NN 神经网络 MLP 多层感知机 入门 步骤可视化 Understanding and coding Neural Networks From Scratch in Python and R翻译
最近在做本科的毕业设计,用到Faster R-CNN,要调整网络结构的时候才发现自己的基础其实挺不扎实的,因此决定从NN和CNN开始重新看起。
我翻译了Analytics Vidhya上一位博主对神经网络的详细、全面地介绍。如果有翻译不恰当之处,请各位及时指正,一起进步!
原文地址:https://www.analyticsvidhya.com/blog/2017/05/neural-network-from-scratch-in-python-and-r/
Neural Network 神经网络
内容提要
- 关于神经网络的一些直观的感受
- 多层感知机和它的基础
- 神经网络方法论所需的步骤
- 神经网络工作的可视化步骤
- 用Numpy实现神经网络(python)
- 用R语言实现神经网络
- 【可选】后向传播算法的数学视角
关于神经网络的一些直观的感受
大家调bug的时候会知道,我们经常写一堆测试用例,改变输入或者环境变量来查看输出。输出的变化往往会暗示我们到哪里去找bug——哪个模型或者哪一行。当我们找到bug的时候,我们会修改代码,继续下一步工作,直到代码正确。
神经网络和这个的工作原理很相似。它有几个输入,用多个神经元和多个隐藏层处理这些输入,然后使用输出层来返回结果。这个结果评估过程被叫做“前向传播”
接着,我们把结果和实际的结果对比。我们的任务是让神经网络输出的结果越接近实际(想要的)结果越好。每一个神经元都多多少少会对最终的输出结果的错误有些影响,那么我们怎么减少这些错误呢?
我们尝试着把对错误影响更大的神经元的值/比重降到最小,这一过程发生在我们重新回到神经网络的这些神经元里寻找错误的发生点,我们称之为“反向传播”
为了减少最小化这些错误时的迭代次数,神经网络有一个通用的算法被称为“梯度下降法”,这使得这项任务高效快捷。
这就是神经网络的工作过程!我知道这是一个很简单的表达,但是这会帮助你更容易地理解它。
多层感知机和它的基础
就像地球上的任何物质都是由原子组成的一样——神经网络的基本组成单位是感知机。所以,什么是感知机呢?
一个感知机可以被理解成一个由多个输入但只有一个输出的东西。比如,看下面这张图。
上面这个结构有三个输入,一个输出。按逻辑来说,下一个问题将会是这些输入和输出之间有什么关系?让我们从最简单的方法开始,然后一点点寻找更复杂的方法。
接下来,我会讨论三种创造输入输出关系的方法:
- 直接把输入结合然后计算输出,设置一个阈值。比如x1=0,x2=1,x3=1,阈值=0.如果x1+x2+x3>0,输出是1,否则是0。所以在这个例子中,感知机的输出结果是1。
- 对输入添加权重。权重代表着输入的重要程度。比如,我们假定w1=2,w2=3,w3=4分别对应着x1,x2和x3。为了计算输出,我们会吧输入和对应的权重相乘,然后护额阈值进行比较:w1*x1+w2*x2+w3*x3>阈值。这个权重表示x3比x1和x2都要重要。
- 添加偏移。每一个感知机同时也有一个偏移,可以看作这个感知机有多灵活。这个在某些程度上和y=ax+b中的常数b有点相像。它允许我们上下移动这条线来更好地预测数据。如果没有b,这条线会始终经过原点(0,0),你可能得不到更好的拟合。比如,一个感知机可能有两个输入,在这种情况下,它需要三个权重:两个输入权重和一个偏移。现在,输入的线性表达式是这样的:w1*x1+w2*x2+w3*x3+1*b。
但是,以上这些全都是线性的,这都是感知机曾经的模样,这些并不有趣。所以,人们提出了一种思想,把感知机进化为现在的“人工神经元”。一个神经元对输入和偏移有着非线性的变换(激活函数)。
什么是激活函数?
