基于CNN网络的轴承故障诊断
内容参考:《基于卷积神经网络的轴承故障 诊断算法研究》–张伟
代码参考:
https://github.com/AaronCosmos/wdcnn_bearning_fault_diagnosis
1 背景:
基于信号处理的特征提取+分类器的传统智能诊断算法,对专家经验要求高,设计耗时且不能保证通用性,已经不能满足机械大数据的要求。提出使用基于卷积神经网络智能诊断算法来自动完成特征提取以及故障识别。
1.1 挑战
机电产品故障诊断面临的挑战,有三大特点:
(1)数据量大,专业分析人员的数量严重不足,仅依靠人力进行检测已不能满足要求,亟需能够进行自动诊断的智能算法。
(2)数据类型多样化,每条数据来源于不同机械设备,工况,以及物理位置,数据特征难挖掘,诊断的难度加大 。
(3)高速率情况下,装备中各零部件的联系更加紧密,一个零件的微小故障很可能引发连锁发应,致使整个设备瘫痪。
1.2 轴承智能故障诊断算法研究现状
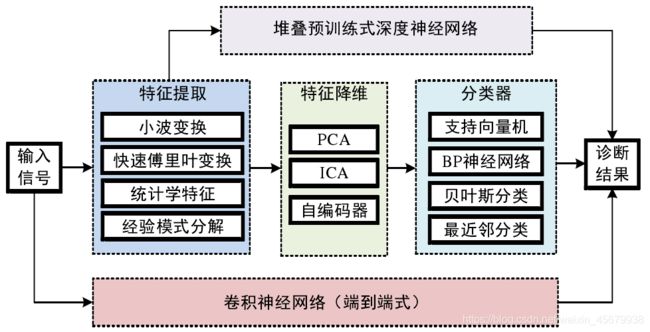
轴承故障诊断时机械状态监测的热门研究方向,其算法的核心在于信号特征提取与模式分类两个部分。在轴承故障诊断领域,常见的特征提取算法有快速傅里叶变化,小波变换,经验模式分解以及信号的统计学特征等,常见的模式分类算法有支持向量机,BP 神经网络(也称为多层感知器),贝叶斯分类器以及最近邻分类器等。当下轴承故障诊断的研究热点是可以归结为 3 类:寻找更好的特征表达;寻找最适合的特征表达以及分类器的组合;以及发明新的传感器。
1.3 智能诊断算法的研究存在以下几个问题:
1)在一个机械系统中表现很好的特征提取器与分类器组合,当装置变化时,不能保证其能否继续保持高识别率,即算法组合的通用性不能保证。
2)在进行故障诊断时,需要先分析机械系统的内在运行机理,再利用信号处理技术分析故障信号。这种做法,对设计人员的技术要求高,难度较大。
3)目前利用数据驱动的特征提取方法,需要预先对信号进行快速傅里叶变换或者小波变换,这种做法存在丢失重要时域特征的可能。
为了解决以上问题,最理想的方式是将特征提取与分类两个环节合二为一,这样不存在相互组合的难题,无需分析机械装置的内在机理,由于直接作用在原始信号上,也不会造成信息的缺失。
然而,卷积神经网络具有“端到端”的特点,即可以通过一个神经网络完成特征提取、特征降维与分类器分类这一整套过程。卷积神经网络的这个特点无疑弥补了当下故障诊断方式的不足,为故障诊断提供了一种崭新的研究思路。
如下图,为轴承智能诊断算法步骤分解 :
2 搭建卷积神经网络进行故障诊断(简称WDCNN)
WDCNN网络搭建的两个关键点:
1)WDCNN第一层为大卷积核,目的是为了提取短时特征,其作用与短时傅里叶变换类似。不同点在于,短时傅里叶变换的窗口函数是正弦函数,而 WDCNN 的第一层大卷积核,是通过优化算法训练得到,其优点是可以自动学习面向诊断的特征,而自动去除对诊断没有帮助的特征。
2)为了增强 WDCNN 的表达能力,除第一层外,其与卷积层的卷积核大小均为3×1。由于卷积核参数少,这样有利于加深网络,同时可以抑制过拟合。每层卷积操作之后均进行批量归一化处理 BN(Batch Normalization),然后进行 2×1 的最大值池化。
其中,BN目的是减少内部协变量转移,提高网络的训练效率,增强网络的泛化能力。
网络结构图如下:
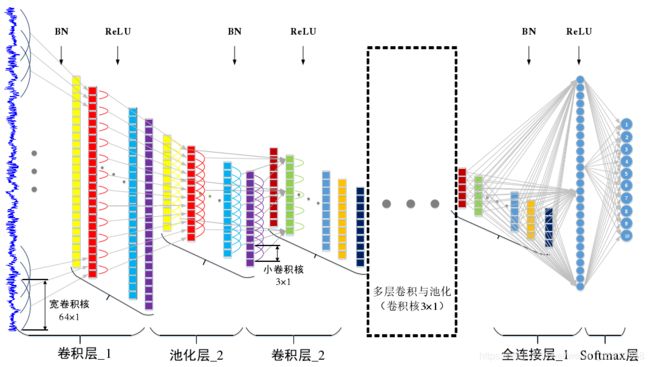
网络结构参数表如下:

3 实验
数据集:凯斯西储大学(CWRU)滚动轴承数据中心
数据网址:https://csegroups.case.edu/bearingdatacenter/pages/download-data-file
