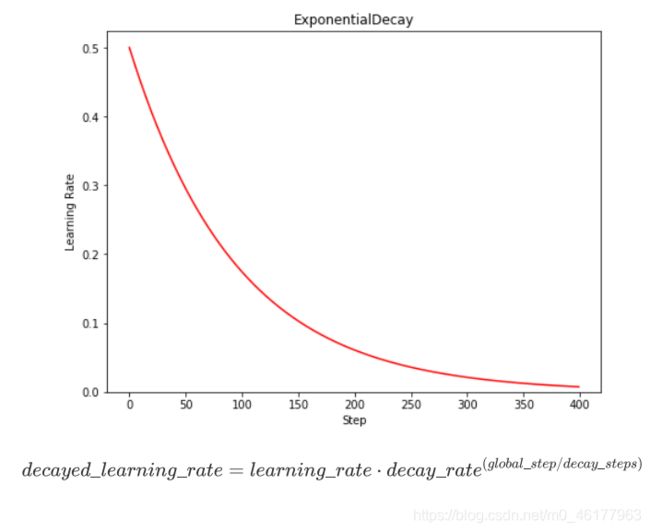
指数衰减学习率
可以先用较大的学习率,快速得到较优解,然后逐步减小学习率,使模型在训练后期稳定
![]()
可使用此公式实现指数衰减学习率,根据当前迭代次数,动态改变学习率的值。指数型学习率衰减法是最常用的衰减方法,在大量模型中都广泛使用.此公式中,绿色的文字为超参数,当前轮数一般为epoch或者是当前迭代的batch数global_step表示
TensorFlow API: tf.keras.optimizers.schedules.ExponentialDecay
分段常数衰减
TensorFlow API: tf.optimizers.schedules.PiecewiseConstantDecay
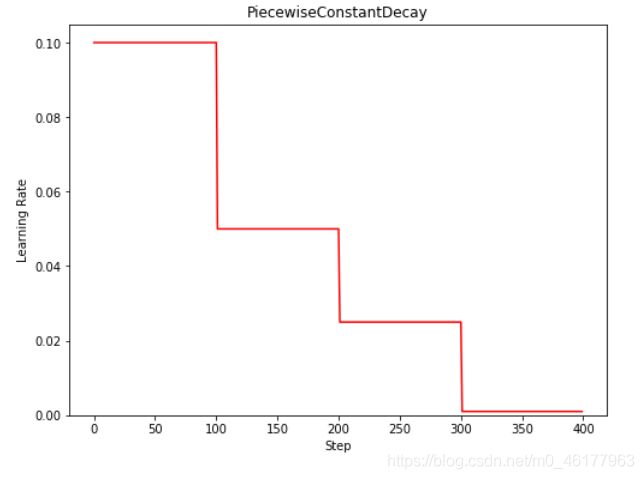
分段常数衰减可以让调试人员针对不同任务设置不同的学习率,进行精细调参,在任意步长后下降任意数值的learning rate,要求调试人员对模型和数据集有深刻认识,一般用的不多。
3.激活函数
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。引入非线性激活函数,可使深层神经网络的表达能力更加强大
优秀的激活函数应满足:
- 非线性:激活函数非线性时,多层神经网络可逼近所有函数
- 可微性:优化器大多使用梯度下降来更新参数
- 单调性:当激活函数是单调的,能保证单层网络的损失函数是凸函数
- 近似恒等性:f(x)约等于x。当参数初始化为随机小值时,神经网络更稳定
简单看下凸函数,比如这就是一个凸函数的图像,像一个大碗一样

与刚才的图有些相反,这是非凸函数,因为它是非凸的并且有很多不同的局部最小值

激活函数输出值的范围:
激活函数输出为有限值时,基于梯度的优化方法更稳定
激活函数输出为无限值时,建议调小学习率
sigmoid
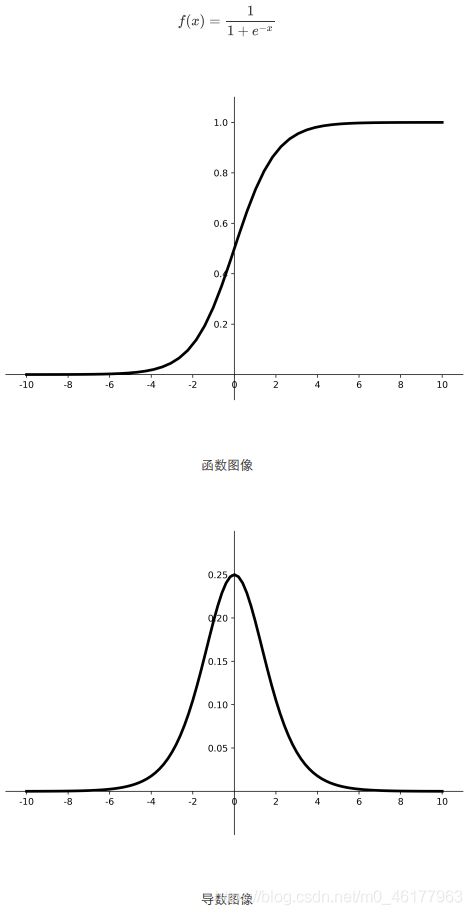
可以看到,sigmoid函数将输入值变换到0-1之间的值输出,若输入值是非常大的负数,则输出为0;若输入值是非常大的正数,则输出值为1,相当于对输入进行归一化。
现在sigmoid函数用的很少,主要的原因是,深层神经网络更新参数时,需要从输出层到输入层,逐层进行链式求导,而sigmoid函数的导数输出是0-0.25之间的小数,链式求导需要多层导数连续相乘,会出现多个0-0.25之间的小数连续相乘,结果将趋于0,产生梯度消失,使得参数无法继续更新
我们希望输入每层神经网络的特征是以0为均值的小数值,但是过sigmoid激活函数后的数据都是正数,会使收敛变慢。而且sigmoid函数存在幂运算,计算复杂度大,计算时间长
TensorFlow API: tf.math.sigmoid
优点:
- 输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可用作输出层;
- 求导容易
缺点:
- 易造成梯度消失;
- 输出非0均值,收敛慢;
- 幂运算复杂,训练时间长。
sigmoid函数可应用在训练过程中。然而,当处理分类问题作为输出时,sigmoid却无能为力。简单地说,sigmoid函数只能处理两个类,不适用于多分类问题。而softmax可以有效解决这个问题,并且softmax函数大都运用在神经网路中的最后一层网络中,使得值得区间在(0,1)之间,而不是二分类的。
tanh
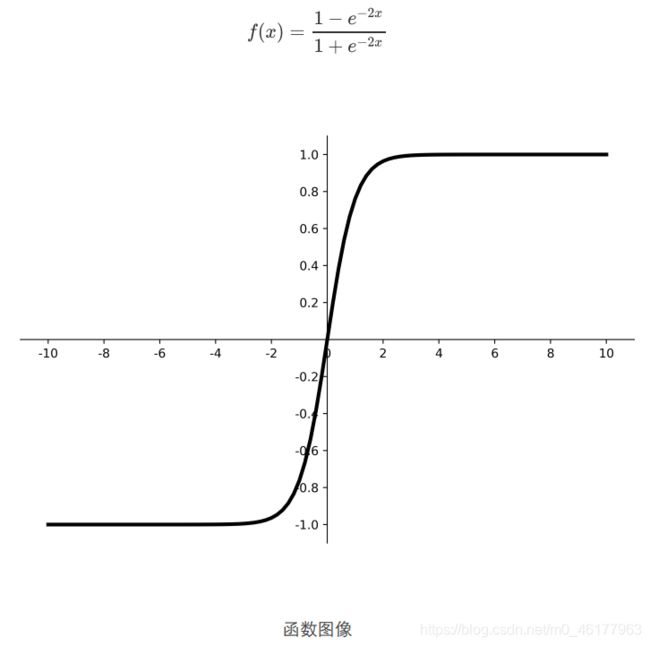
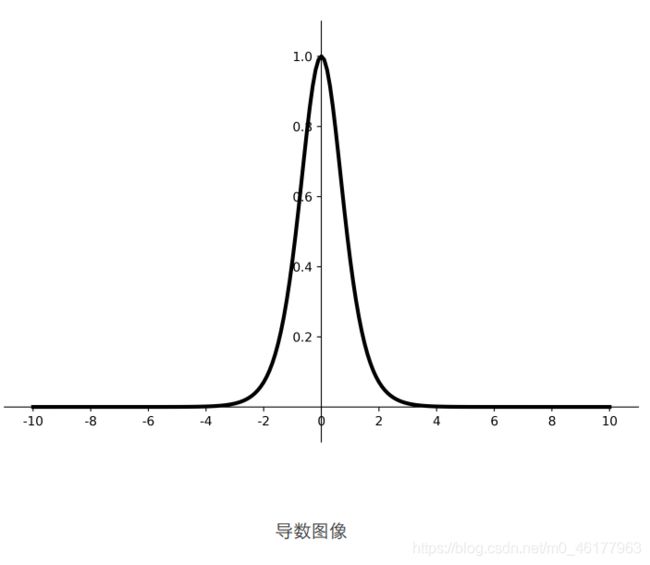
从函数图像看,tanh函数的输出为0均值了,但是依旧存在梯度消失和幂运算问题
TensorFlow API: tf.math.tanh
优点:
- 比sigmoid函数收敛速度更快。
- 相比sigmoid函数,其输出以0为中心
缺点:
- 易造成梯度消失;
- 幂运算复杂,训练时间长。
ReLU
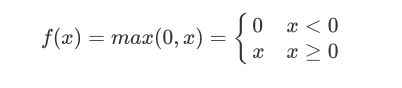
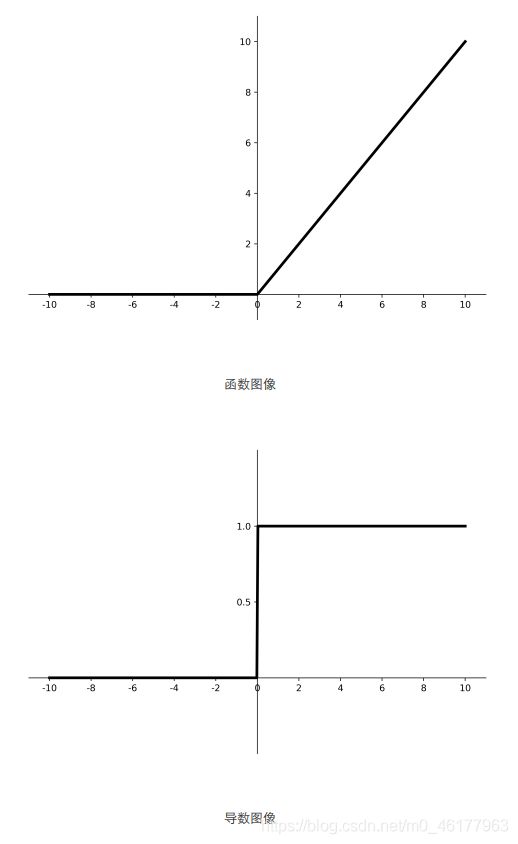
relu函数非常符合好的激活函数应该具有近似恒等性这一要求,
TensorFlow API: tf.nn.relu
优点:
- 解决了梯度消失问题(在正区间);
- 只需判断输入是否大于0,计算速度快;
- 收敛速度远快于sigmoid和tanh,因为sigmoid和tanh涉及很多expensive的操作;
- 提供了神经网络的稀疏表达能力。
缺点:
- 输出非0均值,收敛慢;
- Dead ReLU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。即送入激活函数的特征是负数时,激活函数输出是0,反向传播得到的梯度是0,导致参数无法更新,造成神经元死亡
其实,导致神经元死亡的根本原因是送入神经元的负数特征过多导致的,我们可以改进随机初始化,避免过多的负数特征送入relu函数,可以通过设置更小的学习率,减少参数分布的巨大变化,避免训练中产生过多负数特征进入relu函数
Leaky ReLU
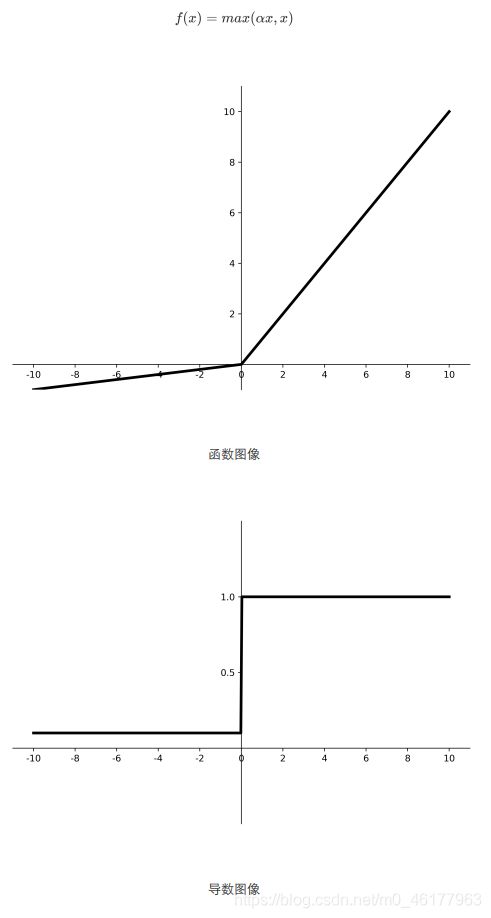
Leaky ReLU是为解决relu负区间为0,引起神经元死亡问题而设计的,Leaky ReLU的负区间引入了一个固定的斜率a,使得Leaky ReLU的负区间不再恒等于0
理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。实际使用中,大部分仍然选用relu
TensorFlow API: tf.nn.leaky_relu
建议
- 首选ReLU激活函数;
- 学习率设置较小值;
- 输入特征标准化,即让输入特征满足以0为均值,1为标准差的正态分布;
- 初始化问题:初始参数中心化,即让随机生成的参数满足以0为均值,以
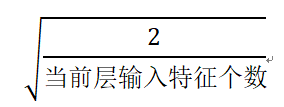
