【精华】YOLO fastest/YOLOX/YOLO fastestv2/Nanodet/Nanodet Plus模型对比
目录
-
-
-
- YOLO fastest/YOLOX/YOLO fastestv2/Nanodet/Nanodet Plus模型对比
-
- (1)网络结构
-
- 1> YOLO fastest
- 2> YOLOX-Nano
- 3> YOLO fastestv2
- 4> NanoDet
- 5> NanoDet Plus
- (2)模型结构差异(优化模块)
-
- 1> YOLO fastest
- 2> YOLOX-Nano
- 3> YOLO fastestv2
- 4> NanoDet
- 5> NanoDet Plus
- (3)模型性能
-
- YOLO fastest官方库
- Yolo-Fastest-1.1 Multi-platform benchmark
- YOLOX-Nano官方库
- NanoDet官方库
- YOLO fastestv2官方库
- 1> YOLO fastest
- 2> YOLOX-Nano
- 3> YOLO fastestv2
- 4> NanoDet
- 5> NanoDet Plus
- (4)关键概念解析
-
- 1> 基于Matching Cost的动态匹配
- 2> 标签匹配策略
- 3> Label Assignment
- 4> Generalized Focal Loss
-
-
YOLO fastest/YOLOX/YOLO fastestv2/Nanodet/Nanodet Plus模型对比
- YOLO fastest
- Paper
- Github库
- YOLOX-Nano
- Paper
- Github库
- YOLO fastestv2
- Paper
- Github库
- NanoDet
- Paper
- Github库
- NanoDet Plus
- Paper
- Github库
(1)网络结构
1> YOLO fastest

2> YOLOX-Nano
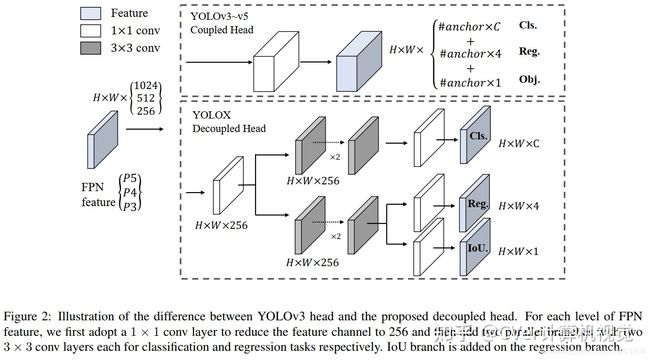
3> YOLO fastestv2
4> NanoDet

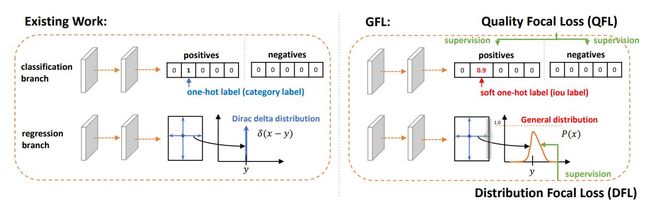
5> NanoDet Plus
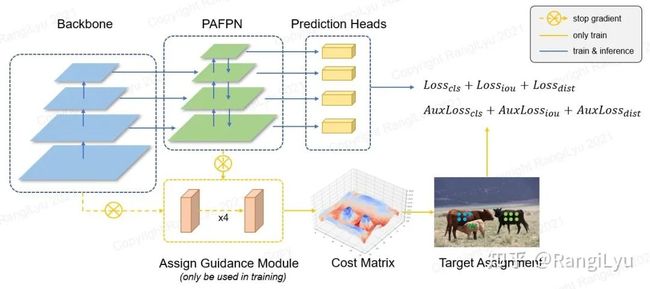
(2)模型结构差异(优化模块)
1> YOLO fastest
-
BackboneEfficientNet-lite
-
注重单核的实时推理性能,在满足实时的条件下的低CPU占用,不单单能在手机移动端达到实时,还要在RK3399,树莓派4以及多种Cortex-A53低成本低功耗设备上满足一定实时性,毕竟这些嵌入式的设备相比与移动端手机要弱很多,但是使用更加广泛,成本更加低廉。
2> YOLOX-Nano
Backbone:YOLOv3(Darknet-53)Head:使用解耦合检测头标签匹配策略:SimOTA
3> YOLO fastestv2
-
BackboneShufflenetv2(相比于EfficientNet-lite,访存减少了,更加轻量)
-
Anchor匹配机制:参考YOLOv5
-
Head:参考YOLOX,使用解耦合检测头。- 检测框的回归、前景背景的分类、检测类别的分类
- 前景背景的分类以及检测类别的分类采用同一网络分支参数共享
- 检测类别分类的loss由sigmoid替换为softmax
- 输出尺度由3个变为2个:(11x11、22x22、44x44)变为(11x11、22x22)
4> NanoDet
-
项目思路- 大模型发展历程:Two stage到One stage,Anchor-base到Anchor-free,Transformer
- 移动端目标检测:YOLO系列和SSD等Anchor-base模型
- NanoDet项目:希望能够开源一个移动端实时的Anchor-free的检测模型。能够提供不亚于YOLO系列的性能,而且同样方便训练和移植。
- 思路一:将FCOS轻量化<原因:FCOS的centerness分支在轻量化模型上很难收敛>(效果不佳,不如MobileNet+YOLOv3)