试验对象:为下图中的驱动端轴承,被诊断的轴承型号为深沟球轴承 SKF6205,有故障的轴承由电火花加工制作而成,系统的采样频率为 12kHz。被诊断的轴承一共有 3 种缺陷位置,分别是滚动体损伤,外圈损伤与内圈损伤,损伤直径的大小分别为包括 0.007inch, 0.014inch 和 0.021inch,共计 9 种损伤状态。
如下图,为CWRU 滚动轴承数据采集系统:

3.1 实验代码
(基于Tensorflow1.5进行操作,win10,i7-9700k,RTX2070SUPER)
(1)数据预处理代码如下:
from scipy.io import loadmat
import numpy as np
import os
from sklearn import preprocessing # 0-1编码
from sklearn.model_selection import StratifiedShuffleSplit # 随机划分,保证每一类比例相同
def prepro(d_path, length=864, number=1000, normal=True, rate=[0.5, 0.25, 0.25], enc=True, enc_step=28):
"""对数据进行预处理,返回train_X, train_Y, valid_X, valid_Y, test_X, test_Y样本.
:param d_path: 源数据地址
:param length: 信号长度,默认2个信号周期,864
:param number: 每种信号个数,总共10类,默认每个类别1000个数据
:param normal: 是否标准化.True,Fales.默认True
:param rate: 训练集/验证集/测试集比例.默认[0.5,0.25,0.25],相加要等于1
:param enc: 训练集、验证集是否采用数据增强.Bool,默认True
:param enc_step: 增强数据集采样顺延间隔
:return: Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
```
import preprocess.preprocess_nonoise as pre
train_X, train_Y, valid_X, valid_Y, test_X, test_Y = pre.prepro(d_path=path,
length=864,
number=1000,
normal=False,
rate=[0.5, 0.25, 0.25],
enc=True,
enc_step=28)
```
"""
# 获得该文件夹下所有.mat文件名
filenames = os.listdir(d_path)
def capture(original_path):
"""读取mat文件,返回字典
:param original_path: 读取路径
:return: 数据字典
"""
files = {}
for i in filenames:
# 文件路径
file_path = os.path.join(d_path, i)
file = loadmat(file_path)
file_keys = file.keys()
for key in file_keys:
if 'DE' in key:
files[i] = file[key].ravel()
return files
def slice_enc(data, slice_rate=rate[1] + rate[2]):
"""将数据切分为前面多少比例,后面多少比例.