激活函数把加了权重的输入的和(w1*x1+w2*x2+w3*x3+1*b)作为一个参数,返回神经元的输出。
在上面这个式子中,我们把1表示为x0,把b表示为w0。(这样就没有+b多出来了)
激活函数大多用来做一个非线性变换,我们可以用它来适应一个非线性假设或者来评估一个复杂的函数。激活函数有多种类型,比如:“Sigmoid”,“Tanh”,“ReLu”等等。
前向传播,反向传播和迭代次数
到目前为止,我们已经计算了输出,这一过程被叫做“前向传播”。但是如果被评估的输出和实际输出相差十万八千里呢(高误差)。在神经网络中,我们基于误差更新偏移和权重。这个权重和误差的更新过程被称为“反向传播”。
反向传播(BP)算法在输出时确定损失(或者误差),然后把它传回网络,更新权重以最小化由各个神经元引起的误差。最小化过程中的第一步就是确定每个节点,也就是最终输出的梯度(导数)。反向传播的数学视角将在下面的板块中展现。
这个前向和反向的传播过程的迭代轮回被叫做一个训练迭代过程,又称为“迭代次数”。
多层感知机
现在,我们来看下一个环节:多层感知机。目前为止,我们已经见识了单层的,由3个输入节点,也就是x1,x2,x3和1个单个神经元输出层组成。但是出于实际目的考虑,单一层的网络可以做的事情有限。一个多层感知机由被叫做隐藏层的多个层堆叠在输入层和输出层之间形成,如下图所示。
上面的图片展示了只有一层绿色的隐藏层的情况,但是实际上可以有多层隐藏层。另外一个要记住的多层感知机的关键点是所有的层都是全连接的,也就是说一层中的每一个节点都与上一层和下一层的每一个节点相连(除了输入和输出层)。
让我们继续下一个话题:一个神经网络(最小化误差)的训练算法。这里,我们将看一下最普遍的训练算法,被称作“梯度下降法”。
全量梯度下降法和随机梯度下降法
梯度下降法的两种变体都在更新多层感知机权重方面做了相同的工作,使用了相同的更新算法。区别在于每次更新权重和偏移时使用的训练样本数量的多少。
全量梯度下降法,如名字所说,用了所有的训练数据去更新每一个权重一次。而随机梯度下降法,用1个或多个(样本),但从来不会是所有的训练数据,去更新权重一次。
我们用一个简单的只有10个数据2个权重w1和w2的数据集来理解这个问题。
全量梯度下降法:你用10个数据(整个数据集)去计算w1和w2的变化(Δw1、Δw2),然后更新w1和w2。
随机梯度下降法:你用第一个数据去计算w1和w2的变化(Δw1、Δw2),然后更新w1和w2。接着,当你用第二个数据的时候,你会在已经更新的权重上继续更新。
更多深入的解释,可以看这篇文章。
神经网络方法论所需的步骤
让我们一步步来看神经网络搭建的方法(一个隐藏层的多层感知机,和上面的结构相似)。旨在输出层,我们只有一个神经元,因为我们要解决的是一个二分类问题(预测0和1).我们也可以有两个神经元去预测每一个类别。
首先我们看一下大概的步骤:
0)我们列出输入和输出
X:一个输入矩阵
y:一个输出矩阵
1)我们用随机值(这只是第一次初始化。下一次,我们会使用更新了的权重和偏移)初始化权重和偏移。我们定义:
- wh:隐藏层的权重矩阵
- bh:隐藏层的偏移矩阵
- wout:输出层的权重矩阵
- bout:输出层的偏移矩阵
2)我们把输入和权重的矩阵点积传入输入层和隐藏层之间,然后给隐藏层神经元对应的输入加上偏移,这一过程被称为线性转换:
hidden_layer_input = matrix_dot_product(X,wh) + bh
3)用激活函数(Sigmoid)来完成非线性转换。Sigmoid会返回输出:1/(1+exp(-x))
hiddenlayer_activations = sigmoid(hidden_layer_input)
4)对隐藏层激活后参数做一个线性变换(与权重矩阵点乘然后加上输出层神经元的偏移),然后传入激活函数(同样适用sigmoid,但你也可以根据你的任务选择使用其他激活函数)来预测输出。
output_layer_input = matrix_dot_product(hiddenlayer_activations * wout) + bout
output = sigmoid(output_layer_input)
以上所有步骤被称为“前向传播”
5)把预测的结果和真实的输出做对比,然后计算误差(真实值-预测值)的梯度。此处,我们设定误差是均方损失= ((Y-t)^2)/2
E = y – output(这应该是宏观意义上的表达式)
