你管这叫操作系统源码(六)
你管这叫操作系统源码之六
- 进程调度初始化shed_init
- 缓冲区初始化buffer_init
- 硬盘初始化
进程调度初始化shed_init
void main(void) {
...
mem_init(main_memory_start,memory_end);
trap_init();
blk_dev_init();
chr_dev_init();
tty_init();
time_init();
sched_init();
buffer_init(buffer_memory_end);
hd_init();
floppy_init();
sti();
move_to_user_mode();
if (!fork()) {init();}
for(;;) pause();
}
sched_init()方法是多进程的基石!它只是进程调度的初始化,也就是为进程调度所需要用到的数据结构做个准备,真正的进程调度还需要调度算法、时钟中断等机制的配合。我们进入这个方法一点点往后看:
void sched_init(void) {
set_tss_desc(gdt+4, &(init_task.task.tss));
set_ldt_desc(gdt+5, &(init_task.task.ldt));
...
}
两行代码初始化了下 TSS 和 LDT。先别急问这俩结构是啥。还记得之前讲的全局描述符表 gdt 么?它在内存的这个位置,并且被设置成了这个样子:
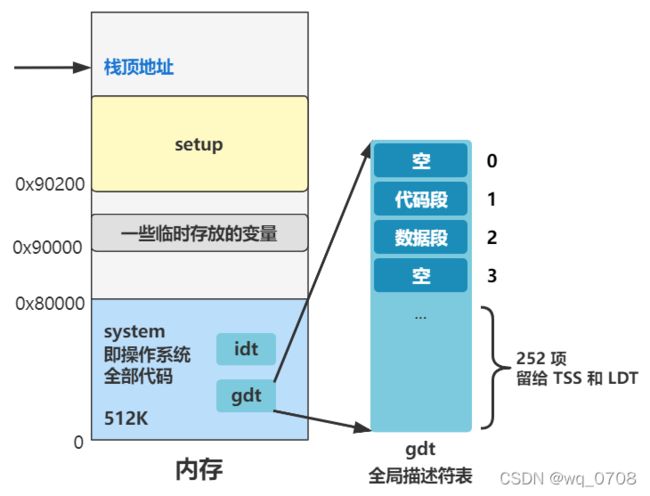
忘了的看一下系列之三里的重新设置idt和gdt,这就说明之前看似没用的细节有多重要了,大家一定要有耐心。
这两行代码其实就是往后又加了两项,分别是TSS和LDT

好,那再说说这俩结构是干嘛的,不过本篇先简单理解,后面会详细讲到。
TSS 叫任务状态段,就是保存和恢复进程的上下文的,所谓上下文,其实就是各个寄存器的信息而已,这样进程切换的时候,才能做到保存和恢复上下文,继续执行。
由它的数据结构你应该可以看出点意思:
struct tss_struct{
long back_link;
long esp0;
long ss0;
long esp1;
long ss1;
long esp2;
long ss2;
long cr3;
long eip;
long eflags;
long eax, ecx, edx, ebx;
long esp;
long ebp;
long esi;
long edi;
long es;
long cs;
long ss;
long ds;
long fs;
long gs;
long ldt;
long trace_bitmap;
struct i387_struct i387;
};
而 LDT 叫局部描述符表,是与 GDT 全局描述符表相对应的,内核态的代码用 GDT 里的数据段和代码段,而用户进程的代码用每个用户进程自己的 LDT 里的数据段和代码段。先不管它,我这里放一张超纲的图,你先找找感觉:
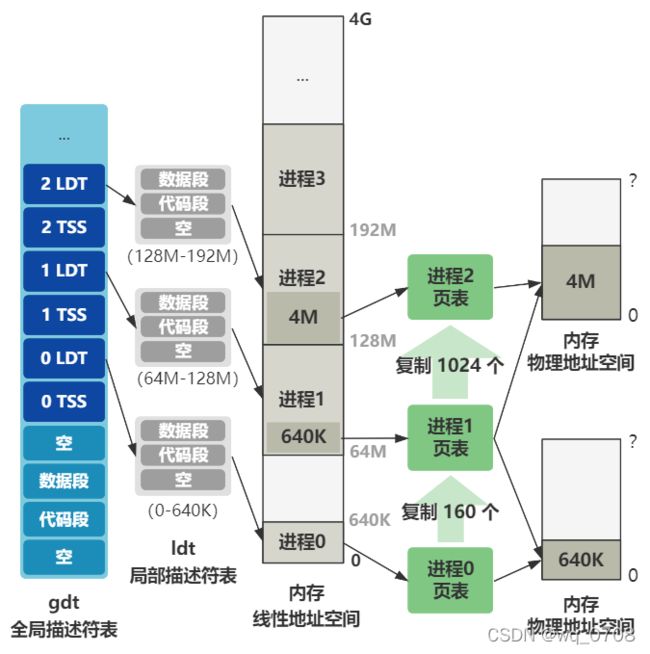
接着往下看:
struct desc_struct {
unsigned long a,b;
}
struct task_struct * task[64] = {&(init_task.task), };
void sched_init(void) {
...