:param data: 单挑数据
:param slice_rate: 验证集以及测试集所占的比例
:return: 切分好的数据
"""
keys = data.keys()
Train_Samples = {}
Test_Samples = {}
for i in keys:
slice_data = data[i]
all_lenght = len(slice_data)
end_index = int(all_lenght * (1 - slice_rate))
samp_train = int(number * (1 - slice_rate)) # 700
Train_sample = []
Test_Sample = []
if enc:
enc_time = length // enc_step
samp_step = 0 # 用来计数Train采样次数
for j in range(samp_train):
random_start = np.random.randint(low=0, high=(end_index - 2 * length))
label = 0
for h in range(enc_time):
samp_step += 1
random_start += enc_step
sample = slice_data[random_start: random_start + length]
Train_sample.append(sample)
if samp_step == samp_train:
label = 1
break
if label:
break
else:
for j in range(samp_train):
random_start = np.random.randint(low=0, high=(end_index - length))
sample = slice_data[random_start:random_start + length]
Train_sample.append(sample)
# 抓取测试数据
for h in range(number - samp_train):
random_start = np.random.randint(low=end_index, high=(all_lenght - length))
sample = slice_data[random_start:random_start + length]
Test_Sample.append(sample)
Train_Samples[i] = Train_sample
Test_Samples[i] = Test_Sample
return Train_Samples, Test_Samples
# 仅抽样完成,打标签
def add_labels(train_test):
X = []
Y = []
label = 0
for i in filenames:
x = train_test[i]
X += x
lenx = len(x)
Y += [label] * lenx
label += 1
return X, Y
# one-hot编码
def one_hot(Train_Y, Test_Y):
Train_Y = np.array(Train_Y).reshape([-1, 1])
Test_Y = np.array(Test_Y).reshape([-1, 1])
Encoder = preprocessing.OneHotEncoder()
Encoder.fit(Train_Y)
Train_Y = Encoder.transform(Train_Y).toarray()
Test_Y = Encoder.transform(Test_Y).toarray()
Train_Y = np.asarray(Train_Y, dtype=np.int32)
Test_Y = np.asarray(Test_Y, dtype=np.int32)
return Train_Y, Test_Y
def scalar_stand(Train_X, Test_X):
# 用训练集标准差标准化训练集以及测试集
scalar = preprocessing.StandardScaler().fit(Train_X)
Train_X = scalar.transform(Train_X)
Test_X = scalar.transform(Test_X)
return Train_X, Test_X
def valid_test_slice(Test_X, Test_Y):
test_size = rate[2] / (rate[1] + rate[2])
ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size)
for train_index, test_index in ss.split(Test_X, Test_Y):
X_valid, X_test = Test_X[train_index], Test_X[test_index]
Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
return X_valid, Y_valid, X_test, Y_test
# 从所有.mat文件中读取出数据的字典
data = capture(original_path=d_path)
# 将数据切分为训练集、测试集
train, test = slice_enc(data)
# 为训练集制作标签,返回X,Y
Train_X, Train_Y = add_labels(train)
# 为测试集制作标签,返回X,Y
Test_X, Test_Y = add_labels(test)
# 为训练集Y/测试集One-hot标签
Train_Y, Test_Y = one_hot(Train_Y, Test_Y)
# 训练数据/测试数据 是否标准化.
if normal:
Train_X, Test_X = scalar_stand(Train_X, Test_X)
else:
# 需要做一个数据转换,转换成np格式.
Train_X = np.asarray(Train_X)
Test_X = np.asarray(Test_X)
