不同分辨率图片匹配_超实用的图像超分辨率重建方法及应用介绍
在之前的文章中已经讲述过很多的传统超分辨率算法。而在AI领域中这几年也是很大热门。CVPR2017超分辨有7篇论文,2018 ICCV共有9篇 ,在CVPR2018中,共收录979篇,而超分辨率论文有14篇,占比1.43%,CVPR2019共收录1300篇文章, 超分辨率领域的文章一共有18篇(有两篇是讲Zoom和视频的),占比1.38%。
CVPR2019的相关论文中从一作的名字来看,18篇中只有2篇不是华人一作。可见,在这一领域,华人有着绝对优势,这一点在国内的宣传上也能体现出来,华为,小米,还有旷视,商汤等算法公司都在大力宣传自己的AI超分辨率算法。
很多超分辨率的技术已经在日常应用中出现。比如:
(1) 手机图片浏览展示:例如微信压缩后的图片进行超分辨率恢复。有时候你会发现同一张图片在不同手机上的效果不一样,这里面超分辨率的算法尽了一份力。
(2)视频观看及在线视频点播:在线视频点播中希望传输过程中能尽量减少数据流量,但是又希望能够在用户观看视频的时候能够提高分辨率。另外一些用户上传的视频质量并不高需要上传后进行分辨率的提升。因此上传后解码后进行超分率的提升很有必要。
(3)拍照:用户对于拍照功能下面分辨率需求是永远没有止境的。

学术研究的热点有时和实际使用中有些不同,通常的超分辨率分两种:SISR和VSR。前者叫做单图像超分辨率,后者叫做视频超分辨率。通常理解的超分辨率都是指SISR,只需要输入一张低分辨率图像而获得高分辨率图像的输出,这也是学术的研究热点。单帧一直是个理想的目标,但是现实使用中往往多张图片生成的超分辨率图片效果更好,效率也更高,因此实际产品有条件使用多帧的时候也会尽量使用。
根据已有的论文,大致整理了一下目前针对AI超分辨率的研究方向。分别从超分辨中常见的研究方向和方法进行讨论,主要集中在上采样,损失函数,深度网络结构设计,超分辨率的评价方法,训练图片和格式,无监督学习下的超分辨率和特殊领域下的应用
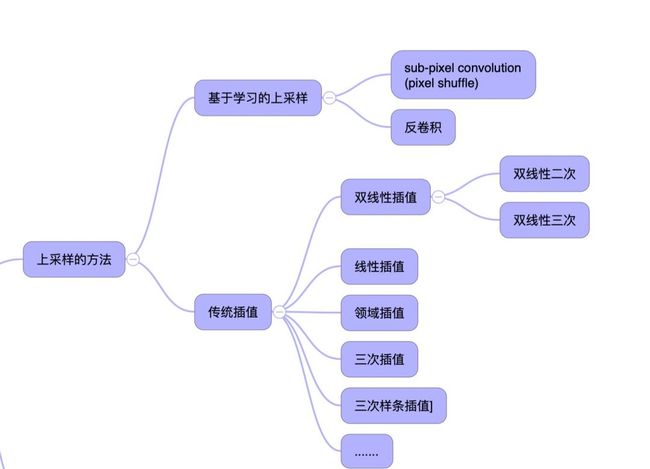
-上采样(升采样)
超分辨是不是一定要上采样呢?其实分辨率一定要像素提升。但是如果大幅度的提升分辨率提升像素是必须的。上采样并非超分辨独创技术,简单的来说就是提高图片的像素数,很早之前插值算法就是一种升采样技术。2000到2010年前后由于相机像素较低,很多手机相机和数码,都会在产品说明上添加上一句类似“可以插值到XX百万像素”的语句,数码相机用到的插值就是一种升采样技术。比如最简单的一种插值算法,当图片放大时,缺少的像素通过直接使用与之最接近的原有像素的颜色生成。在图像处理软件中如升采样的算法也特别好多。传统的插值算法如领域,线性,双线性二次,双线性三次等等就不过多的介绍了。