为标准差的正态分布。
4.损失函数
损失函数:预测值(y)与已知答案(y_)的差距。神经网络的优化目标,就是找到某套参数,使得计算出来的结果y与已知答案y_无限接近,也即它们的差距loss值最小
神经网络模型的效果及优化的目标是通过损失函数来定义的。回归和分类是监督学习中的两个大
类。主流的loss有三种计算方法,均方误差、交叉熵和自定义。下面用一个预测酸奶日销量的例子,来理解损失函数
均方误差损失函数
均方误差(Mean Square Error)是回归问题最常用的损失函数。回归问题解决的是对具体数值的预测,比如房价预测、销量预测等。这些问题需要预测的不是一个事先定义好的类别,而是一个任意实数。均方误差定义如下:
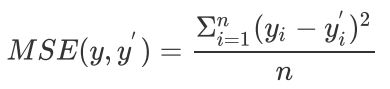
TensorFlow API: tf.keras.losses.MSE
预测酸奶日销量y, x1、 x2是影响日销量的因素。
建模前,应预先采集的数据有:每日x1、 x2和销量y_(即已知答案,知道了销量,就可以建议产量了,这里假定,最佳的情况:产量=销量)
拟造数据集X,Y_: y_ = x1 + x2 噪声: -0.05 ~ +0.05 拟合可以预测销量的函数
构建一个一层的神经网络,将这套构建的数据集喂入其中
import tensorflow as tf
import numpy as np
SEED = 23455
rdm = np.random.RandomState(seed=SEED) # 生成[0,1)之间的随机数
x = rdm.rand(32, 2) #此即x1和x2
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
b1 = tf.Variable(tf.random.normal([1], stddev=1, seed=1))
epoch = 30000
lr = 0.003
for epoch in range(epoch):
with tf.GradientTape() as tape: #用with结构计算前向传播结构y和loss
y = tf.matmul(x, w1) + b1
loss_mse = tf.reduce_mean(tf.square(y_ - y))
grads = tape.gradient(loss_mse, [w1,b1])
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
if epoch % 2000 == 0:
print("After %d training steps,w1 and b1 are " % (epoch))
print(w1.numpy())
print(b1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())
print("Final b1 is: ", b1.numpy())
Final w1 is: [[0.9900439]
[0.983632 ]]
Final b1 is: [0.01385183]
运行代码可以看到,随着迭代轮次的上升,w1的两个元素值不断趋近于1,而偏置项b1不断趋近于0,这符合我们制造数据集的公式y=x1+x2,说明神经网络拟合正确
交叉熵损失函数
交叉熵(Cross Entropy)表征两个概率分布之间的距离,交叉熵越小说明二者分布越接近,是分类问题中使用较广泛的损失函数
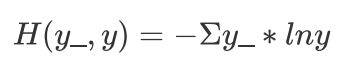
其中y_代表数据的真实值,y代表神经网络的预测值。对于多分类问题,神经网络的输出一般不是概率分布,因此需要引入softmax层,使得输出服从概率分布。TensorFlow中可计算交叉熵损失函数的API有
TensorFlow API: tf.keras.losses.categorical_crossentropy
loss_ce1 = tf.losses.categorical_crossentropy([1, 0], [0.6, 0.4])
loss_ce2 = tf.losses.categorical_crossentropy([1, 0], [0.8, 0.2])
print("loss_ce1:", loss_ce1)
print("loss_ce2:", loss_ce2)
loss_ce1: tf.Tensor(0.5108256, shape=(), dtype=float32)
loss_ce2: tf.Tensor(0.22314353, shape=(), dtype=float32)
TensorFlow API: tf.nn.softmax_cross_entropy_with_logits
解决分类问题,通常先用softmax函数,使输出结果符合概率分布,再求交叉熵损失函数,tensorflow给出了一个可以同时计算softmax和交叉熵的函数tf.nn.softmax_cross_entropy_with_logits
y_ = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 0, 0], [0, 1, 0]])
y = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pro = tf.nn.softmax(y)
loss_ce1 = tf.losses.categorical_crossentropy(y_,y_pro)
loss_ce2 = tf.nn.softmax_cross_entropy_with_logits(y_, y)
#即loss_ce2这一句可以替换y_pro和loss_ce1这两句,一次完成概率分布和交叉熵的计算
print('分步计算的结果:\n', loss_ce1)
print('结合计算的结果:\n', loss_ce2)
分步计算的结果:
tf.Tensor(