int i;
struct desc_struct * p;
p = gdt+6;
for(i=1;i<64;i++) {
task[i] = NULL;
p->a=p->b=0;
p++;
p->a=p->b=0;
p++;
}
...
}
这段代码有个循环,干了两件事。
-
给一个长度为 64,结构为
task_struct的数组 task 附上初始值。

这个
task_struct结构就是代表每一个进程的信息,这可是个相当相当重要的结构了,把它放在心里
struct task_struct {
/* these are hardcoded - don't touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};
这个循环做的另一件事,是给 gdt 剩下的位置填充上 0,也就是把剩下留给 TSS 和 LDT 的描述符都先附上空值。
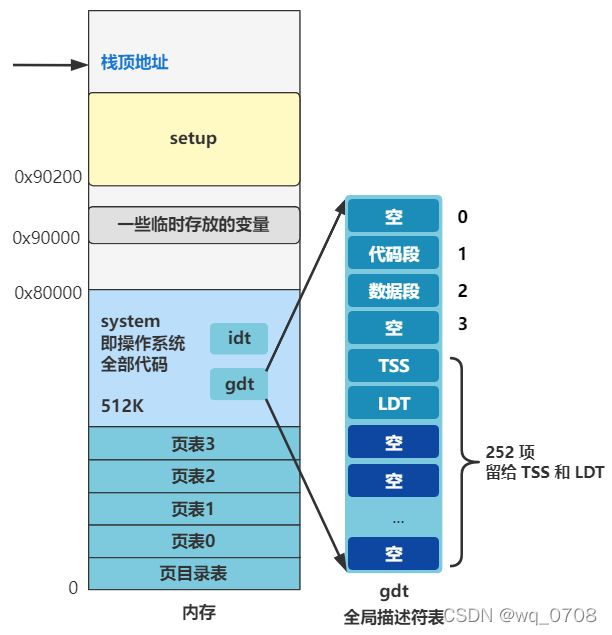
往后展望一下的话,就是以后每创建一个新进程,就会在后面添加一组 TSS 和 LDT 表示这个进程的任务状态段以及局部描述符表信息。还记得刚刚的超纲图吧,未来整个内存的规划就是这样的,不过你先不用理解得很细。
那为什么一开始就先有了一组 TSS 和 LDT 呢?现在也没创建进程呀。错了,现在虽然还没有建立起进程调度的机制,但我们正在运行的代码就是会作为未来的一个进程的指令流。也就是当未来进程调度机制一建立起来,正在执行的代码就会化身成为进程 0 的代码。所以我们需要提前把这些未来会作为进程 0 的信息写好。
如果你觉得很疑惑,别急,等后面整个进程调度机制建立起来,并且让你亲眼看到进程 0 以及进程 1 的创建,以及它们后面因为进程调度机制而切换,你就明白这一切的意义了。
好,初始化了一组 TSS 和 LDT 后,再往下看两行。
#define ltr(n) __asm__("ltr %%ax"::"a" (_TSS(n)))
#define lldt(n) __asm__("lldt %%ax"::"a" (_LDT(n)))
void sched_init(void) {
...
ltr(0);
lldt(0);
...