- 思路二:GFocalLoss完美去掉了FCOS系列的centerness分支,省去了这一分支上的大量卷积,减少了检测头的计算开销,非常适合移动端的轻量化部署。
-
Backbone:-
尝试了Mbilenet系列、GhostNet、Shufflenet、EfficientNet
-
使用
Shufflenet v2:权衡参数量、计算量以及权重大小,该模型在相似精度下体积最小,而且对移动端CPU推理比较友好。使用Shufflenetv2 1.0x作为Backbone,去掉最后一层卷积,并且抽取8、16、32倍下采样的特征输入进PAN做多尺度的特征融合。
-
-
Neck:PAFPN- BiFPN:EfficientDet (性能强大,但堆叠的特征融合操作势必会带来运行速度的降低)
- PAN:YOLOv4/YOLOv5 (只有自下而上和自上而下的两条通路,非常简洁,是轻量化模型特征融合的不二选择)
- BalancedFPN
- PAFPN
- 完全去掉PAN中的所有卷积,只保留从骨干网络特征提取后的1x1卷积来进行特征通道维度的对齐,上采样和下采样均使用插值来完成。
- 与yolo使用的concatenate操作不同,将多尺度的Feature Map直接相加,使得整个特征融合模块的计算量变得非常非常小。
-
Head-
使用2个深度可分离卷积模块同时预测分类和回归,并将卷积堆叠的数量从4个减少到2组,通道由256压缩到96维(大模型中使用4组256channel的3x3卷积预测分类和回归)
-
检测头不共享权重:取消FCOS系列模型的共享权重策略,由于移动端模型推理由CPU进行计算,共享权重并不会对推理过程进行加速,而且在检测头非常轻量的情况下,共享权重使得其检测能力进一步下降,因此还是选择每一层特征使用一组卷积比较合适。
-
用BN代替GN(Group Normalization):在推理时能够将其归一化的参数直接融合进卷积中,节省归一化时间。
-
-
标签匹配策略-
ATSS:根据IOU的均值和方差为每一层feature map动态选取匹配样本(本质上依然时基于先验信息(中心点和Anchor)的静态匹配策略)
在每个 FPN 层选取离 gt 框中心点最近的 k 个 anchor,之后对所有选取的 anchor 与 gt 计算 IOU,同时计算 IOU 均值和方差,最后保留 IOU 大于均值加方差的并且中心点在 gt 之内的 anchor 作为正样本。
-
-
训练策略- SGD+momentum+MutiStepLr
5> NanoDet Plus
-
Backbone- FBNetv5/PicoDet:ESNet(使用NAS搜索,在约束了计算量参数量和精度的搜索空间内搜出强的Backbone)
- NanoDet Plus:沿用NanoDet的Backbone,后期可修改为ESNet。(算力霸权下妥协)
-
Neck- YOLOX/PicoDet/YOLOv5:CSP-PAN
- NanoDet:
Ghost-PAN(GhostNet中的GhostBlock(1x1和3x3的depthwise))(mAP提升2%)
-
Head- ThunderNet:轻量级模型中将深度可分离卷积的depthwise部分从3x3改成5x5(增加较少参数量的同时提升检测器感受野并提升性能)
- PicoDet:在原本NanoDet的3层特征基础上增加一层下采样特征
- NanoDet Plus:沿用通用技巧,将检测头的depthwise卷积的卷积核大小改成5x5,并在NanoDet的3层特征基础上增加一层下采样特征。(mAP提升0.7%)
-
标签匹配策略(使用AGM(Assign Guidance Module)并配合动态的软标签分配策略DSLA(ynamic Soft Label Assigner)来解决轻量级模型中的最优标签匹配问题)(mAP提升2.1%)使用AGM预测的分类概率和检测框会送入DSLA模块计算Matching Cost。Cost函数由三部分组成:classification cost,regression cost以及distance cost:
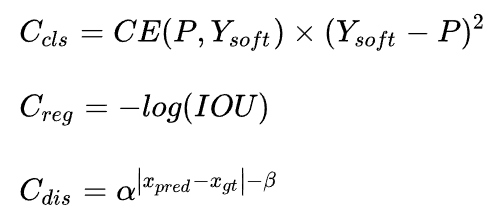