[1.68795487e-04 1.03475622e-03 6.58839038e-02 2.58349207e+00
5.49852354e-02], shape=(5,), dtype=float64)
结合计算的结果:
tf.Tensor(
[1.68795487e-04 1.03475622e-03 6.58839038e-02 2.58349207e+00
5.49852354e-02], shape=(5,), dtype=float64)
TensorFlow API: tf.nn.sparse_softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits(
labels, logits, axis=-1, name=None
) #在机器学习中,对于多分类问题,把未经softmax归一化的向量值称为logits
前面的标签y_已经符合了one-hot编码,若是标签y_还没有经过one-hot编码,则使用tf.nn.sparse_softmax_cross_entropy_with_logits函数,使labels经过one-hot编码,logits经过softmax,两者再进行交叉熵计算,sparse可理解为对labels进行稀疏化处理(即进行one-hot编码)。
labels = [0 , 1]
logits = [[4.0,2.0,1.0] , [0.0,5.0,1.0]]
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels , logits)
print(loss)
tf.Tensor([0.16984604 0.02474492], shape=(2,), dtype=float32)
自定义损失函数
根据具体任务和目的,可设计不同的损失函数,损失函数的定义能极大影响模型预测效果。好的损失函数设计对于模型训练能够起到良好的引导作用。
前面使用均方误差作为损失函数,默认认为,销量预测的多了或者少了,损失是一样的,然而真实情况是,预测多了,损失的是成本;预测少了,损失的是利润。若是利润 ≠ 成本,则mse产生的loss无法实现利益最大化。
这时候我们可以使用自定义的损失函数,计算每一个预测结果y与标准答案y_产生的损失累积和,而将具体的损失定义为一个分段函数:
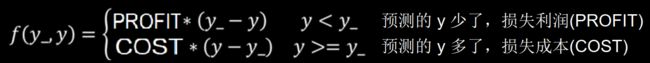
代码为:
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * COST, (y_ - y) * PROFIT))
预测酸奶销量,酸奶成本(COST) 1元,酸奶利润(PROFIT) 99元
预测少了损失利润99元,大于预测多了损失成本1元
显然预测少了损失大,希望生成的预测函数往多了预测。和上面的代码相比,这里干脆去掉偏置项b1,改了下epoch和lr
import tensorflow as tf
import numpy as np
# 自定义损失函数
# 酸奶成本1元, 酸奶利润99元
# 成本很低,利润很高,人们希望多预测些,生成模型系数大于1,往多了预测
SEED = 23455
COST = 1
PROFIT = 99
rdm = np.random.RandomState(SEED)
x = rdm.rand(32, 2)
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
epoch = 10000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * COST, (y_ - y) * PROFIT))
grads = tape.gradient(loss, w1)
w1.assign_sub(lr * grads)
if epoch % 500 == 0:
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())
Final w1 is: [[1.1626335]
[1.1191947]]
可以看到,预测的系数都大于1,系数都偏大,都大于用均方误差做损失函数时的系数,模型的确在尽量往多了预测,这是因为,成本cost远小于利润profit,而预测多了损失的是成本,预测少了损失的是利润,所以往多了预测的损失值会远小于往少了预测的损失值,所以模型会尽量往多了预测
将cost改为99,而profit改为1,再运行一遍代码
COST = 1
PROFIT = 99
Final w1 is: [[0.9205433]
[0.9186459]]
可以看到预测的两个参数均小于1,模型在尽量往小的预测,原因同上
5.欠拟合与过拟合
欠拟合,是模型不能有效拟合数据集, 是对现有数据集学习得不够彻底
过拟合,是模型对当前数据拟合得太好了,但对从未见过的新数据,却难以进行判断,模型缺乏泛化力
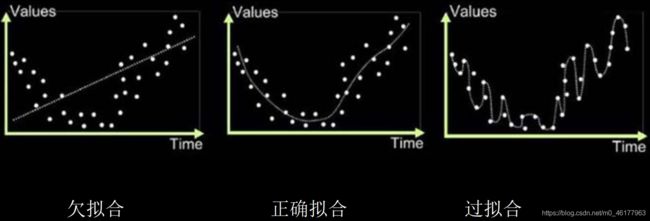
欠拟合的解决方法:
- 增加输入特征项:给网络更多维度的输入特征
- 增加网络参数:扩展网络规模,增加网络深度,提升模型的表达力
- 减少正则化参数
过拟合的解决方法:
- 数据清洗:减少数据集中的噪声,使数据集更纯净
- 增大训练集
- 采用正则化
- 增大正则化参数
6.正则化减少过拟合
概念
在缓解过拟合的方法中,正则化是一种通用的,有效的方法
正则会就是在损失函数中引入模型复杂度指标,利用给w加权值(一般不正则化b),弱化了训练数据的噪声
使用了正则化后,损失函数loss变成了两部分的和

第一部分即为以前求的loss,描述了预测结果与正确结果之间的差距
第二部分是参数的权重,用超参数REGULARIZER给出参数w在总loss中的比例,即正则化的权重
loss(w)的计算,可以使用两种方法,这两种方法又被称为L1正则化和L2正则化

L1正则化大概率会使很多参数变为0,因此该方法可通过稀疏参数来减少参数的数量,降低模型复杂度。
L2正则化会使参数很接近0但不为0,因此该方法可通过减少参数的大小降低复杂度,可有效缓解数据集中因噪声引起的过拟合