如果研究过自编码器等算法的同学会知道反卷积是图像深度学习中常用的上采样方法,在yolo v3中用到的上采样方法也是反卷积。事实上,反卷积这种上采样方法在目前一线的SR算法中已经逐渐减少。有一种叫做pixel shuffle的新型卷积方法在CVPR2016年被提出来,也叫做sub-pixel convolution。这种新型卷积就是为SR量身定做的,如果想要详细了解这种卷积是如何操作的,请搜索下《pixel shuffle》。这也解释了为什么目前基于CNN的SR有些能比基于GAN效果更好了;
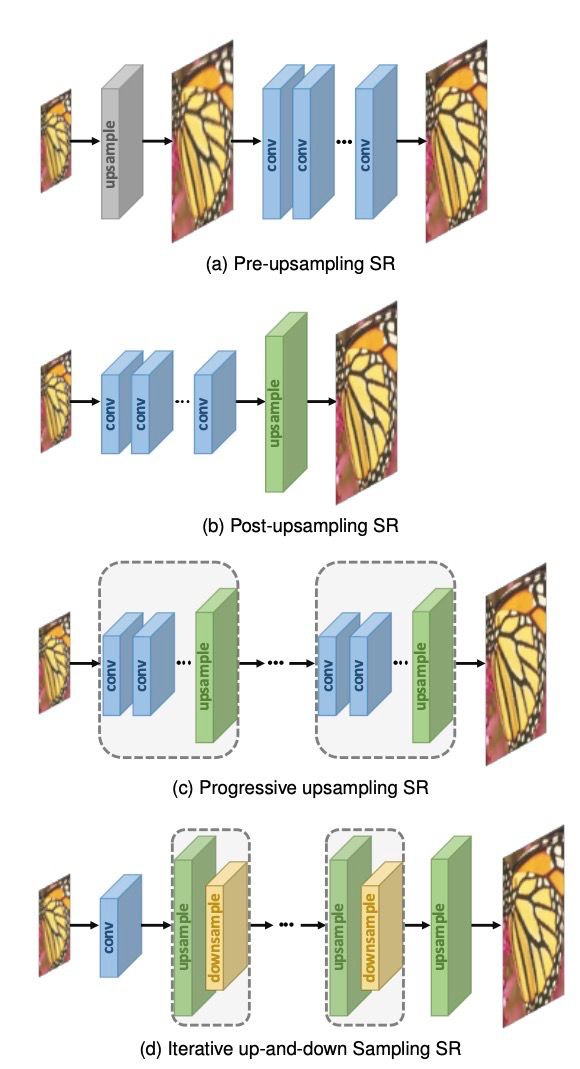
除了上采样的类型,什么时候进行上采样也很重要,而且这对网络结构的影响很大。
根据上采样(upsampling)在网络结构中的位置和使用方式,可以把超分网络结构设计分为四大类:
1前上采样(pre-upsampling),
2 后上采样(post-upsampling),
3 逐步式上采样(progressive upsampling),
4 升降采样迭代式(iterativeup-and-down sampling)。
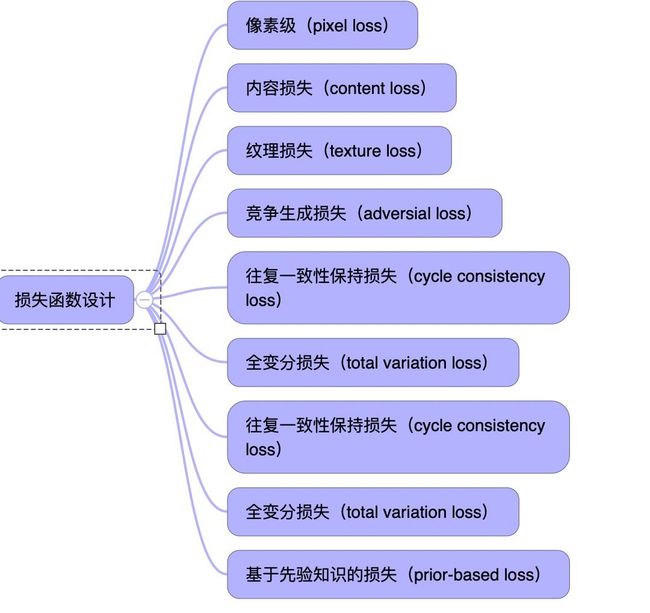
-超分辨损失函数
和其它图像领域的损失函数是比较类似的。从像素到内容到纹理,这些差别并不大。损失函数的计算使用MSE,PSNR,SSIM这些方式。但是这里面有些问题我们会在后面的评价方法中介绍,就是现在方法是比较图像的不同,而不是分辨率上客观的多少。这是一个大的问题。
-网络结构和学习方法
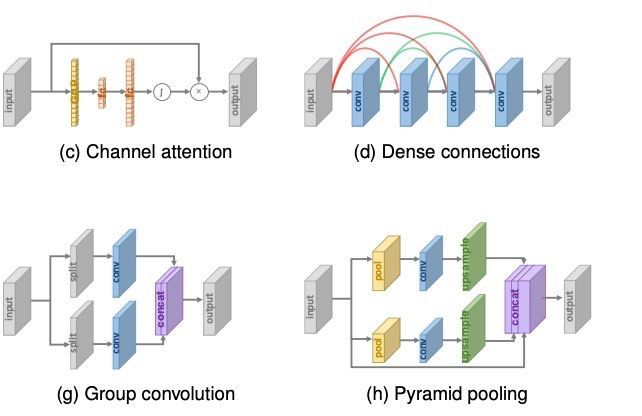
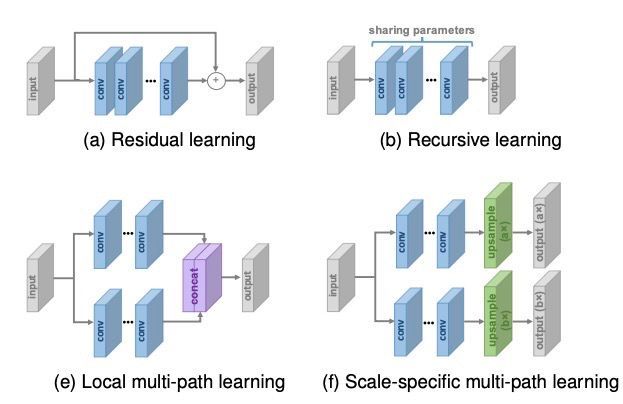
超分辨率全局和局部网络结构设计基本上也是目前已有的在图形图像处理中使用的网络在超分辨的研究中基本上都有使用了。从残差学习到卷积神经网络到生成对抗网络,基于稀疏编码网络都在超分辨领域中使用。下面大致将目前已有在超分辨率的网络列出来,文章有限就不详细介绍了。相信新的网络会出现,基于这些网络的超分辨率方法相信也会跟进的。后面有机会找几个典型的论文我们再写几篇。