# 将测试集切分为验证集合和测试集.
Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)
return Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
if __name__ == "__main__":
path = r'data\0HP'
train_X, train_Y, valid_X, valid_Y, test_X, test_Y = prepro(d_path=path,
length=864,
number=1000,
normal=False,
rate=[0.5, 0.25, 0.25],
enc=False,
enc_step=28)
(2)主程序代码如下:
from keras.layers import Conv1D, Dense, Dropout, BatchNormalization, MaxPooling1D, Activation, Flatten
from keras.models import Sequential
from keras.utils import plot_model
from keras.regularizers import l2
import preprocess
from keras.callbacks import TensorBoard
import numpy as np
# 训练参数
batch_size = 128
epochs = 20
num_classes = 10
length = 2048
BatchNorm = True # 是否批量归一化
number = 1000 # 每类样本的数量
normal = True # 是否标准化
rate = [0.7,0.2,0.1] # 测试集验证集划分比例
path = r'data\0HP'
x_train, y_train, x_valid, y_valid, x_test, y_test = preprocess.prepro(d_path=path,length=length,
number=number,
normal=normal,
rate=rate,
enc=True, enc_step=28)
# 输入卷积的时候还需要修改一下,增加通道数目
x_train, x_valid, x_test = x_train[:,:,np.newaxis], x_valid[:,:,np.newaxis], x_test[:,:,np.newaxis]
# 输入数据的维度
input_shape =x_train.shape[1:]
print('训练样本维度:', x_train.shape)
print(x_train.shape[0], '训练样本个数')
print('验证样本的维度', x_valid.shape)
print(x_valid.shape[0], '验证样本个数')
print('测试样本的维度', x_test.shape)
print(x_test.shape[0], '测试样本个数')
# 定义卷积层
def wdcnn(filters, kernerl_size, strides, conv_padding, pool_padding, pool_size, BatchNormal):
"""wdcnn层神经元
:param filters: 卷积核的数目,整数
