项目--基于http协议的小型web服务器
在我们对网络的学习过程中,会接触到网络编程,我们在网络中可以深刻认识到服务器与客户端的交互,当我们输入网址时背后发生的一系列后端操作,为了加深我们对网络部分的学习,我们找到了一个开源项目TinyWebServer来进行我们的学习,将其用C++部分重新实现,来巩固我们的Linux操作,socket网络编程与http协议的学习 Tinyhttp源码分析
项目名称
基于http协议的小型web服务器
实现了一个小型的web服务器,实现用户的基本网页请求,包括动态网页与静态网页的返回
实现环境
Linux centos 3.10、gcc 4.8.5
技术特点
- 网络编程(http协议,TCP/IP协议,socket流式套接字)
- 多线程技术(线程池)
- CGI技术
功能描述
我们所做的是一个通过http协议限制的tcp通信socket套接字编程来满足服务器与客户端交互的一个程序
我们通过加装http协议使其发送的数据都是http封装的报文,有了http协议我们就可以完成对浏览器请求的解析,并依据请求给出回应,而为了让我们的服务器程序能适应多种编程环境,我们引入了一个cgi模块,得以实现cgi程序与web服务器之间的通信
因为有了cgi技术,我们可以在网页上实现一个简易的计算器程序,当我们用户在页面上进行计算请求时,服务端启用这个计算器程序进行计算,并将结果返回给用户,这就实现了用户与服务器之间的交互,而又因为在我们实际场景中服务器是可能被多个线程同时访问的,所以我们又通过一个线程池来对其池化处理,有效地解决了这个问题
涉及知识
http协议基本内容

http报文request部分

http报文response部分

http状态码及其含义
响应状态码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受 eg:200 OK //客户端请求成功
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
eg:400 Bad Request //客户端请求有语法错误,不能被服务器所理解 ;401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 ;403 Forbidden //服务器收到请求,但是拒绝提供服务 ;404 Not Found //请求资源不存在,eg:输入了错误的URL
5xx:服务器端错误–服务器未能实现合法的请求
eg:500 Internal Server Error //服务器发生不可预期的错误 ;503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
http协议的特点
客户 / 服务器模式 (B/S,C/S)简单快速 ,HTTP 服务器的程序规模小 , 因而通信速度很快。灵活 ,HTTP 允许传输任意类型的数据对象 , 正在传输的类型由 Content-Type 加以标记。无连接 , 每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。(http/1.0 具有的功能, http/1.1 兼容 )无状态
CGI技术
CGI(Common Gateway Interface) 是WWW技术中最重要的技术之一,有着不可替代的重要地位。CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。其实,要真正理解CGI并不简单,首先我们从现象入手 浏览器除了从服务器下获得资源(网页,图片,文字等),有时候还有能上传一些东西(提交表单,注册用户之类的),看看我们目前的http只能进行获得资源,并不能够进行上传资源,所以目前http并不具有交互式。为了让我 们的网站能够实现交互式,我们需要使用CGI完成,时刻记着,我们目前是要写一个http,所以,CGI的所有交互细节,都需要我们来完成。
我们用一张图来说明我们的http cgi
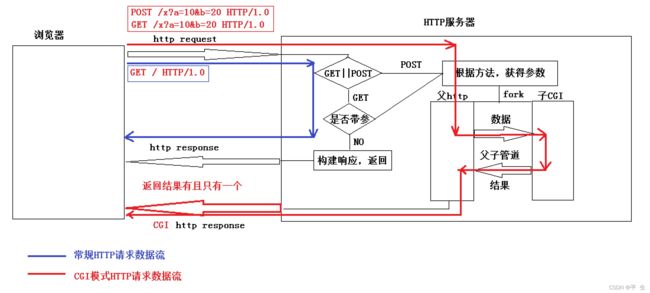
线程池
线程池技术在我们另一个项目已经详细介绍过了,在此项目中我们先一次性创建多个线程,避免了来时再创建的开销,我们使用线程池来对对其进行处理,构建相应返回,并将线程池设置为单例模式,只有一个线程池对象
具体实现
Log.hpp模块
此模块用以实现日志的打印,设立4种级别日志以及枚举4种错误方式,分别对我们可能出现的套接字创建,绑定,监听以及命令行参数出现的错误进行标识
具体实现:
#pragma once
#include
#include
#include
#define Notice 1
#define Warning 2
#define Error 3
#define Fatal 4
//使用枚举的方式在项目中比数字更加直观
enum ERR
{
SocketErr = 1,//套接字错误
BindErr,//绑定错误
ListenErr,//监听错误
ArgErr//命令行参数错误
};
//传入错误级别以及文件
#define LOG(level,message) \
Log(#level,message,__FILE__,__LINE__)//#传入宏参(单#转化为字符串),FILE获取文件名(预定义符号),LINE获取行号
//日志:[日志级别][message][时间戳][filename][line]
void Log(std::string level, std::string message, std::string filename, size_t line)//
{
struct timeval curr;//创建时间结构体用于获取时间戳
gettimeofday(&curr, nullptr);//获取时间戳
std::cout << "[" << level << "]" << "[" << message << "]" << "[" << curr.tv_sec << "]" << "[" << filename << "]" << "[" << line << "]" << std::endl;
} Sock.hpp模块
此模块用以实现对网络接口的处理
Sock():套接字的创建
bind():绑定端口与ip
listen():设置监听位accept做准备
accept():链接
Getline():按行读取报文接口,这个接口主要用于下面分隔http协议的request与
#pragma once
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include"Log.hpp"
#define BACKLOG 5
class Sock
{
public:
static int Socket()
{
int sock = socket(AF_INET, SOCK_STREAM, 0);//创建网络相关的资源与文件,(设置ipv4协议,tcp面向字节流,默认0)
//原先我们都是直接把错误打印出来,但现在改为日志的形式
if (sock < 0){
LOG(Fatal, "socket create error");//日志输出
exit(SocketErr);
}
return sock;//返回网络创建的文件描述符
}
static void Bind(int sock, int port)//绑定端口号与ip
{
struct sockaddr_in local;//提出addr结构体
bzero(&local, sizeof(local));
local.sin_family = AF_INET;//设置结构体位ipv4
local.sin_port = htons(port);//端口号,字节序转网络字节序
local.sin_addr.s_addr = htonl(INADDR_ANY);//绑定0用以接收服务器所有ip收到的地址
if (bind(sock, (struct sockaddr*)&local, sizeof(local)) < 0){//进行绑定
LOG(Fatal, "socket bind error");
exit(BindErr);
}
}
static void Listen(int sock)//设置监听,准备accept
{
if (listen(sock, BACKLOG) < 0){//监听失败,打印日志
LOG(Fatal, "socket listen error");
exit(ListenErr);
}
}
static void SetSockOpt(int sock)//设置端口被释放后立即就可以使用
{
int opt = 1;
setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));//设置层级管理权限,套接字,支持层次,设置选项(允许套接口与一个已在使用的地址捆绑),存放选项值的缓冲区,缓冲区长度
}
static int Accept(int sock)//阻塞等到客户端连接,接受链接
{
struct sockaddr_in peer;//设置请求链接的结构体
socklen_t len = sizeof(peer);//计算大小
int s = accept(sock, (struct sockaddr*)&peer, &len);//连接套接字,请求链接的ip与端口号,addr大小
//别人连接我的信息都放在了peer里面,可以都写到日志里面
if (s < 0){
LOG(Warning, "accept error");
//再次申明一次,这里就相当于我们去引流,如果没有引到,会接着去引,所以说即使错误了也不要紧,不能直接exit
}
return s;//不断链接,直到链接到
}
//作用:整体读取一行内容
static void GetLine(int sock, std::string& line)
{
//换行符是没有硬性规定的,有些平台下有可能是\r \n \r\n 这三种都有可能是换行符标志
//最好的方式是按字符读取
char c = 'X';
while (c != '\n'){
ssize_t s = recv(sock, &c, 1, 0);//接收数据赋给s,数据端套接字,数据缓存区,缓存区大小,连接方式默认0
if (s > 0){
//可以考虑在往后读一个,判断一下是否下一个是\n,如果是那还好,如果不是就读上来一个正常字符,此时你再把这个字符需要放回内核缓冲区是很难做到的
//所以这里需要重新的认识一个这个recv函数的扩展MSG_PEEK(数据的窥探功能)就是只看一下,但是并不从内核缓冲区拷贝到用户缓冲区
if (c == '\r'){
ssize_t ss = recv(sock, &c, 1, MSG_PEEK);
if (ss > 0 && c == '\n'){
//说明我们的换行符是\r\n
recv(sock, &c, 1, 0);//因为窥探并没有把数据读走
}
else{
// \r
c = '\n';
}
}
//1.读取到的内容是常规字符
//2.\n
//此时将\r \r\n -> 为了\n
//因为这个读上来的\n在显示的时候会造成不美观
if (c != '\n'){
line.push_back(c);
}
}
}
}
};
HttpServer.hpp模块
该模块负责将服务器启动起来,是web服务器的起点
InitServer():初始化网络服务器,建立网络连接
Start():开启服务,接收客户端请求
GetInstance():加锁饿汉模式保证线程安全
#pragma once
#include
#include "Sock.hpp"
#include "Protocol.hpp"
#include "ThreadPool.hpp"
#define PORT 8081//端口号8081
class HttpServer{
private:
int port;//端口号
int lsock;//ip
ThreadPool *tp;//线程对象
static HttpServer *http_svr;//创建一个http服务
static pthread_mutex_t lock;//锁
//HttpServer()
//{}
public:
HttpServer(int _p = PORT)
:port(_p), lsock(-1), tp(nullptr)
{}
static HttpServer *GetInstance(int sk)//设置饿汉单例,需要使用时进行加锁实例化
{
if (nullptr == http_svr){
pthread_mutex_lock(&lock);
if (nullptr == http_svr){
http_svr = new HttpServer(sk);//实例化
}
pthread_mutex_unlock(&lock);
}
return http_svr;
}
void InitServer()//初始化网络服务
{
signal(SIGPIPE, SIG_IGN);//屏蔽SIGPIPE信号,该信号会默认结束进程,告诉客户端不进行关闭
//建立网络一系列操作
lsock = Sock::Socket();
Sock::SetSockOpt(lsock);
Sock::Bind(lsock, port);
Sock::Listen(lsock);
tp = new ThreadPool();//将该网络服务分配给一个线程
tp->InitThreadPool();