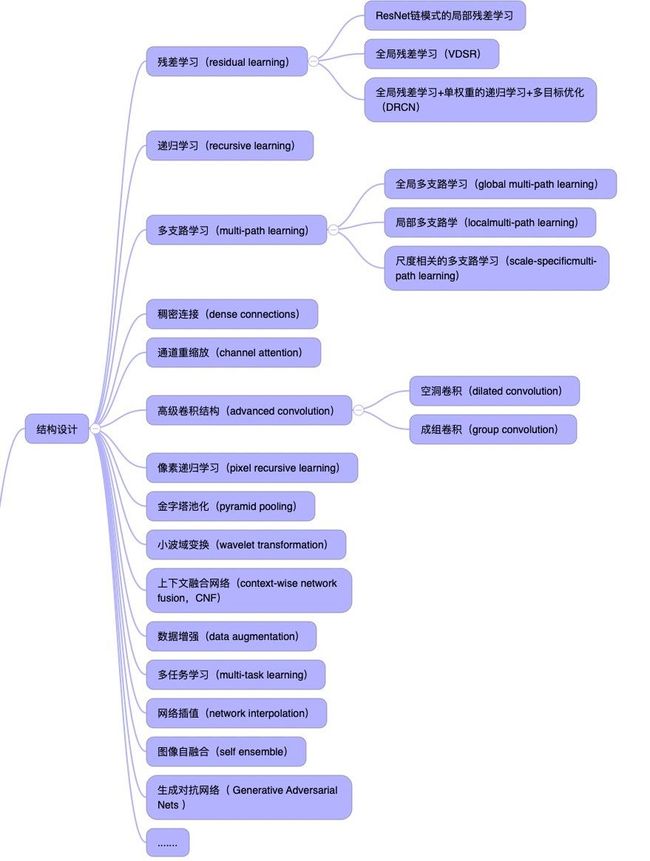
下面从过往的论文中找到一些常见网络结构的示意图。
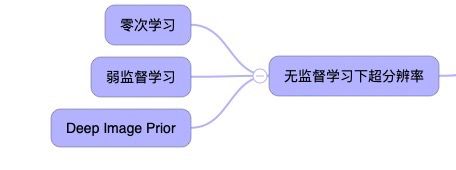
无监督学习一直以来是AI的很重要的一部分,在超分辨领域中也是一样。监督学习的图像超分辨率,基本上是学习了人为设计的图像降质过程的逆过程,需要LR-HR的图像对(image pairs),与实际场景中的图像超分问题不太符合。实际中的超分问题,只有不成对(unpaired)的低分辨率和高分辨图像可以用来进行训练。无监督的图像超分辨率也受到越来越多关注。
-零次学习的图像超分
单个图像内部的统计数据足以提供超分辨率所需的信息,所以零击超分辨率(ZSSR)在测试时训练小图像特定的SR网络进行无监督SR,而不是在大数据集上训练通用模型。具体来说,核估计方法直接从单个测试图像估计退化内核,并在测试图像上执行不同尺度因子的退化来构建小数据集。然后在该数据集上训练超分辨率的小CNN模型用于最终预测。
-弱监督学习的图像超分
为了在超分辨率中不引入预退化,弱监督学习的SR模型,即使用不成对的LR-HR图像,是一种方案。一些方法学习HR-LR退化模型并用于构建训练SR模型的数据集,而另外一些方法设计周期循环(cycle-in-cycle)网络同时学习LR-HR和HR-LR映射。
由于预退化是次优的,从未配对的LR-HR数据集中学习退化是可行的。一种方法称为“两步法”:
1)训练HR-LR 的GAN模型,用不成对的LR-HR图像学习退化;
2)基于第一个GAN模型,使用成对的LR-HR图像训练LR- HR 的GAN模型执行SR。
对于HR到LR 的GAN模型,HR图像被馈送到生成器产生LR输出,不仅需要匹配HR图像缩小(平均池化)获得的LR图像,而且还要匹配真实LR图像的分布。训练之后,生成器作为退化模型生成LR-HR图像对。
对于LR到HR 的GAN模型,生成器(即SR模型)将生成的LR图像作为输入并预测HR输出,不仅需要匹配相应的HR图像而且还匹配HR图像的分布 。
在“两步法”中,无监督模型有效地提高了超分辨率真实世界LR图像的质量,比以前方法性能获得了很大改进。
无监督SR的另一种方法是将LR空间和HR空间视为两个域,并使用周期循环结构学习彼此之间的映射。这种情况下,训练目的包括推送映射结果去匹配目标的域分布,并通过来回(round trip)映射使图像恢复。
-深度图像先验