6)计算隐藏层和输出层神经元的斜度/梯度(为了计算梯度,我们计算非线性激活后的每一层每一个神经元处的x的导数)。sigmoid的导数是x * (1 - x)
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
7)计算输出层的变化因素(delta),取决于误差的梯度与激活后的输出层的梯度之积。
d_output = E * slope_output_layer
8)在这一步,误差会传回到网络,也就是隐藏层的误差。我们会把输出层的delta和隐藏层与输出层之间的权重参数(wout.T)相乘.
Error_at_hidden_layer = matrix_dot_product(d_output, wout.Transpose)
9)计算隐藏层的变化因素(delta),把隐藏层的误差与激活后的隐藏层的梯度相乘
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
10)更新输出层和隐藏层的权重:网络里的权重可以根据训练样本计算得到的误差来更新。
wout = wout + matrix_dot_product(hiddenlayer_activations.Transpose, d_output) * learning_rate
wh = wh + matrix_dot_product(X.Transpose, d_hiddenlayer) * learning_rate
learning_rate:学习率,用来控制权重更新的程度
11)更新输出层和隐藏层的偏移:网络的偏移可以根据神经元的总误差来更新。
- bias at output_layer = bias at output_layer + sum of delta of output_layer at row-wise * learning_rate
- bias at hidden_layer = bias at hidden_layer + sum of delta of output_layer at row-wise * learning_rate
bh = bh + sum(d_hiddenlayer, axis=0) * learning_rate
bout = bout + sum(d_out, axis=0) * learning_rate
步骤5到11被叫做“反向传播”
一次前向和反向传播的迭代被认为是一次训练轮数。 正如我之前所提到的,当我们训练第二次并且更新权重和偏移是前向传播。
以上,我们已经更新了隐藏层和输出层的权重和偏移了,我们使用了全量梯度下降算法。
神经网络工作的可视化步骤
我们会重复上述步骤,然后把输入、权重、偏移、输出、误差矩阵可视化,来更好地理解神经网络(多层感知机)的方法。
注意:
- 为了更好地展示图像,我只保留小数点后两到三位。
- 黄色单元格代表当前激活的单元
- 橙色单元格代表用于计算现有单元格的输入
步骤0:读取输入和输出。

步骤1:用随机值初始化权重和偏移(初始化权重和偏移是有方法的,但是现在我们就用随机值初始化它们)

步骤2:计算隐藏层的输入
hidden_layer_input= matrix_dot_product(X,wh) + bh

步骤3:对隐藏层输入做非线性变换
hiddenlayer_activations = sigmoid(hidden_layer_input)

步骤4:在输出层对激活后的隐藏层完成线性和非线性变换
output_layer_input = matrix_dot_product (hiddenlayer_activations * wout ) + bout
output = sigmoid(output_layer_input)

步骤5:在输出层计算误差(E)的梯度
E = y-output

步骤6:在输出层和隐藏层计算梯度
Slope_output_layer= derivatives_sigmoid(output)
Slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
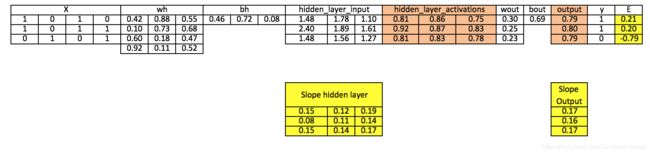
步骤7:在输出层计算delta
d_output = E * slope_output_layer*lr
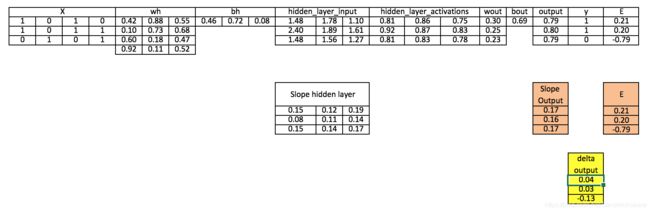
步骤8:在隐藏层计算误差
Error_at_hidden_layer = matrix_dot_product(d_output, wout.Transpose)