}
还记得 lidt 和 lgdt 指令么?一个是给 idtr 寄存器赋值,以告诉 CPU 中断描述符表 idt 在内存的位置;一个是给 gdtr 寄存器赋值,以告诉 CPU 全局描述符表 gdt 在内存的位置。系列之四中整个操作系统就30行代码
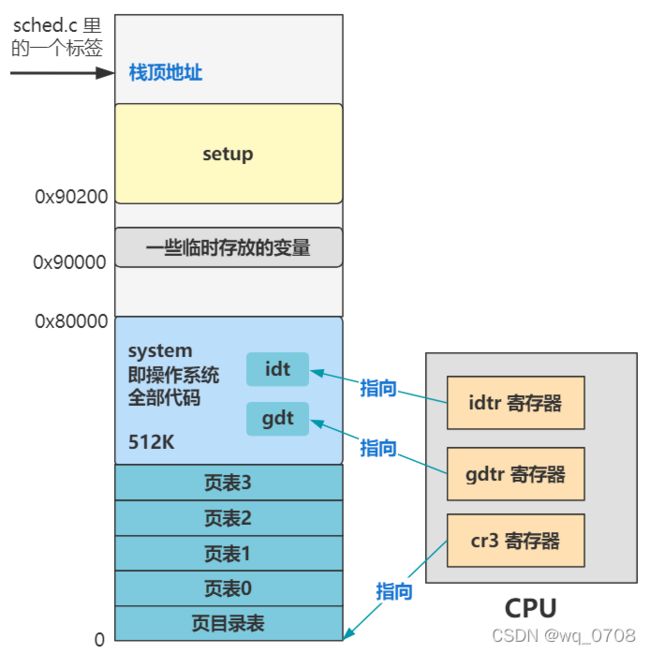
那这两行和刚刚的类似,ltr 是给 tr 寄存器赋值,以告诉 CPU 任务状态段 TSS 在内存的位置;lldt 一个是给 ldt 寄存器赋值,以告诉 CPU 局部描述符 LDT 在内存的位置:

这样,CPU 之后就能通过 tr 寄存器找到当前进程的任务状态段信息,也就是上下文信息,以及通过 ldt 寄存器找到当前进程在用的局部描述符表信息。
我们继续看。
void sched_init(void) {
...
outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
outb_p(LATCH & 0xff , 0x40); /* LSB */
outb(LATCH >> 8 , 0x40); /* MSB */
set_intr_gate(0x20,&timer_interrupt);
outb(inb_p(0x21)&~0x01,0x21);
set_system_gate(0x80,&system_call);
...
}
四行端口读写代码,两行设置中断代码。端口读写我们已经很熟悉了,就是 CPU 与外设交互的一种方式,之前讲硬盘读写以及 CMOS 读写时,已经接触过了。
而这次交互的外设是一个可编程定时器的芯片,这四行代码就开启了这个定时器,之后这个定时器变会持续的、以一定频率的向 CPU 发出中断信号。

而这段代码中设置的两个中断,第一个就是时钟中断,中断号为 0x20,中断处理程序为 timer_interrupt。那么每次定时器向 CPU 发出中断后,便会执行这个函数。
这个定时器的触发,以及时钟中断函数的设置,是操作系统主导进程调度的一个关键!没有他们这样的外部信号不断触发中断,操作系统就没有办法作为进程管理的主人,通过强制的手段收回进程的 CPU 执行权限。
第二个设置的中断叫系统调用 system_call,中断号是 0x80,这个中断又是个非常非常非常重要的中断,所有用户态程序想要调用内核提供的方法,都需要基于这个系统调用来进行。比如 Java 程序员写一个 read,底层会执行汇编指令 int 0x80,这就会触发系统调用这个中断,最终调用到 Linux 里的 sys_read 方法。
这个过程之后会重点讲述,现在只需要知道,在这个地方,偷偷把这个极为重要的中断,设置好了。所以你看这一节的内容,偷偷设置了影响进程和影响用户程序调用系统方法的两个重量级中断处理函数,不简单呀~
到目前为止,中断已经设置了不少了,我们现在看看所设置好的中断有哪些。
| 中断号 | 中断处理函数 |
|---|---|
| 0 ~ 0x10 | trap_init里设置的一堆 |
| 0x20 | timer_interrupt |
| 0x21 | keyboard_interrupt |