CNN结构在逆问题之前捕获大量的低级图像统计量,所以在执行SR之前可使用随机初始化的CNN作为手工先验知识。具体地讲,定义生成器网络,将随机向量z作为输入并尝试生成目标HR图像I。训练目标是网络找到一个Iˆ y,其下采样Iˆy与LR图像Ix相同。因为网络随机初始化,从未在数据集上进行过训练,所以唯一的先验知识是CNN结构本身。
虽然这种方法的性能仍然比监督方法差很多,但远远超过传统的bicubic上采样。此外,表现出的CNN架构本身合理性,促使将深度学习方法与CNN结构或自相似性等先验知识相结合来提高超分辨率。
-数据集和格式
开放的数据集就不用讨论了,改天单独收集下总结给大家。以自制数据集的难度,来说超分辨的数据集是最容易的了。在生成过程中无须标注,只需准备一些高清图像和视频,然后通过下采样或者模糊手段把高清变成低清图像,这样就获得了一一对应的训练集。就可以用以训练了。当然,对训练数据不同的下采样方法也会影响最后的算法最后的应用性能。
而从数据格式来看,超分辨率领域的训练数据中YUV(Ycbcr)要多于RGB, RAW数据也占据了很大一部分。这个和可能和实际的数据源有很大量的图片和视频解码之后都是Ycbcr的格式。而现在主流的成像sensor输出RAW格式的很多,相对来说信息量更多更容易出效果。

-超分辨评价方法
和其它图像评价方法一样,超分的评价也是分主观和客观。
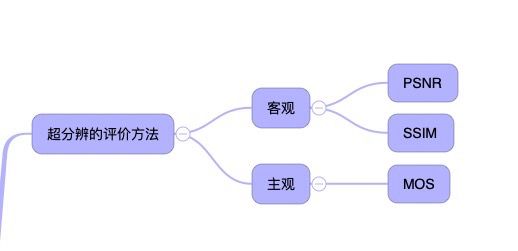
个人觉得目前超分辨的评价方面反而是发展最少的,所有的评价方法都还是传统的图片评价方式。并且客观评价PSNR,SSIM上只是反应了两张图片的区别。但是并不能客观的反应超分辨是否真的带来了益处。而这方面的论文基本没有,而客观评价的方法的提升其实是可以反过来影响损失函数的设计进而提升超分的效果。
主管评价中目前使用平均意见分方法(MOS,Mean Opinion Score)比较多。
下面是两种客观参数的计算方法:
PSNR(Peak Signal to Noise Ratio,峰值信噪比)
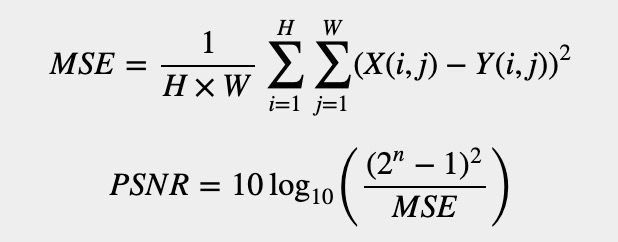
其中,MSE表示当前图像X和参考图像Y的均方误差(Mean Square Error),H、W分别为图像的高度和宽度;n为每像素的比特数,一般取8,即像素灰阶数为256. PSNR的单位是dB,数值越大表示失真越小。
虽然PSNR和人眼的视觉特性并不完全一致,但是一般认为PSNR在38以上的时候,人眼就无法区分两幅图片了。