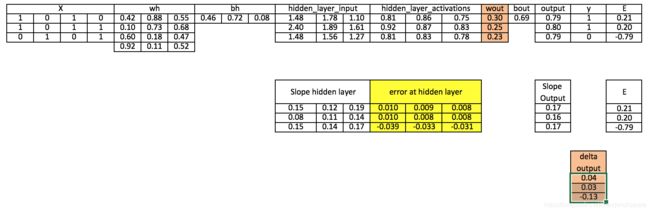
步骤9:计算隐藏层的delta
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
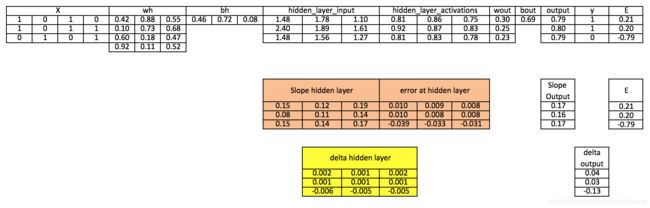
步骤10:在输出层和隐藏层更新权重
wout = wout + matrix_dot_product(hiddenlayer_activations.Transpose,d_output)*learning_rate
wh = wh+ matrix_dot_product(X.Transpose,d_hiddenlayer)*learning_rate
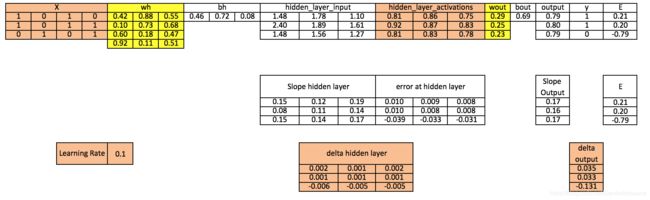
步骤11:在输出层和隐藏层更新偏移
bh = bh + sum(d_hiddenlayer, axis=0) * learning_rate
bout = bout + sum(d_output, axis=0)*learning_rate
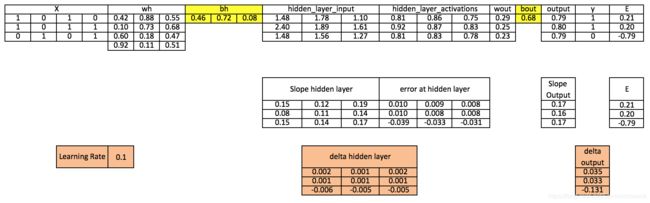
以上,你可以看到我们离实际的目标值还是很远,因为我们只训练了一代。如果我们训练模型多次,那么会有一个非常接近真实值的结果。我训练了上千个迭代次数,并且得到了很接近真实值的值([[ 0.98032096] [ 0.96845624] [ 0.04532167]])。
用Numpy实现神经网络(python)
import numpy as np
#Input arrayX=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Outputy=np.array([[1],[1],[0]])
#Sigmoid Functiondef sigmoid (x):return 1/(1 + np.exp(-x))
#Derivative of Sigmoid Functiondef derivatives_sigmoid(x):return x * (1 - x)
#Variable initializationepoch=5000 #Setting training iterationslr=0.1 #Setting learning rateinputlayer_neurons = X.shape[1] #number of features in data sethiddenlayer_neurons = 3 #number of hidden layers neuronsoutput_neurons = 1 #number of neurons at output layer
#weight and bias initializationwh=np.random.uniform(size=(inputlayer_neurons,hiddenlayer_neurons))bh=np.random.uniform(size=(1,hiddenlayer_neurons))wout=np.random.uniform(size=(hiddenlayer_neurons,output_neurons))bout=np.random.uniform(size=(1,output_neurons))
for i in range(epoch):
#Forward Propogationhidden_layer_input1=np.dot(X,wh)hidden_layer_input=hidden_layer_input1 + bhhiddenlayer_activations = sigmoid(hidden_layer_input)output_layer_input1=np.dot(hiddenlayer_activations,wout)output_layer_input= output_layer_input1+ boutoutput = sigmoid(output_layer_input)