通过实例感受下正则化的作用
可视化
生成一个有两个特征x1x2和一个标签的数据集,让神经网络拟合输入特征x1和x2与标签的关系,模型训练好之后,有数据送入神经网络,神经网络通过前向传播输出预测值,自动判断是1的可能性大还是0的可能性大。将x1和x2分别作为横纵坐标将数据可视化出来,所有标签为1的点标为红色,为0的点标为蓝色,让神经网络画出一条线区分红色点和蓝色点。
画线方法:先让神经网络拟合出x1和x2与标签的函数关系,然后生成密密麻麻的网格覆盖这些点,将这些网格的交点的横纵坐标作为输入送入训练好的神经网络,神经网络会为每个坐标生成一个预测值,要区分输出是偏向1还是偏向0,可以将输出网络预测值为0.5线用不同颜色画出来,这条线也就是红点和蓝点的区分线了
准备数据:
# 读入数据/标签 生成x_train y_train
df = pd.read_csv("dot.csv")
x_data = np.array(df[["x1" , "x2"]]) #x_data = np.array(df.iloc[: , df.columns != "y_c"])这样也可以
y_data = np.array(df["y_c"])
x_train = np.vstack(x_data).reshape(-1,2)
y_train = np.vstack(y_data).reshape(-1,1)
Y_c = [["red" if y else "blue"] for y in y_train] #为后面画散点图scatter做准备
x_train = tf.cast(x_train , tf.float32)
y_train = tf.cast(y_train , tf.float32)
#生成数据集,使输入特征和标签值一一对应
train_db = tf.data.Dataset.from_tensor_slices((x_train , y_train)).batch(32)
搭建网络:
搭建二层神经网络,神经元的个数均设置为11个
# 生成神经网络的参数,输入层为2个神经元,隐藏层为11个神经元,1层隐藏层,输出层为1个神经元
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.random.normal([11]) , dtype=tf.float32)
w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.random.normal([1]) , dtype=tf.float32)
参数优化:(进行训练,更新参数)
# 训练部分
for epoch in range(epoch): #epoch是对数据集的循环计数
for step, (x_train, y_train) in enumerate(train_db): #step是对batch的循环计数
with tf.GradientTape() as tape: # 记录梯度信息
y = tf.matmul(x_train, w1) + b1
y = tf.nn.relu(y)
y = tf.matmul(y, w2) + b2
#注意,这里不需要转换独热码,因为是二分类,y_train已经是独热码的形式了,直接求mseloss即可
loss = tf.reduce_mean(tf.square(y_train - y))
# 计算loss对各个参数的梯度
grads = tape.gradient(loss, [w1 , b1 , w2 , b2])
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
# 每20个epoch,打印loss信息
if epoch % 20 == 0:
print('epoch:', epoch, 'loss:', float(loss))
测试效果:预测部分
先生成网格点,附上生成网格点每一步的输出结果
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成间隔数值点
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# print(xx)
# [[-3. -3. -3. ... -3. -3. -3. ]
# [-2.9 -2.9 -2.9 ... -2.9 -2.9 -2.9]
# [-2.8 -2.8 -2.8 ... -2.8 -2.8 -2.8]
# ...
# [ 2.7 2.7 2.7 ... 2.7 2.7 2.7]
# [ 2.8 2.8 2.8 ... 2.8 2.8 2.8]
# [ 2.9 2.9 2.9 ... 2.9 2.9 2.9]]
# print(yy)
# [[-3. -2.9 -2.8 ... 2.7 2.8 2.9]
# [-3. -2.9 -2.8 ... 2.7 2.8 2.9]
# [-3. -2.9 -2.8 ... 2.7 2.8 2.9]
# ...
# [-3. -2.9 -2.8 ... 2.7 2.8 2.9]
# [-3. -2.9 -2.8 ... 2.7 2.8 2.9]
# [-3. -2.9 -2.8 ... 2.7 2.8 2.9]]
# 将xx , yy拉直,并合并配对为二维张量,生成二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
# print(xx.ravel())
# [-3. -3. -3. ... 2.9 2.9 2.9]
# print(yy.ravel())
# [-3. -2.9 -2.8 ... 2.7 2.8 2.9]
# print(grid)
# [[-3. -3. ]
# [-3. -2.9]
# [-3. -2.8]
# ...
# [ 2.9 2.7]
# [ 2.9 2.8]
# [ 2.9 2.9]]
grid = tf.cast(grid, tf.float32)