最终的代价函数就是这样:
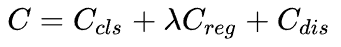
-
训练策略- 优化器:SGD+momentum改成AdamW(对超参数更不敏感且收敛更快)
- 学习率衰减策略:从MultiStepLr改成CosineAnnealingLR,反向传播计算梯度时加了梯度裁剪。
- 其他:增加模型平滑策略EMA
-
部署优化- NanoDet:使用多尺度检测头,每层都有分类和回归两个输出,加上有三个尺度的特征图,共有6个输出。(对不熟悉模型结构的人不友好)
- NanoDet Plus:将模型输出合为一个,所有的输出Tensor都提前reshape,然后concatenate到一起。(略微影响后处理速度,但模型友好)
(3)模型性能
YOLO fastest官方库
| Network | COCO mAP(0.5) | Resolution | Run Time(Ncnn 4xCore) | Run Time(Ncnn 1xCore) | FLOPS | Params | Weight size |
|---|---|---|---|---|---|---|---|
| Yolo-Fastest-1.1 | 24.40 % | 320X320 | 5.59 ms | 7.52 ms | 0.252BFlops | 0.35M | 1.4M |
| Yolo-Fastest-1.1-xl | 34.33 % | 320X320 | 9.27ms | 15.72ms | 0.725BFlops | 0.925M | 3.7M |
| Yolov3-Tiny-Prn | 33.1% | 416X416 | %ms | %ms | 3.5BFlops | 4.7M | 18.8M |
| Yolov4-Tiny | 40.2% | 416X416 | 23.67ms | 40.14ms | 6.9 BFlops | 5.77M | 23.1M |
Yolo-Fastest-1.1 Multi-platform benchmark
| Equipment | Computing backend | System | Framework | Run time |
|---|---|---|---|---|
| Mi 11 | Snapdragon 888 | Android(arm64) | ncnn | 5.59ms |
| Mate 30 | Kirin 990 | Android(arm64) | ncnn | 6.12ms |
| Meizu 16 | Snapdragon 845 | Android(arm64) | ncnn | 7.72ms |
| Development board | Snapdragon 835(Monkey version) | Android(arm64) | ncnn | 20.52ms |
| Development board | RK3399 | Linux(arm64) | ncnn | 35.04ms |
| Raspberrypi 3B | 4xCortex-A53 | Linux(arm64) | ncnn | 62.31ms |
| Orangepi Zero Lts | H2+ 4xCortex-A7 | Linux(armv7) | ncnn | 550ms |
| Nvidia | Gtx 1050ti | Ubuntu(x64) | darknet | 4.73ms |
| Intel | i7-8700 | Ubuntu(x64) | ncnn | 5.78ms |
Pascal VOC performance index comparison
| Network | Model Size | mAP(VOC 2007) | FLOPS |
|---|---|---|---|
| Tiny YOLOv2 | 60.5MB | 57.1% | 6.97BFlops |
| Tiny YOLOv3 | 33.4MB | 58.4% | 5.52BFlops |
| YOLO Nano | 4.0MB | 69.1% | 4.51Bflops |