| 0x80 | system_call |
其中 0-0x10 这 17 个中断是 trap_init 里初始化设置的,是一些基本的中断,比如除零异常等。这个在系列之四中 中断初始化 trap_init 有讲到。
之后,在控制台初始化 con_init 里,我们又设置了 0x21 键盘中断,这样按下键盘就有反应了。这个在系列之五中 控制台初始化 tty_init 有讲到。
现在,我们又设置了 0x20 时钟中断,并且开启定时器。最后又偷偷设置了一个极为重要的 0x80 系统调用中断。
找到些感觉没,有没有越来越发现,操作系统有点靠中断驱动的意思,各个模块不断初始化各种中断处理函数,并且开启指定的外设开关,让操作系统自己慢慢“活”了起来,逐渐通过中断忙碌于各种事情中,无法自拔。恭喜你,我们已经逐渐在接近操作系统的本质了。
本节回顾:
- 往全局描述符表写了两个结构
TSS和LDT,作为未来进程0的任务状态段和局部描述符表信息。 - 初始化了一个结构为
task_struct的数组,未来这里会存放所有进程的信息,并且我们给数组的第一个位置附上了init_task.init这个具体值,也是作为未来进程 0 的信息。 - 设置了时钟中断 0x20 和系统调用 0x80,一个作为进程调度的起点,一个作为用户程序调用操作系统功能的桥梁,非常之重要
缓冲区初始化buffer_init
接下来我们看缓冲区初始化buffer_init(main函数L10)。首先要注意到,这个函数传了个参数 buffer_memory_end,这个是在系列之四中 内存先划分三个边界值,回顾下:

而且我们在系列之四中 主内存初始化mem_init,用 mem_init 设置好了主内存的管理结构 mam_map:
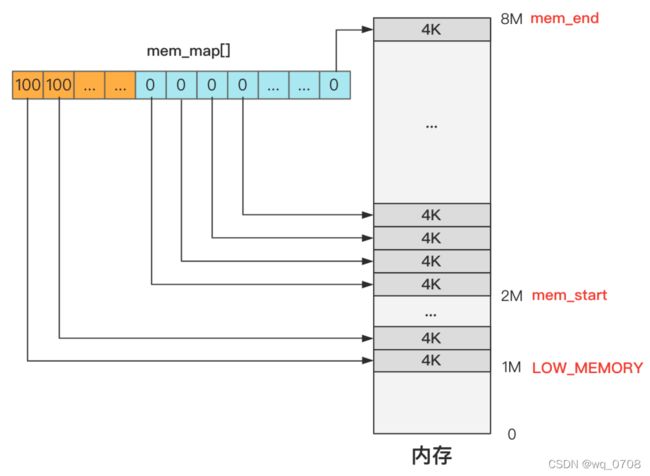
前面是把主内存区管理起来了,所以今天就是把剩下的缓冲区部分,也初始化管理起来。目的就是这么单纯,我们看代码。
我们还是采用之前的方式,就假设内存只有 8M,把一些不相干的分支去掉,方便理解:
extern int end;
struct buffer_head * start_buffer = (struct buffer_head *) &end;
void buffer_init(long buffer_end) {
struct buffer_head * h = start_buffer;
void * b = (void *) buffer_end;
while ( (b -= 1024) >= ((void *) (h+1)) ) {
h->b_dev = 0;
h->b_dirt = 0;
h->b_count = 0;
h->b_lock = 0;
h->b_uptodate = 0;
h->b_wait = NULL;
h->b_next = NULL;
h->b_prev = NULL;
h->b_data = (char *) b;
h->b_prev_free = h-1;
h->b_next_free = h+1;
h++;
}
h--;
free_list = start_buffer;