# print(grid)
# tf.Tensor(
# [[-3. -3. ]
# [-3. -2.9]
# [-3. -2.8]
# ...
# [ 2.9 2.7]
# [ 2.9 2.8]
# [ 2.9 2.9]], shape=(3600, 2), dtype=float32)
将网格坐标点喂入神经网络,进行预测,probs为输出,记录每一个网格点的预测结果
probs = []
for x_test in grid :
y = tf.matmul([x_test] , w1) + b1
y = tf.nn.relu(y)
y = tf.matmul(y , w2) + b2
probs.append(y)
可视化:
# 取第0列给x1,取第1列给x2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
plt.scatter(x1, x2, color=np.squeeze(Y_c)) #squeeze去掉维度是1的维度,相当于去掉[['red'],[''blue]],内层括号变为['red','blue']
# probs的shape调整成xx的样子
probs = np.array(probs).reshape(xx.shape)
# 把坐标xx yy和对应的值probs放入contour<[‘kɑntʊr]>函数,给probs值为0.5的所有点上色 plt点show后 显示的是红蓝点的分界线
plt.contour(xx, yy, probs, levels=[0.5])
plt.show()

可明显的观察到,轮廓不够平滑,存在过拟合现象
加上L2正则化后:
#在上面的代码的基础上,仅改动了损失函数部分,加上了l2正则化
loss_mse = tf.reduce_mean(tf.square(y_train - y))
#添加l2正则化
loss_regularization = []
loss_regularization.append(tf.nn.l2_loss(w1))
loss_regularization.append(tf.nn.l2_loss(w2))
#求和
loss_regularization = tf.reduce_sum(loss_regularization)
loss = loss_mse + 0.03 * loss_regularization #这里超参数REGULARIZER取0.03
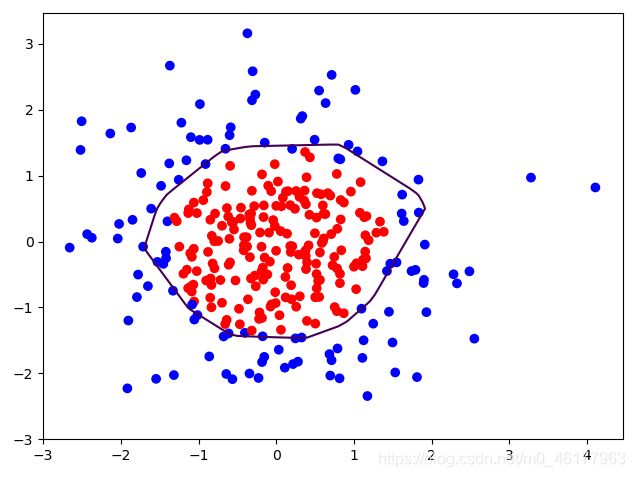
从图片可以看出,加入了l2后的曲线更平缓,有效缓解了过拟合现象
7.优化器更新网络参数
神经网络是基于连接的人工智能,当网络结构固定后,不同参数选取对模型的表达力影响很大,更新模型参数的过程,仿佛是在教一个孩子理解世界,达到学龄的孩子,脑神经元的结构、规模是相似的,他们都具备了学习的潜力,但是不同的引导方法,会让孩子具备不同的能力,达到不同的高度,优化器就是引导神经网络更新参数的工具
优化算法可以分成一阶优化和二阶优化算法,其中一阶优化就是指的梯度算法及其变种,而二阶优化一般是用二阶导数(Hessian 矩阵)来计算,如牛顿法。由于需要计算Hessian阵和其逆矩阵,计算量较大,因此没有流行开来。这里主要总结一阶优化的各种梯度下降方法
深度学习优化算法经历了SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam这样的发展历程
定义:
待优化参数w,损失函数loss,学习率lr,每次迭代一个batch,为了提高效率,数据集中的数据并不是一次仅喂入一组,而是以batch为单位,批量喂入神经网络,每个batch通常包含2的n次方组数据,t表示当前batch迭代的总次数:

步骤3,4对于各算法都是一致的,主要差别体现在步骤1和2上。
一阶动量:与梯度相关的函数
二阶动量:与梯度平方相关的函数
不同的优化器,实质上只是定义了不同的一阶动量和二阶动量公式
SGD
vanilla SGD
朴素 SGD (Stochastic Gradient Descent) 最为简单,没有动量的概念,即
一阶动量定义为梯度,二阶动量恒等于1
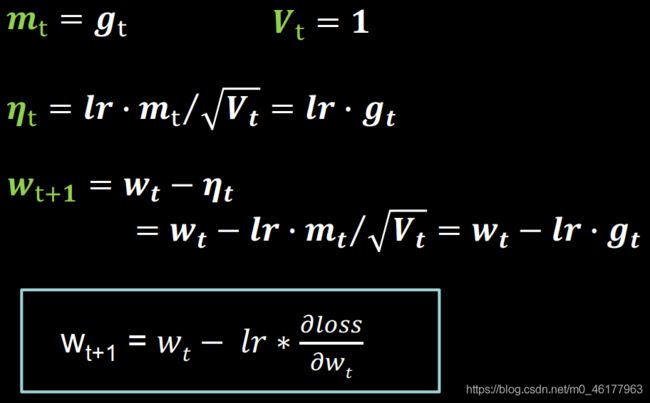
前面用的更新参数的方法,都是用的vanilla SGD
#vanilla SGD
w1.assign_sub(learning_rate * grads[0])
b1.assign_sub(learning_rate * grads[1])
SGD 的缺点在于收敛速度慢,很可能在鞍点处震荡。并且,如何合理的选择学习率是SGD的一大难点
鞍点:
下图中平面的高度为损失函数。在图中似乎各处都分布着局部最优。我们可能会想,梯度下降法或者某个算法可能困在一个局部最优中,而不会抵达全局最优。但是这些理解并不正确,这些低维的图影响了我们的理解,事实上,如果我们要创建一个神经网络,通常梯度为零的点并不是这个图中的局部最优点,实际上成本函数的零梯度点,通常是鞍点,即图中标出来的点。
鞍点是某一个维度有着向上梯度,而另一个维度却是向下的梯度
a point where one dimension has a positive slope, while the other dimension has a negative slope
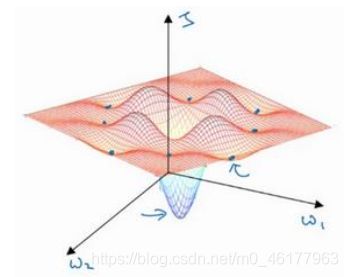
