SparkGraphX快速入门
1 图
图是由顶点和边组成的,并非代数中的图。图可以对事物以及事物之间的关系建模,图可以用来表示自然发生的连接数据,如:
社交网络
互联网web页面
常用的应用有:
在地图应用中找到最短路径
基于与他人的相似度图,推荐产品、服务、人际关系或媒体
2 术语
2.1 顶点和边

2.2 有向图和无向图
在有向图中,一条边的两个顶点一般扮演者不同的角色,比如父子关系、页面A连接向页面B;
在一个无向图中,边没有方向,即关系都是对等的,比如qq中的好友。
GraphX中有一个重要概念,所有的边都有一个方向,那么图就是有向图,如果忽略边的方向,就是无向图。
2.3 有环图和无环图
有环图是包含循环的,一系列顶点连接成一个环。无环图没有环。在有环图中,如果不关心终止条件,算法可能永远在环上执行,无法退出。
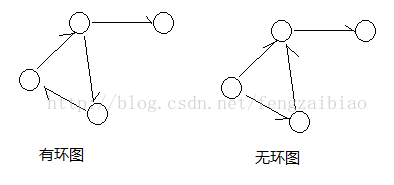
2.4 度、出边、入边、出度、入度
度表示一个顶点的所有边的数量
出边是指从当前顶点指向其他顶点的边
入边表示其他顶点指向当前顶点的边
出度是一个顶点出边的数量
入度是一个顶点入边的数量
2.5 超步
图进行迭代计算时,每一轮的迭代叫做一个超步
3 图数据库和Spark GraphX
图形数据库:是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息,有自己的查询语言,现在有几十种图查询语言,数据库的接口比较弱,只支持简单的查询。
GraphX:是一个计算引擎,提供了强大的计算接口,可以很方便的处理复杂的业务逻辑。
4 发展历程
早在 0.5 版本,Spark 就带了一个小型的Bagel 模块,提供了类似 Pregel 的功能。这个版本还非常原始,性能和功能都比较弱,属于实验型产品。
到 0.8 版本时,鉴于业界对分布式图计算的需求日益见涨,Spark 开始独立一个分支Graphx-Branch,作为独立的图计算模块,借鉴 GraphLab,开始设计开发 GraphX。
在 0.9 版本中,这个模块被正式集成到主干,虽然是 Alpha 版本,但已可以试用,小面包圈Bagel 告别舞台。1.0 版本,GraphX 正式投入生产使用。
5 存储模式
巨型图的存储总体上有边分割和点分割两种存储方式。2013 年,GraphLab2.0 将其存储方式由边分割变为点分割,在性能上取得重大提升,目前基本上被业界广泛接受并使用。
边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。点分割(Vertex-Cut):每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
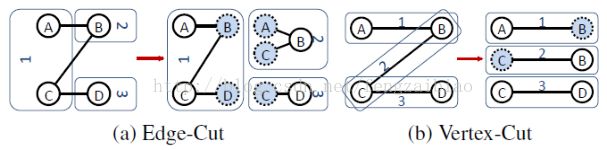
虽然两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架都将自己底层的存储形式变成了点分割。主要原因有以下两个:
1. 磁盘价格下降,存储空间不再是问题,而内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵。这点就类似于常见的空间换时间的策略。
2. 在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量相差非常悬殊。而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割存储方式被渐渐抛弃了。
Graphx 借鉴 PowerGraph,使用的是Vertex-Cut(点分割)方式存储图,用三个 RDD 存储图
数据信息:
VertexTable(id, data):id 为 Vertex id,data 为 Edge data
EdgeTable(pid, src, dst, data):pid 为 Partion id,src 为原定点 id,dst 为目的顶点 id
RoutingTable(id, pid):id 为 Vertex id,pid 为 Partion id
点分割存储实现如下图所示:

6 图计算模式
目前基于图的并行计算框架已经有很多,比如来自 Google 的 Pregel、来自 Apache 开源的图计算框架 Giraph/HAMA 以及最为著名的 GraphLab,其中 Pregel、HAMA 和 Giraph 都是非常类似的,都是基于 BSP(Bulk Synchronous Parallell)模式,Spark GraphX也是。
Bulk Synchronous Parallell,即整体同步并行计算模型,它将计算分成一系列的超步(superstep)的迭代(iteration)。从纵向上看,它是一个串行模式,而从横向上看,它是一个并行的模式,每两个 superstep 之间设置一个栅栏(barrier),即整体同步点,确定所有并行的计算都完成后再启动下一轮 superstep。
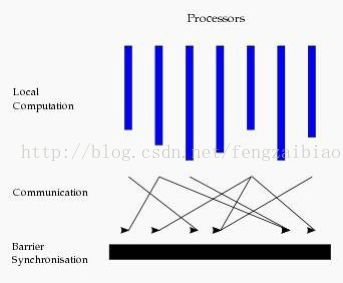
每一个超步(superstep)包含三部分内容:
1. 计算 compute:每一个processor 利用上一个 superstep 传过来的消息和本地的数据进行本地计算;
2. 消息传递:每一个 processor 计算完毕后,将消息传递个与之关联的其它 processors;
3. 整体同步点:用于整体同步,确定所有的计算和消息传递都进行完毕后,进入下一个superstep。
7 SparkGraphX操作
如同Spark一样,GraphX的Graph类提供了丰富的图运算符,大致结构如下图所示:
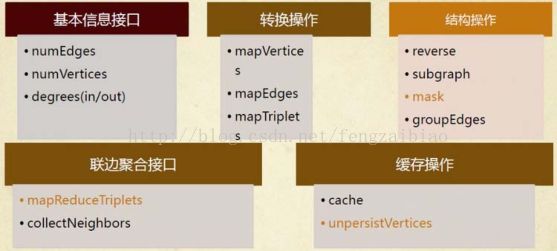
7.1 GraphX的构造
1根据边构建图(Graph.fromEdges)
deffromEdgeTuples[VD: ClassTag](
rawEdges: RDD[(VertexId, VertexId)],
defaultValue: VD,
uniqueEdges:Option[PartitionStrategy] = None,
edgeStorageLevel: StorageLevel =StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel =StorageLevel.MEMORY_ONLY): Graph[VD, Int]