free_list->b_prev_free = h;
h->b_next_free = free_list;
for (int i=0;i<307;i++)
hash_table[i]=NULL;
}
虽然很长,但其实就造了两个数据结构而已。不过别急,我们先看L5这行代码。有个外部变量 end,而我们的缓冲区开始位置 start_buffer 就等于这个变量的内存地址。这个外部变量 end 并不是操作系统代码写就的,而是由链接器 ld 在链接整个程序时设置的一个外部变量,帮我们计算好了整个内核代码的末尾地址。
那在这之前的是内核代码区域肯定不能用,在这之后的,就给 buffer 用了。所以我们的内存分布图可以更精确一点了:
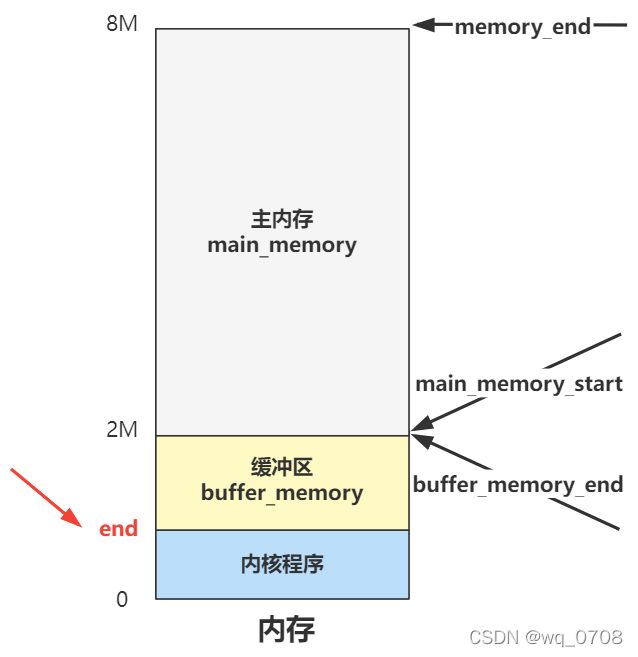
你看,之前的疑惑解决了吧?很好理解嘛,内核程序和缓冲区的划分,肯定有个分界线,这个分界线就是 end 变量的值。这个值定多少合适呢?像主内存和缓冲区的分界线,就直接代码里写死了,就是上图中的 2M。
可是内核程序占多大内存在写的时候完全不知道,就算知道了如果改动一点代码也会变化,所以就由程序编译链接时由链接器程序帮我们把这个内核代码末端的地址计算出来,作为一个外部变量 end 我们拿来即用,就方便多了。
好,回过头我们再看看,整段代码创造了哪两个管理结构?
我们先看这段结构:
void buffer_init(long buffer_end) {
struct buffer_head * h = start_buffer;
void * b = (void *) buffer_end;
while ( (b -= 1024) >= ((void *) (h+1)) ) {
...
h->b_data = (char *) b;
h->b_prev_free = h-1;
h->b_next_free = h+1;
h++;
}
...
}
就俩变量。一个是 buffer_head 结构的 h,代表缓冲头,其指针值是 start_buffer,刚刚我们计算过了,就是图中的内核代码末端地址 end,也就是缓冲区开头。一个是 b,代表缓冲块,指针值是 buffer_end,也就是图中的 2M,就是缓冲区结尾。缓冲区结尾的 b 每次循环 -1024,也就是一页的值,缓冲区结尾的 h 每次循环 +1(一个 buffer_head 大小的内存),直到碰一块为止。
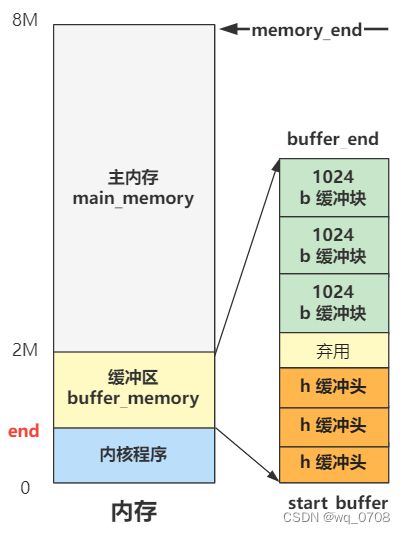
可以看到,其实这个 b 就代表缓冲块,h 代表缓冲头,一个从上往下,一个从下往上。而且这个过程中,h 被附上了属性值,其中比较关键的是这个 buffer 所表示的数据部分 b_data,也就是指向了上面的缓冲块 b。还有这个 buffer 的前后空闲 buffer 的指针 b_prev_free 和 b_next_free。那画成图就是如下这样:

当缓冲头 h 的所有 next 和 prev 指针都指向彼此时,就构成了一个双向链表。继续看。
void buffer_init(long buffer_end) {
...