一个具有高维度空间的函数,如果梯度为 0,那么在每个方向,它可能是凸函数,也可能是凹函数。如果在 2 万维空间中,那么想要得到局部最优,则要求这个局部最优点的所有的方向都向上弯曲,这样发生的机率极小,因此在高维度空间,你更可能碰到鞍点,就是下面这种
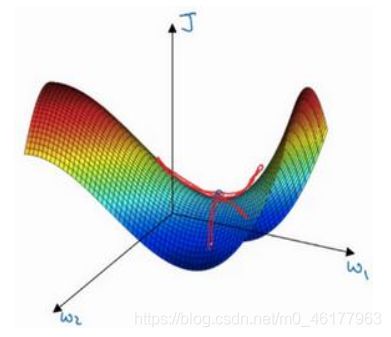
而对于鞍点来说,我们可以观察到,SGD,Momentum和NAG都容易陷入震荡,而剩下的三个优化器能较好的”逃离“鞍点,朝着梯度下降的方向走

SGD with Momentum (SGDM)
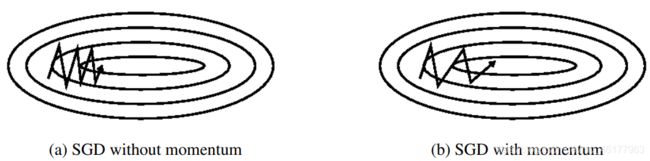
图a这种上下波动减慢了梯度下降法的速度,无法使用更大的学习率,如果你要用较大的学习率,结果可能会偏离函数的范围,为了避免摆动过大,得用一个较小的学习率
在纵轴上,我们希望学习慢一点,因为不想要这些摆动,但是在横轴上,希望加快学习,希望快速从左向右移,移向最小值,所以我们需要使用动量法。动量法是一种使梯度向量向相关方向加速变化,抑制震荡,最终实现加速收敛的方法。
SGD 在遇到沟壑时容易陷入震荡。为此,可以为其引入动量 Momentum,加速 SGD 在正确方向的下降并抑制震荡。即SGDM认为梯度下降过程可以加入惯性,下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。
SGDM就是在SGD的基础上增加了一阶动量mt,mt这个公式表示各时刻梯度方向的指数滑动平均值,与SGD相比,一阶动量的公式多了mt-1这一项,mt-1表示上一时刻的一阶动量,且上一时刻的一阶动量在这个公式里占大头,因为β是个超参数,是个接近1的数值,通常取0.9左右,这就意味着下降方向主要偏向此前累积的下降方向,并略微偏向当前时刻的下降方向,即使得参数中那些梯度方向变化不大的维度可以加速更新,并减少梯度方向变化较大的维度上的更新幅度。由此产生了加速收敛和减小震荡的效果。二阶动量在SGDM中仍恒等于1
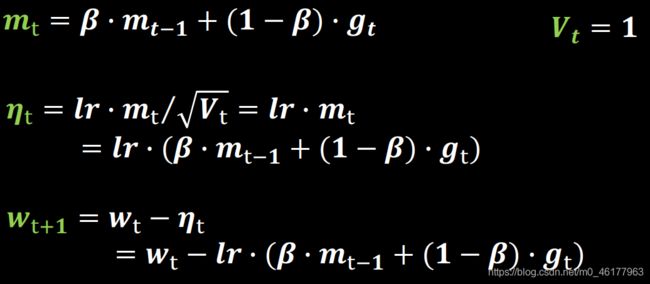
# sgd-momentun
beta = 0.9
m_w = beta * m_w + (1 - beta) * grads[0]
m_b = beta * m_b + (1 - beta) * grads[1]
w1.assign_sub(learning_rate * m_w)
b1.assign_sub(learning_rate * m_b)
SGD with Nesterov Acceleration(NAG)
NAG全称Nesterov Accelerated Gradient,是在SGD、SGDM的基础上的进一步改进,改进点在于步骤1(计算t时刻损失函数关于当前参数的梯度)。
我们知道在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再决定怎么走。因此,NAG在步骤1不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,考虑这个新地方的梯度方向。此时的梯度就变成了:
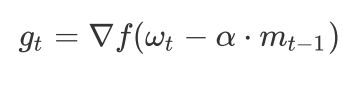
我们用这个梯度带入 SGDM 中计算mt的式子里去,然后再计算当前时刻应有的梯度并更新这一次的参数。其基本思路如下图:

首先,按照原来的更新方向更新一步(棕色线),然后计算该新位置的梯度方向(红色线),然后用这个梯度方向修正最终的更新方向(绿色线)。上图中描述了两步的更新示意图,其中蓝色线是标准
momentum更新路径。
AdaGrad
TensorFlow API: tf.keras.optimizers.Adagrad
上述SGD算法一直存在一个超参数(Hyper-parameter),即学习率。超参数是训练前需要手动选择的参数,学习率可以理解为参数w沿着梯度g反方向变化的步长。
SGD、SGDM 和 NAG 均是以相同的学习率去更新各个分量,即对所有的参数使用统一的、固定的学习率,一个自然的想法是对每个参数设置不同的学习率,这是因为不同参数的更新频率往往有所区别。对于更新不频繁的参数(典型例子:更新 word embedding 中的低频词),我们希望单次步长更大,多学习一些知识;对于更新频繁的参数,我们则希望步长较小,使得学习到的参数更稳定,不至于被单个样本影响太多。
然而在大型网络中这是不切实际的。因此,为解决此问题,AdaGrad算法被提出,其做法是给学习率一个缩放比例,从而达到了自适应学习率的效果(Ada = Adaptive)。其思想是:对于频繁更新的参数,不希望被单个样本影响太大,我们给它们很小的学习率;对于偶尔出现的参数,希望能多得到一些信息,我们给它较大的学习率
那怎么样度量历史更新频率呢?为此引入二阶动量,即AdaGrad是在SGD的基础上引入二阶动量(注意,前面的SGD,SGDM和NAG,其二阶动量均为1),这样我们就可以对模型中的每个参数分配自适应学习率了

AdaGrad 在稀疏数据场景下表现最好。因为对于频繁出现的参数,其二阶动量的对应分量较大,学习率衰减得快;对于稀疏的参数,学习率衰减得更慢。然而在实际很多情况下,二阶动量呈单调递增,累计从训练开始的梯度,学习率会很快减至 0 ,导致参数不再更新,训练过程提前结束
# adagrad
v_w += tf.square(grads[0])