| MobileNetv2-SSD-Lite | 13.8MB | 68.6% | &Bflops |
| MobileNetV2-YOLOv3 | 11.52MB | 70.20% | 2.02Bflos |
| Pelee-SSD | 21.68MB | 70.09% | 2.40Bflos |
| Yolo Fastest | 1.3MB | 61.02% | 0.23Bflops |
| Yolo Fastest-XL | 3.5MB | 69.43% | 0.70Bflops |
| MobileNetv2-YOLOv3-Lite | 8.0MB | 73.26% | 1.80Bflops |
YOLOX-Nano官方库
| Model | size | mAPval 0.5:0.95 | Params (M) | FLOPs (G) | weights |
|---|---|---|---|---|---|
| YOLOX-Nano | 416 | 25.8 | 0.91 | 1.08 | github |
| YOLOX-Tiny | 416 | 32.8 | 5.06 | 6.45 | github |
NanoDet官方库
| Model | Resolution | mAPval 0.5:0.95 | CPU Latency (i7-8700) | ARM Latency (4xA76) | FLOPS | Params | Model Size |
|---|---|---|---|---|---|---|---|
| NanoDet-m | 320*320 | 20.6 | 4.98ms | 10.23ms | 0.72G | 0.95M | 1.8MB(FP16) | 980KB(INT8) |
| NanoDet-m | 416*416 | 21.7 | 16.44ms | 1.2G | 0.95M | 1.8MB(FP16) | 980KB(INT8) | |
| NanoDet-Plus-m | 320*320 | 27.0 | 5.25ms | 11.97ms | 0.9G | 1.17M | 2.3MB(FP16) | 1.2MB(INT8) |
| NanoDet-Plus-m | 416*416 | 30.4 | 8.32ms | 19.77ms | 1.52G | 1.17M | 2.3MB(FP16) | 1.2MB(INT8) |
| NanoDet-Plus-m-1.5x | 320*320 | 29.9 | 7.21ms | 15.90ms | 1.75G | 2.44M | 4.7MB(FP16) | 2.3MB(INT8) |
| NanoDet-Plus-m-1.5x | 416*416 | 34.1 | 11.50ms | 25.49ms | 2.97G | 2.44M | 4.7MB(FP16) | 2.3MB(INT8) |
| YOLOv3-Tiny | 416*416 | 16.6 | - | 37.6ms | 5.62G | 8.86M | 33.7MB |
| YOLOv4-Tiny | 416*416 | 21.7 | - | 32.81ms | 6.96G | 6.06M | 23.0MB |
| YOLOX-Nano | 416*416 | 25.8 | - | 23.08ms | 1.08G | 0.91M | 1.8MB(FP16) |
| YOLOv5-n | 640*640 | 28.4 | - | 44.39ms | 4.5G | 1.9M | 3.8MB(FP16) |
| FBNetV5 | 320*640 | 30.4 | - | - | 1.8G | - | - |
| MobileDet | 320*320 | 25.6 | - | - | 0.9G | - | - |
YOLO fastestv2官方库
| Network | COCO mAP(0.5) | Resolution | Run Time(4xCore) | Run Time(1xCore) | FLOPs(G) | Params(M) |
|---|---|---|---|---|---|---|