SSIM(structural similarity, 结构相似性)
也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。
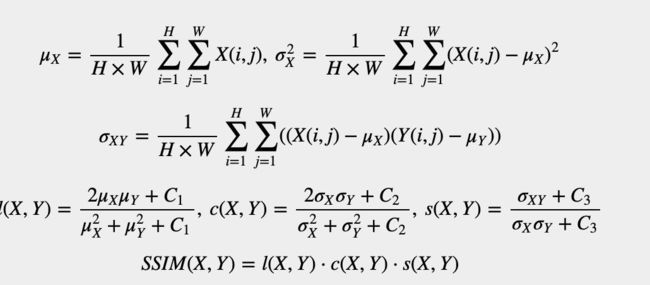
-特定领域的超分辨率应用
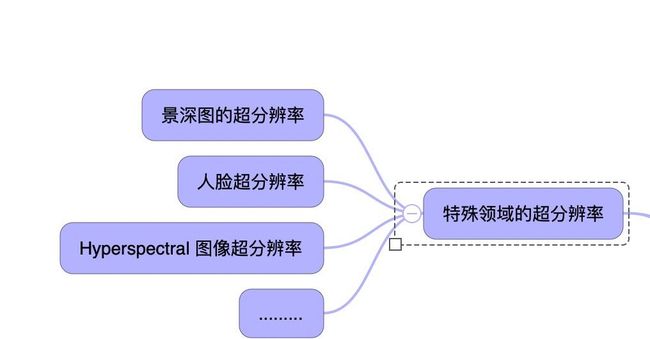
很多的特定的领域对于超分辨有特殊的需求,在对应的问题上的由于使用场景的特殊性往往也会有特殊的处理方法。当然拍月亮这样的场景有点太窄了,不应该算是一个特定的领域。
面部图像超分辨率,也叫面部幻觉(FH, face hallucination),通常可以帮助其他与面部相关的任务。与通用图像相比,面部图像具有更多与面部相关预先的结构化信息,因此将这部分先验知识(例如,关键点,结构解析图和身份)结合到针对人脸的超分辨算法中是很好的方法方法。而在很多面部识别中,人脸的大小和解析力是十分重要的,小面积的脸部解析力提高很重要。
另外拍照场景人物的拍照往往与全色图像(PAN,panchromatic images)即具有3个波段的RGB图像相比,有数百个波段的高光谱图像(HSI,hyperspectral images)提供了丰富的光谱特征并有助于各种视觉任务。然而,由于硬件限制,收集高质量的高光谱图像更困难,高光谱图像往往分辨率要低得多。因此,超分辨率被引入该领域意义也就别的更大了。
景深图的在场景和物体识别的使用,也越来越多。但是高分辨率的3D景深图像获取是更难的。并且现有常用的3D景深图硬件在获取的时候,容易有部分盲区,部分超分辨的方法更容易解决这类的问题。

相信随着平台计算力的提升,超分辨后面的使用的应该会越来广泛。目前看像是RAW域的超分辨率的图像拍摄,人像超分辨率,视频尤其是网络视频点播的超分辨率应用已经开始广泛的使用起来。而各个针对超分辨的方面的研究在最近几年应该还会进一步的发展,本文并没有针对某种AI的超分辨率算法进行描述,后面如果有时间会从CVPR2019及后面的论文中挑选一两篇来详细的介绍。
另外本文参考了
Deep Learning for Image Super-resolution: A Survey
https://arxiv.org/abs/1902.06068
以及网上个别大神们的一些翻译和见解,如引起任何不快请尽快和我联系。
你的每一个“在看”,我都当成了喜欢▼