}
void Start()//开启服务
{
for (;;){
int sock = Sock::Accept(lsock);//链接客户端
if (sock < 0){//无连接跳过
continue;
}
LOG(Notice, "get a new link ...");
Task *tk = new Task(sock);//分配线程池处理
tp->PushTask(tk);
//多线程方案
//在堆上申请空间,保存sock。
//直接传入sock地址,当来了其它连接,会修改sock值
//int *sockp = new int(sock);
//处理协议后需要通过套接字接送数据和发送数据,所以用套接字做参数
//pthread_t tid;
//pthread_create(&tid, nullptr, Entry::handlerhttp, (void *)sockp);
//线程分离,自动回收,避免等待
//pthread_detach(tid);
}
}
~HttpServer()//析构服务器
{
if (lsock >= 0){//关闭客户端
close(lsock);
}
}
};
HttpServer *HttpServer::http_svr = nullptr;//初始化服务器
pthread_mutex_t HttpServer::lock = PTHREAD_MUTEX_INITIALIZER;//锁静态初始化
Util.hpp工具类
该模块主要是封装一些通用API,为其它模块提供服务
StringParse():分割请求行
MakeStringToKV():分割报头
StringToInt():字符串转整型,其实也相当于stii()
#pragma once
#include"Sock.hpp"
#include"Log.hpp"
//打过来的请求都是一行一行的,为了方便分析,我也想要以行的方式读取上来
//需要按行读取的功能
class Util
{
public:
//字符串拆分,也就是1变多
static void StringParse(std::string& request_line, std::string& method, std::string& uri, std::string& version)//将我们的一行请求行数据拆分成请求方法,url以及协议版本
{
//这是最简单的方法来进行字符串解析
std::stringstream ss(request_line);
ss >> method >> uri >> version;
}
//容器内的东西是坚决不能修改的,所以最好传参的时候不要传引用
static void MakeStringToKV(std::string line, std::string& k, std::string& v)//此方法处理的是请求报头,将请求报头的每一行都以kv的形式分隔存储k:报头;v:内容
{
std::size_t pos = line.find(": ");//pos的指针应该在冒号的位置
if (pos != std::string::npos){
//做一下判断,确定找到了
//第一个参数是:从哪里开始,第二个参数是长度
k = line.substr(0, pos);
v = line.substr(pos + 2);
}
}
static ssize_t StringToInt(const std::string& v)//字符串转整型
{
// return stoi(v);
//stringstream 也可以转换成整数
std::stringstream ss(v);
ssize_t i = 0;
ss >> i;
return i;
}
};
ThreadPool.hpp模块
该模块就是搭建了一个线程池,将我们并发的多个网络请求分配到线程池中的各个线程中去,也是一个经典的生产者消费者模型
#pragma once
#include
#include
#include
#include"Protocol.hpp"
typedef void(*handler_t)(int);
class Task//任务队列
{
private:
int sock;//套接字
handler_t handler;
public:
Task(int sk) :sock(sk), handler(Entry::HandlerHttp)//传入套接字与报头
{}
void Run()
{
handler(sock);
}
~Task()
{}
};
class ThreadPool
{
private:
std::queue q;//任务队列
int num;//线程数
pthread_mutex_t lock;//互斥锁
pthread_cond_t cond;//条件变量
public:
void LockQueue()//加锁
{
pthread_mutex_lock(&lock);
}
void UnlockQueue()//解锁
{
pthread_mutex_unlock(&lock);
}
bool IsEmpty()//判空
{
return q.size() == 0;
}
void ThreadWait()//线程等待
{
pthread_cond_wait(&cond, &lock);//在cond变量下等,并释放锁
}
void ThreadWakeup()//唤醒所有等的线程
{
pthread_cond_signal(&cond);
}
public:
ThreadPool(int n = 8) :num(n)//初始化8个线程
{}
static void *Routine(void *args)
{
//static是静态成员函数,不能够去访问非静态的成员函数,但是我现在要使用你ThreadPool里面queue,可以通过对象的方式来
ThreadPool *this_p = (ThreadPool*)args;//拿到线程池
this_p->LockQueue();
while (this_p->IsEmpty()){//检测是否有任务
this_p->ThreadWait();
}
Task *tk = this_p->PopTask();//分配线程
this_p->UnlockQueue();
tk->Run();//让该线程处理请求
delete tk;
}
void InitThreadPool()
{
pthread_mutex_init(&lock, nullptr);
pthread_cond_init(&cond, nullptr);
pthread_t tid[num];
for (int i = 0; i < num; i++){//创建数量为num的线程