注意:VertexId为64位的Long类型
2根据边的两个点元数据构建(Graph.fromEdgeTuples)
deffromEdges[VD: ClassTag, ED: ClassTag](
edges: RDD[Edge[ED]],
defaultValue: VD,
edgeStorageLevel: StorageLevel =StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel =StorageLevel.MEMORY_ONLY): Graph[VD, ED]
3根据顶点和边构造数据
defapply[VD: ClassTag, ED: ClassTag](
vertices: RDD[(VertexId, VD)],
edges: RDD[Edge[ED]],
defaultVertexAttr: VD = null.asInstanceOf[VD],
edgeStorageLevel: StorageLevel =StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel =StorageLevel.MEMORY_ONLY): Graph[VD, ED]
7.2 一些常用API操作
val triplets: RDD[EdgeTriplet[VD, ED]]
Graph的一个属性,所有的边缘属性,包含源点、源点属性、目标点、目标点属性、边属性
defmapTriplets[ED2: ClassTag](
map: EdgeTriplet[VD, ED] => ED2,
tripletFields: TripletFields): Graph[VD, ED2]
使用map函数处理每个边缘的属性,传递相邻两个顶点的属性,得到一个新的图,如果不需要顶点的值,使用mapEdge。
def subgraph(
epred: EdgeTriplet[VD, ED] => Boolean =(x => true),
vpred: (VertexId, VD) => Boolean =((v, d) => true))
: Graph[VD, ED]
通过边过滤epred, 通过顶点过滤vpred得到新的图。
defaggregateMessages[A: ClassTag](
sendMsg: EdgeContext[VD, ED, A] => Unit,
mergeMsg: (A, A) => A,
tripletFields: TripletFields =TripletFields.All)
: VertexRDD[A]
聚集从本地邻居顶点发送的消息。sendMsg,运行在每条边上,把消息发送到相邻的顶点;mergeMsg,把发送到同一顶点的消息聚合起来;tripletFields,规定哪些字段会传递到sendMsg函数的EdgeContext中,设置合理的值会提高性能。
8 迭代操作Pregel
8.1 定义
defapply[VD: ClassTag, ED: ClassTag, A: ClassTag]
(graph: Graph[VD, ED],
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection =EdgeDirection.Either)
(vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
有2个参数列表
参数列表一:初始化一些参数
initialMsg第一次迭代msg的值
maxIterations迭代的次数
activeDirectionPregel的终止条件是不再有消息发送。在每轮迭代中,如果边上的顶点没有收到上一轮迭代传递的消息,那么这条边就不会调用sendMsg函数。这个参数指定了这个过滤条件;对于一条边的两个顶点srcId和dstId:
EdgeDirection.Out,当srcId收到来自上一轮迭代的消息时,就会调用sendMsg,把这条边当做srcId的“出边”。
EdgeDirection.In,当dstId收到来自上一轮迭代的消息时,就会调用sendMsg,这意味着把这条边当做dstId的“入边”。
EdgeDirection.Either,只要srcId或dstId收到来自上一轮迭代的消息时,就会调用sendMsg。
EdgeDirection.Both,只有srcId和dstId都收到来自上一轮迭代的消息时,才会调用sendMsg。
参数列表二:处理逻辑
vprog,用户定义的顶点程序运行在每一个顶点中,负责接收进来的信息,和计算新的顶点值。在第一次迭代的时候,所有的顶点程序将会被默认的defaultMessage调用,在次轮迭代中,顶点程序只有接收到message才会被调用。
sendMsg,用户提供的函数,应用于边缘顶点在当前迭代中接收message
mergeMsg,用户提供定义的函数,将两个类型为A的message合并为一个类型为A的message。
8.2 Pregel的运行过程
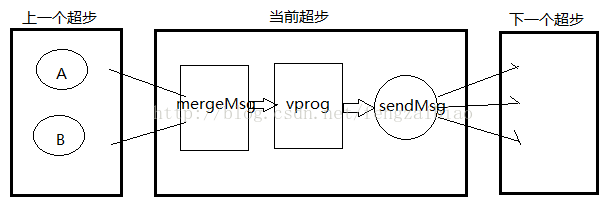
在第一次迭代的时候,所有的顶点都会接收到initialMsg消息;
上一个超步传递过来的顶点消息,会通过自定义的mergeMsg函数聚合成单一的消息;
自定义的vprog函数决定如何用函数mergeMsg传来的消息来更新顶点数据;
自定义的sendMsg函数决定在下个超步中哪些顶点会接收到消息;
下个超步中如果顶点没有收到消息,vprog就不会调用。
操作实例:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
object Test {
def main(args: Array[String]) {
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
//设置运行环境
val conf = new SparkConf().setAppName("GraphXTest").setMaster("local[*]")
val sc = new SparkContext(conf)
//设置顶点和边,注意顶点和边都是用元组定义的 Array
//顶点的数据类型是 VD:(String,Int)
val vertexArray = Array(
(1L, ("Alice", 28)),
(2L, ("Bob", 27)),