#BackpropagationE = y-outputslope_output_layer = derivatives_sigmoid(output)slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)d_output = E * slope_output_layerError_at_hidden_layer = d_output.dot(wout.T)d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layerwout += hiddenlayer_activations.T.dot(d_output) *lrbout += np.sum(d_output, axis=0,keepdims=True) *lrwh += X.T.dot(d_hiddenlayer) *lrbh += np.sum(d_hiddenlayer, axis=0,keepdims=True) *lr
print output
用R语言实现神经网络
# input matrixX=matrix(c(1,0,1,0,1,0,1,1,0,1,0,1),nrow = 3, ncol=4,byrow = TRUE)
# output matrixY=matrix(c(1,1,0),byrow=FALSE)
#sigmoid functionsigmoid<-function(x){1/(1+exp(-x))}
# derivative of sigmoid functionderivatives_sigmoid<-function(x){x*(1-x)}
# variable initializationepoch=5000lr=0.1inputlayer_neurons=ncol(X)hiddenlayer_neurons=3output_neurons=1
#weight and bias initializationwh=matrix( rnorm(inputlayer_neurons*hiddenlayer_neurons,mean=0,sd=1), inputlayer_neurons, hiddenlayer_neurons)bias_in=runif(hiddenlayer_neurons)bias_in_temp=rep(bias_in, nrow(X))bh=matrix(bias_in_temp, nrow = nrow(X), byrow = FALSE)wout=matrix( rnorm(hiddenlayer_neurons*output_neurons,mean=0,sd=1), hiddenlayer_neurons, output_neurons)
bias_out=runif(output_neurons)bias_out_temp=rep(bias_out,nrow(X))bout=matrix(bias_out_temp,nrow = nrow(X),byrow = FALSE)# forward propagationfor(i in 1:epoch){
hidden_layer_input1= X%*%whhidden_layer_input=hidden_layer_input1+bhhidden_layer_activations=sigmoid(hidden_layer_input)output_layer_input1=hidden_layer_activations%*%woutoutput_layer_input=output_layer_input1+boutoutput= sigmoid(output_layer_input)
# Back Propagation
E=Y-outputslope_output_layer=derivatives_sigmoid(output)slope_hidden_layer=derivatives_sigmoid(hidden_layer_activations)d_output=E*slope_output_layerError_at_hidden_layer=d_output%*%t(wout)d_hiddenlayer=Error_at_hidden_layer*slope_hidden_layerwout= wout + (t(hidden_layer_activations)%*%d_output)*lrbout= bout+rowSums(d_output)*lrwh = wh +(t(X)%*%d_hiddenlayer)*lrbh = bh + rowSums(d_hiddenlayer)*lr
}output
【可选】后向传播算法的数学视角
后续更新