| Yolo-FastestV2 | 24.10 % | 352X352 | 3.29 ms | 5.37 ms | 0.212 | 0.25M |
| Yolo-FastestV1.1 | 24.40 % | 320X320 | 4.23 ms | 7.54 ms | 0.252 | 0.35M |
| Yolov4-Tiny | 40.2% | 416X416 | 26.00ms | 55.44ms | 6.9 | 5.77M |
1> YOLO fastest
初衷就是打破算力的瓶颈,能在更多的低成本的边缘端设备实时运行目标检测算法。
- 基于NCNN推理框架开启BF16s,在树莓派3b,4核A53 1.2Ghz,320x320图像单次推理时间在60ms。
- 在性能更加强劲的树莓派4b,单次推理33ms,达到了30fps的全实时。
- 而相比较下应用最广泛的轻量化目标检测算法MobileNet-SSD要在树莓派3b跑200ms左右,Yolo-Fastest速度整整要快3倍+,而且模型才只有1.3MB,而MobileNet-SSD模型达到23.2MB,Yolo-Fastest整整比它小了20倍,当然这也是有代价的,在Pascal voc上的mAP,MobileNet-SSD 是72.7,Yolo-Fastest是61.2,带来了接近10个点的精度损失
总结:YOLO-Fastest是个牺牲一定精度 (大约5%的mAP)、大幅提升速度的目标检测模型。
2> YOLOX-Nano
- 对于YOLO-Nano,所提方法仅需0.91M参数+1.08G FLOPs取得了25.3%AP指标,以1.8%超越了NanoDet;
- 对于YOLOv3,所提方法将指标提升到了47.3%,以3%超越了当前最佳;
- 具有与YOLOv4-CSP、YOLOv5-L相当的参数量,YOLOX-L取得了50.0%AP指标同事具有68.9fps推理速度(Tesla V100),指标超过YOLOv5-L 1.8%;
- 值得一提的是,YOLOX-L凭借单模型取得了Streaming Perception(Workshop on Autonomous Driving at CVPR 2021)竞赛冠军。
3> YOLO fastestv2
- 用0.3%的精度损失换取30%推理速度的提升以及25%的参数量的减少
4> NanoDet
在经过对one-stage检测模型三大模块(Head、Neck、Backbone)都进行轻量化之后,得到了目前开源的NanoDet-m模型,在320x320输入分辨率的情况下,整个模型的Flops只有0.72B,而yolov4-tiny则有6.96B,小了将近十倍!模型的参数量也只有0.95M,权重文件在使用ncnn optimize进行16位存储之后,只有1.8mb,非常适合在移动端部署,能够有效减少APP体积,同时也对更低端的嵌入式设备更加友好。
尽管模型非常的轻量,但是性能却依旧强劲。对于小模型,往往选择使用AP50这种比较宽容的评价指标进行对比,这里我选择用更严格一点的COCO mAP(0.5:0.95)作为评估指标,同时兼顾检测和定位的精度。在COCO val 5000张图片上测试,并没有使用Testing-Time-Augmentation的情况下,320分辨率输入能够达到20.6的mAP,比tiny-yolov3高4分,只比yolov4-tiny低1个百分点,而将输入分辨率与yolo保持一致,都使用416输入的情况下,得分持平。
最后用ncnn部署到手机上之后跑了一下benchmark,模型前向计算时间只要10毫秒左右,对比yolov3和v4 tiny,均在30毫秒的量级。在安卓摄像头demo app上,算上图片预处理,检测框后处理以及绘制检测框的时间,也能轻松跑到40+FPS~。
5> NanoDet Plus
- NanoDet Plus与上一代NanoDet相比,在仅增加1毫秒多的延时的情况下,精度提升了30%。
- 改进了代码和架构,提出了一种非常简单的训练辅助模块,使模型变得更易训练,同时新版本也更易部署。
(4)关键概念解析
1> 基于Matching Cost的动态匹配