:param kernerl_size: 卷积核的尺寸,整数
:param strides: 步长,整数
:param conv_padding: 'same','valid'
:param pool_padding: 'same','valid'
:param pool_size: 池化层核尺寸,整数
:param BatchNormal: 是否Batchnormal,布尔值
:return: model
"""
model.add(Conv1D(filters=filters, kernel_size=kernerl_size, strides=strides,
padding=conv_padding, kernel_regularizer=l2(1e-4)))
if BatchNormal:
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling1D(pool_size=pool_size, padding=pool_padding))
return model
# 实例化序贯模型
model = Sequential()
# 搭建输入层,第一层卷积。因为要指定input_shape,所以单独放出来
model.add(Conv1D(filters=16, kernel_size=64, strides=16, padding='same',kernel_regularizer=l2(1e-4), input_shape=input_shape))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling1D(pool_size=2))
# 第二层卷积
model = wdcnn(filters=32, kernerl_size=3, strides=1, conv_padding='same',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 第三层卷积
model = wdcnn(filters=64, kernerl_size=3, strides=1, conv_padding='same',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 第四层卷积
model = wdcnn(filters=64, kernerl_size=3, strides=1, conv_padding='same',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 第五层卷积
model = wdcnn(filters=64, kernerl_size=3, strides=1, conv_padding='valid',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 从卷积到全连接需要展平
model.add(Flatten())
# 添加全连接层
model.add(Dense(units=100, activation='relu', kernel_regularizer=l2(1e-4)))
# 增加输出层
model.add(Dense(units=num_classes, activation='softmax', kernel_regularizer=l2(1e-4)))