free_list = start_buffer;
free_list->b_prev_free = h;
h->b_next_free = free_list;
...
}
这三行代码,结合刚刚的双向链表 h,我画出图,你就懂了:

看,free_list 指向了缓冲头双向链表的第一个结构,然后就可以顺着这个结构,从双向链表中遍历到任何一个缓冲头结构了,而通过缓冲头又可以找到这个缓冲头对应的缓冲块。
简单说,缓冲头就是具体缓冲块的管理结构,而 free_list 开头的双向链表又是缓冲头的管理结构,整个管理体系就这样建立起来了。现在,从 free_list 开始遍历,就可以找到这里的所有内容了。
不过,还有最后一个事,能帮助更好管理,往下看:
void buffer_init(long buffer_end) {
...
for (i=0;i<307;i++)
hash_table[i]=NULL;
}
一个 307 大小的 hash_table 数组,这是干嘛的呢?其实今天的这个代码在 buffer.c 中,而 buffer.c 是在 fs 包下的,也就是文件系统包下的。所以它今后是为文件系统而服务,具体是内核程序如果需要访问块设备中的数据,就都需要经过缓冲区来间接地操作。也就是说,读取块设备的数据(硬盘中的数据),需要先读到缓冲区中,如果缓冲区已有了,就不用从块设备读取了,直接取走。
那怎么知道缓冲区已经有了要读取的块设备中的数据呢?从双向链表从头遍历当然可以,但是这效率可太低了。所以需要一个 hashmap 的结构方便快速查找,这就是 hash_table 这个数组的作用。
现在只是初始化这个 hash_table,还并没有哪个地方用到了它,所以我就先简单剧透下。之后当要读取某个块设备上的数据时,首先要搜索相应的缓冲块,是下面这个函数。
#define _hashfn(dev,block) (((unsigned)(dev^block))%307)
#define hash(dev,block) hash_table[_hashfn(dev,block)]
// 搜索合适的缓冲块
struct buffer_head * getblk(int dev,int block) {
...
struct buffer_head bh = get_hash_table(dev,block);
...
}
struct buffer_head * get_hash_table(int dev, int block) {
...
find_buffer(dev,block);
...
}
static struct buffer_head * find_buffer(int dev, int block) {
...
hash(dev,block);
...
}
一路跟下来发现,就是通过dev^block % 307,即**(设备号^逻辑块号) Mod 307**找到在 hash_table 里的索引下标,接下来就和 Java 里的 HashMap 类似,如果哈希冲突就形成链表,画成图就是这样:
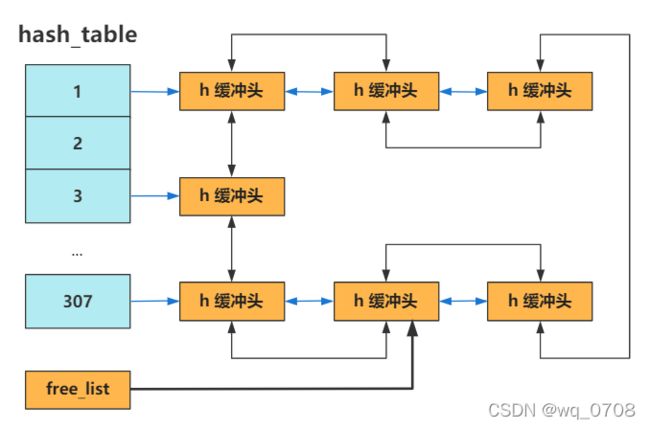
哈希表 + 双向链表,如果刷算法题多了,很容易想到这可以实现 LRU 算法,没错,之后的缓冲区使用和弃用,正是这个算法发挥了作用。也就是之后在讲通过文件系统来读取硬盘文件时,都需要使用和弃用这个缓冲区里的内容,缓冲区即是用户进程的内存和硬盘之间的桥梁。
好了好了,再多说几句就把文件系统里读操作讲出来了,压力太大,本节还是主要了解这个缓冲区的管理工作是如何初始化的,为后面做铺垫。
硬盘初始化
整个初始化的部分,就差 hd_init 和 floppy_init 这两个块设备的初始化还没讲了。而且幸运的是,floppy_init 是软盘初始化,现在软盘几乎都被淘汰了,计算机中也没有软盘驱动器了,所以这个我们完全可以不看,那就剩下一个 hd_init 硬盘初始化了,非常简单!我们直接看 hd_init 这个硬盘初始化干了什么?