简单来说,就是直接使用模型检测头的输出,与每一个Ground Truth计算一个匹配的代价,这个代价一般由分类loss和回归loss组成。Feature Map上所有的点(N个)的预测值与所有的Ground Truth(M个)计算得到的NxM的矩阵,就是所谓的Cost Matrix,基于这个Cost Matrix进行二分图匹配也好还是传输优化也好再或者直接取TopK也好,就是一种动态匹配策略。这种策略与之前的基于Anchor算IOU的匹配最大的不同就是,它不再只依赖先验的静态的信息,而是使用当前的预测结果去动态寻找最优的匹配,只要模型预测的越准确,匹配算法求得的结果也会更优秀。
2> 标签匹配策略
- 基于位置
- 基于Anchor IOU
- 基于Matching Cost(直接使用检测头的输出与每一个Ground Truth计算一个匹配的代价(分类Loss和回归Loss))
- 基于全局的动态匹配策略
DETR:使用匈牙利匹配算法进行双边匹配OTA:使用Sinkhorn迭代求解匹配中的最优传输问题(位置约束:使用5x5的中心区域限制匹配自由度)YOLOX:使用OTA的近似算法SimOTA(位置约束:使用5x5的中心区域限制匹配自由度)----:使用LAD(Label Assignment Distillation)用教室网络的结果计算标签匹配来指导学生网络的训练IQDet:使用QDE模块对每个实例预测PAA中提出的高斯混合质量分布的三个参数来指导检测头的训练NanoDet Plus:使用AGM(Assign Guidance Module)并配合动态的软标签分配策略DSLA(ynamic Soft Label Assigner)来解决轻量级模型中的最优标签匹配问题
- 基于全局的动态匹配策略
3> Label Assignment
参考博客:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/109475944
-
主要是指检测算法在训练阶段,如何给特征图上的每个位置进行合适的学习目标的表示,以及如何进行正负样本的分配的。
算法类型 先验 学习目标的表示 正负样本的分配 anchor box anchor box bounding box IoU anchor point center 高斯等 高斯热图等 key point point representative points feature map bin和IoU等 set prediction embedding bounding box Hungarian算法 -
(1)ATSS
论文标题:
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
论文链接 | 代码链接
这篇文章从 anchor-free 和 anchor-base 算法的本质区别出发,通过分析对比 anchor-base 经典算法 retinanet 和 anchor-free 经典算法 FCOS 来说明正负样本分配(label assignment)的重要性。
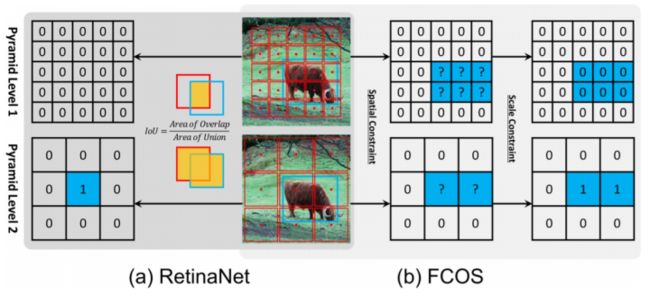
如上图所示,RetinaNet 使用IoU阈值来区分正负 anchor box,处于中间 anchor box 的全部忽略。FCOS 使用空间(spatial)和尺寸(scale)限制来区分正负 anchor point,正样本首先选择在 GT box 内的 anchor points,其次选择 GT 尺寸对应的层 anchor points,其余均为负样本。
最后通过交叉实验,发现在相同正负样本定义下情况下,RetinaNet 和 FCOS 性能几乎一样,而且 spatila and scale constraint 的方式比 IOU 的效果好,如下表:
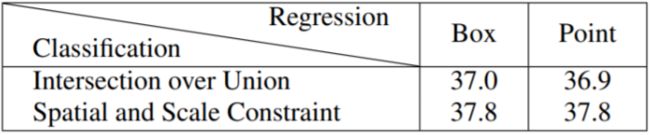
因此 ATSS 提出了一种新的正负样本选取方式,这种方法几乎不会引入额外的超参数并且更加鲁棒。
主要就是在每个 FPN 层选取离 gt 框中心点最近的 k 个 anchor,之后对所有选取的 anchor 与 gt 计算 IOU,同时计算 IOU 均值和方差,最后保留 IOU 大于均值加方差的并且中心点在 gt 之内的 anchor 作为正样本。
