近期C6000 DSP开发小结
使用C++开发DSP
如果你也跟我一样刚开始接触C6000系列的DSP,我觉得可以尝试一下用C++来开发,虽然说这么做代码的执行效率可能会比C或者纯汇编的开发来得低,但它胜在能够让整个工程的脉络更加清晰。

面向C6000开发的cl6x编译器对C++有比较好的支持。上面三个文档就在编译器的安装路径下,一个是介绍COFF移植到EABI的注意点,另外两个一个是关于编译器的文档,一个是关于汇编工具的文档。本文中的部分内容主要也是参考上面的文档。
编译器支持的C标准是C89,支持的C++标准是C++98(而且有一些例外,本文中没有列出),支持的C++的主要特性有下面这些:
- Complete C++ standard library support
- Templates
- Exceptions, which are enabled with the --exceptions option
- Run-time type information (RTTI), which can be enabled with the --rtti compiler option
它虽然并不是完全支持C++98,但上面这些特性基本上完全够用了,模板、异常处理。特别是模板类的定义和类的继承让一些算法的实现方便很多。
实现了C++的灵活性的同时,肯定损失了不少性能,因此还可以使能“Embedded C++”的选项,它限制了部分开销较大的C++的功能,从一定程度上能够提高代码的执行效率,受到限制的功能主要有下面这些:
- Templates
- Exception handling
- Run-time type information
- The new cast syntax
- The keyword mutable
- Multiple inheritance
- Virtual inheritance
可以注意到,这里模板、虚继承、多重继承都被禁用了。所以如果决定使能“Embedded C++”时,就要注意写代码的时候不能用到上面这些特性。使能Embedded C++势必能够提高代码的执行效率,是否需要使能可以根据实际情况决定。
我先写了一段最简单的代码试了一下,然后发现没有输出。(一度以为它对C++的支持有毛病)
#include
int main()
{
std::cout << "Hello World!" << std::endl;
return 0;
}
后来发现是栈溢出的问题,DSP的开发,一直没有栈溢出的报错。有个Stack Usage的窗口我也用不了,可能是我的CCS版本太低的缘故。每次栈溢出了,程序就会跑飞。我一开始没有输出就是stack设置得太小了。
cl6x对C/C++采用同样的编译命令,所以其实源代码中可以C和C++的代码混着写。C++的代码在调用C写的函数的时候,C写的函数的声明需要有exter "C"的说明,可以把C函数的声明包括在 “exter “C” {}” 的花括号中间。
#ifdef __cplusplus
extern "C" {
#endif
// function declarations
#ifdef __cplusplus
}
#endif
初始化列表中的数组初始化
C++11中新引入了初始化列表,initializer-clause。这个在C++98里面是没有的,下面是两种规范中对“赋值运算表达式”的定义,C++11中做了这一更改。
C++11 中的定义

C++98 中的定义

我当时是想在类的构造函数的初始化列表里直接初始化数组,后来发现不行,才在构造函数的函数体里逐个初始化数组的每个元素。后来我做了一个简单的实验。
这是我在windows下的g++版本

用C++98的标准来编译的,报错。

用C++11的标准来编译的,就能正常通过。

COFF与EABI
COFF和EABI主要就是设置编译生成的目标文件的格式。COFF是传统的格式,EABI是新的格式。我们能用新的就用新的呗。但以前的驱动文件是以COFF的标准写的,要从COFF移植到EABI是我们需要关心的问题。
COFF和EABI的差异在上面的文档SPRAB09中有详细的介绍。我目前觉得最大的区别就是,在编译COFF格式的目标文件的时候,C/C++的源文件中的symbol前面会加上一个下划线。而EABI则不会有这个情况。
如果整个工程中的源文件都是用C/C++写的,那就不会有什么问题,因为每个源文件都遵守相同的规则。但是如果有用汇编写的源文件,目标文件格式是COFF,那么“.asm”文件中的symbol前面都至少有一个下划线,那样才能和C/C++的源文件link;而如果目标文件格式是EABI,那这些symbol就和C/C++的源文件中保持一致就行。
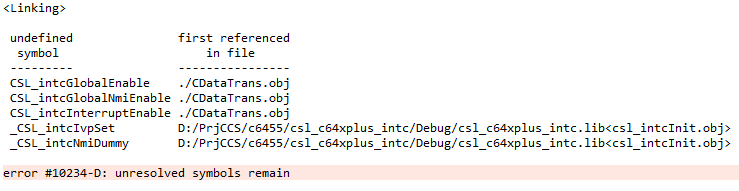
上面这个报错就是因为在汇编文件中的symbol定义都是在前面加了下划线的,所以在link的时候就出现了找不到symbol的问题。
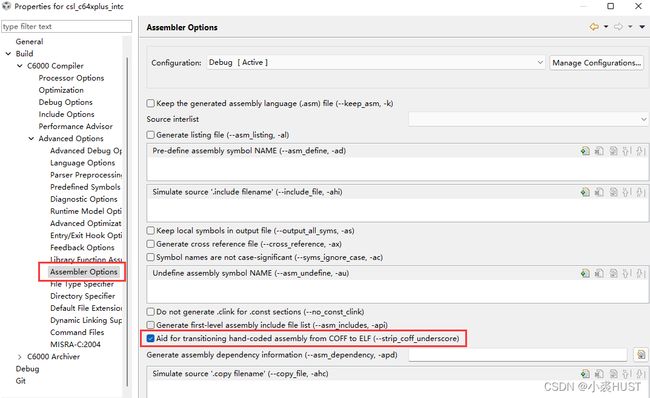
这一问题最简单的办法我觉得就是把上面这个“–strip_coff_underscore”的选项勾上。这样在编译的时候“.asm”文件中的symbol前面的下划线都会被去掉。当然还可以去改汇编的源代码,但那样就相对来说麻烦很多了。
数据地址模型
文档里写的是“Data Adress Model”,我也不知道我的翻译合不合适。大概是说有一个数据页面指针(DP),里面存放一个基地址,在这一基地址附近的数据可以很快被访问到,因为偏移地址可以直接嵌在一条指令里面;而如果待访问的数据不在DP指针附近,那就需要多个周期才能访问到需要的数据。前者是near类型的变量,后者是far类型的变量。