//struct blk_dev_struct {
// void (*request_fn)(void);
// struct request * current_request;
//};
//extern struct blk_dev_struct blk_dev[NR_BLK_DEV];
void hd_init(void) {
blk_dev[3].request_fn = do_hd_request;
set_intr_gate(0x2E,&hd_interrupt);
outb_p(inb_p(0x21)&0xfb,0x21);
outb(inb_p(0xA1)&0xbf,0xA1);
}
就这?一共就四行代码。没错,初始化嘛,往往都比较简单,尤其是对硬件设备的初始化,大体都是:
-
往某些 IO 端口上读写一些数据,表示开启它;
-
然后再向中断向量表中添加一个中断,使得 CPU 能够响应这个硬件设备的动作;
-
最后再初始化一些数据结构来管理。不过像是内存管理可能结构复杂些,外设的管理,相对就简单很多了。
看第一行代码:
void hd_init(void) {
blk_dev[3].request_fn = do_hd_request;
...
}
我们把 blk_dev 数组索引 3 位置处的块设备管理结构 blk_dev_struct 的 request_fn 赋值为了 do_hd_request,这是啥意思呢?因为有很多块设备,所以 Linux 0.11 内核用了一个 blk_dev[] 来进行管理,每一个索引表示一个块设备:
struct blk_dev_struct blk_dev[NR_BLK_DEV] = {
{ NULL, NULL }, /* no_dev */
{ NULL, NULL }, /* dev mem */
{ NULL, NULL }, /* dev fd */
{ NULL, NULL }, /* dev hd */
{ NULL, NULL }, /* dev ttyx */
{ NULL, NULL }, /* dev tty */
{ NULL, NULL } /* dev lp */
};
你看,索引为 3 这个位置,就表示给硬盘 hd 这个块设备留的位置。那么每个块设备执行读写请求都有自己的函数实现,在上层看来都是一个统一函数 request_fn 即可,具体实现各有不同,对于硬盘来说,这个实现就是 do_hd_request 函数。
是不是有点像接口?这其实就是多态思想在 C 语言的体现嘛~ 用 Java 程序员熟悉的话就是,父类引用 request_fn 指向子类对象 do_hd_request 的感觉咯
我们再看第二行:
void hd_init(void) {
...
set_intr_gate(0x2E,&hd_interrupt);
...
}
对于中断我们已经很熟悉了,这里就是又设置了一个新的中断,中断号是 0x2E,中断处理函数是 hd_interrupt,也就是说硬盘发生读写时,硬盘会发出中断信号给 CPU,之后 CPU 便会陷入中断处理程序,也就是执行 hd_interrupt 函数
_hd_interrupt:
...
xchgl _do_hd,%edx
...
// 如果是读盘操作,这个 do_hd 是 read_intr
static void read_intr(void) {
...
do_hd_request();
...