# 编译模型 评价函数和损失函数相似,不过评价函数的结果不会用于训练过程中
model.compile(optimizer='Adam', loss='categorical_crossentropy',
metrics=['accuracy'])
# TensorBoard调用查看一下训练情况
tb_cb = TensorBoard(log_dir='logs')
# 开始模型训练
model.fit(x=x_train, y=y_train, batch_size=batch_size, epochs=epochs,
verbose=1, validation_data=(x_valid, y_valid), shuffle=True,
callbacks=[tb_cb])
# 评估模型
score = model.evaluate(x=x_test, y=y_test, verbose=0)
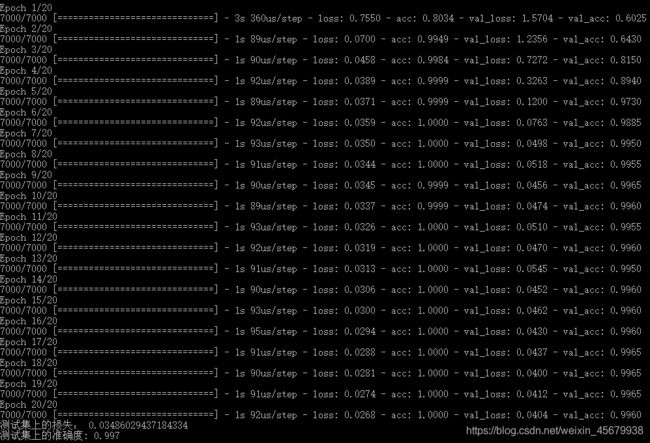
print("测试集上的损失:", score[0])
print("测试集上的准确度:",score[1])
# plot_model(model=model, to_file='wdcnn.png', show_shapes=True)
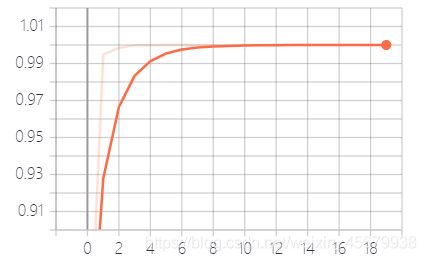
(3)运行结果如下:
(4)启用tensorboard观察训练效果如下:
命令:tensorboard --logdir=logs 或者python -m tensorboard.main --logdir=logs(前面不行用后面)
4 问题延申
4.1 关于噪声与变载问题
在实际的工业应用中,工作环境十分复杂,有两个问题在故障诊断领域值得关注:
1)工业现场的噪声无法避免,使用加速度计测得的振动信号易被污染,如何从含有噪声的信号中诊断出轴承的故障成为众多学者研究的重点;
2)由于工作任务的变化,机器工作负载也会随之改变,如何利用在一个负载下的数据进行训练,对另一个负载下的信号进行诊断,是衡量智能诊断算法适应能力的重要指标。
针对问题1:(噪声影响)
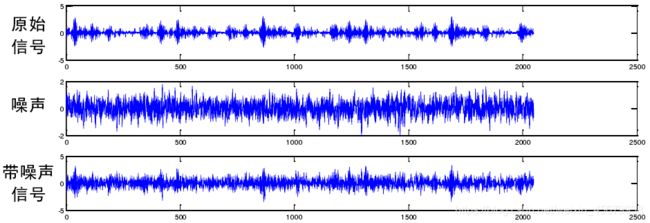
问题描述:信号被噪声严重污染,人眼几乎无法辨析出原型号的振动特征。因此,从带有噪声的信号中提取出有效的故障信息,难度很大。
如下图,为内圈故障信号,加性高斯白噪声及两者相加后 SNR=0dB 的信号 :
针对问题2:(变载情况)
问题描述:工作负载的变化对一个机械系统很常见,当负载发生变化后,由传感器测得的信号也会发生变化。不同负载下,振动信号中特征的个数不相同,幅值大小也不一致,波动周期与相位差别也很大。以上情况会造成分类器对提取的特征无法进行正确归类,从而降低智能诊断系统的识别率。
如下图,为不同负载下,归一化后内圈缺陷大小为 0.014inch 的诊断信号:

解决方案:
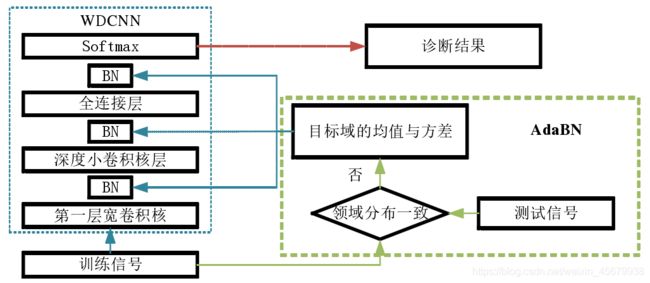
结合AdaBN 算法。AdaBN是基于 BN 的领域自适应算法,主要用于图像识别领域。该算法使用目标领域样本在每一个 BN 层的均值与方差,替换原来 BN 层所使用的由源领域样本计算出的均值与方差。由于 BN 可以减少内部协变量,通过 BN 对源领域样本的作用,以及 AdaBN 对目标领域样本的作用,可以源领域与目标领域调整到一个新的分布空间,在此空间内,两者近似一致,从而达到领域自适应的目的。因为 WDCNN算法采用了 BN 算法,所以可以使用 AdaBN 算法来提高 WDCNN 模型的领域自适应能力,进而增强 WDCNN 模型在噪声以及负载变化的情况下的适应能力。