(3L, ("Charlie", 65)),
(4L, ("David", 42)),
(5L, ("Ed", 55)),
(6L, ("Fran", 50))
)
//边的数据类型 ED:Int
val edgeArray = Array(
Edge(2L, 1L, 7),
Edge(2L, 4L, 2),
Edge(3L, 2L, 4),
Edge(3L, 6L, 3),
Edge(4L, 1L, 1),
Edge(5L, 2L, 2),
Edge(5L, 3L, 8),
Edge(5L, 6L, 3)
)
//构造 vertexRDD 和 edgeRDD
val vertexRDD: RDD[(Long, (String, Int))] = sc.parallelize(vertexArray)
val edgeRDD: RDD[Edge[Int]] = sc.parallelize(edgeArray)
//构造图 Graph[VD,ED]
val graph: Graph[(String, Int), Int] = Graph(vertexRDD, edgeRDD)
println("***********************************************")
println("属性演示")
println("**********************************************************")
println("找出图中年龄大于 30 的顶点:")
graph.vertices.filter { case (id, (name, age)) => age > 30 }.collect.foreach {
case (id, (name, age)) => println(s"$name is $age")
}
graph.triplets.foreach(t => println(s"triplet:${t.srcId},${t.srcAttr},${t.dstId},${t.dstAttr},${t.attr}"))
//边操作:找出图中属性大于 5 的边
println("找出图中属性大于 5 的边:")
graph.edges.filter(e => e.attr > 5).collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
//triplets 操作,((srcId, srcAttr), (dstId, dstAttr), attr)
println("列出边属性>5 的 tripltes:")
for (triplet <- graph.triplets.filter(t => t.attr > 5).collect) {
println(s"${triplet.srcAttr._1} likes ${triplet.dstAttr._1}")
}
println
//Degrees 操作
println("找出图中最大的出度、入度、度数:")
def max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = {
if (a._2 > b._2) a else b
}
println("max of outDegrees:" + graph.outDegrees.reduce(max) + ", max of inDegrees:" + graph.inDegrees.reduce(max) + ", max of Degrees:" +
graph.degrees.reduce(max))
println
println("**********************************************************")
println("转换操作")
println("**********************************************************")
println("顶点的转换操作,顶点 age + 10:")
graph.mapVertices { case (id, (name, age)) => (id, (name,
age + 10))
}.vertices.collect.foreach(v => println(s"${v._2._1} is ${v._2._2}"))
println
println("边的转换操作,边的属性*2:")
graph.mapEdges(e => e.attr * 2).edges.collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
println("**********************************************************")
println("结构操作")
println("**********************************************************")
println("顶点年纪>30 的子图:")
val subGraph = graph.subgraph(vpred = (id, vd) => vd._2 >= 30)
println("子图所有顶点:")
subGraph.vertices.collect.foreach(v => println(s"${v._2._1} is ${v._2._2}"))
println
println("子图所有边:")
subGraph.edges.collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
println("**********************************************************")
println("连接操作")
println("**********************************************************")
val inDegrees: VertexRDD[Int] = graph.inDegrees
case class User(name: String, age: Int, inDeg: Int, outDeg: Int)
//创建一个新图,顶点 VD 的数据类型为 User,并从 graph 做类型转换