pthread_create(tid + i, nullptr, Routine, this);
pthread_detach(tid[i]);//县城分离
}
}
void PushTask(Task *tk)//将任务入队
{
LockQueue();
q.push(tk);
UnlockQueue();
ThreadWakeup();
}
Task* PopTask()
{
Task *tk = q.front();
q.pop();
return tk;
}
~ThreadPool()
{
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&cond);
}
};
Protocol.hpp
这是我们最重要的一个模块,主要负责协议的处理部分,包括获取请求,制作响应,发送响应而等
篇幅较长,我们再将其细分
首先是通用模块,这里解决了响应种类的问题以及提取文件类别的问题
#pragma once
#include"Sock.hpp"
#include"Log.hpp"
#include"Util.hpp"
//对于一个服务器来说,应该是从webroot下去拿资源
#define WEBROOT "webroot"
#define HOMEPAGE "index.html"
#define VERSION "HTTP/1.0"//为了兼容性考虑我们使用http/1.0
//不想要被外面人访问到,因为这个函数只和本文件强相关
static std::string CodeToDesc(int code)
{
std::string desc;
//写成这种形式是代码的维护性将极高,如果来了新的错误,直接加一个case即可
switch (code){
case 200:
desc = "OK";
break;
case 404:
desc = "Not Found";
break;
case 401:
desc = "Unauthorized";
break;
case 403:
desc = "Forbidden";
break;
case 400:
desc = "Bad Request";
break;
case 500:
desc = "Internal Server Error";
break;
case 503:
desc = "Server Unavailable";
break;
default:
break;
}
return desc;
}
static std::string SuffixToDesc(const std::string& suffix)//传入文件结尾,返回相应的文件类别
{
if (suffix == ".html" || suffix == ".htm"){
return "text/html";
}
else if (suffix == ".js"){
return "application/x-javascript";
}
else if (suffix == ".css"){
return "text/css";
}
else if (suffix == ".jpg"){
return "image/jpeg";
}
else{
return "text/html";
}
}class HttpRequest类
该类主要是为了处理接收的请求文本,我们再来回顾一下http协议的格式内容,存在请求行,请求报头,以及空行后的请求正文

以及我们的url详细解析
该类中详细处理了收到的http协议request部分,包括请求行拆分解析为请求方法,并做相应的处理,url,将url详细拆分,以及版本号
//用来专门分析过来的Request
//请求行、请求报头、空行、正文
class HttpRequest//处理接收的请求文本
{
private:
std::string request_line;//请求行
std::vector request_header;//请求报头
std::string blank;//空行
std::string request_body;//正文
private:
std::string method;//请求方法
std::string uri;//url
std::string version;//协议版本
//这两个是通过分析uri来拿到Path和参数
std::string path;
std::string query_string;
std::unordered_map header_kv;//对应报头的kv结构
ssize_t content_length; //为了区分开给三个默认为-1表示不存在 0表示没有 >0表示有正文
bool cgi;//是否开启cgi模式的标志位
ssize_t file_size; //供后续使用的,不然会显得代码很冗余再调用一次stat
std::string suffix;//提取文件后缀
public:
HttpRequest() :blank("\n"), content_length(-1), path(WEBROOT), cgi(false), suffix("text/html")//默认不开启cgi,为get方法,默认文件为html格式,初始化请求request
{}
void SetRequest(std::string& line)//设置空行
{
request_line = line;
}
//解析请求行
//也就是把request_line打散成为三个字符串分别为method uri version
//所以此时就需要一个这个功能,可以写在Util这个工具类里面
void RequestLineParse()
{
Util::StringParse(request_line, method, uri, version);//调用之前的字符串分割函数,将请求行分为三部分
//LOG(Notice,request_line);
//LOG(Notice,method);
//LOG(Notice,uri);
//LOG(Notice,version);
}
void InsertHeaderLine(const std::string& line)//插入请求行
{
request_header.push_back(line);
LOG(Notice, "line");
}
void RequestHeaderParse()//拆分报头
{
//我们更想用一个Key值直接找到它的Value值,所以可以对一行报头拆分搞个map
//说简单点就是:把vector遍历一遍,然后把里面的每个字符串拆分成KV
for (auto& e : request_header){
//再把每个字符串拆成map的KV结构
std::string k, v;