根据下表可以发现,即使 anchor box 数量为 1 的 RetinaNet 和 FOCS 在都加上 ATSS 策略之后,效果都有明显的提升,这也证明了 ATSS 策略的有效性。
-
(2)SAPD
论文标题:
Soft Anchor-Point Object Detection
论文链接 | 代码链接
SAPD 就是对 anchor-free 检测器中的 anchor-point 检测器进行了训练策略的改进。SAPD 分析了两个问题:注意力偏差(attention bias)和特征选择(feature selection)。其中,特征选择的问题对金字塔特征层级做软选择,这里就不深入了。而为了解决注意力偏差(attention bias),SAPD 使用了一个新颖的训练策略:Soft-weighted anchor points。
2.1 Attention bias 注意力偏差
在自然图像中,可能会出现遮挡、背景混乱等干扰,SAPD 发现原始的 anchor-point 检测器在处理这些具有挑战性的场景时存在注意力偏差的问题,即具有清晰明亮 views 的目标会生成过高的得分区域,从而抑制了周围的其他目标的得分区域。
这个问题是由于特征不对齐导致了靠近目标边界的位置会得到不必要的高分 所导致的。

2.2 Soft-weighted anchor points
将目标实际位置与 anchor point(也就是 center)的距离作为一个 anchor 的惩罚权重,加入到损失函数的计算中(仅针对正样本,负样本不做改动)。公式如下:
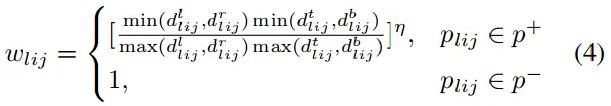
其中,η 控制递减幅度,权重 范围为 0~1,公式保证了目标边界处的 points 权重为 0,目标中心处的 ponit 权重为 1。
这种通过对 anchor points 做软加权,就是 label assign 的进行优化,减少对靠近边界包含大量背景信息的锚点的关注。
-
(3)AutoAssign
论文标题:
AutoAssign: Differentiable Label Assignment for Dense Object Detection
论文链接
AutoAssign 对 label assignment 进行非常全面的讨论。主要解决了在给定一个 bounding box (x, y, w, h) 后,根据框内的物体形状,动态分配正负样本的问题。如下图所示:
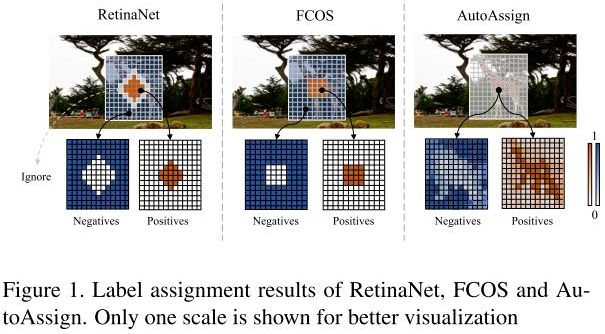
(1)RetinaNet 是根据 anchor box 和 ground truth 的 IOU 阈值定义正负样本,这样会每个样本都是打上非正即负以及 ignore 的标签,而且 anchor box 的 num,size,aspect ratios 等等都是超参数;
(2)FCOS 通过 centerness、空间和尺度约束来分配正负样本,也引入了很多超参数;
(3)AutoAssign 将 label assignment 看做一种连续问题,没有真正意义上的正负样本之分,每个特征图上的位置都有正样本属性和负样本属性,只是权重不同罢了;而且如上图最左变所示,动态分配正负样本更符合目标的形状,可以说有利用分割做检测的思想。
下面是 AutoAssign 的正负样本分配的示意图:
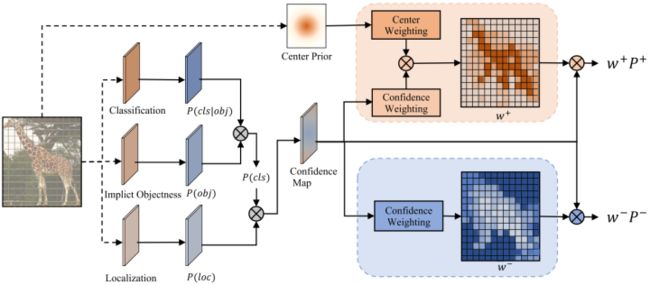
可以看到,比一般的检测算法多了一个 Implict Objectness 分支,用于背景与前景的判断,已解决引入的大量背景位置的问题。
(1)Center Weighting
先使用高斯中心先验确定图像中一个目标正负样本的权重:
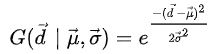
(2)Confidence Weighting
通过 ImpObj 分支来避免引入大量背景位置
与 FreeAnchor 相似,将分类和定位联合看成极大似然估计问题,学习出样本的置信度 Confidence Weighting,即下面的 C(Pi):
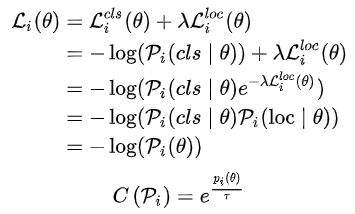
直观的理解 C(Pi) 就是,分类得分高、框预测的准的 location 拥有较大的 C(Pi) 值的概率就会高。