val initialUserGraph: Graph[User, Int] = graph.mapVertices { case (id, (name, age))
=> User(name, age, 0, 0)
}
//initialUserGraph 与 inDegrees、outDegrees(RDD)进行连接,并修改 initialUserGraph中 inDeg 值、outDeg 值
val userGraph = initialUserGraph.outerJoinVertices(initialUserGraph.inDegrees) {
case (id, u, inDegOpt) => User(u.name, u.age, inDegOpt.getOrElse(0), u.outDeg)
}.outerJoinVertices(initialUserGraph.outDegrees) {
case (id, u, outDegOpt) => User(u.name, u.age, u.inDeg, outDegOpt.getOrElse(0))
}
println("连接图的属性:")
userGraph.vertices.collect.foreach(v => println(s"${v._2.name} inDeg: ${v._2.inDeg} outDeg: ${v._2.outDeg}"))
println
println("出度和入读相同的人员:")
userGraph.vertices.filter {
case (id, u) => u.inDeg == u.outDeg
}.collect.foreach {
case (id, property) => println(property.name)
}
println
println("**********************************************************")
println("聚合操作")
println("**********************************************************")
println("找出年纪最大的follower:")
val oldestFollower: VertexRDD[(String, Int)] = userGraph.aggregateMessages[(String,
Int)](
// 将源顶点的属性发送给目标顶点,map 过程
et => et.sendToDst((et.srcAttr.name,et.srcAttr.age)),
// 得到最大follower,reduce 过程
(a, b) => if (a._2 > b._2) a else b
)
userGraph.vertices.leftJoin(oldestFollower) { (id, user, optOldestFollower) =>
optOldestFollower match {
case None => s"${user.name} does not have any followers."
case Some((name, age)) => s"${name} is the oldest follower of ${user.name}."
}
}.collect.foreach { case (id, str) => println(str) }
println
println("**********************************************************")
println("聚合操作")
println("**********************************************************")
println("找出距离最远的顶点,Pregel基于对象")
val g = Pregel(graph.mapVertices((vid, vd) => (0, vid)), (0, Long.MinValue), activeDirection = EdgeDirection.Out)(
(id: VertexId, vd: (Int, Long), a: (Int, Long)) => math.max(vd._1, a._1) match {
case vd._1 => vd
case a._1 => a
},
(et: EdgeTriplet[(Int, Long), Int]) => Iterator((et.dstId, (et.srcAttr._1 + 1+et.attr, et.srcAttr._2))) ,
(a: (Int, Long), b: (Int, Long)) => math.max(a._1, b._1) match {
case a._1 => a
case b._1 => b
}
)
g.vertices.foreach(m=>println(s"原顶点${m._2._2}到目标顶点${m._1},最远经过${m._2._1}步"))
// 面向对象
val g2 = graph.mapVertices((vid, vd) => (0, vid)).pregel((0, Long.MinValue), activeDirection = EdgeDirection.Out)(
(id: VertexId, vd: (Int, Long), a: (Int, Long)) => math.max(vd._1, a._1) match {
case vd._1 => vd
case a._1 => a
},
(et: EdgeTriplet[(Int, Long), Int]) => Iterator((et.dstId, (et.srcAttr._1 + 1, et.srcAttr._2))),
(a: (Int, Long), b: (Int, Long)) => math.max(a._1, b._1) match {
case a._1 => a
case b._1 => b
}
)
// g2.vertices.foreach(m=>println(s"原顶点${m._2._2}到目标顶点${m._1},最远经过${m._2._1}步"))
sc.stop()
}
}
本文参考资料:http://www.cnblogs.com/shishanyuan
《Spark GraphX实战》