}
好了,又多了一个中断,那我们再次梳理下目前开启的中断都有哪些:
| 中断号 | 中断处理函数 |
|---|---|
| 0 ~ 0x10 | trap_init里设置的一堆 |
| 0x20 | timer_interrupt |
| 0x21 | keyboard_interrupt |
| 0x2E | hd_interrupt |
| 0x80 | system_call |
现在,我们在硬盘初始化 hd_init 里,又设置了硬盘中断,这样硬盘读写完成后将通过中断来通知 CPU。
上节我提醒大家,有没有感觉到操作系统的中断驱动的特征,那本回再给大家展望一下。
看到最后,你会发现操作系统就是一个靠中断驱动的死循环而已,如果不发生任何中断,操作系统会一直在一个死循环里等待。换句话说,让操作系统工作的唯一方式,就是触发中断
再往下看后两行:
void hd_init(void) {
...
outb_p(inb_p(0x21)&0xfb,0x21);
outb(inb_p(0xA1)&0xbf,0xA1);
}
就是往几个 IO 端口上读写,其作用是允许硬盘控制器发送中断请求信号,仅此而已。我们向来是不深入硬件细节,知道往这个端口里写上这些数据,导致硬盘开启了中断,即可。
OK,本节就结束了,仅仅看初始化工作,太简单了,连图都不用画。当然hd.c里还有很多读写硬盘的方法,这个在之后文件系统用到他们时,自然会讲起,这里就抛个引子,看看读硬盘最最底层的操作流程,是怎样的。我们看硬盘的端口表:
| 端口 | 读 | 写 |
|---|---|---|
| 0x1F0 | 数据寄存器 | 数据寄存器 |
| 0x1F1 | 错误寄存器 | 特征寄存器 |
| 0x1F2 | 扇区计数寄存器 | 扇区计数寄存器 |
| 0x1F3 | 扇区号寄存器或 LBA 块地址 0~7 | 扇区号或 LBA 块地址 0~7 |
| 0x1F4 | 磁道数低 8 位或 LBA 块地址 8~15 | 磁道数低 8 位或 LBA 块地址 8~15 |
| 0x1F5 | 磁道数高 8 位或 LBA 块地址 16~23 | 磁道数高 8 位或 LBA 块地址 16~23 |
| 0x1F6 | 驱动器/磁头或 LBA 块地址 24~27 | 驱动器/磁头或 LBA 块地址 24~27 |
| 0x1F7 | 命令寄存器或状态寄存器 | 命令寄存器 |
那读硬盘就是,往除了第一个以外的后面几个端口写数据,告诉要读硬盘的哪个扇区,读多少。然后再从 0x1F0 端口一个字节一个字节的读数据。这就完成了一次硬盘读操作。
如果觉得不够具体,那来个具体的版本:
-
在
0x1F2写入要读取的扇区数 -
在
0x1F3 ~ 0x1F6这四个端口写入计算好的起始 LBA 地址 -
在
0x1F7处写入读命令的指令号 -
不断检测
0x1F7(此时已成为状态寄存器的含义)的忙位 -
如果第四步骤为不忙,则开始不断从
0x1F0处读取数据到内存指定位置,直到读完
而操作系统的代码,也是这样写的,我们一睹为快一下,不用理解细节:
static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,
unsigned int head,unsigned int cyl,unsigned int cmd,
void (*intr_addr)(void)) {
...
do_hd = intr_addr;
outb_p(hd_info[drive].ctl,HD_CMD);
port = 0x1f0;
outb_p(hd_info[drive].wpcom>>2,++port);
outb_p(nsect,++port);
outb_p(sect,++port);
outb_p(cyl,++port);
outb_p(cyl>>8,++port);
outb_p(0xA0|(drive<<4)|head,++port);
outb(cmd,++port);
}
看,那些 outb_p 方法,转换成汇编语言,就是 out 指令,往指定的硬盘 IO 端口上写数据,达到我们想要的读或者写的目的。是不是很 low?但我们由用户层写的各种 read\write 函数,即便是经过系统调用、文件系统、缓冲区管理等等过程,但只要是读写硬盘,最终都要调用到这个最底层的函数,殊途同归,逃不掉的!
好了,至此,我们就把所有的初始化工作,都讲完了!坚持读到现在的,都为自己鼓鼓掌!!!