Util::MakeStringToKV(e, k, v);//将e分为kv两部分,分别为类别以及对应的参数
LOG(Notice, k);
LOG(Notice, v);
if (k == "Content-Length"){
content_length = Util::StringToInt(v);//设置content_length字段,设置为正文字符数
}
header_kv.insert({ k, v });//插入报头
}
}
//1.请求方法必须得是post
//2.Content-length必须不是0
bool IsNeedRecvBody()//处理post方法
{
//Post PoSt POST 所以还需要做字母大小写同一
//这里就是用了一个C语言的接口strcasecmp()可以忽略大小写问题比较字符串
if (strcasecmp(method.c_str(), "POST") == 0 && content_length > 0){//解析请求方法,若为post则开启cgi进行参数传递,从客户端发送给服务器
cgi = true;
return true;
}
return false;
}
ssize_t GetContentLength()//获取正文长度
{
return content_length;
}
void SetRequestBody(const std::string& body)//设置请求正文
{
request_body = body;
}
bool IsMethodLegal()//判断请求方法是否合法
{
if (strcasecmp(method.c_str(), "POST") == 0 || strcasecmp(method.c_str(), "GET") == 0){
return true;
}
return false;
}
bool IsGet()//判断方法是否为get
{
return strcasecmp(method.c_str(), "GET") == 0 ? true : false;
}
bool IsPost()//判断是否为post方法
{
return strcasecmp(method.c_str(), "POST") == 0 ? true : false;
}
void UriParse()//解析url
{
std::size_t pos = uri.find('?');//get方法中参数在?后,寻找?分隔符,参数和路径的分隔符是"?",
//这个"?"是唯一的,如果查询"?"会被urlencode转化。如果不存在"?"说明没有参数。存在"?"在url中找到"?"前面为路径,后面为参数
if (pos == std::string::npos){
//说明没有找到'?',直接加上后面字符
path += uri;
}
else{
//说明找到了'?'
path += uri.substr(0, pos);//分割url,前面为路径
query_string = uri.substr(pos + 1);//后面为请求方法
cgi = true;//需要cgi处理
}
}
void SetUriEqPath()//设置绝对路径
{
path += uri;
}
std::string GetPath()//获取路径
{
return path;
}
void IsAddHomePage()//添加文件路径
{
if (path[path.size() - 1] == '/'){
path += HOMEPAGE;
}
}
std::string SetPath(std::string _path)
{
return path = _path;
}
void SetCgi()
{
cgi = true;
}
bool IsCgi()
{
return cgi;
}
void SetFileSize(ssize_t s)//设置文件大小
{
file_size = s;
}
ssize_t GetFileSize()//获取文件大小
{
return file_size;
}
std::string GetQueryString()//获取url中的参数
{
return query_string;
}
std::string GetBody()//获取请求正文
{
return request_body;
}
std::string GetMethod()//获取方法
{
return method;
}
std::string MakeSuffix()//获取文件类别
{
std::string suffix;
size_t pos = path.rfind(".");//找到.后的部分进行判断
if (std::string::npos != pos){
suffix = path.substr(pos);
}
return suffix;
}
~HttpRequest()
{}
}; class HttpResponce类
该类相对于请求request就简单多了,只是分拆我们的响应报文
//用来专门分析过来的Response
//状态行、响应报头、空行、响应正文
//可以理解为定义了一套标准
class HttpResponse
{
private:
std::string status_line;//响应行
std::vector response_header;//响应报头
std::string blank;
std::string response_body;//相应正文
public:
HttpResponse() :blank("\r\n")//初始化为空行
{}
//版本号 状态码 状态码描述
void SetStatusLine(const std::string& line)//设置响应行
{
status_line = line;
}
std::string GetStatusLine()//提取响应行
{
return status_line;
}
const std::vector& GetRspHeader()//设置响应报头
{
response_header.push_back("\n");
return response_header;
}
void AddHeader(const std::string& ct)//添加报头
{
response_header.push_back(ct);
}
~HttpResponse()
{}
}; 接下来就是我们的的处理模块,将sock获取的请求与响应分别进行解析,制作响应报头返回,而后在构建响应正文的时候分为,不使用cgi技术处理GET无参,POST无参,普通网页文件直接发送的情况,使用CGI技术处理POST有参的情况,使用进程替换将数据与代码替换到cgi程序中,而后通过管道重定向到标准输入的方式,将POST的参数传递给进程,而GET方法请求方式与正文大小则直接通过环境变量传递,而后将处理结果以标准输出重定向到管道的方式传递给父进程,完成子进程的处理,最后将服务器守护进程化