(3)正负样本的权重(w+/w-)
positive weights:通过Center Weighting和Confidence Weighting得到Positive weights
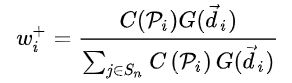
negative weights:通过最大 IOU 得到 Negative weights
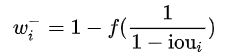
对于前景和背景的 weighting function,有一个共同的特点是 “单调递增”;这就保证了一个位置预测 pos / neg 的置信度越高,那么对应的权重就越大。
(4)loss function
有了对于正负样本的权重之后,对于一个 gt box,其 loss 如下:

Positive weights 和 Negative weights 在训练过程中动态调整达到平衡,像是在学该目标的形状。
-
(4)DETR
论文标题:
End-to-End Object Detection with Transformers
论文链接 | 代码链接
4.1 Object detection set prediction
DETR 将目标检测任务视为一个图像到集合(image-to-set)的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。

那么对于一个目标 ground truth,如何找到对应的 prediction 呢?Detr 用的是 Hungarian algorithm 实现预测值与真值实现最大的匹配,并且是一一对应。
假设有 4 个 prediction(a,b,c,d),有 4 个 ground truth(p,q,r,s),每个 prediction 匹配 ground truth 的好坏都不同,那么便可构造一个代价矩阵(cost matrix,是 cost_bbox、cost_class 和 cost_giou 的加权和),通过求解最优的分配后,得到的每个 prediction 对应 ground truth 最佳分配的结果。
4.2 object queries
传统的 Anchor 是人工设计,铺在特征图上。最初人们给 Anchor 加上 scales 和 aspect ration,后来还有加上了 dense,再到后来,也出现了可学习的 Guided Anchoring,把 anchor 拆解为:位置预测和形状预测。
这种方式的 anchor 有个缺陷是:在推理阶段会产生大量的框,需要 NMS 进行抑制,这说明人工设计的 anchor 是存在冗余的(多个 anchor 匹配到一个 gt 上)。
而 DETR 的 object queries 就是一个 embedding 形式的 learned anchor,目的是让网络自己根据数据集自己学习 anchor。并且 DETR 的实验结果也证明 embedding 已经足够学习 anchor 了。
Detr 也在 coco 2017 val 上对把每个 object query 预测的框做了可视化,如下,选取 N=100 中的 20 个 object query,可以看到不同的 query vector 具有不同的分布(有些注重左下角,有些注重中间…),可以想成:有 N 个不同的人用不同的角度进行观测。

4> Generalized Focal Loss
参考博客:https://zhuanlan.zhihu.com/p/147691786
论文地址:https://arxiv.org/pdf/2006.04388.pdf
源码和预训练模型地址:https://github.com/implus/GFocal
MMDetection官方收录地址:https://github.com/open-mmlab/mmdetection/blob/master/configs/gfl/README.md
总结:基于任意one-stage 检测器上,调整框本身与框质量估计的表示,同时用泛化版本的GFocal Loss训练该改进的表示,无cost涨点(一般1个点出头)AP。