v_b += tf.square(grads[1])
w1.assign_sub(learning_rate * grads[0] / tf.sqrt(v_w))
b1.assign_sub(learning_rate * grads[1] / tf.sqrt(v_b))
RMSProp
TensorFlow API: tf.keras.optimizers.RMSprop
RMSProp算法的全称叫 Root Mean Square Prop,由于 AdaGrad 的学习率衰减太过激进,二阶动量单调递增,使得学习率逐渐递减至 0,可能导致训练过程提前结束。考虑改变二阶动量的计算策略:不累计全部梯度,只关注过去某一窗口内的梯度。修改的思路很直接,指数滑动平均值大约是过去一段时间的平均值,反映“局部的”参数信息,因此我们用这个方法来计算二阶累积动量。超参数β与SGDM中的参数类似,通常取0.9左右
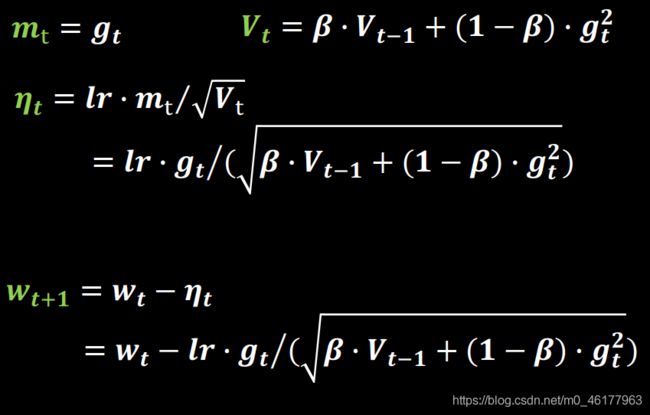
# RMSProp
beta = 0.9
v_w = beta * v_w + (1 - beta) * tf.square(grads[0])
v_b = beta * v_b + (1 - beta) * tf.square(grads[1])
w1.assign_sub(learning_rate * grads[0] / tf.sqrt(v_w))
b1.assign_sub(learning_rate * grads[1] / tf.sqrt(v_b))
AdaDelta
TensorFlow API: tf.keras.optimizers.Adadelta
为解决AdaGrad的学习率递减太快的问题,RMSProp和AdaDelta几乎同时独立被提出。而AdaDelta与RMSprop仅仅是分子项不同
RMSProp:
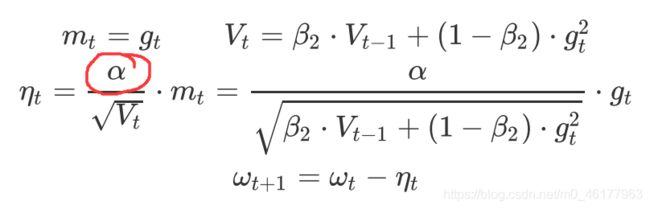
AdaDelta:
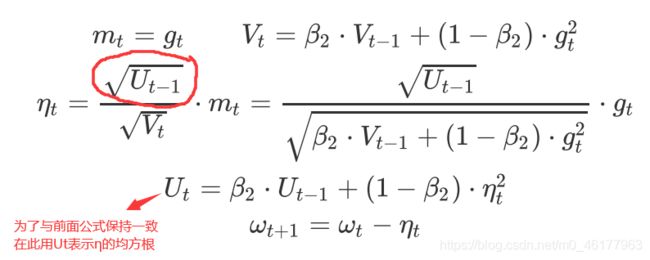
# AdaDelta
beta = 0.999
v_w = beta * v_w + (1 - beta) * tf.square(grads[0
v_b = beta * v_b + (1 - beta) * tf.square(grads[1
delta_w = tf.sqrt(u_w) * grads[0] / tf.sqrt(v_w)
delta_b = tf.sqrt(u_b) * grads[1] / tf.sqrt(v_b)
u_w = beta * u_w + (1 - beta) * tf.square(delta_w
u_b = beta * u_b + (1 - beta) * tf.square(delta_b
w1.assign_sub(delta_w)
b1.assign_sub(delta_b)
Adam
TensorFlow API: tf.keras.optimizers.Adam
Adam,同时引入了SGDM的一阶动量和RMSProp的二阶动量,并在此基础上增加了两个修正项,把修正后的一阶动量和二阶动量,也就是说,Adam融合了Adagrad和RMSprop的思想。其实说到这里,Adam的出现就很自然而然了——它们是前述方法的集大成者。我们看到,SGDM在SGD基础上增加了一阶动量,AdaGrad、RMSProp和AdaDelta在SGD基础上增加了二阶动量。把一阶动量和二阶动量结合起来,再修正偏差,就是Adam了
SGDM的一阶动量:
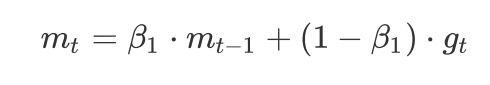
加上RMSProp的二阶动量:
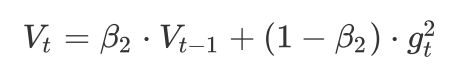
其中,参数经验值是β1=0.9,β2=0.999
一阶动量和二阶动量都是按照指数移动平均值进行计算的。初始化m0 = 0,V0 = 0,在初期,迭代得到的mt,Vt会接近于0。我们可以通过对mt,Vt进行偏差修正来解决这一问题:

再进行更新:

# adam
m_w = beta1 * m_w + (1 - beta1) * grads[0]
m_b = beta1 * m_b + (1 - beta1) * grads[1]
v_w = beta2 * v_w + (1 - beta2) * tf.square(grads[0])
v_b = beta2 * v_b + (1 - beta2) * tf.square(grads[1])
m_w_correction = m_w / (1 - tf.pow(beta1, int(global_step)))
m_b_correction = m_b / (1 - tf.pow(beta1, int(global_step)))
v_w_correction = v_w / (1 - tf.pow(beta2, int(global_step)))
v_b_correction = v_b / (1 - tf.pow(beta2, int(global_step)))
w1.assign_sub(learning_rate * m_w_correction / tf.sqrt(v_w_correction))