//通过sock来获取过来的Request和Response,然后在交给对应的两个类里面的具体方法进行拆解分析
class EndPoint
{
private:
int sock;
HttpRequest req;
HttpResponse rsp;
private:
void GetRequestLine()//获取请求行并进行分析
{
std::string line;
Sock::GetLine(sock, line);
//读上来的这一行我们要拿去给HttpRequest进行分析
req.SetRequest(line);
//设置进去了之后,最主要的是能够分析出来他所使用请求方法、URL、版本号
req.RequestLineParse();
}
void SetResponseStatusLine(int code)//设置响应行
{
std::string status_line;
status_line = VERSION;//首先加入版本
status_line += " ";
status_line += std::to_string(code);//加入上面公共方法的状态码
status_line += " ";
status_line += CodeToDesc(code);//通过状态码转换为所对应的描述
status_line += "\r\n";//对于我们自己写的我们就设置为以\r\n为结束
rsp.SetStatusLine(status_line);//设置进我们的响应报文中
}
void GetRequestHeader()//获取请求报头
{
//报头就是不断的循环读,一直读取到"\n"停止
std::string line;
do{//至少读一次为空
line = "";
Sock::GetLine(sock, line);
req.InsertHeaderLine(line);
} while (!line.empty());
//上面是获得了报头,此时在对报头进行一下分析
req.RequestHeaderParse();//设置进响应报文
}
void SetResponseHeaderLine()//获取响应报头
{
//图片、网页类型不同表示Content-type不同
std::string suffix = req.MakeSuffix();
std::string content_type = "Content-Type: ";
content_type += SuffixToDesc(suffix);
content_type += "\r\n";
rsp.AddHeader(content_type);
}
void GetRequestBody()//获取请求正文
{
int len = req.GetContentLength();
char c;
std::string body;
while (len != 0){//读上面length模块所显示的字符数
ssize_t s = recv(sock, &c, 1, 0);
body.push_back(c);
len--;
}
req.SetRequestBody(body);//设置进请求报文中
}
public:
EndPoint(int _sock) :sock(_sock)
{}
void RecvRequest()
{
//整体思路:
//获取完整http请求
//分析http请求
//读取并分析完了
GetRequestLine();
//读取报头
GetRequestHeader();
//好好分析Sock::GetLine你就会发现,在上面读取报头的时候,你已经把空行信息也读完了
//读取正文(但是是否有正文呢?所以1.要看请求方法--Post 2.要看Content-length,但是这个参数是要经常判断是否大于0的,所以可以把它直接算出来content-length成员变量)
if (req.IsNeedRecvBody())
{
//说明有正文,那就读
GetRequestBody();//这个接口不但把正文都读取上来了,而且还设置进了我所定制的协议里面
}
//已经读完了所有的请求
}
void MakeResponse()//制作响应报文
{
//开始分析
//只想要处理GET和POST方法
int code = 200;//当状态码为200时正常
std::string path; //在goto 和 end之间最好不要定义变量,因为跳转的时候有可能会导致一些变量的定义丢失
if (!req.IsMethodLegal()){
//说明不是POST或者GET方法
LOG(Warning, "method is not legal");
code = 404;
goto end;
}
//说明此时方法是没有问题的,那么就该看是POST还是GET方法了,得到方法就知道是通过正文传参还是uri进行传参了
//其中url也分为两种一种是不带?(比如说请求首页),一种是带问好的,也就是有参数的
//不管咋分析uri,首先你得是GET方法
if (req.IsGet()){
req.UriParse();
}
else{
//此时就是POST方法
req.SetUriEqPath();
}
req.IsAddHomePage();//因为直接用ip+port访问服务器应该让他的默认路径为首页路径
// get && 没有参数 ->path 对应着你把资源从服务器上拿下来
// 下面两种方式对应着你向服务器要资源,所以才需要参数
// get && 有参数 ->path + query_string
// post 路径在uri中,参数在body中
//所以此时就应该检测对应的path是否在系统内合法 /a/b/c
//此时可以使用一个系统接口stat(),成功返回0,失败返回-1
path = req.GetPath();
LOG(Notice, path);
struct stat st;
if (stat(path.c_str(), &st) < 0){
LOG(Warning, "html is not exist! 404");
code = 404;
goto end;
}
else{
//说明文件路径合法
//结尾没有带'/'但是最后一个是一个目录
//但是此时有可能访问的是目录,也有可能是一个普通的html,对于webroot下的任何目录都有一个index.html
if (S_ISDIR(st.st_mode)){
//这里应该在给他拼接index.html
path += "/";
req.SetPath(path);