框架图如下:
如下图,WDCNN(AdaBN)在不同噪声环境下与其它算法的诊断率的对比:

4.2 AdaBN 算法依赖测试集统计学信息问题
问题描述:
虽然 AdaBN 算法可以提高 WDCNN 模型的抗噪能力与变载领域自适应能力,但 AdaBN 算法需要整个测试集的样本在 WDCNN 每一个 BN 层的均值与方差,这对于一个故障诊断系统,在初期是难以满足的。
解决思路:
1)根据部分测试样本的均值方差,对整体测试样本的均值方差进行估计;
2)不获取任何测试集的信息,通过对 WDCNN 模型本身结构与训练方式进行改进,增强其泛化能力。
具体措施:
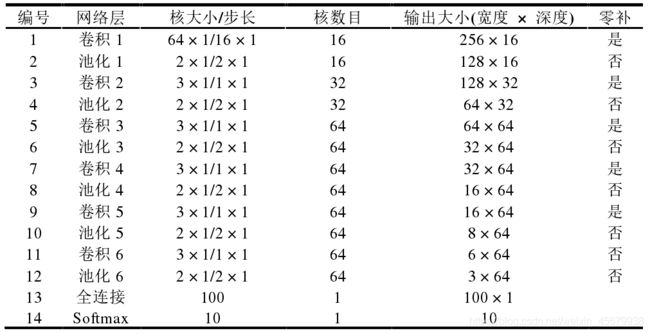
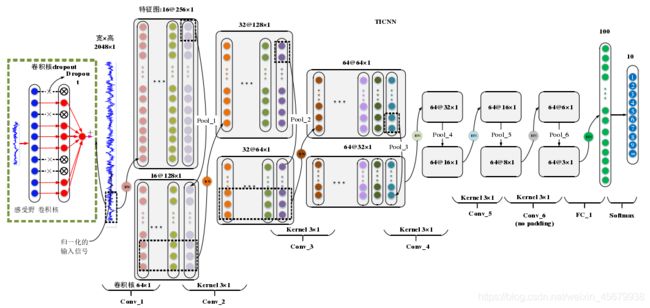
(1)TICNN 模型的结构与 WDCNN 类似,第一层卷积核均为大卷积核,大小为 64×1,之后的卷积核均为 3×1 的小卷积核。两者结构上有两点不同:1)TICNN 模型的第一个卷积层的步长从 16 减少到了 8,这样做增加了 TICNN 模型在时域上的分辨率;2)TICNN 增加了一个卷积层与池化层,这样做可以增强网络的非线性表达能力。具体的模型参数如表 5-1 所示,其中第六个卷积层在卷积时没有采用零补,其余的卷积操作均采用零补。此外,第一个卷积层的输出神经元的个数为 4096,大于原始信号的长度 2048,表明第一个卷积层的特征是原始信号的过完备表达。
(2)在使用第一层大卷积核进行卷积时,先对卷积核进行 Dropout 操作,这是 TICNN 模型的第一个训练干扰,目的是给 TICNN训练时提供不完整的信号,从而强化 TICNN 在信号部分缺失时的诊断能力。
(3)TICNN 使用了极小的mini-batch 来进行批量训练,这是 TICNN 模型的第二个训练干扰,目的是增大 mini-batch 的均值方差变化范围增加,增强模型对测试集的均值方差于训练集发生的偏移时容忍度。
(4)在测试阶段,采用集成学习的方式(Ensemble Learning)来进行预测。文中采用的是多数同意规则(Majority Voting),即独立训练 5 个 TICNN模型,对于同一个测试样本,采用投票的方式来决定信号所属故障。集成学习被用来提高模型的识别率,增强模型的稳定性。
如下图,为TICNN结构参数表:
如下图,为TICNN网络结构:
如下图,为TICNN 模型的训练过程及测试过程流程图:

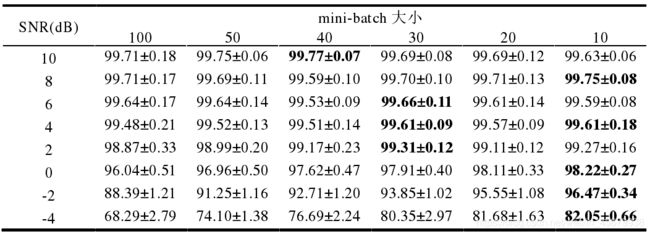
如下图,为不同大小的 minibatch 下,TICNN 对噪声信号的识别率:
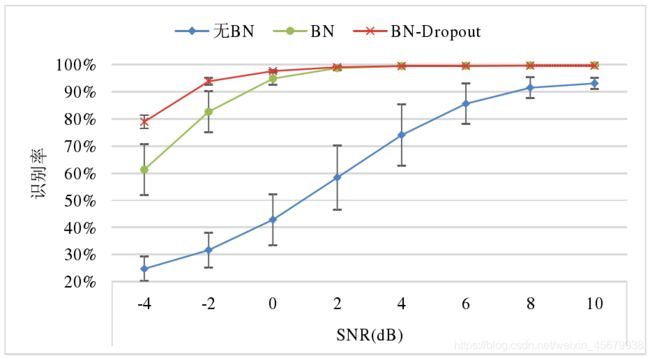
如下图,为TICNN 在三种模式下的识别率:
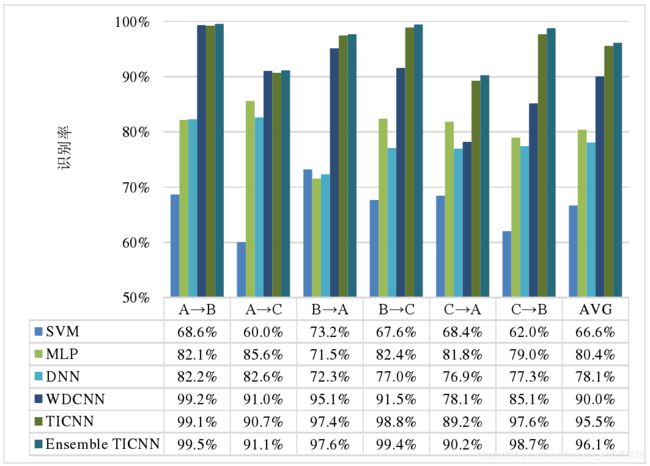
如下图,为集成 TICNN 在三种模式下的识别率:

如下图,为TICNN 在不同噪声环境下与其它算法的识别率对比 :

如下图,为TICNN 算法及对照算法在 6 种不同域自适应场景中的识别率 :