b1.assign_sub(learning_rate * m_b_correction / tf.sqrt(v_b_correction))
优化器算法可视化
两张动图直观的展现了不同算法的性能
An overview of gradient descent optimization algorithms
Visualizing Optimization Algos
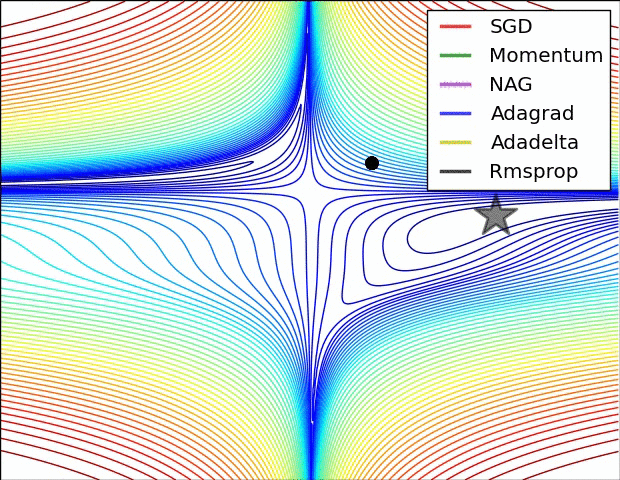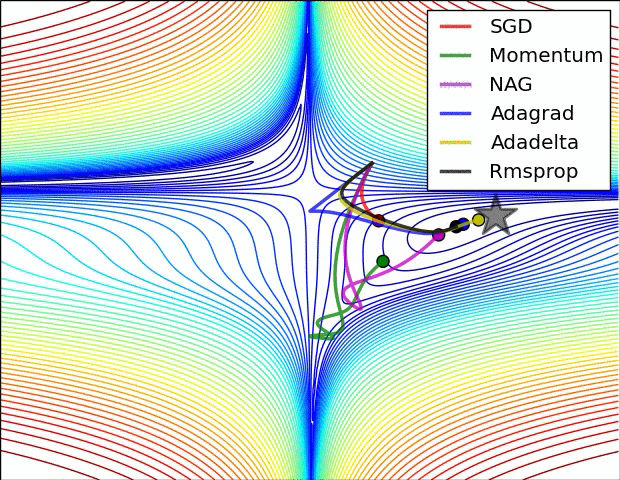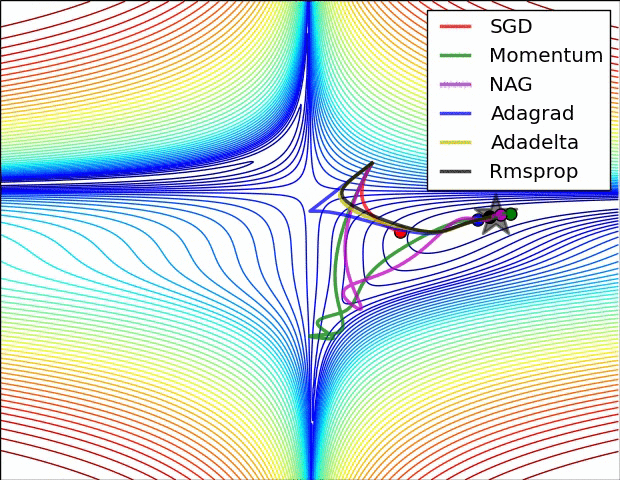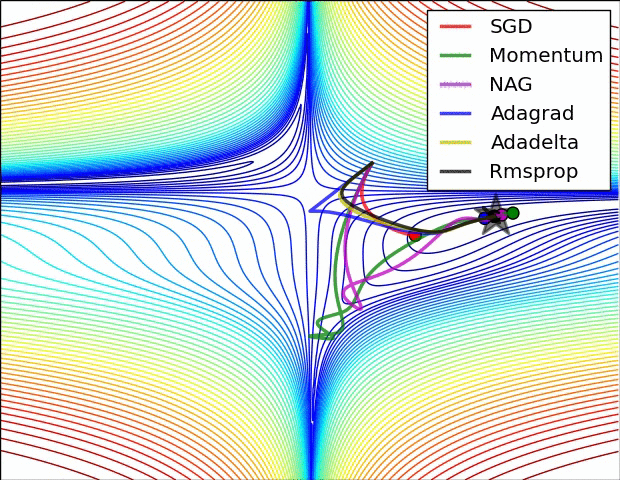
我们可以看到不同算法在损失面等高线图中的学习过程,它们均同同一点出发,但沿着不同路径达到最小值点。其中 Adagrad、Adadelta、RMSprop 从最开始就找到了正确的方向并快速收敛;SGD 找到了正确方向但收敛速度很慢;SGDM 和 NAG 最初都偏离了航道,但也能最终纠正到正确方向,SGDM 偏离的惯性比 NAG 更大

前面讲解鞍点的时候展示了此图,这里再展现一次。此图展现了不同算法在鞍点处的表现。这里,SGD、SGDM、NAG 都受到了鞍点的严重影响,尽管后两者最终还是逃离了鞍点,但是Adagrad、RMSprop、Adadelta都很快找到了正确的方向。
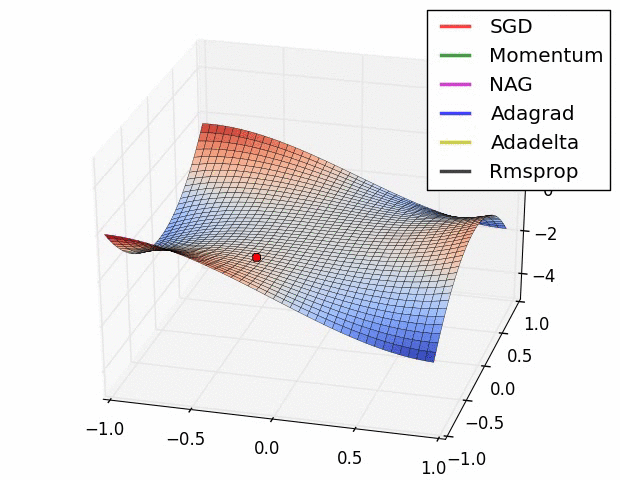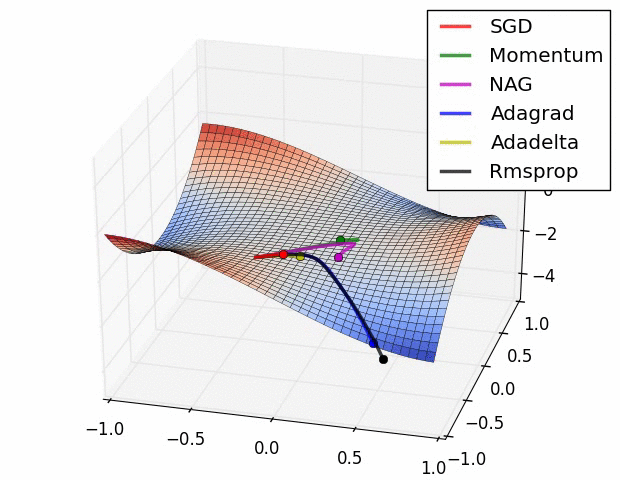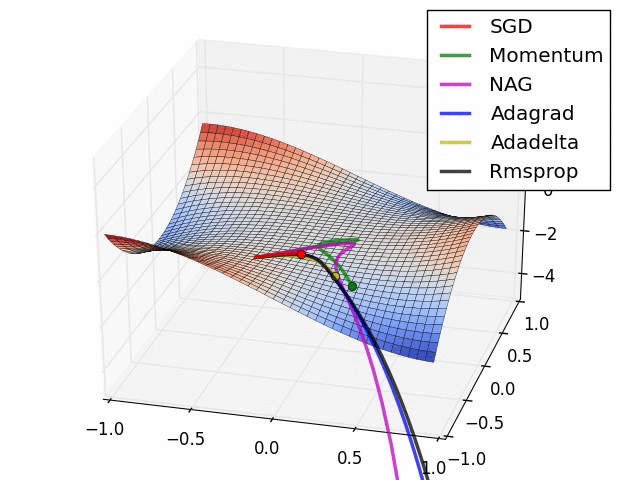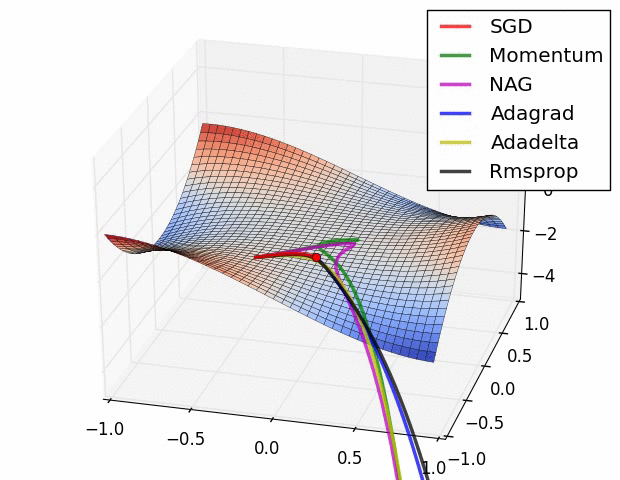
此图同样是鞍点附近各算法的表现
Behavior around a saddle point.
NAG/Momentum again like to explore around, almost taking a different path.
Adadelta/Adagrad/RMSProp proceed like accelerated SGD.
优化器选择
很难说某一个优化器在所有情况下都表现很好,我们需要根据具体任务选取优化器。一些优化器在计算机视觉任务表现很好,另一些在涉及RNN网络时表现很好,甚至在稀疏数据情况下表现更出色。
总结上述,基于原始SGD增加动量和Nesterov动量,RMSProp是针对AdaGrad学习率衰减过快的改进,它与AdaDelta非常相似,不同的一点在于AdaDelta采用参数更新的均方根(RMS)作为分子。Adam在RMSProp的基础上增加动量和偏差修正。如果数据是稀疏的,建议用自适用方法,即Adagrad, RMSprop, Adadelta, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。随着梯度变的稀疏,Adam 比 RMSprop 效果会好。总的来说,Adam整体上是最好的选择
然而很多论文仅使用不带动量的vanilla SGD和简单的学习率衰减策略。SGD通常能够达到最小点,但是相对于其他优化器可能要采用更长的时间。采取合适的初始化方法和学习率策略,SGD更加可靠,但也有可能陷于鞍点和极小值点。因此,当在训练大型的、复杂的深度神经网络时,我们想要快速收敛,应采用自适应学习率策略的优化器。
如果是刚入门,优先考虑Adam或者SGD+Nesterov Momentum。
算法没有好坏,最适合数据的才是最好的
优化算法的常用tricks
- 首先,各大算法孰优孰劣并无定论。刚入门,优先考虑SGD+Nesterov Momentum或者Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam)
- 选择熟悉的算法——这样可以更加熟练地利用你的经验进行调参。
- 充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
- 根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
- 先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
- 考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。
- 充分打乱数据集(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。在每一轮迭代后对训练数据打乱是一个不错的主意。
- 训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
- 制定一个合适的学习率衰减策略。可以使用分段常数衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
- Early stopping。如Geoff Hinton所说:“Early Stopping是美好的免费午餐”。你因此必须在训练的过程中时常在验证集上监测误差,在验证集上如果损失函数不再显著地降低,那么应该提前结束训练。
- 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值
主要参考:慕课北大Tensorflow2.0课程及其笔记