req.IsAddHomePage();
}
else{
//这里又分为了2种可能,可能请求的是一个可执行程序(二进制)或者html,
//如果是可执行程序是由权限属性的
if ((st.st_mode & S_IXUSR) || \
(st.st_mode & S_IXGRP) || \
(st.st_mode & S_IXOTH)){
//CGI(就是让服务器帮你把程序跑完,然后给你返回结果的技术)
req.SetCgi();
}
else{
//这里说明是一个正常的网页请求
}
}
if (!req.IsCgi()){
req.SetFileSize(st.st_size);//设置对应的文件大小
}
}
end:
//制作response
//设置状态行
SetResponseStatusLine(code);
SetResponseHeaderLine();
//设置响应报头
//SetResponseHeader();
}
//要做的基本工作就是打开文件,再把文件里面的内容通过sock发回去
void ExecNonCgi(const std::string& path)//不使用cgi的方法
{
ssize_t s = req.GetFileSize();
int fd = open(path.c_str(), O_RDONLY);
if (fd < 0){
LOG(Error, "path is not exists bug!!!");
return;
}
//ssize_t sendfile(int out_fd,int in_fd, off_t *offset,size_t count);
//在这里面in_fd should be file descriptor opend for reading
//out_fd writing
//offset 偏移量 count
//这也是系统调用接口
sendfile(sock, fd, nullptr, s);
close(fd);
}
void ExecCgi()//使用cgi方法
{
//这里想要使GET的CGI处理和POST的CGI处理方式有所不同
//std::string arg;
//if(req.IsGet()){
//把参数拿上来
//arg = req.GetQueryString();
//}
//else{
//arg = req.GetBody();
//}
//如果是cgi模式就是想要让服务器去创建一个子进程,然后子进程去处理参数,然后把结果在交给父进程,父进程在返回
std::string content_length_env;
std::string path = req.GetPath();
std::string method = req.GetMethod();
//可能回想为什么要这样做呢?难道全部都是用管道直接把数据都发过去不好吗? 事实上这里也就是想要严格的遵守CGI的标准,对于url有参数的就是要环境变量传参
//对于想POST方法的,可能body十分的长,所以选择使用管道来传
std::string method_env = "METHOD=";
method_env += method; //环境变量是全局变量,子进程也是可以获得到的
std::string query_string;
std::string query_string_env;
std::string body;
//进程间通信使用管道,但是管道是单向的,所以要出创建两个 1个是父进程给子进程数据 一个是子进程给父进程返回结果
int pipe_in[2] = { 0 };
int pipe_out[2] = { 0 };
//站在被调用进程的角度
//pipe[0]是读端 pipe[1]是写端
pipe(pipe_in);
pipe(pipe_out);
putenv((char*)method_env.c_str());
pid_t id = fork();
if (id == 0){
//子进程
//但是此时数据是父进程拿着呢,但是要交给子进程去处理,所以这里还涉及到一个进程间通信的问题
close(pipe_in[1]); //父进程来写数据进管道,子进程来读
close(pipe_out[0]);//父进程来读结果,子进程来写
dup2(pipe_in[0], 0);
dup2(pipe_out[1], 1);
//第一种是通过环境变量传参给子进程 GET -> query_string
if (req.IsGet()){
query_string = req.GetQueryString();
query_string_env = "QUERY_STRING=";
query_string_env += query_string;
putenv((char*)query_string_env.c_str());
}
else if (req.IsPost()){
content_length_env = "CONTENT-LENGTH=";
content_length_env += std::to_string(req.GetContentLength());
putenv((char*)content_length_env.c_str());
}
execl(path.c_str(), path.c_str(), nullptr); //你要执行的程序的路径和文件名
exit(0);
}
//father
close(pipe_in[0]);
close(pipe_out[1]);
char c = 'X';
//第二种通过管道传参给子进程 POST -> body
if (req.IsPost()){//post方法
body = req.GetBody();
int size = body.size();
int i = 0;
for (; i< size; i++){
write(pipe_in[1], &body[i], 1);//使用写端将请求报文的数据挨个写入父进程
}
}
//让子进程去拿着参数去帮你执行完毕以后,对于父进程还需要拿到子进程返回回来的结果
ssize_t s = 0;
do{
s = read(pipe_out[0], &c, 1);//父进程读取管道获取结过
if (s > 0){
send(sock, &c, 1, 0);
}
} while (s > 0);
waitpid(id, nullptr, 0);//阻塞进程
}
void SendResponse()//发送响应报文
{
//先把状态行给发出去
std::string line = rsp.GetStatusLine();
send(sock, line.c_str(), line.size(), 0);
//再把响应报头发出去