DSP有三种可选的设置。near和far分别表示变量默认为near类型的访问或者far类型的访问。而“far aggregates”则表示数组作为far类型访问,而其他的变量作为near类型访问。
如果设置了很多全局变量,就有可能出现这样的错误。就是near类型的访问够不到这些变量了。
the xx-bit relocated address xxx is too large to encode in the 15-bit unsigned field

最简单的解决办法就是把访问类型设置成far,这样会导致变量的访问变慢;或者设置部分变量为far。比如:
int far a;
EDMA3配置
C6000系列的EDMA3可以实现非常灵活的数据传输功能。我用过C6455的EDMA和M6678的EDMA,它们的功能几乎完全一样,不同的可能只是通道数量、中断源的编号不同。下面的代码以C6455的CSL驱动函数为例做一个介绍。
EDMA有很多通道,每个通道可能会和一个外部事件绑定(也可能没有),这是固定的。通道和PaRAM还有队列的关系可以用户自己设置。队列是有优先级的,队列号小的优先级高(会优先出队列)。每个队列都和一个传输控制器对应,多个传输控制器在数据总线上也有优先级,这也可以设置。EDMA功能的实现最关键的还是PaRAM的设置,它决定了每次传输要实现的功能。
下面是某一个PaRAM的设置代码。
hParam = CSL_edma3GetParamHandle(ms_hEdma3, 0, &status);
paramSetup.option = CSL_EDMA3_OPT_MAKE(CSL_EDMA3_ITCCH_DIS, \
CSL_EDMA3_TCCH_EN, \
CSL_EDMA3_ITCINT_DIS, \
CSL_EDMA3_TCINT_DIS,\
CSL_EDMA3_CHA_3,\
CSL_EDMA3_TCC_NORMAL,\
CSL_EDMA3_FIFOWIDTH_32BIT, \
CSL_EDMA3_STATIC_DIS, \
CSL_EDMA3_SYNC_A, \
CSL_EDMA3_ADDRMODE_INCR, \
CSL_EDMA3_ADDRMODE_CONST);
paramSetup.srcAddr = IR_IMG_RD_ADDR;
paramSetup.aCntbCnt = CSL_EDMA3_CNT_MAKE(8, 1);
paramSetup.dstAddr = ms_pMatIr0->GetHeaderAddr();
paramSetup.srcDstBidx = CSL_EDMA3_BIDX_MAKE(0, 0);
paramSetup.linkBcntrld = CSL_EDMA3_LINKBCNTRLD_MAKE(1<<5,0);
paramSetup.srcDstCidx = CSL_EDMA3_CIDX_MAKE(0, 0);
paramSetup.cCnt = 1;
CSL_edma3ParamSetup(hParam, ¶mSetup);
一个事件产生,或者一次手动触发,通道控制器(CC)就会向传输控制器(TC)发送一个传输请求(TR)
A模式和AB模式的区别主要在于,一个TR传输的数据量。A模式一个TR传输ACnt数据,AB模式一个TR传输ACnt×BCnt的数据。
TC完成一次TR之后一般就会等待下一次触发,但如果设置了ITCCH,在这次TR完成之后还会触发另一个传输。TCCH表示在完成了整个PaRAM的传输之后会触发另一个传输。这个叫做“Chain”。
中断也是类似的,ITCINT表示在这次TR完成之后会触发中断。TCINT表示在完成了整个PaRAM的传输之后会触发中断。
在整个PaRAM传输完成之后,可以设置link字段,从别的PaRAM把参数复制过来,更新PaRAM。这个叫做“Link”。
合理地设置Chain和Link就能利用EDMA实现复杂的数据传输功能。