for (auto& e : rsp.GetRspHeader()){
send(sock, e.c_str(), e.size(), 0);
}
//发送空行,但是这个逻辑不好,其实可以把这个行上面的报头结合到一块,这样上面其实连我们的空行也已经发过去了
//所以此时就剩下发送response_body
//但是此时应该判断执行模式,有可能你只是想要一个普通的html,还有可能是给我传过参数
//1. GET方法uri里面有参数
//2.POST方法 有正文
//3 分析出来的路径最终访问的是一个可执行程序都要使用cgi技术
if (req.IsCgi()){
//yes -> cgi
LOG(Notice, "use cgi model!");
ExecCgi();
}
else{
LOG(Notice, "use no cgi model!");
//请求的就是一个普通的html
std::string path = req.GetPath();
ExecNonCgi(path);//以非cgi的形式运行
}
}
//是基于短链接的,完成一次请求和响应就应该把链接进行关闭
~EndPoint()
{
if (sock >= 0){
close(sock);
}
}
};
class Entry
{
public:
static void HandlerHttp(int sock)//将其设置为单例
{
//int sock = *(int*)arg;//就是把堆空间上的arg拷贝到了私有栈里面
//delete (int*)arg;//再把堆空间保存的sock进行释放
#ifdef DEBUG//条件编译
char request[10240];
recv(sock, request, sizeof(request), 0);
close(sock);
#else
EndPoint *ep = new EndPoint(sock);
ep->RecvRequest();
ep->MakeResponse(); //这里只研究两种方法:是GET和POST 对于其他的方法如果来了,直接构建response返回回去
ep->SendResponse();
delete ep;
#endif
}
};这就是我们这个小型web服务器的主要模块
我们再来梳理一下实现细节
项目主要包括
HttpServer.hpp:web服务器的起点
ThreadPool.hpp:多线程部分
Sock.hpp:关于网络套接字部分
Protocol.hpp:关于协议处理部分,获得请求,分析请求,制作响应,发送响应。
Util.hpp:与协议无关的处理,比如:字符串转整形
Log.hpp:日志
套接字部分
可以从网络中获得请求。
建立套接字,设置端口复用(setsockopt),绑定套接字(端口号和IP地址),监听套接字(listen),等待连接请求的到来
线程池部分
一次性创建多个线程,避免来一个请求再创建一个线程的开销。使用线程池中的线程来处理请求,构建响应返回,并且将线程池设成单例模式(懒汉模式),只有一个线程池对象。
注意:线程处理的任务时一个个请求。
协议处理
获得请求并细分:
根据HTTP协议请求包括四个部分请求行,请求报头,空行,请求正文。其中请求行包括请求方法,url,协议版本。请求报头是一些属性信息,以KV形式呈现。报头和正文以空行分隔。
收到请求,需要将其拆分成4个部分,请求行,请求报头,空行,请求正文。每个部分还需要细分。由于协议是以行为单位,所以按行读取,由于不同客户端制作的协议行分隔符可能不同(\r,\n,\r\n)。所以按字符读取,我们获取后 统一以\n结尾。
请求行:
读取一行,将请求行细分为请求方法,url,协议版本。以空格分隔。
请求报头:
循环按行读取,读取到空行结束。保存在map中,方便查找。
空行:
在读取报头时可以一起读上来。
请求正文:
GET方法没有正文,不需要读取正文。
POST方法,如果在报头中有一个属性Content_length表示正文字节数。如果大于0,需要读取正文,按字符读取,读取content_length个字符。
分析请求
主要处理GET和POST方法,其它方法直接构建响应返回,状态码为404。
分析请求主要是获得请求资源的路径和参数。请求资源的路径在url中。注意:在web的目录中都会有一个text.html文件。
请求的资源从web根目录开始。GET和POST方式传参方式不同,GET方法参数在url中,POST在正文中
如果是GET方法:
参数和路径的分隔符是"?",这个"?"是唯一的,如果查询"?"会被urlencode转化。如果不存在"?"说明没有参数。存在"?"在url中找到"?"前面为路径,后面为参数。
如果是POST方法:
路径直接是url,有请求正文的话,参数是请求正文。
其中GET有参数,POST有参数需要使用CGI技术来处理参数。
判断请求资源:
请求资源不存在,直接构建响应返回,状态码为404。
如果是一个目录,说明访问下的该目录下的text.html文件。
如果是可执行程序,需要使用cgi技术处理。
如果是一个普通网页文件,说明直接就是访问该文件内容
构建响应返回
以行为单位。根据HTTP协议响应包括四个部分状态行,响应报头,空行,响应正文。其中状态行包括协议版本,状态码,状态码描述。响应报头是一些属性信息,以KV形式呈现。报头和正文以空行分隔。
构建响应行:
直接构建,需要通过不同状态码,对应不同描述。发送响应行。构建协议版本,状态码(可以响应的为200,不可以响应的404),状态码描述。最后以/r/n结尾。构建响应报头:
需要添加一些属性content_type等。发送响应报头。构建空行:
发送空行构建响应正文:发送响应正文。构建响应正文需要区分是否使用CGI技术。
1.不需要用到CGI技术:GET无参,POST无参,普通网页文件,直接打开文件,将文件内容发送过去。
2.使用CGI技术:
创建子进程,使用进程替换,替换到CGI程序。替换进程主要替换子进程的数据和代码。通过环境变量和进程间通信技术来传数据。
参数传递:参数POST方式参数用管道发送给替换进程,替换进程不知道管道文件描述符,需要将管道重定向到标准输入。替换进程从标准输入那参数。GET方式,通过环境变量发送给替换进程。请求方式通过环境变量发送给替换进程(通过请求方式来确定从哪里获取参数),正文大小通过环境变量发送给替换进程(POST需要读取正文)。
结果传递:替换进程不清楚管道文件描述符,重定向管道到标准输出,将处理的结果从标准输出传递给父进程。
web服务器将处理的结果发送到网络中。
参考资料:
-
开源Tinyhttp原码链接: link.
-
CGI获取POST方法和GET方法传参详解链接: link.
-
管道链接: link.
-
单例模式链接: link.
-
线程池链接: link.
-
守护进程链接: link.